

| 项目 | MySQL |
| 博客名称 | 2003031126-石升福-Python数据分析第七周作业 |
| 班级链接 | 20级数据班(本) |
| 作业链接 | 第七周作业 |
| 要求 | 每道题要有题目,代码(使用插入代码,不会插入代码的自己查资料解决,不要直接截图代码!!),截图(只截运行结果) |
一.*扩展阅读:小白必看!超详细MySQL下载安装教程
1.数据库可以存储数据、优化读写,关系型数据库由大量表格组成,表与表之间有关联;Mysql、SqlServer、Oracle等都属于关系型数据库管理系统。
2.mysol的安装需要经过五个步骤
(1)登入官网下载mysql的安装包,官网地址:https://dev.mysql.com/downloads/mysql/
(2)下载格式
(3)点击下载,下载完成后为压缩包。
(4)将 zip 包解压缩
(5).在【安装目录】内,新建 my.ini 空文件
3.需要进行环境配置,方便调用数据库,相当于一个快捷方式。
二.*扩展阅读:MySQL教程
所有平台的 MySQL 下载地址为: MySQL 下载 。 挑选你需要的 MySQL Community Server 版本及对应的平台。你也可以使用 MariaDB 代替,MariaDB 数据库管理系统是 MySQL 的一个分支,主要由开源社区在维护,采用 GPL 授权许可。开发这个分支的原因之一是:甲骨文公司收购了 MySQL 后,有将 MySQL 闭源的潜在风险,因此社区采用分支的方式来避开这个风险。在成功安装 MySQL 后,一些基础表会表初始化,在服务器启动后,你可以通过简单的测试来验证 MySQL 是否工作正常。
三.*扩展阅读:MySQL卸载
1.确认你的mysql服务是关闭的状态,不然卸载不干净。
2.在我的电脑(计算机)-- 管理 – 服务和应用程序 – 服务,找到mysql 把状态关闭,在控制面板中卸载mysql软件。
3.卸载过后删除C:Program Files (x86)\MySQL该目录下剩余了所有文件,把mysql文件夹也删了。因为我的系统是64位,把软件安装的位置是E盘,所以按这个路径去查找删除。E:ProgramData \MySQL
四.作业
1.安装好MySQL,连接上Navicat
2..完成课本练习(代码4-1~3/4-9~31)。
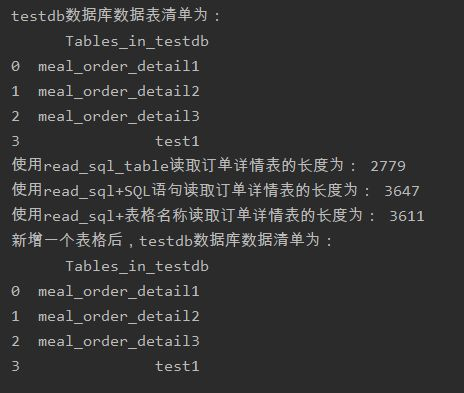
from sqlalchemy import create_engine #创建一个MySQL连接器,用户名为root,密码为root1234 #地址为127.0.0.1数据库名称为testdb,编码为UTF—8 engine=create_engine("mysql+pymysql://root:root@127.0.0.1:3306/testdb? charset=utf8") print(engine) import pandas as pd #使用read_sql_query查看testdb中的数据表书目 formlist=pd.read_sql_query('show tables',con=engine) print('testdb数据表清单为:","\n ',formlist) #使用read_sql_table读取订单详情表 detail1=pd.read_sql_table('meal_order_detail1',con=engine) print("使用read_sql_query读取清单的长度为:",len(detail1)) detail2=pd.read_sql('select*from meal_order_detail2',con=engine) print("使用read_sql函数+SQL语句读取的订单详情表长度为:",len(detail2)) detail3=pd.read_sql('meal_order_detail3',con=engine) print('使用read_sql函数+SQL语句读取的订单详情表长度为:',len(detail3)) #使用to_sql存储orderDate detail1.to_sql('test1',con=engine,index=False,if_exists='replace') #使用read_sql读取test表 formlist1=pd.read_sql_query('show tables',con=engine) print('新增一个表格后,testdb数据表清单为:“,”\n',formlist1)
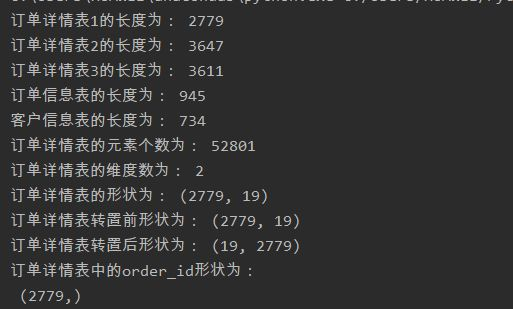
#导入sqlalchemy 库的 create_engine函数 from sqlalchemy import create_engine engine=create_engine("mysql+pymysql://root:root@127.0.0.1:3306/testdb?charset=utf8") import pandas as pd order1=pd.read_sql_table('meal_order_detail1',con=engine) print("订单详情表1的长度为:",len(order1)) order2=pd.read_sql_table('meal_order_detail2',con=engine) print("订单详情表2的长度为:",len(order2)) order3=pd.read_sql_table('meal_order_detail3',con=engine) print("订单详情表3的长度为:",len(order3)) orderinfo=pd.read_table('E:/桌面/meal_order_info (1).csv',sep=",",encoding='gbk') print('订单信息表的长度为:',len(orderinfo)) userinfo=pd.read_excel('E:/桌面/users (1).xlsx') print('客户信息表的长度为:',len(userinfo))
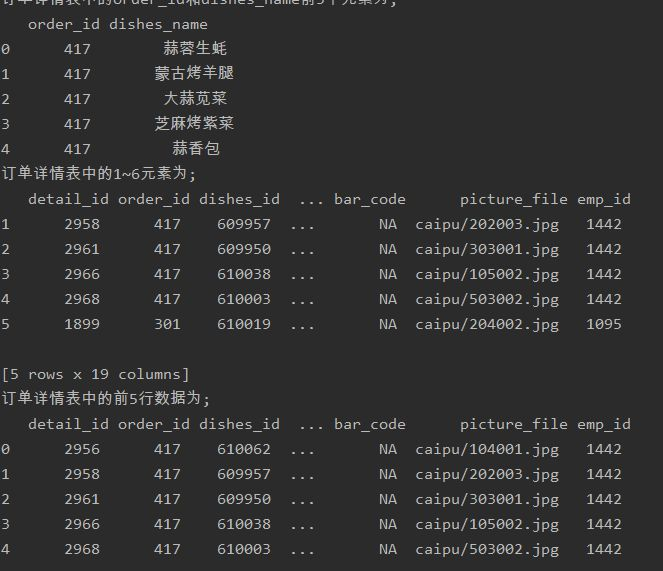
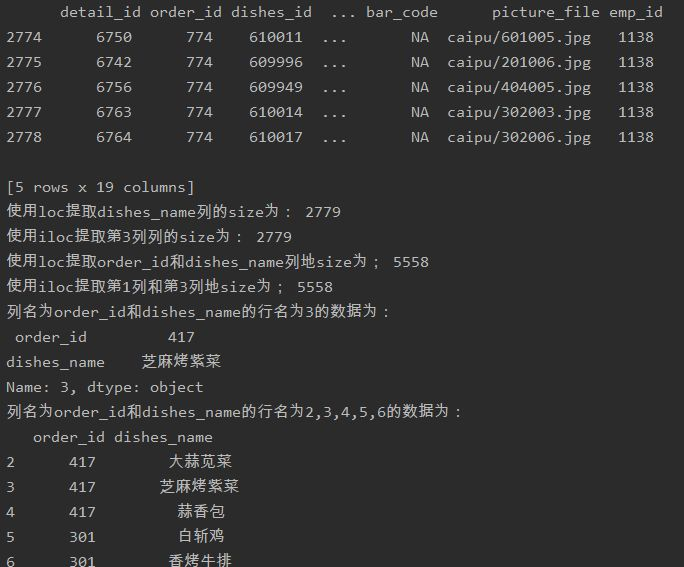
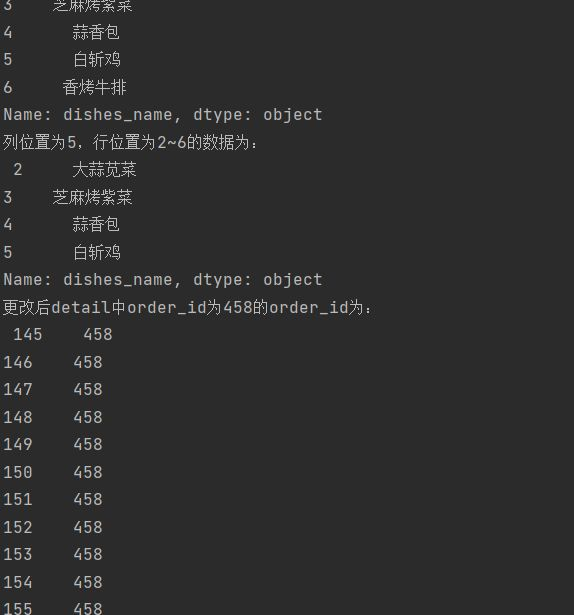
detail = pd.read_sql_table('meal_order_detail1',con = engine) '''print('订单详情的索引表为:',detail.index) print('订单详情表的所有值为:','\n',detail.values) print('订单详情表列名为:','\n',detail.columns) print('订单详情表的数据类型为:','\n',detail.dtypes)''' #查看DataFrame的元素个数 print('订单详情表的元素个数为:',detail.size) print('订单详情表的维度数为:',detail.ndim)#查看DataFrame的维度数 print('订单详情表的形状为:',detail.shape)#查看DataFrame的形状 print('订单详情表转置前形状为:',detail.shape) print('订单详情表转置后形状为:',detail.T.shape) #使用字典访问的方式取出orderInfo中的某一列 order_id = detail['order_id'] print('订单详情表中的order_id形状为:','\n',order_id.shape) #使用访问属性的方式取出orderInfo中的菜品名称列 dishes_name = detail.dishes_name print('订单详情表中的dishes_name的形状为:','\n',dishes_name.shape) dishes_name5 = detail['dishes_name'][:5] print('订单详情表中的dishes_name前5个元素为;','\n',dishes_name5) orderDish = detail[['order_id','dishes_name']][:5] print('订单详情表中的order_id和dishes_name前5个元素为;','\n',orderDish) order5 = detail[:][1:6] print('订单详情表中的1~6元素为;','\n',order5) print('订单详情表中的前5行数据为;','\n',detail.head()) print('订单详情表中的后5行数据为;','\n',detail.tail()) dishes_name1 = detail.loc[:,'dishes_name'] print('使用loc提取dishes_name列的size为:',dishes_name1.size) dishes_name2 = detail.iloc[:,3] print('使用iloc提取第3列列的size为:',dishes_name2.size) orderDish1 = detail.loc[:,['order_id','dishes_name']] print('使用loc提取order_id和dishes_name列地size为;',orderDish1.size) orderDish2 = detail.iloc[:,[1,3]] print('使用iloc提取第1列和第3列地size为;',orderDish2.size) print('列名为order_id和dishes_name的行名为3的数据为:\n',detail.loc[3,['order_id','dishes_name']]) print('列名为order_id和dishes_name的行名为2,3,4,5,6的数据为:\n',detail.loc[2:6,['order_id','dishes_name']]) print('列位置为1和3,,行位置为3的数据为:\n',detail.iloc[3,[1,3]]) print('列位置为1和3,,行位置为2,3,4,5,6的数据为:\n',detail.iloc[2:7,[1,3]]) #loc内部传入表达式 print('detail中order_id为458的dishes_name为:\n',detail.loc[detail['order_id']=='458',['order_id','dishes_name']]) #错误示例如下: #print('detail中order_id为458的第1、5列数据为:\n',detail.iloc[detail['order_id']=='458',[1,5]]) print('detail中order_id为458的第1,5列数据为:\n',detail.iloc[(detail['order_id']=='458').values,[1,5]]) print('列名为dishes_name行名为 2,3,4,5,6的数据为:\n',detail.loc[2:6,'dishes_name']) print('列位置为5,行位置为2~6的数据为:\n',detail.iloc[2:6,5]) #print('列位置为5,行名为2~6的数据为:', '\n',detail.ix[2:6,5]) #pandas的1.0.0版本后,已经对ix进行了升级和重构。 #将ordeer_id为458的变换为45800 detail.loc[detail['order_id']=='458','ordeer_id'] = '45800' print('更改后detail中order_id为458的order_id为:\n',detail.loc[detail['order_id']=='458','order_id']) print('更改后detail中order_id为45800的order_id为:\n',detail.loc[detail['order_id']=='45800','order_id']) detail['payment'] = detail['counts']*detail['amounts'] print('detail新增列payment的前5行为:','\n',detail['payment'].head()) detail['pay_way'] = '现金支付' print('detail新增列pay_way的前5行为:','\n',detail['pay_way'].head()) print('删除pay_way前detail的列索引为:','\n',detail.columns) detail.drop(labels = 'pay_way',axis = 1,inplace = True) print('删除pay_way后detail的列索引为:','\n',detail.columns) print('删除1~10行前detail的长度为:',len(detail)) detail.drop(labels = range(1,11),axis = 0,inplace = True) print('删除1~10行后detail的长度为:',len(detail))



 浙公网安备 33010602011771号
浙公网安备 33010602011771号