[数据分析] target encoding
本文整理了target encoding的相关知识,如果你对特征编码的内容不太了解,建议先阅读一下参考资料[1],在对特征编码方法有一定了解后,本文的阅读会更加轻松。
特征编码可以仅基于特征本身进行,也可以结合目标值(target)的信息进行。Target encoding就是一种结合目标值进行特征编码的方式。正式地来讲,target encoding是将特征值替换为给定特征取值,目标值在训练数据中的先验概率和后验概率的混合。后面的例子会帮助你更好地理解这句话的意思。
1. 编码方式
1.1 二分类
在二分类中,对于特征\(i\),target encoding在该特征取值为\(k\)时的编码值为类别\(k\)对应的目标值期望\(E(y|x^i=x_k^i)\)。
在给定训练样本时,估算期望的最直接方式为训练样本中相同类别\(x_k^i\)的目标变量\(y\)的均值:
\(\hat{x}_{k}^{i}=\frac{\sum_{j=1}^{n} \mathbb{I}{\left\{x_{j}^{i}=x_{k}^{i}\right\} \cdot y_{i}}}{\sum_{j=1}^{n} \mathbb{I}{\left\{x_{j}^{i}=x_{k}^{i}\right\}}}\)
让我们看个例子[4]
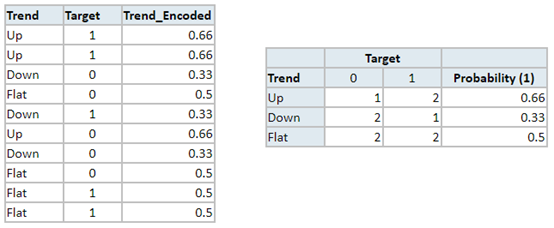
在这个数据集中,特征\(i\)的可能取值为Up, Down, Flat,我们试着对k=Up进行编码。
在样本集中一共有10条记录,其中3条记录中特征Trend的取值为Up,我们关注这3条记录。在k=Up时,目标值的期望为2/3 ≈ 0.66,所以我们将Up编码为0.66。
这种简单的编码方式也被称为Greedy TS,在这里,我们只考虑了目标值在数据中的后验分布。
这种编码方式很简单,但可能存在标签泄露的问题。看一个极端的例子,如果训练集长这个样子:
| Trend | Target | Trend_Encoded |
|---|---|---|
| Up | 1 | 1 |
| Down | 1 | 1 |
| Flat | 0 | 0 |
| UpThenFlat | 1 | 1 |
| UpThenDown | 0 | 0 |
| FlatThenDown | 1 | 1 |
此时,我们编码的特征值原封不动地反映了目标值的信息。
后文会提到针对这个问题,我们可以如何改进编码方式。在此之前,我们先看看如何在多分类问题中进行编码。
1.2 多分类
在m分类问题中,可以生成m-1个特征,每个特征分别表示第i类的概率。
1.3 缺失值问题
可将缺失值看为新的一类,计算编码的方式与原来相同
2. 标签泄露(target leakage)
在特征类别较多或者是数据分布不平均时,使用简单的target encoding容易过拟合训练集,也称为标签泄露。下面我们列举几种处理标签泄露问题的方法。
2.1 Additive smoothing
结合标签的先验分布来改进编码方式。它的想法是,当某个类别值对应的样本过少时,其均值并不可信。通过结合所有样本的目标值均值可以对编码进行平滑。
目前实现最多的target encoding的定义方式如下
\(\hat{x}_{k}^{i}=\frac{\sum_{j=1}^{n} \mathbb{I}{\left\{x_{j}^{i}=x_{k}^{i}\right\} \cdot y_{i}+a p}}{\sum_{j=1}^{n} \mathbb{I}_{\left\{x{j}^{i}=x_{k}^{i}\right\}}+a}\)
公式中,\(a\)为用户自定义参数,用来调节先验在最终编码结果中的贡献程度,\(p\)可以设置成全部标签的均值。
2.2 Cross-validation
Kaggle竞赛中的参赛者较常使用这种方式。
Cross-validation将训练数据分成k份,在计算某一份的target encoding时,我们不使用这一份中对应的目标值进行计算,而是使用剩余k-1份数据,进行对应标签的target encoding计算。
对于同一个属性值,这种方式产生的encoding一般是不一致的。在测试集中,对应的target encoding可以通过将训练集中这些属性的encoding取平均获得。[9]
3. Target encoding的优点与局限
3.1 优点
Target encoding是一种简单、快速的编码方式,在二分类的情况下,它不增加数据集的维度。
这种编码方式提取了有助于解释目标值的信息。
3.2 局限性
Target encoding依赖于目标值的分布,容易出现过拟合的问题。
这种编码方式并不是任何时候都能改进模型结果,能否改进与数据集相关。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号