

使用SQL Server 2008提供的表分区向导
表分区(Partition Table)是自从SQL Server 2005就开始提供的功能,解决的问题是大型表的存储和查询。
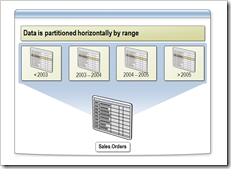
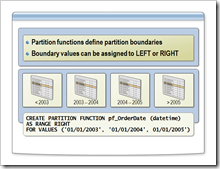
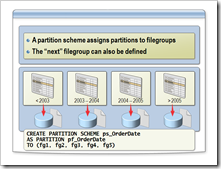
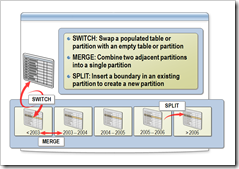
我们之前大致的语法是这样的
-- =========================
-- 演示:陈希章
-- 如何创建分区函数
-- 如何创建分区架构
-- 如何创建分区表
--=========================
alter database adventureWorks add filegroup [fg1]
go
alter database adventureWorks add filegroup [fg2]
go
alter database adventureWorks add filegroup [fg3]
go
alter database adventureWorks
add file
(name='fg1',
filename='c:\fg1.ndf',
size=5mb)
to filegroup [fg1]
go
alter database adventureWorks
add file
(name='fg2',
filename='d:\fg2.ndf',
size=5mb)
to filegroup [fg2]
go
alter database adventureWorks
add file
(name='fg3',
filename='e:\fg3.ndf',
size=5mb)
to filegroup [fg3]
go
use adventureWorks
go
Create partition function emailPF(nvarchar(50)) as range right for values ('G','N')--创建分区函数
go
Create partition scheme emailPS as partition emailPF to (fg1,fg2,fg3)--创建分区方案
go
Create table customermail (custid int, email nvarchar(50)) on emailPS(email)--创建分区表
Go
为了简化操作,SQL Server 2008中为表分区提供了相关的操作
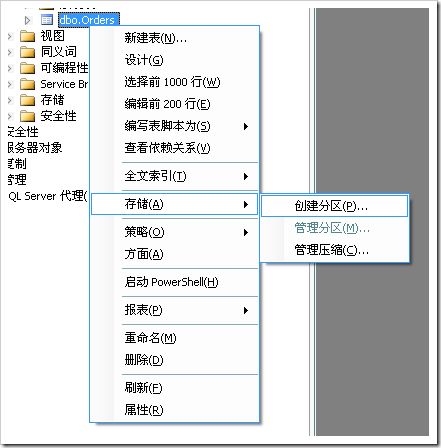

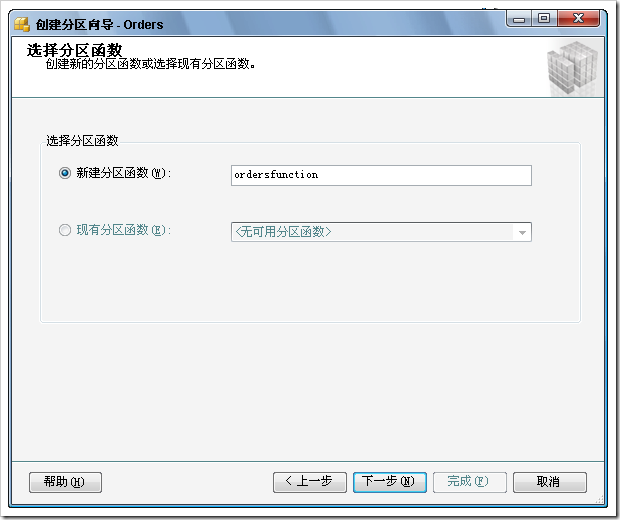


最后生成的脚本是这样的
USE [demo]
GO
BEGIN TRANSACTION
CREATE PARTITION FUNCTION [ordersfunction](date) AS RANGE LEFT FOR VALUES (N'2008-01-01', N'2008-02-01', N'2008-03-01')
CREATE PARTITION SCHEME [ordersscheme] AS PARTITION [ordersfunction] TO ([PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY])
CREATE CLUSTERED INDEX [ClusteredIndex_on_ordersscheme_633765890752500000] ON [dbo].[Orders]
(
[OrderDate]
)WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [ordersscheme]([OrderDate])
DROP INDEX [ClusteredIndex_on_ordersscheme_633765890752500000] ON [dbo].[Orders] WITH ( ONLINE = OFF )
COMMIT TRANSACTION

 浙公网安备 33010602011771号
浙公网安备 33010602011771号