

《spring源码IOC主流程解析+ spring解决循环依赖的思路方法》
一、主流程图
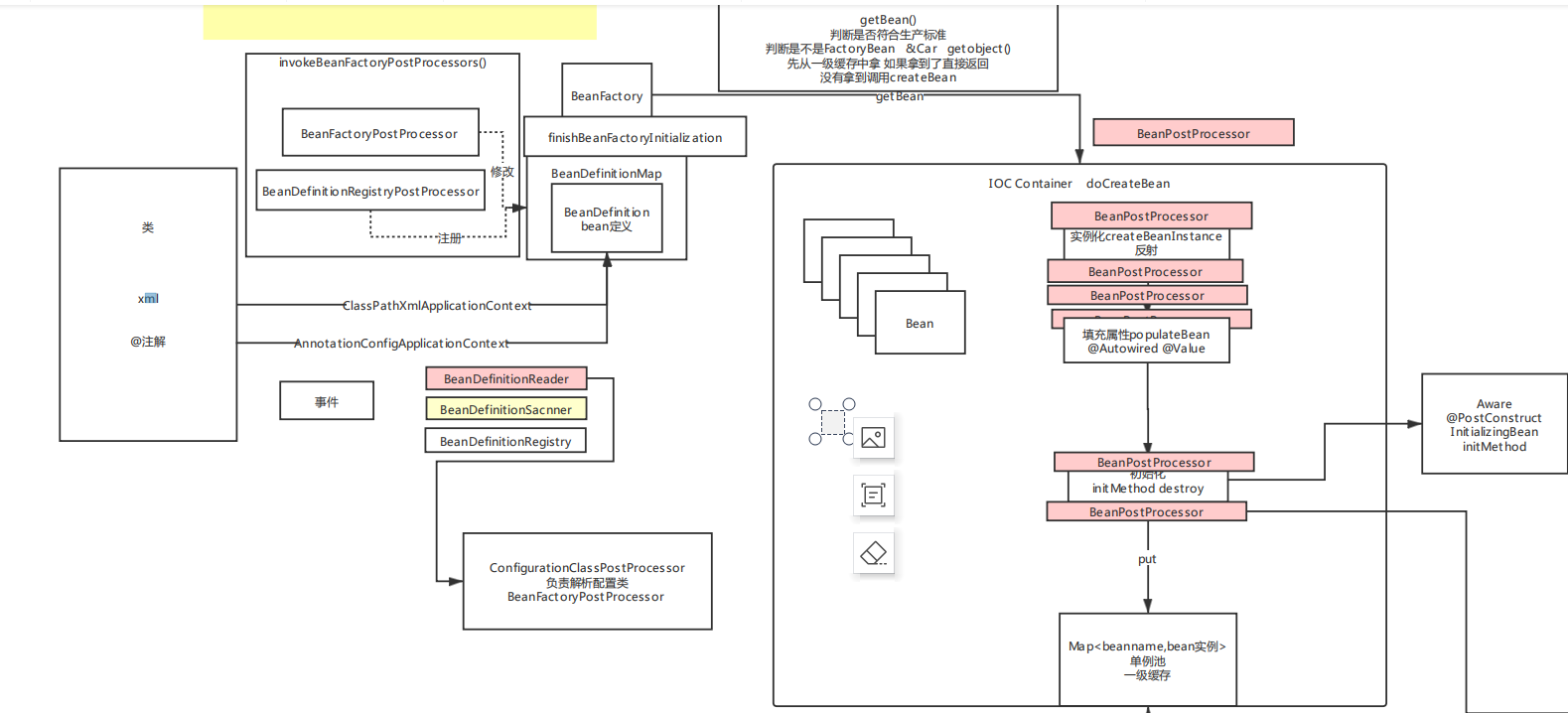
二、源码刨析(IOC主要加载流程)
1. 创建配置类,以及spring的上下文解析配置的主类,来解析包下的所有类 cn.tulignxueyuan;
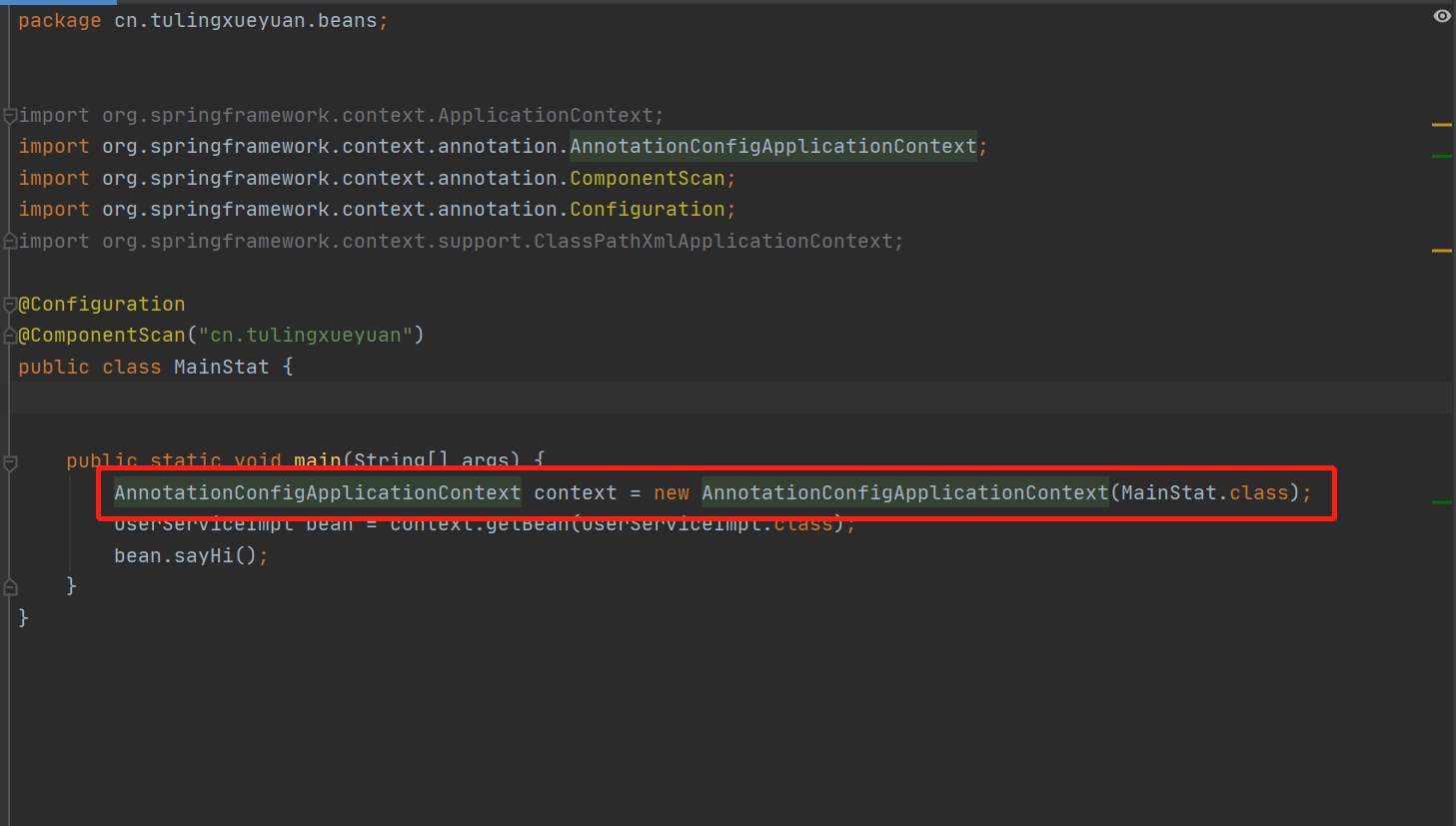
2.点击进入AnnotationConfigApplicationContext类中,主要有三个方法;
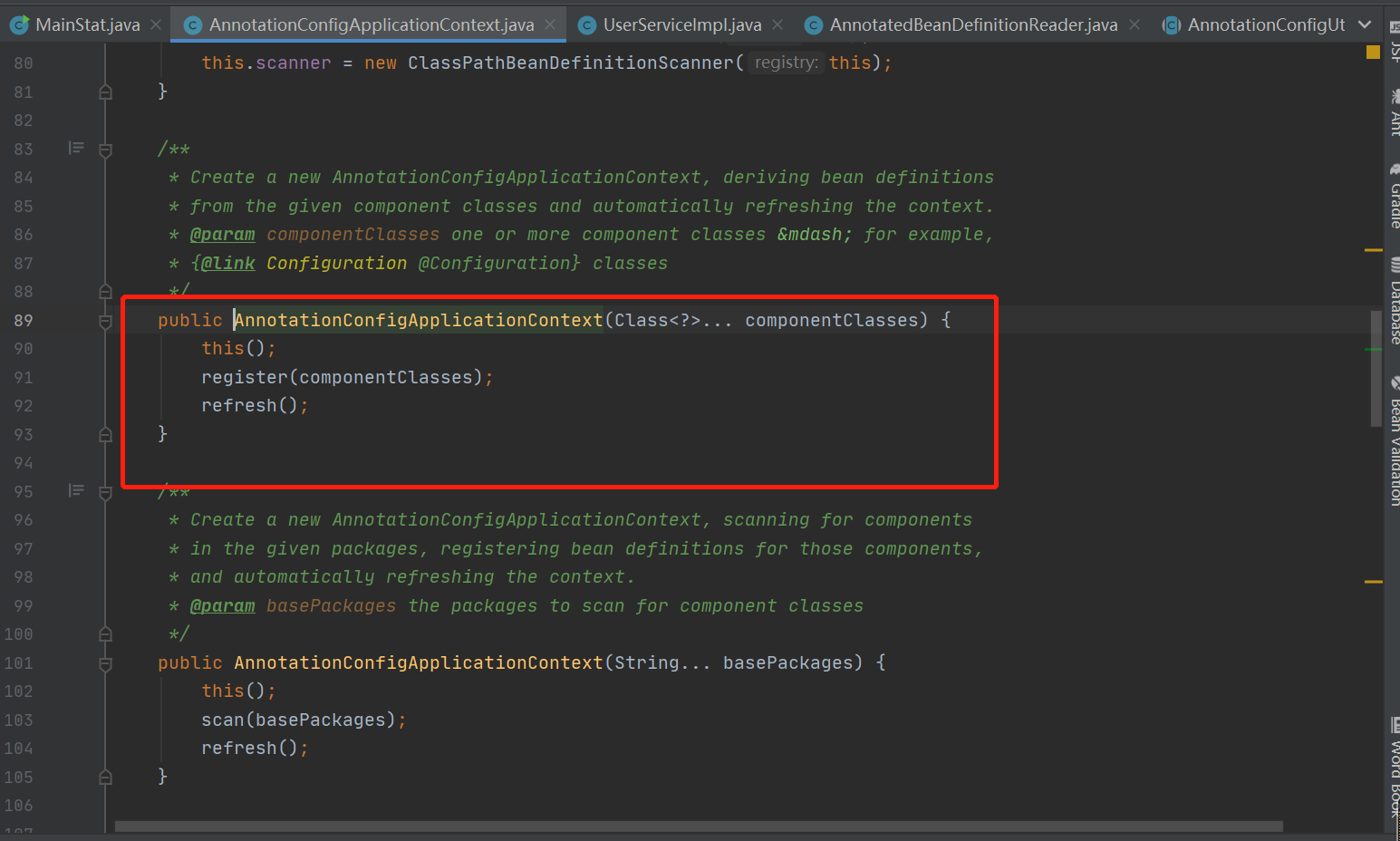
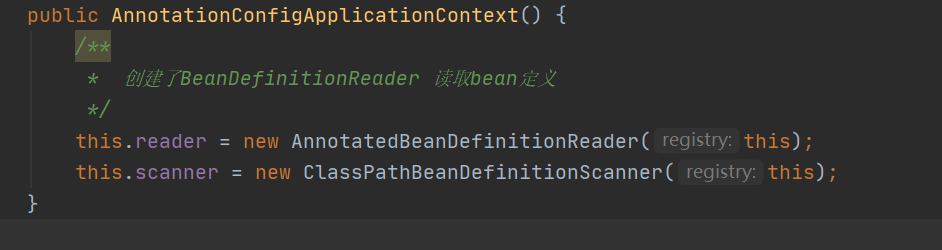
3.this()方法主要做了 创建了beanFactory以及BeanDefinitionReader来读取bean定义类,BeanDefinitionReader将configClasspostprocess类注册到BeanDefinitionMap中(注;这里创建DefinitionScanner不是真正的扫描bean定义的类,这个DefinitionScanner的作用是可以在外面,也就是上下文AnnotationConfigApplicationContext调用scan()扫描自定义的包)
4.点击AnnotatedBeanDefinitionReader类到AnnotationConfigUtils类中,创建了几个创世纪类,也就是解析配置文件类解析有关@Import,@bean @value等等注解的类,还有自动注入的@Autowired类;
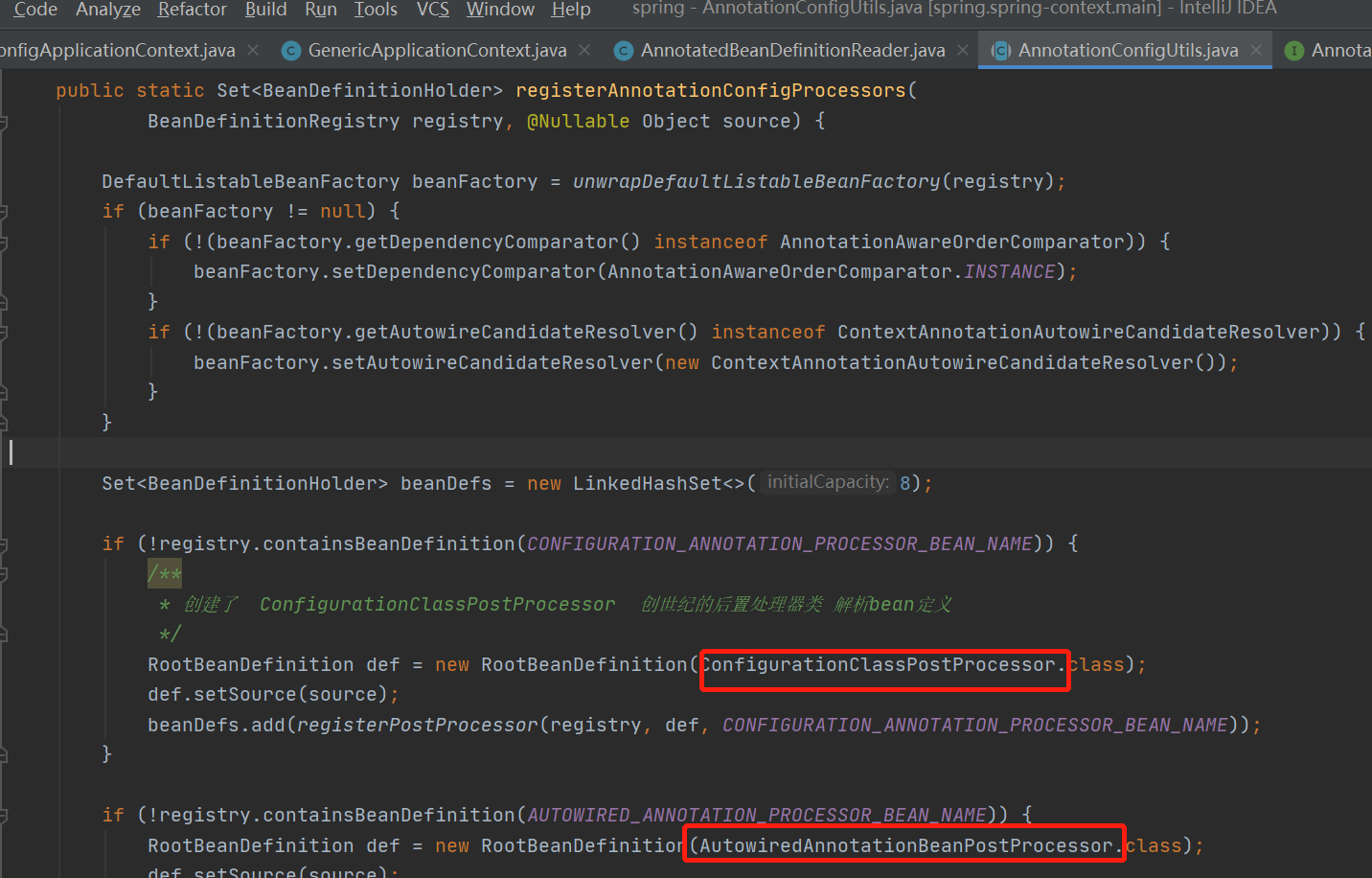
5.上面创建了用来解析配置的类,这一步我们在跳回去,看register(),这个方法其实就是将配置类注册成bean定义并放入到BeanDefinitionMap中;
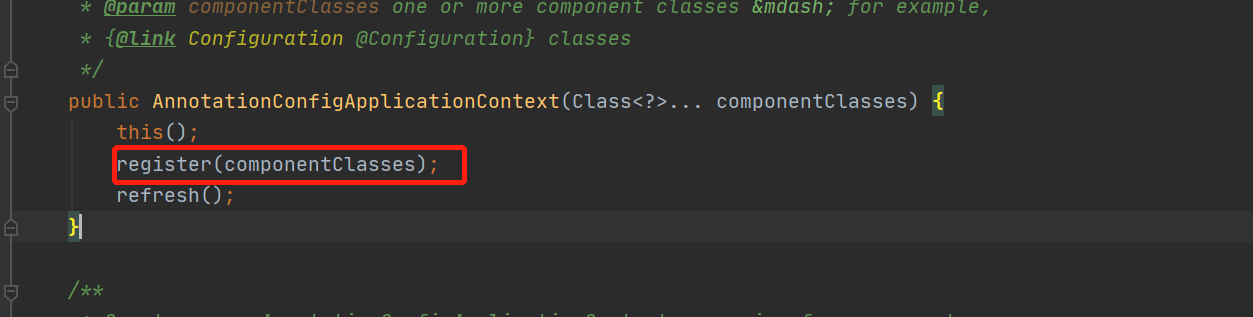
6 refresh()方法里有两个重要方法invokeBeanFactoryPostProcessors(beanFactory)和finishBeanFactoryInitialization(beanFactory),前者是实例化解BeanDefinitionMap中的创世纪类configClasspostprocess类并通过它来解析配置类MainStat的bean定义,后者是真正实例化所有单例bean,调用BeanFactory.getBean()方法来创建实例化bean,属性注入,以及初始化initbean,同时调用9次 beanPostProcess以及很多的Aware接口;
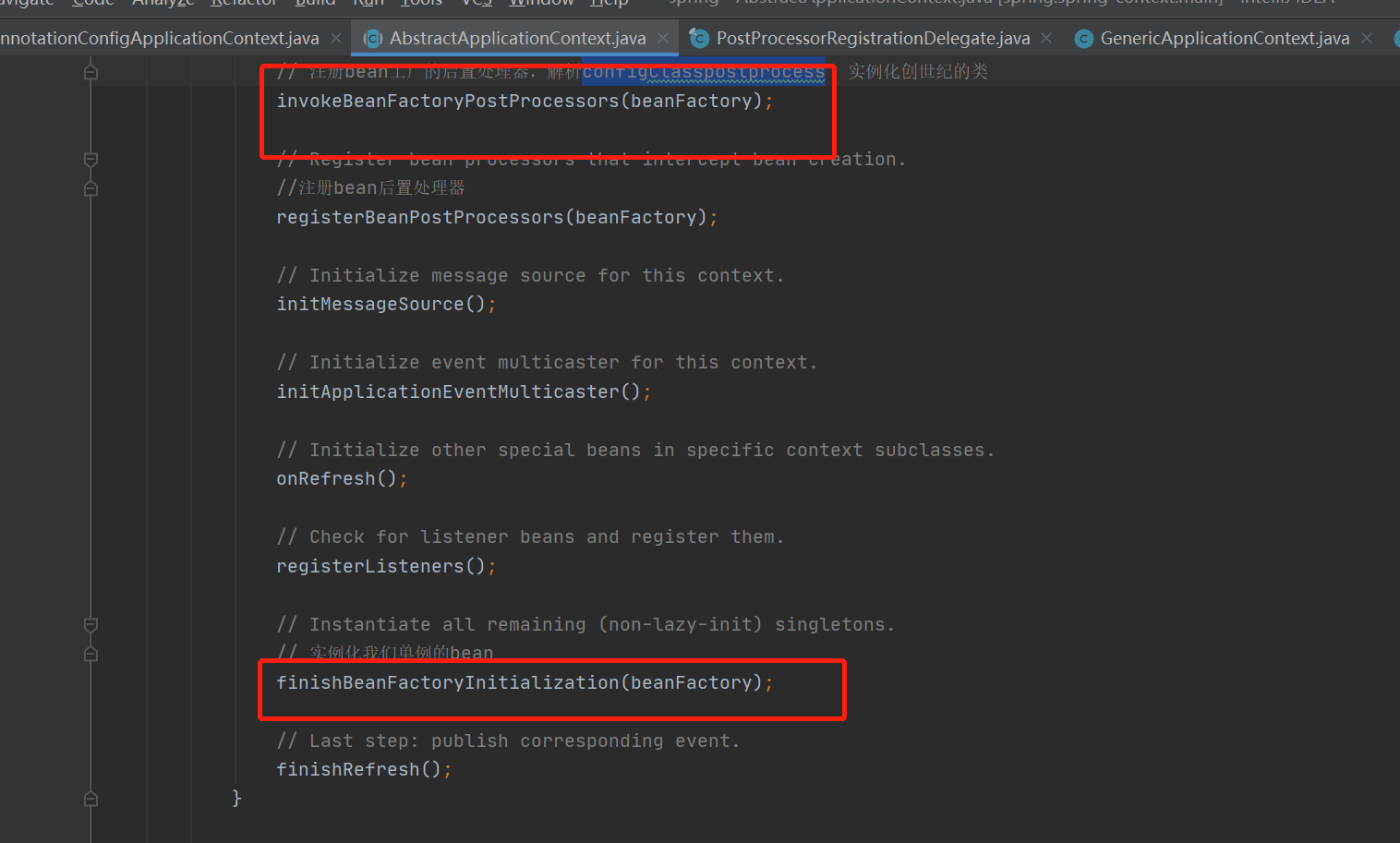
三、源码刨析(具体分析创世纪类以及配置类实现后置处理器的解析过程)
1.、上面IOC整体加载流程已经说明,实例化创世纪类以及配置类的方法就是invokeBeanFactoryPostProcessors(beanFactory);
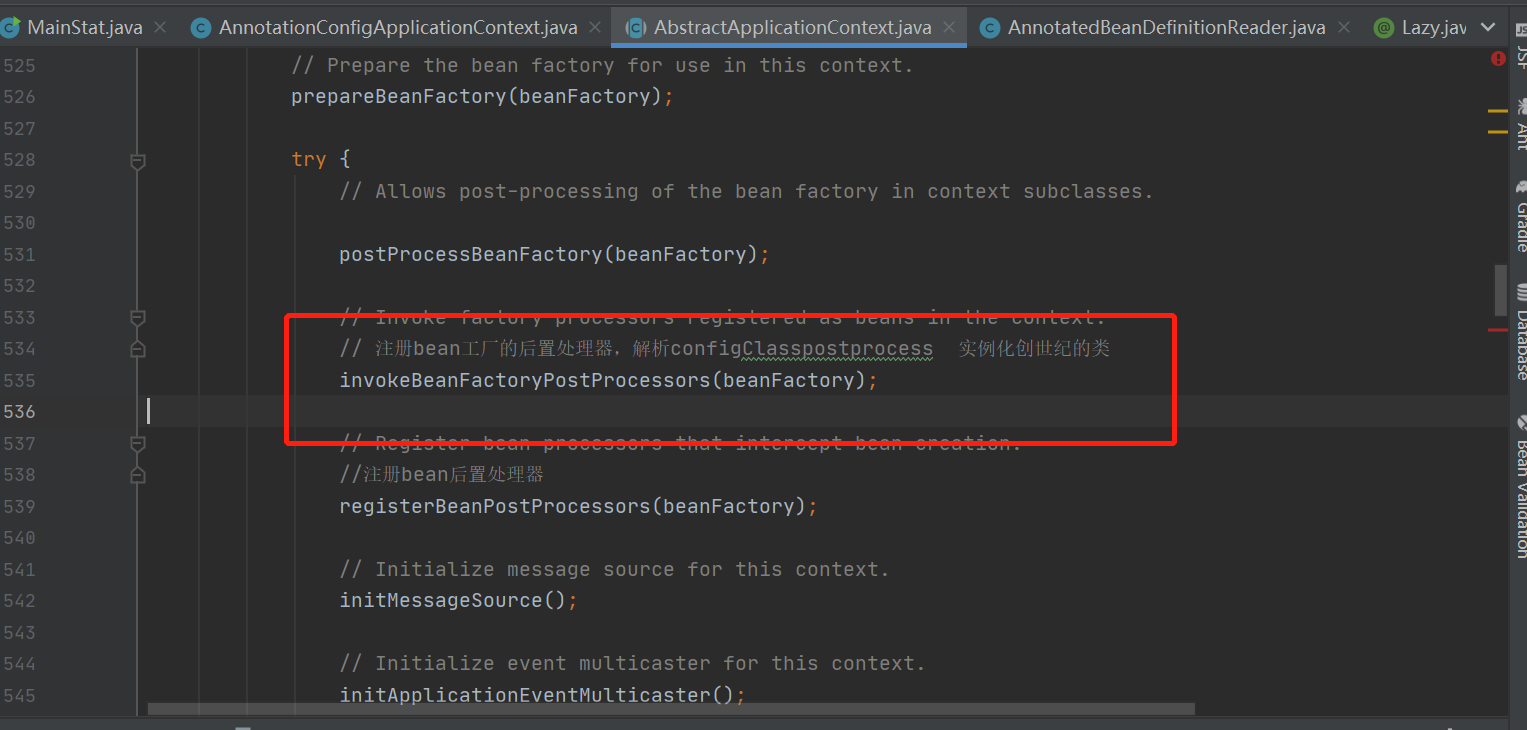
2、点击进去,红色标记的方法,再次跳进
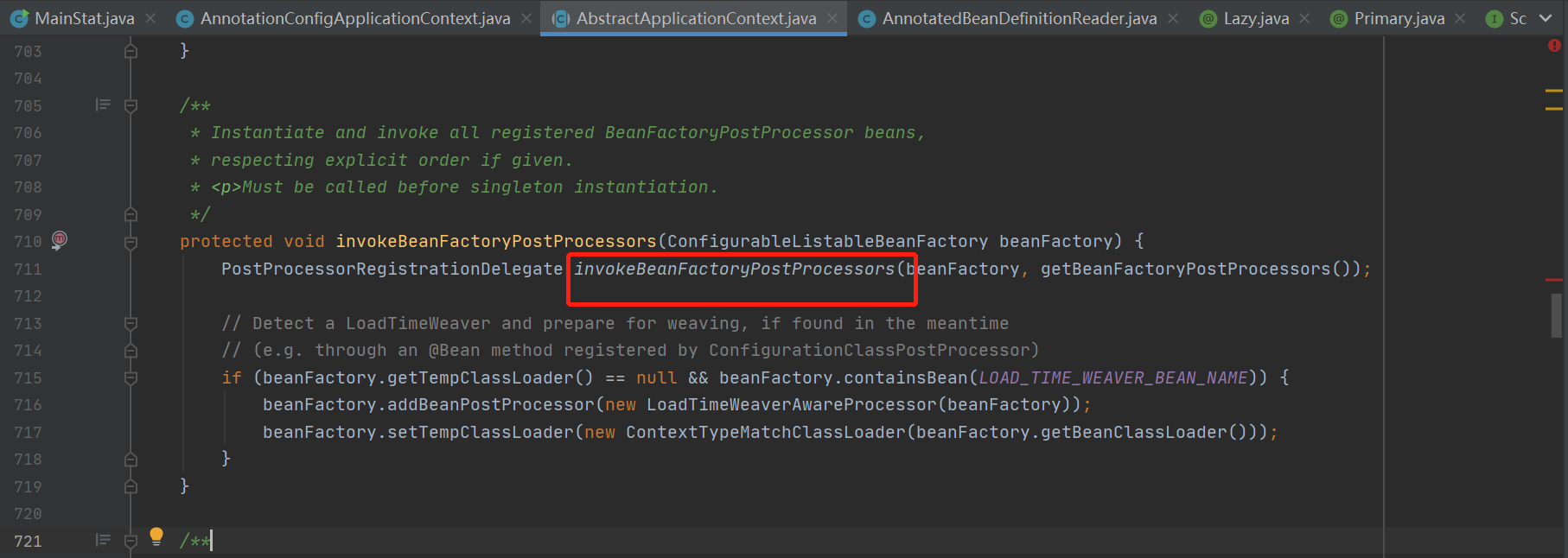
3.这里的方法就很重要了,有四种场景分别为:实现BeanDefinitionRegistryPostProcessor、PriorityOrdered由先执行,其次实BeanDefinitionRegistryPostProcessor、Ordered,然后只是实现了BeanDefinitionRegistryPostProcessor,最后实现了BeanDefinitionRegistryPostProcessor、beanFactoryPostProcessors, IOC提供了这四种场景就可以让我们程序员自由发挥,将我们自己定义的bean定义实现想要的效果,当然解析配置类的创世纪类configClassPostProcess实现了第一种所以优先执行,我们自己也可以定义一个配置类来实现这四种创景;
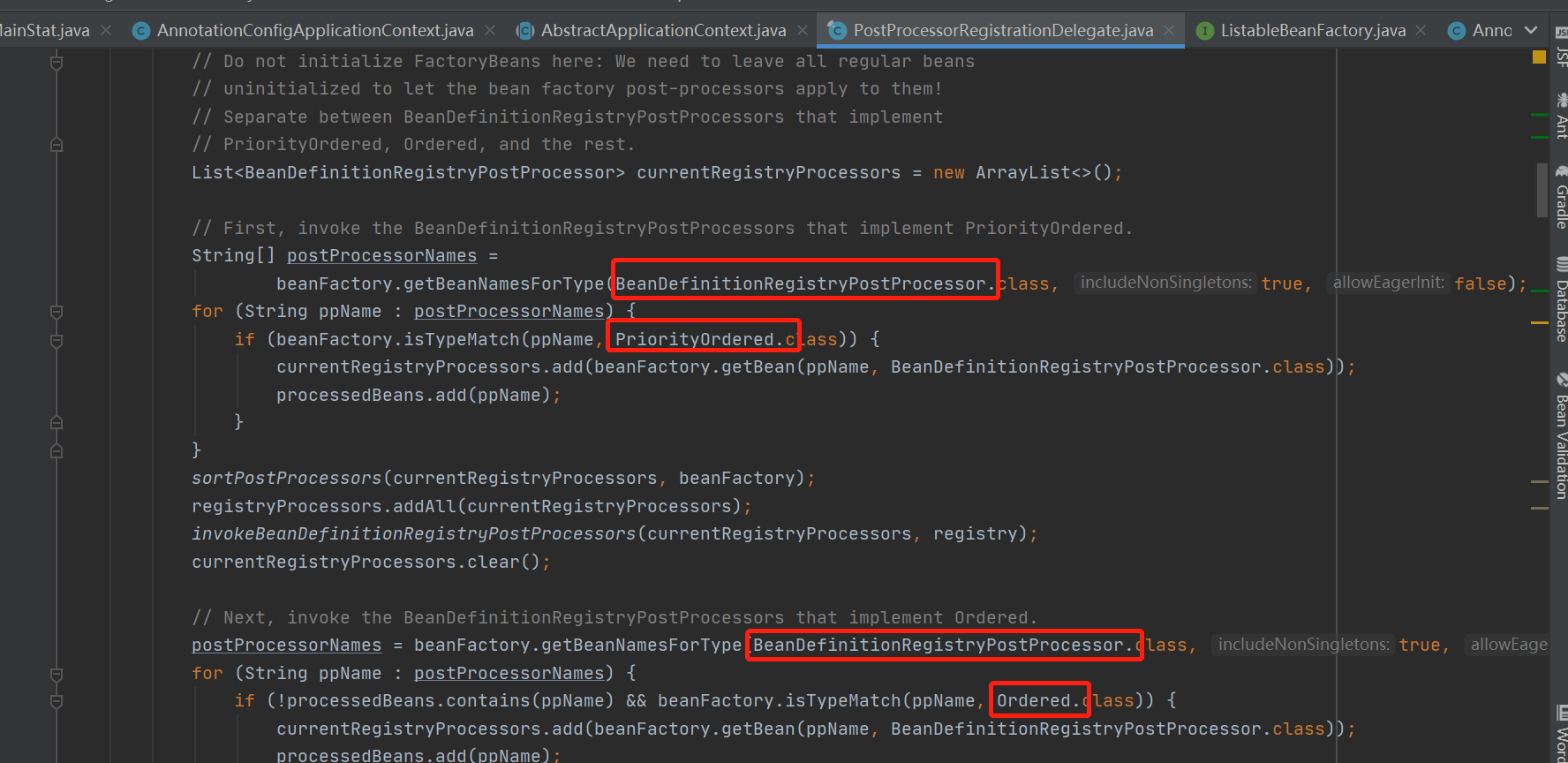

4.创世纪类configClasspostprocess实现了BeanDefinitionRegistryPostProcessor、PriorityOrdered,所以它会去执行这个方法
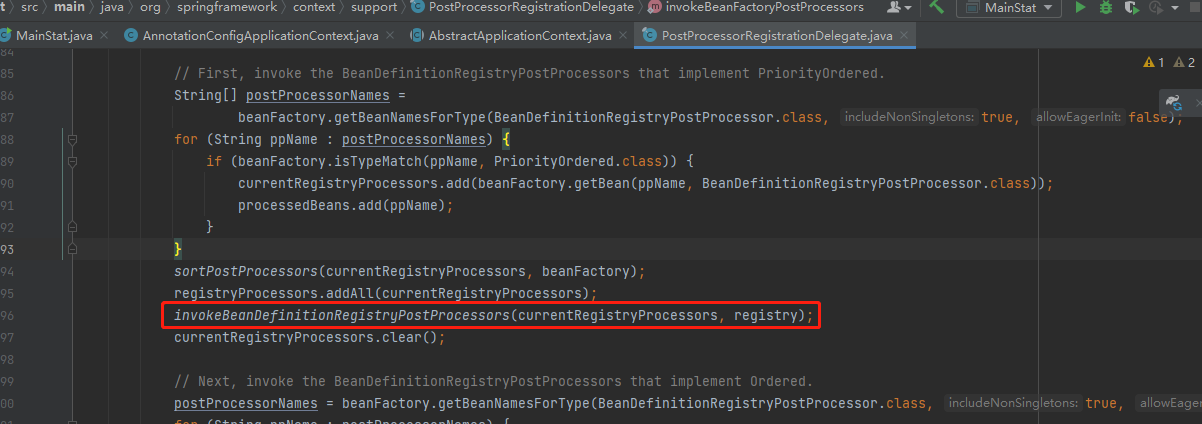
5.跳进这个方法中
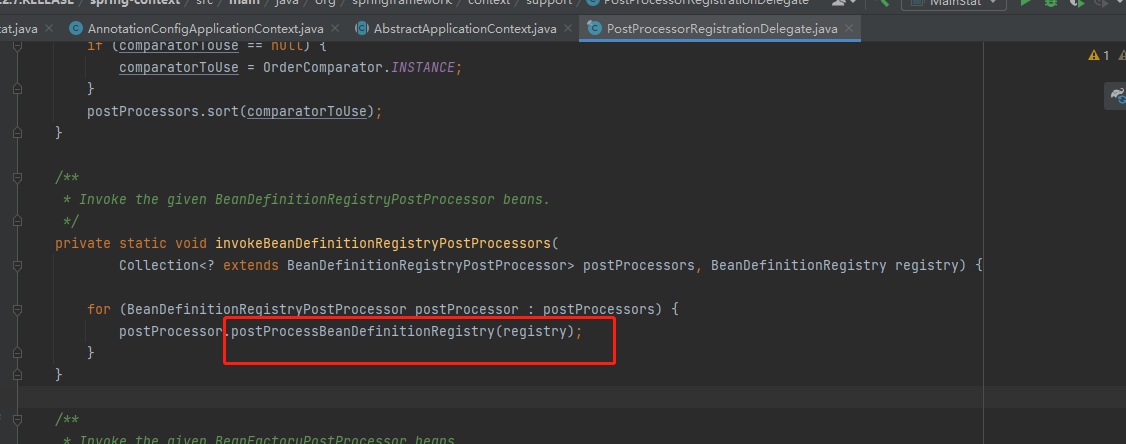
6.因为下面这个类是一个接口,所有必须有实现类来实现,看图
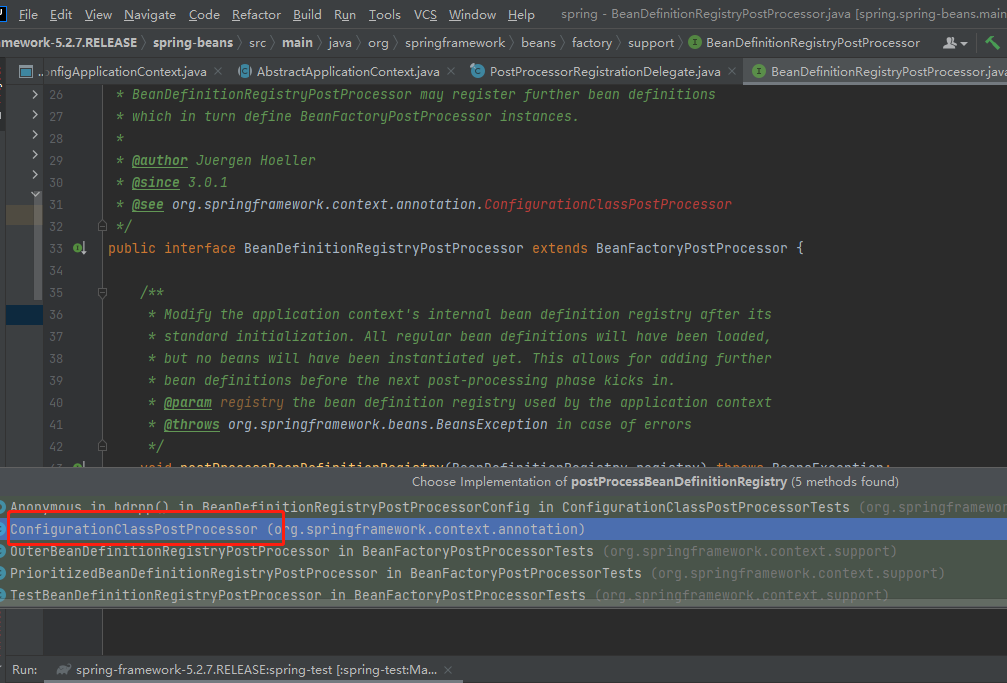
7.进入实现类中,接着执行图上标记的方法
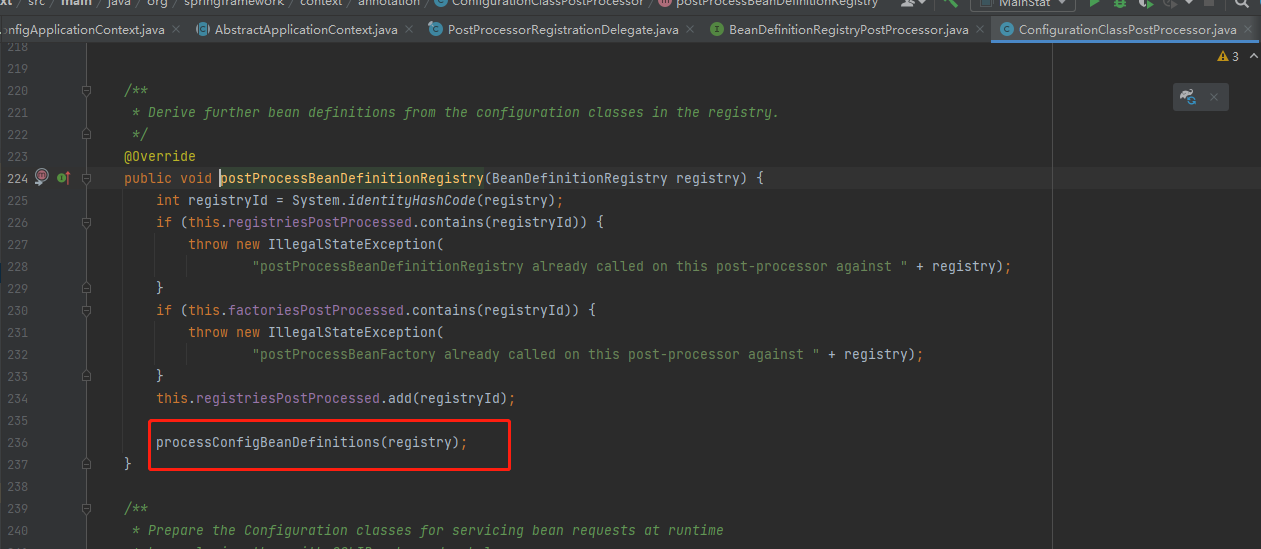
8.进入上面的方法后, 往下滑动,找到下面标记的类ConfigurationClassParser,并执行parser.parse(candidates),点击进入parse方法后,再次点击进入里面的parse方法,你就按着截图一直往下点击
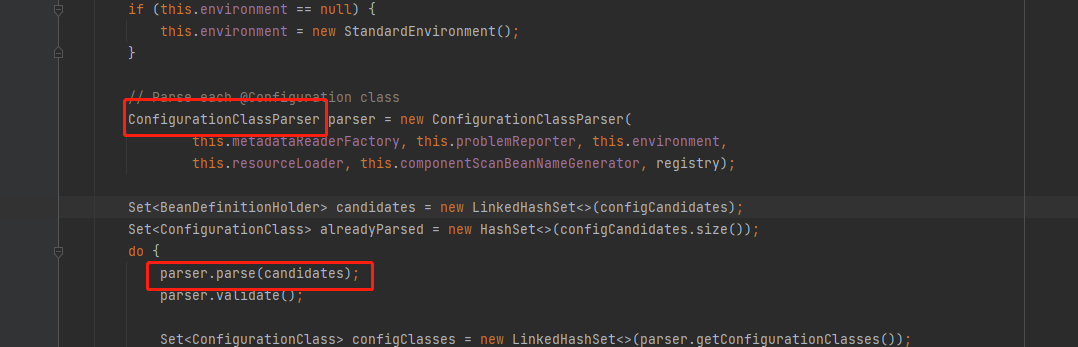
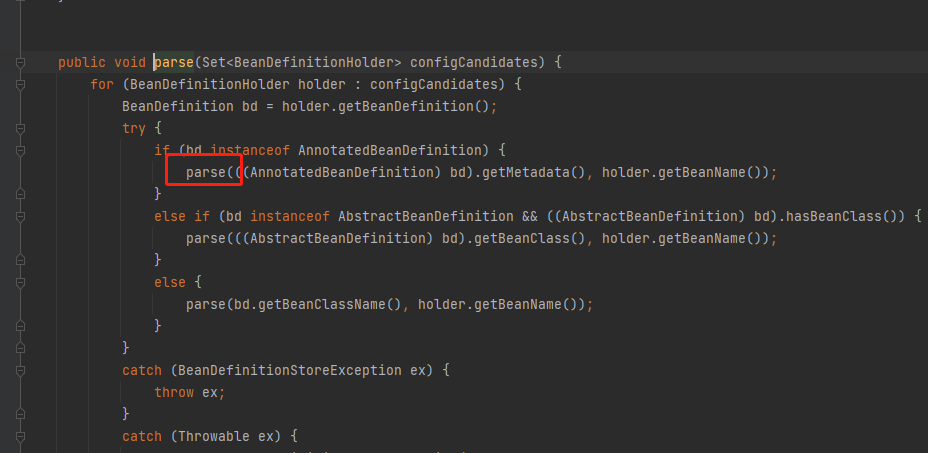

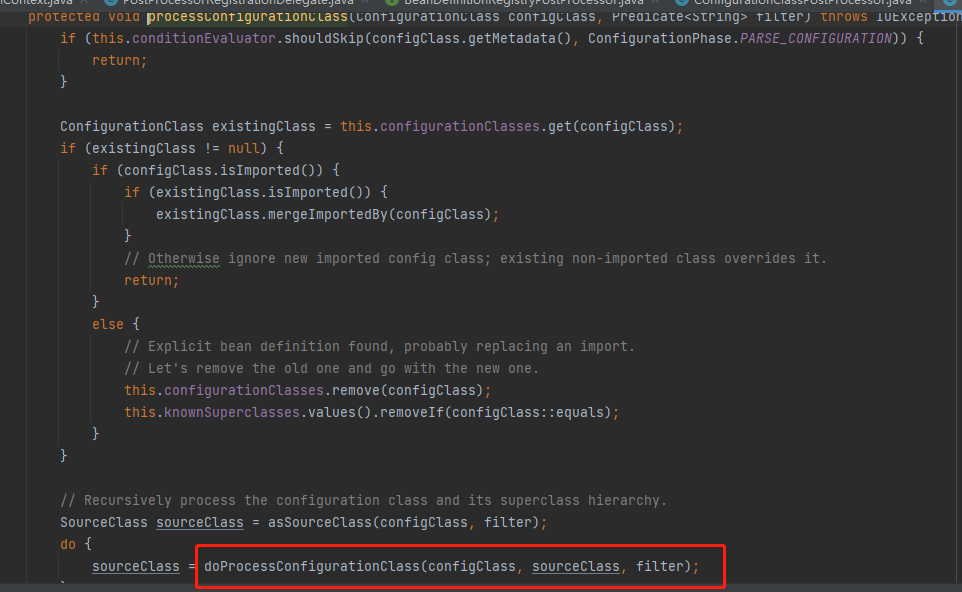
9.执行上面截图doProcessConfigurationClass()方法,这个方法里面就是,解析了@Component @PropertySources @ComponentScans @Import等等注解,以上这些就是整个配置类解析
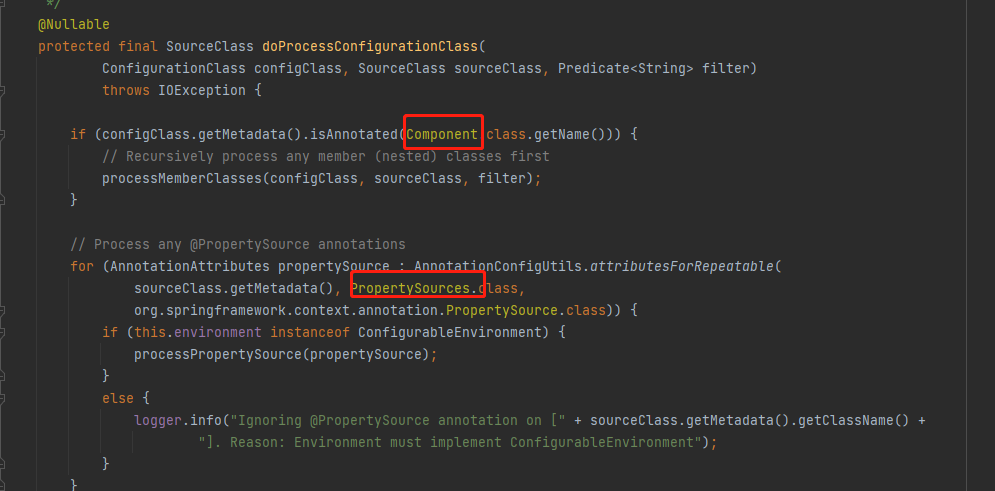
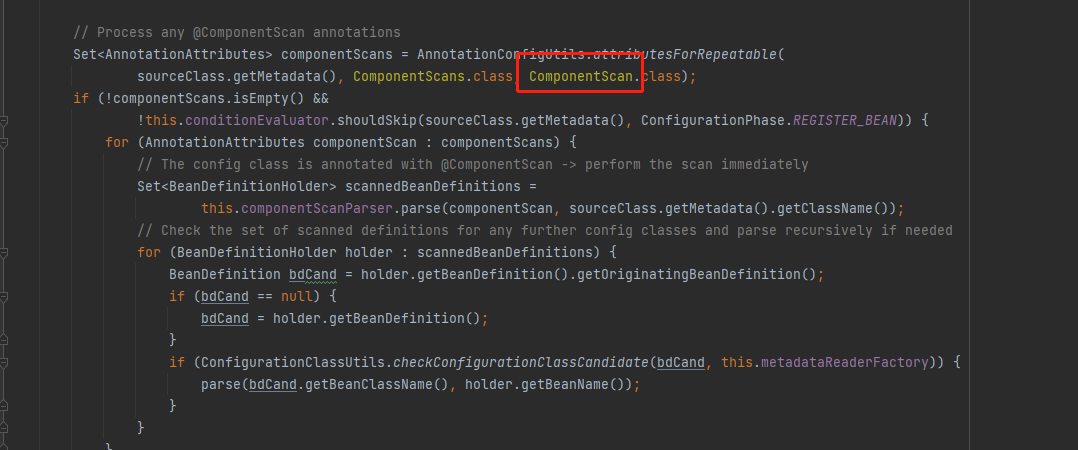
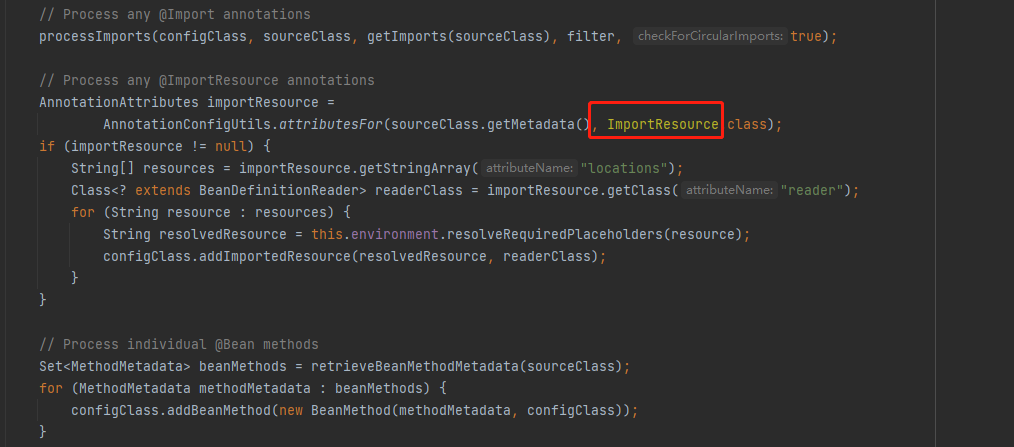
上面这个就是简单介绍了IOC后置处理器,主要解析流程
循环依赖问题解决?
首先咱们先说一下什么是循环依赖或者怎么样会导致循环依赖?
循环依赖就是 当我们在写代码的时候,我们创建了一个A类,同时在这个A类中,添加了B类的属性,并且通过@Autowired进行属性注入,这个是正常的,但是我们在B类中也同样添加了A类,通过@Autowired属性注入,或者(A依赖了B,B依赖了C,C又依赖了A,此处省略了写),那么这样就是我们所谓的循环依赖,而且我们市面说的循环依赖就是属性注入的时候发生循环依赖,而且spring也只是解决了属性注入的循环依赖, 如果是构造的时候循环依赖或者是多例下的依赖,spring是没有解决的,因为构造的时候依赖,顾名思义构造大家都清楚是创建对象实例,如何我们连实例的都没有,怎么解决依赖关系,所以如果是构造的时候依赖,那就直接报错抛异常,然后在说多例下的依赖循环,这个就更不用说了, 多例我们知道是不会放到缓存中的,每次请求或者会话都会创建一个新的bean出来,不会放到缓存,何来解决循环依赖呢,spring解决循环依赖就是用的三级缓存,所以多例下的循环依赖依旧解决不了直接报错;下面的图就是最典型最简单的一个循环依赖
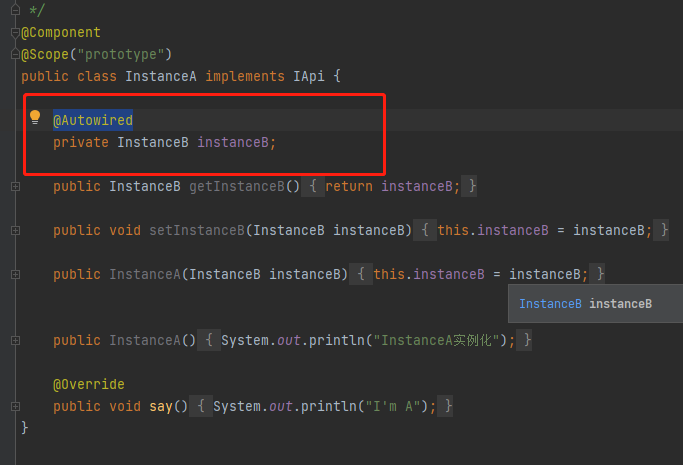
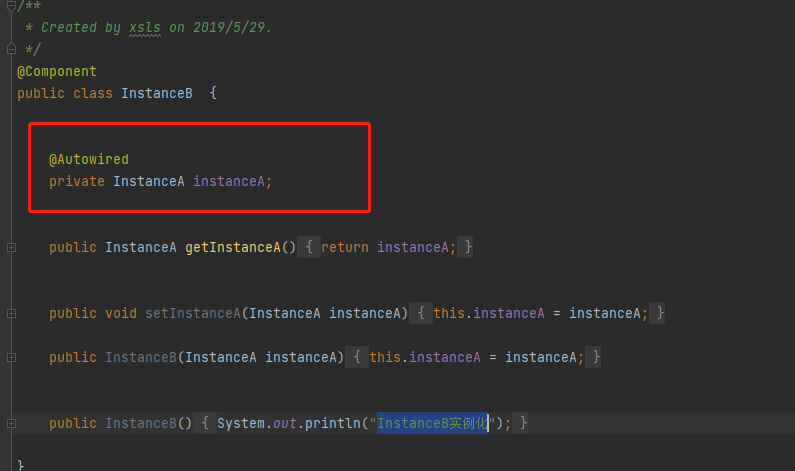
上面说清楚循环依赖是什么怎么产生了,那么下面我们来说spring是如何解决循环依赖的,首先spring解决循环依赖用了三级缓存,也就是三个map集合,再加一个正在创建的标识
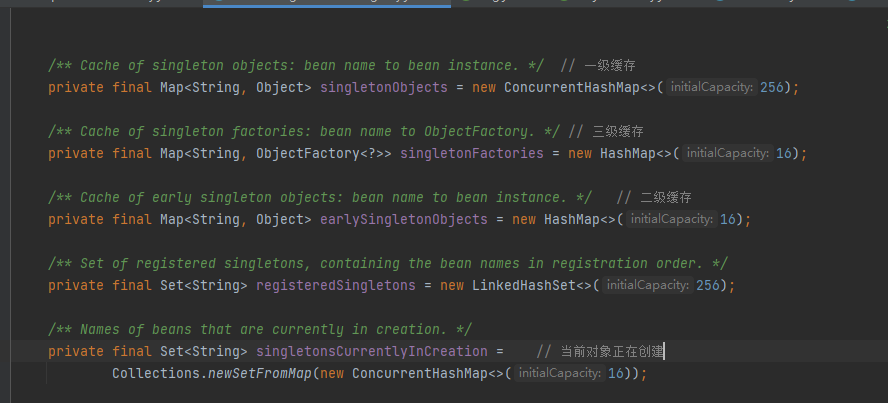
这里说一下,这几个缓存的意义,然后在通过一个demo来说明spring具体解决循环依赖的方法;
一级缓存singletonObjects : 存储完整的bean实例; 比如: A实例创建了,同时它里面的属性B对象也实例化了
二级缓存earlySingletonObjects: 存储不完整的bean实例,早期的bean, 比如,创建了A,但是A里面的B对象还没有实例化
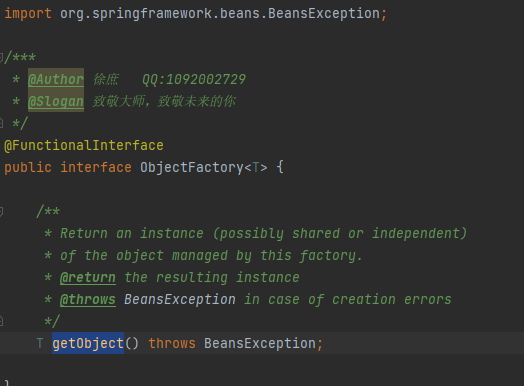
三级缓存 singletonFactories: 存储的是bean的名称对应的一个回调函数的勾子(创建当前Bean的实例),也是为了解耦用的;
正在创建singletonsCurrentLyInCreation:为了标识当前对象正在创建,在循环依赖的时候,防止频繁创建对象,同时也是通过正在创建标识来判断是否从二级缓存取或者到三级缓存中重新生成实例
介绍完上面这几个缓存的概念,下面通过一个demo来说明spring解决循环依赖的思路与步骤;
这里本人用文字来介绍,图没有画因为很抽象;好,下面大家来进入到我思路里,
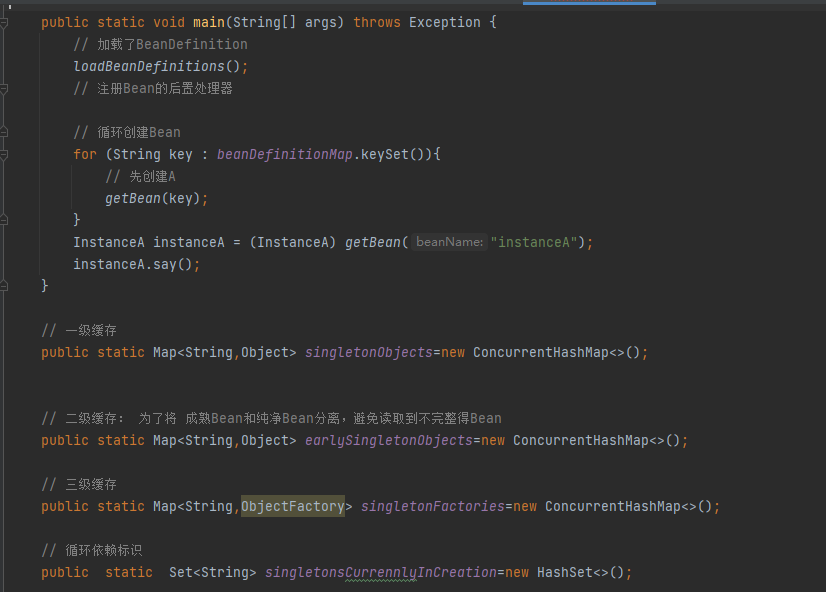
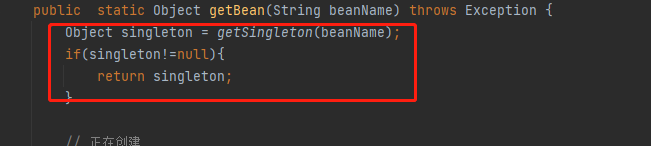
假设:遍历beanDefintionMap,获取到了A类,这时候调用getBean(A),会去调用getSingLeton(A)方法,如果返回值不为null,那么就直接return 当前实例,
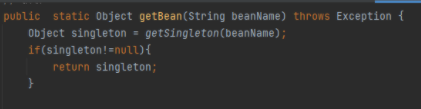
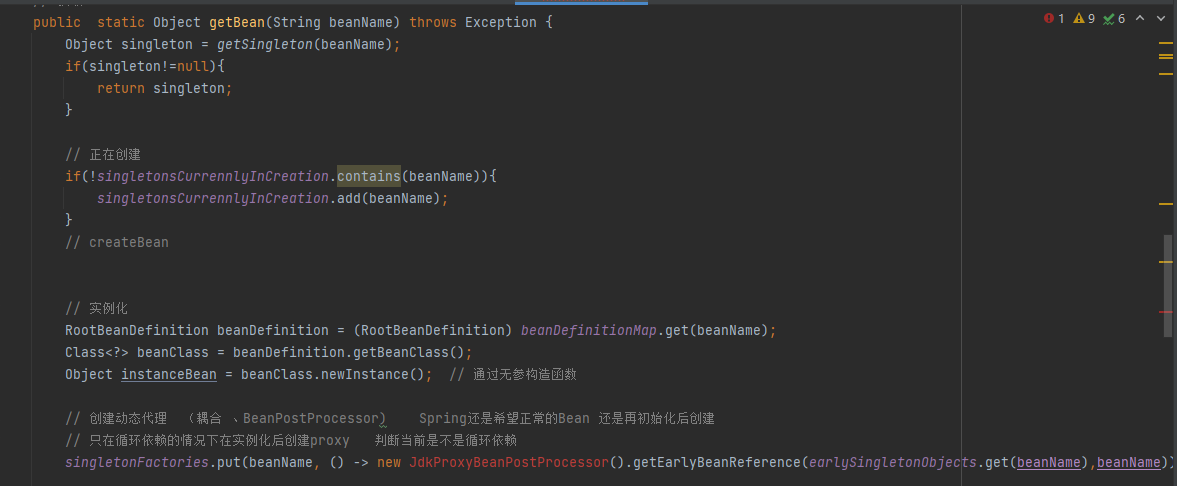
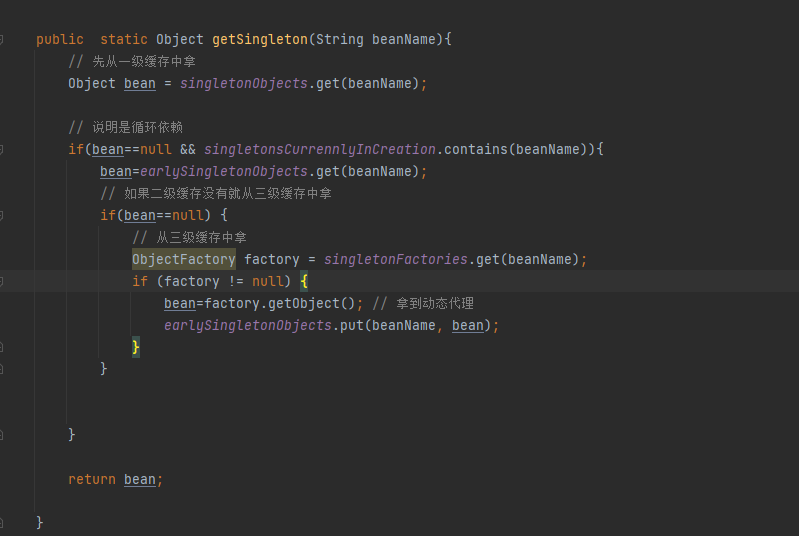
那么我们就来分析getSingLeton(A)方法做了什么,首先A类作为参数进入这个方法中,当前beanName就是A,然后调用sinletonObjects.get(A),从一级缓存中去获取A的实例,第一次进来A肯定获取不到,因为没有在任何环节把A存进去,这个大家应该清楚;所以代码执行下一步,如果bean为空并且标记正在创建那么执行if语句里的代码,但是A现在也没有正在创建,所以条件不满足,那么就直接return null 返回,自然上面的getSingLeton(A)方法也是返回null,所以就跳过if语句,执行下一步,大家跟好节奏和思路,千万别落队了,接着看下面文字
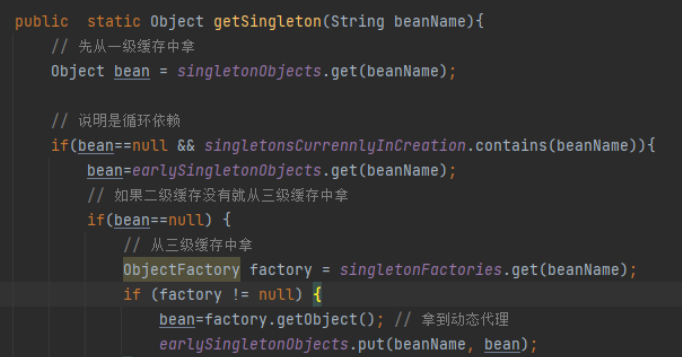
看这里,执行这一步,判断A有没有标记为正在创建,如果没有,就把A存入标记为正在创建,并且开始实例化,获取RooBeanDefintion然后获取实例,@1然后这里会在三级缓存里存入当前A的名称以及放进了勾子函数(函数就是创建A实例的,如果A是实现AOP那么这里就是动态代理方法,如果没有实现就是创建普通的实例,我们这里模拟的实现了AOP并且A实现了接口用的Jdk的动态代理生成实例),在三级缓存中放入一个函数,ObjectFactory接口,这个接口里只有一个方法getObject(), 我们开发的时候,可以通过这样方式进行解耦和回调, 可以学习一下这种调法,然后执行这个函数什么时候调用,我们会在下面介绍,大家仔细看哦


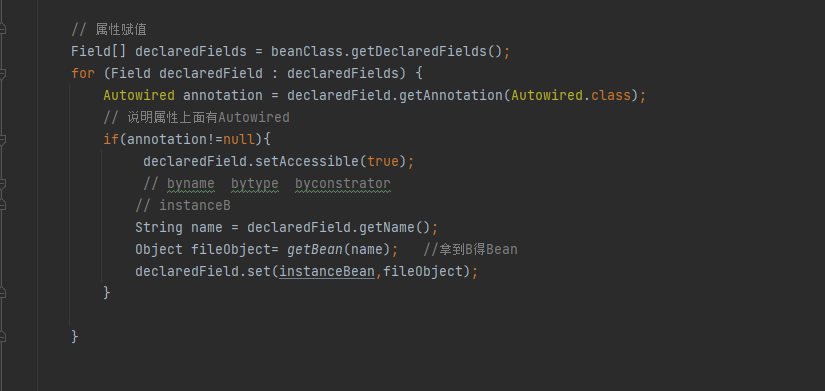
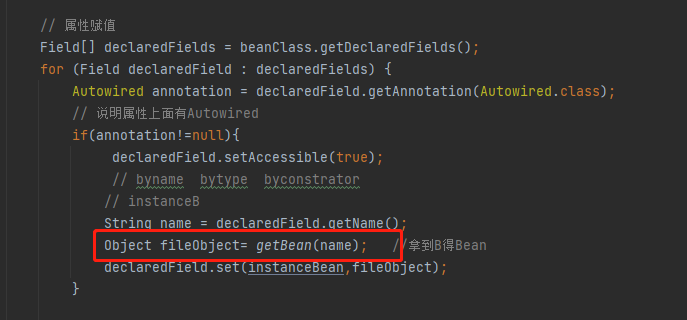
然后这一步是,获取A类里面的属性赋值,A类里面大家都知道有一个B ,并且通过Autowired注解进行注入,这时候就获取B,B也要实例化,所以再次调用getBean(B),这里用到了递归,这里特殊注明(本人因为之间用递归少,因为递归困扰了我半天的时间,整的我很长时间没有相同这里的逻辑,大家清楚最好,如果不清楚就可以学习一下,递归比较特殊,就在于必须有出口,否则就是死循环,并且递归是一层一层的循环,当满足出口条件后,不是直接退出,而是从满足出口这一层,一层一层的回退,回退到第一次递归的时候,比如:1->2->3->4,当4的时候满足条件,那么不是直接return,而是从4开始回退,4->3->2->1);
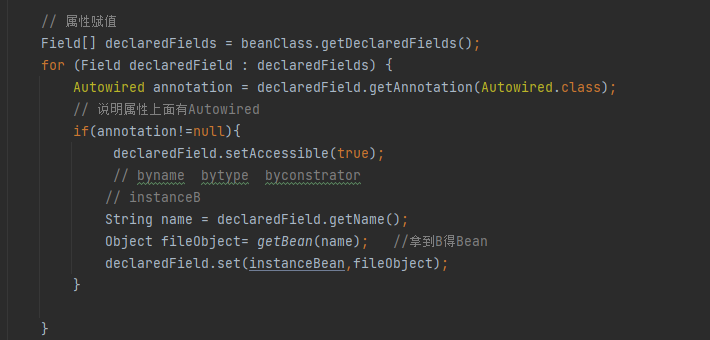
好了, 递归就说到这里,如果还是不懂大家可以学习一下,我们接着说循环依赖,这时候递归调用getBean(B),然后代码就又会回到最初一步去调用getSingleton(B),再次去去一级缓存里获取B的实例,这时候肯定获取不到,那么也不是正在创建,所以就直接返回null,这时候就又不会进入if语句里,接着执行下一步,判断当前B是不是正在创建中,如果不是,就把B放进正在创建中,@2 然后同时往三级缓存中存入B的名称以及对应的B函数(创建B的实例或者jdk动态代理(AOP)和上面的A是一样的看红色的部分)然后一样执行下面进行属性赋值,和A上面的一模一样的,我这里就不放图了,大家应该清楚,然后大家跟着思路来,这时候B来进行属性赋值,是不是把 B中的A属性就调出来拉,这时候又会去走第二次递归,调用getBean(A),同样再次去调用getSingLeton(A)方法,这时候大家要擦亮眼睛了,来。上图,再上一次这块代码;
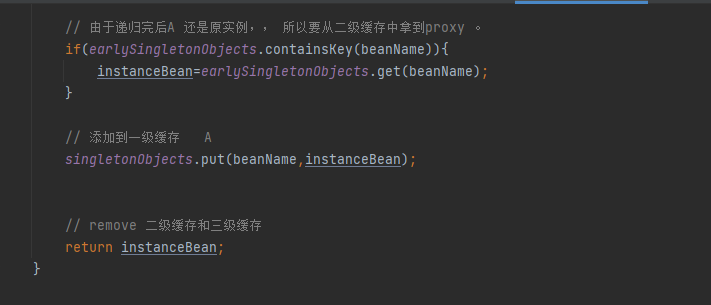
大家来看,这里beanName就是A, 同样还是去一级缓存里获取A的实例,还是没有,那么就执行if语句,上面我们说了,这里的判断条件是一级缓存为null,然后如果当前类为正在创建,就会进入if代码块, 那么A这时候就满足条件,因为它是正在创建,千万要跟进哦,如果跟不进,这里你就进不去了,回到正题,现在满足条件进入if代码块,然后执行去二级缓存中获取,这时候二级缓存获取不到,因为前面咱们没有任何地方往二级缓存中储存,获取到null,那么就会进入到if(bean==null)的代码块,然后这时候,就会进入下面的代码从三级缓存里拿, 然后上面说了,我们在实例化的时候,把A的名称以及创建A的勾子函数放进了三级缓存中,上面说了没有地方调用, 其实就是在这里调用,通过A的名称获取到对用的勾子函数,然后如果不为null,那么就会调用函数的getObject()方法,然后就会执行上面@1的部分去创建A的实例,这里我们模拟了A的实现了AOP,所以创建了A的动态代理,返回实例bean,并把A的实例存入到了二级缓存,这里代码没有写,spring是存到二级缓存后,就把三级缓存的A执行了remove删除了,大家千万别走心哦,大家想这里是不是获取到了A的实例,那么看下一步(看下面的文字)
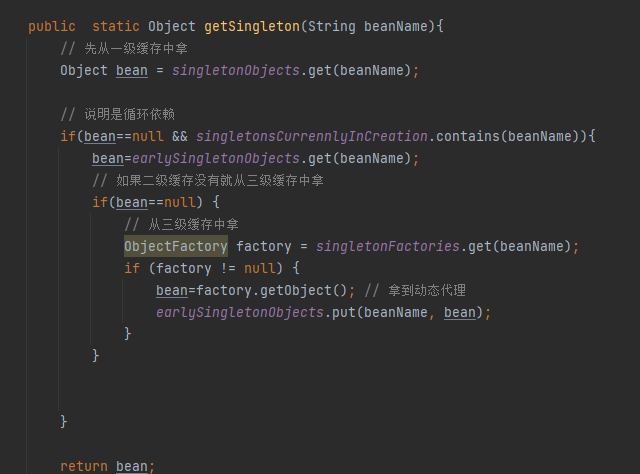
来,看这一步,这里是不是就把A的实例返回了,这时A不为null,那么就return了A的实例了,对吧,大家走了吗,来,来,来,千万别走心, 还记得我说了递归吗,就是这个玩意儿让我在这里的逻辑绕了半天,没有反应过来,琢磨的两年,研究了两天递归,终于让我整明白了,还记递归的特性吗,就是一但满足出口的条件,那么就会在当前的层级回退到它的上一次, 再看下面的文字
来, 瞅这里, 说递归前, 咱们先把流程走完, 红框这里getbean是不是返回了A的实例,然后把A的实例(这里动态代理)属性赋值给了B, 因为前面是B的实例查到了B里面又个属性A,然后执行A的递归方法,从三级缓存里获取到了A, 所以返回来这时候肯定将A放到B中,
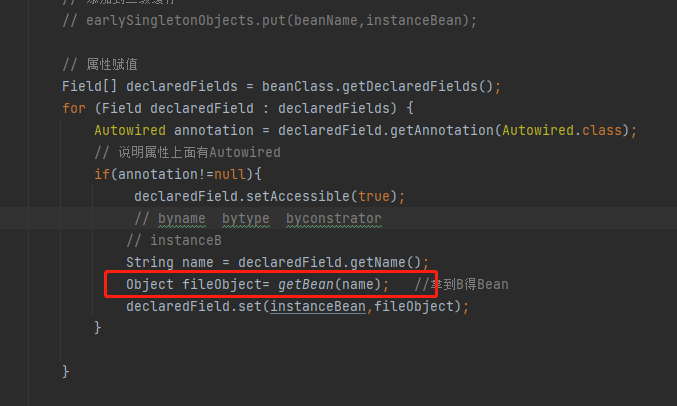
最后存入到一级缓存中, 这里应该大家明白了吧,

这时候,千万别放松, 来我们刚才说了, 递归, 这时候放进一级缓存后,然后retrurn B的实例,最后递归回退到上一次, 那么getBean(这里是不是B),应该刚才是A啊,回退这里肯定是B啊对吧, 那么这里是B,说明前面的肯定通过A获取到A的里面有个带Autowired的B, 所以这里就getBean(B),然后就又回到getSingLeton(B)方法中去做判断,这时候是不是这里从一级缓存里能拿到B, 咱们刚才刚刚放进去, 所以这里就可以拿到B了, 然后执行拿到后, 再次把B放到了A中,这时候不是A里的B 也又了, 最终循环依赖解决了,这样就结束了, 不知道大家看明白了吗, 可以仔细看几遍;
大家记住几点, getBean(),getSingLeton(),以及几个缓存都干了什么, 就是一级缓存拿不到,就去二级缓存拿,二级缓存拿不到,去三级缓存中拿,就是怎么简单!
spring解决读取不完整的bean? 这个我就不多说了,其实就是加了双重检验锁;
就是再getSingLeton()方法中, 再if代码块里 判断一级缓存为null && 正在创建,加了synchronized (singletonObjects), 再创建bean的时候也加了一把synchronized (singletonObjects)锁, 并且再创建完对象,往一级缓存中存入的时候,做了一个判断if(earlySingletonObjects.containsKey(beanName)){instanceBean=earlySingletonObjects.get(beanName);} 如果二级缓存中有,就取二级缓存中,因为咱们再getSingLeton()方法中创建完实例,会把实例放进二级缓存中,这样的话,当二级缓存中存的如果是代理对象的话, 那么再创建bean的时候就可以在二级缓存中取出代理bean对象,最终放进一级缓存;
