

《mysql之索引》
一、索引介绍
在程序员的世界里,我想大家应该都会遇到过慢查询,或者你在面试的时候,大家都会被问过如果解决慢查询,我相信伙伴们肯定都说创建索引,因为我之前也是这样回答的,然后面试官问,索引是什么?如何建索引最优,为什么创建了索引速度就快了?因为。。。。。。呃。。。。。,最后来一句,索引能快速定位到,就没有后续了,或者大部分面试官还会问,如何优化sql?然后按着百度上说的 like 最好用右%,不要用is null is not null, 还有什么in or ,查询最好不要用 * 号,用字段等等,如果大家都是这样回答的,那么今天咱们就来彻底把索引整明白,上面说的怎么多确实可以优化sql,但是有没有想过,为什么这样写就OK呢?在讲索引之前,我想让大家一定记住一句话: 索引就是排好序的数据结构! 切记!切记!切记!
今天我们来拿MySQL 5.7版本介绍, 而且在这里我们只讲mysql默认的存储引擎 InnoDB, 因为现在互联网大部分也都是使用InnoDB(记住数据库的存储引擎指的表而不是数据库),InnoDB存储引擎当你创建索引的时候,mysql 会在底层帮你创建好了一个索引文件,在这个文件中是用B+Tree的方式来存储索引的
B+Tree结构:
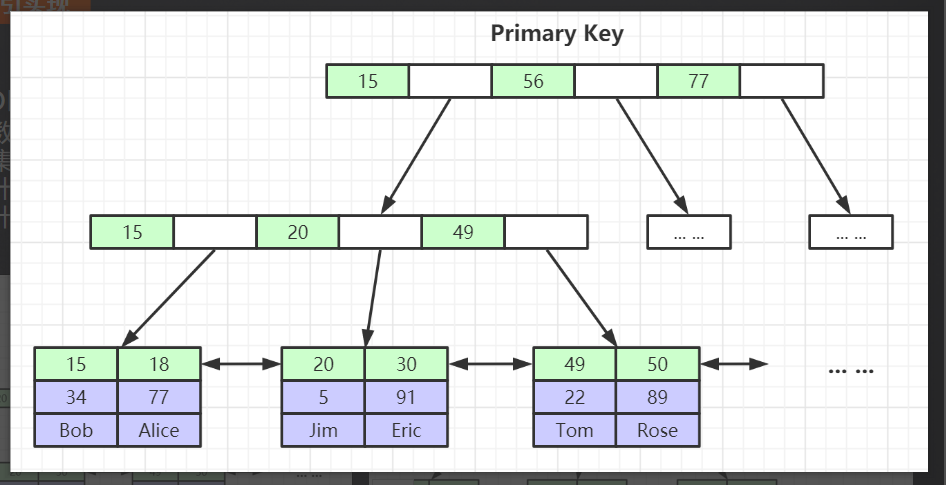
这张图是聚簇索引,意思就是通过唯一主键id,绿色部分都是整个表的主键,从上到下,第一层和第二层都是第三层的冗余的id,每一层也叫节点,每个节点从左到右依次都是排好序,然后第二个节点上数据都是第一个节点中间部门,比方第二节点上的20会在第一个节点的15-56之间,我相信大家应该这时明白,B+Tree结构的特点了吧,前两层节点先简单介绍到这里,我们往下看第三层叶子节点,从左到右依次排好序,并且这里的主键包含了前两层所有的主键也就是所有的索引,蓝色部分是主键对应的表中每行数据,这里在告诉大家一个知识点,mysql设计的根节点大概能存放1170个索引,第二层上的每个节点也能存放1170, 第三层,一行数据java中一个对象按最大的来说1KB,总共能存放16kB, 那么整个B+Tree能存放1170*1170*16,大家可以算一个,大概是2千万,意思就是说,B+Tree只用三层就可以构建千万级数据量,这是多么牛逼的一件事儿,你这时候就可以想想了, 我们查询一张千万级数据表,假设我们查询id为20000000,我们用主键索引,我们最多只需要走3步就可以查询到你要的数据,如果不用索引,你需要从上到下依次进行磁盘扫表20000000次才能找到你要的数据, 大家应该清楚 3<20000000,并且大家看图,会发现在叶子节点,每个节点中间都用了指针的方式指向对方,并且是双向指针,大家先记住这个知识点,一会儿会用到;
在这里我在补充一点,我记得曾经有个面试题; 为什么最好创建自增的整数id? 看完这张图和介绍大家应该想到了吧,自增是为了方便索引从左到右排序,整数比较大小很方便,而且能更好的排序,同时节省空间,你想如果你的索引的大小特别小的话,那整个B+Tree是不是就可以存放更多的数据,甚至比20000000还要大,现在好多公司用的还是uuid, 你想想一个uuid特别长,索引查询的时候,比较大小是很麻烦的,并且(985632478950XERGH17a)和(1 ) 这两个数字哪个占用空间小,并且好比较,不用我多说了吧;
下面我们来看二级索引,其实和聚簇索引一样的数据结构,这个我就不多说了,我只是讲一下特别之处,大家先看图:
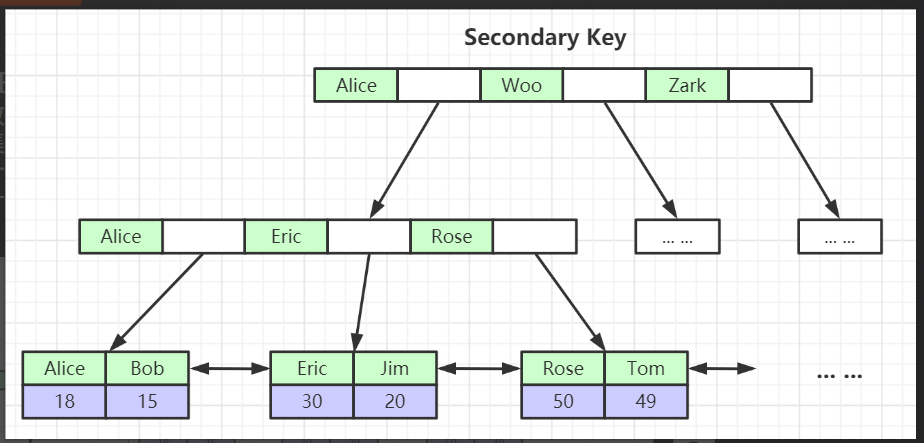
这样的二级索引,其实也是B+Tree数据结构,并且也是排好序的,他们是通过第一个字母开始比较,如果相等就是比较第二个字母,并且大家看叶子节点,这里存的不是每行数据,大家应该能想到吧,这里存的是主键id,这就是mysql设计的,不要问我为什么,哈哈, 所以二级索引占用空间一般会很小,但是他有个特点就是,有可能需要回表,就是你查询的结果集如果在二级索引中包含不到,就会根据id 回到聚簇索引中再次查询,这样肯定是低效率,但是比起不用索引查询快无数倍,所以你在百度上查询的时候不要用* 号,最好用字段,其实就在这里,最好覆盖索引;
来看例子: 假设这个表叫 a表, select * from a where a.name=Alice 和 select id, name from a where a.name=Alice,你看第一条sql语句,我们通过Alice索引能快速定位到树的位置,但是查询的结果集是*号,意思是所有的字段,但是在二级索引中其他的字段是不存在,所以需要回表,然后到聚簇索引中,通过id拿到数据,我们刚才讲了,聚簇索引的叶子节点存放的整行数据, 那我们来看第二条sql语句, 结果集是id和name, 这两个字段在二级索引树中已包含,那就不用回表了,直接在索引树中拿出来就可以了呀,快不快,大家应该一目了然;
联合索引,我想大家在公司应该经常创建联合索引吧,公司一般也会让你尽量创建联合索引,因为如何你能用一个联合索引就能把整张表90%的业务逻辑包括了是最好的,因为一张表维护索引也是需要消耗性能的,如果你一个字段创建一个索引,mysql底层维护一个数据结构表,那mysql维护起来太麻烦了,mysql就是帮我存储数据的,避免过多的去消耗没必要的mysql性能,人为控制就行;
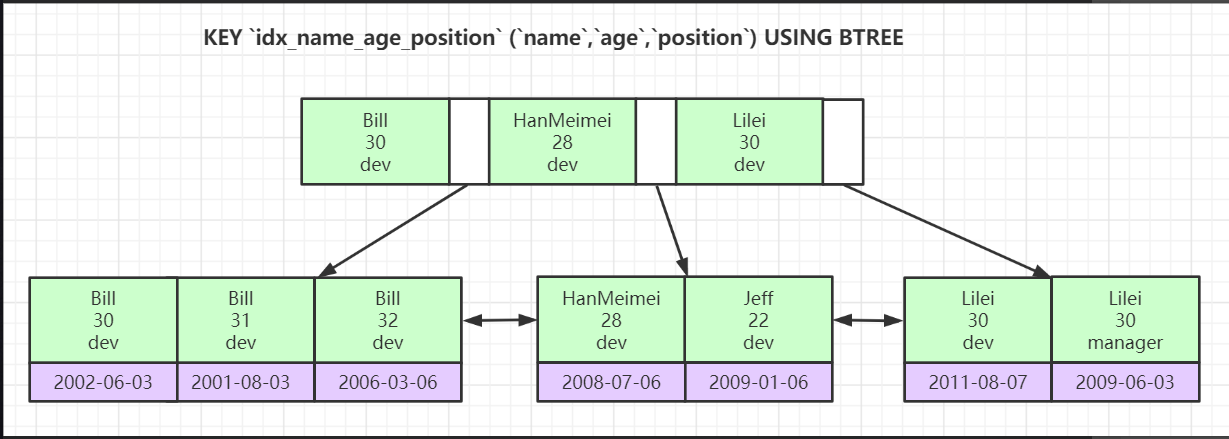
联合索引其实一样,都是B+Tree数据结构,遵循最左前缀原则,在这张图中我们建的联合索引是 (name、age、position),底层首先先比较name字段进行排序,如果name字段就可以排好序了,那就不在比较第二个和第三个字段了,如果name字段都相等,那么就通过age进行比较大小排序,依次类推,age相等,比较position,如果都相等就放在一起,联合索引就是这样的特点;
大家一定要记住, mysql数据库InnoDB存储引擎 索引都是B+Tree 并且是排好序的数据结构,从左到右依次递增,并且聚簇索引叶子节点是包含整行数据,二级索引叶子节点包含的id,联合索引遵循最左前缀原则,并且不管是什么索引,叶子节点都有双向指针,脑子里一定切记这些规则,我们下面就开始索引实战,通过实战可以更加巩固索引;
实战前大家需要先学习mysql提供给我们如何查询慢查询的工具 explain,我们知道通过explain工具, 我们可以得到结果集如下:

id: 这里是整数值,代表着sql语句的执行顺序,值越大优先执行,如果相同,从上到下顺序执行;
select_type: 代表查询语句的类型(简单复杂查询),并且也可以根据当前值来判断,查询的是 from前后的临时表;
slmple :这个不多说就是简单的查询,查询语句中不包含子查询;
primary:复杂查询;一般指的最外层的select;
subquery: 一般指的查询from前面的临时表;
derived: 一般指的是查询from后面的临时表(子查询);
table: 这个就不解释了,就是查询的的那张表,当然这里有可能 derivedx, 这个x指的 select_type是derived的id值,查询的derived的临时表;
type: 这个就很重要了,这个字段的值就代表的你的某条查询sql语句的快慢程度;
值的快慢比较: system>const>eq_ref>ref>rang>index>all 我们后面根据实战来逐个攻破;
possible_keys: mysql通过优化判断sql有可能走索引,但不代表实际走了索引;
key: sql实际走的索引;
key_len: 可以通过数字来判断走了那些索引;
ref: 这一列显示了在key列记录的索引中,表查找值所用到的列或常量;
rows: 查询sql语句总共在表中扫描了多少行;
extra:这一列展示的是额外信息;(只是列举了几个常见的,这里的值很多,有兴趣的伙伴们可以自己去查)
Using index:使用覆盖索引;
Using where:使用 where 语句来处理结果,并且查询的列未被索引覆盖;
Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围;
Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索
Using filesort:将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。这种情况下一
Select tables optimized away:使用某些聚合函数(比如 max、min)来访问存在索引的某个字段;
=====================================================================================================================
介绍完explain工具,那我们接下来就开实战;
=====================================================================================================================
首先我们先创建employees表, 并且创建联合索引KEY `idx_name_age_position` ( `name`, `age`, `position` ) USING BTREE
CREATE TABLE `employees` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT,
`name` VARCHAR ( 24 ) NOT NULL DEFAULT '' COMMENT '姓名',
`age` INT ( 11 ) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` VARCHAR ( 20 ) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY ( `id` ),
KEY `idx_name_age_position` ( `name`, `age`, `position` ) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 4 DEFAULT CHARSET = utf8 COMMENT = '员工记录表';
INSERT INTO employees ( NAME, age, position, hire_time )
VALUES
(
'LiLei',
22,
'manager',
NOW());
INSERT INTO employees ( NAME, age, position, hire_time )
VALUES
(
'HanMeimei',
23,
'dev',
NOW());
INSERT INTO employees ( NAME, age, position, hire_time )
VALUES
(
'Lucy',
23,
'dev',
NOW());
=======================================================================================================================
1、EXPLAIN SELECT * FROM employees WHERE name= 'LiLei';

通过explain可以看到上面这个sql 首先是slmple简单查询,并且type的值ref,用到了索引name(最左前缀原则),其实ref类型的sql几乎可以不用在优化了;
这里解释一下 key_len 这里的数字 如果是VARCHAR 类型,就是(3n+2) 因为name字段创建表的时候设置24,所以按照公式74
=======================================================================================================================
2、 EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22;

看红色标记和第一个一样,不多解释,key这里也是用到联合索引, 用到了name和age两个索引;int 是4个字节,所以用到了两个索引78
=======================================================================================================================
3、EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22 AND position ='manager';

这里根据最左前缀原则 联合索引三个字段全部用上了,并且ref,速度可以,其实以上三个的sql语句还可以优化的,就i是用覆盖索引,查询出来结果集把索引覆盖,直接走二级索引就可以了,不要让他拿到id在回表;
=======================================================================================================================
5、
不用在索引上添加各种函数,上面这个sql语句name,在B+Tree上是通过name整个值的来比较排序的,但是你只用左边三个字母,不一定有顺序的,所以mysql在底层优化器上有一个const成本,这个后面讲,他比较了一下,发现走索引的const成本比全表扫描成本还要高,不如直接就全表了;
=======================================================================================================================
7、我们给hire_time字段加一个普通所索引,ALTER TABLE `employees` ADD INDEX `idx_hire_time` (`hire_time`) USING BTREE ;

这条语句,我们看key_len只走了前两个索引,大家肯定有疑问?这不是遵循了最左原则吗,对,没错是遵循规则了,但是我们说了mysql有自己的优化器,它分析age>22,是个范围,这个结果集有可能很庞大啊,所以不如拿出Lilei和>22结果集,去全表里进行扫描兴许比在索引去找manager速度更快;
=======================================================================================================================
9、EXPLAIN SELECT name,age FROM employees WHERE name= 'LiLei' AND age = 23 AND position ='manager';
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 23 AND position ='manager';
这两个sql语句,大家自己去尝试啊,如果你真的从上面看到这里的,应该清楚我说过,尽量使用覆盖索引,让它在联合索引中就能找到全部结果集最好,不用在让它回表在去通过id查询,回表是消耗性能的,浪费时间的;
=======================================================================================================================
10、

mysql在使用不等于(!=或者<>),not in ,not exists 的时候无法使用索引会导致全表扫描< 小于、 > 大于、 <=、>= 这些,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引;
=======================================================================================================================
11、

EXPLAIN SELECT * FROM employees WHERE name like 'Lei%'

尽可能去用左模糊,不用用右模糊, 大家可以想想B+Tree数据结构,%Lilei,在数据结构是无序的,相当于就是xxxLilei, 我们说过树结构是通过字母最开头开始比较的,你把xxx模糊了,去比较Lilei怎么可能是有序的;反之下面在这个sql 右模糊 开始就比较Lilei,这个有可能是有序的,并且mysql一般把Lilei%这种优化成=Lilei;

EXPLAIN SELECT * FROM employees WHERE name = 1000;

字符串不加单引号索引失效
=======================================================================================================================
13、EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' or name = 'HanMeimei';

少用or或in,用它查询时,mysql不一定使用索引,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引,详见范围查询优化;
=======================================================================================================================
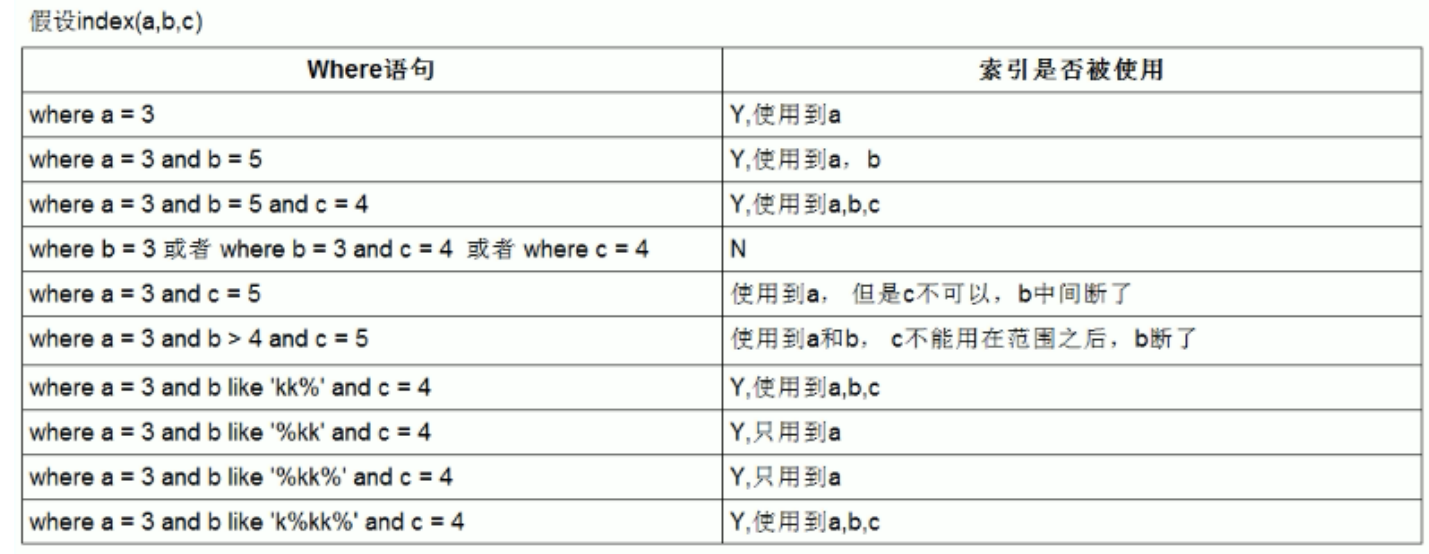
14、范围查询优化 ,给年龄添加单值索引;

 =======================================================================================================================
=======================================================================================================================
一条sql语句在数据库中到底如何执行的;
mysql内部组件,分为 server层(连接器、缓存、分析器、优化器以及执行器),store层(各种存储引擎,InnoDB、myisam、memory)

连接器:[root@192 ~]# mysql -h host[数据库地址] -u root[用户] -p root[密码] -P 3306
 客户端如果长时间不发送command到Server端,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。
客户端如果长时间不发送command到Server端,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。======================================================================================================
缓存:
======================================================================================================
优化器:这个就不多说了,就是优化你sql语句,如果有索引走索引,如果没有,mysql根据const成本来比较,尽可能优化到最优;
======================================================================================================
执行器:
- 调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 1,如果不是则跳过,如果是则将这行存在结果集中;
- 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
- 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
查看binlog内容:
脏写:最后的事务覆盖了其他事务的更新操作 比如:前提是两个事务都还在begin状态,还未commit,A事务 select到了10,同时B事务也select到了10,这时候 A事务-5更新到了5,这时候B事务-1更新到了9,然后update, 这时候数据库数据变成了9,但是对于A事务应该是5,并且正常来说B事务读取到数据-1,应该数据库是4,但是现在数据库是9,这就要脏写;
脏读:A事务读到了B事务更新但未提交的数据; 比如:B事务select到10,然后-5,这时A事务进来select数据读到了5,但是B事务突然出bug了,事务rollback,回滚了,那么A事务应该读的是10,但是却是5,这就脏读;
不可重复读:A事务在自己的事务里不断读取到了B事务操作的数据(不符合隔离性);比如:表里一个字段是boolean类型,那么B事务操作这个字段,改成了true,这时候A事务select到了true,然后B事务又把值改成了false, 那么A事务这时select又读了false,那么我们写代码也就太复杂了,这需要判断多少次才能满足逻辑;
幻读:A事务读到了B事务新增的数据(不符合隔离性);不多解释了,就是B事务增加一条数据,A事务读到了;
前面讲的例子 A事务和B事务都是还在自己的事务里,还没有提交事务,还没有结束;
那么有了这些并发问题,我们自然而然就要解决,要解决就比较遵循事务的四大特性:
原子性: 就是事务的整个操作要不全部成功,要不全部失败;
一致性: 就在操作的过程中,数据必须保持一致,不能一会儿读到true,一会儿读到false;
隔离性:就是事务A和事务B,自己在自己的事务里操作自己的数据,不能互相干扰;
持久性: 数据存入数据库中,必须持久保存;
在写解决并发前,先讲一下表锁和行锁,这个不多写了,看图看实例;
--建表SQL
CREATE TABLE `mylock` (
`id` INT (11) NOT NULL AUTO_INCREMENT,
`NAME` VARCHAR (20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = MyISAM DEFAULT CHARSET = utf8;
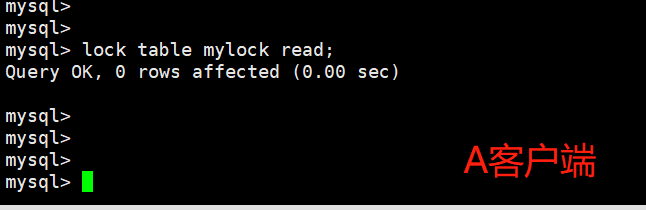
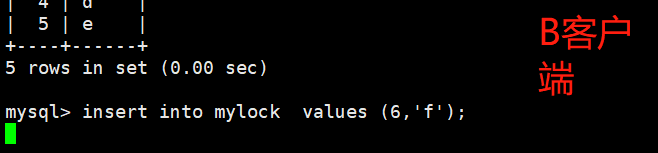
1、对MyISAM表的读操作(加读锁) ,不会阻寒其他进程对同一表的读请求,但会阻赛对同一表的写请求。只有当读锁释放后,才会执行其它进程的写操作。
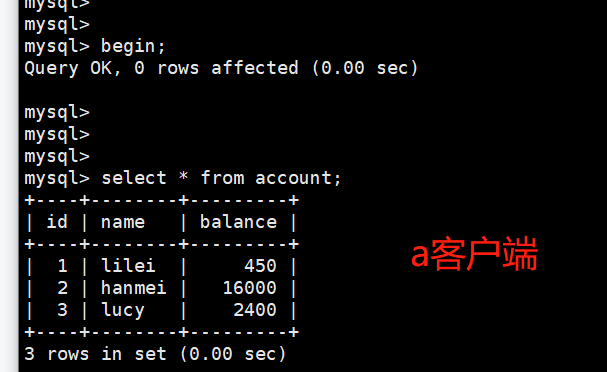

一旦客户端B的事务因为某种原因回滚,所有的操作都将会被撤销,那客户端A查询到的数据其实就是脏数据:
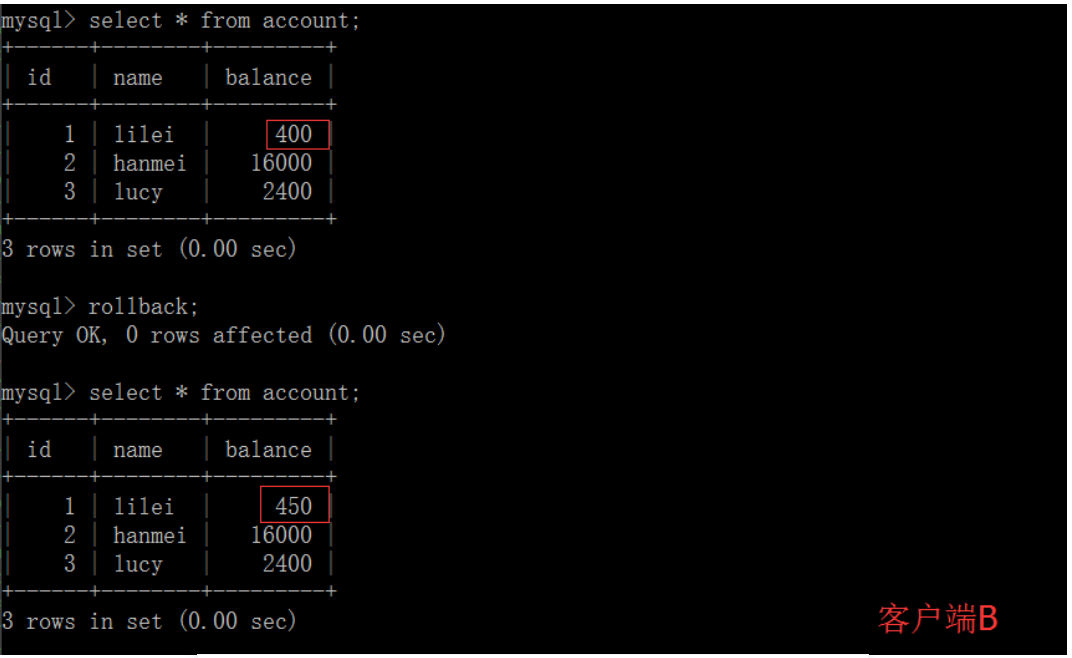
在客户端A执行更新语句update account set balance = balance - 50 where id =1,lilei的balance没有变成350,居然是400,是不是很奇怪,数据不一致啊,如果你这么想就太天真 了,在应用程序中,我们会用400-50=350,并不知道其他会话回滚了,要想解决这个问题可以采用读已提交的隔离级别
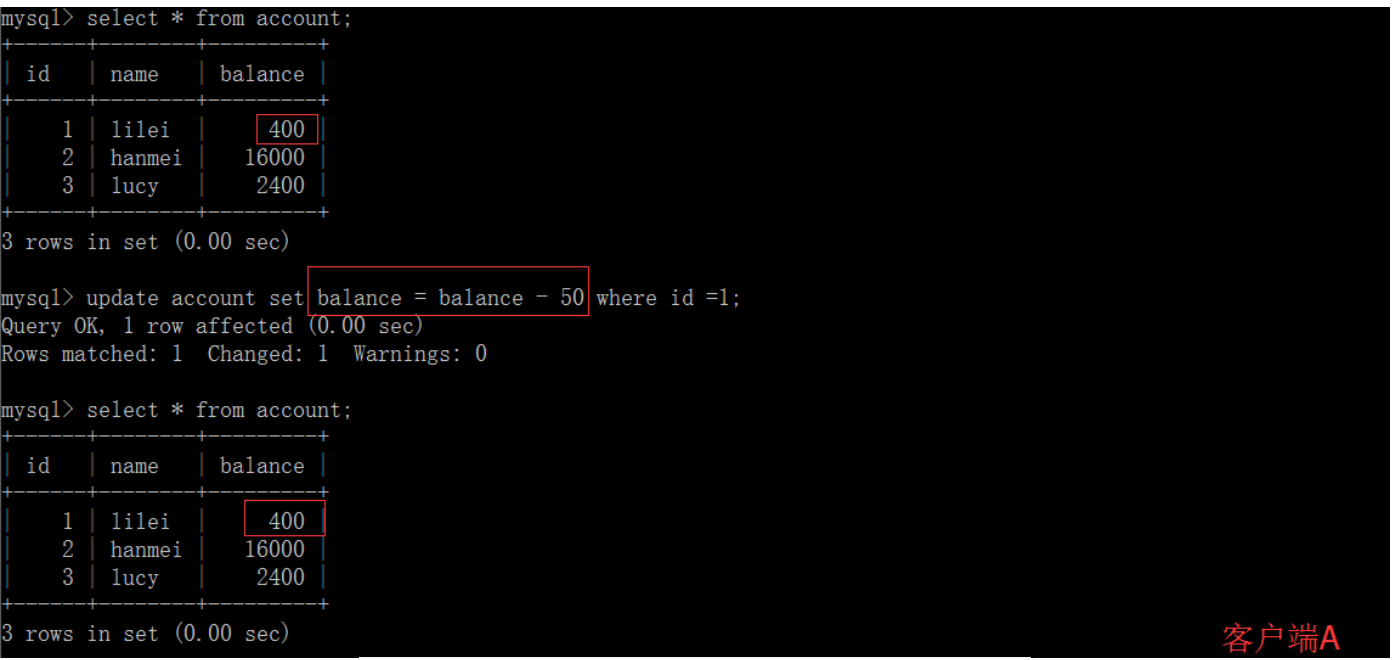
读已提交
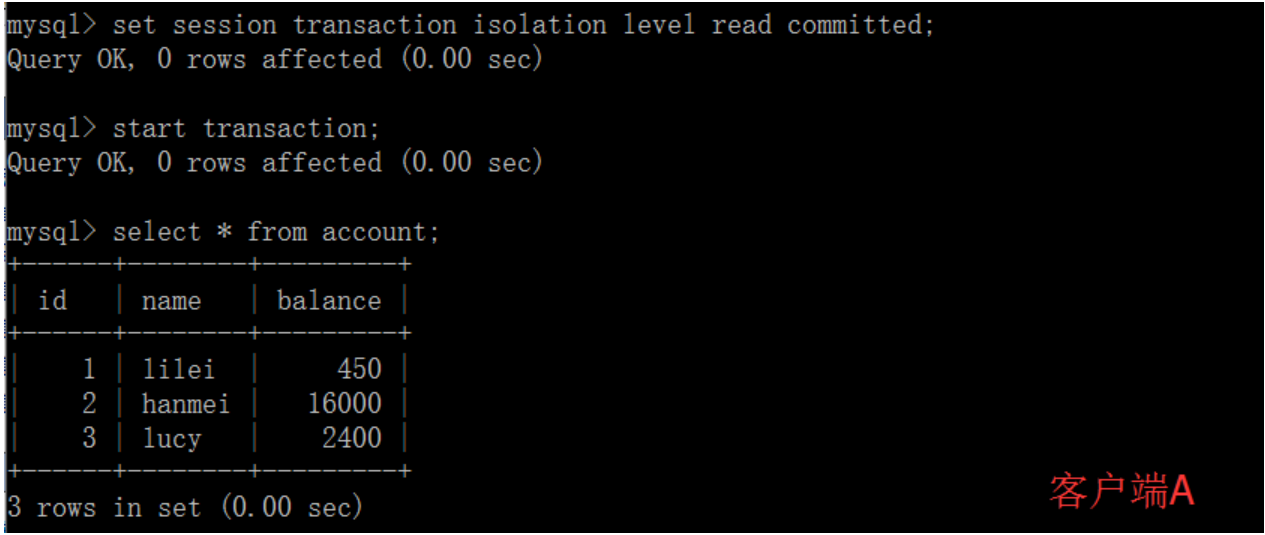
(2)在客户端A的事务提交之前,打开另一个客户端B,更新表account: 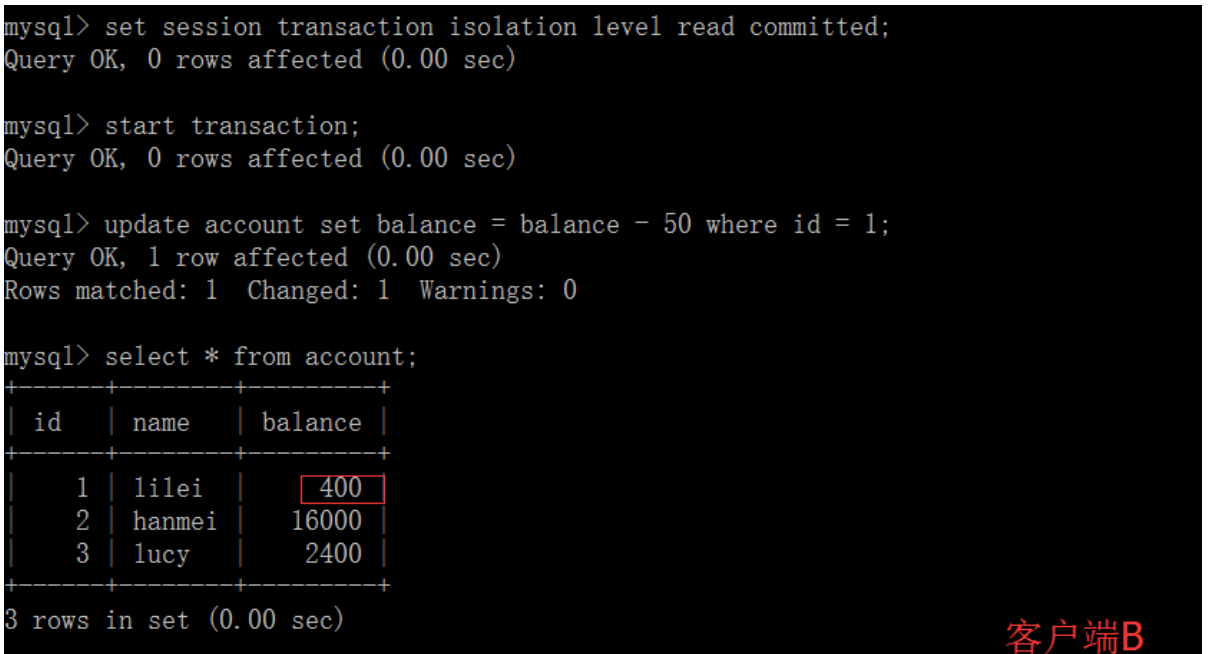
(3)这时,客户端B的事务还没提交,客户端A不能查询到B已经更新的数据,解决了脏读问题:
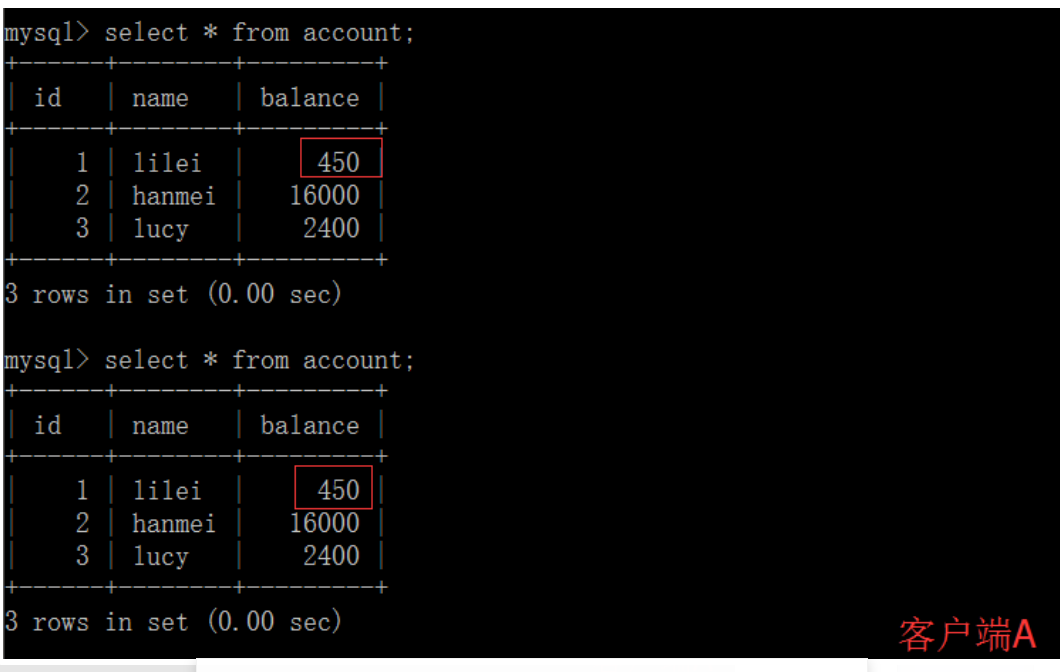
(4)客户端B的事务提交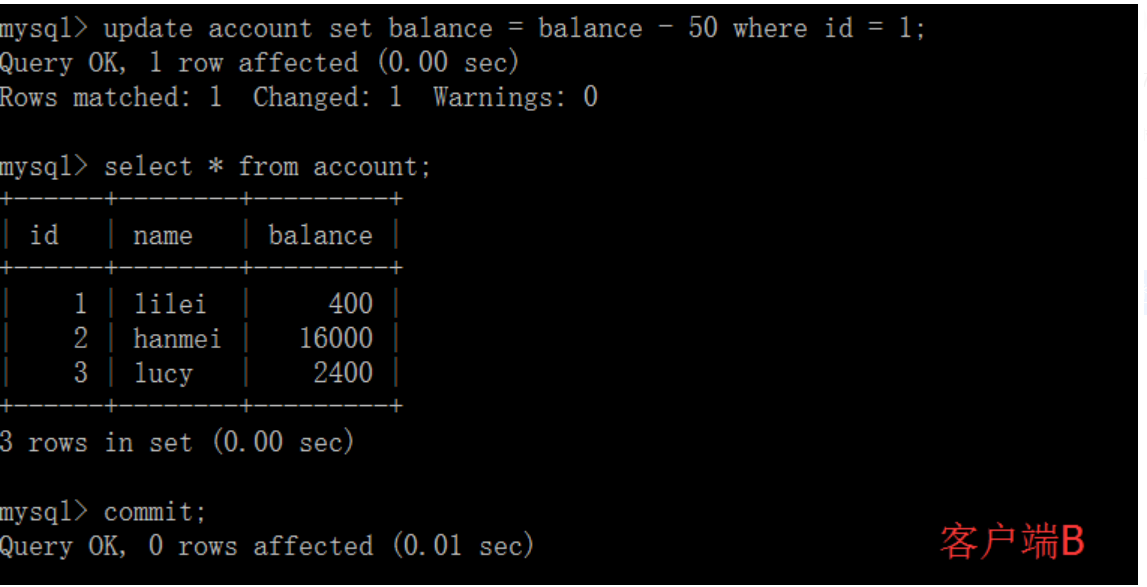
(5)客户端A执行与上一步相同的查询,结果 与上一步不一致,即产生了不可重复读的问题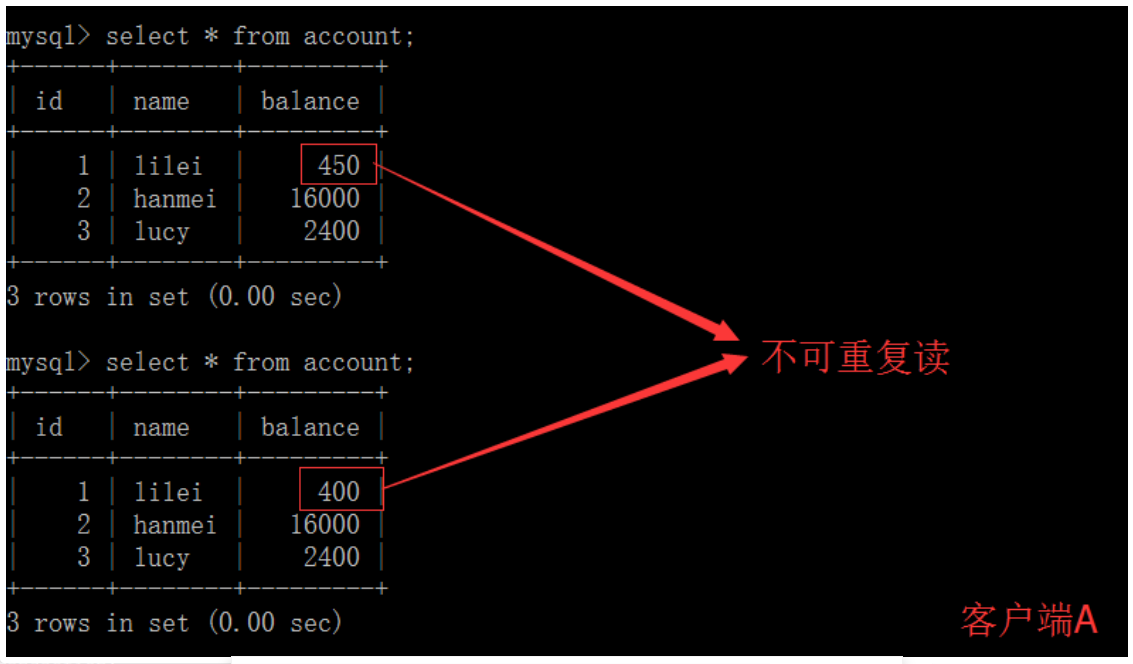 可重复读
可重复读
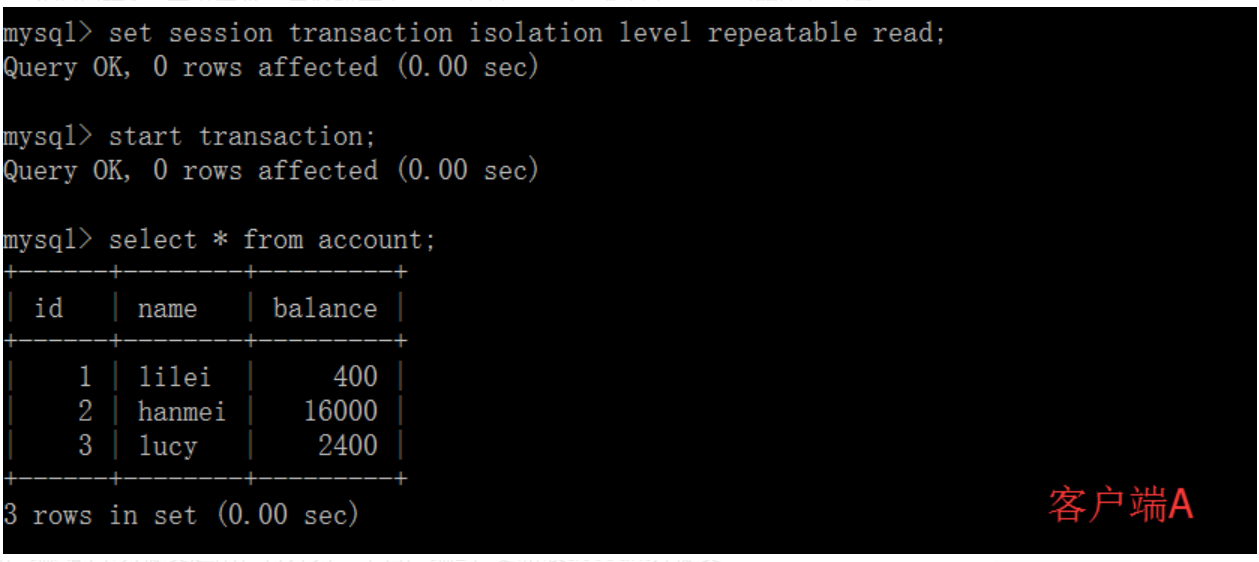 (2)在客户端A的事务提交之前,打开另一个客户端B,更新表account并提交;
(2)在客户端A的事务提交之前,打开另一个客户端B,更新表account并提交;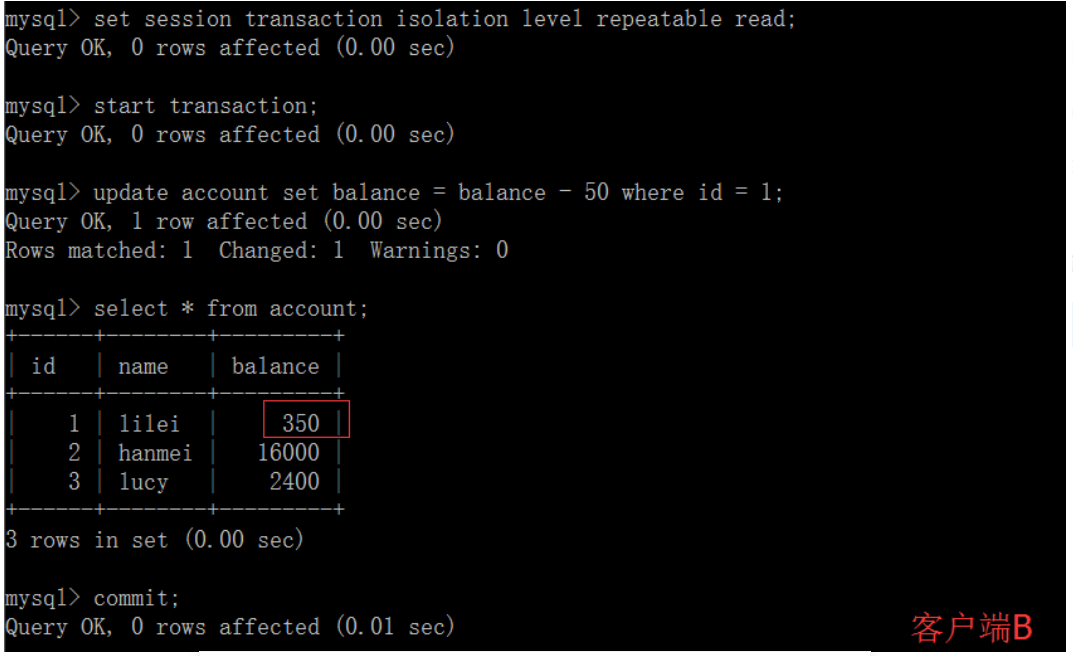
(3)在客户端A查询表account的所有记录,与步骤(1)查询结果一致,没有出现不可重复读的问题;
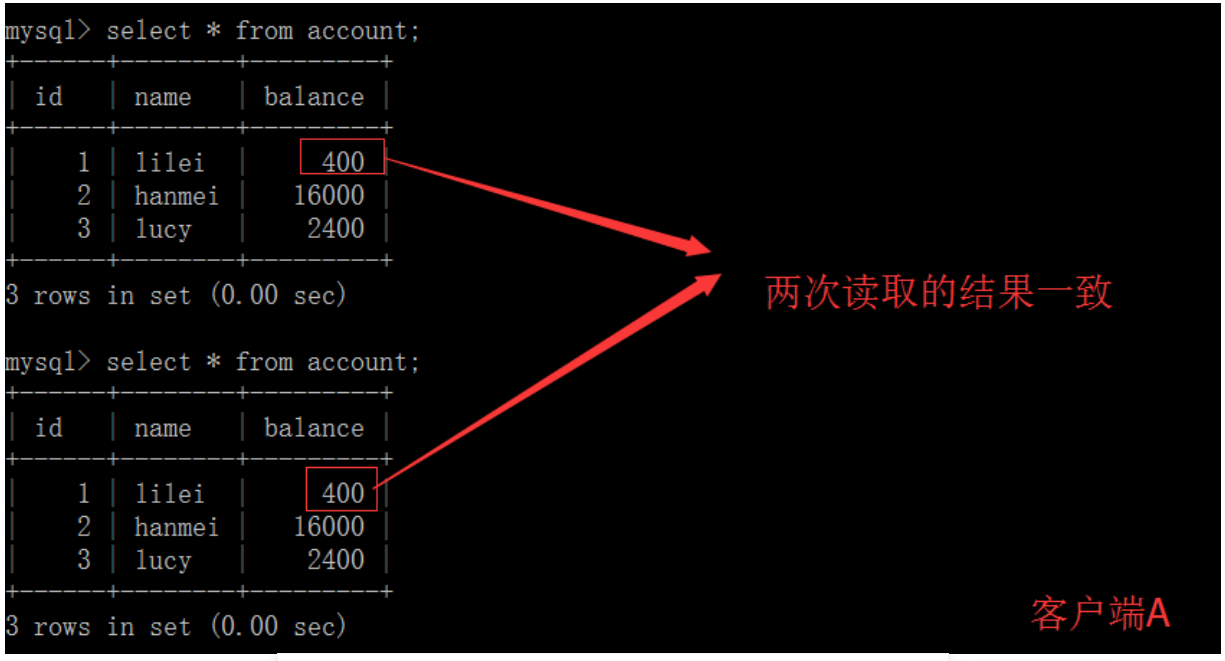
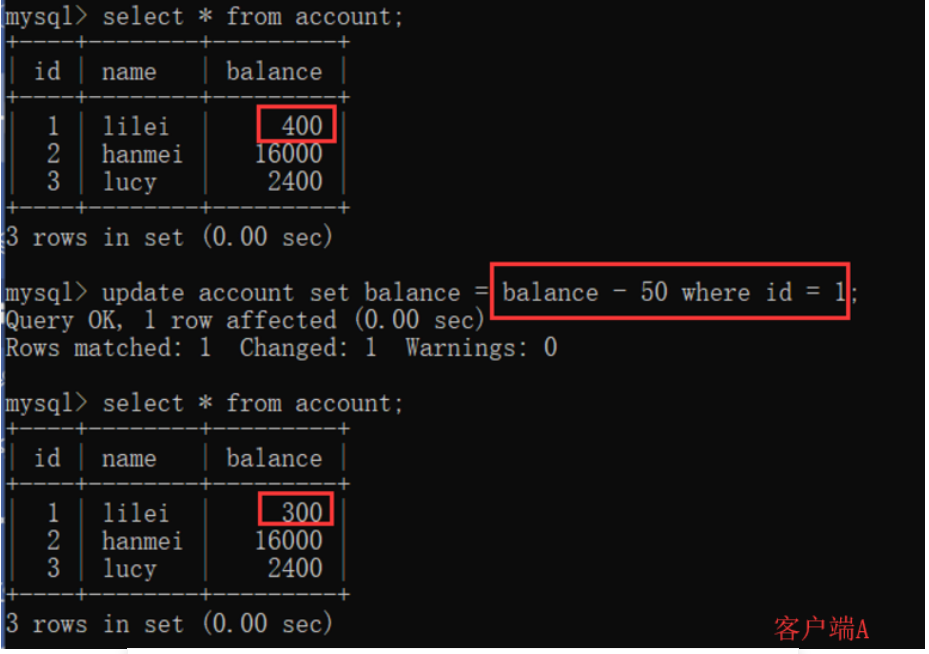
(4)在客户端A,接着执行update account set balance = balance - 50 where id = 1,balance没有变成400-50=350,lilei的balance值用的是步骤2中的350来算的,所以是300,数据的一致性倒是没有被破坏。可重复读的隔离级别下使用了MVCC(multi-version concurrency control)机制,select操作不会更新版本号,是快照读(历史版本);insert、update和delete会更新版本号,是当前读(当前版本)。
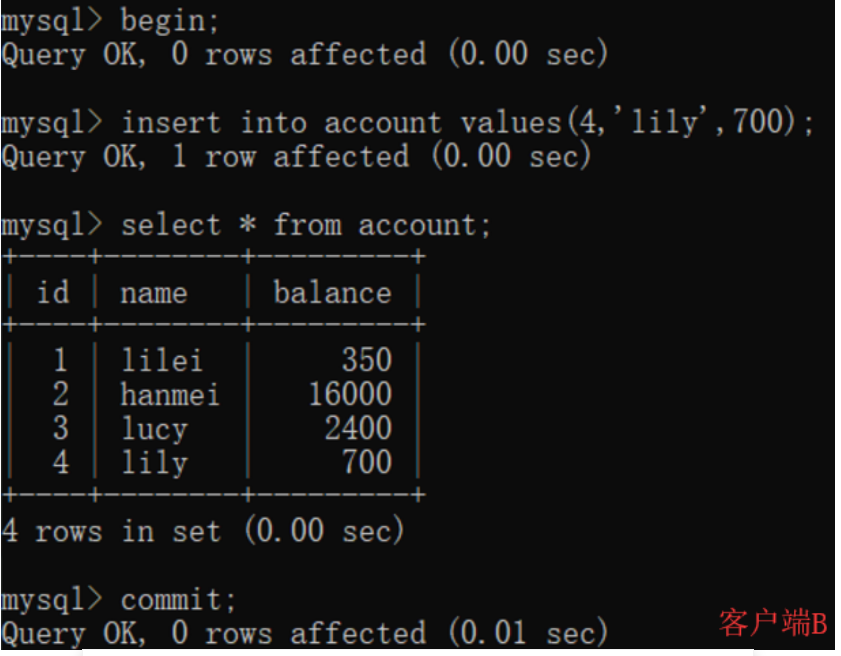
(6)在客户端A查询表account的所有记录,没有查出新增数据,所以没有出现幻读;
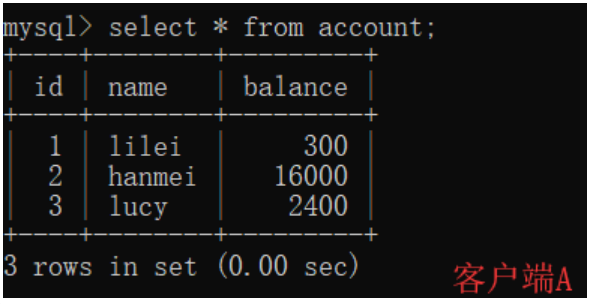
(7)验证幻读
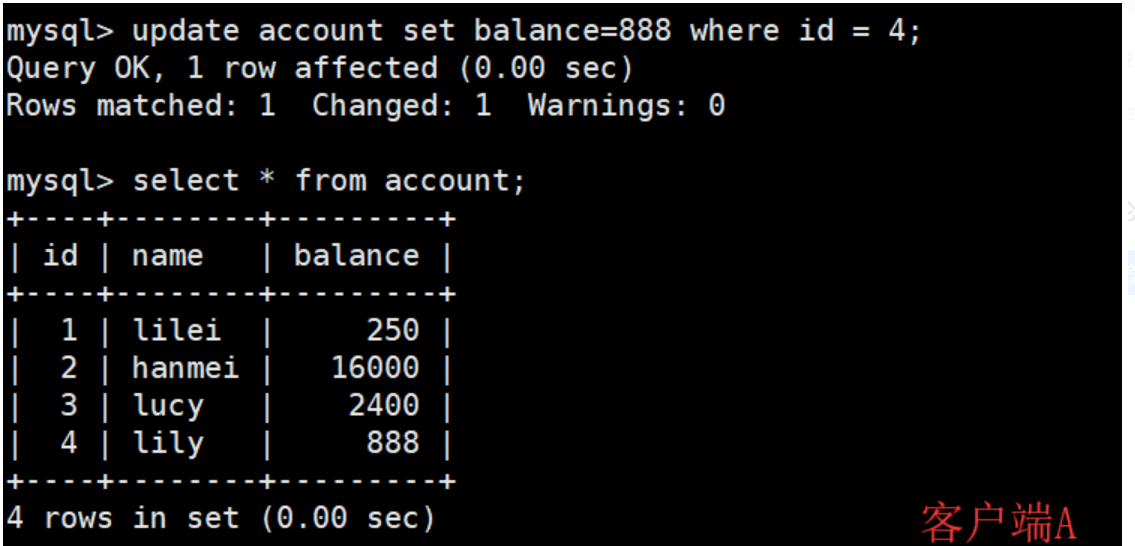
串行化
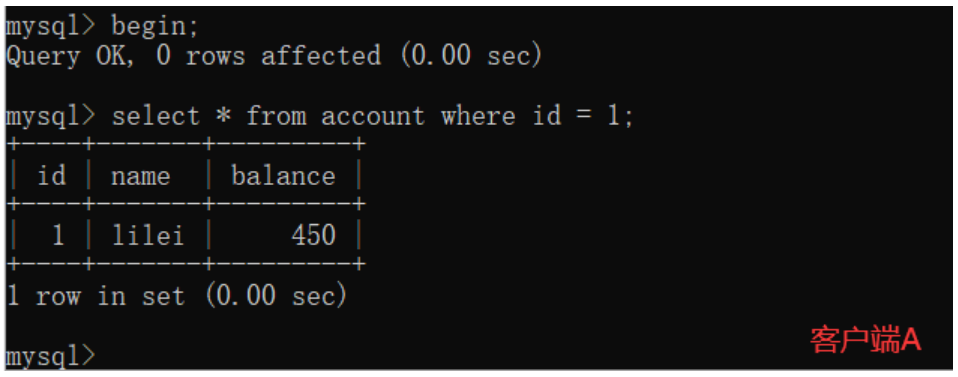
(2)打开一个客户端B,并设置当前事务模式为serializable,更新相同的id为1的记录会被阻塞等待,更新id为2的记录可以成功,说明在串行模式下innodb的查询也会被加上行锁。
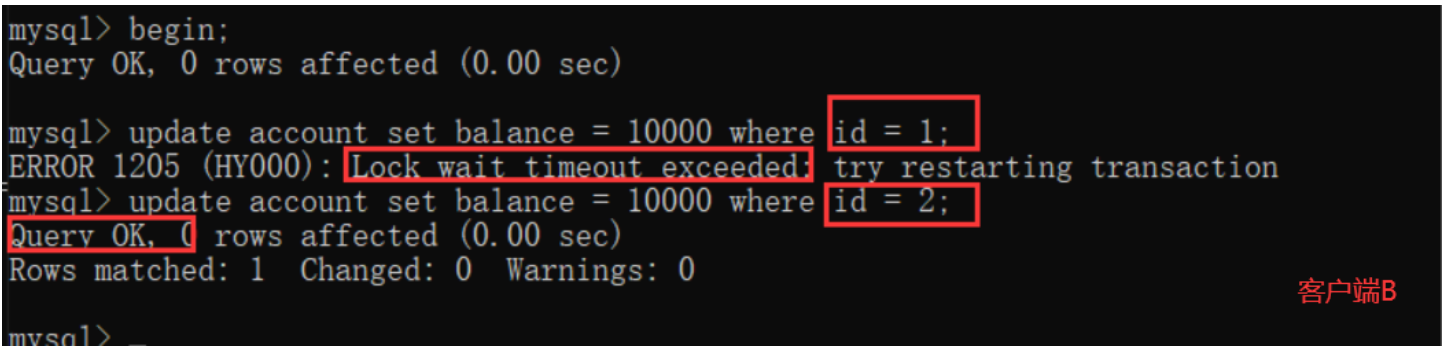
MVCC多版本并发控制机制
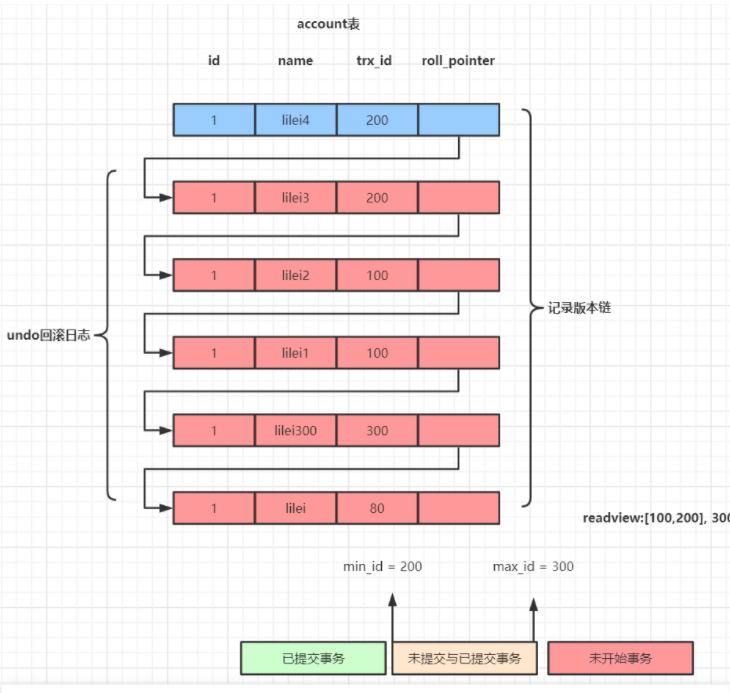
在可重复读隔离级别,当事务开启,执行任何查询sql时会生成当前事务的一致性视图read-view,该视图在事务结束之前都不会变化(如果是读已提交隔离级别在每次执行查询sql时都会重新生成),这个视图由执行查询时所有未提交事务id数组(数组里最小的id为min_id)和已创建的最大事务id(max_id)组成,事务里的任何sql查询结果需要从对应版本链里的最新数据开始逐条跟read-view做比对从而得到最终的快照结果。
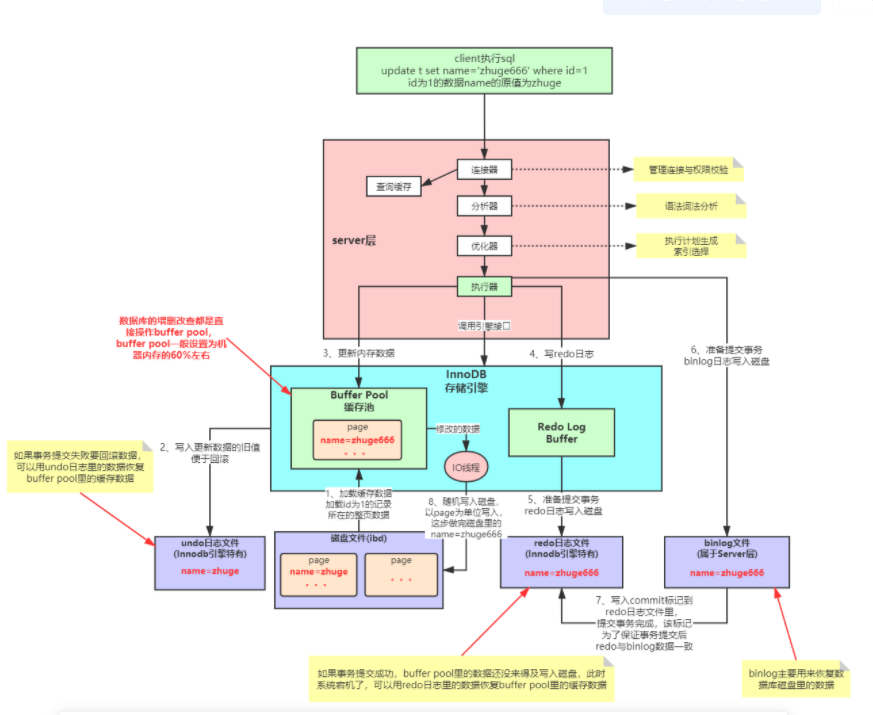
为什么Mysql不能直接更新磁盘上的数据而且设置这么一套复杂的机制来执行SQL了?
本人工作3年中级菜鸟程序员, 最近想回顾一下知识,做了一些简单总结同时也为了自己今后复习方便,如果有逻辑错误,大家体谅,同时也希望大牛们能给出正确答案让我改正,谢谢!
