

1.用图与自己的话,简要描述Hadoop起源与发展阶段。(作业3中剪过来)
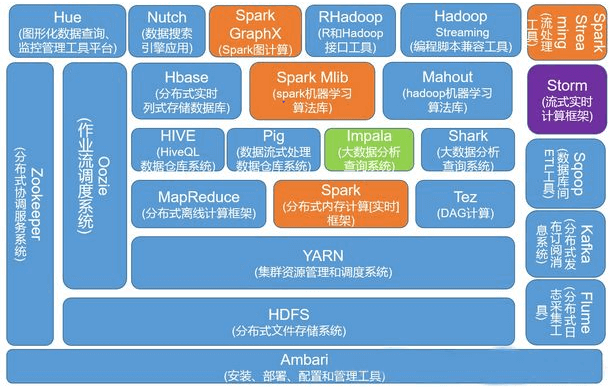
Hadoop是道格·卡丁(Doug Cutting)创建的,Hadoop起源于开源网络搜索引擎Apache Nutch,后者本身也是Lucene项目的一部分。Nutch项目面世后,面对数据量巨大的网页显示出了架构的灵活性不够。当时正好借鉴了谷歌分布式文件系统,做出了自己的开源系统NDFS分布式文件系统。第二年谷歌又发表了论文介绍了MapReduce系统,Nutch开发人员也开发出了MapReduce系统。随后NDFS和MapReduce命名为Hadoop,成为了Apache顶级项目。
发展阶段:阶段0:Ad Hoc集群时代——标志着Hadoop的起源,集群以Ad Hoc、单用户方式建立。
阶段1:Hadoop on Demand(HOD),是进化过程中的下一个阶段,以一种通用系统的形式,在商用硬件组成的共享集群上提供和管理私有Hadoop MapReduce和HDFS实例。
阶段2:共享计算集群的黎明——始于大量Hadoop安装转向与共享HDFS实例一起的共享MapReduce集群。
阶段3:YARN的出现——用以解决以往架构的需求和缺陷
2.用图与自己的话,简要描述名称节点、数据节点的主要功能及相互关系、名称节点的工作机制。

名称节点: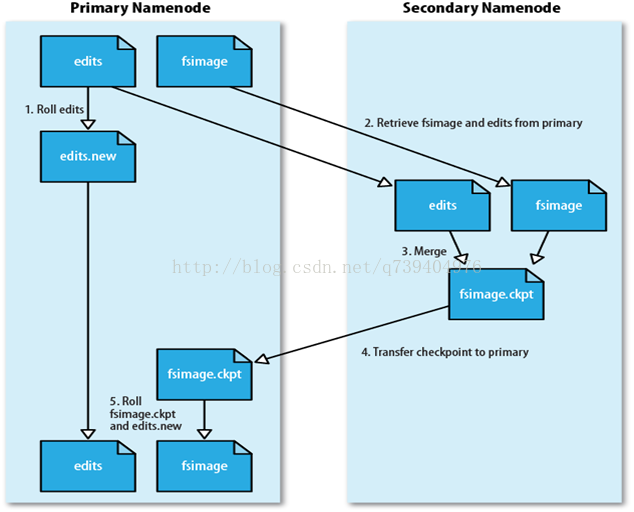
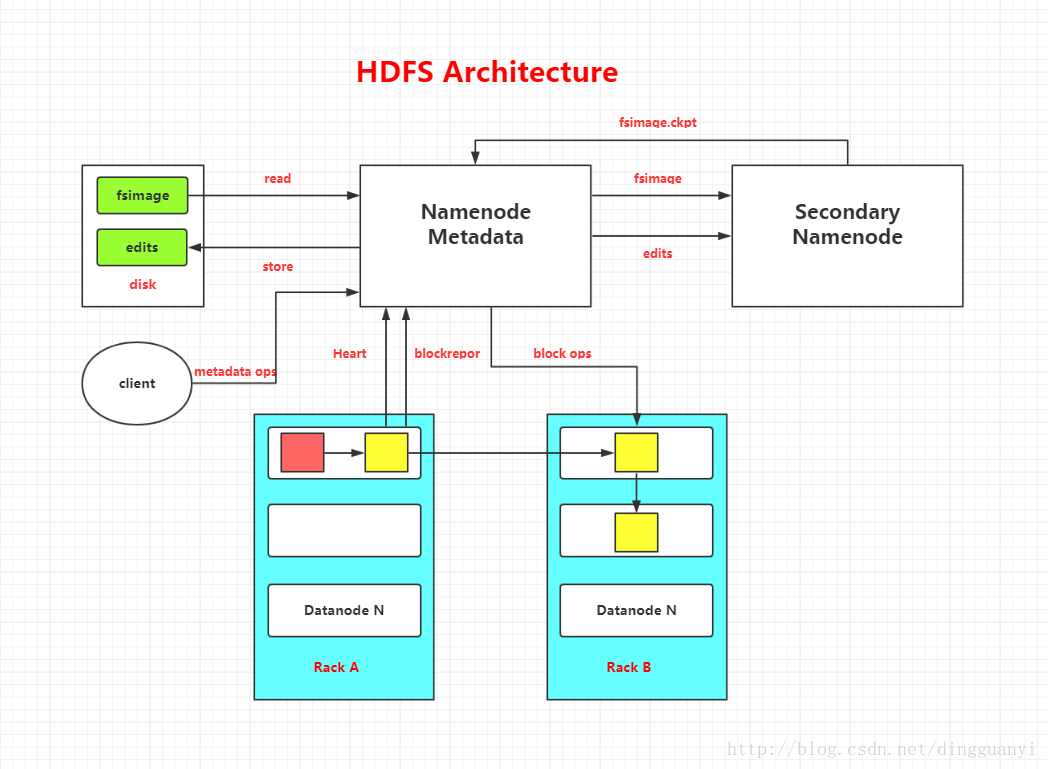
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog
FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据
操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作
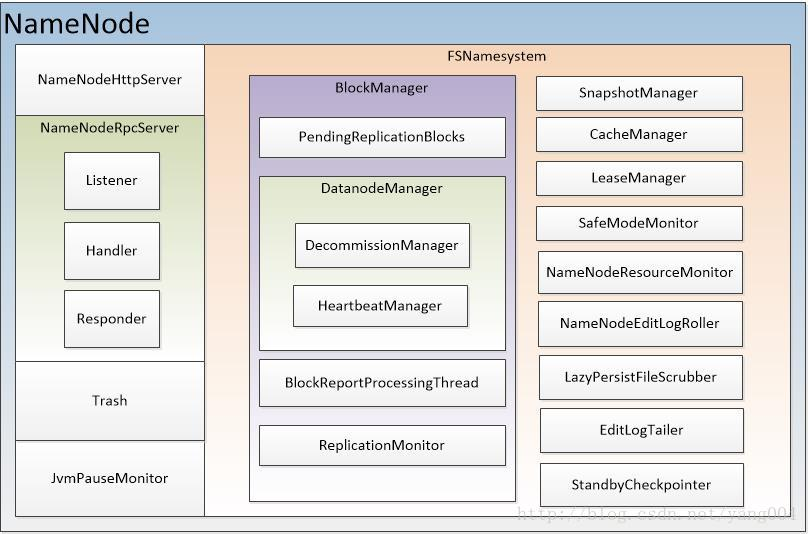
主要功能:
NameNodeHttpServer:提供Http服务
NameNodeRpcServer:RPC机制实现,名字节点与其他节点之间远程调用的实现(名字节点与客户端,名字节点之间以及数据节点与名字节点之间)。
Trash:回收站机制
JvmPauseMonitor:停顿检测
FSNamesystem:名字节点功能实现类,保存主要的数据信息
BlockManager:数据块管理
PendingReplicationBlocks:复制数据块管理
DatanodeManager:数据节点管理
DecommissionManager:节点退役管理
HeartbeatManager:心跳管理
BlockReportProcessingThread:数据块汇报管理
ReplicationMonitor:副本监视
SnapshotManager:快照管理
CacheManager:缓存管理
LeaseManager:租约管理
SafeModeMonitor:安全模式监视
NameNodeResourceMonitor:资源监视
NameNodeEditLogRoller:日志编辑
LazyPersistFileScrubber:lazyPersist文件管理
EditLogTailer:日志跟踪
StandbyCheckpointer:日志检查合并(Standby NameNode)
工作机制:
名称节点启动时,会将FsImage的内容加载到内存当中,然后执行EditLog文件中的各项操作,使得内存中的元数据保存最新。这个操作完成后,就会创建一个新的FsImage文件和一个空的EditLog文件。名称节点启动成功并进入正常运行状态以后,HDFS中的更新操作都会被写入到EditLog,而不是直接写入FsImage(文件大,直接写入系统会变慢)。
数据节点:
DataNode:数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
主要功能:
(一)数据建立。
(二)数据销毁。
(三)数据存储访问。
(四)数据节点间相互配合和自适应。
(五)数据节点间同步。
(六)数据节点与数据使用方同步。
(七)数据持久化。
相互关系:没有名称节点,文件系统将无法使用。事实上,如果运行名称节点的机器被毁坏了,文件系统上所有的文件都会丢失,因为我们无法知道如何通过数据节点上的块来重建文件。因此,名称节点能够经受故障是非常重要的,Hadoop提供了两种机制来确保这一点。
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
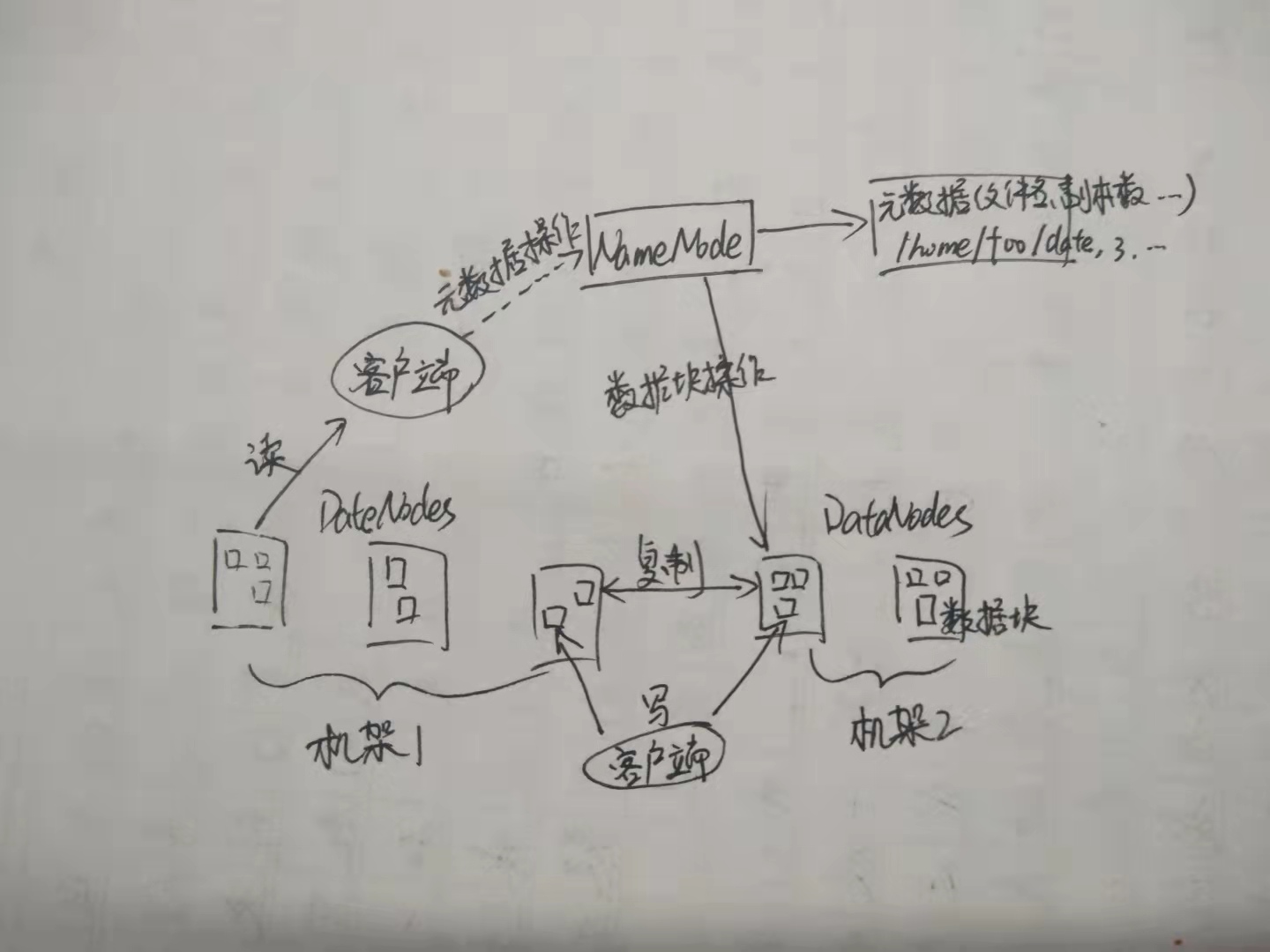
- 客户端与HDFS
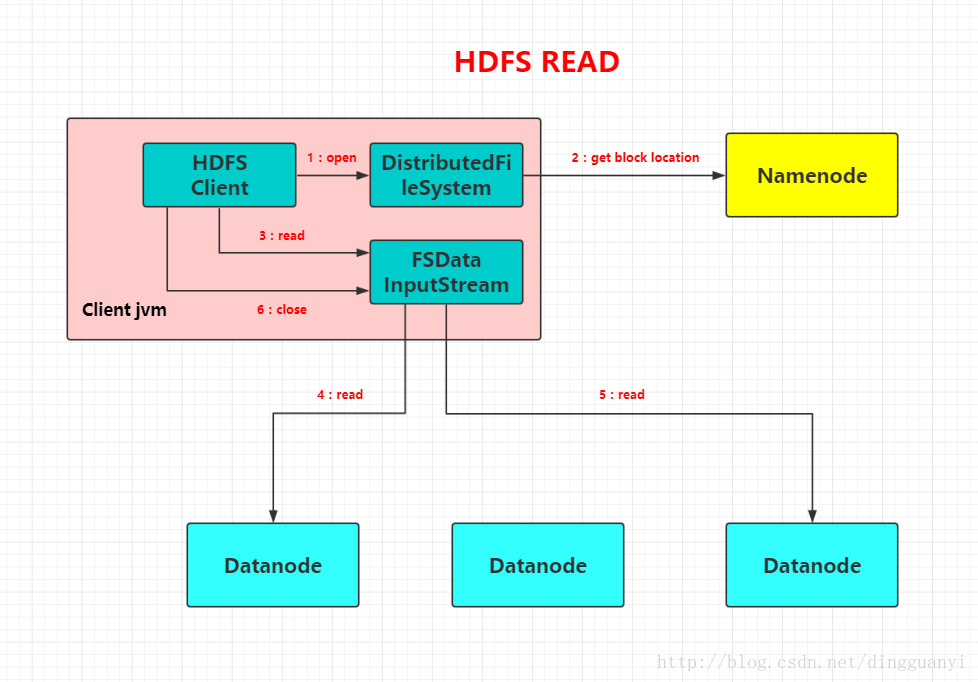
- 客户端读
![]()
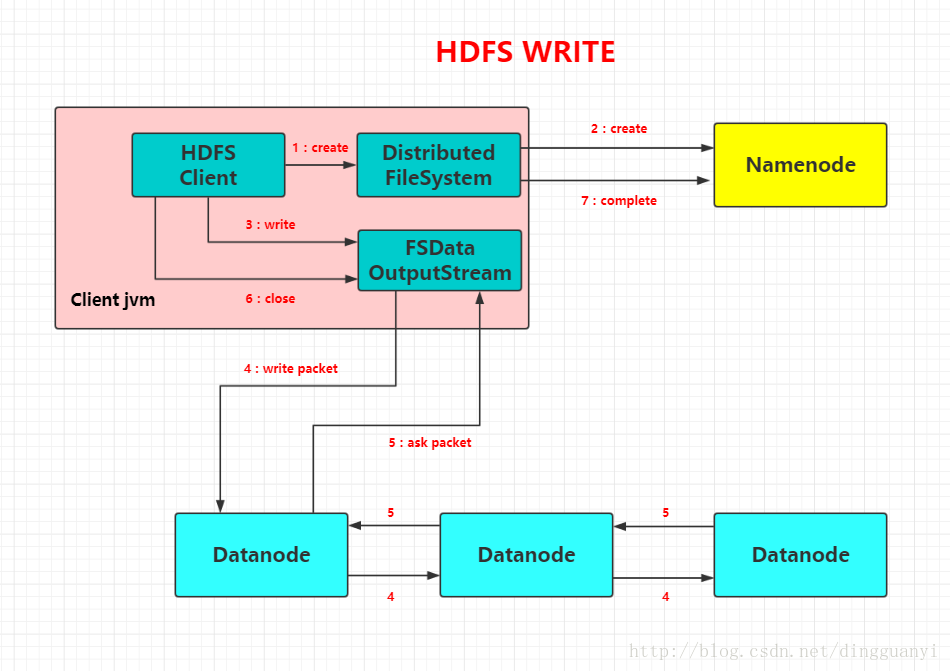
- 客户端写
![]()
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复
5.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
-
①监控RegionServer;
②处理RegionServer故障转移、处理源数据变更;
③处理region的分配与移除;
④空闲时进行数据的负载均衡;
⑤通过Zookeeper发布自己的位置给客户端连接;
- Region服务器的功能
-
①负责与HDFS的交互,存储数据到HDFS中;
②处理Master分配的region;
③刷新缓存到HDFS;
④维护HLog;
⑤执行压缩;
⑥处理region分片;
⑦处理来自客户端的读写请求;
- Zookeeper协同的功能
-
①负责Master的高可用;
②Region服务器的监控;
③元数据的入口以及集群配置的维护工作;
- Client客户端的请求流程
-
①HBase写数据流程
Client请求Zookeeper确定meta表所在的Region服务器所在的地址,接着根据Rowkey找到数据所归属的Region服务器;用户提交put或delete请求时,HBase Client会将put或delete请求添加到本地buffer中,符合一定条件会通过异步批量提交服务器处理。
数据到达Region后,Region服务器获取RowLock,region更新共享锁,接着HBase写日志WAL(数据可靠性),再写缓存MemStore,然后释放锁,将日志落到HDFS;如果MemStore达到阈值将缓存数据落磁盘Store File,最后多个Store File发生合并,若Store File很大则触发split操作,将当前的region分割程2个Region,并且同步至HMaster。
②HBase读数据
Region服务器收到get请求后,对当前的Region进行Scan,接着根据列族对Store进行Scan,同时会对对应的MemStore进行Scan,最后找到需要的数据返回给Client。
- 四者之间的相系关系
-
①Hbase集群有两种服务器:一个Master服务器和多个RegionServer服务器;
②Master服务负责维护表结构信息和各种协调工作,比如建表、删表、移动region、合并等操作;
③客户端获取数据是由客户端直连RegionServer的,所以Master服务挂掉之后依然可以查询、存储、删除数据,就是不能建新表了;
④RegionServer非常依赖Zookeeper服务,Zookeeper管理Hbase所有的RegionServer信息,包括具体的数据段存放在那个RegionServer上;
⑤客户端每次与Hbase连接,其实都是先于Zookeeper通信,查询出哪个RegionServer需要连接,然后再连接RegionServer;客户端从Zookeeper获取了RegionServer的地址后,会直接从RegionServer获取数据;
⑥RegionServer保存的数据直接存储在Hadoop的HDFS上。
总的来说 ,Client访问HBase上的数据的过程并不需要Master的参与,Master仅仅维护着table和region的元数据信息,负载很低。 - 与HDFS的关联
- HDFS为HBase提供最终的底层数据存储服务,同时为HBase提供高可用的支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号