集合
 集合、泛型、迭代器
集合、泛型、迭代器
集合
集合对象是一个容纳数据的容器。集合用于存放数据,之所以用集合存储数据是因为基本数据类型跟字符串、数组等不够用,局限性太大。
例如数组可以存放数据,但是数组的长度不可变,当我不确定我需要存放多少数据时,那在创建时数组的时候到底是创建多长的数组呢?短了存储需求不满足,长了就浪费空间。

java的集合分为两大体系,单列集合collection跟双列集合map。Collection接口的子接口List、Set、Queue的具体实现类和Map具体实现类都是实际开发中常用的。
Collection:
- Collection实现子类可以存放多个元素,每个元素都可以是Object
- 有些Collection子类可以存放重复的元素,有些不可以存放重复的元素
- 有些实现子类是有序的,有些是无序的
- Collection没有直接的实现子类,是通过子接口List、Set来实现的
Map:
- Map用于保存具有映射关系的数据
- Map中的key和value可以是任何引用类型数据,会封装到HashMap&Node对象中
- Map中的Key不允许重复,value可以重复
- Map的key可以为null,value也可以为null,key为null只能有一个,value可以有多个
- 重复添加key会使用后面的元素把前面的元素覆盖
- 常用String类型作为Map的key
- key和value存在一对一的关系,可以通过key找到value
- Map存放数据的结构,一对K-v键值对是存放到HashMap&Node(内部类)中,因为Node实现了Map.Entry接口,所以有一些书上面也说,一对K-V就是一个Entry。
ArrayList
ArrayList是接口List的具体实现类,List接口是Collection接口的子接口
底层结构
- ArrayList可以存放任何数据类型,包括null,可以存入多个null
- ArrayList底层是用数组来实现的存储结构,所以存储有序
- ArrayList不是线程安全的,在多线程下不要使用
数据结构:一个顺序表
特点:
按插入顺序存储数据,数据可以重复。
创建、插入元素
ArrayList list = new ArrayList(); //创建ArrayList集合,长度默认为10
ArrayList list = new ArrayList(5); //创建ArrayList集合,长度指定为5
list.add("zhangsan");
list.add("lisi");
sout(list); //默认的toString方法打印:[zhangsan,lisi]
list.add(0,"wangwu") //在索引位置0出插入数据“wangwu”
list1.addAll(list2); //将list2中的元素都追加到list1后边都是顺序插入的,最先插入的在最前
获取长度
int size = list.size();
sout(size); 获取指定位置数据
list.get(0); //获取第一个元素修改指定位置数据
Object old= list.set(0,"lisipeng"); //修改第一个数据值为lisipeng
sout("修改之前的数据为:"+old) //zhangsanset()修改成功后会返回被修改掉的数据
删除数据
Object delVal = list.remove(0);
sout("被删除的值:"+delVal); //lisipeng
list.remove(Integer.valueOf(55));//删除数组中值为55的对象remove()删除指定位置数据,并返回被删的数据
boolean remove(Object o) 根据值去删除
其他用法
ArrayList list = new ArrayList();
ArrayList list1 = new ArrayList();
ArrayList list2 = new ArrayList();
list.clear(); //清空list中的数据
list.isEmpty(); //判断list集合是否为空
list1.removeAll(lsit2);; //删除list1中 两个集合里面共有的元素
list.contains("zhangsan"); //在当前集合中是否包含指定的元素 ,存在则返回true,不存在返回 false
list.indexOf("zhangsan"); //返回指定元素第一次出现的索引,没有就返回-1
list.lastIndexOf("zhangsan"); //返回指定元素最后一次出现的索引,没有就返回-1
list.toArray() //将集合转化为数组
Integer[] array = (Integer[]) a.toArray();
ArrayList clone = (ArrayList)list.clone(); //复制一个新集合,因为list.clone()返回的是一个Object,所以需要强转
LinkedList
数据结构:一个双链表
创建、添加
LinkedList list = new LinkedList(); //创建LinkedList集合
list.add("张三"); //默认往后添加
list.addFirst(); //往list头部添加
list.add(1,"zhangsasna"); //往指定索引位置添加
list.addAll(list2); //将list2添加到list后边。获取
list.get(1); //获取索引为1的
list.getFirst()
list.getLast()修改
list.set(1,"wangwu") //修改索引为1的数据为wangwu删除
list.remove("lisi"); //删除lisi,成功返回true,反之false
list.remove(); //删除第一个元素
list.remove(1); //删除索引为1的元素
list.removeLast();
list.removeFirst();其他方法
list.clear(); //清空集合
list.contains("1"); //是否包含数据"1"
list.element(); //获取第一个数据
list.indexOf("zhangs");
list.lastIndexOf("zhangs");
list.push("123"); //往list集合里面添加元素“123”
list.pop(); //删除第一个元素
泛型
多态
class Person{
int age;
public void eat(){};
}
class Son extends Person {
public void writeCode(){};
}
//...........
Person p = new Son();
p.writeCode(); //报错
多态是父类类型变量引用子类类型对象对吧,也就是Person p = new Son(); 当p需要使用子类Son中独有writeCode()方法,也就是p.writeCode(); 这样的写法是不被允许的,因为变量p是Person类型,而Person中并没有writeCode()函数。这就是问题所在,因为多态限制住了类型,约束了对象的使用场景,只能在指定类型的场景下去使用他的属性和方法。
场景
class Person{
int age;
public void eat(){};
}
class Son {
public void writeCode(){};
}
//...........
Person p = new Son();
Son s = (Son) p; //强转
p.writeCode(); //成功
//同理,在集合中取出数据使用的时候
ArryList list = new ArrayList();
Person pe = new Person();
Son se = new Son();
list.add(pe);
list.add(se);
Object ob = list.get(0); //取出一个通用类型,因为所有类都继承自Object
Person p2 = (Person) ob; //强转
p2.writeCode(); 如此一来,及其繁琐对吧。
正是多态的这个规则,又因为集合中能够存储任意类型的数据,所以当一个集合中的数据类型有太多类型的话,在处理的数据的时候是非常复杂的,为了避免太过复杂的情况,就需要在往集合中存入数据的时候做一个限制,规定集合只能存储那个类型的数据,这样一来就可以使用泛型。
泛型使用
ArryList<Person> list = new ArrayList<>();
Person pe = new Person();
list.add(pe);
Person ob = list.get(0); //取出一个数据,直接自动就是Person类型,因为定义了泛型体会场景了就容易理解了,通俗理解就是为了限制存入集合的数据的类型,方便读取时处理数据,所以使用泛型。
泛型和类型的区别
上边说的泛型就是为了限制存入集合的数据的类型,对,但不全对,泛型还有另外一个用处,虽然也是限制数据的类型。看下边例子
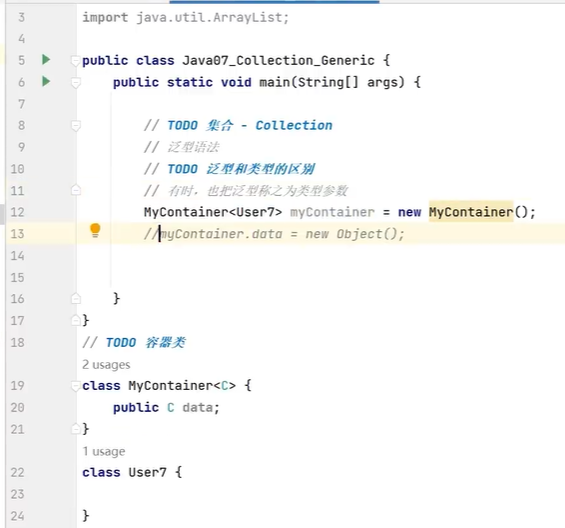
在类名后设置,用法跟集合的差不太多,意会!
泛型总结
- 类型存在多态的使用
- 泛型没有多态
HashSet
特点
特点:数据不能重复,数据无序存储
无序:传入的数据通过hash算法计算决定将这个数据存放在哪里,因为不同数据经过Hash算法计算后的结果是不一致的,所以HashSet中的数据是无序的。
不重复:另外同一个数据(根据hashCode)经过Hash计算多次的结果都是一致的,所以HashSet并不能够存储相同的数据元素,就是说当多个相同数据放入HashSet中它并不报错,只是只存储了一个相同的数据。
可以简单的认为,在hash算法的世界,hashcode就是类似内存地址的存在
底层结构
底层数据结构:数组+双链表
常用方法
HashSet set = new HashSet(); //创建一个HashSet集合
ArrayList list = new ArrayList();
list.add("lisi");
list.add("zhangsan");
set.addAll(list); //将list添加到set中
set.isEmpty(); //判断set是否为空,返回boolean值
set.clear(); //清空set
set.contains("zhangsan"); //判断set中是否存在zhangsan
Object clone = set.clone(); //复制一份
Object[] ob = set.toArray(); //将HashSet集合set转换成数组,注意!基本的方法都是跟ArrayList的差不太多,但需要注意的是:
1、将HashSet集合转换成数组,因为HashSet是无序存储的,所以没有索引,那为啥还能转换成数组啊,这还是因为hash算法,通过该算法将原本无序的HashSet中的数据组合成一个数组,这个数组中的顺序是由hash算法决定的,基本固定(具体咋组的就问hash算法吧)
2、因为HashSet中的数据不能重复,但并不会报错,只是相同数据只存储一份
ArrayBlockingQueue
Queue是Collection接口的一个子接口。
ArrayBlockingQueue = Array + Blocking(阻塞)
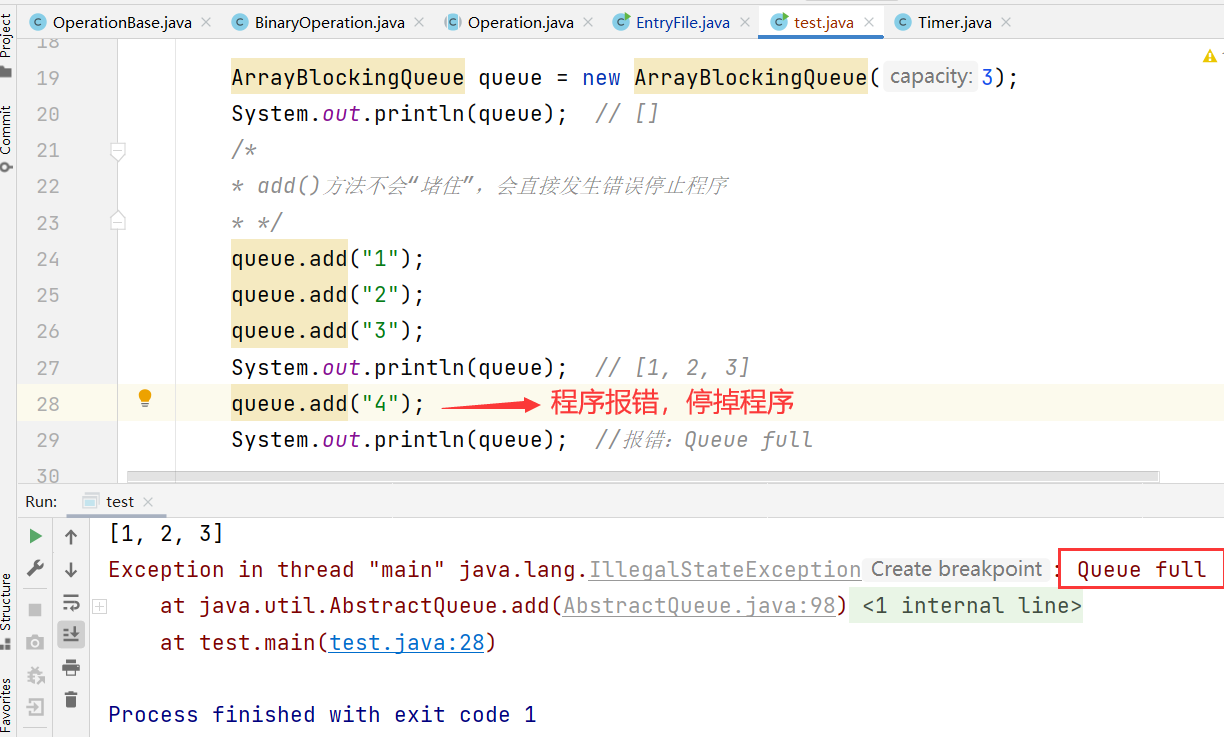
ArrayBlockingQueue queue = new ArrayBlockingQueue( 3 );add()
创建的时候需要传入一个参数,集合长度。当阻塞的时候直接报错停掉程序
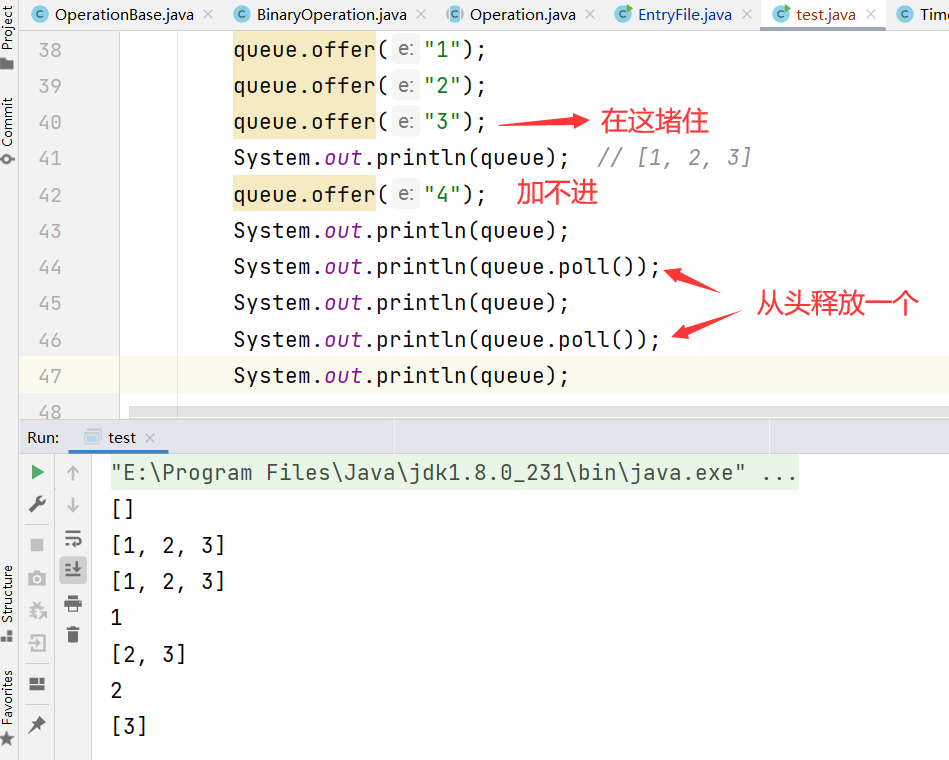
put()
当阻塞的时候程序会等待,不会结束程序也不报错

offer()
queue.offer()往ArrayBlockingQueue 中添加一个数据, 会返回一个boolean类型的数据,当阻塞的时候既不等待也不报错
queue.poll() 表示释放第一个数据,这样后边就可以往里继续添加数据了,会返回被释放(删)的数据
其他方法
跟以上ArrayList的差不多。
HashMap
特点
数据存储无序,key不能重复
无序:是因为需要根据hash算法计算决定存储位置。
key不能重复: 参考HashSet。同一个数据的key(根据hashCode)经过Hash计算多次的结果都是一致的,所以HashMap并不能够存储相同key的数据元素,就是说当多个相同数据放入HashMap中它并不报错,但它会覆盖!就是说后存储进来的数据,因为key相同,所以将相同key值的数据覆盖掉
底层结构
HashMap = 数组+单链表, 跟HashSet相似但又不同
不同是HashSet是面向单一数据,而HashMap是面向kv键值对的数据
基本操作
HashMap map = new HashMap(); //创建HashMap对象
map.put("zhangsan","1"); //没有这个k,就添加该数据,有这个k就修改该数据并返回被修改掉的数据
System.out.println(map.put("zhangsan", "2")); // 1 ,覆盖并返回被修改的数据
map.put("lisi","3");
map.put("wangwu","3");
System.out.println(map); // {lisi=3, zhangsan=2, wangwu=3}
System.out.println(map.get("zhangsan")); // 2 ,获取对应key的值
map.remove("zhangsan"); //删除数据
System.out.println(map.get("zhangsan")); //null
System.out.println(map); // {lisi=3, wangwu=3}常用方法
//添加、修改数据: 没有就添加,有就修改
map.put("a","0");
//添加数据: 没有就添加,有就有啊(不操作)
map.putIfAbsent("b","2");
//修改数据: 有就修改并返回被修改的值,没有就不修改
Objcet b = map.replace("c",3);
//清空
map.clear();
//删除
map.remove("a"); //删除key为a的键值对
map.remove("a","123"); //删除key为a,value为123的键值对遍历HashMap
对key操作
//获取HashMap集合中所有的key
Set set = map.keySet();
for (Object k : set){
sout(map.get(k));
}
//判断有没有一个key叫做“zhangsan”,有就返回true,无就false
sout(map.containsKey("zhangsan"));
对value操作
//获取HashMap集合中所有的value
Collection values = map.values();
//判断map中的值有没有为“1”的
map.containsValue("1");
sout(map);获取键值对对象

Hashtable
跟HashMap很相似,
Hashtable和HashMap的区别
Hashtable的常用方法跟HashMap是差不多的,但是还有一些不一样,HashMap能存任意数据类型,而Hashtable null值就不能存
Hashtable table = new Hashtable();
table.put(null ,null); //不可行
HashMap map = new HashMap();
map.put(null,null); //可行- 实现方式不一样:继承的父类不一样
- 底层结构的容量不同:HashMap(16),Hashtable(11)
- HashMap的kv都可以为null,hashta的kv不能是null
- HashMap的数据定位采用的是hash算法,但是Hashtable采用的就是hashcode
- HashMap的性能较高,但是Hashtable较低。(Hashtable性能较低是因为在多线程时做了更多的操作,更安全,多线程操作时HashMap可能会出毛病)
迭代器
在循环遍历操作(新增、删除)一个集合的时候可能会导致操作,因为删了之后原先的集合并不知道我删了一个数据,导致了数据不一致直接报错(em....没太明白不是都引用了么)
总之对map集合进行遍历时不要进行操作,如要操作就是用迭代器

🙄🙄🙄🙄🙄🙄🙄🙄🙄🙄🙄🙄🙄🙄🙄🙄🙄
参考教程: https://www.bilibili.com/video/BV1o841187iP?p=117&vd_source=7b2999f2f7cc110c9f00dd470572695c

 浙公网安备 33010602011771号
浙公网安备 33010602011771号