LevelDB - 03. DBImpl::write 的逻辑
简单地过一下 levelDB 中 dbimpl.cc 中的 write 逻辑
首先需要说明的就是当我们调用 DBImpl::Put 操作的时候,实际上他会调用 DB::Put 默认的实现,调用到对应的 DBImpl::Write 操作。
简单地过一些对应的步骤,主要是分成了 4 个大部分吧
第一部分:构造 Writer 对象
每一个线程的写操作都会创建一个对应的 Writer 对象,这个对象中存储了此次需要修改的 batch 数据,是否需要同步 sync,以及是否完成 done
Writer w(&mutex_);
w.batch = updates;
w.sync = options.sync;
w.done = false;
每一个 Writer 对象内部都会有一个条件变量,传递 DBImpl 的 mutex_ 给内部的条件变量,使用此条件变量进行线程之间的同步
第二部分:加锁,队头获得锁
首先加锁将每一个写操作放入 wruters_ 队列当中
只允许第一个 writer 获得锁,其他的 writer 线程都被阻塞,由队头 writer 负责后面的写入,利用上面传递的 mutex 进行同步实现
实际上写操作一次只允许一个线程写入,因为对于 MemTable 底层就是非阻塞的跳表,这个跳表可以实现非阻塞的读,但是对写操作,只允许一个写入 LevelDB 中内存数据库的实现:非阻塞的Skiplist
MutexLock l(&mutex_); // 加锁使得 writers 这个 deque 线程安全,MutexLock 就是一个锁的包装类,析构时释放
writers_.push_back(&w);
while (!w.done && &w != writers_.front()) {
w.cv.Wait(); // 只有一个线程可以获得写锁,其他的都会阻塞
}
if (w.done) {
return w.status; // 当写操作已经被合并完成之后直接返回结果
}
之后队头的写操作在能接受的写操作的范围内,负责后面写操作要处理的部分,对于被负责的线程,因为有条件变量的 wait 就会有对应的唤醒,在被唤醒后,检查自己的写操作是否 done,如果 done 说明自己的操作已经被合并写
第三部分:队头合并写
线程能到这里,说明他是队头,并且只有唯一一个写线程能到这里
在这个写的步骤,我觉得可以分成 2 个操作:
- 合并写操作
- 添加写操作 log + 应用修改到内存数据库中
操作一:合并写操作
Status status = MakeRoomForWrite(updates == nullptr);
uint64_t last_sequence = versions_->LastSequence();
Writer* last_writer = &w;
if (status.ok() && updates != nullptr) { // nullptr batch is for compactions
WriteBatch* write_batch = BuildBatchGroup(&last_writer);
WriteBatchInternal::SetSequence(write_batch, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(write_batch);
这里先简单地说明一下 MakeRoomForWrite() 我们可以先简单地将其理解成为是检查 MemTable 是否有足够的空间,如果没有足够的空间,就为其创建足够的空间,因为我们的 MemTable 是有一定的限制大小的,不能一直增加内存的使用,MakeRoomForWrite介绍
之后的逻辑就是 BuildBatchGroup() 方法就会将 writes_ 中后面的写操作与队头的写操作的 batch 进行合并,分配 sequence number 写入到 batch 中,并更新 last_sequence,BuildBatchGroup介绍
这里对 batch 的 WriteBatchInternal::SetSequence 不是由 WriteBatch 负责,这是因为 WriteBatch 是会暴露给客户端的,但我们并不希望客户端可以来设置 sequence number,因此在 WriteBatch 中并没有提供这样设置序列号的方法,而是使用了 WriteBatchInternal 类,他内部提供 static 方法设置序列号,并且不会暴露给客户端。可以学习这样的设计
操作二:添加写操作 log + 修改内存数据库
// Add to log and apply to memtable. We can release the lock
// during this phase since &w is currently responsible for logging
// and protects against concurrent loggers and concurrent writes
// into mem_.
{
mutex_.Unlock();
status = log_->AddRecord(WriteBatchInternal::Contents(write_batch));
bool sync_error = false;
if (status.ok() && options.sync) {
status = logfile_->Sync();
if (!status.ok()) {
sync_error = true;
}
}
if (status.ok()) {
status = WriteBatchInternal::InsertInto(write_batch, mem_);
}
/* 这里加上锁 */
mutex_.Lock();
if (sync_error) {
// The state of the log file is indeterminate: the log record we
// just added may or may not show up when the DB is re-opened.
// So we force the DB into a mode where all future writes fail.
RecordBackgroundError(status);
}
}
if (write_batch == tmp_batch_) tmp_batch_->Clear();
versions_->SetLastSequence(last_sequence);
}
这里其实就是和 LSM 一样了,就是先写 log,然后再将其修改到内存数据库中,主要分析的是为什么在写 log 和应用修改到 memtable 的时候不需要使用锁
这主要是因为在这个时候,因为 writer 是唯一的一个写线程,然后对应读数据,虽然他可能也会读 memtable 但是是可以非阻塞的读的,而其他的后台线程,compaction 线程实际上是不会使用 log 和 memtable 的
因为这里有一个分离设计,就是对于 compaction 线程他进行 minor compaction 或者 major compaction.
- major compaction 是对磁盘中的 SSTable 进行 compaction
- minor compaction 是对 immutable memtable 进行 compcation 产生 level 0 文件,只有 memtable 变成 imm_ 的时候才会被后台线程使用
因此,这里可以不用加锁,正是这样,使得前台写入和后台压缩可以并发安全地运行,而且减少了很多管理的复杂性;注意,在出了 log 写和修改内存数据库之后,对全局的状态进行修改的时候,比如 versions_, 这个就是对应的后台 compaction 也会使用的,这里就需要加上锁了
第四部分:为下一次写操作准备
这里的准备,正如我们之前说的,有 wait 就会有 signal 通知,于是在操作完成后,放入结果并且修改为 done 状态,从 writers_ 中将已经被写入的操作弹出,然后通过对应的条件变量通知他们,使得他们被唤醒,然后可以观察到自己的 done 状态
while (true) {
Writer* ready = writers_.front();
writers_.pop_front();
if (ready != &w) {
ready->status = status;
ready->done = true;
ready->cv.Signal();
}
if (ready == last_writer) break;
}
// Notify new head of write queue
if (!writers_.empty()) {
writers_.front()->cv.Signal();
}
return status;
在过完一遍整体的 write 操作之后,我们来看看对应内部的帮助方法是如何实现的
其他:帮助方法
DBImpl::MakeRoomForWrite
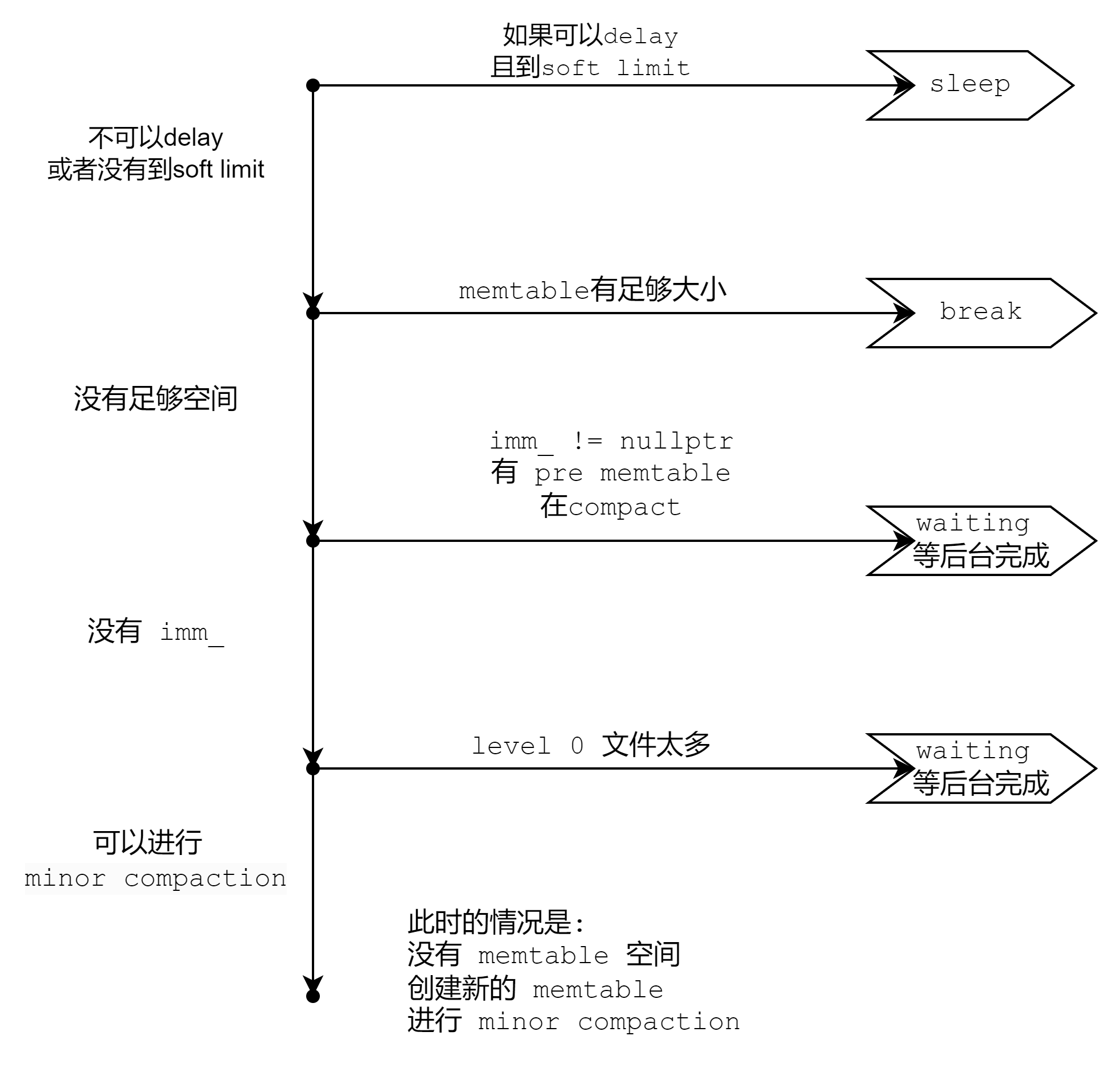
这里就是一共有 5 种情况, 然后一个一个顺着下来
// REQUIRES: mutex_ is held
// REQUIRES: this thread is currently at the front of the writer queue
Status DBImpl::MakeRoomForWrite(bool force) {
mutex_.AssertHeld();
assert(!writers_.empty());
bool allow_delay = !force;
Status s;
while (true) {
if (!bg_error_.ok()) {
// Yield previous error
s = bg_error_;
break;
}
/* 情况一: 操作可以 delay 并且到了 soft limit -> sleep */
else if (allow_delay && versions_->NumLevelFiles(0) >=
config::kL0_SlowdownWritesTrigger) {
// We are getting close to hitting a hard limit on the number of
// L0 files. Rather than delaying a single write by several
// seconds when we hit the hard limit, start delaying each
// individual write by 1ms to reduce latency variance. Also,
// this delay hands over some CPU to the compaction thread in
// case it is sharing the same core as the writer.
mutex_.Unlock();
env_->SleepForMicroseconds(1000);
allow_delay = false; // Do not delay a single write more than once
mutex_.Lock();
}
/* 情况二: 当前 memtable 有足够空间 -> break */
else if (!force &&
(mem_->ApproximateMemoryUsage() <= options_.write_buffer_size)) {
// There is room in current memtable
break;
}
/* 情况三: memtable 没有足够空间,但是之前的 imm_ 还没有 compact 完毕 -> waiting */
else if (imm_ != nullptr) {
// We have filled up the current memtable, but the previou
// one is still being compacted, so we wait.
Log(options_.info_log, "Current memtable full; waiting...\n");
background_work_finished_signal_.Wait();
}
/* 情况四: memtable 没有足够空间,可以转换为 imm_, 但是 level 0 文件太多 -> waiting */
else if (versions_->NumLevelFiles(0) >= config::kL0_StopWritesTrigger) {
// There are too many level-0 files.
Log(options_.info_log, "Too many L0 files; waiting...\n");
background_work_finished_signal_.Wait();
}
/* 情况五: memtable 没有足够空间,可以转换为 imm_, 并且不需要等等 level 0 -> 创建新 memtable,转移为 imm_,schedule minor compaction */
else {
// Attempt to switch to a new memtable and trigger compaction of old
assert(versions_->PrevLogNumber() == 0);
uint64_t new_log_number = versions_->NewFileNumber();
WritableFile* lfile = nullptr;
s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile);
if (!s.ok()) {
// Avoid chewing through file number space in a tight loop.
versions_->ReuseFileNumber(new_log_number);
break;
}
delete log_;
s = logfile_->Close();
if (!s.ok()) {
// We may have lost some data written to the previous log file.
// Switch to the new log file anyway, but record as a background
// error so we do not attempt any more writes.
//
// We could perhaps attempt to save the memtable corresponding
// to log file and suppress the error if that works, but that
// would add more complexity in a critical code path.
RecordBackgroundError(s);
}
delete logfile_;
logfile_ = lfile;
logfile_number_ = new_log_number;
log_ = new log::Writer(lfile);
imm_ = mem_;
has_imm_.store(true, std::memory_order_release);
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
force = false; // Do not force another compaction if have room
MaybeScheduleCompaction();
}
}
return s;
}
这里就是在换 memtable 的时候, log 也要换
DBImpl::BuildBatchGroup
这个逻辑其实很简单,就是从 writes_ 中不断取出来还没有写入的 batch 然后把他合并放入到 tmp_batch_ 中
这里有一个点就是,如果说队头的 batch 是比较小的,那么也不会放入太多的 batch,使得原本应该很快的操作变得太慢
然后最后 *last_writer 指向的就是第一个还没有被合并的操作,即下一个队头
// REQUIRES: Writer list must be non-empty
// REQUIRES: First writer must have a non-null batch
WriteBatch* DBImpl::BuildBatchGroup(Writer** last_writer) {
mutex_.AssertHeld();
assert(!writers_.empty());
Writer* first = writers_.front();
WriteBatch* result = first->batch;
assert(result != nullptr);
size_t size = WriteBatchInternal::ByteSize(first->batch);
// Allow the group to grow up to a maximum size, but if the
// original write is small, limit the growth so we do not slow
// down the small write too much.
size_t max_size = 1 << 20;
if (size <= (128 << 10)) {
max_size = size + (128 << 10);
}
*last_writer = first;
std::deque<Writer*>::iterator iter = writers_.begin();
++iter; // Advance past "first"
for (; iter != writers_.end(); ++iter) {
Writer* w = *iter;
if (w->sync && !first->sync) {
// Do not include a sync write into a batch handled by a non-sync write.
break;
}
if (w->batch != nullptr) {
size += WriteBatchInternal::ByteSize(w->batch);
if (size > max_size) {
// Do not make batch too big
break;
}
// Append to *result
if (result == first->batch) {
// Switch to temporary batch instead of disturbing caller's batch
result = tmp_batch_;
assert(WriteBatchInternal::Count(result) == 0);
WriteBatchInternal::Append(result, first->batch);
}
WriteBatchInternal::Append(result, w->batch);
}
*last_writer = w;
}
return result;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号