
去雾算法杂谈
Single Image Dehazing
Raanan Fattal
Hebrew University of Jerusalem, Israel
这篇文章提出一种新的从单幅输入图像中估计传输函数的方法。新方法中,重新定义了大气传输模型,大气散射模型中除了传输函数(transmission function)这个变量外,还增加了表面阴影(surface shading)这个变量。作者假设一个前提,表面阴影和传输函数是统计无关的,根据这一前提对大气散射模型进行运算分析,即可求得传输函数并对图像去雾。
作者首先介绍了大气散射模型:

该式定义域RGB三颜色通道空间,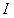 表示探测系统获取的图像,
表示探测系统获取的图像,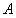 是无穷远处的大气光,
是无穷远处的大气光, 表示目标辐射光,即需要回复的目标图像,
表示目标辐射光,即需要回复的目标图像,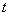 表示传输函数,即光在散射介质中传输经过衰减等作用能够到达探测系统的那一部分的光的比例。坐标向量
表示传输函数,即光在散射介质中传输经过衰减等作用能够到达探测系统的那一部分的光的比例。坐标向量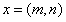 表示探测系统获取的图像中每一个像素的坐标位置。
表示探测系统获取的图像中每一个像素的坐标位置。
对大气散射模型进行变形,将需要恢复的目标图像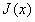 视作表面反射系数
视作表面反射系数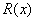 (surface albedo coefficients)和阴影系数
(surface albedo coefficients)和阴影系数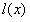 (shading factor)的按坐标的点乘,即
(shading factor)的按坐标的点乘,即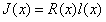 ,其中
,其中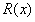 为三通道向量,
为三通道向量,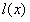 是描述在表面反射的光的标量。即
是描述在表面反射的光的标量。即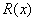 的尺度与
的尺度与 相同,为彩色图像,
相同,为彩色图像,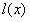 为灰度图像。为了简化,假设
为灰度图像。为了简化,假设 在某区域内为常数,即在像素区域
在某区域内为常数,即在像素区域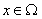 内,
内,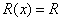 为常数。则大气散射模型变为:
为常数。则大气散射模型变为:

将向量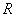 分解成两个部分,一部分为与大气光
分解成两个部分,一部分为与大气光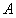 平行的向量,另一部分为与大气光
平行的向量,另一部分为与大气光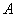 垂直的残留向量(residual vector),记作
垂直的残留向量(residual vector),记作 ,且
,且 ,
,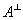 表示与大气光向量
表示与大气光向量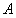 垂直的所有向量构成的向量空间。
垂直的所有向量构成的向量空间。
对于重新定义的大气散射模型中的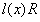 ,将其写成平行于
,将其写成平行于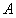 的向量于平行于
的向量于平行于 的向量之和:
的向量之和:
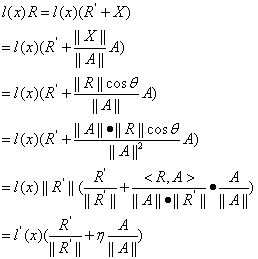
其中,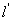 记作
记作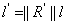 ,
,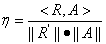 为表面反射和大气光的相关量或相关系数,
为表面反射和大气光的相关量或相关系数,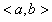 表示在RGB空间中的两个三维向量的点积。
表示在RGB空间中的两个三维向量的点积。
为了获得独立的方程,求取输入图像沿着大气光向量的那一分量(标量)为:

则输入图像沿着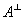 方向的那一分量(标量)为:
方向的那一分量(标量)为:

(因为向量 和向量
和向量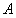 垂直,所以
垂直,所以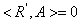 ) 。则有:
) 。则有:
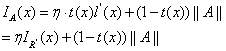
由上式解得传输函数为:
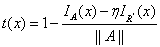
若已知无穷远出的大气光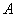 ,则
,则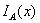 与
与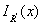 均可求,唯一未知量为
均可求,唯一未知量为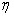 ,所以求解
,所以求解 的问题就归结为求解
的问题就归结为求解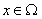 内
内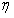 的问题。
的问题。
由于传输函数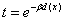 ,所以传输函数与散射系数
,所以传输函数与散射系数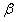 和景深
和景深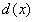 有关,而表面阴影
有关,而表面阴影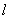 与场景的光照(illuminance in the scene)、表面反射属性(surface reflectance properties)和场景几何结构(scene geometry)有关。所以假设,阴影函数
与场景的光照(illuminance in the scene)、表面反射属性(surface reflectance properties)和场景几何结构(scene geometry)有关。所以假设,阴影函数 和传输函数
和传输函数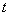 不具有局部相关性,用协方差表示这种无关性为:
不具有局部相关性,用协方差表示这种无关性为:
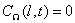
其中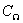 表示为在区域
表示为在区域 内两变量的协方差(covariance),协方差的计算公式为:
内两变量的协方差(covariance),协方差的计算公式为:
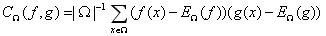
均值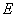 的计算公式为:
的计算公式为:
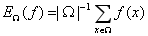
为了使计算简便,考虑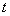 和
和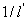 的协方差无关性,即通过
的协方差无关性,即通过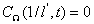 解出
解出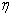 的表达式。重新表达
的表达式。重新表达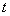 和
和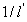 为:
为:

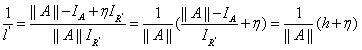
上述两式中,除了参数 和
和 为常量外,其余参数均为变量,式中
为常量外,其余参数均为变量,式中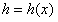 定义为:
定义为:
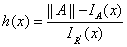
根据协方差公式的性质 ,
,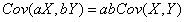 和
和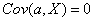 (a为常量),可以得到:
(a为常量),可以得到:
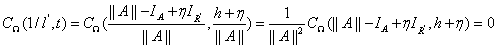
所以有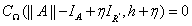 ,该式中由于
,该式中由于 和
和 均为常量,所以可得
均为常量,所以可得 ,即
,即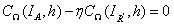 ,从而得到:
,从而得到:
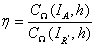
将解得的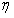 代入到传输函数的表达式中,即可解析去雾模型中的
代入到传输函数的表达式中,即可解析去雾模型中的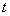 参量。
参量。
本例中为了方便计算,所选块状区域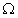 的大小为整幅输入图像的尺寸;本文注重介绍传输函数的求解方法,所以无穷远处大气光的求解可以参考暗通道先验模型进行求解;最后回复出的无雾图像需要进行一次线性拉伸,才能显示出去雾结果。本实验的C++代码如下:
的大小为整幅输入图像的尺寸;本文注重介绍传输函数的求解方法,所以无穷远处大气光的求解可以参考暗通道先验模型进行求解;最后回复出的无雾图像需要进行一次线性拉伸,才能显示出去雾结果。本实验的C++代码如下:
#include <iostream> #include <stdlib.h> #include <time.h> #include <cmath> #include <algorithm> #include <opencv2\opencv.hpp> using namespace cv; using namespace std; float sqr(float x); float norm(float *array); float avg(float *vals, int n); float conv(float *xs, float *ys, int n); Mat stress(Mat& input); Mat getDehaze(Mat& scrimg, Mat& transmission, float *array); Mat getTransmission(Mat& input, float *airlight); int main() { string loc = "E:\\fattal\\project\\project\\house.bmp"; double scale = 1.0; clock_t start, finish; double duration; cout << "A defog program" << endl << "----------------" << endl; Mat image = imread(loc); imshow("hazyiamge", image); cout << "input hazy image" << endl; Mat resizedImage; int originRows = image.rows; int originCols = image.cols; if (scale < 1.0) { resize(image, resizedImage, Size(originCols * scale, originRows * scale)); } else { scale = 1.0; resizedImage = image; } start = clock(); int rows = resizedImage.rows; int cols = resizedImage.cols; int nr = rows; int nl = cols; Mat convertImage(nr, nl, CV_32FC3); resizedImage.convertTo(convertImage, CV_32FC3, 1 / 255.0, 0); int kernelSize = 15; float tmp_A[3]; tmp_A[0] = 0.84; tmp_A[1] = 0.83; tmp_A[2] = 0.80; Mat trans = getTransmission(convertImage, tmp_A); cout << "tansmission estimated." << endl; imshow("t", trans); cout << "start recovering." << endl; Mat finalImage = getDehaze(convertImage, trans, tmp_A); cout << "recovering finished." << endl; Mat resizedFinal; if (scale < 1.0) { resize(finalImage, resizedFinal, Size(originCols, originRows)); imshow("final", resizedFinal); } else { imshow("final", finalImage); } finish = clock(); duration = (double)(finish - start); cout << "defog used " << duration << "ms time;" << endl; waitKey(0); finalImage.convertTo(finalImage, CV_8UC3, 255); const char *path; path = "C:\\Users\\Administrator\\Desktop\\recover.jpg"; imwrite(path, finalImage); destroyAllWindows(); image.release(); resizedImage.release(); convertImage.release(); trans.release(); finalImage.release(); return 0; } float sqr(float x) { return x * x; } float norm(float *array) { return sqrt(sqr(array[0]) + sqr(array[1]) + sqr(array[2])); } float avg(float *vals, int n) { float sum = 0; for (int i = 0; i < n; i++) { sum += vals[i]; } return sum / n; } float conv(float *xs, float *ys, int n) { float ex = avg(xs, n); float ey = avg(ys, n); float sum = 0; for (int i = 0; i < n; i++) { sum += (xs[i] - ex) * (ys[i] - ey); } return sum / n; } Mat getDehaze(Mat &scrimg, Mat &transmission, float *array) { int nr = transmission.rows; int nl = transmission.cols; Mat result = Mat::zeros(nr, nl, CV_32FC3); Mat one = Mat::ones(nr, nl, CV_32FC1); vector<Mat> channels(3); split(scrimg, channels); Mat R = channels[2]; Mat G = channels[1]; Mat B = channels[0]; channels[2] = (R - (one - transmission) * array[2]) / transmission; channels[1] = (G - (one - transmission) * array[1]) / transmission; channels[0] = (B - (one - transmission) * array[0]) / transmission; merge(channels, result); return result; } Mat getTransmission(Mat &input, float *airlight) { float normA = norm(airlight); //Calculate Ia int nr = input.rows, nl = input.cols; Mat Ia(nr, nl, CV_32FC1); for (int i = 0; i < nr; i++) { const float *inPtr = input.ptr<float>(i); float *outPtr = Ia.ptr<float>(i); for (int j = 0; j < nl; j++) { float dotresult = 0; for (int k = 0; k < 3; k++) { dotresult += (*inPtr++) * airlight[k]; } *outPtr++ = dotresult / normA; } } imshow("Ia", Ia); //Calculate Ir Mat Ir(nr, nl, CV_32FC1); for (int i = 0; i < nr; i++) { Vec3f *ptr = input.ptr<Vec3f>(i); float *irPtr = Ir.ptr<float>(i); float *iaPtr = Ia.ptr<float>(i); for (int j = 0; j < nl; j++) { float inNorm = norm(ptr[j]); *irPtr = sqrt(sqr(inNorm) - sqr(*iaPtr)); iaPtr++; irPtr++; } } imshow("Ir", Ir); //Calculate h Mat h(nr, nl, CV_32FC1); for (int i = 0; i < nr; i++) { float *iaPtr = Ia.ptr<float>(i); float *irPtr = Ir.ptr<float>(i); float *hPtr = h.ptr<float>(i); for (int j = 0; j < nl; j++) { *hPtr = (normA - *iaPtr) / *irPtr; hPtr++; iaPtr++; irPtr++; } } imshow("h", h); //Estimate the eta int length = nr * nl; float *Iapix = new float[length]; float *Irpix = new float[length]; float *hpix = new float[length]; for (int i = 0; i < nr; i++) { const float *IaData = Ia.ptr<float>(i); const float *IrData = Ir.ptr<float>(i); const float *hData = h.ptr<float>(i); for (int j = 0; j < nl; j++) { Iapix[i * nl + j] = *IaData++; Irpix[i * nl + j] = *IrData++; hpix[i * nl + j] = *hData++; } } float eta = conv(Iapix, hpix, length) / conv(Irpix, hpix, length); cout << "the value of eta is:" << eta << endl; //Calculate the transmission Mat t(nr, nl, CV_32FC1); for (int i = 0; i < nr; i++) { float *iaPtr = Ia.ptr<float>(i); float *irPtr = Ir.ptr<float>(i); float *tPtr = t.ptr<float>(i); for (int j = 0; j < nl; j++) { *tPtr = 1 - (*iaPtr - eta * (*irPtr)) / normA; tPtr++; iaPtr++; irPtr++; } } imshow("t1", t); Mat trefined; trefined = stress(t); return trefined; } Mat stress(Mat &input) { float data_max = 0.0, data_min = 5.0; int nr = input.rows; int nl = input.cols; Mat output(nr, nl, CV_32FC1); for (int i = 0; i < nr; i++) { float *data = input.ptr<float>(i); for (int j = 0; j < nl; j++) { if (*data > data_max) data_max = *data; if (*data < data_min) data_min = *data; data++; } } float temp = data_max - data_min; for (int i = 0; i < nr; i++) { float *indata = input.ptr<float>(i); float *outdata = output.ptr<float>(i); for (int j = 0; j < nl; j++) { *outdata = (*indata - data_min) / temp; if (*outdata < 0.1) *outdata = 0.1; indata++; outdata++; } } return output; }
上述代码仅做测试参考使用,并没有较大的实际应用价值。代码中的大气光值是假设事先知道的参量,以house这一组数据为例,事先得知bgr三个通道的大气光值分别为0.84、0.83、0.80,则运行结果如下(左右两幅图像分别为原始雾天图像和去雾结果图像):


Single image dehazing via reliability guided fusion
Irfan Riaz, Teng Yu, Yawar Rehman, Hyunchul Shin
Hanyang University
本文的去雾方法本质上是暗通道去雾方法的一种改进,效果很不错,如果你追求去雾效果的话,本文的算法是一种很好的选择。本文主要介绍的是对传输函数的优化,作者构造一种reliability map,将该图像与暗通道得到的传输函数融合,从而得到优化的传输函数,以提升暗通道去雾方法的效果。
文中将本文的暗通道优化方法以流程图的形式给出,并和暗通道方法作了比较:
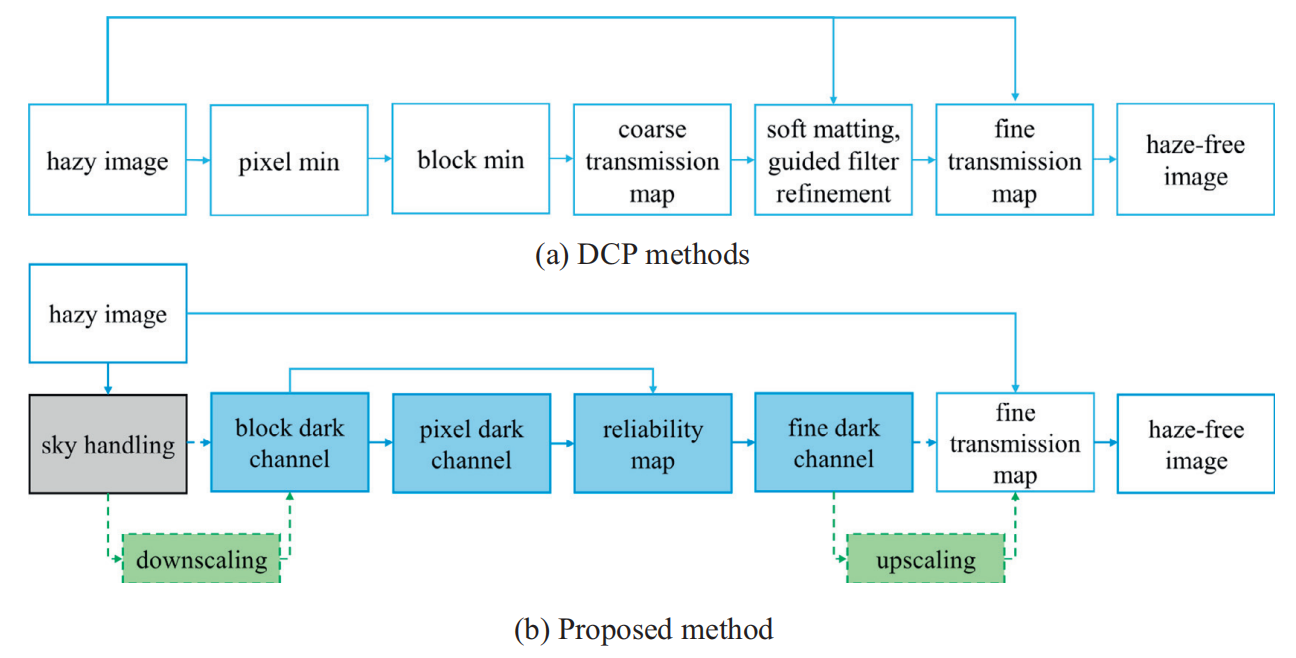
对于图像的固定窗口的尺寸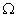 ,首先计算其暗通道图像(c是RGB三个通道的某一个通道),可得:
,首先计算其暗通道图像(c是RGB三个通道的某一个通道),可得:
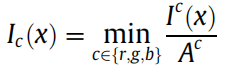
![]()
对暗通道图像作窗口为r x r (r=3)的均值滤波得到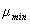 ,然后对
,然后对 作窗口尺寸为的最大值滤波,可得block dark channel
作窗口尺寸为的最大值滤波,可得block dark channel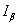 为:
为:
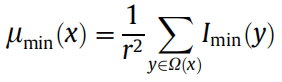
![]()
然后计算pixel dark channel![]() 为:
为:
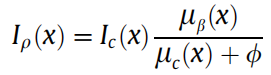
其中, 与
与![]() 分别为对
分别为对![]() 和
和 作均值滤波,其窗口大小为r x r(r=3),
作均值滤波,其窗口大小为r x r(r=3), 为很小的数以防止除数为零。
为很小的数以防止除数为零。
文中给出上述多图对应的计算结果以及其复原效果:

下面介绍计算reliability map以及其与暗通道图像融合的方法。首先计算reliability map 如下:
如下:


其中系数 取0.0025,则将与暗通道图像融合,并估计传输函数如下:
取0.0025,则将与暗通道图像融合,并估计传输函数如下:
![]()
![]()
![]()
文中给出上述各个参量的估计结果特例,以及复原结果:

至此,优化的传输函数已经得到,但是将上述估计的传输函数代入到某些含有大量天空区域的雾天图像进行图像复原时,会发现天空区域的处理结果并不理想,因此有必要对天空区域作进一步处理。构造权重函数 并修改
并修改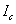 如下:
如下:

![]()
将修改后的代替其原始的计算公式,即可解决图像的天空区域复原的问题。式中参数 与
与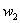 分别为10和0.2。
分别为10和0.2。
下面给出本文的C++代码以供参考:
#include <iostream> #include <stdlib.h> #include <time.h> #include <cmath> #include <algorithm> #include <opencv2\opencv.hpp> using namespace cv; using namespace std; typedef struct Pixel { int x, y; int data; }Pixel; bool structCmp(const Pixel &a, const Pixel &b) { return a.data > b.data;//descending降序 } Mat minFilter(Mat srcImage, int kernelSize); Mat maxFilter(Mat srcImage, int kernelSize); void makeDepth32f(Mat &source, Mat &output); void guidedFilter(Mat &source, Mat &guided_image, Mat &output, int radius, float epsilon); Mat getTransmission(Mat &srcimg, Mat &transmission, int windowsize); Mat recover(Mat &srcimg, Mat &t, float *array, int windowsize); int main() { string loc = "E:\\code\\reliability\\project\\project\\cones.bmp"; double scale = 1.0; string name = "forest"; clock_t start, finish; double duration; cout << "A defog program" << endl << "----------------" << endl; Mat image = imread(loc); Mat resizedImage; int originRows = image.rows; int originCols = image.cols; imshow("hazyimg", image); if (scale < 1.0) { resize(image, resizedImage, Size(originCols * scale, originRows * scale)); } else { scale = 1.0; resizedImage = image; } int rows = resizedImage.rows; int cols = resizedImage.cols; Mat convertImage; resizedImage.convertTo(convertImage, CV_32FC3, 1 / 255.0); int kernelSize = 15 ? max((rows * 0.01), (cols * 0.01)) : 15 < max((rows * 0.01), (cols * 0.01)); //int kernelSize = 15; int parse = kernelSize / 2; Mat darkChannel(rows, cols, CV_8UC1); Mat normalDark(rows, cols, CV_32FC1); Mat normal(rows, cols, CV_32FC1); int nr = rows; int nl = cols; float b, g, r; start = clock(); cout << "generating dark channel image." << endl; if (resizedImage.isContinuous()) { nl = nr * nl; nr = 1; } for (int i = 0; i < nr; i++) { float min; const uchar *inData = resizedImage.ptr<uchar>(i); uchar *outData = darkChannel.ptr<uchar>(i); for (int j = 0; j < nl; j++) { b = *inData++; g = *inData++; r = *inData++; min = b > g ? g : b; min = min > r ? r : min; *outData++ = min; } } darkChannel = minFilter(darkChannel, kernelSize); darkChannel.convertTo(normal, CV_32FC1, 1 / 255.0); imshow("darkChannel", darkChannel); cout << "dark channel generated." << endl; //estimate Airlight //开一个结构体数组存暗通道,再sort,取最大0.1%,利用结构体内存储的原始坐标在原图中取点 cout << "estimating airlight." << endl; rows = darkChannel.rows, cols = darkChannel.cols; int pixelTot = rows * cols * 0.001; int *A = new int[3]; Pixel *toppixels, *allpixels; toppixels = new Pixel[pixelTot]; allpixels = new Pixel[rows * cols]; for (unsigned int r = 0; r < rows; r++) { const uchar *data = darkChannel.ptr<uchar>(r); for (unsigned int c = 0; c < cols; c++) { allpixels[r * cols + c].data = *data; allpixels[r * cols + c].x = r; allpixels[r * cols + c].y = c; } } std::sort(allpixels, allpixels + rows * cols, structCmp); memcpy(toppixels, allpixels, pixelTot * sizeof(Pixel)); float A_r, A_g, A_b, avg, maximum = 0; int idx, idy, max_x, max_y; for (int i = 0; i < pixelTot; i++) { idx = allpixels[i].x; idy = allpixels[i].y; const uchar *data = resizedImage.ptr<uchar>(idx); data += 3 * idy; A_b = *data++; A_g = *data++; A_r = *data++; //cout << A_r << " " << A_g << " " << A_b << endl; avg = (A_r + A_g + A_b) / 3.0; if (maximum < avg) { maximum = avg; max_x = idx; max_y = idy; } } delete[] toppixels; delete[] allpixels; for (int i = 0; i < 3; i++) { A[i] = resizedImage.at<Vec3b>(max_x, max_y)[i]; } cout << "airlight estimated as: " << A[0] << ", " << A[1] << ", " << A[2] << endl; //暗通道归一化操作(除A) //(I / A) float tmp_A[3]; tmp_A[0] = A[0] / 255.0; tmp_A[1] = A[1] / 255.0; tmp_A[2] = A[2] / 255.0; int radius = 3; int kernel = 2 * radius+1; Size win_size(kernel, kernel); Mat S(rows, cols, CV_32FC1); float w1 = 10.0; float w2 = 0.2; float min = 1.0; float b_A, g_A, r_A; float pixsum; for (int i = 0; i < nr; i++) { const float *inData = convertImage.ptr<float>(i); float *outData = normalDark.ptr<float>(i); float *sData = S.ptr<float>(i); for (int j = 0; j < nl; j++) { b = *inData++; g = *inData++; r = *inData++; b_A = b / tmp_A[0]; g_A = g / tmp_A[1]; r_A = r / tmp_A[2]; min = b_A > g_A ? g_A : b_A; min = min > r_A ? r_A : min; *outData++ = min; pixsum = (b - tmp_A[0]) * (b - tmp_A[0]) + (g - tmp_A[1]) * (g - tmp_A[1]) + (r - tmp_A[2]) * (b - tmp_A[2]); *sData++ = exp((-1 * w1) * pixsum); } } imshow("S", S); //calculate the Iroi map Mat Ic = normalDark; Mat Icest; Mat Imin; Mat umin; Mat Ibeta; Ic = Ic.mul(Mat::ones(rows, cols, CV_32FC1) - w2 * S); imshow("Ic", Ic); Imin = minFilter(Ic, kernel); imshow("Imin", Imin); boxFilter(Imin, umin, CV_32F, win_size); Ibeta = maxFilter(umin, kernel); imshow("Ibeta", Ibeta); Mat ubeta; Mat uc; boxFilter(Ibeta, ubeta, CV_32F, win_size); boxFilter(Ic, uc, CV_32F, win_size); float fai = 0.0001; Mat Iroi; Mat weight = (Mat::ones(rows, cols, CV_32FC1)) * fai; divide((Ic.mul(ubeta)), (uc + weight), Iroi); imshow("Iroi", Iroi); //calculate the reliability map alpha Mat uepsilon; Mat alpha; Mat m = Ibeta - umin; Mat n = Ibeta - Iroi; boxFilter(m.mul(m) + n.mul(n), uepsilon, CV_32F, win_size); float zeta = 0.0025; uepsilon / (uepsilon + Mat::ones(rows, cols, CV_32FC1) * zeta); alpha = Mat::ones(rows, cols, CV_32FC1) - uepsilon / (uepsilon + Mat::ones(rows, cols, CV_32FC1) * zeta); imshow("alpha", alpha); //calculate the Idark map Mat Ialbe; Mat ualpha; Mat ualbe; Mat Idark; Ialbe = alpha.mul(Ibeta); boxFilter(alpha, ualpha, CV_32F, win_size); boxFilter(Ialbe, ualbe, CV_32F, win_size); Idark = Iroi.mul(Mat::ones(rows, cols, CV_32FC1) - ualpha) + ualbe; imshow("Idark", Idark); float w = 0.95; Mat t; t = Mat::ones(rows, cols, CV_32FC1) - w*Idark; int kernelSizeTrans = std::max(3, kernelSize); Mat trans = getTransmission(convertImage, t, kernelSizeTrans); imshow("t",trans); Mat finalImage = recover(convertImage, trans, tmp_A, kernelSize); cout << "recovering finished." << endl; Mat resizedFinal; if (scale < 1.0) { resize(finalImage, resizedFinal, Size(originCols, originRows)); imshow("final", resizedFinal); } else { imshow("final", finalImage); } finish = clock(); duration = (double)(finish - start); cout << "defog used " << duration << "ms time;" << endl; waitKey(0); finalImage.convertTo(finalImage, CV_8UC3, 255); imwrite("refined.png", finalImage); destroyAllWindows(); image.release(); resizedImage.release(); convertImage.release(); darkChannel.release(); trans.release(); finalImage.release(); return 0; } Mat minFilter(Mat srcImage, int kernelSize) { int radius = kernelSize / 2; int srcType = srcImage.type(); int targetType = 0; if (srcType % 8 == 0) { targetType = 0; } else { targetType = 5; } Mat ret(srcImage.rows, srcImage.cols, targetType); Mat parseImage; copyMakeBorder(srcImage, parseImage, radius, radius, radius, radius, BORDER_REPLICATE); for (unsigned int r = 0; r < srcImage.rows; r++) { float *fOutData = ret.ptr<float>(r); uchar *uOutData = ret.ptr<uchar>(r); for (unsigned int c = 0; c < srcImage.cols; c++) { Rect ROI(c, r, kernelSize, kernelSize); Mat imageROI = parseImage(ROI); double minValue = 0, maxValue = 0; Point minPt, maxPt; minMaxLoc(imageROI, &minValue, &maxValue, &minPt, &maxPt); if (!targetType) { *uOutData++ = (uchar)minValue; continue; } *fOutData++ = minValue; } } return ret; } Mat maxFilter(Mat srcImage, int kernelSize) { int radius = kernelSize / 2; int srcType = srcImage.type(); int targetType = 0; if (srcType % 8 == 0) { targetType = 0; } else { targetType = 5; } Mat ret(srcImage.rows, srcImage.cols, targetType); Mat parseImage; copyMakeBorder(srcImage, parseImage, radius, radius, radius, radius, BORDER_REPLICATE); for (unsigned int r = 0; r < srcImage.rows; r++) { float *fOutData = ret.ptr<float>(r); uchar *uOutData = ret.ptr<uchar>(r); for (unsigned int c = 0; c < srcImage.cols; c++) { Rect ROI(c, r, kernelSize, kernelSize); Mat imageROI = parseImage(ROI); double minValue = 0, maxValue = 0; Point minPt, maxPt; minMaxLoc(imageROI, &minValue, &maxValue, &minPt, &maxPt); if (!targetType) { *uOutData++ = (uchar)maxValue; continue; } *fOutData++ = maxValue; } } return ret; } void makeDepth32f(Mat &source, Mat &output) { if ((source.depth() != CV_32F) > FLT_EPSILON) source.convertTo(output, CV_32F); else output = source; } void guidedFilter(Mat &source, Mat &guided_image, Mat &output, int radius, float epsilon) { CV_Assert(radius >= 2 && epsilon > 0); CV_Assert(source.data != NULL && source.channels() == 1); CV_Assert(guided_image.channels() == 1); CV_Assert(source.rows == guided_image.rows && source.cols == guided_image.cols); Mat guided; if (guided_image.data == source.data) { //make a copy guided_image.copyTo(guided); } else { guided = guided_image; } //将输入扩展为32位浮点型,以便以后做乘法 Mat source_32f, guided_32f; makeDepth32f(source, source_32f); makeDepth32f(guided, guided_32f); //计算I*p和I*I Mat mat_Ip, mat_I2; multiply(guided_32f, source_32f, mat_Ip); multiply(guided_32f, guided_32f, mat_I2); //计算各种均值 Mat mean_p, mean_I, mean_Ip, mean_I2; Size win_size(2 * radius + 1, 2 * radius + 1); boxFilter(source_32f, mean_p, CV_32F, win_size); boxFilter(guided_32f, mean_I, CV_32F, win_size); boxFilter(mat_Ip, mean_Ip, CV_32F, win_size); boxFilter(mat_I2, mean_I2, CV_32F, win_size); //计算Ip的协方差和I的方差 Mat cov_Ip = mean_Ip - mean_I.mul(mean_p); Mat var_I = mean_I2 - mean_I.mul(mean_I); var_I += epsilon; //求a和b Mat a, b; divide(cov_Ip, var_I, a); b = mean_p - a.mul(mean_I); //对包含像素i的所有a、b做平均 Mat mean_a, mean_b; boxFilter(a, mean_a, CV_32F, win_size); boxFilter(b, mean_b, CV_32F, win_size); //计算输出 (depth == CV_32F) output = mean_a.mul(guided_32f) + mean_b; } Mat getTransmission(Mat &srcimg, Mat &transmission, int windowsize) { int nr = srcimg.rows, nl = srcimg.cols; Mat trans(nr, nl, CV_32FC1); Mat graymat(nr, nl, CV_8UC1); Mat graymat_32F(nr, nl, CV_32FC1); if (srcimg.type() % 8 != 0) { cvtColor(srcimg, graymat_32F, CV_BGR2GRAY); guidedFilter(transmission, graymat_32F, trans, 6 * windowsize, 0.001); } else { cvtColor(srcimg, graymat, CV_BGR2GRAY); for (int i = 0; i < nr; i++) { const uchar *inData = graymat.ptr<uchar>(i); float *outData = graymat_32F.ptr<float>(i); for (int j = 0; j < nl; j++) *outData++ = *inData++ / 255.0; } guidedFilter(transmission, graymat_32F, trans, 6 * windowsize, 0.001); } return trans; } Mat recover(Mat &srcimg, Mat &t, float *array, int windowsize) { //J(x) = (I(x) - A) / max(t(x), t0) + A; int radius = windowsize / 2; int nr = srcimg.rows, nl = srcimg.cols; float tnow = t.at<float>(0, 0); float t0 = 0.1; Mat finalimg = Mat::zeros(nr, nl, CV_32FC3); float val = 0; for (unsigned int r = 0; r < nr; r++) { const float *transPtr = t.ptr<float>(r); const float *srcPtr = srcimg.ptr<float>(r); float *outPtr = finalimg.ptr<float>(r); for (unsigned int c = 0; c < nl; c++) { tnow = *transPtr++; tnow = std::max(tnow, t0); for (int i = 0; i < 3; i++) { val = (*srcPtr++ - array[i]) / tnow + array[i]; *outPtr++ = val + 10 / 255.0; } } } return finalimg; }
以一组实验结果为例,验证实验是否正确:



hazy image Ibeta Iroi



alpha transmission map output image
下面给出本文方法的多组运行结果:
















如果将该算法部署在实际工程中,应该使用C/C++编写程序,并结合SSE优化加速,可以参考如下的代码:
// 打开宏定义 __SIMD__ 即可进行SSE指令集的加速
#include <stdlib.h>
#include <assert.h>
#include <time.h>
#include <cmath>
#include <algorithm>
#include <iostream>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
// 使用指令集进行优化时 一次处理16个像素 然后处理8个像素
#define __SIMD__
#ifdef __SIMD__
#include <xmmintrin.h> //sse
#include <emmintrin.h> //sse2
#include <tmmintrin.h> //sse3
#include <smmintrin.h> //sse4.1
/************************************************ _mm_exp_ps_ ************************************************/
static const __m128 _ln2 = _mm_set1_ps(0.69314718056f);
static const __m128 _inv_ln2 = _mm_set1_ps(1.44269504089f);
static const __m128 _c0 = _mm_set1_ps(1.0f);
static const __m128 _c1 = _mm_set1_ps(1.0f);
static const __m128 _c2 = _mm_set1_ps(0.5000030518f);
static const __m128 _c3 = _mm_set1_ps(0.1666656616f);
static const __m128 _half = _mm_set1_ps(0.5f);
inline __m128 _mm_exp_ps_(__m128 _x) {
__m128 _kf = _mm_mul_ps(_x, _inv_ln2);
_kf = _mm_add_ps(_kf, _half);
__m128i _k = _mm_cvtps_epi32(_kf);
__m128 _r = _mm_sub_ps(_x, _mm_mul_ps(_mm_cvtepi32_ps(_k), _ln2));
__m128 _r2 = _mm_mul_ps(_r, _r);
__m128 _r3 = _mm_mul_ps(_r2, _r);
__m128 _poly = _mm_add_ps(_c0, _mm_mul_ps(_r, _c1));
_poly = _mm_add_ps(_poly, _mm_mul_ps(_r2, _c2));
_poly = _mm_add_ps(_poly, _mm_mul_ps(_r3, _c3));
__m128i _exp_bias = _mm_set1_epi32(127 << 23);
__m128i _k_shifted = _mm_slli_epi32(_k, 23);
__m128i _pow2_k_bits = _mm_add_epi32(_k_shifted, _exp_bias);
__m128 _pow2_k = _mm_castsi128_ps(_pow2_k_bits);
return _mm_mul_ps(_poly, _pow2_k);
}
/************************************************ _mm_exp_ps_ ************************************************/
#endif
inline unsigned char ClampToByte(int value) {
if (value < 0) return 0;
else if (value > 255) return 255;
else return (unsigned char)value;
}
/************************************************************* the basic filtering functions *************************************************************/
void transpose(const float* src, float* dst, int width, int height);
void min_filter_func(float* src, float* dest, int width, int height, int mask_size);
void min_filter(float* src, float* dest, int width, int height, int mask_size);
void max_filter_func(float* src, float* dest, int width, int height, int mask_size);
void max_filter(float* src, float* dest, int width, int height, int mask_size);
void box_filter(float* src, float* dest, int width, int height, int mask_size);
/************************************************************* the basic filtering functions *************************************************************/
/*********************************************************** the functions for dehaze process ************************************************************/
void dark_function(unsigned char* input, unsigned char* output, int width, int height, int stride);
void airlight_estimation(unsigned char* src_image, unsigned char* dark_channel, int width, int height, int stride, int* A_b, int* A_g, int* A_r);
void sky_handling(unsigned char* I, float* Ic, float* Ic_refine, int width, int height, int stride, int A_b, int A_g, int A_r);
void recover(unsigned char* hazy_image, unsigned char* recover_result, float* transmission, int width, int height, int stride, int A_b, int A_g, int A_r);
/*********************************************************** the functions for dehaze process *************************************************************/
/************************************************************ the basic calculation functions *************************************************************/
void cvt_u_f(unsigned char* src, float* dest, int width, int height);
void cvt_f_u(float* src, unsigned char* dest, int width, int height);
void array_add(float* a_array, float* b_array, float* output, int width, int height, float a_weight, float b_weight);
void array_sub(float* a_array, float* b_array, float* output, int width, int height, float a_weight, float b_weight);
void array_sub_pow(float* a_array, float* b_array, float* output, int width, int height);
void array_dot_mul(float* a_array, float* b_array, float* output, int width, int height);
void array_dot_div(float* a_array, float* b_array, float* output, int width, int height, float eps);
void down_sample(float* src, float* dest, int width, int height, float ratio_w, float ratio_h);
void up_sample(float* src, float* dest, int width_src, int height_src, int width_dest, int height_dest);
/************************************************************ the basic calculation functions *************************************************************/
/// <summary>
/// 单通道图像转置函数
/// </summary>
/// <param name="src"></param> 输入图像数据
/// <param name="dst"></param> 输出图像数据
/// <param name="width"></param> 输入图像的宽 输出图像的高
/// <param name="height"></param> 输入图像的高 输出图像的宽
void transpose(const float* src, float* dst, int width, int height) {
#ifdef __SIMD__
const int block_size = 4;
// 主处理块 - 仅处理完整的4x4块
for (int h = 0; h <= height - block_size; h += block_size) {
for (int w = 0; w <= width - block_size; w += block_size) {
// 加载源矩阵的4行(4×4块)
__m128 _row_0 = _mm_loadu_ps(src + h * width + w);
__m128 _row_1 = _mm_loadu_ps(src + (h + 1) * width + w);
__m128 _row_2 = _mm_loadu_ps(src + (h + 2) * width + w);
__m128 _row_3 = _mm_loadu_ps(src + (h + 3) * width + w);
// 转置4×4矩阵
__m128 _tmp_0 = _mm_unpacklo_ps(_row_0, _row_1);
__m128 _tmp_1 = _mm_unpacklo_ps(_row_2, _row_3);
__m128 _tmp_2 = _mm_unpackhi_ps(_row_0, _row_1);
__m128 _tmp_3 = _mm_unpackhi_ps(_row_2, _row_3);
__m128 _transposed_0 = _mm_movelh_ps(_tmp_0, _tmp_1);
__m128 _transposed_1 = _mm_movehl_ps(_tmp_1, _tmp_0);
__m128 _transposed_2 = _mm_movelh_ps(_tmp_2, _tmp_3);
__m128 _transposed_3 = _mm_movehl_ps(_tmp_3, _tmp_2);
// 存储到目标位置
_mm_storeu_ps(dst + w * height + h, _transposed_0);
_mm_storeu_ps(dst + (w + 1) * height + h, _transposed_1);
_mm_storeu_ps(dst + (w + 2) * height + h, _transposed_2);
_mm_storeu_ps(dst + (w + 3) * height + h, _transposed_3);
}
}
// 处理剩余部分 - 关键修复区域
const int processed_h = height - (height % block_size);
const int processed_w = width - (width % block_size);
// 1. 处理主区域外的底部行
for (int h = processed_h; h < height; h++) {
for (int w = 0; w < width; w++) {
dst[w * height + h] = src[h * width + w];
}
}
// 2. 处理主区域外的右侧列(不包括已处理的底部行)
for (int h = 0; h < processed_h; h++) {
for (int w = processed_w; w < width; w++) {
dst[w * height + h] = src[h * width + w];
}
}
#else
for (int h = 0; h < height; h++) {
for (int w = 0; w < width; w++) {
dst[w * height + h] = src[h * width + w];
}
}
#endif
}
/// <summary>
/// 浮点型最小值滤波垂直方向核心函数
/// 算法参考论文 https://www.cnblogs.com/Imageshop/p/7018510.html
/// </summary>
/// <param name="src"></param> 输入图像数据
/// <param name="dest"></param> 输出图像数据
/// <param name="width"></param> 输入图像的宽
/// <param name="height"></param> 输入图像的高
/// <param name="mask_size"></param> 滤波窗口的尺寸 通常为奇数
void min_filter_func(float* src, float* dest, int width, int height, int mask_size) {
/* ensure the mask_size be odd number greater than 3 */
if (mask_size < 3 || mask_size % 2 == 0) {
printf("Invalid mask size!");
return;
}
int radius = (mask_size - 1) / 2;
int block_vert_num = ((height % mask_size) == 0 ? height / mask_size : height / mask_size + 1);
// 分配临时内存(使用calloc初始化)
float* G = (float*)calloc(height * width, sizeof(float));
float* H = (float*)calloc(height * width, sizeof(float));
if (G == NULL || H == NULL) {
if (G) free(G);
if (H) free(H);
return;
}
// 垂直分块处理
for (int block_idx = 0; block_idx < block_vert_num; block_idx++) {
int start_h = block_idx * mask_size;
int end_h = std::min(start_h + mask_size, height);
// 初始化G的首行(使用memcpy确保正确复制)
memcpy(G + start_h * width, src + start_h * width, width * sizeof(float));
// 正向计算G(从上到下)
for (int h = start_h + 1; h < end_h; h++) {
float* srcPtr = src + h * width;
float* destPtr = G + h * width;
float* prevPtr = G + (h - 1) * width;
int w = 0;
#ifdef __SIMD__
// SSE处理16个浮点数(4组SSE寄存器)
for (; w + 15 < width; w += 16) {
// 加载数据
__m128 _srcPtr_0 = _mm_loadu_ps(srcPtr + w);
__m128 _srcPtr_1 = _mm_loadu_ps(srcPtr + w + 4);
__m128 _srcPtr_2 = _mm_loadu_ps(srcPtr + w + 8);
__m128 _srcPtr_3 = _mm_loadu_ps(srcPtr + w + 12);
__m128 _prevPtr_0 = _mm_loadu_ps(prevPtr + w);
__m128 _prevPtr_1 = _mm_loadu_ps(prevPtr + w + 4);
__m128 _prevPtr_2 = _mm_loadu_ps(prevPtr + w + 8);
__m128 _prevPtr_3 = _mm_loadu_ps(prevPtr + w + 12);
// 计算最小值
__m128 _min_0 = _mm_min_ps(_srcPtr_0, _prevPtr_0);
__m128 _min_1 = _mm_min_ps(_srcPtr_1, _prevPtr_1);
__m128 _min_2 = _mm_min_ps(_srcPtr_2, _prevPtr_2);
__m128 _min_3 = _mm_min_ps(_srcPtr_3, _prevPtr_3);
// 存储结果
_mm_storeu_ps(destPtr + w, _min_0);
_mm_storeu_ps(destPtr + w + 4, _min_1);
_mm_storeu_ps(destPtr + w + 8, _min_2);
_mm_storeu_ps(destPtr + w + 12, _min_3);
}
for (; w + 7 < width; w += 8) {
// 加载数据
__m128 _srcPtr_0 = _mm_loadu_ps(srcPtr + w);
__m128 _srcPtr_1 = _mm_loadu_ps(srcPtr + w + 4);
__m128 _prevPtr_0 = _mm_loadu_ps(prevPtr + w);
__m128 _prevPtr_1 = _mm_loadu_ps(prevPtr + w + 4);
// 计算最小值
__m128 _min_0 = _mm_min_ps(_srcPtr_0, _prevPtr_0);
__m128 _min_1 = _mm_min_ps(_srcPtr_1, _prevPtr_1);
// 存储结果
_mm_storeu_ps(destPtr + w, _min_0);
_mm_storeu_ps(destPtr + w + 4, _min_1);
}
for (; w + 3 < width; w += 4) {
// 加载数据
__m128 _srcPtr = _mm_loadu_ps(srcPtr + w);
__m128 _prevPtr = _mm_loadu_ps(prevPtr + w);
// 计算最小值
__m128 _min = _mm_min_ps(_srcPtr, _prevPtr);
// 存储结果
_mm_storeu_ps(destPtr + w, _min);
}
// 标量处理剩余部分(使用数组索引保持一致性)
for (; w < width; w++) {
destPtr[w] = std::min(srcPtr[w], prevPtr[w]);
}
#else
for (; w < width; w++) {
destPtr[w] = std::min(srcPtr[w], prevPtr[w]);
}
#endif
}
// 初始化H数组(修正复制范围)
memcpy(H + start_h * width, G + (end_h - 1) * width, width * sizeof(float));
memcpy(H + (end_h - 1) * width, src + (end_h - 1) * width, width * sizeof(float));
// 反向计算H(从下到上)
for (int h = end_h - 2; h > start_h; h--) {
float* srcPtr = src + h * width;
float* destPtr = H + h * width;
float* nextPtr = H + (h + 1) * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
// 加载数据
__m128 _srcPtr_0 = _mm_loadu_ps(srcPtr + w);
__m128 _srcPtr_1 = _mm_loadu_ps(srcPtr + w + 4);
__m128 _srcPtr_2 = _mm_loadu_ps(srcPtr + w + 8);
__m128 _srcPtr_3 = _mm_loadu_ps(srcPtr + w + 12);
__m128 _nextPtr_0 = _mm_loadu_ps(nextPtr + w);
__m128 _nextPtr_1 = _mm_loadu_ps(nextPtr + w + 4);
__m128 _nextPtr_2 = _mm_loadu_ps(nextPtr + w + 8);
__m128 _nextPtr_3 = _mm_loadu_ps(nextPtr + w + 12);
// 计算最小值
__m128 _min_0 = _mm_min_ps(_srcPtr_0, _nextPtr_0);
__m128 _min_1 = _mm_min_ps(_srcPtr_1, _nextPtr_1);
__m128 _min_2 = _mm_min_ps(_srcPtr_2, _nextPtr_2);
__m128 _min_3 = _mm_min_ps(_srcPtr_3, _nextPtr_3);
// 存储结果
_mm_storeu_ps(destPtr + w, _min_0);
_mm_storeu_ps(destPtr + w + 4, _min_1);
_mm_storeu_ps(destPtr + w + 8, _min_2);
_mm_storeu_ps(destPtr + w + 12, _min_3);
}
for (; w + 7 < width; w += 8) {
// 加载数据
__m128 _srcPtr_0 = _mm_loadu_ps(srcPtr + w);
__m128 _srcPtr_1 = _mm_loadu_ps(srcPtr + w + 4);
__m128 _nextPtr_0 = _mm_loadu_ps(nextPtr + w);
__m128 _nextPtr_1 = _mm_loadu_ps(nextPtr + w + 4);
// 计算最小值
__m128 _min_0 = _mm_min_ps(_srcPtr_0, _nextPtr_0);
__m128 _min_1 = _mm_min_ps(_srcPtr_1, _nextPtr_1);
// 存储结果
_mm_storeu_ps(destPtr + w, _min_0);
_mm_storeu_ps(destPtr + w + 4, _min_1);
}
for (; w + 3 < width; w += 4) {
// 加载数据
__m128 _srcPtr = _mm_loadu_ps(srcPtr + w);
__m128 _nextPtr = _mm_loadu_ps(nextPtr + w);
// 计算最小值
__m128 _min = _mm_min_ps(_srcPtr, _nextPtr);
// 存储结果
_mm_storeu_ps(destPtr + w, _min);
}
// 标量处理剩余部分
for (; w < width; w++) {
destPtr[w] = std::min(srcPtr[w], nextPtr[w]);
}
#else
for (; w < width; w++) {
destPtr[w] = std::min(srcPtr[w], nextPtr[w]);
}
#endif
}
}
// 边界处理(顶部区域)- 修正内存访问
for (int h = 0; h < std::min(radius, height); h++) {
int ref_h = std::min(h + radius, height - 1);
float* GPtr = G + ref_h * width;
float* destPtr = dest + h * width;
// 使用memcpy确保正确复制整行
memcpy(destPtr, GPtr, width * sizeof(float));
}
// 中间区域处理 - 修正边界计算
int h_mid_start = std::min(radius, height);
int h_mid_end = std::min(block_vert_num * mask_size - radius, height);
for (int h = h_mid_start; h < h_mid_end; h++) {
int ref_g = std::min(h + radius, height - 1);
float* GPtr = G + ref_g * width;
float* HPtr = H + (h - radius) * width;
float* destPtr = dest + h * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
// 加载数据
__m128 _GPtr_0 = _mm_loadu_ps(GPtr + w);
__m128 _GPtr_1 = _mm_loadu_ps(GPtr + w + 4);
__m128 _GPtr_2 = _mm_loadu_ps(GPtr + w + 8);
__m128 _GPtr_3 = _mm_loadu_ps(GPtr + w + 12);
__m128 _HPtr_0 = _mm_loadu_ps(HPtr + w);
__m128 _HPtr_1 = _mm_loadu_ps(HPtr + w + 4);
__m128 _HPtr_2 = _mm_loadu_ps(HPtr + w + 8);
__m128 _HPtr_3 = _mm_loadu_ps(HPtr + w + 12);
// 计算最小值
__m128 _min_0 = _mm_min_ps(_GPtr_0, _HPtr_0);
__m128 _min_1 = _mm_min_ps(_GPtr_1, _HPtr_1);
__m128 _min_2 = _mm_min_ps(_GPtr_2, _HPtr_2);
__m128 _min_3 = _mm_min_ps(_GPtr_3, _HPtr_3);
// 存储结果
_mm_storeu_ps(destPtr + w, _min_0);
_mm_storeu_ps(destPtr + w + 4, _min_1);
_mm_storeu_ps(destPtr + w + 8, _min_2);
_mm_storeu_ps(destPtr + w + 12, _min_3);
}
for (; w + 7 < width; w += 8) {
// 加载数据
__m128 _GPtr_0 = _mm_loadu_ps(GPtr + w);
__m128 _GPtr_1 = _mm_loadu_ps(GPtr + w + 4);
__m128 _HPtr_0 = _mm_loadu_ps(HPtr + w);
__m128 _HPtr_1 = _mm_loadu_ps(HPtr + w + 4);
// 计算最小值
__m128 _min_0 = _mm_min_ps(_GPtr_0, _HPtr_0);
__m128 _min_1 = _mm_min_ps(_GPtr_1, _HPtr_1);
// 存储结果
_mm_storeu_ps(destPtr + w, _min_0);
_mm_storeu_ps(destPtr + w + 4, _min_1);
}
for (; w + 3 < width; w += 4) {
// 加载数据
__m128 _GPtr = _mm_loadu_ps(GPtr + w);
__m128 _HPtr = _mm_loadu_ps(HPtr + w);
// 计算最小值
__m128 _min = _mm_min_ps(_GPtr, _HPtr);
// 存储结果
_mm_storeu_ps(destPtr + w, _min);
}
// 标量处理剩余部分
for (; w < width; w++) {
destPtr[w] = std::min(GPtr[w], HPtr[w]);
}
#else
for (; w < width; w++) {
destPtr[w] = std::min(GPtr[w], HPtr[w]);
}
#endif
}
// 底部边界处理 - 修正边界计算和内存访问
int h_bot_start = std::max(std::min(block_vert_num * mask_size - radius, height), 0);
for (int h = h_bot_start; h < height; h++) {
int ref_h = std::max(h - radius, 0);
float* HPtr = H + ref_h * width;
float* destPtr = dest + h * width;
// 使用memcpy确保正确复制整行
memcpy(destPtr, HPtr, width * sizeof(float));
}
// 释放内存
free(G);
free(H);
}
/// <summary>
/// 浮点型最小值滤波函数
/// </summary>
/// <param name="src"></param> 输入图像数据
/// <param name="dest"></param> 输出图像数据
/// <param name="width"></param> 输入图像的宽
/// <param name="height"></param> 输入图像的高
/// <param name="mask_size"></param> 滤波窗口的尺寸 通常为奇数
void min_filter(float* src, float* dest, int width, int height, int mask_size) {
/* ensure the mask_size be odd number greater than 3 */
if (mask_size < 3 || mask_size % 2 == 0) {
printf("Invalid mask size!");
return;
}
// 第一步:垂直方向处理
float* temp_1 = (float*)malloc(width * height * sizeof(float));
min_filter_func(src, temp_1, width, height, mask_size);
// 第二步:转置图像
float* transposed = (float*)malloc(width * height * sizeof(float));
transpose(temp_1, transposed, width, height);
// 第三步:转置后再次垂直滤波(等效水平方向)
float* temp_2 = (float*)malloc(width * height * sizeof(float));
min_filter_func(transposed, temp_2, height, width, mask_size);
// 第四步:转置回原方向
transpose(temp_2, dest, height, width);
// 释放中间内存
free(temp_1);
free(transposed);
free(temp_2);
}
/// <summary>
/// 浮点型最大值滤波垂直方向核心函数
/// 算法参考论文 https://www.cnblogs.com/Imageshop/p/7018510.html
/// </summary>
/// <param name="src"></param> 输入图像数据
/// <param name="dest"></param> 输出图像数据
/// <param name="width"></param> 输入图像的宽
/// <param name="height"></param> 输入图像的高
/// <param name="mask_size"></param> 滤波窗口的尺寸 通常为奇数
void max_filter_func(float* src, float* dest, int width, int height, int mask_size) {
/* ensure the mask_size be odd number greater than 3 */
if (mask_size < 3 || mask_size % 2 == 0) {
printf("Invalid mask size!");
return;
}
int radius = (mask_size - 1) / 2;
int block_vert_num = ((height % mask_size) == 0 ? height / mask_size : height / mask_size + 1);
// 分配临时内存(使用calloc初始化)
float* G = (float*)calloc(height * width, sizeof(float));
float* H = (float*)calloc(height * width, sizeof(float));
if (G == NULL || H == NULL) {
if (G) free(G);
if (H) free(H);
return;
}
// 垂直分块处理
for (int block_idx = 0; block_idx < block_vert_num; block_idx++) {
int start_h = block_idx * mask_size;
int end_h = std::min(start_h + mask_size, height);
// 初始化G的首行(使用memcpy确保正确复制)
memcpy(G + start_h * width, src + start_h * width, width * sizeof(float));
// 正向计算G(从上到下)
for (int h = start_h + 1; h < end_h; h++) {
float* srcPtr = src + h * width;
float* destPtr = G + h * width;
float* prevPtr = G + (h - 1) * width;
int w = 0;
#ifdef __SIMD__
// SSE处理16个浮点数(4组SSE寄存器)
for (; w + 15 < width; w += 16) {
// 加载数据
__m128 _srcPtr_0 = _mm_loadu_ps(srcPtr + w);
__m128 _srcPtr_1 = _mm_loadu_ps(srcPtr + w + 4);
__m128 _srcPtr_2 = _mm_loadu_ps(srcPtr + w + 8);
__m128 _srcPtr_3 = _mm_loadu_ps(srcPtr + w + 12);
__m128 _prevPtr_0 = _mm_loadu_ps(prevPtr + w);
__m128 _prevPtr_1 = _mm_loadu_ps(prevPtr + w + 4);
__m128 _prevPtr_2 = _mm_loadu_ps(prevPtr + w + 8);
__m128 _prevPtr_3 = _mm_loadu_ps(prevPtr + w + 12);
// 计算最大值
__m128 _max_0 = _mm_max_ps(_srcPtr_0, _prevPtr_0);
__m128 _max_1 = _mm_max_ps(_srcPtr_1, _prevPtr_1);
__m128 _max_2 = _mm_max_ps(_srcPtr_2, _prevPtr_2);
__m128 _max_3 = _mm_max_ps(_srcPtr_3, _prevPtr_3);
// 存储结果
_mm_storeu_ps(destPtr + w, _max_0);
_mm_storeu_ps(destPtr + w + 4, _max_1);
_mm_storeu_ps(destPtr + w + 8, _max_2);
_mm_storeu_ps(destPtr + w + 12, _max_3);
}
for (; w + 7 < width; w += 8) {
// 加载数据
__m128 _srcPtr_0 = _mm_loadu_ps(srcPtr + w);
__m128 _srcPtr_1 = _mm_loadu_ps(srcPtr + w + 4);
__m128 _prevPtr_0 = _mm_loadu_ps(prevPtr + w);
__m128 _prevPtr_1 = _mm_loadu_ps(prevPtr + w + 4);
// 计算最大值
__m128 _max_0 = _mm_max_ps(_srcPtr_0, _prevPtr_0);
__m128 _max_1 = _mm_max_ps(_srcPtr_1, _prevPtr_1);
// 存储结果
_mm_storeu_ps(destPtr + w, _max_0);
_mm_storeu_ps(destPtr + w + 4, _max_1);
}
for (; w + 3 < width; w += 4) {
// 加载数据
__m128 _srcPtr = _mm_loadu_ps(srcPtr + w);
__m128 _prevPtr = _mm_loadu_ps(prevPtr + w);
// 计算最大值
__m128 _max = _mm_max_ps(_srcPtr, _prevPtr);
// 存储结果
_mm_storeu_ps(destPtr + w, _max);
}
// 标量处理剩余部分(使用数组索引保持一致性)
for (; w < width; w++) {
destPtr[w] = std::max(srcPtr[w], prevPtr[w]);
}
#else
for (; w < width; w++) {
destPtr[w] = std::max(srcPtr[w], prevPtr[w]);
}
#endif
}
// 初始化H数组(修正复制范围)
memcpy(H + start_h * width, G + (end_h - 1) * width, width * sizeof(float));
memcpy(H + (end_h - 1) * width, src + (end_h - 1) * width, width * sizeof(float));
// 反向计算H(从下到上)
for (int h = end_h - 2; h > start_h; h--) {
float* srcPtr = src + h * width;
float* destPtr = H + h * width;
float* nextPtr = H + (h + 1) * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
// 加载数据
__m128 _srcPtr_0 = _mm_loadu_ps(srcPtr + w);
__m128 _srcPtr_1 = _mm_loadu_ps(srcPtr + w + 4);
__m128 _srcPtr_2 = _mm_loadu_ps(srcPtr + w + 8);
__m128 _srcPtr_3 = _mm_loadu_ps(srcPtr + w + 12);
__m128 _nextPtr_0 = _mm_loadu_ps(nextPtr + w);
__m128 _nextPtr_1 = _mm_loadu_ps(nextPtr + w + 4);
__m128 _nextPtr_2 = _mm_loadu_ps(nextPtr + w + 8);
__m128 _nextPtr_3 = _mm_loadu_ps(nextPtr + w + 12);
// 计算最大值
__m128 _max_0 = _mm_max_ps(_srcPtr_0, _nextPtr_0);
__m128 _max_1 = _mm_max_ps(_srcPtr_1, _nextPtr_1);
__m128 _max_2 = _mm_max_ps(_srcPtr_2, _nextPtr_2);
__m128 _max_3 = _mm_max_ps(_srcPtr_3, _nextPtr_3);
// 存储结果
_mm_storeu_ps(destPtr + w, _max_0);
_mm_storeu_ps(destPtr + w + 4, _max_1);
_mm_storeu_ps(destPtr + w + 8, _max_2);
_mm_storeu_ps(destPtr + w + 12, _max_3);
}
for (; w + 7 < width; w += 8) {
// 加载数据
__m128 _srcPtr_0 = _mm_loadu_ps(srcPtr + w);
__m128 _srcPtr_1 = _mm_loadu_ps(srcPtr + w + 4);
__m128 _nextPtr_0 = _mm_loadu_ps(nextPtr + w);
__m128 _nextPtr_1 = _mm_loadu_ps(nextPtr + w + 4);
// 计算最大值
__m128 _max_0 = _mm_max_ps(_srcPtr_0, _nextPtr_0);
__m128 _max_1 = _mm_max_ps(_srcPtr_1, _nextPtr_1);
// 存储结果
_mm_storeu_ps(destPtr + w, _max_0);
_mm_storeu_ps(destPtr + w + 4, _max_1);
}
for (; w + 3 < width; w += 4) {
// 加载数据
__m128 _srcPtr = _mm_loadu_ps(srcPtr + w);
__m128 _nextPtr = _mm_loadu_ps(nextPtr + w);
// 计算最大值
__m128 _max = _mm_max_ps(_srcPtr, _nextPtr);
// 存储结果
_mm_storeu_ps(destPtr + w, _max);
}
// 标量处理剩余部分
for (; w < width; w++) {
destPtr[w] = std::max(srcPtr[w], nextPtr[w]);
}
#else
for (; w < width; w++) {
destPtr[w] = std::max(srcPtr[w], nextPtr[w]);
}
#endif
}
}
// 边界处理(顶部区域)- 修正内存访问
for (int h = 0; h < std::min(radius, height); h++) {
int ref_h = std::min(h + radius, height - 1);
float* GPtr = G + ref_h * width;
float* destPtr = dest + h * width;
// 使用memcpy确保正确复制整行
memcpy(destPtr, GPtr, width * sizeof(float));
}
// 中间区域处理 - 修正边界计算
int h_mid_start = std::min(radius, height);
int h_mid_end = std::min(block_vert_num * mask_size - radius, height);
for (int h = h_mid_start; h < h_mid_end; h++) {
int ref_g = std::min(h + radius, height - 1);
float* GPtr = G + ref_g * width;
float* HPtr = H + (h - radius) * width;
float* destPtr = dest + h * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
// 加载数据
__m128 _GPtr_0 = _mm_loadu_ps(GPtr + w);
__m128 _GPtr_1 = _mm_loadu_ps(GPtr + w + 4);
__m128 _GPtr_2 = _mm_loadu_ps(GPtr + w + 8);
__m128 _GPtr_3 = _mm_loadu_ps(GPtr + w + 12);
__m128 _HPtr_0 = _mm_loadu_ps(HPtr + w);
__m128 _HPtr_1 = _mm_loadu_ps(HPtr + w + 4);
__m128 _HPtr_2 = _mm_loadu_ps(HPtr + w + 8);
__m128 _HPtr_3 = _mm_loadu_ps(HPtr + w + 12);
// 计算最大值
__m128 _max_0 = _mm_max_ps(_GPtr_0, _HPtr_0);
__m128 _max_1 = _mm_max_ps(_GPtr_1, _HPtr_1);
__m128 _max_2 = _mm_max_ps(_GPtr_2, _HPtr_2);
__m128 _max_3 = _mm_max_ps(_GPtr_3, _HPtr_3);
// 存储结果
_mm_storeu_ps(destPtr + w, _max_0);
_mm_storeu_ps(destPtr + w + 4, _max_1);
_mm_storeu_ps(destPtr + w + 8, _max_2);
_mm_storeu_ps(destPtr + w + 12, _max_3);
}
for (; w + 7 < width; w += 8) {
// 加载数据
__m128 _GPtr_0 = _mm_loadu_ps(GPtr + w);
__m128 _GPtr_1 = _mm_loadu_ps(GPtr + w + 4);
__m128 _HPtr_0 = _mm_loadu_ps(HPtr + w);
__m128 _HPtr_1 = _mm_loadu_ps(HPtr + w + 4);
// 计算最大值
__m128 _max_0 = _mm_max_ps(_GPtr_0, _HPtr_0);
__m128 _max_1 = _mm_max_ps(_GPtr_1, _HPtr_1);
// 存储结果
_mm_storeu_ps(destPtr + w, _max_0);
_mm_storeu_ps(destPtr + w + 4, _max_1);
}
for (; w + 3 < width; w += 4) {
// 加载数据
__m128 _GPtr = _mm_loadu_ps(GPtr + w);
__m128 _HPtr = _mm_loadu_ps(HPtr + w);
// 计算最大值
__m128 _max = _mm_max_ps(_GPtr, _HPtr);
// 存储结果
_mm_storeu_ps(destPtr + w, _max);
}
// 标量处理剩余部分
for (; w < width; w++) {
destPtr[w] = std::max(GPtr[w], HPtr[w]);
}
#else
for (; w < width; w++) {
destPtr[w] = std::max(GPtr[w], HPtr[w]);
}
#endif
}
// 底部边界处理 - 修正边界计算和内存访问
int h_bot_start = std::max(std::min(block_vert_num * mask_size - radius, height), 0);
for (int h = h_bot_start; h < height; h++) {
int ref_h = std::max(h - radius, 0);
float* HPtr = H + ref_h * width;
float* destPtr = dest + h * width;
// 使用memcpy确保正确复制整行
memcpy(destPtr, HPtr, width * sizeof(float));
}
// 释放内存
free(G);
free(H);
}
/// <summary>
/// 浮点型最大值滤波函数
/// </summary>
/// <param name="src"></param> 输入图像数据
/// <param name="dest"></param> 输出图像数据
/// <param name="width"></param> 输入图像的宽
/// <param name="height"></param> 输入图像的高
/// <param name="mask_size"></param> 滤波窗口的尺寸 通常为奇数
void max_filter(float* src, float* dest, int width, int height, int mask_size) {
/* ensure the mask_size be odd number greater than 3 */
if (mask_size < 3 || mask_size % 2 == 0) {
printf("Invalid mask size!");
return;
}
// 第一步:垂直方向处理
float* temp_1 = (float*)malloc(width * height * sizeof(float));
max_filter_func(src, temp_1, width, height, mask_size);
// 第二步:转置图像
float* transposed = (float*)malloc(width * height * sizeof(float));
transpose(temp_1, transposed, width, height);
// 第三步:转置后再次垂直滤波(等效水平方向)
float* temp_2 = (float*)malloc(width * height * sizeof(float));
max_filter_func(transposed, temp_2, height, width, mask_size);
// 第四步:转置回原方向
transpose(temp_2, dest, height, width);
// 释放中间内存
free(temp_1);
free(transposed);
free(temp_2);
}
/// <summary>
/// 对图像做固定窗口尺寸的盒子滤波
/// </summary>
/// <param name="src"></param> 输入图像数据
/// <param name="dest"></param> 输出滤波结果
/// <param name="width"></param> 图像的宽
/// <param name="height"></param> 图像的高
/// <param name="mask_size"></param> 盒子滤波窗口尺寸
void box_filter(float* src, float* dest, int width, int height, int mask_size)
{
/* ensure the mask_size be odd number greater than 3 */
if (mask_size < 3 || mask_size % 2 == 0) {
printf("Invalid mask size!");
return;
}
int radius = (mask_size - 1) / 2;
float InvertAmount = 1.0f / (mask_size * mask_size);
std::vector<float> cache(width * height);
std::vector<float> colSum(width);
float* cachePtr = &(cache[0]);
// sum horizonal
for (int h = 0; h < height; h++) {
//int shift = h * width;
// 每一行第一个像素初始化为:左侧半径相同值求和 + 右侧半径像素求和
float tmp = (radius + 1) * src[h * width + 0];
for (int w = 0; w < radius; w++) {
tmp += src[h * width + w];
}
// 处理左侧radius个像素的边界
for (int w = 0; w <= radius; w++) {
tmp += src[h * width + w + radius]; // 新加的一个像素
tmp -= src[h * width + 0]; // 减去的左边像素,这里是左侧边界像素值
cachePtr[h * width + w] = tmp;
}
int start = radius + 1;
int end = width - 1 - radius;
for (int w = start; w <= end; w++) {
tmp += src[h * width + w + radius];
tmp -= src[h * width + w - radius - 1];
cachePtr[h * width + w] = tmp;
}
// 处理右侧radius个像素的边界
start = width - radius;
for (int w = start; w < width; w++) {
tmp += src[h * width + width - 1]; // 加上最右边的新元素,此处为图像最右侧边界的值
tmp -= src[h * width + w - radius - 1]; // 减去最左侧旧的值
cachePtr[h * width + w] = tmp;
}
}
// 列指针数值初始化
float* colSumPtr = &(colSum[0]);
// 考虑向上的边界,以radius相同的上边界值代替
for (int indexW = 0; indexW < width; indexW++) {
colSumPtr[indexW] = (radius + 1) * cachePtr[0 + indexW]; // h = 0 第一行,第indexW列
}
// 列方向向下相加radius个像素值
for (int h = 0; h < radius; h++) {
float* tmpColSumPtr = colSumPtr;
float* tmpCachePtr = cachePtr + h * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
__m128 _colSum_0 = _mm_loadu_ps(tmpColSumPtr);
__m128 _colSum_1 = _mm_loadu_ps(tmpColSumPtr + 4);
__m128 _colSum_2 = _mm_loadu_ps(tmpColSumPtr + 8);
__m128 _colSum_3 = _mm_loadu_ps(tmpColSumPtr + 12);
__m128 _cache_0 = _mm_loadu_ps(tmpCachePtr);
__m128 _cache_1 = _mm_loadu_ps(tmpCachePtr + 4);
__m128 _cache_2 = _mm_loadu_ps(tmpCachePtr + 8);
__m128 _cache_3 = _mm_loadu_ps(tmpCachePtr + 12);
__m128 _addTmp_0 = _mm_add_ps(_colSum_0, _cache_0);
__m128 _addTmp_1 = _mm_add_ps(_colSum_1, _cache_1);
__m128 _addTmp_2 = _mm_add_ps(_colSum_2, _cache_2);
__m128 _addTmp_3 = _mm_add_ps(_colSum_3, _cache_3);
_mm_store_ps(tmpColSumPtr, _addTmp_0);
_mm_store_ps(tmpColSumPtr + 4, _addTmp_1);
_mm_store_ps(tmpColSumPtr + 8, _addTmp_2);
_mm_store_ps(tmpColSumPtr + 12, _addTmp_3);
tmpColSumPtr += 16; tmpCachePtr += 16;
}
for (; w + 7 < width; w += 8) {
__m128 _colSum_0 = _mm_loadu_ps(tmpColSumPtr);
__m128 _colSum_1 = _mm_loadu_ps(tmpColSumPtr + 4);
__m128 _cache_0 = _mm_loadu_ps(tmpCachePtr);
__m128 _cache_1 = _mm_loadu_ps(tmpCachePtr + 4);
__m128 _addTmp_0 = _mm_add_ps(_colSum_0, _cache_0);
__m128 _addTmp_1 = _mm_add_ps(_colSum_1, _cache_1);
_mm_store_ps(tmpColSumPtr, _addTmp_0);
_mm_store_ps(tmpColSumPtr + 4, _addTmp_1);
tmpColSumPtr += 8; tmpCachePtr += 8;
}
for (; w + 3 < width; w += 4) {
__m128 _colSum = _mm_loadu_ps(tmpColSumPtr);
__m128 _cache = _mm_loadu_ps(tmpCachePtr);
__m128 _addTmp = _mm_add_ps(_colSum, _cache);
_mm_store_ps(tmpColSumPtr, _addTmp);
tmpColSumPtr += 4; tmpCachePtr += 4;
}
for (; w < width; w++) {
*tmpColSumPtr += *tmpCachePtr;
tmpColSumPtr++;
tmpCachePtr++;
}
#else
for (; w < width; w++) {
*tmpColSumPtr += *tmpCachePtr;
tmpColSumPtr++;
tmpCachePtr++;
}
#endif
}
// sum vertical
// 处理上面radius个像素边界
for (int h = 0; h <= radius; h++) {
float* addPtr = cachePtr + (h + radius) * width;
float* subPtr = cachePtr + 0 * width; // 最上面的像素以边界值代替
float* outPtr = dest + h * width;
float* tmpAddPtr = addPtr; float* tmpSubPtr = subPtr;
float* tmpColSumPtr = colSumPtr; float* tmpOutPtr = outPtr;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
__m128 _colSum_0 = _mm_loadu_ps(tmpColSumPtr);
__m128 _colSum_1 = _mm_loadu_ps(tmpColSumPtr + 4);
__m128 _colSum_2 = _mm_loadu_ps(tmpColSumPtr + 8);
__m128 _colSum_3 = _mm_loadu_ps(tmpColSumPtr + 12);
__m128 _tmp_0 = _mm_add_ps(_colSum_0, _mm_loadu_ps(tmpAddPtr));
_tmp_0 = _mm_sub_ps(_tmp_0, _mm_loadu_ps(tmpSubPtr));
__m128 _tmp_out_0 = _mm_mul_ps(_tmp_0, _mm_set1_ps(InvertAmount));
__m128 _tmp_1 = _mm_add_ps(_colSum_1, _mm_loadu_ps(tmpAddPtr + 4));
_tmp_1 = _mm_sub_ps(_tmp_1, _mm_loadu_ps(tmpSubPtr + 4));
__m128 _tmp_out_1 = _mm_mul_ps(_tmp_1, _mm_set1_ps(InvertAmount));
__m128 _tmp_2 = _mm_add_ps(_colSum_2, _mm_loadu_ps(tmpAddPtr + 8));
_tmp_2 = _mm_sub_ps(_tmp_2, _mm_loadu_ps(tmpSubPtr + 8));
__m128 _tmp_out_2 = _mm_mul_ps(_tmp_2, _mm_set1_ps(InvertAmount));
__m128 _tmp_3 = _mm_add_ps(_colSum_3, _mm_loadu_ps(tmpAddPtr + 12));
_tmp_3 = _mm_sub_ps(_tmp_3, _mm_loadu_ps(tmpSubPtr + 12));
__m128 _tmp_out_3 = _mm_mul_ps(_tmp_3, _mm_set1_ps(InvertAmount));
_mm_store_ps(tmpColSumPtr, _tmp_0);
_mm_store_ps(tmpColSumPtr + 4, _tmp_1);
_mm_store_ps(tmpColSumPtr + 8, _tmp_2);
_mm_store_ps(tmpColSumPtr + 12, _tmp_3);
_mm_store_ps(tmpOutPtr, _tmp_out_0);
_mm_store_ps(tmpOutPtr + 4, _tmp_out_1);
_mm_store_ps(tmpOutPtr + 8, _tmp_out_2);
_mm_store_ps(tmpOutPtr + 12, _tmp_out_3);
tmpAddPtr += 16; tmpSubPtr += 16;
tmpColSumPtr += 16; tmpOutPtr += 16;
}
for (; w + 7 < width; w += 8) {
__m128 _colSum_0 = _mm_loadu_ps(tmpColSumPtr);
__m128 _colSum_1 = _mm_loadu_ps(tmpColSumPtr + 4);
__m128 _tmp_0 = _mm_add_ps(_colSum_0, _mm_loadu_ps(tmpAddPtr));
_tmp_0 = _mm_sub_ps(_tmp_0, _mm_loadu_ps(tmpSubPtr));
__m128 _tmp_out_0 = _mm_mul_ps(_tmp_0, _mm_set1_ps(InvertAmount));
__m128 _tmp_1 = _mm_add_ps(_colSum_1, _mm_loadu_ps(tmpAddPtr + 4));
_tmp_1 = _mm_sub_ps(_tmp_1, _mm_loadu_ps(tmpSubPtr + 4));
__m128 _tmp_out_1 = _mm_mul_ps(_tmp_1, _mm_set1_ps(InvertAmount));
_mm_store_ps(tmpColSumPtr, _tmp_0);
_mm_store_ps(tmpColSumPtr + 4, _tmp_1);
_mm_store_ps(tmpOutPtr, _tmp_out_0);
_mm_store_ps(tmpOutPtr + 4, _tmp_out_1);
tmpAddPtr += 8; tmpSubPtr += 8;
tmpColSumPtr += 8; tmpOutPtr += 8;
}
for (; w + 3 < width; w += 4) {
__m128 _colSum = _mm_loadu_ps(tmpColSumPtr);
__m128 _tmp = _mm_add_ps(_colSum, _mm_loadu_ps(tmpAddPtr));
_tmp = _mm_sub_ps(_tmp, _mm_loadu_ps(tmpSubPtr));
__m128 _tmp_out = _mm_mul_ps(_tmp, _mm_set1_ps(InvertAmount));
_mm_store_ps(tmpColSumPtr, _tmp);
_mm_store_ps(tmpOutPtr, _tmp_out);
tmpAddPtr += 4; tmpSubPtr += 4;
tmpColSumPtr += 4; tmpOutPtr += 4;
}
for (; w < width; w++) {
*tmpColSumPtr += *tmpAddPtr;
*tmpColSumPtr -= *tmpSubPtr;
*tmpOutPtr = *tmpColSumPtr * InvertAmount;
tmpAddPtr++; tmpSubPtr++;
tmpColSumPtr++; tmpOutPtr++;
}
#else
for (; w < width; w++) {
*tmpColSumPtr += *tmpAddPtr;
*tmpColSumPtr -= *tmpSubPtr;
*tmpOutPtr = *tmpColSumPtr * InvertAmount;
tmpAddPtr++; tmpSubPtr++;
tmpColSumPtr++; tmpOutPtr++;
}
#endif
}
int start = radius + 1;
int end = height - 1 - radius;
for (int h = start; h <= end; h++) {
float* addPtr = cachePtr + (h + radius) * width;
float* subPtr = cachePtr + (h - radius - 1) * width;
float* outPtr = dest + h * width;
float* tmpAddPtr = addPtr; float* tmpSubPtr = subPtr;
float* tmpColSumPtr = colSumPtr; float* tmpOutPtr = outPtr;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
__m128 _colSum_0 = _mm_loadu_ps(tmpColSumPtr);
__m128 _colSum_1 = _mm_loadu_ps(tmpColSumPtr + 4);
__m128 _colSum_2 = _mm_loadu_ps(tmpColSumPtr + 8);
__m128 _colSum_3 = _mm_loadu_ps(tmpColSumPtr + 12);
__m128 _tmp_0 = _mm_add_ps(_colSum_0, _mm_loadu_ps(tmpAddPtr));
_tmp_0 = _mm_sub_ps(_tmp_0, _mm_loadu_ps(tmpSubPtr));
__m128 _tmp_out_0 = _mm_mul_ps(_tmp_0, _mm_set1_ps(InvertAmount));
__m128 _tmp_1 = _mm_add_ps(_colSum_1, _mm_loadu_ps(tmpAddPtr + 4));
_tmp_1 = _mm_sub_ps(_tmp_1, _mm_loadu_ps(tmpSubPtr + 4));
__m128 _tmp_out_1 = _mm_mul_ps(_tmp_1, _mm_set1_ps(InvertAmount));
__m128 _tmp_2 = _mm_add_ps(_colSum_2, _mm_loadu_ps(tmpAddPtr + 8));
_tmp_2 = _mm_sub_ps(_tmp_2, _mm_loadu_ps(tmpSubPtr + 8));
__m128 _tmp_out_2 = _mm_mul_ps(_tmp_2, _mm_set1_ps(InvertAmount));
__m128 _tmp_3 = _mm_add_ps(_colSum_3, _mm_loadu_ps(tmpAddPtr + 12));
_tmp_3 = _mm_sub_ps(_tmp_3, _mm_loadu_ps(tmpSubPtr + 12));
__m128 _tmp_out_3 = _mm_mul_ps(_tmp_3, _mm_set1_ps(InvertAmount));
_mm_store_ps(tmpColSumPtr, _tmp_0);
_mm_store_ps(tmpColSumPtr + 4, _tmp_1);
_mm_store_ps(tmpColSumPtr + 8, _tmp_2);
_mm_store_ps(tmpColSumPtr + 12, _tmp_3);
_mm_store_ps(tmpOutPtr, _tmp_out_0);
_mm_store_ps(tmpOutPtr + 4, _tmp_out_1);
_mm_store_ps(tmpOutPtr + 8, _tmp_out_2);
_mm_store_ps(tmpOutPtr + 12, _tmp_out_3);
tmpAddPtr += 16; tmpSubPtr += 16;
tmpColSumPtr += 16; tmpOutPtr += 16;
}
for (; w + 7 < width; w += 8) {
__m128 _colSum_0 = _mm_loadu_ps(tmpColSumPtr);
__m128 _colSum_1 = _mm_loadu_ps(tmpColSumPtr + 4);
__m128 _tmp_0 = _mm_add_ps(_colSum_0, _mm_loadu_ps(tmpAddPtr));
_tmp_0 = _mm_sub_ps(_tmp_0, _mm_loadu_ps(tmpSubPtr));
__m128 _tmp_out_0 = _mm_mul_ps(_tmp_0, _mm_set1_ps(InvertAmount));
__m128 _tmp_1 = _mm_add_ps(_colSum_1, _mm_loadu_ps(tmpAddPtr + 4));
_tmp_1 = _mm_sub_ps(_tmp_1, _mm_loadu_ps(tmpSubPtr + 4));
__m128 _tmp_out_1 = _mm_mul_ps(_tmp_1, _mm_set1_ps(InvertAmount));
_mm_store_ps(tmpColSumPtr, _tmp_0);
_mm_store_ps(tmpColSumPtr + 4, _tmp_1);
_mm_store_ps(tmpOutPtr, _tmp_out_0);
_mm_store_ps(tmpOutPtr + 4, _tmp_out_1);
tmpAddPtr += 8; tmpSubPtr += 8;
tmpColSumPtr += 8; tmpOutPtr += 8;
}
for (; w + 3 < width; w += 4) {
__m128 _colSum = _mm_loadu_ps(tmpColSumPtr);
__m128 _tmp = _mm_add_ps(_colSum, _mm_loadu_ps(tmpAddPtr));
_tmp = _mm_sub_ps(_tmp, _mm_loadu_ps(tmpSubPtr));
__m128 _tmp_out = _mm_mul_ps(_tmp, _mm_set1_ps(InvertAmount));
_mm_store_ps(tmpColSumPtr, _tmp);
_mm_store_ps(tmpOutPtr, _tmp_out);
tmpAddPtr += 4; tmpSubPtr += 4;
tmpColSumPtr += 4; tmpOutPtr += 4;
}
for (; w < width; w++) {
*tmpColSumPtr += *tmpAddPtr;
*tmpColSumPtr -= *tmpSubPtr;
*tmpOutPtr = *tmpColSumPtr * InvertAmount;
tmpAddPtr++; tmpSubPtr++;
tmpColSumPtr++; tmpOutPtr++;
}
#else
for (; w < width; w++) {
*tmpColSumPtr += *tmpAddPtr;
*tmpColSumPtr -= *tmpSubPtr;
*tmpOutPtr = *tmpColSumPtr * InvertAmount;
tmpAddPtr++; tmpSubPtr++;
tmpColSumPtr++; tmpOutPtr++;
}
#endif
}
// 处理下面radius个像素边界
start = height - radius;
for (int h = start; h < height; h++) {
float* addPtr = cachePtr + (height - 1) * width; // 最下面边界索引
float* subPtr = cachePtr + (h - radius - 1) * width; // 最上面旧的一行索引
float* outPtr = dest + h * width;
float* tmpAddPtr = addPtr; float* tmpSubPtr = subPtr;
float* tmpColSumPtr = colSumPtr; float* tmpOutPtr = outPtr;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
__m128 _colSum_0 = _mm_loadu_ps(tmpColSumPtr);
__m128 _colSum_1 = _mm_loadu_ps(tmpColSumPtr + 4);
__m128 _colSum_2 = _mm_loadu_ps(tmpColSumPtr + 8);
__m128 _colSum_3 = _mm_loadu_ps(tmpColSumPtr + 12);
__m128 _tmp_0 = _mm_add_ps(_colSum_0, _mm_loadu_ps(tmpAddPtr));
_tmp_0 = _mm_sub_ps(_tmp_0, _mm_loadu_ps(tmpSubPtr));
__m128 _tmp_out_0 = _mm_mul_ps(_tmp_0, _mm_set1_ps(InvertAmount));
__m128 _tmp_1 = _mm_add_ps(_colSum_1, _mm_loadu_ps(tmpAddPtr + 4));
_tmp_1 = _mm_sub_ps(_tmp_1, _mm_loadu_ps(tmpSubPtr + 4));
__m128 _tmp_out_1 = _mm_mul_ps(_tmp_1, _mm_set1_ps(InvertAmount));
__m128 _tmp_2 = _mm_add_ps(_colSum_2, _mm_loadu_ps(tmpAddPtr + 8));
_tmp_2 = _mm_sub_ps(_tmp_2, _mm_loadu_ps(tmpSubPtr + 8));
__m128 _tmp_out_2 = _mm_mul_ps(_tmp_2, _mm_set1_ps(InvertAmount));
__m128 _tmp_3 = _mm_add_ps(_colSum_3, _mm_loadu_ps(tmpAddPtr + 12));
_tmp_3 = _mm_sub_ps(_tmp_3, _mm_loadu_ps(tmpSubPtr + 12));
__m128 _tmp_out_3 = _mm_mul_ps(_tmp_3, _mm_set1_ps(InvertAmount));
_mm_store_ps(tmpColSumPtr, _tmp_0);
_mm_store_ps(tmpColSumPtr + 4, _tmp_1);
_mm_store_ps(tmpColSumPtr + 8, _tmp_2);
_mm_store_ps(tmpColSumPtr + 12, _tmp_3);
_mm_store_ps(tmpOutPtr, _tmp_out_0);
_mm_store_ps(tmpOutPtr + 4, _tmp_out_1);
_mm_store_ps(tmpOutPtr + 8, _tmp_out_2);
_mm_store_ps(tmpOutPtr + 12, _tmp_out_3);
tmpAddPtr += 16; tmpSubPtr += 16;
tmpColSumPtr += 16; tmpOutPtr += 16;
}
for (; w + 7 < width; w += 8) {
__m128 _colSum_0 = _mm_loadu_ps(tmpColSumPtr);
__m128 _colSum_1 = _mm_loadu_ps(tmpColSumPtr + 4);
__m128 _tmp_0 = _mm_add_ps(_colSum_0, _mm_loadu_ps(tmpAddPtr));
_tmp_0 = _mm_sub_ps(_tmp_0, _mm_loadu_ps(tmpSubPtr));
__m128 _tmp_out_0 = _mm_mul_ps(_tmp_0, _mm_set1_ps(InvertAmount));
__m128 _tmp_1 = _mm_add_ps(_colSum_1, _mm_loadu_ps(tmpAddPtr + 4));
_tmp_1 = _mm_sub_ps(_tmp_1, _mm_loadu_ps(tmpSubPtr + 4));
__m128 _tmp_out_1 = _mm_mul_ps(_tmp_1, _mm_set1_ps(InvertAmount));
_mm_store_ps(tmpColSumPtr, _tmp_0);
_mm_store_ps(tmpColSumPtr + 4, _tmp_1);
_mm_store_ps(tmpOutPtr, _tmp_out_0);
_mm_store_ps(tmpOutPtr + 4, _tmp_out_1);
tmpAddPtr += 8; tmpSubPtr += 8;
tmpColSumPtr += 8; tmpOutPtr += 8;
}
for (; w + 3 < width; w += 4) {
__m128 _colSum = _mm_loadu_ps(tmpColSumPtr);
__m128 _tmp = _mm_add_ps(_colSum, _mm_loadu_ps(tmpAddPtr));
_tmp = _mm_sub_ps(_tmp, _mm_loadu_ps(tmpSubPtr));
__m128 _tmp_out = _mm_mul_ps(_tmp, _mm_set1_ps(InvertAmount));
_mm_store_ps(tmpColSumPtr, _tmp);
_mm_store_ps(tmpOutPtr, _tmp_out);
tmpAddPtr += 4; tmpSubPtr += 4;
tmpColSumPtr += 4; tmpOutPtr += 4;
}
for (; w < width; w++) {
*tmpColSumPtr += *tmpAddPtr;
*tmpColSumPtr -= *tmpSubPtr;
*tmpOutPtr = *tmpColSumPtr * InvertAmount;
tmpAddPtr++; tmpSubPtr++;
tmpColSumPtr++; tmpOutPtr++;
}
#else
for (; w < width; w++) {
*tmpColSumPtr += *tmpAddPtr;
*tmpColSumPtr -= *tmpSubPtr;
*tmpOutPtr = *tmpColSumPtr * InvertAmount;
tmpAddPtr++; tmpSubPtr++;
tmpColSumPtr++; tmpOutPtr++;
}
#endif
}
}
/// <summary>
/// 获取图像中每一点像素三通道数值的最小值作为输出结果
/// </summary>
/// <param name="input"></param> 输入雾天三通道图像
/// <param name="output"></param> 输出三通道最小值结果图像
/// <param name="width"></param> 图像的高
/// <param name="height"></param> 图像的宽
/// <param name="stride"></param> 三通道图像像素步长,通常为 width * 3
void dark_function(unsigned char* input, unsigned char* output, int width, int height, int stride)
{
int in_channels = stride / width;
if (in_channels != 3) {
printf("Error: Invalid channel number (expected 3, got %d)\n", in_channels);
return;
}
for (int h = 0; h < height; h++)
{
unsigned char* inputPtr = input + h * stride;
unsigned char* outputPtr = output + h * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16)
{
__m128i _src_0, _src_1, _src_2, _blue, _green, _red;
_src_0 = _mm_loadu_si128((__m128i*)(inputPtr));
_src_1 = _mm_loadu_si128((__m128i*)(inputPtr + 16));
_src_2 = _mm_loadu_si128((__m128i*)(inputPtr + 32));
// 以下操作把16个连续像素的像素顺序由 B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R
// 更改为适合于SIMD指令处理的连续序列 B B B B B B B B B B B B B B B B G G G G G G G G G G G G G G G G R R R R R R R R R R R R R R R R
_blue = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_blue = _mm_or_si128(_blue, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14, -1, -1, -1, -1, -1)));
_blue = _mm_or_si128(_blue, _mm_shuffle_epi8(_src_2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1, 4, 7, 10, 13)));
_green = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_green = _mm_or_si128(_green, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1)));
_green = _mm_or_si128(_green, _mm_shuffle_epi8(_src_2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14)));
_red = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(2, 5, 8, 11, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_red = _mm_or_si128(_red, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1)));
_red = _mm_or_si128(_red, _mm_shuffle_epi8(_src_2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15)));
// 在此处一定要使用_mm_min_epu8,而不是_mm_min_epi8
__m128i _min_value = _mm_min_epu8(_blue, _green);
_min_value = _mm_min_epu8(_min_value, _red);
_mm_storeu_si128((__m128i*)(outputPtr), _min_value);
inputPtr += 48;
outputPtr += 16;
}
// 处理8个像素 (需要加载24字节)
for (; w + 7 < width; w += 8) {
// 加载24字节(8像素*3通道)
__m128i _src_0 = _mm_loadu_si128((__m128i*)(inputPtr)); // 加载前16字节(偏移0-15)
__m128i _src_1 = _mm_loadl_epi64((__m128i*)(inputPtr + 16)); // 加载后8字节(偏移16-23,低64位有效)
// -------------------------- B通道分离 --------------------------
// 从_src0提取像素0-5的B通道(偏移0,3,6,9,12,15)
__m128i _blue = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 从_src1提取像素6的B(偏移18=16+2→_src1字节2)、像素7的B(偏移21=16+5→_src1字节5)
_blue = _mm_or_si128(_blue, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, -1, -1, -1, -1, -1, -1, -1, -1)));
// -------------------------- G通道分离 --------------------------
// 从_src0提取像素0-4的G通道(偏移1,4,7,10,13)
__m128i _green = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 从_src1提取像素5-7的G通道(字节0,3,6)
_green = _mm_or_si128(_green, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 0, 3, 6, -1, -1, -1, -1, -1, -1, -1, -1)));
// -------------------------- R通道分离 --------------------------
// 从_src0提取像素0-4的R通道(偏移2,5,8,11,14)
__m128i _red = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(2, 5, 8, 11, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 从_src1提取像素5-7的R通道(字节1,4,7)
_red = _mm_or_si128(_red, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 1, 4, 7, -1, -1, -1, -1, -1, -1, -1, -1)));
// 计算三通道最小值(暗通道)
__m128i _min_value = _mm_min_epu8(_blue, _green);
_min_value = _mm_min_epu8(_min_value, _red);
// 存储低64位(8个暗通道值)
_mm_storel_epi64((__m128i*)outputPtr, _min_value);
// 指针偏移:24字节(8×3)输入,8字节输出
inputPtr += 24;
outputPtr += 8;
}
// 处理4个像素的批次
for (; w + 3 < width; w += 4) {
// 加载12字节(4像素×3通道)
__m128i _src = _mm_loadu_si128((__m128i*)inputPtr); // 实际只使用前12字节
// 提取B通道 (偏移0,3,6,9)
__m128i _blue = _mm_shuffle_epi8(_src, _mm_setr_epi8(0, 3, 6, 9, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 提取G通道 (偏移1,4,7,10)
__m128i _green = _mm_shuffle_epi8(_src, _mm_setr_epi8(1, 4, 7, 10, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 提取R通道 (偏移2,5,8,11)
__m128i _red = _mm_shuffle_epi8(_src, _mm_setr_epi8(2, 5, 8, 11, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 计算三通道最小值
__m128i _min_value = _mm_min_epu8(_blue, _green);
_min_value = _mm_min_epu8(_min_value, _red);
// 存储4个结果(取低32位)
__m128i _low = _mm_unpacklo_epi8(_min_value, _mm_setzero_si128());
_mm_store_ss((float*)outputPtr, _mm_castsi128_ps(_low));
inputPtr += 12; // 4×3通道
outputPtr += 4; // 4个输出像素
}
for (; w < width; w++)
{
int min_value = *inputPtr;
if (*(inputPtr + 1) < min_value) min_value = *(inputPtr + 1);
if (*(inputPtr + 2) < min_value) min_value = *(inputPtr + 2);
*outputPtr = (unsigned char)min_value;
inputPtr += 3;
outputPtr++;
}
#else
for (; w < width; w++)
{
int min_value = *inputPtr;
if (*(inputPtr + 1) < min_value) min_value = *(inputPtr + 1);
if (*(inputPtr + 2) < min_value) min_value = *(inputPtr + 2);
*outputPtr = (unsigned char)min_value;
inputPtr += 3;
outputPtr++;
}
#endif
}
}
/// <summary>
/// 依据雾天图像及其暗通道图像估计每一个通道的大气光值
/// </summary>
/// <param name="src_image"></param> 输入雾天图像
/// <param name="dark_channel"></param> 输入雾天图像的暗通道图像
/// <param name="width"></param> 图像的宽
/// <param name="height"></param> 图像的高
/// <param name="stride"></param> 雾天图像对应的像素步长,通常取值为 width * 3
/// <param name="A_b"></param> blue通道的大气光值
/// <param name="A_g"></param> green通道的大气光值
/// <param name="A_r"></param> red通道的大气光值
void airlight_estimation(unsigned char* src_image, unsigned char* dark_channel, int width, int height, int stride, int* A_b, int* A_g, int* A_r)
{
int in_channels = stride / width;
if (in_channels != 3) {
printf("Error: Invalid channel number (expected 3, got %d)\n", in_channels);
return;
}
// 1. 统计暗通道直方图并计算阈值(前1%最亮像素)
int histogram[256] = { 0 };
const int total_pixels = width * height;
for (int i = 0; i < total_pixels; i++) {
unsigned char val = dark_channel[i];
histogram[val]++; // 统计每个亮度值的像素数量
}
int threshold = 0; int pixel_sum = 0;
const int one_percent = (int)(total_pixels * 0.01f + 0.5f);
for (int intensity = 255; intensity >= 0; intensity--) {
pixel_sum += histogram[intensity];
// 当累计像素数超过总像素的1%时,记录当前亮度为阈值
if (pixel_sum > one_percent) {
threshold = intensity;
break;
}
}
// 2. 筛选暗通道值>=阈值的像素,累加其RGB值
int A_b_sum = 0, A_g_sum = 0, A_r_sum = 0;
int pixel_count = 0;
#ifdef __SIMD__
__m128i _sum_b_16 = _mm_setzero_si128();
__m128i _sum_g_16 = _mm_setzero_si128();
__m128i _sum_r_16 = _mm_setzero_si128();
__m128i _count_16 = _mm_setzero_si128();
__m128i _sum_b_8 = _mm_setzero_si128();
__m128i _sum_g_8 = _mm_setzero_si128();
__m128i _sum_r_8 = _mm_setzero_si128();
__m128i _count_8 = _mm_setzero_si128();
__m128i _sum_b_4 = _mm_setzero_si128();
__m128i _sum_g_4 = _mm_setzero_si128();
__m128i _sum_r_4 = _mm_setzero_si128();
__m128i _count_4 = _mm_setzero_si128();
__m128i _threshold_vec = _mm_set1_epi8((unsigned char)threshold); // 无符号处理
#endif
for (int h = 0; h < height; h++) {
unsigned char* srcPtr = src_image + h * stride; // 当前行的BGR数据
unsigned char* darkPtr = dark_channel + h * width; // 当前行的暗通道数据
int w = 0;
#ifdef __SIMD__
// SSE批量处理16像素
for (; w + 15 < width; w += 16) {
// 加载16个暗通道值(无符号字节)
__m128i _dark_vals = _mm_loadu_si128((__m128i*)(darkPtr + w));
// 计算掩码:暗通道值>=阈值(无符号比较)
__m128i _mask = _mm_cmpeq_epi8(_dark_vals, _threshold_vec); // 0xFF表示满足条件
// 加载16个像素的BGR数据(共16*3=48字节)
__m128i _src_0 = _mm_loadu_si128((__m128i*)(srcPtr));
__m128i _src_1 = _mm_loadu_si128((__m128i*)(srcPtr + 16));
__m128i _src_2 = _mm_loadu_si128((__m128i*)(srcPtr + 32));
// 分离B通道(每个像素第0字节)
__m128i _b = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_b = _mm_or_si128(_b, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14, -1, -1, -1, -1, -1)));
_b = _mm_or_si128(_b, _mm_shuffle_epi8(_src_2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1, 4, 7, 10, 13)));
// 分离G通道(每个像素第1字节)
__m128i _g = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_g = _mm_or_si128(_g, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1)));
_g = _mm_or_si128(_g, _mm_shuffle_epi8(_src_2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14)));
// 分离R通道(每个像素第2字节)
__m128i _r = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(2, 5, 8, 11, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_r = _mm_or_si128(_r, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1)));
_r = _mm_or_si128(_r, _mm_shuffle_epi8(_src_2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15)));
// 应用掩码:仅保留满足条件的像素值(0xFF & 原值 = 原值,0x00 & 原值 = 0)
__m128i _b_masked = _mm_and_si128(_b, _mask);
__m128i _g_masked = _mm_and_si128(_g, _mask);
__m128i _r_masked = _mm_and_si128(_r, _mask);
// 转换为32位整数并累加(避免溢出)
_sum_b_16 = _mm_add_epi32(_sum_b_16, _mm_cvtepu8_epi32(_b_masked)); // 无符号扩展
_sum_g_16 = _mm_add_epi32(_sum_g_16, _mm_cvtepu8_epi32(_g_masked));
_sum_r_16 = _mm_add_epi32(_sum_r_16, _mm_cvtepu8_epi32(_r_masked));
_count_16 = _mm_add_epi32(_count_16, _mm_cvtepu8_epi32(_mask)); // 计数累加(0xFF扩展为255,需修正)
// 移动指针(16像素 * 3通道 = 48字节)
srcPtr += 48;
}
// 处理8个像素
for (; w + 7 < width; w += 8) {
// 加载8个暗通道值(仅低64位有效,对应8个无符号字节)
__m128i _dark_vals = _mm_loadl_epi64((__m128i*)(darkPtr + w));
// 计算掩码:暗通道值>=阈值(无符号比较,满足条件的字节设为0xFF,否则0x00)
__m128i _mask = _mm_cmpeq_epi8(_dark_vals, _threshold_vec);
// 加载8个BGR像素的24字节数据:_src0存前16字节(偏移0-15),_src1存后8字节(偏移16-23,低64位有效)
__m128i _src_0 = _mm_loadu_si128((__m128i*)(srcPtr)); // 偏移0-15:包含B0-G5-R5(前6个像素完整,第6个像素缺R5)
__m128i _src_1 = _mm_loadl_epi64((__m128i*)(srcPtr + 16)); // 偏移16-23:包含R5-B6-G6-R6-B7-G7-R7(第6个像素补R5,第7个像素完整)
// -------------------------- B通道分离 --------------------------
// 从_src0提取B0(0)、B1(3)、B2(6)、B3(9)、B4(12)、B5(15)
__m128i _b = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 从_src1提取B6(偏移18→_src1字节2)、B7(偏移21→_src1字节5),补充到_b的第6、7个位置
_b = _mm_or_si128(_b, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, -1, -1, -1, -1, -1, -1, -1, -1)));
// -------------------------- G通道分离 --------------------------
// 从_src0提取G0(1)、G1(4)、G2(7)、G3(10)、G4(13)
__m128i _g = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 从_src1提取G5(偏移16→_src1字节0)、G6(偏移19→_src1字节3)、G7(偏移22→_src1字节6)
_g = _mm_or_si128(_g, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 0, 3, 6, -1, -1, -1, -1, -1, -1, -1, -1)));
// -------------------------- R通道分离 --------------------------
// 从_src0提取R0(2)、R1(5)、R2(8)、R3(11)、R4(14)
__m128i _r = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(2, 5, 8, 11, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 从_src1提取R5(偏移17→_src1字节1)、R6(偏移20→_src1字节4)、R7(偏移23→_src1字节7)
_r = _mm_or_si128(_r, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 1, 4, 7, -1, -1, -1, -1, -1, -1, -1, -1)));
// -------------------------- 后续逻辑(掩码应用、累加)保持不变 --------------------------
// 应用掩码:仅保留暗通道值>=阈值的像素的BGR数据
__m128i _b_masked = _mm_and_si128(_b, _mask);
__m128i _g_masked = _mm_and_si128(_g, _mask);
__m128i _r_masked = _mm_and_si128(_r, _mask);
// 无符号字节→32位整数扩展后累加(避免溢出)
_sum_b_8 = _mm_add_epi32(_sum_b_8, _mm_cvtepu8_epi32(_b_masked));
_sum_g_8 = _mm_add_epi32(_sum_g_8, _mm_cvtepu8_epi32(_g_masked));
_sum_r_8 = _mm_add_epi32(_sum_r_8, _mm_cvtepu8_epi32(_r_masked));
// 计数累加(_mask为0xFF时扩展为255,后续需除以255得到实际像素数)
_count_8 = _mm_add_epi32(_count_8, _mm_cvtepu8_epi32(_mask));
// 指针偏移:8个BGR像素 = 8*3 = 24字节
srcPtr += 24;
}
// -------------------------- 处理4个像素的批次 --------------------------
for (; w + 3 < width; w += 4) {
// 加载4个暗通道值(无符号字节,用128位加载,前4字节有效)
__m128i _dark_vals = _mm_loadu_si128((__m128i*)(darkPtr + w));
// 生成掩码:暗通道值>=阈值(保持原逻辑用_mm_cmpeq_epi8,与16/8像素一致)
__m128i _mask = _mm_cmpeq_epi8(_dark_vals, _threshold_vec); // 0xFF=有效,0x00=无效
// 加载4个BGR像素的12字节数据(4×3=12字节,128位加载,前12字节有效)
__m128i _src = _mm_loadu_si128((__m128i*)srcPtr);
// 分离B通道(每个像素第0字节:偏移0、3、6、9)
__m128i _b = _mm_shuffle_epi8(_src, _mm_setr_epi8(0, 3, 6, 9, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 分离G通道(每个像素第1字节:偏移1、4、7、10)
__m128i _g = _mm_shuffle_epi8(_src, _mm_setr_epi8(1, 4, 7, 10, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 分离R通道(每个像素第2字节:偏移2、5、8、11)
__m128i _r = _mm_shuffle_epi8(_src, _mm_setr_epi8(2, 5, 8, 11, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 7. 应用掩码:仅保留有效像素的通道值
__m128i _b_masked = _mm_and_si128(_b, _mask);
__m128i _g_masked = _mm_and_si128(_g, _mask);
__m128i _r_masked = _mm_and_si128(_r, _mask);
// 8. 无符号字节→32位整数扩展(避免累加溢出),并累加到对应向量
_sum_b_4 = _mm_add_epi32(_sum_b_4, _mm_cvtepu8_epi32(_b_masked));
_sum_g_4 = _mm_add_epi32(_sum_g_4, _mm_cvtepu8_epi32(_g_masked));
_sum_r_4 = _mm_add_epi32(_sum_r_4, _mm_cvtepu8_epi32(_r_masked));
_count_4 = _mm_add_epi32(_count_4, _mm_cvtepu8_epi32(_mask)); // 计数累加(后续需修正)
// 9. 指针偏移:4个BGR像素 = 4×3 = 12字节
srcPtr += 12;
}
// 处理剩余像素(不足16个且不足8个)
for (; w < width; w++) {
if (darkPtr[w] >= threshold) { // 筛选有效像素
// 累加BGR值
A_b_sum += srcPtr[0]; // B通道
A_g_sum += srcPtr[1]; // G通道
A_r_sum += srcPtr[2]; // R通道
pixel_count++;
}
srcPtr += 3; // 移动到下一个像素(BGR各1字节)
}
#else
for (; w < width; w++) {
if (darkPtr[w] >= threshold) { // 筛选有效像素
// 累加BGR值
A_b_sum += srcPtr[0]; // B通道
A_g_sum += srcPtr[1]; // G通道
A_r_sum += srcPtr[2]; // R通道
pixel_count++;
}
srcPtr += 3; // 移动到下一个像素(BGR各1字节)
}
#endif
}
#ifdef __SIMD__
// 提取SSE累加结果并修正计数(关键修复:mask为0xFF时扩展后是255,需除以255得到实际计数)
auto sum_sse_vec = [](__m128i cnt) {
int arr[4];
// 将128位向量存储到4个int的数组
_mm_store_si128((__m128i*)arr, cnt);
return (arr[0] + arr[1] + arr[2] + arr[3]);
};
// 累加通道总和
A_b_sum += sum_sse_vec(_sum_b_16) + sum_sse_vec(_sum_b_8) + sum_sse_vec(_sum_b_4);
A_g_sum += sum_sse_vec(_sum_g_16) + sum_sse_vec(_sum_g_8) + sum_sse_vec(_sum_g_4);
A_r_sum += sum_sse_vec(_sum_r_16) + sum_sse_vec(_sum_r_8) + sum_sse_vec(_sum_r_4);
// 修正计数(掩码0xFF扩展后为255,需除以255还原实际像素数)
int total_cnt_sse = sum_sse_vec(_count_16) + sum_sse_vec(_count_8) + sum_sse_vec(_count_4);
pixel_count += (int)((float)total_cnt_sse / 255.0f + 0.5f);
#endif
// 3. 计算最终大气光值(确保像素数不为0)
if (pixel_count <= 0) {
printf("Error: No valid pixels found (pixel_count=%d)\n", pixel_count);
printf("Warning: No valid pixels found, use default airlight: 255.\n");
*A_b = *A_g = *A_r = 255;
return;
}
*A_b = A_b_sum / pixel_count;
*A_g = A_g_sum / pixel_count;
*A_r = A_r_sum / pixel_count;
}
/// <summary>
/// 处理天空区域,抑制复原结果中出现的光晕
/// </summary>
/// <param name="I"></param> 输入雾天图像
/// <param name="Ic"></param> 依据大气光值归一化雾天图像,取三通道最小值获得Ic图像
/// <param name="Ic_refine"></param> 对Ic图像做天空区域修正,得到Ic_refine
/// <param name="width"></param> 图像的宽
/// <param name="height"></param> 图像的高
/// <param name="stride"></param> 雾天图像像素的步长,通常取值为 width * 3
/// <param name="A_b"></param> blue通道的大气光值
/// <param name="A_g"></param> green通道的大气光值
/// <param name="A_r"></param> red通道的大气光值
void sky_handling(unsigned char* I, float* Ic, float* Ic_refine, int width, int height, int stride, int A_b, int A_g, int A_r)
{
float airlight_b = A_b / 255.0f; float airlight_g = A_g / 255.0f; float airlight_r = A_r / 255.0f;
float omega_1 = 10.0f; float omega_2 = 0.2f; // 对应论文中的经验值
int I_channels = stride / width;
if (I_channels != 3) {
printf("Error: Invalid channel number (expected 3, got %d)\n", I_channels);
return;
}
else {
for (int h = 0; h < height; h++)
{
unsigned char* I_Ptr = I + h * stride;
float* Ic_Ptr = Ic + h * width;
float* Ic_refine_Ptr = Ic_refine + h * width;
float b, g, r;
float sum = 0.0f, S = 0.0f; float min = 1.0f;
int w = 0;
#ifdef __SIMD__
__m128i _zero = _mm_setzero_si128();
__m128 _value_255 = _mm_set1_ps(255.0f);
__m128 _plus_1 = _mm_set1_ps(1.0f);
__m128 _minus_1 = _mm_set1_ps(-1.0f);
__m128 _airlight_b = _mm_set1_ps(airlight_b);
__m128 _airlight_g = _mm_set1_ps(airlight_g);
__m128 _airlight_r = _mm_set1_ps(airlight_r);
__m128 _omega_1 = _mm_set1_ps(omega_1);
__m128 _omega_2 = _mm_set1_ps(omega_2);
for (; w + 15 < width; w += 16)
{
__m128i _src_0 = _mm_loadu_si128((__m128i*)(I_Ptr));
__m128i _src_1 = _mm_loadu_si128((__m128i*)(I_Ptr + 16));
__m128i _src_2 = _mm_loadu_si128((__m128i*)(I_Ptr + 32));
// 以下操作把16个连续像素的像素顺序由 B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R
// 更改为适合于SIMD指令处理的连续序列 B B B B B B B B B B B B B B B B G G G G G G G G G G G G G G G G R R R R R R R R R R R R R R R R
__m128i _blue = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_blue = _mm_or_si128(_blue, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14, -1, -1, -1, -1, -1)));
_blue = _mm_or_si128(_blue, _mm_shuffle_epi8(_src_2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1, 4, 7, 10, 13)));
__m128i _green = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_green = _mm_or_si128(_green, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1)));
_green = _mm_or_si128(_green, _mm_shuffle_epi8(_src_2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14)));
__m128i _red = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(2, 5, 8, 11, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_red = _mm_or_si128(_red, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1)));
_red = _mm_or_si128(_red, _mm_shuffle_epi8(_src_2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15)));
__m128i _blue_0 = _mm_unpacklo_epi8(_mm_unpacklo_epi64(_blue, _zero), _zero); // 获取低64位8个bit 并将有效bit扩展成16位 16 * 8
__m128i _blue_1 = _mm_unpacklo_epi8(_mm_unpackhi_epi64(_blue, _zero), _zero); // 获取高64位8个bit 并将有效bit扩展成16位 16 * 8
__m128 _blue_0_0 = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_blue_0, _zero));
__m128 _blue_0_1 = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_blue_0, _zero));
__m128 _blue_1_0 = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_blue_1, _zero));
__m128 _blue_1_1 = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_blue_1, _zero));
__m128 _b_0_0 = _mm_div_ps(_blue_0_0, _value_255);
__m128 _b_0_1 = _mm_div_ps(_blue_0_1, _value_255);
__m128 _b_1_0 = _mm_div_ps(_blue_1_0, _value_255);
__m128 _b_1_1 = _mm_div_ps(_blue_1_1, _value_255);
__m128i _green_0 = _mm_unpacklo_epi8(_mm_unpacklo_epi64(_green, _zero), _zero);
__m128i _green_1 = _mm_unpacklo_epi8(_mm_unpackhi_epi64(_green, _zero), _zero);
__m128 _green_0_0 = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_green_0, _zero));
__m128 _green_0_1 = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_green_0, _zero));
__m128 _green_1_0 = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_green_1, _zero));
__m128 _green_1_1 = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_green_1, _zero));
__m128 _g_0_0 = _mm_div_ps(_green_0_0, _value_255);
__m128 _g_0_1 = _mm_div_ps(_green_0_1, _value_255);
__m128 _g_1_0 = _mm_div_ps(_green_1_0, _value_255);
__m128 _g_1_1 = _mm_div_ps(_green_1_1, _value_255);
__m128i _red_0 = _mm_unpacklo_epi8(_mm_unpacklo_epi64(_red, _zero), _zero);
__m128i _red_1 = _mm_unpacklo_epi8(_mm_unpackhi_epi64(_red, _zero), _zero);
__m128 _red_0_0 = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_red_0, _zero));
__m128 _red_0_1 = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_red_0, _zero));
__m128 _red_1_0 = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_red_1, _zero));
__m128 _red_1_1 = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_red_1, _zero));
__m128 _r_0_0 = _mm_div_ps(_red_0_0, _value_255);
__m128 _r_0_1 = _mm_div_ps(_red_0_1, _value_255);
__m128 _r_1_0 = _mm_div_ps(_red_1_0, _value_255);
__m128 _r_1_1 = _mm_div_ps(_red_1_1, _value_255);
__m128 _sum_0_0 = _mm_add_ps(_mm_mul_ps(_mm_sub_ps(_b_0_0, _airlight_b), _mm_sub_ps(_b_0_0, _airlight_b)), \
_mm_mul_ps(_mm_sub_ps(_g_0_0, _airlight_g), _mm_sub_ps(_g_0_0, _airlight_g)));
_sum_0_0 = _mm_add_ps(_sum_0_0, _mm_mul_ps(_mm_sub_ps(_r_0_0, _airlight_r), _mm_sub_ps(_r_0_0, _airlight_r)));
__m128 _sum_0_1 = _mm_add_ps(_mm_mul_ps(_mm_sub_ps(_b_0_1, _airlight_b), _mm_sub_ps(_b_0_1, _airlight_b)), \
_mm_mul_ps(_mm_sub_ps(_g_0_1, _airlight_g), _mm_sub_ps(_g_0_1, _airlight_g)));
_sum_0_1 = _mm_add_ps(_sum_0_1, _mm_mul_ps(_mm_sub_ps(_r_0_1, _airlight_r), _mm_sub_ps(_r_0_1, _airlight_r)));
__m128 _sum_1_0 = _mm_add_ps(_mm_mul_ps(_mm_sub_ps(_b_1_0, _airlight_b), _mm_sub_ps(_b_1_0, _airlight_b)), \
_mm_mul_ps(_mm_sub_ps(_g_1_0, _airlight_g), _mm_sub_ps(_g_1_0, _airlight_g)));
_sum_1_0 = _mm_add_ps(_sum_1_0, _mm_mul_ps(_mm_sub_ps(_r_1_0, _airlight_r), _mm_sub_ps(_r_1_0, _airlight_r)));
__m128 _sum_1_1 = _mm_add_ps(_mm_mul_ps(_mm_sub_ps(_b_1_1, _airlight_b), _mm_sub_ps(_b_1_1, _airlight_b)), \
_mm_mul_ps(_mm_sub_ps(_g_1_1, _airlight_g), _mm_sub_ps(_g_1_1, _airlight_g)));
_sum_1_1 = _mm_add_ps(_sum_1_1, _mm_mul_ps(_mm_sub_ps(_r_1_1, _airlight_r), _mm_sub_ps(_r_1_1, _airlight_r)));
__m128 _minus_omega_1 = _mm_mul_ps(_minus_1, _omega_1);
__m128 _S_0_0 = _mm_exp_ps_(_mm_mul_ps(_minus_omega_1, _sum_0_0));
__m128 _S_0_1 = _mm_exp_ps_(_mm_mul_ps(_minus_omega_1, _sum_0_1));
__m128 _S_1_0 = _mm_exp_ps_(_mm_mul_ps(_minus_omega_1, _sum_1_0));
__m128 _S_1_1 = _mm_exp_ps_(_mm_mul_ps(_minus_omega_1, _sum_1_1));
__m128 _min_0_0 = _mm_min_ps(_mm_div_ps(_b_0_0, _airlight_b), _mm_div_ps(_g_0_0, _airlight_g));
_min_0_0 = _mm_min_ps(_min_0_0, _mm_div_ps(_r_0_0, _airlight_r));
__m128 _min_0_1 = _mm_min_ps(_mm_div_ps(_b_0_1, _airlight_b), _mm_div_ps(_g_0_1, _airlight_g));
_min_0_1 = _mm_min_ps(_min_0_1, _mm_div_ps(_r_0_1, _airlight_r));
__m128 _min_1_0 = _mm_min_ps(_mm_div_ps(_b_1_0, _airlight_b), _mm_div_ps(_g_1_0, _airlight_g));
_min_1_0 = _mm_min_ps(_min_1_0, _mm_div_ps(_r_1_0, _airlight_r));
__m128 _min_1_1 = _mm_min_ps(_mm_div_ps(_b_1_1, _airlight_b), _mm_div_ps(_g_1_1, _airlight_g));
_min_1_1 = _mm_min_ps(_min_1_1, _mm_div_ps(_r_1_1, _airlight_r));
_mm_store_ps(Ic_Ptr, _min_0_0);
_mm_store_ps(Ic_Ptr + 4, _min_0_1);
_mm_store_ps(Ic_Ptr + 8, _min_1_0);
_mm_store_ps(Ic_Ptr + 12, _min_1_1);
_mm_store_ps(Ic_refine_Ptr, _mm_mul_ps(_min_0_0, _mm_sub_ps(_plus_1, _mm_mul_ps(_omega_2, _S_0_0))));
_mm_store_ps(Ic_refine_Ptr + 4, _mm_mul_ps(_min_0_1, _mm_sub_ps(_plus_1, _mm_mul_ps(_omega_2, _S_0_1))));
_mm_store_ps(Ic_refine_Ptr + 8, _mm_mul_ps(_min_1_0, _mm_sub_ps(_plus_1, _mm_mul_ps(_omega_2, _S_1_0))));
_mm_store_ps(Ic_refine_Ptr + 12, _mm_mul_ps(_min_1_1, _mm_sub_ps(_plus_1, _mm_mul_ps(_omega_2, _S_1_1))));
I_Ptr += 48;
Ic_Ptr += 16; Ic_refine_Ptr += 16;
}
// 处理8个像素
for (; w + 7 < width; w += 8) {
// 加载8个BGR像素的24字节数据:_src0存前16字节,_src1存后8字节(低64位)
__m128i _src_0 = _mm_loadu_si128((__m128i*)(I_Ptr)); // I_Ptr --- I_Ptr+15
__m128i _src_1 = _mm_loadl_epi64((__m128i*)(I_Ptr + 16)); // I_Ptr+16 --- I_Ptr+23 (仅低64位有效)
// -------------------------- 正确分离B通道(8个像素) --------------------------
// B通道在_src0中的字节偏移:0(B0),3(B1),6(B2),9(B3),12(B4),15(B5)
// B通道在_src1中的字节偏移:2(B6,对应I_Ptr+18),5(B7,对应I_Ptr+21)
__m128i _blue = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 补充后2个B(B6-B7):从_src1的字节2、5提取
_blue = _mm_or_si128(_blue, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, -1, -1, -1, -1, -1, -1, -1, -1)));
// -------------------------- 正确分离G通道(8个像素) --------------------------
// G通道在_src0中的字节偏移:1(G0),4(G1),7(G2),10(G3),13(G4),-1(无G5)
// G通道在_src1中的字节偏移:0(G5,对应I_Ptr+16),3(G6,对应I_Ptr+19),6(G7,对应I_Ptr+22)
__m128i _green = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 补充后3个G(G5-G7):从_src1的字节0、3、6提取
_green = _mm_or_si128(_green, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 0, 3, 6, -1, -1, -1, -1, -1, -1, -1, -1)));
// -------------------------- 正确分离R通道(8个像素) --------------------------
// R通道在_src0中的字节偏移:2(R0),5(R1),8(R2),11(R3),14(R4),-1(无R5)
// R通道在_src1中的字节偏移:1(R5,对应I_Ptr+17),4(R6,对应I_Ptr+20),7(R7,对应I_Ptr+23)
__m128i _red = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(2, 5, 8, 11, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 补充后3个R(R5-R7):从_src1的字节1、4、7提取
_red = _mm_or_si128(_red, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 1, 4, 7, -1, -1, -1, -1, -1, -1, -1, -1)));
// -------------------------- 后续计算(与原逻辑一致,无需修改) --------------------------
// B通道:8位→32位浮点数,归一化到[0,1]
__m128i _b_lo = _mm_unpacklo_epi8(_blue, _zero);
__m128 _b_0 = _mm_div_ps(_mm_cvtepi32_ps(_mm_unpacklo_epi16(_b_lo, _zero)), _value_255);
__m128 _b_1 = _mm_div_ps(_mm_cvtepi32_ps(_mm_unpackhi_epi16(_b_lo, _zero)), _value_255);
// G通道:8位→32位浮点数,归一化到[0,1]
__m128i _g_lo = _mm_unpacklo_epi8(_green, _zero);
__m128 _g_0 = _mm_div_ps(_mm_cvtepi32_ps(_mm_unpacklo_epi16(_g_lo, _zero)), _value_255);
__m128 _g_1 = _mm_div_ps(_mm_cvtepi32_ps(_mm_unpackhi_epi16(_g_lo, _zero)), _value_255);
// R通道:8位→32位浮点数,归一化到[0,1]
__m128i _r_lo = _mm_unpacklo_epi8(_red, _zero);
__m128 _r_0 = _mm_div_ps(_mm_cvtepi32_ps(_mm_unpacklo_epi16(_r_lo, _zero)), _value_255);
__m128 _r_1 = _mm_div_ps(_mm_cvtepi32_ps(_mm_unpackhi_epi16(_r_lo, _zero)), _value_255);
// 计算距离平方和 sum = (B-Ab) * (B-Ab) + (G-Ag) * (G-Ag) + (R-Ar) * (R-Ar)
__m128 _sum_0 = _mm_add_ps(_mm_mul_ps(_mm_sub_ps(_b_0, _airlight_b), _mm_sub_ps(_b_0, _airlight_b)), \
_mm_add_ps(_mm_mul_ps(_mm_sub_ps(_g_0, _airlight_g), _mm_sub_ps(_g_0, _airlight_g)), \
_mm_mul_ps(_mm_sub_ps(_r_0, _airlight_r), _mm_sub_ps(_r_0, _airlight_r))));
__m128 _sum_1 = _mm_add_ps(_mm_mul_ps(_mm_sub_ps(_b_1, _airlight_b), _mm_sub_ps(_b_1, _airlight_b)), \
_mm_add_ps(_mm_mul_ps(_mm_sub_ps(_g_1, _airlight_g), _mm_sub_ps(_g_1, _airlight_g)), \
_mm_mul_ps(_mm_sub_ps(_r_1, _airlight_r), _mm_sub_ps(_r_1, _airlight_r))));
// 计算指数项 S = exp(-omega1 * sum)
__m128 _minus_omega_1 = _mm_mul_ps(_minus_1, _omega_1);
__m128 _S_0 = _mm_exp_ps_(_mm_mul_ps(_minus_omega_1, _sum_0));
__m128 _S_1 = _mm_exp_ps_(_mm_mul_ps(_minus_omega_1, _sum_1));
// 计算三通道最小值 min(B/Ab, G/Ag, R/Ar)
__m128 _min_0 = _mm_min_ps(_mm_div_ps(_b_0, _airlight_b), _mm_div_ps(_g_0, _airlight_g));
_min_0 = _mm_min_ps(_min_0, _mm_div_ps(_r_0, _airlight_r));
__m128 _min_1 = _mm_min_ps(_mm_div_ps(_b_1, _airlight_b), _mm_div_ps(_g_1, _airlight_g));
_min_1 = _mm_min_ps(_min_1, _mm_div_ps(_r_1, _airlight_r));
// 存储结果(Ic和Ic_refine)
_mm_storeu_ps(Ic_Ptr, _min_0); // 前4个像素的Ic
_mm_storeu_ps(Ic_Ptr + 4, _min_1); // 后4个像素的Ic
_mm_storeu_ps(Ic_refine_Ptr, _mm_mul_ps(_min_0, _mm_sub_ps(_plus_1, _mm_mul_ps(_omega_2, _S_0)))); // 前4个像素的Ic_refine
_mm_storeu_ps(Ic_refine_Ptr + 4, _mm_mul_ps(_min_1, _mm_sub_ps(_plus_1, _mm_mul_ps(_omega_2, _S_1)))); // 后4个像素的Ic_refine
// 指针偏移:8个像素(24字节)8个float结果
I_Ptr += 24;
Ic_Ptr += 8; Ic_refine_Ptr += 8;
}
// -------------------------- 处理4个像素的批次 --------------------------
for (; w + 3 < width; w += 4) {
// 加载4个像素的BGR数据(4×3=12字节,128位加载,前12字节有效)
__m128i _src = _mm_loadu_si128((__m128i*)I_Ptr);
// 分离B/G/R通道(按4像素的通道偏移提取,无需多段合并)
// B通道:每个像素第0字节,偏移0、3、6、9
__m128i _blue = _mm_shuffle_epi8(_src, _mm_setr_epi8(0, 3, 6, 9, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// G通道:每个像素第1字节,偏移1、4、7、10
__m128i _green = _mm_shuffle_epi8(_src, _mm_setr_epi8(1, 4, 7, 10, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// R通道:每个像素第2字节,偏移2、5、8、11
__m128i _red = _mm_shuffle_epi8(_src, _mm_setr_epi8(2, 5, 8, 11, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 8位无符号字节 → 32位浮点数(归一化到[0,1])
// B通道转换:unpack扩展→转32位int→转float→除以255
__m128i _b_unpack = _mm_unpacklo_epi8(_blue, _zero); // 8位→16位扩展
__m128i _b_int32 = _mm_unpacklo_epi16(_b_unpack, _zero); // 16位→32位扩展
// 32位int→float 归一化
__m128 _b_norm = _mm_div_ps(_mm_cvtepi32_ps(_b_int32), _value_255);
// G通道转换(与B通道逻辑完全一致)
__m128i _g_unpack = _mm_unpacklo_epi8(_green, _zero);
__m128i _g_int32 = _mm_unpacklo_epi16(_g_unpack, _zero);
__m128 _g_norm = _mm_div_ps(_mm_cvtepi32_ps(_g_int32), _value_255);
// R通道转换(与B通道逻辑完全一致)
__m128i _r_unpack = _mm_unpacklo_epi8(_red, _zero);
__m128i _r_int32 = _mm_unpacklo_epi16(_r_unpack, _zero);
__m128 _r_norm = _mm_div_ps(_mm_cvtepi32_ps(_r_int32), _value_255);
// 计算sum = (B-Ab) * (B-Ab) + (G-Ag) * (G-Ag) + (R-Ar) * (R-Ar)
__m128 _b_sub = _mm_sub_ps(_b_norm, _airlight_b); // B - Ab
__m128 _g_sub = _mm_sub_ps(_g_norm, _airlight_g); // G - Ag
__m128 _r_sub = _mm_sub_ps(_r_norm, _airlight_r); // R - Ar
// (B-Ab) * (B-Ab) + (G-Ag) * (G-Ag) + (R-Ar) * (R-Ar)
__m128 _sum = _mm_add_ps(_mm_mul_ps(_b_sub, _b_sub), _mm_mul_ps(_g_sub, _g_sub)); // 前两通道和
_sum = _mm_add_ps(_sum, _mm_mul_ps(_r_sub, _r_sub)); // 加第三通道,得到最终sum
// 计算S = exp(-omega1 * sum)(复用原有指数指令)
__m128 _minus_omega_1 = _mm_mul_ps(_minus_1, _omega_1); // -omega1
__m128 _S = _mm_exp_ps_(_mm_mul_ps(_minus_omega_1, _sum)); // exp(-omega1 * sum)
// 计算min = min(B/Ab, G/Ag, R/Ar)
__m128 _b_ratio = _mm_div_ps(_b_norm, _airlight_b); // B/Ab
__m128 _g_ratio = _mm_div_ps(_g_norm, _airlight_g); // G/Ag
__m128 _r_ratio = _mm_div_ps(_r_norm, _airlight_r); // R/Ar
__m128 _min_temp = _mm_min_ps(_b_ratio, _g_ratio); // 先比B和G的比值
__m128 _min = _mm_min_ps(_min_temp, _r_ratio); // 再比R的比值,得最终min
// 计算Ic_refine = min * (1 - omega2 * S)
__m128 _omega2_S = _mm_mul_ps(_omega_2, _S); // omega2 * S
__m128 _Ic_refine = _mm_mul_ps(_min, _mm_sub_ps(_plus_1, _omega2_S)); // 最终Ic_refine
// 存储结果(4个float值 用unpack存储避免对齐问题)
_mm_storeu_ps(Ic_Ptr, _min); // 存储Ic(min值)
_mm_storeu_ps(Ic_refine_Ptr, _Ic_refine); // 存储Ic_refine
// 指针偏移:4像素BGR数据(12字节) 4个输出结果(各4个float)
I_Ptr += 12;
Ic_Ptr += 4; Ic_refine_Ptr += 4;
}
for (; w < width; w++)
{
b = *I_Ptr / 255.0f; g = *(I_Ptr + 1) / 255.0f; r = *(I_Ptr + 2) / 255.0f;
sum = (b - airlight_b) * (b - airlight_b) + (g - airlight_g) * (g - airlight_g) + (r - airlight_r) * (r - airlight_r);
S = std::exp(-1.0f * omega_1 * sum);
min = b / airlight_b > g / airlight_g ? g / airlight_g : b / airlight_b;
min = min > r / airlight_r ? r / airlight_r : min;
*Ic_Ptr = min;
*Ic_refine_Ptr = min * (1.0f - omega_2 * S);
I_Ptr += 3;
Ic_Ptr++; Ic_refine_Ptr++;
}
#else
for (; w < width; w++)
{
b = *I_Ptr / 255.0f; g = *(I_Ptr + 1) / 255.0f; r = *(I_Ptr + 2) / 255.0f;
sum = (b - airlight_b) * (b - airlight_b) + (g - airlight_g) * (g - airlight_g) + (r - airlight_r) * (r - airlight_r);
S = std::exp(-1 * omega_1 * sum);
min = b / airlight_b > g / airlight_g ? g / airlight_g : b / airlight_b;
min = min > r / airlight_r ? r / airlight_r : min;
*Ic_Ptr = min;
*Ic_refine_Ptr = min * (1.0f - omega_2 * S);
I_Ptr += 3; Ic_Ptr++; Ic_refine_Ptr++;
}
#endif
}
}
}
/// <summary>
/// 对雾天图像依据透射率做去雾操作
/// </summary>
/// <param name="hazy_image"></param> 输入雾天图像
/// <param name="recover_result"></param> 输出去雾结果
/// <param name="transmission"></param> 透射率,也就是传输函数
/// <param name="width"></param> 图像的宽
/// <param name="height"></param> 图像的高
/// <param name="stride"></param> 雾天图像像素的步长,通常取值为 width * 3
/// <param name="A_b"></param> blue通道的大气光值
/// <param name="A_g"></param> green通道的大气光值
/// <param name="A_r"></param> red通道的大气光值
void recover(unsigned char* hazy_image, unsigned char* recover_result, float* transmission, int width, int height, int stride, int A_b, int A_g, int A_r)
{
int channels = stride / width;
if (channels != 3) {
printf("Error: Invalid channel number (expected 3, got %d)\n", channels);
return;
}
else {
for (int h = 0; h < height; h++)
{
unsigned char* input_Ptr = hazy_image + h * stride;
unsigned char* output_Ptr = recover_result + h * stride;
float* trans_Ptr = transmission + h * width;
float trans_min = 0.1f; float trans_now = 0.0f;
int w = 0;
#ifdef __SIMD__
__m128i _zero = _mm_setzero_si128();
__m128 _airlight_b = _mm_set1_ps(float(A_b));
__m128 _airlight_g = _mm_set1_ps(float(A_g));
__m128 _airlight_r = _mm_set1_ps(float(A_r));
__m128 _trans_min = _mm_set1_ps(trans_min);
for (; w + 15 < width; w += 16)
{
__m128i _src_0, _src_1, _src_2, _blue, _green, _red;
_src_0 = _mm_loadu_si128((__m128i*)(input_Ptr));
_src_1 = _mm_loadu_si128((__m128i*)(input_Ptr + 16));
_src_2 = _mm_loadu_si128((__m128i*)(input_Ptr + 32));
__m128 _trans_0_0 = _mm_loadu_ps(trans_Ptr);
_trans_0_0 = _mm_max_ps(_trans_0_0, _trans_min);
__m128 _trans_0_1 = _mm_loadu_ps(trans_Ptr + 4);
_trans_0_1 = _mm_max_ps(_trans_0_1, _trans_min);
__m128 _trans_1_0 = _mm_loadu_ps(trans_Ptr + 8);
_trans_1_0 = _mm_max_ps(_trans_1_0, _trans_min);
__m128 _trans_1_1 = _mm_loadu_ps(trans_Ptr + 12);
_trans_1_1 = _mm_max_ps(_trans_1_1, _trans_min);
// 以下操作把16个连续像素的像素顺序由 B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R
// 更改为适合于SIMD指令处理的连续序列 B B B B B B B B B B B B B B B B G G G G G G G G G G G G G G G G R R R R R R R R R R R R R R R R
_blue = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_blue = _mm_or_si128(_blue, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14, -1, -1, -1, -1, -1)));
_blue = _mm_or_si128(_blue, _mm_shuffle_epi8(_src_2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1, 4, 7, 10, 13)));
_green = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_green = _mm_or_si128(_green, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1)));
_green = _mm_or_si128(_green, _mm_shuffle_epi8(_src_2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14)));
_red = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(2, 5, 8, 11, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_red = _mm_or_si128(_red, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1)));
_red = _mm_or_si128(_red, _mm_shuffle_epi8(_src_2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15)));
__m128i _blue_0 = _mm_unpacklo_epi8(_mm_unpacklo_epi64(_blue, _zero), _zero); // 获取低64位8个bit 并将有效bit扩展成16位 16 * 8
__m128i _blue_1 = _mm_unpacklo_epi8(_mm_unpackhi_epi64(_blue, _zero), _zero); // 获取高64位8个bit 并将有效bit扩展成16位 16 * 8
__m128 _blue_0_0 = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_blue_0, _zero));
__m128 _blue_0_1 = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_blue_0, _zero));
__m128 _blue_1_0 = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_blue_1, _zero));
__m128 _blue_1_1 = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_blue_1, _zero));
__m128i _green_0 = _mm_unpacklo_epi8(_mm_unpacklo_epi64(_green, _zero), _zero);
__m128i _green_1 = _mm_unpacklo_epi8(_mm_unpackhi_epi64(_green, _zero), _zero);
__m128 _green_0_0 = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_green_0, _zero));
__m128 _green_0_1 = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_green_0, _zero));
__m128 _green_1_0 = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_green_1, _zero));
__m128 _green_1_1 = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_green_1, _zero));
__m128i _red_0 = _mm_unpacklo_epi8(_mm_unpacklo_epi64(_red, _zero), _zero);
__m128i _red_1 = _mm_unpacklo_epi8(_mm_unpackhi_epi64(_red, _zero), _zero);
__m128 _red_0_0 = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_red_0, _zero));
__m128 _red_0_1 = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_red_0, _zero));
__m128 _red_1_0 = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_red_1, _zero));
__m128 _red_1_1 = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_red_1, _zero));
__m128 _result_b_0_0 = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_blue_0_0, _airlight_b), _trans_0_0), _airlight_b);
__m128 _result_b_0_1 = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_blue_0_1, _airlight_b), _trans_0_1), _airlight_b);
__m128 _result_b_1_0 = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_blue_1_0, _airlight_b), _trans_1_0), _airlight_b);
__m128 _result_b_1_1 = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_blue_1_1, _airlight_b), _trans_1_1), _airlight_b);
__m128 _result_g_0_0 = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_green_0_0, _airlight_g), _trans_0_0), _airlight_g);
__m128 _result_g_0_1 = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_green_0_1, _airlight_g), _trans_0_1), _airlight_g);
__m128 _result_g_1_0 = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_green_1_0, _airlight_g), _trans_1_0), _airlight_g);
__m128 _result_g_1_1 = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_green_1_1, _airlight_g), _trans_1_1), _airlight_g);
__m128 _result_r_0_0 = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_red_0_0, _airlight_r), _trans_0_0), _airlight_r);
__m128 _result_r_0_1 = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_red_0_1, _airlight_r), _trans_0_1), _airlight_r);
__m128 _result_r_1_0 = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_red_1_0, _airlight_r), _trans_1_0), _airlight_r);
__m128 _result_r_1_1 = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_red_1_1, _airlight_r), _trans_1_1), _airlight_r);
// 8 * 16bit = 128i
__m128i _result_b_0 = _mm_packus_epi32(_mm_cvtps_epi32(_result_b_0_0), _mm_cvtps_epi32(_result_b_0_1));
__m128i _result_b_1 = _mm_packus_epi32(_mm_cvtps_epi32(_result_b_1_0), _mm_cvtps_epi32(_result_b_1_1));
// 16 * 8bit = 128i
__m128i _result_b = _mm_packus_epi16(_result_b_0, _result_b_1);
__m128i _result_g_0 = _mm_packs_epi32(_mm_cvtps_epi32(_result_g_0_0), _mm_cvtps_epi32(_result_g_0_1));
__m128i _result_g_1 = _mm_packs_epi32(_mm_cvtps_epi32(_result_g_1_0), _mm_cvtps_epi32(_result_g_1_1));
__m128i _result_g = _mm_packus_epi16(_result_g_0, _result_g_1);
__m128i _result_r_0 = _mm_packs_epi32(_mm_cvtps_epi32(_result_r_0_0), _mm_cvtps_epi32(_result_r_0_1));
__m128i _result_r_1 = _mm_packs_epi32(_mm_cvtps_epi32(_result_r_1_0), _mm_cvtps_epi32(_result_r_1_1));
__m128i _result_r = _mm_packus_epi16(_result_r_0, _result_r_1);
// 转换成BGR BGR的形式
__m128i _dest_0 = _mm_shuffle_epi8(_result_b, _mm_setr_epi8(0, -1, -1, 1, -1, -1, 2, -1, -1, 3, -1, -1, 4, -1, -1, 5));
_dest_0 = _mm_or_si128(_dest_0, _mm_shuffle_epi8(_result_g, _mm_setr_epi8(-1, 0, -1, -1, 1, -1, -1, 2, -1, -1, 3, -1, -1, 4, -1, -1)));
_dest_0 = _mm_or_si128(_dest_0, _mm_shuffle_epi8(_result_r, _mm_setr_epi8(-1, -1, 0, -1, -1, 1, -1, -1, 2, -1, -1, 3, -1, -1, 4, -1)));
__m128i _dest_1 = _mm_shuffle_epi8(_result_b, _mm_setr_epi8(-1, -1, 6, -1, -1, 7, -1, -1, 8, -1, -1, 9, -1, -1, 10, -1));
_dest_1 = _mm_or_si128(_dest_1, _mm_shuffle_epi8(_result_g, _mm_setr_epi8(5, -1, -1, 6, -1, -1, 7, -1, -1, 8, -1, -1, 9, -1, -1, 10)));
_dest_1 = _mm_or_si128(_dest_1, _mm_shuffle_epi8(_result_r, _mm_setr_epi8(-1, 5, -1, -1, 6, -1, -1, 7, -1, -1, 8, -1, -1, 9, -1, -1)));
__m128i _dest_2 = _mm_shuffle_epi8(_result_b, _mm_setr_epi8(-1, 11, -1, -1, 12, -1, -1, 13, -1, -1, 14, -1, -1, 15, -1, -1));
_dest_2 = _mm_or_si128(_dest_2, _mm_shuffle_epi8(_result_g, _mm_setr_epi8(-1, -1, 11, -1, -1, 12, -1, -1, 13, -1, -1, 14, -1, -1, 15, -1)));
_dest_2 = _mm_or_si128(_dest_2, _mm_shuffle_epi8(_result_r, _mm_setr_epi8(10, -1, -1, 11, -1, -1, 12, -1, -1, 13, -1, -1, 14, -1, -1, 15)));
_mm_storeu_si128((__m128i*)(output_Ptr), _dest_0);
_mm_storeu_si128((__m128i*)(output_Ptr + 16), _dest_1);
_mm_storeu_si128((__m128i*)(output_Ptr + 32), _dest_2);
input_Ptr += 48; output_Ptr += 48;
trans_Ptr += 16;
}
// 处理8个像素
for (; w + 7 < width; w += 8) {
// 加载8个透射率值(每个像素1个float,共8个)并限制最小值为trans_min
__m128 _trans_lo = _mm_loadu_ps(trans_Ptr); // 前4个透射率
__m128 _trans_hi = _mm_loadu_ps(trans_Ptr + 4); // 后4个透射率
_trans_lo = _mm_max_ps(_trans_lo, _trans_min); // 透射率下限保护
_trans_hi = _mm_max_ps(_trans_hi, _trans_min);
// 加载8个BGR像素的24字节数据(B0G0R0...B7G7R7)
__m128i _src_0 = _mm_loadu_si128((__m128i*)(input_Ptr)); // 前16字节(偏移0-15)
__m128i _src_1 = _mm_loadl_epi64((__m128i*)(input_Ptr + 16)); // 后8字节(偏移16-23),仅低64位有效
// -------------------------- 正确分离B通道(8个像素:B0-B7) --------------------------
// B通道偏移:0(B0),3(B1),6(B2),9(B3),12(B4),15(B5),18(B6),21(B7)
// _src0包含B0-B5(偏移0,3,6,9,12,15),_src1包含B6(偏移18→_src1字节2)、B7(偏移21→_src1字节5)
__m128i _blue = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_blue = _mm_or_si128(_blue, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, -1, -1, -1, -1, -1, -1, -1, -1)));
// -------------------------- 正确分离G通道(8个像素:G0-G7) --------------------------
// G通道偏移:1(G0),4(G1),7(G2),10(G3),13(G4),16(G5),19(G6),22(G7)
// _src0包含G0-G4(偏移1,4,7,10,13),_src1包含G5(偏移16→_src1字节0)、G6(偏移19→_src1字节3)、G7(偏移22→_src1字节6)
__m128i _green = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_green = _mm_or_si128(_green, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 0, 3, 6, -1, -1, -1, -1, -1, -1, -1, -1)));
// -------------------------- 正确分离R通道(8个像素:R0-R7) --------------------------
// R通道偏移:2(R0),5(R1),8(R2),11(R3),14(R4),17(R5),20(R6),23(R7)
// _src0包含R0-R4(偏移2,5,8,11,14),_src1包含R5(偏移17→_src1字节1)、R6(偏移20→_src1字节4)、R7(偏移23→_src1字节7)
__m128i _red = _mm_shuffle_epi8(_src_0, _mm_setr_epi8(2, 5, 8, 11, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
_red = _mm_or_si128(_red, _mm_shuffle_epi8(_src_1, _mm_setr_epi8(-1, -1, -1, -1, -1, 1, 4, 7, -1, -1, -1, -1, -1, -1, -1, -1)));
// -------------------------- 通道数据转换:8位无符号→32位浮点数 --------------------------
// B通道转换
__m128i _b_unpack = _mm_unpacklo_epi8(_blue, _zero); // 8位→16位扩展
__m128 _b_lo = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_b_unpack, _zero)); // 前4个B→float
__m128 _b_hi = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_b_unpack, _zero)); // 后4个B→float
// G通道转换
__m128i _g_unpack = _mm_unpacklo_epi8(_green, _zero);
__m128 _g_lo = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_g_unpack, _zero));
__m128 _g_hi = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_g_unpack, _zero));
// R通道转换
__m128i _r_unpack = _mm_unpacklo_epi8(_red, _zero);
__m128 _r_lo = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_r_unpack, _zero));
__m128 _r_hi = _mm_cvtepi32_ps(_mm_unpackhi_epi16(_r_unpack, _zero));
// -------------------------- 图像恢复计算:(像素 - 大气光) / 透射率 + 大气光 --------------------------
// 前4个像素(对应_trans_lo)
__m128 _res_b_lo = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_b_lo, _airlight_b), _trans_lo), _airlight_b);
__m128 _res_g_lo = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_g_lo, _airlight_g), _trans_lo), _airlight_g);
__m128 _res_r_lo = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_r_lo, _airlight_r), _trans_lo), _airlight_r);
// 后4个像素(对应_trans_hi)
__m128 _res_b_hi = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_b_hi, _airlight_b), _trans_hi), _airlight_b);
__m128 _res_g_hi = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_g_hi, _airlight_g), _trans_hi), _airlight_g);
__m128 _res_r_hi = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_r_hi, _airlight_r), _trans_hi), _airlight_r);
// -------------------------- 浮点数→8位无符号整数(饱和打包,避免溢出) --------------------------
// 合并前4和后4个像素的结果(32位float→32位int→16位int→8位int)
__m128i _res_b_32 = _mm_packus_epi32(_mm_cvtps_epi32(_res_b_lo), _mm_cvtps_epi32(_res_b_hi));
__m128i _res_b_8 = _mm_packus_epi16(_res_b_32, _zero); // 仅保留低8位有效数据,高8位填0
__m128i _res_g_32 = _mm_packus_epi32(_mm_cvtps_epi32(_res_g_lo), _mm_cvtps_epi32(_res_g_hi));
__m128i _res_g_8 = _mm_packus_epi16(_res_g_32, _zero);
__m128i _res_r_32 = _mm_packus_epi32(_mm_cvtps_epi32(_res_r_lo), _mm_cvtps_epi32(_res_r_hi));
__m128i _res_r_8 = _mm_packus_epi16(_res_r_32, _zero);
// -------------------------- 重组为BGR交错格式(8像素→24字节:B0G0R0...B7G7R7) --------------------------
// _dest0:处理前5个像素(15字节,对应输出偏移0-14)
__m128i _dest_0 = _mm_shuffle_epi8(_res_b_8, _mm_setr_epi8(0, -1, -1, 1, -1, -1, 2, -1, -1, 3, -1, -1, 4, -1, -1, 5));
_dest_0 = _mm_or_si128(_dest_0, _mm_shuffle_epi8(_res_g_8, _mm_setr_epi8(-1, 0, -1, -1, 1, -1, -1, 2, -1, -1, 3, -1, -1, 4, -1, -1)));
_dest_0 = _mm_or_si128(_dest_0, _mm_shuffle_epi8(_res_r_8, _mm_setr_epi8(-1, -1, 0, -1, -1, 1, -1, -1, 2, -1, -1, 3, -1, -1, 4, -1)));
// _dest1:处理后3个像素(9字节,对应输出偏移15-23,低64位有效)
__m128i _dest_1 = _mm_shuffle_epi8(_res_b_8, _mm_setr_epi8(-1, -1, 5, -1, -1, 6, -1, -1, 7, -1, -1, -1, -1, -1, -1, -1));
_dest_1 = _mm_or_si128(_dest_1, _mm_shuffle_epi8(_res_g_8, _mm_setr_epi8(5, -1, -1, 6, -1, -1, 7, -1, -1, -1, -1, -1, -1, -1, -1, -1)));
_dest_1 = _mm_or_si128(_dest_1, _mm_shuffle_epi8(_res_r_8, _mm_setr_epi8(-1, 5, -1, -1, 6, -1, -1, 7, -1, -1, -1, -1, -1, -1, -1, -1)));
// -------------------------- 存储结果(24字节) --------------------------
_mm_storeu_si128((__m128i*)(output_Ptr), _dest_0); // 存储前16字节(含前5个完整像素)
_mm_storel_epi64((__m128i*)(output_Ptr + 16), _dest_1); // 存储后8字节(含后3个完整像素)
// -------------------------- 指针偏移(同步前进) --------------------------
// 8个BGR像素 = 8*3 = 24字节
input_Ptr += 24; output_Ptr += 24;
trans_Ptr += 8; // 8个透射率值(每个像素1个)
}
// -------------------------- 处理4个像素的批次 --------------------------
for (; w + 3 < width; w += 4) {
// 加载4个透射率值 限制最小值为trans_min(透射率保护)
__m128 _trans = _mm_loadu_ps(trans_Ptr); // 4个float透射率(16字节)
_trans = _mm_max_ps(_trans, _trans_min); // 避免透射率过小导致图像过亮
// 加载4个像素的BGR数据(4×3=12字节 128位加载 前12字节有效)
__m128i _src = _mm_loadu_si128((__m128i*)input_Ptr);
// 分离B/G/R通道(按4像素的通道偏移提取,无需多段合并)
// B通道:每个像素第0字节,偏移0、3、6、9
__m128i _blue = _mm_shuffle_epi8(_src, _mm_setr_epi8(0, 3, 6, 9, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// G通道:每个像素第1字节,偏移1、4、7、10
__m128i _green = _mm_shuffle_epi8(_src, _mm_setr_epi8(1, 4, 7, 10, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// R通道:每个像素第2字节,偏移2、5、8、11
__m128i _red = _mm_shuffle_epi8(_src, _mm_setr_epi8(2, 5, 8, 11, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// 通道数据转换:8位无符号字节 → 32位浮点数(与16/8像素逻辑一致)
// B通道转换:unpack扩展→转32位int→转float
__m128i _b_unpack = _mm_unpacklo_epi8(_blue, _zero); // 8位→16位扩展
// 16位→32位扩展 32位int→float
__m128 _b = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_b_unpack, _zero));
// G通道转换(与B通道完全一致)
__m128i _g_unpack = _mm_unpacklo_epi8(_green, _zero);
__m128 _g = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_g_unpack, _zero));
// R通道转换(与B通道完全一致)
__m128i _r_unpack = _mm_unpacklo_epi8(_red, _zero);
__m128 _r = _mm_cvtepi32_ps(_mm_unpacklo_epi16(_r_unpack, _zero));
// 图像恢复计算:(像素值 - 大气光) / 透射率 + 大气光(核心公式)
// (B - Ab)/t + Ab
__m128 _res_b = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_b, _airlight_b), _trans), _airlight_b);
// (G - Ag)/t + Ag
__m128 _res_g = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_g, _airlight_g), _trans), _airlight_g);
// (R - Ar)/t + Ar
__m128 _res_r = _mm_add_ps(_mm_div_ps(_mm_sub_ps(_r, _airlight_r), _trans), _airlight_r);
// 浮点数→8位无符号整数(饱和打包 避免溢出 对应标量ClampToByte)
// 32位float→32位int→16位int(饱和)→8位int(饱和)
// float→32位int 32→16位(饱和,高位置零)16→8位(饱和 高位置零)
__m128i _res_b_16 = _mm_packus_epi32(_mm_cvtps_epi32(_res_b), _zero);
__m128i _res_b_8 = _mm_packus_epi16(_res_b_16, _zero);
__m128i _res_g_16 = _mm_packus_epi32(_mm_cvtps_epi32(_res_g), _zero);
__m128i _res_g_8 = _mm_packus_epi16(_res_g_16, _zero);
__m128i _res_r_16 = _mm_packus_epi32(_mm_cvtps_epi32(_res_r), _zero);
__m128i _res_r_8 = _mm_packus_epi16(_res_r_16, _zero);
// 重组为BGR交错格式(4像素→12字节:B0G0R0 B1G1R1 B2G2R2 B3G3R3)
// 用shuffle+or组合通道数据 每个像素占3字节 对应输出偏移0-11
// 填充B通道:B0(0)、B1(3)、B2(6)、B3(9)
__m128i _dest = _mm_shuffle_epi8(_res_b_8, _mm_setr_epi8(0, -1, -1, 1, -1, -1, 2, -1, -1, 3, -1, -1, -1, -1, -1, -1));
// 填充G通道:G0(1)、G1(4)、G2(7)、G3(10)
_dest = _mm_or_si128(_dest, _mm_shuffle_epi8(_res_g_8, _mm_setr_epi8(-1, 0, -1, -1, 1, -1, -1, 2, -1, -1, 3, -1, -1, -1, -1, -1)));
// 填充R通道:R0(2)、R1(5)、R2(8)、R3(11)
_dest = _mm_or_si128(_dest, _mm_shuffle_epi8(_res_r_8, _mm_setr_epi8(-1, -1, 0, -1, -1, 1, -1, -1, 2, -1, -1, 3, -1, -1, -1, -1)));
// 存储结果(12字节 用_mm_storeu_si128兼容存储 后4字节零不影响)
_mm_storeu_si128((__m128i*)output_Ptr, _dest);
// 指针偏移:同步前进
input_Ptr += 12; output_Ptr += 12;
trans_Ptr += 4;
}
for (; w < width; w++) {
trans_now = std::fmax(*trans_Ptr, trans_min);
*output_Ptr = ClampToByte((*input_Ptr - A_b) / trans_now + A_b);
*(output_Ptr + 1) = ClampToByte((*(input_Ptr + 1) - A_g) / trans_now + A_g);
*(output_Ptr + 2) = ClampToByte((*(input_Ptr + 2) - A_r) / trans_now + A_r);
input_Ptr += 3; output_Ptr += 3;
trans_Ptr++;
}
#else
for (; w < width; w++) {
trans_now = std::fmax(*trans_Ptr, trans_min);
*output_Ptr = ClampToByte((*input_Ptr - A_b) / trans_now + A_b);
*(output_Ptr + 1) = ClampToByte((*(input_Ptr + 1) - A_g) / trans_now + A_g);
*(output_Ptr + 2) = ClampToByte((*(input_Ptr + 2) - A_r) / trans_now + A_r);
input_Ptr += 3; output_Ptr += 3;
trans_Ptr++;
}
#endif
}
}
}
/// <summary>
/// 将一幅单通道图像数值无变换地从uchar精度转换为float精度
/// </summary>
/// <param name="src"></param> 输入图像
/// <param name="dest"></param> 输出转换图像
/// <param name="width"></param> 图像的宽
/// <param name="height"></param> 图像的高
void cvt_u_f(unsigned char* src, float* dest, int width, int height)
{
for (int h = 0; h < height; h++) {
unsigned char* srcPtr = src + h * width;
float* destPtr = dest + h * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
__m128i _src_u = _mm_loadu_si128((__m128i*)(srcPtr));
// 解包为 16 位整数
__m128i _zero_u = _mm_setzero_si128();
__m128i _lo_u = _mm_unpacklo_epi8(_src_u, _zero_u);
__m128i _hi_u = _mm_unpackhi_epi8(_src_u, _zero_u);
// 解包为 32 位整数
__m128i _in_u_0 = _mm_unpacklo_epi16(_lo_u, _zero_u);
__m128i _in_u_1 = _mm_unpackhi_epi16(_lo_u, _zero_u);
__m128i _in_u_2 = _mm_unpacklo_epi16(_hi_u, _zero_u);
__m128i _in_u_3 = _mm_unpackhi_epi16(_hi_u, _zero_u);
// 转换为浮点数
__m128 _out_f_0 = _mm_cvtepi32_ps(_in_u_0);
__m128 _out_f_1 = _mm_cvtepi32_ps(_in_u_1);
__m128 _out_f_2 = _mm_cvtepi32_ps(_in_u_2);
__m128 _out_f_3 = _mm_cvtepi32_ps(_in_u_3);
// 存储结果
_mm_storeu_ps(destPtr, _out_f_0);
_mm_storeu_ps(destPtr + 4, _out_f_1);
_mm_storeu_ps(destPtr + 8, _out_f_2);
_mm_storeu_ps(destPtr + 12, _out_f_3);
srcPtr += 16; destPtr += 16;
}
// 处理剩下的8个像素 (如果可用)
for (; w + 7 < width; w += 8) {
// 加载8个uint8_t数据(64位)
__m128i _src_u = _mm_loadl_epi64((__m128i*)(srcPtr)); // 加载低64位
// 解包为16位整数
__m128i _zero = _mm_setzero_si128();
__m128i _u16_vals = _mm_unpacklo_epi8(_src_u, _zero);
// 解包为32位整数并转换为浮点数
__m128i _i32_vals_lo = _mm_unpacklo_epi16(_u16_vals, _zero);
__m128i _i32_vals_hi = _mm_unpackhi_epi16(_u16_vals, _zero);
__m128 _f32_vals_lo = _mm_cvtepi32_ps(_i32_vals_lo);
__m128 _f32_vals_hi = _mm_cvtepi32_ps(_i32_vals_hi);
// 存储结果
_mm_storeu_ps(destPtr, _f32_vals_lo);
_mm_storeu_ps(destPtr + 4, _f32_vals_hi);
srcPtr += 8; destPtr += 8;
}
// 处理剩下的4个像素 (如果可用)
for (; w + 3 < width; w += 4) {
// 加载4个uint8_t数据(32位)。我们加载4字节,然后转换为32位整数。
// 注意:这里使用 mm_cvtepu8_epi32 指令(SSE4.1),它可以直接将4个uint8_t零扩展到4个int32_t。
// 如果你的编译器支持SSE4.1,这更简洁高效。
//__m128i _src_u = _mm_cvtepu8_epi32(_mm_loadu_si32(srcPtr)); // _mm_loadu_si32 加载未对齐的32位
// 兼容性加载
int tmp;
std::memcpy(&tmp, srcPtr + w, sizeof(int));
__m128i _src_u = _mm_cvtsi32_si128(tmp);
// 转换为浮点数
__m128 _f32_vals = _mm_cvtepi32_ps(_src_u);
// 存储结果
_mm_storeu_ps(destPtr, _f32_vals);
srcPtr += 4; destPtr += 4;
}
// 处理边界像素
for (; w < width; w++) {
*destPtr = (float)*srcPtr;
srcPtr++; destPtr++;
}
#else
for (; w < width; w++) {
*destPtr = (float)*srcPtr;
srcPtr++; destPtr++;
}
#endif
}
}
/// <summary>
/// 将一幅单通道图像数值无变换地从float精度转换为uchar精度
/// </summary>
/// <param name="src"></param> 输入图像
/// <param name="dest"></param> 输出转换图像
/// <param name="width"></param> 图像的宽
/// <param name="height"></param> 图像的高
void cvt_f_u(float* src, unsigned char* dest, int width, int height)
{
for (int h = 0; h < height; h++) {
float* srcPtr = src + h * width;
unsigned char* destPtr = dest + h * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
// 加载 4 组浮点数
__m128 _in_f_0 = _mm_loadu_ps(srcPtr);
__m128 _in_f_1 = _mm_loadu_ps(srcPtr + 4);
__m128 _in_f_2 = _mm_loadu_ps(srcPtr + 8);
__m128 _in_f_3 = _mm_loadu_ps(srcPtr + 12);
// 转换为 32 为正数(截断)
__m128i _in_u_0 = _mm_cvttps_epi32(_in_f_0);
__m128i _in_u_1 = _mm_cvttps_epi32(_in_f_1);
__m128i _in_u_2 = _mm_cvttps_epi32(_in_f_2);
__m128i _in_u_3 = _mm_cvttps_epi32(_in_f_3);
// 打包成 16 位整数
__m128i _out_u_0 = _mm_packs_epi32(_in_u_0, _in_u_1);
__m128i _out_u_1 = _mm_packs_epi32(_in_u_2, _in_u_3);
// 打包成 8 位无符号整数(饱和转换)
__m128i _out_u = _mm_packus_epi16(_out_u_0, _out_u_1);
// 存储结果
_mm_storeu_si128((__m128i*)(destPtr), _out_u);
srcPtr += 16; destPtr += 16;
}
// 处理剩下的8个像素 (如果可用)
for (; w + 7 < width; w += 8) {
// 加载2组浮点数(共8个)
__m128 _in_f_0 = _mm_loadu_ps(srcPtr);
__m128 _in_f_1 = _mm_loadu_ps(srcPtr + 4);
// 转换为32位整数
__m128i _in_i_0 = _mm_cvttps_epi32(_in_f_0);
__m128i _in_i_1 = _mm_cvttps_epi32(_in_f_1);
// 打包成16位整数
__m128i _out_i = _mm_packs_epi32(_in_i_0, _in_i_1);
// 打包成8位无符号整数(饱和转换) - 此时_out_i包含8个16位整数 只需要低8个8位整数
__m128i _out_u = _mm_packus_epi16(_out_i, _out_i); // 将同一个向量打包两次 高8位会被忽略
// 存储低64位(8个字节)
_mm_storel_epi64((__m128i*)destPtr, _out_u);
srcPtr += 8; destPtr += 8;
}
// 处理剩下的4个像素 (如果可用)
for (; w + 3 < width; w += 4) {
// 加载1组浮点数(4个)
__m128 _in_f = _mm_loadu_ps(srcPtr);
// 转换为32位整数
__m128i _in_i = _mm_cvttps_epi32(_in_f);
// 打包成16位整数(需要第二个向量,这里用零填充)
__m128i _zero = _mm_setzero_si128();
__m128i _out_i = _mm_packs_epi32(_in_i, _zero);
// 打包成8位无符号整数(饱和转换)
__m128i _out_u = _mm_packus_epi16(_out_i, _zero);
// 存储低32位(4个字节)
//_mm_storeu_si32(destPtr, _out_u); // 或者使用 *(int*)destPtr = _mm_cvtsi128_si32(_out_u);
*(int*)destPtr = _mm_cvtsi128_si32(_out_u);
srcPtr += 4; destPtr += 4;
}
// 处理边界像素
for (; w < width; w++) {
*destPtr = (unsigned char)*srcPtr;
srcPtr++; destPtr++;
}
#else
for (; w < width; w++) {
*destPtr = (unsigned char)*srcPtr;
srcPtr++; destPtr++;
}
#endif
}
}
/// <summary>
/// 计算两个数组相加的和
/// </summary>
/// <param name="a_array"></param> 加数数组a
/// <param name="b_array"></param> 加数数组b
/// <param name="output"></param> 输出相加的结果
/// <param name="width"></param> 图像的宽
/// <param name="height"></param> 图像的高
/// <param name="a_weight"></param> 相加时数组a的权重
/// <param name="b_weight"></param> 相加时数组b的权重
void array_add(float* a_array, float* b_array, float* output, int width, int height, float a_weight, float b_weight)
{
for (int h = 0; h < height; h++)
{
float* a_arrayPtr = a_array + h * width;
float* b_arrayPtr = b_array + h * width;
float* outputPtr = output + h * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
__m128 _a_array_0 = _mm_loadu_ps(a_arrayPtr);
__m128 _a_array_1 = _mm_loadu_ps(a_arrayPtr + 4);
__m128 _a_array_2 = _mm_loadu_ps(a_arrayPtr + 8);
__m128 _a_array_3 = _mm_loadu_ps(a_arrayPtr + 12);
__m128 _b_array_0 = _mm_loadu_ps(b_arrayPtr);
__m128 _b_array_1 = _mm_loadu_ps(b_arrayPtr + 4);
__m128 _b_array_2 = _mm_loadu_ps(b_arrayPtr + 8);
__m128 _b_array_3 = _mm_loadu_ps(b_arrayPtr + 12);
__m128 _a_weight = _mm_set1_ps(a_weight);
_a_array_0 = _mm_mul_ps(_a_array_0, _a_weight);
_a_array_1 = _mm_mul_ps(_a_array_1, _a_weight);
_a_array_2 = _mm_mul_ps(_a_array_2, _a_weight);
_a_array_3 = _mm_mul_ps(_a_array_3, _a_weight);
__m128 _b_weight = _mm_set1_ps(b_weight);
_b_array_0 = _mm_mul_ps(_b_array_0, _b_weight);
_b_array_1 = _mm_mul_ps(_b_array_1, _b_weight);
_b_array_2 = _mm_mul_ps(_b_array_2, _b_weight);
_b_array_3 = _mm_mul_ps(_b_array_3, _b_weight);
__m128 _output_0 = _mm_add_ps(_a_array_0, _b_array_0);
__m128 _output_1 = _mm_add_ps(_a_array_1, _b_array_1);
__m128 _output_2 = _mm_add_ps(_a_array_2, _b_array_2);
__m128 _output_3 = _mm_add_ps(_a_array_3, _b_array_3);
_mm_store_ps(outputPtr, _output_0);
_mm_store_ps(outputPtr + 4, _output_1);
_mm_store_ps(outputPtr + 8, _output_2);
_mm_store_ps(outputPtr + 12, _output_3);
a_arrayPtr += 16; b_arrayPtr += 16;
outputPtr += 16;
}
for (; w + 7 < width; w += 8) {
__m128 _a_array_0 = _mm_loadu_ps(a_arrayPtr);
__m128 _a_array_1 = _mm_loadu_ps(a_arrayPtr + 4);
__m128 _b_array_0 = _mm_loadu_ps(b_arrayPtr);
__m128 _b_array_1 = _mm_loadu_ps(b_arrayPtr + 4);
__m128 _a_weight = _mm_set1_ps(a_weight);
_a_array_0 = _mm_mul_ps(_a_array_0, _a_weight);
_a_array_1 = _mm_mul_ps(_a_array_1, _a_weight);
__m128 _b_weight = _mm_set1_ps(b_weight);
_b_array_0 = _mm_mul_ps(_b_array_0, _b_weight);
_b_array_1 = _mm_mul_ps(_b_array_1, _b_weight);
__m128 _output_0 = _mm_add_ps(_a_array_0, _b_array_0);
__m128 _output_1 = _mm_add_ps(_a_array_1, _b_array_1);
_mm_store_ps(outputPtr, _output_0);
_mm_store_ps(outputPtr + 4, _output_1);
a_arrayPtr += 8; b_arrayPtr += 8;
outputPtr += 8;
}
for (; w + 3 < width; w += 4) {
__m128 _a_array = _mm_loadu_ps(a_arrayPtr);
__m128 _b_array = _mm_loadu_ps(b_arrayPtr);
__m128 _a_weight = _mm_set1_ps(a_weight);
_a_array = _mm_mul_ps(_a_array, _a_weight);
__m128 _b_weight = _mm_set1_ps(b_weight);
_b_array = _mm_mul_ps(_b_array, _b_weight);
__m128 _output = _mm_add_ps(_a_array, _b_array);
_mm_store_ps(outputPtr, _output);
a_arrayPtr += 4; b_arrayPtr += 4;
outputPtr += 4;
}
for (; w < width; w++) {
*outputPtr = a_weight * (*a_arrayPtr) + b_weight * (*b_arrayPtr);
a_arrayPtr++; b_arrayPtr++;
outputPtr++;
}
#else
for (; w < width; w++) {
*outputPtr = a_weight * (*a_arrayPtr) + b_weight * (*b_arrayPtr);
a_arrayPtr++; b_arrayPtr++;
outputPtr++;
}
#endif
}
}
/// <summary>
/// 计算两个数组的差值
/// </summary>
/// <param name="a_array"></param> 被减数数组a
/// <param name="b_array"></param> 减数数组b
/// <param name="output"></param> 输出两个数组差值结果
/// <param name="width"></param> 图像的宽
/// <param name="height"></param> 图像的高
/// <param name="a_weight"></param> 相减时数组a的权重
/// <param name="b_weight"></param> 相减时数组b的权重
void array_sub(float* a_array, float* b_array, float* output, int width, int height, float a_weight, float b_weight)
{
for (int h = 0; h < height; h++)
{
float* a_arrayPtr = a_array + h * width;
float* b_arrayPtr = b_array + h * width;
float* outputPtr = output + h * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
__m128 _a_array_0 = _mm_loadu_ps(a_arrayPtr);
__m128 _a_array_1 = _mm_loadu_ps(a_arrayPtr + 4);
__m128 _a_array_2 = _mm_loadu_ps(a_arrayPtr + 8);
__m128 _a_array_3 = _mm_loadu_ps(a_arrayPtr + 12);
__m128 _b_array_0 = _mm_loadu_ps(b_arrayPtr);
__m128 _b_array_1 = _mm_loadu_ps(b_arrayPtr + 4);
__m128 _b_array_2 = _mm_loadu_ps(b_arrayPtr + 8);
__m128 _b_array_3 = _mm_loadu_ps(b_arrayPtr + 12);
__m128 _a_weight = _mm_set1_ps(a_weight);
_a_array_0 = _mm_mul_ps(_a_array_0, _a_weight);
_a_array_1 = _mm_mul_ps(_a_array_1, _a_weight);
_a_array_2 = _mm_mul_ps(_a_array_2, _a_weight);
_a_array_3 = _mm_mul_ps(_a_array_3, _a_weight);
__m128 _b_weight = _mm_set1_ps(b_weight);
_b_array_0 = _mm_mul_ps(_b_array_0, _b_weight);
_b_array_1 = _mm_mul_ps(_b_array_1, _b_weight);
_b_array_2 = _mm_mul_ps(_b_array_2, _b_weight);
_b_array_3 = _mm_mul_ps(_b_array_3, _b_weight);
__m128 _output_0 = _mm_sub_ps(_a_array_0, _b_array_0);
__m128 _output_1 = _mm_sub_ps(_a_array_1, _b_array_1);
__m128 _output_2 = _mm_sub_ps(_a_array_2, _b_array_2);
__m128 _output_3 = _mm_sub_ps(_a_array_3, _b_array_3);
_mm_store_ps(outputPtr, _output_0);
_mm_store_ps(outputPtr + 4, _output_1);
_mm_store_ps(outputPtr + 8, _output_2);
_mm_store_ps(outputPtr + 12, _output_3);
a_arrayPtr += 16; b_arrayPtr += 16;
outputPtr += 16;
}
for (; w + 7 < width; w += 8) {
__m128 _a_array_0 = _mm_loadu_ps(a_arrayPtr);
__m128 _a_array_1 = _mm_loadu_ps(a_arrayPtr + 4);
__m128 _b_array_0 = _mm_loadu_ps(b_arrayPtr);
__m128 _b_array_1 = _mm_loadu_ps(b_arrayPtr + 4);
__m128 _a_weight = _mm_set1_ps(a_weight);
_a_array_0 = _mm_mul_ps(_a_array_0, _a_weight);
_a_array_1 = _mm_mul_ps(_a_array_1, _a_weight);
__m128 _b_weight = _mm_set1_ps(b_weight);
_b_array_0 = _mm_mul_ps(_b_array_0, _b_weight);
_b_array_1 = _mm_mul_ps(_b_array_1, _b_weight);
__m128 _output_0 = _mm_sub_ps(_a_array_0, _b_array_0);
__m128 _output_1 = _mm_sub_ps(_a_array_1, _b_array_1);
_mm_store_ps(outputPtr, _output_0);
_mm_store_ps(outputPtr + 4, _output_1);
a_arrayPtr += 8; b_arrayPtr += 8;
outputPtr += 8;
}
for (; w + 3 < width; w += 4) {
__m128 _a_array = _mm_loadu_ps(a_arrayPtr);
__m128 _b_array = _mm_loadu_ps(b_arrayPtr);
__m128 _a_weight = _mm_set1_ps(a_weight);
_a_array = _mm_mul_ps(_a_array, _a_weight);
__m128 _b_weight = _mm_set1_ps(b_weight);
_b_array = _mm_mul_ps(_b_array, _b_weight);
__m128 _output = _mm_sub_ps(_a_array, _b_array);
_mm_store_ps(outputPtr, _output);
a_arrayPtr += 4; b_arrayPtr += 4;
outputPtr += 4;
}
for (; w < width; w++) {
*outputPtr = a_weight * (*a_arrayPtr) - b_weight * (*b_arrayPtr);
a_arrayPtr++; b_arrayPtr++;
outputPtr++;
}
#else
for (; w < width; w++) {
*outputPtr = a_weight * (*a_arrayPtr) - b_weight * (*b_arrayPtr);
a_arrayPtr++; b_arrayPtr++;
outputPtr++;
}
#endif
}
}
/// <summary>
/// 对两个数组计算差值,并取其平方值
/// </summary>
/// <param name="a_array"></param> 被减数数组a
/// <param name="b_array"></param> 减数数组b
/// <param name="output"></param> 输出差值平方结果
/// <param name="width"></param> 图像的宽
/// <param name="height"></param> 图像的高
void array_sub_pow(float* a_array, float* b_array, float* output, int width, int height)
{
for (int h = 0; h < height; h++)
{
float* a_arrayPtr = a_array + h * width;
float* b_arrayPtr = b_array + h * width;
float* outputPtr = output + h * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
__m128 _a_array_0 = _mm_loadu_ps(a_arrayPtr);
__m128 _a_array_1 = _mm_loadu_ps(a_arrayPtr + 4);
__m128 _a_array_2 = _mm_loadu_ps(a_arrayPtr + 8);
__m128 _a_array_3 = _mm_loadu_ps(a_arrayPtr + 12);
__m128 _b_array_0 = _mm_loadu_ps(b_arrayPtr);
__m128 _b_array_1 = _mm_loadu_ps(b_arrayPtr + 4);
__m128 _b_array_2 = _mm_loadu_ps(b_arrayPtr + 8);
__m128 _b_array_3 = _mm_loadu_ps(b_arrayPtr + 12);
__m128 _sub_0 = _mm_sub_ps(_a_array_0, _b_array_0);
__m128 _sub_1 = _mm_sub_ps(_a_array_1, _b_array_1);
__m128 _sub_2 = _mm_sub_ps(_a_array_2, _b_array_2);
__m128 _sub_3 = _mm_sub_ps(_a_array_3, _b_array_3);
__m128 _sub_pow_0 = _mm_mul_ps(_sub_0, _sub_0);
__m128 _sub_pow_1 = _mm_mul_ps(_sub_1, _sub_1);
__m128 _sub_pow_2 = _mm_mul_ps(_sub_2, _sub_2);
__m128 _sub_pow_3 = _mm_mul_ps(_sub_3, _sub_3);
_mm_store_ps(outputPtr, _sub_pow_0);
_mm_store_ps(outputPtr + 4, _sub_pow_1);
_mm_store_ps(outputPtr + 8, _sub_pow_2);
_mm_store_ps(outputPtr + 12, _sub_pow_3);
a_arrayPtr += 16; b_arrayPtr += 16;
outputPtr += 16;
}
for (; w + 7 < width; w += 8) {
__m128 _a_array_0 = _mm_loadu_ps(a_arrayPtr);
__m128 _a_array_1 = _mm_loadu_ps(a_arrayPtr + 4);
__m128 _b_array_0 = _mm_loadu_ps(b_arrayPtr);
__m128 _b_array_1 = _mm_loadu_ps(b_arrayPtr + 4);
__m128 _sub_0 = _mm_sub_ps(_a_array_0, _b_array_0);
__m128 _sub_1 = _mm_sub_ps(_a_array_1, _b_array_1);
__m128 _sub_pow_0 = _mm_mul_ps(_sub_0, _sub_0);
__m128 _sub_pow_1 = _mm_mul_ps(_sub_1, _sub_1);
_mm_store_ps(outputPtr, _sub_pow_0);
_mm_store_ps(outputPtr + 4, _sub_pow_1);
a_arrayPtr += 8; b_arrayPtr += 8;
outputPtr += 8;
}
for (; w + 3 < width; w += 4) {
__m128 _a_array = _mm_loadu_ps(a_arrayPtr);
__m128 _b_array = _mm_loadu_ps(b_arrayPtr);
__m128 _sub = _mm_sub_ps(_a_array, _b_array);
__m128 _sub_pow = _mm_mul_ps(_sub, _sub);
_mm_store_ps(outputPtr, _sub_pow);
a_arrayPtr += 4; b_arrayPtr += 4;
outputPtr += 4;
}
for (; w < width; w++) {
*outputPtr = ((*a_arrayPtr) - (*b_arrayPtr)) * ((*a_arrayPtr) - (*b_arrayPtr));
a_arrayPtr++; b_arrayPtr++;
outputPtr++;
}
#else
for (; w < width; w++) {
*outputPtr = ((*a_arrayPtr) - (*b_arrayPtr)) * ((*a_arrayPtr) - (*b_arrayPtr));
a_arrayPtr++; b_arrayPtr++;
outputPtr++;
}
#endif
}
}
/// <summary>
/// 对两个数组进行点乘运算
/// </summary>
/// <param name="a_array"></param> 乘数数组a
/// <param name="b_array"></param> 乘数数组b
/// <param name="output"></param> 输出点乘计算结果
/// <param name="width"></param> 图像的宽
/// <param name="height"></param> 图像的高
void array_dot_mul(float* a_array, float* b_array, float* output, int width, int height)
{
for (int h = 0; h < height; h++)
{
float* a_arrayPtr = a_array + h * width;
float* b_arrayPtr = b_array + h * width;
float* outputPtr = output + h * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
__m128 _a_array_0 = _mm_loadu_ps(a_arrayPtr);
__m128 _a_array_1 = _mm_loadu_ps(a_arrayPtr + 4);
__m128 _a_array_2 = _mm_loadu_ps(a_arrayPtr + 8);
__m128 _a_array_3 = _mm_loadu_ps(a_arrayPtr + 12);
__m128 _b_array_0 = _mm_loadu_ps(b_arrayPtr);
__m128 _b_array_1 = _mm_loadu_ps(b_arrayPtr + 4);
__m128 _b_array_2 = _mm_loadu_ps(b_arrayPtr + 8);
__m128 _b_array_3 = _mm_loadu_ps(b_arrayPtr + 12);
__m128 _output_0 = _mm_mul_ps(_a_array_0, _b_array_0);
__m128 _output_1 = _mm_mul_ps(_a_array_1, _b_array_1);
__m128 _output_2 = _mm_mul_ps(_a_array_2, _b_array_2);
__m128 _output_3 = _mm_mul_ps(_a_array_3, _b_array_3);
_mm_store_ps(outputPtr, _output_0);
_mm_store_ps(outputPtr + 4, _output_1);
_mm_store_ps(outputPtr + 8, _output_2);
_mm_store_ps(outputPtr + 12, _output_3);
a_arrayPtr += 16; b_arrayPtr += 16;
outputPtr += 16;
}
for (; w + 7 < width; w += 8) {
__m128 _a_array_0 = _mm_loadu_ps(a_arrayPtr);
__m128 _a_array_1 = _mm_loadu_ps(a_arrayPtr + 4);
__m128 _b_array_0 = _mm_loadu_ps(b_arrayPtr);
__m128 _b_array_1 = _mm_loadu_ps(b_arrayPtr + 4);
__m128 _output_0 = _mm_mul_ps(_a_array_0, _b_array_0);
__m128 _output_1 = _mm_mul_ps(_a_array_1, _b_array_1);
_mm_store_ps(outputPtr, _output_0);
_mm_store_ps(outputPtr + 4, _output_1);
a_arrayPtr += 8; b_arrayPtr += 8;
outputPtr += 8;
}
for (; w + 3 < width; w += 4) {
__m128 _a_array = _mm_loadu_ps(a_arrayPtr);
__m128 _b_array = _mm_loadu_ps(b_arrayPtr);
__m128 _output = _mm_mul_ps(_a_array, _b_array);
_mm_store_ps(outputPtr, _output);
a_arrayPtr += 4; b_arrayPtr += 4;
outputPtr += 4;
}
for (; w < width; w++) {
*outputPtr = (*a_arrayPtr) * (*b_arrayPtr);
a_arrayPtr++; b_arrayPtr++;
outputPtr++;
}
#else
for (; w < width; w++) {
*outputPtr = (*a_arrayPtr) * (*b_arrayPtr);
a_arrayPtr++; b_arrayPtr++;
outputPtr++;
}
#endif
}
}
/// <summary>
/// 对两个数组进行点除运算
/// </summary>
/// <param name="a_array"></param> 被除数数组
/// <param name="b_array"></param> 除数数组
/// <param name="output"></param> 输出点除计算结果
/// <param name="width"></param> 图像的宽
/// <param name="height"></param> 图像的高
/// <param name="eps"></param> 除数上的微小数值,以防止除数为0
void array_dot_div(float* a_array, float* b_array, float* output, int width, int height, float eps)
{
for (int h = 0; h < height; h++)
{
float* a_arrayPtr = a_array + h * width;
float* b_arrayPtr = b_array + h * width;
float* outputPtr = output + h * width;
int w = 0;
#ifdef __SIMD__
for (; w + 15 < width; w += 16) {
__m128 _a_array_0 = _mm_loadu_ps(a_arrayPtr);
__m128 _a_array_1 = _mm_loadu_ps(a_arrayPtr + 4);
__m128 _a_array_2 = _mm_loadu_ps(a_arrayPtr + 8);
__m128 _a_array_3 = _mm_loadu_ps(a_arrayPtr + 12);
__m128 _b_array_0 = _mm_loadu_ps(b_arrayPtr);
__m128 _b_array_1 = _mm_loadu_ps(b_arrayPtr + 4);
__m128 _b_array_2 = _mm_loadu_ps(b_arrayPtr + 8);
__m128 _b_array_3 = _mm_loadu_ps(b_arrayPtr + 12);
__m128 _eps = _mm_set1_ps(eps);
__m128 _output_0 = _mm_div_ps(_a_array_0, _mm_add_ps(_b_array_0, _eps));
__m128 _output_1 = _mm_div_ps(_a_array_1, _mm_add_ps(_b_array_1, _eps));
__m128 _output_2 = _mm_div_ps(_a_array_2, _mm_add_ps(_b_array_2, _eps));
__m128 _output_3 = _mm_div_ps(_a_array_3, _mm_add_ps(_b_array_3, _eps));
_mm_store_ps(outputPtr, _output_0);
_mm_store_ps(outputPtr + 4, _output_1);
_mm_store_ps(outputPtr + 8, _output_2);
_mm_store_ps(outputPtr + 12, _output_3);
a_arrayPtr += 16; b_arrayPtr += 16;
outputPtr += 16;
}
for (; w + 7 < width; w += 8) {
__m128 _a_array_0 = _mm_loadu_ps(a_arrayPtr);
__m128 _a_array_1 = _mm_loadu_ps(a_arrayPtr + 4);
__m128 _b_array_0 = _mm_loadu_ps(b_arrayPtr);
__m128 _b_array_1 = _mm_loadu_ps(b_arrayPtr + 4);
__m128 _eps = _mm_set1_ps(eps);
__m128 _output_0 = _mm_div_ps(_a_array_0, _mm_add_ps(_b_array_0, _eps));
__m128 _output_1 = _mm_div_ps(_a_array_1, _mm_add_ps(_b_array_1, _eps));
_mm_store_ps(outputPtr, _output_0);
_mm_store_ps(outputPtr + 4, _output_1);
a_arrayPtr += 8; b_arrayPtr += 8;
outputPtr += 8;
}
for (; w + 3 < width; w += 4) {
__m128 _a_array = _mm_loadu_ps(a_arrayPtr);
__m128 _b_array = _mm_loadu_ps(b_arrayPtr);
__m128 _eps = _mm_set1_ps(eps);
__m128 _output = _mm_div_ps(_a_array, _mm_add_ps(_b_array, _eps));
_mm_store_ps(outputPtr, _output);
a_arrayPtr += 4; b_arrayPtr += 4;
outputPtr += 4;
}
for (; w < width; w++) {
*outputPtr = (*a_arrayPtr) * (1.0f / (*b_arrayPtr + eps));
a_arrayPtr++; b_arrayPtr++;
outputPtr++;
}
#else
for (; w < width; w++) {
*outputPtr = (*a_arrayPtr) * (1.0f / (*b_arrayPtr + eps));
a_arrayPtr++; b_arrayPtr++;
outputPtr++;
}
#endif
}
}
/// <summary>
/// 图像下采样,可以实现原图像的宽和高不同比例的缩小;实现方式是等间隔采样
/// </summary>
/// <param name="src"></param> 输入图像
/// <param name="dest"></param> 缩小后图像
/// <param name="width"></param> 输入图像的宽
/// <param name="height"></param> 输入图像的高
/// <param name="ratio_w"></param> 输入图像宽的缩小比例 缩小后图像尺寸:width * ratio_w
/// <param name="ratio_h"></param> 输入图像高的缩小比例 缩小后图像尺寸:height * ratio_h
void down_sample(float* src, float* dest, int width, int height, float ratio_w, float ratio_h)
{
int width_dest = (int)(width * ratio_w);
int height_dest = (int)(height * ratio_h);
for (int h_dest = 0; h_dest < height_dest; h_dest++)
{
// h_dest * (int)(height / height_dest)为src行等间隔取值的索引,与src的stride -- width相乘换行
// h_dest为下采样后图像的每一行的索引,与下采样后图像的stride -- width_dest相乘换行
float* srcPtr = src + (h_dest * (int)(height / height_dest)) * width;
float* destPtr = dest + h_dest * width_dest;
for (int w_dest = 0; w_dest < width_dest; w_dest++)
{
destPtr[w_dest] = srcPtr[w_dest * (int)(width / width_dest)];
}
}
}
/// <summary>
/// 对图像进行上采样,上采样至宽和高为指定大小
/// </summary>
/// <param name="src"></param> 输入图像
/// <param name="dest"></param> 上采样输出图像
/// <param name="width_src"></param> 输入图像的宽
/// <param name="height_src"></param> 输入图像的高
/// <param name="width_dest"></param> 上采样结果图像的宽
/// <param name="height_dest"></param> 上采样结果图像的高
void up_sample(float* src, float* dest, int width_src, int height_src, int width_dest, int height_dest)
{
// 安全分配临时内存(添加检查)
float* temp = (float*)malloc(height_src * width_dest * sizeof(float));
if (!temp) return; // 内存分配失败处理
// ========== 水平方向插值W ==========
for (int h_src = 0; h_src < height_src; h_src++)
{
float* srcPtr = src + h_src * width_src;
float* tempPtr = temp + h_src * width_dest;
int w_dest = 0;
for (; w_dest < width_dest; w_dest++)
{
// 安全坐标计算(避免越界)
float pos_w = (w_dest + 0.5f) * (width_src - 1.0f) / width_dest - 0.5f;
// 约束在合法范围内 [0, width_src-1]
pos_w = std::fmax(0.0f, std::fmin(pos_w, width_src - 1.0f));
int pos_w_left = (int)pos_w;
int pos_w_right = std::fmin(pos_w_left + 1.0f, width_src - 1.0f); // 右边界保护
// 插值权重 [0,1]
float weight = pos_w - pos_w_left;
// 安全插值
tempPtr[w_dest] = srcPtr[pos_w_left] * (1.0f - weight) + srcPtr[pos_w_right] * weight;
}
}
// ========== 垂直方向插值 ==========
for (int h_dest = 0; h_dest < height_dest; h_dest++)
{
// 计算插值位置(带安全约束)
float pos_h = h_dest * (height_src - 1.0f) / (height_dest - 1.0f);
pos_h = std::fmax(0.0f, std::fmin(pos_h, height_src - 1.0f));
int pos_h_shift = (int)pos_h;
float part_h_bottom = pos_h - pos_h_shift;
float part_h_top = 1.0f - part_h_bottom;
// 获取行指针(带边界保护)
float* temp_topPtr = temp + pos_h_shift * width_dest;
// 底部行安全访问(避免越界)
float* temp_bottomPtr = (pos_h_shift < height_src - 1)
? temp_topPtr + width_dest // 正常情况
: temp_topPtr; // 最后一行时使用顶部行
float* destPtr = dest + h_dest * width_dest;
// SSE优化处理
int w_dest = 0;
#ifdef __SIMD__
__m128 _h_top = _mm_set1_ps(part_h_top);
__m128 _h_bottom = _mm_set1_ps(part_h_bottom);
for (; w_dest + 15 < width_dest; w_dest += 16)
{
// 加载顶部行的16个float(分4组 每组4个)
__m128 _top_0 = _mm_loadu_ps(temp_topPtr + w_dest); // 像素w_dest --- w_dest+3
__m128 _top_1 = _mm_loadu_ps(temp_topPtr + w_dest + 4); // 像素w_dest+4 --- w_dest+7
__m128 _top_2 = _mm_loadu_ps(temp_topPtr + w_dest + 8); // 像素w_dest+8 --- w_dest+11
__m128 _top_3 = _mm_loadu_ps(temp_topPtr + w_dest + 12); // 像素w_dest+12 ---W w_dest+15
// 加载底部行的16个float(与顶部行对应)
__m128 _bottom_0 = _mm_loadu_ps(temp_bottomPtr + w_dest);
__m128 _bottom_1 = _mm_loadu_ps(temp_bottomPtr + w_dest + 4);
__m128 _bottom_2 = _mm_loadu_ps(temp_bottomPtr + w_dest + 8);
__m128 _bottom_3 = _mm_loadu_ps(temp_bottomPtr + w_dest + 12);
// 双线性插值计算:top * weight_top + bottom * weight_bottom(每组4个像素)
__m128 _res_0 = _mm_add_ps(_mm_mul_ps(_top_0, _h_top), _mm_mul_ps(_bottom_0, _h_bottom));
__m128 _res_1 = _mm_add_ps(_mm_mul_ps(_top_1, _h_top), _mm_mul_ps(_bottom_1, _h_bottom));
__m128 _res_2 = _mm_add_ps(_mm_mul_ps(_top_2, _h_top), _mm_mul_ps(_bottom_2, _h_bottom));
__m128 _res_3 = _mm_add_ps(_mm_mul_ps(_top_3, _h_top), _mm_mul_ps(_bottom_3, _h_bottom));
// 存储16个结果到dest
_mm_storeu_ps(destPtr + w_dest, _res_0);
_mm_storeu_ps(destPtr + w_dest + 4, _res_1);
_mm_storeu_ps(destPtr + w_dest + 8, _res_2);
_mm_storeu_ps(destPtr + w_dest + 12, _res_3);
}
for (; w_dest + 7 < width_dest; w_dest += 8)
{
__m128 _top_0 = _mm_loadu_ps(temp_topPtr + w_dest);
__m128 _top_1 = _mm_loadu_ps(temp_topPtr + w_dest + 4);
__m128 _bottom_0 = _mm_loadu_ps(temp_bottomPtr + w_dest);
__m128 _bottom_1 = _mm_loadu_ps(temp_bottomPtr + w_dest + 4);
__m128 _res_0 = _mm_add_ps(_mm_mul_ps(_top_0, _h_top), _mm_mul_ps(_bottom_0, _h_bottom));
__m128 _res_1 = _mm_add_ps(_mm_mul_ps(_top_1, _h_top), _mm_mul_ps(_bottom_1, _h_bottom));
_mm_storeu_ps(destPtr + w_dest, _res_0);
_mm_storeu_ps(destPtr + w_dest + 4, _res_1);
}
for (; w_dest + 3 < width_dest; w_dest += 4)
{
__m128 _top = _mm_loadu_ps(temp_topPtr + w_dest);
__m128 _bottom = _mm_loadu_ps(temp_bottomPtr + w_dest);
__m128 _res = _mm_add_ps(_mm_mul_ps(_top, _h_top), _mm_mul_ps(_bottom, _h_bottom));
_mm_storeu_ps(destPtr + w_dest, _res);
}
// 处理剩余像素(带边界保护)
for (; w_dest < width_dest; w_dest++)
{
float top_val = temp_topPtr[w_dest];
// 最后一行时使用顶部值
float bottom_val = (pos_h_shift < height_src - 1) ? temp_bottomPtr[w_dest] : top_val;
destPtr[w_dest] = top_val * part_h_top + bottom_val * part_h_bottom;
}
#else
for (; w_dest < width_dest; w_dest++)
{
float top_val = temp_topPtr[w_dest];
// 最后一行时使用顶部值
float bottom_val = (pos_h_shift < height_src - 1) ? temp_bottomPtr[w_dest] : top_val;
destPtr[w_dest] = top_val * part_h_top + bottom_val * part_h_bottom;
}
#endif
}
free(temp); // 释放临时内存
}
int main()
{
// 读取灰度图像
cv::Mat image = cv::imread("xxx", cv::IMREAD_UNCHANGED);
// 检查图像是否成功读取
if (image.empty()) {
printf("Unable to load the input image!\n");
return -1;
}
// 获取图像宽度和高度
int width = image.cols; int height = image.rows;
int64 st = cv::getTickCount();
unsigned char* imageData = new unsigned char[width * height * 3 * sizeof(unsigned char)];
unsigned char* darkData = new unsigned char[width * height * sizeof(unsigned char)];
// 将图像数据复制到 unsigned char* 数组
memcpy(imageData, image.data, width * height * 3 * sizeof(unsigned char));
dark_function(imageData, darkData, width, height, width * 3);
//cv::Mat dark_result(height, width, CV_8UC1, darkData);
//cv::imwrite("dark.png", dark_result);
/************************************* min-filter for dark image *************************************/
float* dark_float = new float[width * height * sizeof(float)];
cvt_u_f(darkData, dark_float, width, height);
float* dark_min_float = new float[width * height * sizeof(float)];
// the patch-size is 15x15
// 取值为21和论文贴切
min_filter(dark_float, dark_min_float, width, height, 15);
//cv::Mat dark_min_result(height, width, CV_32FC1, dark_min_float);
//cv::imwrite("dark_min.png", dark_min_result);
/************************************* min-filter for dark image *************************************/
/************************************* estimate the airlight vector *************************************/
unsigned char* dark_minData = new unsigned char[width * height * sizeof(unsigned char)];
cvt_f_u(dark_min_float, dark_minData, width, height);
int A_b = 0; int A_g = 0; int A_r = 0;
airlight_estimation(imageData, dark_minData, width, height, width * 3, &A_b, &A_g, &A_r);
std::cout << "The airlight in channel blue is: " << A_b << std::endl
<< "The airlight in channel green is: " << A_g << std::endl
<< "The airlight in channel red is: " << A_r << std::endl;
/************************************* estimate the airlight vector *************************************/
// 后面的浮点计算归一化处理
/************************************* handling the sky regions *************************************/
// 依据公式(23), (24)计算Ic及其天空优化处理的图像
float* Ic = new float[width * height * sizeof(float)];
float* Ic_refine = new float[width * height * sizeof(float)];
sky_handling(imageData, Ic, Ic_refine, width, height, width * 3, A_b, A_g, A_r);
//cv::Mat Ic_result(height, width, CV_32FC1, Ic);
//Ic_result.convertTo(Ic_result, CV_8UC1, 255.0);
//cv::imwrite("Ic_result.png", Ic_result);
//cv::Mat Ic_refine_result(height, width, CV_32FC1, Ic_refine);
//Ic_refine_result.convertTo(Ic_refine_result, CV_8UC1, 255.0);
//cv::imwrite("Ic_refine_result.png", Ic_refine_result);
/************************************* handling the sky regions *************************************/
// 计算Ibeta和Iroi
// 使用下采样和上采样的方法对计算过程进行加速,即对Ic_refine进行下采样,对trans进行上采样
// float ratio = 0.5; 宽和高等比例下采样和上采样
// 因为使用了下采样,计算时图像尺寸缩小为原来一半,所以maxmin_size和box_size也适时缩小
/************************************* estimation of middle maps in paper *************************************/
// 对Ic_refine宽和高等比例下采样,宽和高缩小为原来一半
float down_ratio = 0.5f;
int down_width = width * down_ratio; int down_height = height * down_ratio;
float* Ic_refine_down = new float[down_width * down_height * sizeof(float)];
down_sample(Ic_refine, Ic_refine_down, width, height, down_ratio, down_ratio);
int maxmin_size = 15;
int box_radius = 5; int box_size = 2 * box_radius + 1;
float* Imin_down = new float[down_width * down_height * sizeof(float)];
min_filter(Ic_refine_down, Imin_down, down_width, down_height, maxmin_size);
// 计算I_beta (15)-(16)
float* umin_down = new float[down_width * down_height * sizeof(float)];
box_filter(Imin_down, umin_down, down_width, down_height, box_size);
float* Ibeta_down = new float[down_width * down_height * sizeof(float)];
max_filter(umin_down, Ibeta_down, down_width, down_height, maxmin_size);
// 计算I_roi (17)
float* ubeta_down = new float[down_width * down_height * sizeof(float)];
box_filter(Ibeta_down, ubeta_down, down_width, down_height, box_size);
float* uc_down = new float[down_width * down_height * sizeof(float)];
box_filter(Ic_refine_down, uc_down, down_width, down_height, box_size);
float* ubeta_div_uc = new float[down_width * down_height * sizeof(float)];
float eps = 0.0000001f;
array_dot_div(ubeta_down, uc_down, ubeta_div_uc, down_width, down_height, eps);
float* Iroi_down = new float[down_width * down_height * sizeof(float)];
array_dot_mul(Ic_refine_down, ubeta_div_uc, Iroi_down, down_width, down_height);
// calculate the reliability map alpha (18)-(19)
float* Ibeta_umin_pow = new float[down_width * down_height * sizeof(float)];
float* Ibeta_Iroi_pow = new float[down_width * down_height * sizeof(float)];
array_sub_pow(Ibeta_down, umin_down, Ibeta_umin_pow, down_width, down_height);
array_sub_pow(Ibeta_down, Iroi_down, Ibeta_Iroi_pow, down_width, down_height);
float* pow_sum = new float[down_width * down_height * sizeof(float)];
array_add(Ibeta_umin_pow, Ibeta_Iroi_pow, pow_sum, down_width, down_height, 1.0f, 1.0f);
float* uepsilon = new float[down_width * down_height * sizeof(float)];
box_filter(pow_sum, uepsilon, down_width, down_height, box_size);
float* ones = new float[down_width * down_height * sizeof(float)];
for (int i = 0; i < down_width * down_height; i++) {
ones[i] = 1.0f;
}
float zeta = 0.0025f;
array_dot_div(uepsilon, uepsilon, uepsilon, down_width, down_height, zeta);
float* alpha_down = new float[down_width * down_height * sizeof(float)];
array_sub(ones, uepsilon, alpha_down, down_width, down_height, 1.0f, 1.0f);
/************************************* estimation of middle maps in paper *************************************/
/************************************* estimation of the transmission map *************************************/
// calculate the transmission map (20)-(22)
float* Ialphabeta_down = new float[down_width * down_height * sizeof(float)];
array_dot_mul(alpha_down, Ibeta_down, Ialphabeta_down, down_width, down_height);
float* ualpha_down = new float[down_width * down_height * sizeof(float)];
float* ualphabeta_down = new float[down_width * down_height * sizeof(float)];
box_filter(alpha_down, ualpha_down, down_width, down_height, box_size);
box_filter(Ialphabeta_down, ualphabeta_down, down_width, down_height, box_size);
float* alpha_down_coefs = new float[down_width * down_height * sizeof(float)];
float* Iroi_down_coefs = new float[down_width * down_height * sizeof(float)];
array_sub(ones, ualpha_down, alpha_down_coefs, down_width, down_height, 1.0f, 1.0f);
array_dot_mul(Iroi_down, alpha_down_coefs, Iroi_down_coefs, down_width, down_height);
float* Idark_down = new float[down_width * down_height * sizeof(float)];
array_add(Iroi_down_coefs, ualphabeta_down, Idark_down, down_width, down_height, 1.0f, 1.0f);
float* trans_down = new float[down_width * down_height * sizeof(float)];
array_sub(ones, Idark_down, trans_down, down_width, down_height, 1.0f, 0.95f);
// 将上采样前后数据进行对比,尺寸较小的时候,指令集最多一次处理4个像素或8个像素:否则出现边缘未处理的情况
//cv::Mat trans_down_result(down_height, down_width, CV_32FC1, trans_down);
//trans_down_result.convertTo(trans_down_result, CV_8UC1, 255.0);
//cv::imwrite("trans_down_result.png", trans_down_result);
// 对估计得到的trans进行上采样,放大到图像原来的尺寸
float* trans = new float[width * height * sizeof(float)];
up_sample(trans_down, trans, down_width, down_height, width, height);
//cv::Mat trans_result(height, width, CV_32FC1, trans);
//trans_result.convertTo(trans_result, CV_8UC1, 255.0);
//cv::imwrite("trans_result.png", trans_result);
/************************************* estimation of the transmission map *************************************/
/************************************* get the haze-free recovery result *************************************/
// 复原结果 (9)
unsigned char* recoverData = new unsigned char[width * height * 3 * sizeof(unsigned char)];
recover(imageData, recoverData, trans, width, height, width * 3, A_b, A_g, A_r);
/************************************* get the haze-free recovery result *************************************/
double duration = (cv::getTickCount() - st) / cv::getTickFrequency() * 1000;
std::cout << "Dehazing time delay: " << duration << "ms;" << std::endl;
/************************************* write the recovery result *************************************/
cv::Mat recover(height, width, CV_8UC3, recoverData);
cv::imwrite("recover.png", recover);
/************************************* write the recovery result *************************************/
// 所估计的 alpha 图像中边缘可能过于明显,以至于复原结果会有边缘效应
// 可以尽量缩小最大值滤波,最小值滤波和盒子滤波的窗口,以消除边缘效应
delete[] imageData;
delete[] darkData; delete[] dark_float; delete[] dark_min_float; delete[] dark_minData;
delete[] Ic; delete[] Ic_refine; delete[] Ic_refine_down;
delete[] Imin_down; delete[] umin_down;
delete[] Ibeta_down; delete[] ubeta_down;
delete[] uc_down; delete[] ubeta_div_uc;
delete[] Iroi_down; delete[] Ibeta_umin_pow; delete[] Ibeta_Iroi_pow;
delete[] pow_sum; delete[] uepsilon; delete[] ones;
delete[] alpha_down; delete[] Ialphabeta_down; delete[] ualpha_down; delete[] ualphabeta_down;
delete[] alpha_down_coefs; delete[] Iroi_down_coefs; delete[] Idark_down;
delete[] trans_down; delete[] trans;
delete[] recoverData;
recover.release();
return 0;
}
Efficient Image Dehazing with Boundary Constraint and Contextual Regularization
Gaofeng Meng, Ying Wang, Jiangyong Duan, Shiming Xiang, Chunhong Pan
National Laboratory of Pattern Recognition, Institute of Automation
Chinese Academy of Science, Beijing, P.R. China
本文依然依据大气散射模型进行图像去雾,则大气散射模型在此处不再叙述,直接介绍去雾算法。雾天图像中某一点像素处的雾气比例由传输函数决定,根据大气散射模型变形可得传输函数的倒数的表达式为:

考虑到图像中像素的灰度值总是有一定的界限,设其上界和下界分别为![]() 和
和![]() ,则无雾场景用边界条件界定为:
,则无雾场景用边界条件界定为:
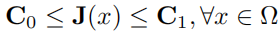
图像中的各个元素分量及其示意图如下图所示:

对于每一个![]() ,均对应一个
,均对应一个![]() ,由上图中的几何关系可得:
,由上图中的几何关系可得:
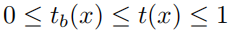
其中![]() 为
为![]() 的下界,由下式给出:
的下界,由下式给出:
 再对
再对![]() 作最大值滤波和最小值滤波,可得到传输函数的粗略估计值:
作最大值滤波和最小值滤波,可得到传输函数的粗略估计值:
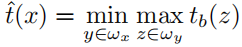
下面通过加权LI范数正则化对初始估计的传输函数进行优化:通常,图像中矩形窗口中邻近像素具有相似的景深,可用下式描述该规律:
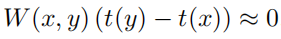
其中![]() 为权重函数,有很多种权重函数可以选择,本文选取关于雾天图像像素灰度值的高斯分布函数:
为权重函数,有很多种权重函数可以选择,本文选取关于雾天图像像素灰度值的高斯分布函数:

其中![]() 为预设系数。则关于传输函数
为预设系数。则关于传输函数![]() 的正则化表达式为:
的正则化表达式为:

其中,![]() 表示整幅图像区域,
表示整幅图像区域, 为以像素
为以像素 为中心的邻域。上式表示连续积分的过程,由于图像为离散化的数据,则上式的离散化形式为:
为中心的邻域。上式表示连续积分的过程,由于图像为离散化的数据,则上式的离散化形式为:
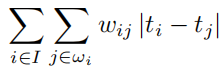
其中,![]() 为图像像素的索引,
为图像像素的索引,![]() 为
为![]() 的离散化形式。
的离散化形式。
若引入微分算子,则正则化的离散形式公式为:

该式进一步精简为:

其中,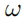 表示矩形领域窗口中所有像素的集合,运算符
表示矩形领域窗口中所有像素的集合,运算符![]() 表示像素灰度值的点乘,
表示像素灰度值的点乘,![]() 为卷积算符,
为卷积算符,![]() 为一阶微分算子,
为一阶微分算子,![]() 表示权重矩阵。
表示权重矩阵。
将前面所述的高斯分布函数的权重函数用微分算子的形式重新表述为(即![]() ):
):
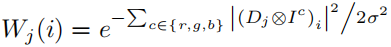
文中选择了多个![]() 微分算子,如下:
微分算子,如下:

作者在估计大气光向量![]() 时,选取了何恺明的方法:首先计算雾天图像的暗通道图像,然后取对应于暗通道图像的最亮的0.1%像素处的原雾天图像像素,计算这些像素处三个通道灰度值的平均值,即可得到大气光向量
时,选取了何恺明的方法:首先计算雾天图像的暗通道图像,然后取对应于暗通道图像的最亮的0.1%像素处的原雾天图像像素,计算这些像素处三个通道灰度值的平均值,即可得到大气光向量![]() 。
。
接下来着重介绍传输函数的优化过程。首先定义关于传输函数![]() 的目标函数:
的目标函数:

其中第一项为数据项,衡量![]() 与边界条件得到的传输函数
与边界条件得到的传输函数![]() 之间的相似程度,
之间的相似程度,![]() 为平衡数据项与正则项的系数。
为平衡数据项与正则项的系数。
为了优化该目标函数,引入辅助项![]() 以构造一个新的代价函数(cost function):
以构造一个新的代价函数(cost function):

其中,![]() 为权重系数。
为权重系数。
对于固定系数![]() ,最小化损失函数的过程即为分别关于
,最小化损失函数的过程即为分别关于![]() 和
和![]() 求解最优化的过程,求解过程为:首先固定
求解最优化的过程,求解过程为:首先固定![]() 求解
求解![]() 的最优解,然后固定
的最优解,然后固定![]() 求解
求解![]() 的最优解。
的最优解。
具体步骤如下:1,优化![]() :若
:若![]() 固定,则正则化函数变为:
固定,则正则化函数变为:

该优化过程可归结为如下形式的最优化问题:
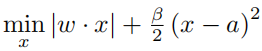
其中,系数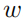 ,
,![]() 和
和![]() 已经给出,则该最优化问题可直接通过下式解出:
已经给出,则该最优化问题可直接通过下式解出:
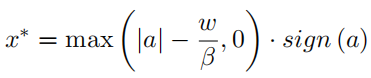
2,优化![]() :若固定损失函数中的
:若固定损失函数中的![]() 分量,则损失函数可进一步简化为:
分量,则损失函数可进一步简化为:
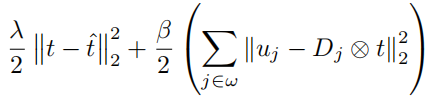
对上式关于![]() 求导并变形,且令求解结果为0,可得:
求导并变形,且令求解结果为0,可得:

其中![]() 通过算子
通过算子![]() 关于中心像素作镜像得到,对上式两边作2D傅里叶变换和傅里叶逆变换,可解得
关于中心像素作镜像得到,对上式两边作2D傅里叶变换和傅里叶逆变换,可解得![]() 的最优解
的最优解![]() 为:
为:
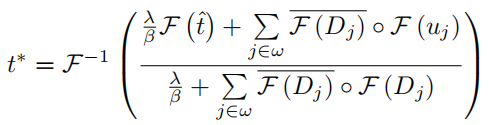
其中![]() 表示傅里叶变换,
表示傅里叶变换,![]() 表示傅里叶逆变换,
表示傅里叶逆变换,![]() 表示复数共轭。
表示复数共轭。
需要不断迭代参数![]() 以求解上述最优化过程,将
以求解上述最优化过程,将![]() 从
从![]() 增加到
增加到![]() ,且增加的步长为
,且增加的步长为![]() 。
。
在实验过程中,参数选择分别为:![]() ,
,![]() 和
和![]() 。
。
使用C++实现本文的代码如下:
#include <iostream> #include <stdlib.h> #include <time.h> #include <cmath> #include <algorithm> #include <opencv2/opencv.hpp> #include <opencv2/highgui/highgui.hpp> #include <opencv2/imgproc/imgproc.hpp> using namespace cv; using namespace std; Mat minFilter(Mat& input, int kernelSize); Mat boundCon(Mat& srcimg, float *airlight, int C0, int C1); Mat calTrans(Mat& srcimg, Mat& t, float lambda, float param); Mat calWeight(Mat& srcimg, Mat& kernel, float param); Mat fft2(Mat I, Size size); void ifft2(const Mat &src, Mat &Fourier); void psf2otf(Mat& src, int rows, int cols, Mat& dst); void circshift(Mat& img, int dw, int dh, Mat& dst); Mat sign(Mat& input); Mat fliplr(Mat& input); Mat flipud(Mat& input); Mat recover(Mat& srcimg, Mat& t, float *airlight, float delta); int main() { clock_t start, finish; double duration; cout << "A defog program" << endl << "----------------" << endl; Mat image = imread("forest.png"); imshow("hazyiamge", image); cout << "input hazy image" << endl; Mat resizedImage; int originRows = image.rows; int originCols = image.cols; double scale = 1.0; if (scale < 1.0) { resize(image, resizedImage, Size(originCols * scale, originRows * scale)); } else { scale = 1.0; resizedImage = image; } start = clock(); int rows = resizedImage.rows; int cols = resizedImage.cols; int nr = rows; int nl = cols; Mat convertImage(nr, nl, CV_32FC3); resizedImage.convertTo(convertImage, CV_32FC3, 1 / 255.0, 0); vector<Mat> channels(3); split(convertImage, channels); Mat R = channels[2]; Mat G = channels[1]; Mat B = channels[0]; int kernelSize = 15; Mat minImgR = minFilter(channels[2], kernelSize); Mat minImgG = minFilter(channels[1], kernelSize); Mat minImgB = minFilter(channels[0], kernelSize); double RminValue = 0, RmaxValue = 0; Point RminPt, RmaxPt; minMaxLoc(minImgR, &RminValue, &RmaxValue, &RminPt, &RmaxPt); cout << RmaxValue << endl; double GminValue = 0, GmaxValue = 0; Point GminPt, GmaxPt; minMaxLoc(minImgG, &GminValue, &GmaxValue, &GminPt, &GmaxPt); cout << GmaxValue << endl; double BminValue = 0, BmaxValue = 0; Point BminPt, BmaxPt; minMaxLoc(minImgB, &BminValue, &BmaxValue, &BminPt, &BmaxPt); cout << BmaxValue << endl; float A[3]; A[0] = BmaxValue; A[1] = GmaxValue; A[2] = RmaxValue; Mat trans = boundCon(convertImage, A, 30, 300); imshow("t", trans); int s = 3; Mat element; Mat transrefine; element = getStructuringElement(MORPH_ELLIPSE, Size(s, s)); morphologyEx(trans, transrefine, CV_MOP_CLOSE, element); imshow("transrefine", transrefine); float lambda = 2.0; float param = 0.5; Mat finaltrans = calTrans(convertImage, transrefine, lambda, param); imshow("finaltrans", finaltrans); float delta = 0.85; Mat recoverimg = recover(convertImage, finaltrans, A, delta); imshow("recover", recoverimg); recoverimg.convertTo(recoverimg, CV_8UC3, 255.0, 0); imwrite("recover.png", recoverimg); finish = clock(); duration = (double)(finish - start); cout << "defog used " << duration << "ms time;" << endl; waitKey(0); return 0; } Mat minFilter(Mat& input, int kernelSize) { int row = input.rows; int col = input.cols; int radius = kernelSize / 2; Mat parseImage; copyMakeBorder(input, parseImage, radius, radius, radius, radius, BORDER_REPLICATE); Mat output = Mat::zeros(input.rows, input.cols, CV_32FC1); for (unsigned int r = 0; r < row; r++) { float *fOutData = output.ptr<float>(r); for (unsigned int c = 0; c < col; c++) { Rect ROI(c, r, kernelSize, kernelSize); Mat imageROI = parseImage(ROI); double minValue = 0, maxValue = 0; Point minPt, maxPt; minMaxLoc(imageROI, &minValue, &maxValue, &minPt, &maxPt); *fOutData++ = minValue; } } return output; } Mat boundCon(Mat& srcimg, float *airlight, int C0, int C1) { int nr = srcimg.rows; int nl = srcimg.cols; float c0 = C0 / 255.0; float c1 = C1 / 255.0; Mat trans = Mat::zeros(nr, nl, CV_32FC1); float airlight0 = airlight[0]; float airlight1 = airlight[1]; float airlight2 = airlight[2]; for (unsigned int r = 0; r < nr; r++) { float* srcPtr = srcimg.ptr<float>(r); float* tPtr = trans.ptr<float>(r); float B, G, R; float t_b, t_g, t_r; float tb; float tmax = 1.0; for (unsigned int c = 0; c < nl; c++) { B = *srcPtr++; G = *srcPtr++; R = *srcPtr++; t_b = std::max((airlight0 - B) / (airlight0 - c0), (B - airlight0) / (c1 - airlight0)); t_g = std::max((airlight1 - G) / (airlight1 - c0), (G - airlight1) / (c1 - airlight1)); t_r = std::max((airlight2 - R) / (airlight2 - c0), (R - airlight2) / (c1 - airlight2)); tb = t_b > t_g ? t_b : t_g; tb = tb > t_r ? tb : t_r; tb = std::min(tb, tmax); *tPtr++ = tb; } } return trans; } Mat calTrans(Mat& srcimg, Mat& t, float lambda, float param) { int nsz = 3; int NUM = nsz * nsz; int nr = t.rows; int nl = t.cols; Size size = t.size(); Mat kernel1 = (Mat_<float>(3, 3) << 5, 5, 5, -3, 0, -3, -3, -3, -3); Mat kernel2 = (Mat_<float>(3, 3) << -3, 5, 5, -3, 0, 5, -3, -3, -3); Mat kernel3 = (Mat_<float>(3, 3) << -3, -3, 5, -3, 0, 5, -3, -3, 5); Mat kernel4 = (Mat_<float>(3, 3) << -3, -3, -3, -3, 0, 5, -3, 5, 5); Mat kernel5 = (Mat_<float>(3, 3) << 5, 5, 5, -3, 0, -3, -3, -3, -3); Mat kernel6 = (Mat_<float>(3, 3) << -3, -3, -3, 5, 0, -3, 5, 5, -3); Mat kernel7 = (Mat_<float>(3, 3) << 5, -3, -3, 5, 0, -3, 5, -3, -3); Mat kernel8 = (Mat_<float>(3, 3) << 5, 5, -3, 5, 0, -3, -3, -3, -3); normalize(kernel1, kernel1, 1.0, 0.0, NORM_L2); normalize(kernel2, kernel2, 1.0, 0.0, NORM_L2); normalize(kernel3, kernel3, 1.0, 0.0, NORM_L2); normalize(kernel4, kernel4, 1.0, 0.0, NORM_L2); normalize(kernel5, kernel5, 1.0, 0.0, NORM_L2); normalize(kernel6, kernel6, 1.0, 0.0, NORM_L2); normalize(kernel7, kernel7, 1.0, 0.0, NORM_L2); normalize(kernel8, kernel8, 1.0, 0.0, NORM_L2); Mat d = Mat::zeros(3, 3, CV_32FC(8)); vector<Mat> dchannels(8); split(d, dchannels); dchannels[0] = kernel1; dchannels[1] = kernel2; dchannels[2] = kernel3; dchannels[3] = kernel4; dchannels[4] = kernel5; dchannels[5] = kernel6; dchannels[6] = kernel7; dchannels[7] = kernel8; Mat wfun = Mat::zeros(nr, nl, CV_32FC(8)); vector<Mat> wfunchannels(8); for (int k = 0; k < 8; k++) { wfunchannels[k] = calWeight(srcimg, dchannels[k], param); } Mat Tf; Tf=fft2(t,size); Mat D = Mat::zeros(nr, nl, CV_32FC(8)); Mat DS = Mat::zeros(nr, nl, CV_32FC1); vector<Mat> Dchannels(8); split(D, Dchannels); for (int k = 0; k < 8; k++) { psf2otf(dchannels[k], nr, nl, Dchannels[k]); Mat Dchannels_temp = Mat::zeros(nr, nl, CV_32FC1); vector<Mat> Dchannels_temp1(2); split(Dchannels[k], Dchannels_temp1); magnitude(Dchannels_temp1[0], Dchannels_temp1[1], Dchannels_temp); pow(Dchannels_temp, 2, Dchannels_temp); DS += Dchannels_temp; } float beta = 1.0; float beta_rate = 2 * sqrt(2); float beta_max = 256; while (beta < beta_max) { float gamma = lambda / beta; Mat dt = Mat::zeros(nr, nl, CV_32FC(8)); Mat u = Mat::zeros(nr, nl, CV_32FC(8)); Mat DU = Mat::zeros(nr, nl, CV_32FC2); vector<Mat> dtchannels(8); split(dt, dtchannels); vector<Mat> uchannels(8); split(u, uchannels); for (int k = 0; k < 8; k++) { float zero = 0.0; filter2D(t, dtchannels[k], t.depth(), dchannels[k]); uchannels[k] = max(abs(dtchannels[k]) - (1 / (8 * beta)) * wfunchannels[k], zero).mul(sign(dtchannels[k])); Mat dfliplr = fliplr(dchannels[k]); Mat dflipud = flipud(dfliplr); filter2D(uchannels[k], uchannels[k], uchannels[k].depth(), dflipud); Mat DUtemp; DUtemp=fft2(uchannels[k],size); DU += DUtemp; } Mat ifft; Mat tfftup = gamma * Tf + DU; Mat tfftdown = gamma * Mat::ones(nr, nl, CV_32FC1) + DS; vector<Mat> tfft_temp(2); split(tfftup, tfft_temp); tfft_temp[0] = tfft_temp[0] / tfftdown; tfft_temp[1] = tfft_temp[1] / tfftdown; Mat final_tfft; merge(tfft_temp, final_tfft); ifft2(final_tfft, ifft); t = abs(ifft); beta = beta * beta_rate; } Mat trans(nr, nl, CV_32FC1); trans = t; return trans; } Mat calWeight(Mat& srcimg, Mat& kernel, float param) { int nr = srcimg.rows; int nl = srcimg.cols; Mat wfun; float weight = -1 / (param * 2); vector<Mat> channels(3); split(srcimg, channels); Mat d_b; Mat d_g; Mat d_r; filter2D(channels[0], d_b, channels[0].depth(), kernel); filter2D(channels[1], d_g, channels[1].depth(), kernel); filter2D(channels[2], d_r, channels[2].depth(), kernel); exp(weight * (d_b.mul(d_b) + d_g.mul(d_g) + d_r.mul(d_r)), wfun); return wfun; } Mat fft2(Mat I, Size size) { Mat If = Mat::zeros(I.size(), I.type()); Size dftSize; // compute the size of DFT transform dftSize.width = getOptimalDFTSize(size.width); dftSize.height = getOptimalDFTSize(size.height); // allocate temporary buffers and initialize them with 0's Mat tempI(dftSize, I.type(), Scalar::all(0)); //copy I to the top-left corners of temp Mat roiI(tempI, Rect(0, 0, I.cols, I.rows)); I.copyTo(roiI); if (I.channels() == 1) { dft(tempI, If, DFT_COMPLEX_OUTPUT); } else { vector<Mat> channels; split(tempI, channels); for (int n = 0; n<I.channels(); n++) { dft(channels[n], channels[n], DFT_COMPLEX_OUTPUT); } cv::merge(channels, If); } return If(Range(0, size.height), Range(0, size.width)); } void ifft2(const Mat &src, Mat &Fourier) { int mat_type = src.type(); assert(mat_type < 15); if (mat_type < 7) { Mat planes[] = { Mat_<double>(src), Mat::zeros(src.size(), CV_64F) }; merge(planes, 2, Fourier); dft(Fourier, Fourier, DFT_INVERSE + DFT_SCALE, 0); } else { Mat tmp; dft(src, tmp, DFT_INVERSE + DFT_SCALE, 0); vector<Mat> planes; split(tmp, planes); magnitude(planes[0], planes[1], planes[0]); Fourier = planes[0]; } } void psf2otf(Mat& src, int rows, int cols, Mat& dst) { Mat src_fill = Mat::zeros(rows, cols, CV_32FC1); Mat src_fill_out = Mat::zeros(rows, cols, CV_32FC1); for (int i = 0; i < src.rows; i++) { float* data = src_fill.ptr<float>(i); float* data2 = src.ptr<float>(i); for (int j = 0; j < src.cols; j++) { data[j] = data2[j]; } } Size size; size.height = rows; size.width = cols; circshift(src_fill, -int(src.rows / 2), -int(src.cols / 2), src_fill_out); dst = fft2(src_fill_out, size); return; } void circshift(Mat& img, int dw, int dh, Mat& dst) { int rows = img.rows; int cols = img.cols; dst = img.clone(); if (dw < 0 && dh < 0) { for (int i = 0; i < rows; i++) { int t = i + dw; if (t >= 0) { float* data = img.ptr<float>(i); float* data2 = dst.ptr<float>(t); for (int j = 0; j < cols; j++) { data2[j] = data[j]; } } else { float* data = img.ptr<float>(i); float* data2 = dst.ptr<float>(dst.rows + t); for (int j = 0; j < cols; j++) { data2[j] = data[j]; } } } for (int j = 0; j < cols; j++) { int t = j + dh; if (t >= 0) { for (int i = 0; i < rows; i++) { float* data = img.ptr<float>(i); float* data2 = dst.ptr<float>(i); data2[t] = data[j]; } } else { for (int i = 0; i < rows; i++) { float* data = img.ptr<float>(i); float* data2 = dst.ptr<float>(i); data2[dst.cols + t] = data[j]; } } } } return; } Mat sign(Mat& input) { int nr = input.rows; int nl = input.cols; Mat output(nr, nl, CV_32FC1); for (int i = 0; i < nr; i++) { const float* inData = input.ptr<float>(i); float* outData = output.ptr<float>(i); for (int j = 0; j < nl; j++) { if (*inData > 0) { *outData = 1; } else if (*inData < 0) { *outData = -1; } else { *outData = 0; } outData++; } } return output; } Mat fliplr(Mat& input) { int nr = input.rows; int nl = input.cols; Mat output(nr, nl, CV_32FC1); float temp; for (int i = 0; i < nr; i++) { for (int j = 0; j < (nl - 1) / 2 + 1; j++) { temp = input.at<float>(i, j); output.at<float>(i, j) = input.at<float>(i, nl - j - 1); output.at<float>(i, nl - j - 1) = temp; } } return output; } Mat flipud(Mat& input) { int nr = input.rows; int nl = input.cols; Mat output(nr, nl, CV_32FC1); float temp; for (int i = 0; i < (nr - 1) / 2 + 1; i++) { for (int j = 0; j < nl; j++) { temp = input.at<float>(i, j); output.at<float>(i, j) = input.at<float>(nr - 1 - i, j); output.at<float>(nr - 1 - i,j) = temp; } } return output; } Mat recover(Mat& srcimg, Mat& t, float *airlight, float delta) { int nr = srcimg.rows, nl = srcimg.cols; float tnow = t.at<float>(0, 0); float t0 = 0.0001; Mat finalimg = Mat::zeros(nr, nl, CV_32FC3); float val = 0; for (unsigned int r = 0; r < nr; r++) { const float* transPtr = t.ptr<float>(r); const float* srcPtr = srcimg.ptr<float>(r); float* outPtr = finalimg.ptr<float>(r); for (unsigned int c = 0; c < nl; c++) { tnow = *transPtr++; tnow = std::max(tnow, t0); pow(tnow, delta); for (int i = 0; i < 3; i++) { val = (*srcPtr++ - airlight[i]) / tnow + airlight[i]; *outPtr++ = val; } } } return finalimg; }
为了节省篇幅,在此仅举一例实验结果:




雾天图像 原始传输函数 正则化后的传输函数 复原结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号