es6学习3:正则梳理
前言:
简单理解正则, 大致从这几个方面
[ 1: 创建形式 2: 元字符和转义字符 3: 数词量词 4: 分组 5: 修饰符 6:常用方法 7: 附加功能 ]
一、创建形式
// case 1: var reg1 = /a/g; // 为正则边界 // case 2: var reg2 = new RegExp(/a/g); // 与上一个不同的是方便把变量生成为正则条件 // case 3: let reg3 = new RegExp(/a/,'g'); // es6专用
二、元字符和转义字符
.................元字符.................
\t => tab 水平制表符
\v => 垂直制表符 (不太清除干嘛用的, 有研究的朋友可以回复下~)
\n => 换行
\r => 回车换行符 (不太请拿出\r\n的区别, 只知道linux和windows下有些差异, 并且\r是相当于敲了了个回车, \n还记得html中中肿么用的嘛~)
\0 => 空字符 
\f => 换页 (没用到过不敢说)
\cx =>对应ctrl+x (没用到过不敢说)
.................常见转义字符.................

三、数词 量词 边界控制
正则的使用经常伴随着如下模式 / (数词)(量词) / (修饰) 如 var reg = /a{5}/gi;
.................数词.................
case 预定义类型:
\w => 匹配字母或数字或下划线或汉字 等价于 '[A-Za-z0-9_]'。
\s => 空格
\d => [0-9]
\u{xxxx} => 直接键入unicode编码
case 非预定义类型:
/avenda/ => 对应avenda单词
/1234/ => 对应1234
/\.\\\?\-/ => 对应.\?-
case 类对象 (占一个位置, 内部为所有满足条件的条件):
[\dabc] => 数字或者abc
case 非与或:
(1|2|3) => 1或2或3 等同于[123] //'或'一般结合分组使用
[^\d] =>非数字 // '非'一般用于类对象中, 如果不是在类对象中则表示以xx开始
case 条件断言 (跟在一个正则单元后面判断是否满足条件):
(?= xxx) 例: 'AvendaAvenda2333'.replace(/avenda(?=\d)/ig,'X') 这里是把后面为数字的avenda替换为X字母, i修饰符为忽略大小写
.................量词.................
量词表达出现的数量, 跟在量词后面做循环判定
? => 最多1次 例: /a?/ 最多出现一次a或者没有
+ => 最少1次 例: /a+/ 至少出现1次
* => 任意次数 例: /a*/
{n} 出现n次 例: /a{3}/出现3次
{n, m} 出现n到m次 例: /a{2,3}/出现2或3次
{n, } 至少出现n次 例: /a{2,}/至少出现2次
{0, n} 最多出现n此 例: /a{0,3}/最多出现3次
.................边界控制.................
\b 匹配单词边界 例: 'this is'.replace(/\bis\b/,'X') => 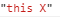
\B 匹配非单词边界 例: 'this is'.replace(/\Bis\b/,'X') => 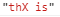
^ 行头, 放在类元素[] 里表示 '非'
$ 行尾
四、分组 ( '(xxx)' )
为什么要用分组?...
情景1 :
var reg = new RegExp('(^|&)age=([^&]*)($|&)');
// 分组1 :(^|&) => 开头为行首或者'&'
// 默认分组2 : 'age=' => 切出匹配'age=的元素'
// 分组3 :([^&]*) => 若干个不是字符'&'的元素, 换言之, 遇到字符'&'则停下来
// 分组4 :(&|$) => 以字符'&'或者行尾结束
reg.exec('name=avenda&age=15');
output:
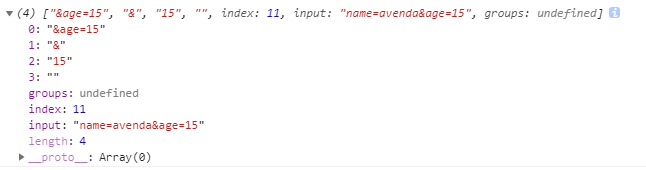
请看数组2元素, 是了, 就是为了拿到age的值
那么 ... 拿name的值呢?
var reg = new RegExp('(^|&)name=([^&]*)($|&)');
reg.exec('name=avenda&age=15');
output:
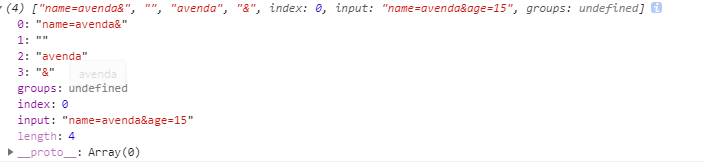
结论1: 我们可以利用分组借助exec或者match方法去把数据划分为数组片段, 从而拿到我们需要的值,
每一个分组都可以形成一个数组元素
情景2 :
var str = '666hahaAvenda';
var reg = /(\d{3})(\w{4})(\w{6})/i;
str.replace(reg,'$3$1$2');
output:

结论2: 分组后, 每个分组元素会对应 $1 $2 $3 变量, 可以通过变量来进行增删改
五、修饰符
/ / 没修饰符时, 匹配到一个后停止, 不会再继续进行匹配
/ /g 全局匹配, g修饰符时, 会一直匹配直到没有满足条件的元素位置
/ /y 全局匹配-黏连模式, y修饰符时, 匹配完第一个满足元素后, 第二个满足元素必须紧挨着第一个元素, 中间有任何元素哪怕一个空格也会停止匹配
/ /i 忽略大小写
/ /m 多行匹配(受换行符影响)
/ /u 对unicode超过0xFFFF的字符支持, 如 /\u{20BB7}/.test('𠮷') -> false /\u{20BB7}/u.test('𠮷') -> true
例: /a/gi => 匹配所有a元素忽略大小写
六、常用方法
正则本身方法:
exec(str)
特性: 会返回结果数组
test(str)
特性; 会返回boolean
字符串方法:
str.replace(reg, newStr)
str.match(reg)
特性: 受全局g修饰符比较大
扩展: 循环match
var regex = /t(e)(st(\d?))/g; //注意一定要加g, 不然会无限循环 var string = 'test1test2test3'; var matches = []; var match; while (match = regex.exec(string)) { matches.push(match); }
七、附加说明
对象属性:
例子: var reg = /a/gi ;
reg.lastIndex 连续匹配时候, 匹配元素的坐标 => 0-n
reg.source 连续匹配时候, 匹配元素的坐标 => a
reg.flags 正则修饰符 => gi
贪婪模式与非贪婪模式
贪婪模式(默认) '12334444'.replace(/\d{3,6}/,'X') => 
费贪婪模式(尽可能少的匹配, 尾部加?) '12334444'.replace(/\d{3,6}?/,'X') => 
推荐一些不错的工具和文档
正则解析(知道自己打的正则匹配含义): https://regexper.com/#%0A
正则匹配测试: https://regexr.com/
转载一个常用正则: https://www.cnblogs.com/myTerritory/p/6855932.html
es6的一些api: http://es6.ruanyifeng.com/#README
一些坑:
1. '.'不可以代表任意字符, 如果unicode编码大于2个字符则.失效 应对: 加u修饰符
2. ^非的话一定要写在[]里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号