RAG入门
RAG 检索增强生成(Retrieval Augmented Generation),已经成为当前最火热的LLM应用方案和打开方式了。比如常见的智能客服,就是rag的应用。
既然有了 deepseek 这种成熟的大模型,为什么还需要 rag 呢?
举个例子,比如你是一个卖自行车的电商店家,你怎么构建一个卖自行车的智能客服呢?如果直接使用 deepseek 的话,他可不知道你店里面,具体有什么自行车以及价格分别是多少?于是你又想,那我每次提问的时候,都把店铺清单,一起送给大模型不就可以了吗?如果你的进货单有几百页,每次都送给大模型,太影响效率了,而且大模型会有 上下文窗口大小限制, 传入的东西,不能太多。而且传入大量的上下文,会严重影响模型的推理速度。此时,就需要 rag登场了
rag 流程图解
提问前
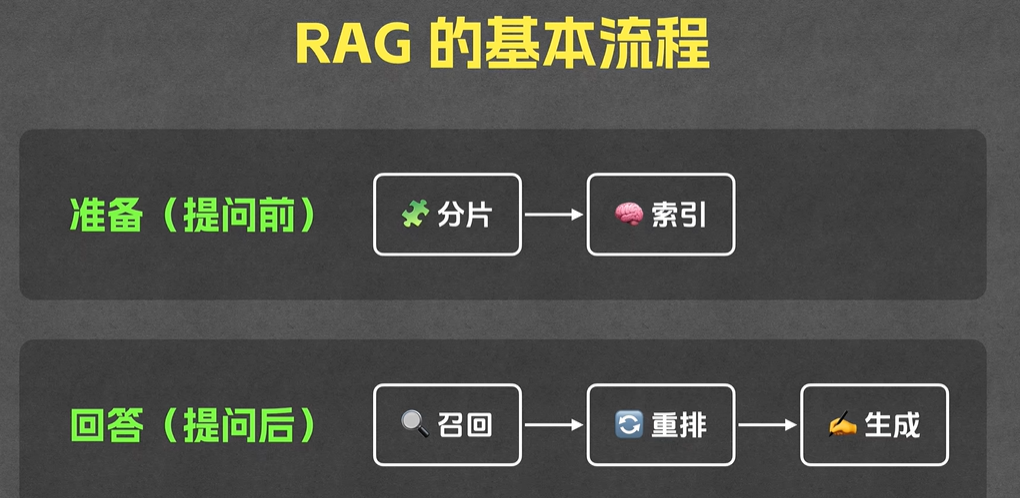
提问后
rag 流程梳理
# 自行车款式及价格参考指南
## 一、通勤代步自行车
适合日常城市短途出行、买菜、通勤等场景,注重舒适性和实用性。
| 车型名称 | 品牌 | 主要特点 | 参考价格(人民币) |
|------------------|-----------------|-----------------------------------------------|-------------------|
| 捷安特 ATX 660 | 捷安特(Giant) | 铝合金车架,21速变速,机械碟刹,适合城市及轻度郊游 | 1,598 - 1,898元 |
| 美利达 勇士500D | 美利达(Merida) | 24速变速,液压碟刹,减震前叉,耐用性强 | 1,699 - 1,999元 |
| 迪卡侬 BTWIN TILT 500 | 迪卡侬(Decathlon) | 单速设计,轻便易维护,带挡泥板和后货架 | 799 - 999元 |
| 永久 C 型复古通勤车 | 永久(Forever) | 复古造型,皮带传动(免维护),内置发电机照明 | 1,299 - 1,599元 |
## 二、山地自行车
适合野外越野、山地骑行,具备强减震、高通过性特点。
| 车型名称 | 品牌 | 主要特点 | 参考价格(人民币) |
|--------------------------|---------------------|---------------------------------------------------|-------------------|
| 捷安特 XTC 800 | 捷安特 | 27.5英寸轮径,24速变速,气压减震前叉,液压碟刹 | 3,598 - 4,298元 |
| 美利达 挑战者 300 | 美利达 | 铝合金车架,27速变速,肩控锁死减震前叉,培林花鼓 | 3,299 - 3,899元 |
| 崔克(Trek)Marlin 7 | 崔克 | 29英寸轮径,1×10速变速,液压碟刹,适合复杂地形 | 4,598 - 5,298元 |
| 闪电(Specialized)Rockhopper Comp | 闪电 | 27速变速,铝合金液压成型车架,线控减震前叉 | 5,990 - 6,590元 |
## 三、公路自行车
主打轻量、高速,适合长途骑行、竞速,路面需平坦。
| 车型名称 | 品牌 | 主要特点 | 参考价格(人民币) |
|------------------------|-------------|-----------------------------------------------|-------------------|
| 捷安特 TCR SL 2 | 捷安特 | 铝合金车架,16速变速,碳纤维前叉,气动轮组 | 4,998 - 5,598元 |
| 美利达 Scultura 400 | 美利达 | 轻量化铝合金车架,18速变速,培林中轴 | 4,299 - 4,899元 |
| 迪卡侬 Triban RC520 | 迪卡侬 | 碳纤维前叉,10速变速,适合入门公路骑行 | 2,799 - 3,299元 |
| 崔克 Domane AL 3 | 崔克 | endurance几何设计(长距离舒适),10速变速 | 6,298 - 6,898元 |
## 四、折叠自行车
方便携带和收纳,适合地铁通勤、短途出行,车内/电梯内易存放。
| 车型名称 | 品牌 | 主要特点 | 参考价格(人民币) |
|----------------------|---------------------|-----------------------------------------------|-------------------|
| 大行(DAHON)K3 Plus | 大行 | 16英寸轮径,6速变速,铝合金车架,折叠后体积小 | 2,199 - 2,599元 |
| 捷安特 TCR Fold | 捷安特 | 20英寸轮径,8速变速,快拆折叠设计 | 3,598 - 4,198元 |
| 欧亚马(OYAMA)CR16 | 欧亚马 | 16英寸轮径,16速变速,轻量化设计 | 1,899 - 2,299元 |
| Brompton M6L | Brompton(英国) | 16英寸轮径,6速变速,折叠后可推行,高端折叠车代表 | 8,990 - 12,990元 |
## 五、电动助力自行车
自带电机辅助骑行,省力适合长距离通勤或爬坡,需注意部分地区上牌规定。
| 车型名称 | 品牌 | 主要特点 | 参考价格(人民币) |
|----------------------------|-------------|-----------------------------------------------|-------------------|
| 小牛(Niu)电动助力车 | 小牛 | 续航50-80km,智能APP连接,锂电可拆卸 | 3,999 - 5,499元 |
| 雅迪(Yadea)F3 | 雅迪 | 续航60-100km,助力模式三档可调,带后货架 | 4,299 - 5,999元 |
| 捷安特 Momentum Voya E+ | 捷安特 | 250W电机,续航80-120km,铝合金车架 | 7,998 - 9,598元 |
## 说明
1. 价格因配置、渠道(线上/线下)、促销活动可能存在差异,以上为常规参考价。
2. 入门级车型(1000-3000元)适合日常通勤;中高端车型(3000-8000元)适合进阶骑行需求;专业级车型(8000元以上)针对竞速、越野等专业场景。
3. 购买时建议结合自身用途(通勤/运动/长途)、预算及身高(选择合适车架尺寸)综合考虑。
提问前的操作
首先,我们需要将一段文本切按照某种规则,分成多个段落,每个段落,我们需要 embedding 的模型,计算出来一个向量,存储在向量数据库chromadb中。这里的知识点
- 分片: 由于如上的 markdown 文档,段落之前关系明确,可以直接按照段落切分。不同情况,需要考虑不同的切分方式
- 创建索引:
embedding模型,会将每个片段运算,最后形成一个固定长度的组数(就是数学中的向量,有点类似于hash函数,无论传入什么,最后都是),数组之间的距离,表示语义之间的关系 - 入库: 最后将运算结果,存储到专门的向量数据库中
chromadb
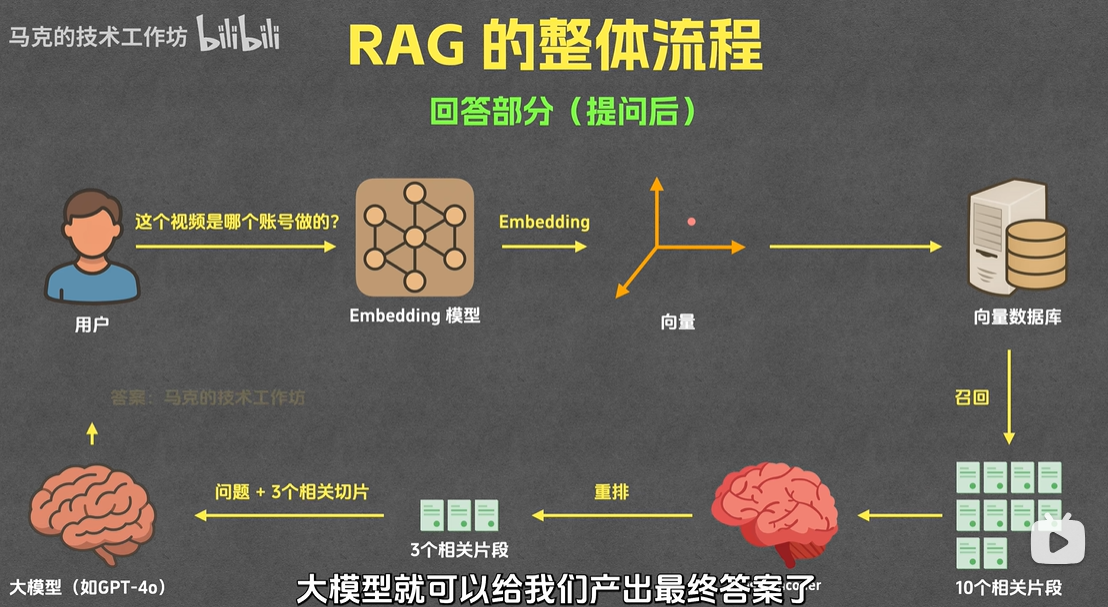
提问后的操作
- 召回: 提问的时候,我们会将提出的问题,通过
embedding转换为向量,传给向量数据库,获取 10 条最相似的结果 - 重排: 是从召回的10条记录中,使用精度更高的算法,取出 3 条关系最相关的片段,一起传给大模型。
- 生成: 将重拍后的 3 条记录,连同问题,已一种固定的格式
prompt传个大模型
代码实现
安装 DeepSeek
先安装 ollama,然后使用 ollama 安装 deepseek,建议使用 gpu+ docker的方式安装,其他模型支持,可以查看 ollama 官网 https://ollama.com/search
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
docker exec -it ollama ollama run deepseek-r1:8b
代码分片
import re
import nltk
nltk.download("punkt")
def split_markdown(md_text, max_chunk_chars=1500):
"""
Markdown 智能分片(按标题、表格、句子)
"""
# 步骤 1:按二级标题切段
sections = re.split(r"\n(?=## )", md_text)
chunks = []
for sec in sections:
sec = sec.strip()
if not sec:
continue
# 如果超过最大长度,继续进行句子分割
if len(sec) > max_chunk_chars:
chunks.extend(split_long_text(sec, max_chunk_chars))
else:
chunks.append(sec)
return chunks
def split_long_text(text, max_chars):
"""
对超长文本按句子切割,防止 chunk 过大
"""
sentences = nltk.sent_tokenize(text)
chunks = []
buf = ""
for sent in sentences:
if len(buf) + len(sent) > max_chars:
chunks.append(buf.strip())
buf = sent
else:
buf += " " + sent
if buf.strip():
chunks.append(buf.strip())
return chunks
# --------------------------
# 测试
# --------------------------
if __name__ == "__main__":
with open("bike.md", "r", encoding="utf-8") as f:
md = f.read()
chunks = split_markdown(md)
embeding 过程
embedding_model = SentenceTransformer("shibing624/text2vec-base-chinese")
def embed_chunk(chunk: str) -> List[float]:
embedding = embedding_model.encode(chunk, normalize_embeddings=True)
return embedding.tolist()
将结果存入到数据库中
import chromadb
from typing import List
#chromadb_client = chromadb.EphemeralClient()
chromadb_client = chromadb.PersistentClient("./chroma.db")
chromadb_collection = chromadb_client.get_or_create_collection(name="default")
def save_embeddings(chunks: List[str], embeddings: List[List[float]]) -> None:
for i, (chunk, embedding) in enumerate(zip(chunks, embeddings)):
chromadb_collection.add(
documents=[chunk],
embeddings=[embedding],
ids=[str(i)]
)
save_embeddings(chunks, embeddings)
召回和重排
import re
import nltk
from typing import List
from sentence_transformers import SentenceTransformer
import chromadb
from sentence_transformers import CrossEncoder
def retrieve(query: str, top_k: int) -> List[str]:
query_embedding = embed_chunk(query)
results = chromadb_collection.query(
query_embeddings=[query_embedding],
n_results=top_k
)
return results['documents'][0]
query = "山地自行车的平均价格"
retrieved_chunks = retrieve(query, 4)
def rerank(query: str, retrieved_chunks: List[str], top_k: int) -> List[str]:
# cross_encoder = CrossEncoder('cross-encoder/mmarco-mMiniLMv2-L12-H384-v1')
cross_encoder = CrossEncoder("./cross-encoder-model") # 本地路径
pairs = [(query, chunk) for chunk in retrieved_chunks]
scores = cross_encoder.predict(pairs)
scored_chunks = list(zip(retrieved_chunks, scores))
scored_chunks.sort(key=lambda x: x[1], reverse=True)
return [chunk for chunk, _ in scored_chunks][:top_k]
reranked_chunks = rerank(query, retrieved_chunks, 3)
最后调用 deepseek 接口
# from dotenv import load_dotenv
import requests
import json
from typing import List
# load_dotenv()
# Ollama 部署的 deepseek-r1:8b 接口地址(端口为 11434)
# OLLAMA_API = "http://localhost:11434/api/generate"
OLLAMA_API = "http://127.0.0.1:11434/api/generate"
# OLLAMA_API = "http://172.29.35.188:11434/api/generate"
# 模型名称(需与 Ollama 中拉取的模型名一致)
MODEL_NAME = "deepseek-r1:8b"
def generate(query: str, chunks_text) -> str:
# chunks_text = "\n\n".join(chunks)
# 构建提示词(保持与检索片段的关联)
prompt_content = f"""你是知识助手,仅根据以下用户问题和提供的参考片段回答,不编造信息。
用户问题: {query}
参考片段:
{chunks_text}
请基于上述片段作答。"""
print(f"{prompt_content}\n\n---\n")
# 构造 Ollama 格式的请求参数
payload = {
"model": MODEL_NAME,
"prompt": prompt_content,
"stream": False, # 关闭流式输出,直接获取完整回答
"options": {
"max_tokens": 1024, # 最大生成长度
"temperature": 0.3, # 低温度保证准确性
"top_p": 0.9,
},
}
try:
# 调用 Ollama 接口(端口 11434)
response = requests.post(
url=OLLAMA_API,
headers={"Content-Type": "application/json"},
data=json.dumps(payload),
# proxies={"http": None, "https": None}, # 禁用代理
timeout=(5, 200),
)
if response.status_code == 200:
result = response.json()
# Ollama 返回格式中,生成内容在 "response" 字段
return result.get("response", "未生成有效回答")
else:
return (
f"模型调用失败,状态码: {response.status_code},详情: {response.text}"
)
except Exception as e:
return f"调用出错: {str(e)}"
# 使用示例
query = "山地自行车的平均价格"
# reranked_chunks = ["..."] # 检索到的相关片段
# answer = generate(query, reranked_chunks)
with open("chunks.txt", "r", encoding="utf-8") as f:
chunks_text = f.read()
answer = generate(query, chunks_text)
print(answer)
最终结果如下
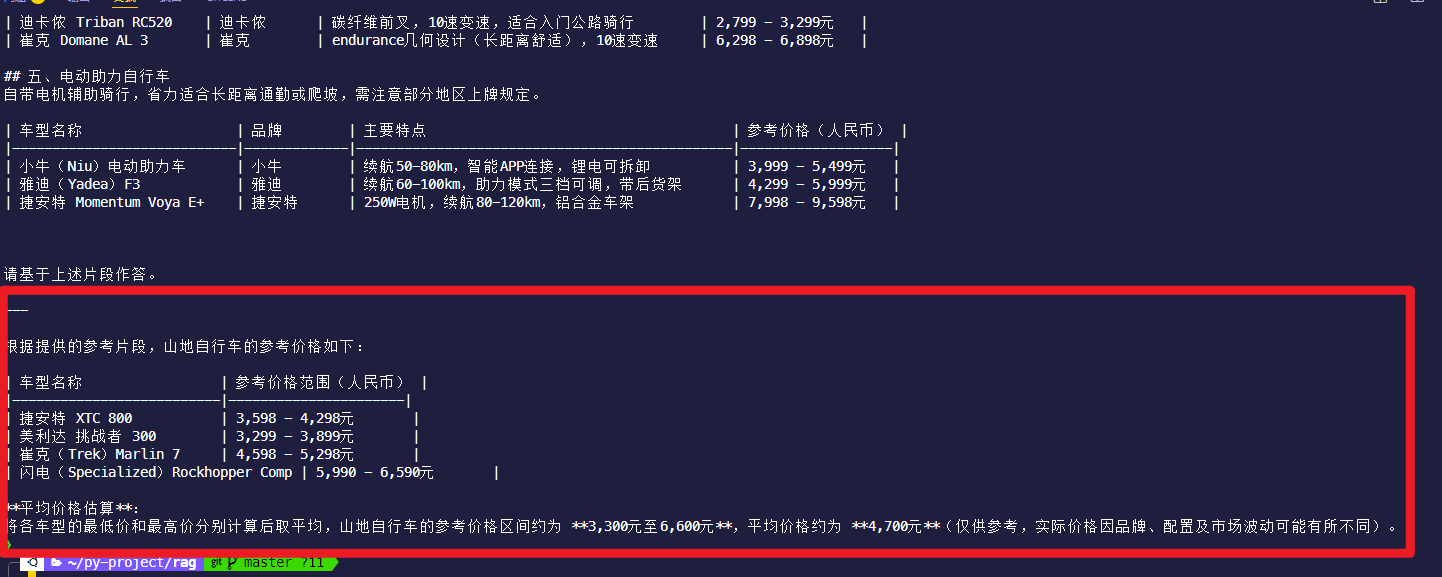
参考文献
【RAG 工作机制详解,一个高质量知识库背后的技术全流程】 https://www.bilibili.com/video/BV1JLN2z4EZQ/?share_source=copy_web&vd_source=80cf96a12f63a1720dfc645c2eb041c0
【这就是RAG 一看就懂的个人知识库架构】 https://www.bilibili.com/video/BV19RJhzyEWN/?share_source=copy_web&vd_source=80cf96a12f63a1720dfc645c2eb041c0
https://github.com/MarkTechStation/VideoCode

 浙公网安备 33010602011771号
浙公网安备 33010602011771号