
数据结构与算法学习之路(java语言)一
本文是本人在学习过程中的一些笔记,如有错误请见谅。
一、引论
学习数据结构和算法需要离散数学以及程序设计个一些概念作为支柱,我认为算法的设计更像是数学模型的搭建,我们需要在搭建过程中考虑运行性能和近乎所有会出现的状况。
以下的笔记主要出自《数据结构与算法分析》机械工业出版社。
先来说一下递归吧,因为递归在算法中的使用频率非常高,而且也是高级算法的基础。
递归的简要特性说明:
当一个函数用自己来定义时就称之为递归。虽然java允许函数是递归的,但是对于数值的计算来说并不是很适合,java提供的仅仅只是遵循递归思想的一种尝试,不是所有的数学递归函数都能被有效的由java的递归来模拟实现。
在设计递归方法时,优先考虑基准情形(即方法的出口),再进行递归调用。
递归调用并不是循环推理,它一定会朝着一个基准情形无限推进。
递归过程所有递归调用都要能够运行,考虑这一基本法则时结合数学中的归纳法。
再求解一个问题的同时,切勿在不同递归调用中做重复性的工作。
二、算法分析
说到算法就一定会有好坏之分,那么怎么区分算法的好坏呢?这里会引入两个概念,时间复杂度和空间复杂度。
当有一个算法需要估算时间复杂度,我们一般会以最坏情况为标准去估算时间,因此复杂度也一样会抛弃低阶计算一个上界O。实际上分析的结果为程序在一定时间范围内能够终止提供了保障,程序可能提前结束但是 绝不可能错后。
下面是一个简单的for循环例子:
1 public static int sum(int n) { 2 int partiaSum; 3 4 partiaSum = 0; 5 for (int i = 1; i <= n; i++) { 6 partiaSum += i*i*i; 7 } 8 return partiaSum; 9 }
这个算法计算∑i^3,那么要计算时间复杂度,首先所有的声明不计时间,第4行和第8行各占一个时间单位,第6行每执行一次占用4个时间单位会进行两次乘法,一次加法和一次赋值,执行n次共使用4n个时间单位,第5行在初始化i、测试i<=n和对i自增存在开销,初始化1个,测试为n+1个,自增为n个共2n+2个时间单位,我们忽略调用方法和返回值的开销,得到总量为6n+4个时间单位。因此我们说该方法时间复杂度为O(N)。空间复杂度则可以看此算法所创建的变量数量,这里为两个变量partiaSum和i。
三、表
说表之前先介绍一个概念:抽象数据类型(Abstract Data Type),指的是带有一组操作的一些对象的组合。对于集合ADT,可以由添加、删除、查询等操作。表、栈、队列这三种数据结构就是最基本的ADT例子。

处理形如上图A0到An-1的一般表,我们定义A0是A1的前驱,A2是A1的后继,A0将没有前驱,An-1也没有后继。
我么需要对表进行操作比如插入,删除那么我们把表当成一个单纯的数组进行操作就不是一个太好的选择,因此我们会处理另一种数据结构:链表

为了避免插入和删除的线性开销,我们需要保证表可以不连续存储,否则一旦更改表的元素,表的的某个整体都需要移动。链表由一系列节点组成,这些节点不必在内存中相连,每一个节点均包含有表元素和到包含元素的后继元节点的链(next链)。最后一个节点的next链指向null。
remove方法可以通过一修改一个next引用来实现,insert方法需要使用new操作符从系统取得一个新节点,此后执行两次引用调整。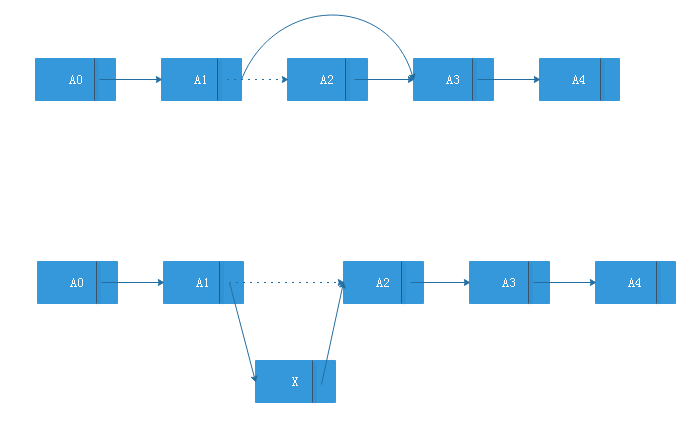
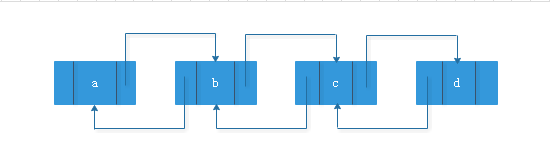
在这种链表结构中我们想要查找某个节点的数值需要遍历链表,因为节点的信息中并不会保存其前驱的任何信息,若我们想要删除最后一个节点则需要花费最长的查找时间,所以我们的做法是让每一个节点持有一个指向它在表中的前驱节点的链,作为双链表。
四、Java Collections API中的表
上一篇说明了表的基本结构,那么在Java中如何实现的呢?在jdk类库中,Java语言包含有一些普通数据结构的实现叫做Collections API。表ADT是在其中的实现的数据结构之一。
先来说明一下Collection接口,它存储一组数据类型相同的对象,还扩展了Iterable(迭代)接口。实现Iterable接口的那些可以拥有增强的for循环,该循环施于这些类之上以观察它们所有的项,实现Iteratable接口的集合必须提供一个成为Iterator的方法,该方法返回一个Iterator类型的对象。Iterator接口的思路是:通过iterator方法,每个集合均可创建并返回给用户一个实现Iterator接口的对象,并将当前位置的概念在对象内部存储下来,每次对next()的调用都给出集合的下一项,hasNext来表示是否存在下一项。
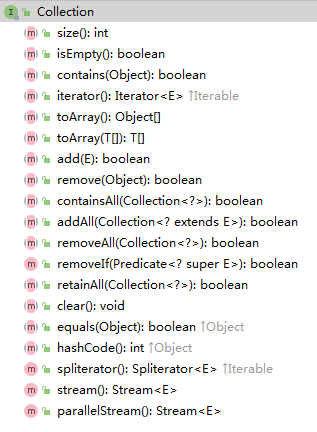
由于Iterator接口中的方法有限,很难使用iterator做简单遍历之外的任何操作。Iterator接口还包含一个remove(),该方法可以删除由next()最新返回的项。我们可以看到Collection也有一个remove(),但是这里的Iterator.remov()有更多的优点。Collection的rm方法需要知道所要删除的项的准确位置,那么删除此项还需要遍历或者给出此项的位置。若使用迭代器则可以进行更有效率的有序的删除,比如在集合中每隔一项删除一项。


当直接使用Iterator(而不是通过增强for循环间接使用)时,我们需要注意:如果对正在被迭代的集合进行结构上的改变(即对该集合使用add(),remove()或clear()等),那么迭代器将不再合法并且会抛出Concurrent-ModificationException。所以只有在立即需要使用一个迭代器的时候,我们才应该获取迭代器,其中如果迭代器调用自己的remove()那么这个迭代器仍然是合法的。
五、List接口
List方接口继承了Collection接口,使其包含Collection接口的所有方法外加其他一些方法。最重要方法有四个:get(index)、set(index,element)、add(index,element)、remove(index);
get和set使得用户可以访问或改变通过由位置索引index也就是传入参数给定表中指定位置上的项。索引0位于表的前端,索引size()-1代表表中最后一项,二索引size()则表示新添加的项可以被放置的位置,add使得在位置index处置入一个新的项并把其后的项向后位移一个位置。remove也是同理会先删除指定位置上的项再将其后项向前位移一个位置。最后,List接口指定listiterator方法,它将产生比通常认为的还要复杂的迭代器。List作为一个接口它有两种用的最多的实现方式。ArrayList类提供了List的一种可增长数组的实现,使用ArrayList的优点在于,对get和set的调用花费常数时间。其缺点是新项的插入和现有项的删除代价昂贵。另一种为LinkedList,使用LinkedList的优点自安于,新项的插入和现有项的删除开销很小,这里假设变动项的位置是已知的。这意味着,在表的前端执行删除和添加都是常数时间,由此LinkedList提供了addFirst()、removeFirst()、addLast()、remove()等以有效添加、删除和访问表的两端。它的缺点是不容易索引,因此对get的调用是昂贵的,除非调用非常接近表两端的项。我们考察对一个List进行某些方法的操作:
public static void makeList1(List<Integer> lst, int N) {
lst.clear();
for (int i = 0; i < N; i++)
lst.add(i);
}
我们在末端添加项时,不管时ArrayList还是LinkedList作为参数被传递,makeList1()的运行时间都是O(N),因为对add的每次调用都是在末端进行从而均花费常数时间。
public static void makeList2(List<Integer> lst, int N) {
lst.clear();
for (int i = 0; i < N; i++)
lst.add(0,i);
}
我们在前端添加项时,对于LinkedList它的运行时间是O(N),但是对于ArrayList其运行时间是O(N^2)。
public static int sum(List<Integer> lst) {
int total = 0;
for (int i = 0; i < N; i++) {
total+=lst.get( i );
}
return total;
}
我们再计算一下List中所有数的和,这里ArrayList的运行时间是O(N),但对于LinkedList来说,其运行时间则是O(N^2),因为在LinkedList中每进行一次get操作所需时间为O(N)。但是这里如果使用迭代器进行增强for循环,那么它对任意List的运行时间都是O(N),因为迭代器将有效地从一项到下一项推进。对于搜索而言,ArrayList和LinkedList都是低效的。
ArrayList中有一个容量的概念,它表示基础数组的大小。在需要的时候自动增加其容量以保证它至少具有所需要的表的大小。如果该大小的数组已经存在,呢么ensureCapacity()可以设置容量为一个足够大的量以避免数组容量之后的扩展。再有trimToSize()会在所有ArrayList添加操作完使用以避免浪费空间。
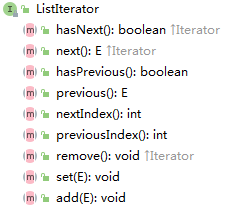
关于ListIterator接口,它扩展了Iterator的功能,新增了几个方法,previous和hasPrevious使得对表从后向前遍历的操作可以完成。add方法将一个新的项以当前位置放入表中。当前项的概念通过把迭代器看作是在对next方法的调用所给出的项和对previous方法的调用给出的项之间抽象出来的。下图为这种抽象效果。
1.正常起始点,next返回2,previous是非法的,而add会把项放在2之前;
2.next返回4,previous返回2,而add则把项添加在2和4之间;
3.next非法,previous返回8,而add则把项置于8后;
六、ArrayList类的实现
我们将会模拟ArrayList泛型类的实现但是不会将全部方法列出。为了避免与java类库中的类相混淆,这里把我们的类叫MyArrayList。主要会有以下细节:
1.MyArrayList将会保持基础数组,数组的容量以及存储在MyArrayList中的当前项数;
2.MyArrayList将会提供一种机制以改变基础数组的容量。通过获得一个新数组,将老数组拷贝到新数组中来改变数组的容量,允许虚拟机回收老数组;
3.MyArrayList将提供set()和get()实现;
4MyArrayList将提供基本的例程,如size()、isEmpty()和clear()。
5MyArrayList将提供一个实现Iterator接口的类,这个类将存储迭代序列中的下一项的下标,并提供next()、hasNext()和remove()等方法的实现。MyArrayList的迭代器方法直接返回实现Iterator接口的该类的新构造实例。
1 public class MyArrayList<E> implements Iterable<E>{
2 private static final int DEFAULT_CAPACITY = 10;
3
4 //MyArrayList把大小及数组作为其数据成员进行存储
5 private int theSize;
6 private E[] theElements;
7
8 public MyArrayList() { doClear(); }
9
10 //几个短例程实现
11 public void clear() { doClear(); }
12 public void doClear() {
13 theSize = 0;
14 ensureCapacity(DEFAULT_CAPACITY);
15 }
16 public int size() { return theSize; }
17 public boolean isEmpty() { return size() == 0; }
18 public void trimToSize() { ensureCapacity(size()); }
19
20 //get方法实现
21 public E get(int idx) {
22 if (idx < 0 || idx >= size())throw new ArrayIndexOutOfBoundsException();
23 return theElements[idx];
24 }
25
26 //set方法实现
27 public E set(int idx, E element) {
28 if (idx < 0 || idx >= size()) throw new ArrayIndexOutOfBoundsException();
29 E old = theElements[idx];
30 theElements[idx] = element;
31 return old;
32 }
33
34 //容量扩充
35 public void ensureCapacity(int newCapacity) {
36 if (newCapacity < theSize)return;
37 //存储对原始数组的一个引用,
38 E[] old = theElements;
39 //为新数组分配内存(泛型数组的创建是非法的,需要进行类型转换)
40 theElements = (E[]) new Objects[newCapacity];
41 //将旧内容拷贝到新数组中
42 for (int i = 0; i < size(); i++)
43 theElements[i] = old[i];
44 }
45
46 //添加元素到表末
47 public boolean add(E element) {
48 add(size(), element);
49 return true;
50 }
51 //添加元素到指定位置,这种方法计算成本较于昂贵,因为它需要移动在指定位置上或之后的元素们到一个更高的位置上。
52 public void add(int idx, E element) {
53 //可能会要求扩容,扩容代价也比较昂贵,因为需要复制数组如果扩容就要变成原来大小的两倍,以免扩容频率过快。
54 if (theElements.length == size())
55 ensureCapacity(size() * 2 + 1);
56 for (int i = theSize; i > idx; i--)
57 theElements[i] = theElements[i - 1];
58 theElements[idx] = element;
59 theSize++;
60 }
61 //类似add方法,将元素向前进行位移
62 public E remove(int idx) {
63 E removedElement = theElements[idx];
64 for (int i = idx; i < size() - 1; i++)
65 theElements[i] = theElements[i + 1];
66 theSize--;
67 return removedElement;
68 }
69
70 //返回迭代器
71 public Iterator<E> iterator() {
72 return new ArrayListIterator();
73 }
74 //内部类实现迭代器
75 private class ArrayListIterator implements Iterator<E> {
76 private int current = 0;
77
78 @Override
79 public boolean hasNext() {
80 return current < size();
81 }
82
83 @Override
84 public E next() {