深入源码分析Linux进程模型
一、操作系统是怎么组织进程的
1、进程的概念
在进程模型中,计算机上所有可运行的软件,通常也包括操作系统,被组织成若干顺序进程,简称进程。一个进程应该包含如下内容:
(1)程序的代码,既然进程是一个正在运行的程序,自然需要程序的代码;
(2)程序的数据;
(3)CPU寄存器的值,包括通用寄存器,程序计数器;
(4)堆(heap)是用来保存进程运行时动态分配的内存空间;
(5)栈(stack)有两个用途,1保存运行的上下文信息。2在函数调用时保存被调用函数的形参或者局部变量;
(6)进程所占用的一组系统资源,如打开的文件。
2、进程的组织
系统为每个进程维护了一个进程控制块(Process Control Block,PCB),用来保存与该进程有关的各种状态信息。PCB只是基本原理中的说法,对于一个真实的操作系统可能不叫PCB,就像我所要讲的Linux中,PCB叫做任务结构体(task struct)。
struct task_struct { //进程的运行时状态 volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ void *stack; atomic_t usage; //进程当前的状态 /* 0x00000002表示进程正在被创建; 0x00000004表示进程正准备退出; 0x00000040 表示此进程被fork出,但是并没有执行exec; 0x00000400表示此进程由于其他进程发送相关信号而被杀死 。 */ unsigned int flags; /* per process flags, defined below */ unsigned int ptrace; int on_rq; //表示此进程的运行优先级,prio表示动态优先级,根据static_prio和交互性奖罚算出,static_prio是进程的静态优先级,在进程创建时确定,范围从-20到19,越小优先级越高。 int prio, static_prio, normal_prio; //进程的运行优先级 unsigned int rt_priority; //list_head结构体 struct list_head tasks; //mm_struct结构体,描述了进程内存的相关情况 struct mm_struct *mm, *active_mm; /* per-thread vma caching */ u32 vmacache_seqnum; struct vm_area_struct *vmacache[VMACACHE_SIZE]; /* task state */ //进程的状态参数 int exit_state; int exit_code, exit_signal; //父进程退出后信号被发送 int pdeath_signal; /* The signal sent when the parent dies */ /* scheduler bits, serialized by scheduler locks */ unsigned sched_reset_on_fork:1; unsigned sched_contributes_to_load:1; unsigned sched_migrated:1; unsigned sched_remote_wakeup:1; unsigned :0; /* force alignment to the next boundary */ /* unserialized, strictly 'current' */ unsigned in_execve:1; /* bit to tell LSMs we're in execve */ unsigned in_iowait:1; struct restart_block restart_block; //进程号 pid_t pid; //进程组号 pid_t tgid; //进程的亲身父亲 struct task_struct __rcu *real_parent; /* real parent process */ //进程的现在的父亲,可能为继父 struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */ //进程的孩子链表 struct list_head children; /* list of my children */ //进程兄弟的链表 struct list_head sibling; /* linkage in my parent's children list */ //主线程的进程描述符 struct task_struct *group_leader; /* threadgroup leader */ /* PID/PID hash table linkage. */ struct pid_link pids[PIDTYPE_MAX]; //该进程的所有线程链表 struct list_head thread_group; struct list_head thread_node; //该进程使用cpu时间的信息,utime是在用户态下执行的时间,stime是在内核态下执行的时间。 cputime_t utime, stime; cputime_t gtime; struct prev_cputime prev_cputime; //启动时间,,只是时间基准不一样 u64 start_time; /* monotonic time in nsec */ u64 real_start_time; /* boot based time in nsec */ struct task_cputime cputime_expires; //list_head的CPU时间 struct list_head cpu_timers[3]; //保存进程名字的数组,一般数组大小为15位 char comm[TASK_COMM_LEN]; /* file system info */ //文件系统信息 struct nameidata *nameidata; /* 文件系统信息计数*/ int link_count, total_link_count; /* filesystem information */ //文件系统相关信息结构体 struct fs_struct *fs; /* open file information */ //打开文件信息的结构体 struct files_struct *files; /* namespaces */ struct nsproxy *nsproxy; /* signal handlers */ //信号相关信息的句柄 struct signal_struct *signal; struct sighand_struct *sighand; struct callback_head *task_works; struct audit_context *audit_context; struct seccomp seccomp; /* Thread group tracking */ u32 parent_exec_id; u32 self_exec_id; /* journalling filesystem info */ void *journal_info; /* VM state */ struct reclaim_state *reclaim_state; struct backing_dev_info *backing_dev_info; struct io_context *io_context; unsigned long ptrace_message; siginfo_t *last_siginfo; /* For ptrace use. */ /* * time slack values; these are used to round up poll() and * select() etc timeout values. These are in nanoseconds. */ //松弛时间值,用来记录select和poll的超时时间,单位为ns u64 timer_slack_ns; u64 default_timer_slack_ns; /* CPU-specific state of this task */ //该进程在特定CPU下的状态 struct thread_struct thread; };
PID每个经常都有自己的“身份证号码”,即PID号,PID是重要的系统资源,它是用以区分各个进程的基本依据,可以使用ps来查看进程的PID。一个task struct对应一个PID。
二、进程状态如何转换(给出进程状态转换图)
| 状态 | 描述 |
| TASK_RUNNING | 就绪态或者运行态,进程就绪可以运行,但是不一定正在占有CPU,对应进程状态的R |
| TASK_INTERRUPTIBLE | 睡眠态,但是进程处于浅度睡眠,可以响应信号,一般是进程主动sleep进入的状态,对应进程状态S |
| TASK_UNINTERRUPTIBLE | 睡眠态,深度睡眠,不响应信号,典型场景是进程获取信号量阻塞,对应进程状态D |
| TASK_ZOMBIE | 僵尸态,进程已退出或者结束,但是父进程还不知道,没有回收时的状态,对应进程状态Z |
| TASK_STOPED | 停止,调试状态,对应进程状态T |
(1)两状态进程模型
在该模型中,一个进程要么正在执行,要么没有在执行,没有其他状态,所以进程所处的状态有两种:运行态、未运行态。进程状态的转换方式如1.1图所示。

图1.1 两状态转换图
(2)三状态进程模型
在该模型中,进程所处的状态有三种:运行态、就绪态、和阻塞态。进程状态的转换方式如图1.2所示。

图1.2 三状态转换图
(3)五状态进程模型相较于三状态进程模型而言,在三状态进程模型的基础上另增加了两个状态:新建态和退出态。进程状态的转换方式如图1.3所示。

图1.3 五状态转换图
三、进程是如何调度的
在Linux操作系统中,有实时进程和普通今天之分,这里我想围绕普通进程的调度展开,对o(1)调度算法和CFS调度算法进行分析。
1、o(1)调度算法
在Linux2.6中,o(1)调度被采用,它是对普通进程进行调度的一种调度算法。因为Linux2.6版的调度算法与Linux2.4版相比在性能等方面的改进非常大,且它的时间复杂度为恒定的o(1),故把它称为o(1)调度算法。
renqueue结构体的部分定义如下:
struct runqueue { unsigned long nr_running; task_t *curr; prio_array_t *active,*expired,array[2]; }
上述结构体列举了一些比较重要的字段:
(1)nr_running:就绪进程的数目,等于活动进程和过期进程之和;
(2)curr:指向正在运行的进程;
(3)active:指向表示活动进程集的结构体;
(4)expired:指向表示过期进程集的结构体;
(5)arrays[2]:为active和expired分配静态空间。
调度的核心步骤:
(1)若当前处理器的运行队列上没有任何可运行态进程,那么为了实现多处理器间的负载平衡,则从其他处理器上调一些可运行态进程进来。若调完后当前处理器的运行队列上还是没有进程可运行,则在处理器上运行idle进程来使处理器处于低功耗模式直到有可运行态进程出现。若运行队列上有可运行态进程则执行步骤(2)
(2)判断active队列是否为空。当active队列为空,即表示所有活动进程都运行完了,这时就要让expired队列的过期进程再次变为活动进程。但是并不需要将expired队列中的进程一个个移进active队列中去,只需要将active和expired的指针指向的地址互换就行了。具体内核实现代码如下:
struct prop_array *array=rq->active; if(array->nr_active!=0) { re->active=rq->expired; rq->expired=array; }
(3)步骤(2)执行成功后active队列中必定存在活动进程,这时通过active中的优先级位图bitmap来选择优先级最高且有可运行态进程的优先级队列,具体如图1.4所示。
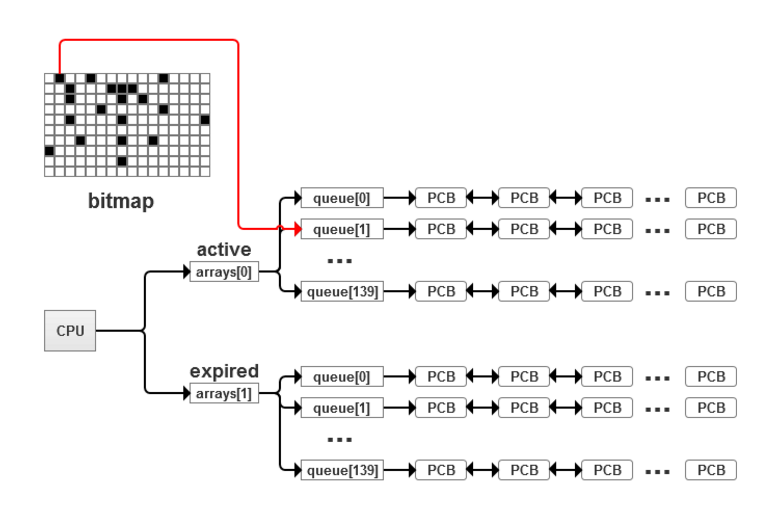
图1.4 通过bitmap来选择优先级队列的示意图
(4)最后选择active的bitmap所指向链表中的第一个进程即可。
通过以上4个核心步骤,o(1)调度器基本完成了对于可运行态进程的一次调度过程。
2、CFS调度算法
从Linux2.6开始,考虑到o(1)调度的一些不足以及公平性方面的缺陷,所以改用完全公平调度(CFS)算法。不同于o(1)调度,CFS调度基于公平的理念,对进程一视同仁,不再对交互式进程进行区别,也不再根据进程的平均睡眠时间来确定奖励bonus并以此来调整动态优先级。取而代之,CFS通过权重使每个进程都能过获得公平的运行时间。更为关键的是,CFS调度算法的设计和实现都很简单,且实际性能非常优越。CFS调度器的整体结构如图1.5所示。
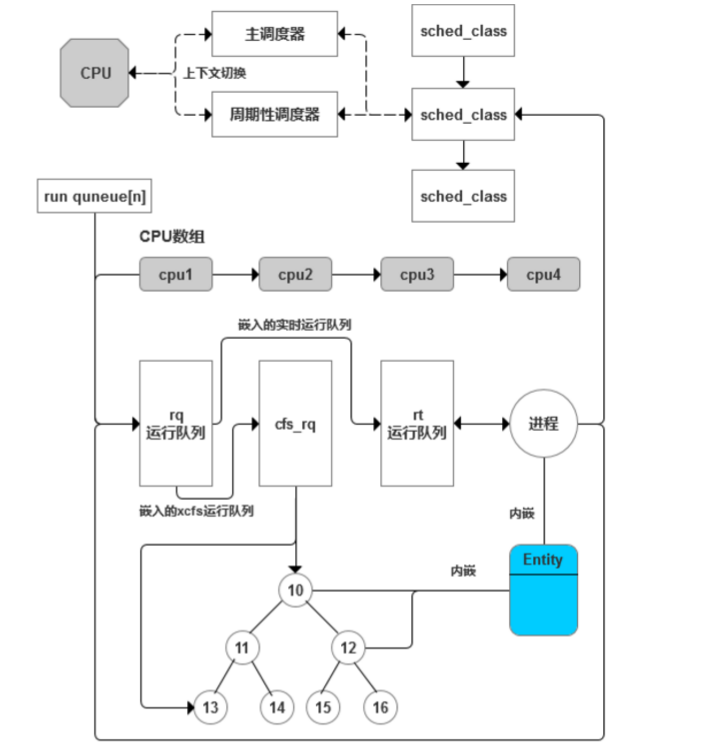
图1.5 CFS调度器的整体结构
相对比于o(1)调度,CFS调度没有用运行队列来维护可运行态进程,而是用来红黑树来组织普通进程。红黑树本质上是一颗二叉查找树,它具有以下五个特点:
(1)每个叶结点都是空结点,并且他们都是黑色的;
(2)根结点是黑色的;
(3)红色结点的子结点必定是黑色的;
(4)对于任意结点而言,其到叶结点的每条路径上的黑色结点的书目都相同;
(5)每个结点不是黑色就是红色;
这些特点决定了红黑树是自平衡的,虽然红黑树没有达到恒定o(1)的时间复杂度但是它最差的时间复杂度也为o(logn),这就决定了它可以在插入和删除等操作上表现的非常高效。CFS使用的红黑树是以时间为顺序的,它的结点由调度实体来描述,而进程的虚拟运行时间和权重也存放在这个结构中,图1.6描绘了CFS中红黑树的结果。
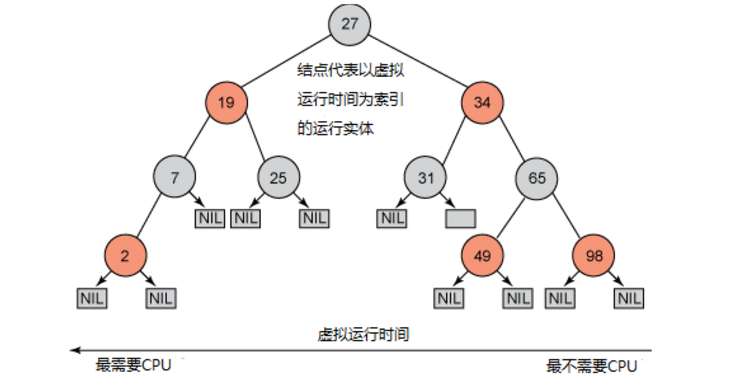
图1.6 CFS红黑树的结构
内核通过红黑树来对虚拟运行时间进行排序,红黑树的最左侧结点的虚拟运行时间最少,所以该结点所表示的进程将是下一个要被调度的进程。
3、两种算法的比较
通过上面对于o(1)调度和CFS调度的分析,我们发现他们的区别归根结底在于两者的设计思想的不同。
o(1)调度是通过优先级来实现对时间片的绝对映射,而CFS调度对于时间片的映射则是通过权重完成的,CFS调度相比o(1)调度的最主要优势在于它实现了进程间的调度的相对公平,而这也是调度算法设计中非常重要的一个部分。虽然o(1)调度的恒定的时间复杂o(1)也是一大特色,只是CFS的o(logn)的性能已经能够满足于系统的需要,而且CFS的设计与实现简单,实际运行高效,不像o(1)调度有那么多的复杂公式,弥补了o(1)调度的许多不足之处。所以,这些因素最终决定了CFS调度要取代o(1)调度的位置。但是也不能完全否定o(1)调度算法,它对于以后进程调度算法的发展还是有许多值得借鉴的地方。
四、谈谈自己对Linux操作系统的看法
我想通过和windows系统的比较来谈我的看法。
Linux有以下几个优点:
(1)追求免费的正版,微软公司开发的平台下的软件都是明码标价的,如果不购买,那么就是属于盗版,为了追求正版,所以只能选择linux,特别是对于公司,则是为了防止出现版权纠纷问题;
(2)学习,linux开放源代码,是学习系统和软件开发的平台,也是国外很多研究机构开发系统的盗版源泉;
(3)防毒,有许多网站挂马,给客户安全造成了影响,linux作为一个小众平台,感染病毒的概率比较低,因此为了放心地看大片,所以安装了它;
(4)最后,也是最重要的一点,装逼,linux是一个高大上的名词,使用linux就和高手挂上了勾,特别是compiz等软件,让windows的客户看得目瞪口呆,然后可以高大上地享受大家对高手地崇拜。
windows有以下几个优点:
(1)windows形成了良好地生态圈,有着丰富实用地软件支持,形成了良好地盈利模式,在windows平台下,你的需要可以得到贴心的维护,当然你要付出你的money;
(2)维护成本低,技术文档资料详实,不想linux什么都要靠自己、靠社区;
(3)最重要的是对我们这些初学者比较友善。
说真的,作为一个计算机菜鸟,如果要我选择的话,我更喜欢windows,不过想成为大佬,还是应该使用Linux。
五、参考资料
https://wenku.baidu.com/view/2003f071cbaedd3383c4bb4cf7ec4afe04a1b1c8.html?qq-pf-to=pcqq.c2c
https://blog.csdn.net/xxpresent/article/details/71023637

 浙公网安备 33010602011771号
浙公网安备 33010602011771号