20202216 2020-2021-2 《Python程序设计》实验四报告
20202216 2020-2021-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2022
姓名: 邓童丹
学号:20202216
实验教师:王志强
实验日期:2021年6月14日
必修/选修: 公选课
- 实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
课代表和各小组负责人收集作业(源代码、视频、综合实践报告)
批阅:注意本次实验不算做实验总分,前三个实验每个实验10分,累计30分。本次实践算入综合实践,打分为25分。
评分标准:
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)10分
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。10分。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。5分
- 实验过程及结果
平常喜欢上微博,看到一些好看的图片就想保存下来,但是一张一张的保存会很麻烦,所以想到了用python爬虫直接爬取保存到本地,非常方便,本次实验参考了网上教程和课堂内容实现。
找到自己想要爬取的博主的微博,因为移动端微博爬取的难度较小,所以在Chrome浏览器上打开微博移动端的网页
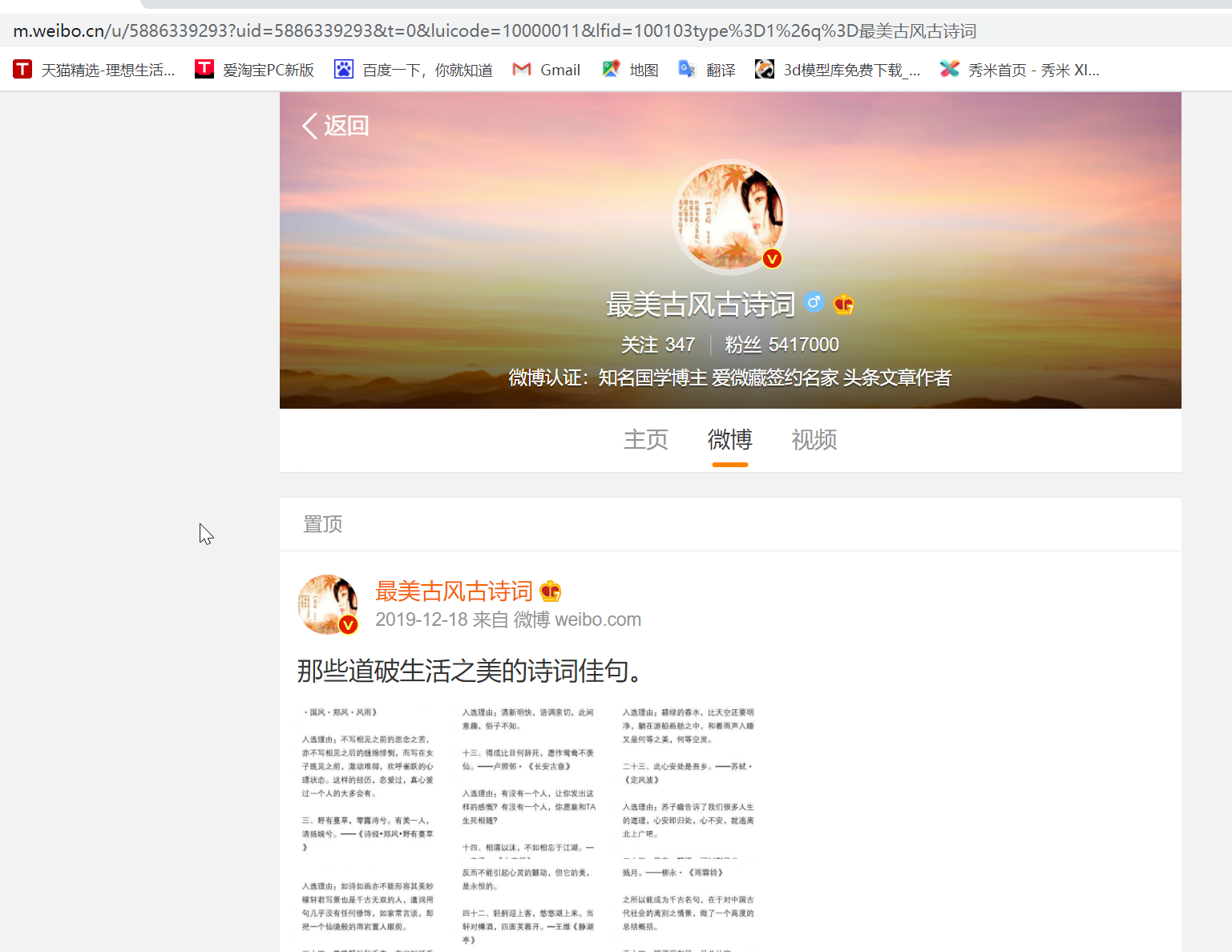
网页url那里/u/后面的那串数字就是博主的微博id,在爬虫中需要用到
右键选择检查,打开浏览器的调试功能,选择 Network 菜单,Ctrl+R刷新获取数据

注意到Name栏里的倒数第二行,复制它的link address下来后是这样的
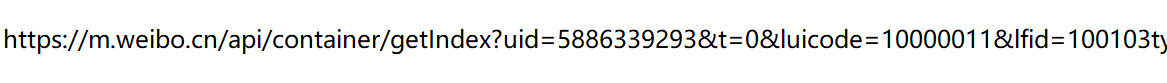
这是微博移动端api,可以在此进行json数据的获取和提取
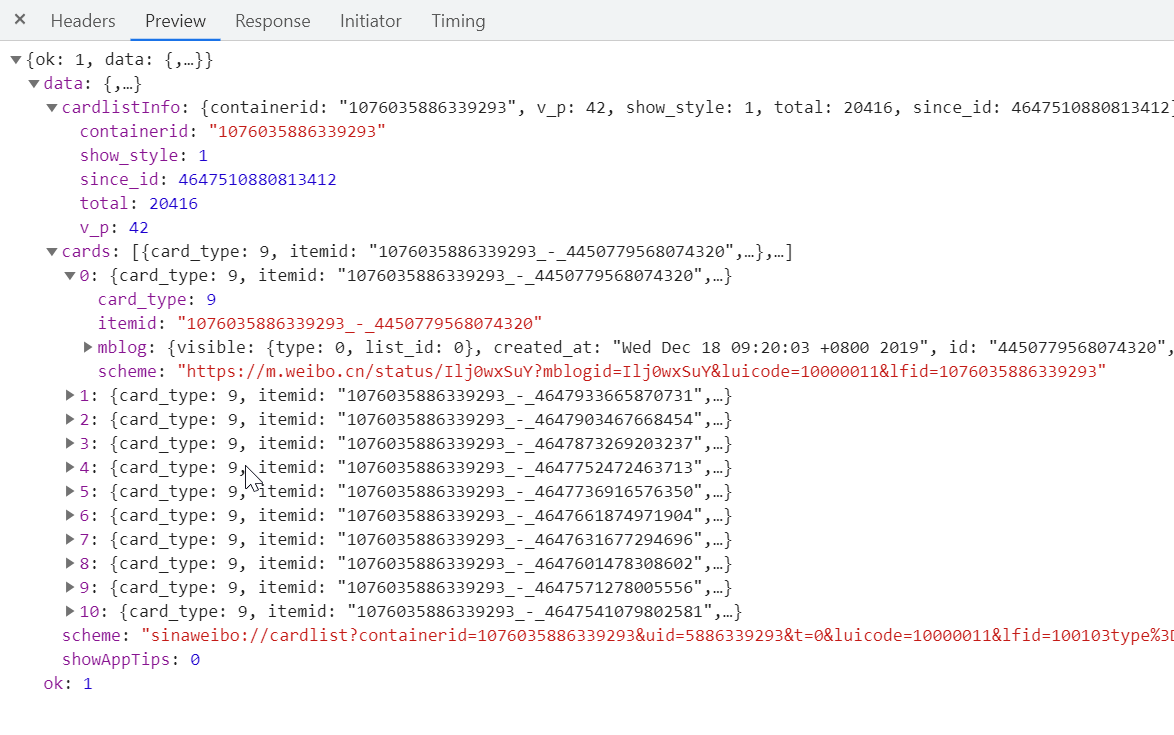
cardlistInfo是列表信息
cards是当前页面的编号
用户的特定containerId等于107603+UID
total是总微博数
card_type正常为9
ok: 1就表明获取页面信息成功
pic是我要找的图片信息,这在mblog下,我主要需要获取图片的id和url
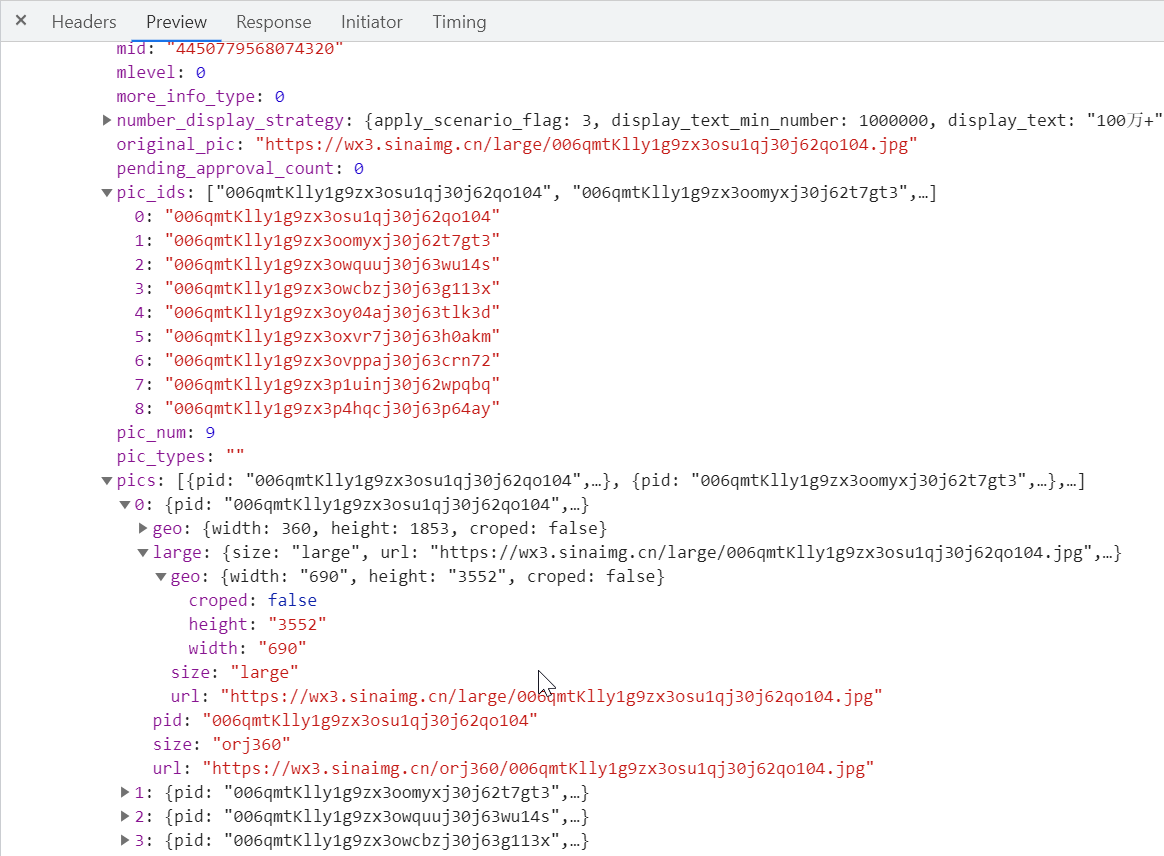
大概知道要爬取的内容和信息位置后,开始写代码
构建请求头,并随便找个移动端设备的用户代理
host = 'm.weibo.cn'
base_url = 'https://%s/api/container/getIndex?' % host
user_agent = 'User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1 wechatdevtools/0.7.0 MicroMessenger/6.3.9 Language/zh_CN webview/0' # 在网上随便找个user_agent
user_id = str(5886339293) # 这里填写用户id
headers = {
'Host': host,
'Referer': 'https://m.weibo.cn/u/%s' % user_id,
'User-Agent': user_agent
}
导入模块,有些模块没有安装,还需要先安装好
import requests
import urllib.request
import time
import os
from tqdm import tqdm
from urllib.parse import urlencode
编写一个函数用于对网页进行请求
def get_single_page(page):
params = {
'type': 'uid',
'value': 1665372775,
'containerid': int('107603' + user_id),
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('爬取失败', e.args)
此函数解析页面返回的json数据
def analysis_page(json, pic_filebagPath):
items = json.get('data').get('cards')
for item in items:
item = item.get('mblog')
if item:
if pic_choice == 'y':
pics = item.get('pics')
if pics:
for pic in pics:
picture_url = pic.get('large').get('url') # 得到原图地址
pid = pic.get('pid') # 图片id
pic_name = pid[25:]
download_pics(picture_url, pic_name, pic_filebagPath)
此函数用于保存图片到本地
def download_pics(pic_url, pic_name, pic_filebagPath):
pic_filePath = pic_filebagPath + '\\'
try:
f = open(pic_filePath + str(pic_name) + ".jpg", 'wb')
response = urllib.request.urlopen(pic_url)
f.write(response.read())
f.close()
except Exception as e:
print(pic_name + " error", e)
time.sleep(0.1)
主函数部分
if __name__ == '__main__':
base_data = {}
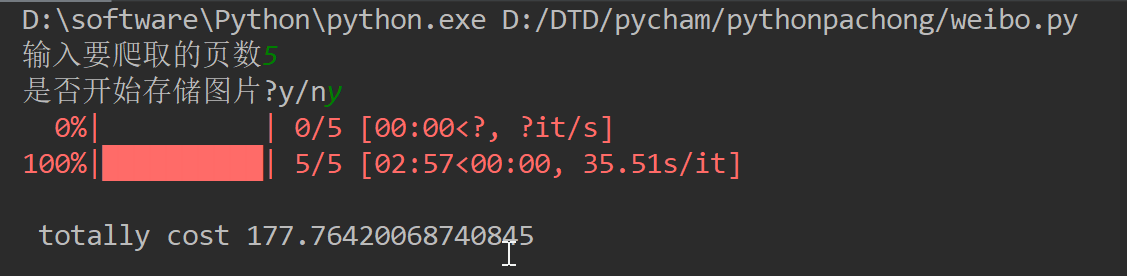
page = input('输入要爬取的页数') # 输入爬取页数,输入‘all’即爬取所有微博
pic_choice = input('是否开始存储图片?y/n')
time_start = time.time()
try:
json = get_single_page(1)
screen_name = json.get('data').get('cards')[0].get('mblog').get('user').get('screen_name')
total = json.get('data').get('cardlistInfo').get('total')
if pic_choice == 'y':
pic_filebagPath = 'D:\\weibopachong\\%s_picture' % screen_name
os.makedirs(pic_filebagPath) # 建立文件夹
else:
pic_filebagPath = None
if page == 'all':
page = total // 10
while get_single_page(page).get('ok') == 1:
page = page + 1
print('总页数为:%s' % page)
page = int(page) + 1
for page in tqdm(range(1, page)): # 抓取数据
json = get_single_page(page)
analysis_page(json, pic_filebagPath)
except Exception as e:
print('error:', e)
finally:
time_end = time.time()
print('\n total cost', time_end - time_start)
运行结果
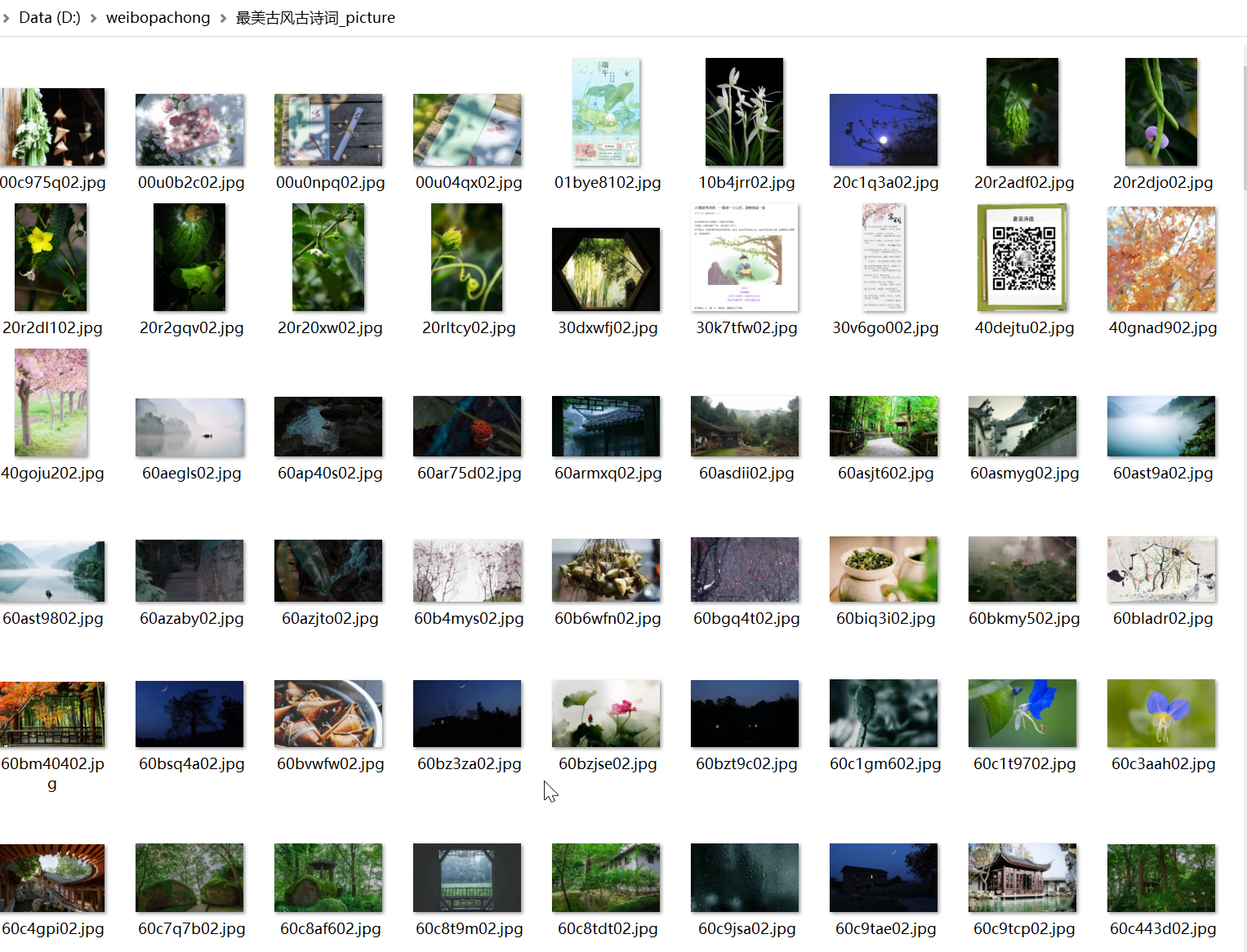
图片保存到本地后
- 实验过程中遇到的问题和解决过程
- 问题1:一开始用了老师上课时给的请求头,结果爬取失败。
- 问题1解决方案:因为用的是移动端网页,所以要用移动端设备的请求头,在网上重新找了一个。
- 问题2:第一次运行时没有得到图片。
- 问题2解决方案:通过查阅网上的资料和分析Network标签页下的信息,找到了所需图片内容的正确标识。
- 课程感悟:
在这一学期,我结识了python这一神奇的程序设计语言,python一门开源免费、通用型的脚本编程语言,它上手简单,功能强大,坚持「极简主义」。它有非常多的优点,如具有极其丰富类库,这使得 Python 几乎无所不能,不管是传统的 Web 开发、PC 软件开发、Linux 运维,还是当下火热的机器学习、大数据分析、网络爬虫,Python 都能胜任。python还提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
在课上,我学习到了python的基本输入输出,数据类型,基础语法,有关字符串的操作,了解了许多字符串处理函数,索引和切片,正则表达式,各种序列,函数、面向对象的设计、模块,异常处理,还用python进行数据库,socket库的编程,文件操作以及网络爬虫。同样的我还认识到python的选择,循环语句与C语言的异同和它更具优势的地方。总而言之,关于python还有很多可学的方面,尤其是它庞大的第三方库资源。或许我现在认识的只是其中的冰山一角,在以后我还会继续探索。感谢王志强老师带领我走入python的世界,能让我在课堂上由浅入深的学习python,虽然对于我而言,还是有一些地方并没有弄明白,但我有信心在未来继续学习的过程中能够逐渐理解。
还有王志强老师让我们以博客的形式提交实验报告的这一点让我受益匪浅,这培养了我写博客的习惯,还让我看到了许多大佬的文章,还有在gitee上注册账号和对git的使用,这对以后的计算机学习是非常有利的。
最后,感谢王志强老师这一学期的教导,希望以后也有机会于老师探讨更多计算机相关的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号