python 与 c# 差异以及爬虫的简单使用
python安装
官方地址:https://www.python.org/
下载地址:https://www.python.org/downloads/
下载完成后直接安装,安装的时候勾选Add Python 3.6 to PATH,这样可以将 Python 及其相关工具(如 pip)的路径自动添加到系统环境变量 PATH 中

安装了打开cmd输入python ,成功了就是下面这样

基础语法差异(只列出python的语法和c# 不一样的地方)
1. 变量声明
Python 没有用于声明变量的命令。当您第一次为变量赋值时,该变量就会被创建。
x = 5 y = "John" print(x) print(y)
2. 数据类型

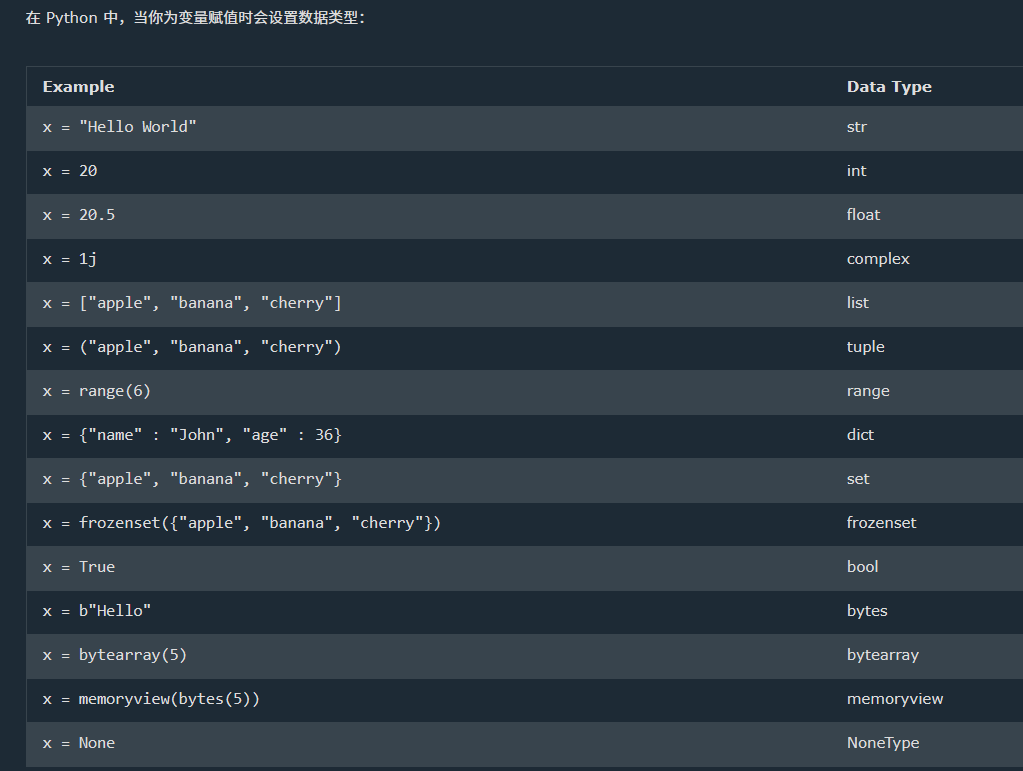
特殊的是:
tuple:就是c# 的元组
range: 序列对象,x = range(6) 创建一个从 0 开始到 5 结束的整数序列(不包括 6),创建了一个序列对象,包含数字 0, 1, 2, 3, 4, 5 ,查看具体的数字列表必须要将 range 对象转换为列表
x = range(6) print(list(x))
frozenset: 创建一个不可变的集合,创建后不可更改,也就是说,你不能添加、删除或修改其中的元素
complex :表示复数 (数学知识,忘完了)。 z = 2+3j # 创建一个复数 2 + 3j ,其中2为实部,3为虚部
list :方括号 [] 来定义,例如 my_list = [1, 2, 3]。是有序的,这意味着列表中的元素是按照添加的顺序排列的,并且可以通过索引访问。 可以包含重复的元素。支持各种操作,例如通过索引添加、删除或修改元素。的索引访问速度较快,但在插入和删除元素时可能比 set 更慢,特别是对于大列表。
set: 使用花括号 是无序的,集合中的元素没有特定的顺序,也不支持通过索引访问。只包含唯一的元素,不能有重复项。提供了集合特有的操作,如并集、交集、差集等,这些操作在 {} 来定义,例如 my_set = {1, 2, 3}。list 中并不直接支持。set 通常比 list 更快,因为 set 是基于哈希表实现的。
memoryview: 字节对象的一个视图. x = memoryview(bytes(5))其中 bytes(5) 会创建一个长度为 5 的字节对象,内容为 5 个空字节(即 b'\x00\x00\x00\x00\x00')。memoryview 允许你在这个字节对象上进行内存级别的操作,而不需要拷贝数据。
使用type()以下函数获取任何对象的数据类型:
x = 5
print(type(x))
输出
<class 'int'>
如果想指定变量的数据类型,可以通过强制转换来完成。
a="3" b=3 c=3.0 print(type(a)) print(type(b)) print(type(c)) x = str(3) # x will be '3' y = int(3) # y will be 3 z = float(3) # z will be 3.0 print(type(x)) print(type(y)) print(type(z))
输出
<class 'str'> <class 'int'> <class 'float'> <class 'str'> <class 'int'> <class 'float'>
总体指定数据类型的构造函数如下:
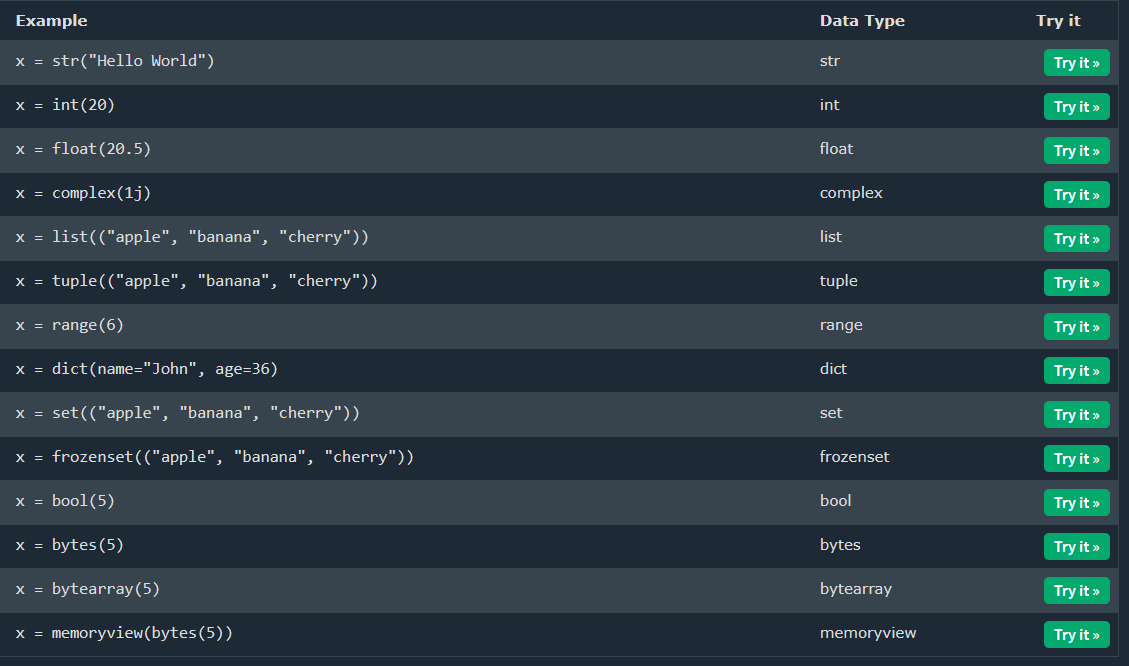
3. 解包
如果你有一个列表、元组等中的值集合,Python 允许你将值提取到变量中。这称为解包。
fruits = ["apple", "banana", "cherry"] x, y, z = fruits print(x) print(y) print(z)
输出
apple
banana
orange
4. 作用域,变量仅在其被创建的区域内有效,但是全局变量有点区别
全局变量
在函数外部创建的变量(如前几页中的所有示例)称为全局变量。
全局变量可供任何人使用,无论是在函数内部还是外部。
x = "awesome" def myfunc(): x = "fantastic" print("Python is " + x) myfunc() print("Python is " + x)
如果在函数内部和外部使用相同的变量名,Python 会将它们视为两个单独的变量,一个在全局作用域(函数外部)可用,一个在局部作用域(函数内部)可用:
这里myfunc()函数内部的x 为新定义的局部变量,和外部的全局变量没有关系,所以这里输出为
Python is fantastic Python is awesome
放在c# 或者java 里面,x 都为同一个变量并且已经被赋值了,这里要想要达到赋值的效果,就要用到 global 关键字
要在函数内部创建或者引用全局变量,可以使用 global关键字。
x = "awesome" def myfunc(): global x x = "fantastic" print("Python is " + x) myfunc() print("Python is " + x)
输出
Python is fantastic Python is fantastic
nonlocal关键字 用于处理嵌套函数内的变量,使变量属于外部函数
def myfunc1(): x = "Jane" def myfunc2(): nonlocal x x = "hello" myfunc2() return x print(myfunc1()) # Output: hello
5. 缩进
在c# 或者java中 可以通过{}来定义代码块,c# 中代码块只有一行的时候才可以不用使用{}花括号。
但是在python中,不能使用{}来定义,只能使用空格缩进来定义代码块,正确的缩进通常使用 4 个空格或一个 Tab,并且同一个代码块儿内容缩进的空格必须是一样的。注意 if语句的条件后面需要有一个冒号 :
if 5 > 2: print("Five is greater than two!") print("Five is greater than two!")
而这样就会报错
if 5 > 2: print("Five is greater than two!") print("Five is greater than two!")
6. 代码注释
单行注释:使用 #
多行注释 : Python 实际上并没有多行注释的语法。要添加多行注释,可以为每一行插入一个 # 。
由于 Python 会忽略未分配给变量的字符串文字,因此您可以在代码中添加多行字符串(三重引号),并将注释放在其中,模拟多行注释
#这个是单行注释 #这个是多行注释 #这个是多行注释 #这个是多行注释 """ 这个是多行字符串模拟多行注释 这个是多行字符串模拟多行注释 这个是多行字符串模拟多行注释 """
7. 字符串相关操作
字符串长度:len()
a = "Hello, World!" print(len(a))
字符串中存在:关键字 in
txt = "The best things in life are free!" if "free" in txt: print("Yes, 'free' is present.") else: print("No, 'free' is not present.")
字符串中不存在:关键字not in
txt = "The best things in life are free!" print("expensive" not in txt)
字符串切片
b = "Hello, World!" print(b[2:5]) # output: "llo" print(b[:5]) # output: "Hello" print(b[2:]) # output: "llo, World!" print(b[-5:-2]) # output: "orl"
转大写:upper()
a = "Hello, World!" print(a.upper())
转小写: lower()
删除文本前后空格: strip()
a = " Hello, World! " print(a.strip()) # Output: "Hello, World!"
格式化字符串: 关键字 f ,在c# 中是$
age = 36 txt = f"My name is John, I am {age}" print(txt)
8. 集合的区别
四种集合数据类型区别
List是有序且可更改的集合。允许重复成员。
元组是有序且不可更改的集合。允许重复成员。
set 是无序、不可更改*、无索引的集合。没有重复的成员。
字典是有序且可变的集合。没有重复的成员
python 没有自带数组,需要用数组 需要引用 NumPy 库 ,相关教程
list 是有序,多变(列表是可更改的,这意味着我们可以在创建列表后更改、添加和删除列表中的项目。),允许重复
可以同时包含不同的数据类型
list1 = ["apple", "banana", "cherry"] list2 = ["abc", 34, True, 40, "male"]
list 更改 列表项
thislist = ["apple", "banana", "cherry"] thislist[1] = "blackcurrant" print(thislist) # Output: ['apple', 'blackcurrant', 'cherry'] thislist = ["apple", "banana", "cherry", "orange", "kiwi", "mango"] thislist[1:3] = ["blackcurrant", "watermelon"] print(thislist) # Output: ['apple', 'blackcurrant', 'watermelon', 'orange', 'kiwi', 'mango'] thislist = ["apple", "banana", "cherry"] thislist[1:2] = ["blackcurrant", "watermelon"] print(thislist) # Output: ['apple', 'blackcurrant', 'watermelon', 'cherry'] thislist = ["apple", "banana", "cherry"] thislist[1:3] = ["watermelon"] print(thislist) # Output: ['apple', 'watermelon']
list 添加列表项 insert() , append()
thislist = ["apple", "banana", "cherry"] thislist.append("orange") # 将元素添加到列表末尾 thislist.insert(1, "orange") # 在索引1的位置插入元素
list 扩展 extend()。可以迭代任何对象(元组、集合、字典等)
thislist = ["apple", "banana", "cherry"] tropical = ["mango", "pineapple", "papaya"] thislist.extend(tropical) thislist = ["apple", "banana", "cherry"] thistuple = ("kiwi", "orange") thislist.extend(thistuple)
list 删除:
remove() 方法删除指定的项目。如果有多个具有指定值的项目,该remove()方法将删除第一个出现的项目
pop()方法删除指定的索引。如果不指定索引,该pop()方法将删除最后一项。
del关键字:删除指定的索引,还可以彻底删除列表。
thislist = ["apple", "banana", "cherry"] del thislist[0] print(thislist) thislist = ["apple", "banana", "cherry"] del thislist
list 列表推导式,一种语法糖
newlist = [expression for item in iterable if condition == True]
当需要打印时的用例
thislist = ["apple", "banana", "cherry"] for x in thislist: print(x) [print(x) for x in thislist] # 改用列表推导式简写,可以直接打印
当需要复制新列表时的用例
fruits = ["apple", "banana", "cherry", "kiwi", "mango"] newlist = [] #常规方式 for x in fruits: if "a" in x: newlist.append(x) print(newlist) #列表推导式 newlist = [x for x in fruits if "a" in x] print(newlist)
列表推导式输出也可以添加if 语句
fruits = ["apple", "banana", "cherry", "kiwi", "mango"] newlist = [x if x != "banana" else "orange" for x in fruits] # 如果x不等于"banana",则将x添加到newlist中;如果x等于"banana",则将"orange"添加到newlist中 print(newlist) #['apple', 'orange', 'cherry', 'kiwi', 'mango']
9. for 循环
所有的循环都没有{},后面直接跟 :,并且内容代码块儿都是空格
fruits = ["apple", "banana", "cherry"] for x in fruits: print(x)
循环指定的次数 必须要用到 range() 函数,而不能像c# 那样直接 写数字 for (int i = 0; i < 6; i++)
for x in range(6): print(x) ## range(6) 意思是从0到5,不包含6,序列化结果为 0,1,2,3,4,5 for x in range(2, 6): print(x) # range(2,6) 意思是从2到5,不包含6,序列化结果为 2,3,4,5 for x in range(2, 30, 3): print(x) # range(2,30,3)意思是从2到29递增,不包含30,增量为3,序列化结果为 2,5,8,11,14,17,20,23,26,29
循环集合
fruits = ["apple", "banana", "cherry"] for x in range(len(fruits)): print(fruits[x])
for 循环中else 关键字,指定for 循环完成时要执行的代码块
for x in range(6): print(x) else: print("Finally finished!")
但是遇到break ,就会被打断,不会执行else 了
for x in range(6): if x == 3: break print(x) else: print("Finally finished!")
空的for 语句 使用关键字 pass
for x in [0, 1, 2]: pass
10. While 循环 和 for 循环 和for循环一样
11. 函数定义使用关键字 def
def my_function(fname): print(fname + " Refsnes") my_function("Emil")
当参数不确定时,定义多个参数 使用 *args
def my_function(*kids): print("The youngest child is " + kids[2]) my_function("Emil", "Tobias", "Linus")
当关键字参数不确定时,定义多个关键字参数 使用 **args
def my_function(**kid): print("His last name is " + kid["lname"]) my_function(fname = "Tobias", lname = "Refsnes")
11. Lambda 函数
Lambda 函数是一个小的匿名函数,
c# 中连接是使用=> , java 是 -> ,而python是 :
句法
lambda arguments : expression
x = lambda a : a + 10 print(x(5)) # Output: 15
lambda 结合函数使用
def myfunc(n): return lambda a : a * n mydoubler = myfunc(2) mytripler = myfunc(3) print(mydoubler(11)) # Output: 22 print(mytripler(11)) # Output: 33
12 类/对象
创建类使用关键字 class , 创建对象使用class() , 和 c# 一样,只是少了一个new 关键字
#创建类 class MyClass: x = 5 #创建对应实例对象 p1 = MyClass() #打印实例对象的属性值 print(p1.x) #输出5
__init__() 函数 ,其实就是构造函数,该函数总是在类被初始化时执行。和c# 区别在于需要固定第一个参数为self (可以随便叫什么,但它必须是第一个参数)是对类的当前实例的引用,用于访问属于该类的变量, 也就是实例完的对象。
class Person: def __init__(self, name, age): self.name = name self.age = age p1 = Person("John", 36) print(p1.name) print(p1.age)
__str__() 函数
该__str__()函数控制当类对象表示为字符串时应返回的内容。
class Person: def __init__(self, name, age): self.name = name self.age = age def __str__(self): return f"{self.name}({self.age})" p1 = Person("John", 36) print(p1) # Output: John(36)
如果__str__()未设置该函数,则返回对象的字符串表示形式:
class Person: def __init__(self, name, age): self.name = name self.age = age p1 = Person("John", 36) print(p1) # Output: <__main__.Person object at 0x000001>
其实就是不设置返回对象,设置了之后返回设置的字符串
类结合函数使用
class Person: def __init__(self, name, age): self.name = name self.age = age def myfunc(self): print("Hello my name is " + self.name) p1 = Person("John", 36) p1.myfunc()
修改对象
p1.age = 40
删除对象。使用 del关键字删除对象的属性,python好多删除都是使用的del 关键字 ,比如删除list ,元组 ,字典,变量等等
del p1.age
13 继承。直接在类后面打个括号放基类就行了
class Person: def __init__(self, fname, lname): self.firstname = fname self.lastname = lname def printname(self): print(self.firstname, self.lastname) class Student(Person): pass x = Student("Mike", "Olsen") x.printname() # Output: Mike Olsen
这里实例化子类也会调用基类的构造函数,那么我们想实现了基类构造函数,又想实现子类构造函数,使用super() 函数,不必使用父元素的名称,它将自动从其父级继承方法和属性。
class Person: def __init__(self, fname, lname): print("Creating a person object...") self.firstname = fname self.lastname = lname def printname(self): print(self.firstname, self.lastname) class Student(Person): def __init__(self, fname, lname): print("Creating a student object...") super().__init__(fname, lname) x = Student("Mike", "Olsen") x.printname() # Output: Creating a person object... # Creating a student object... # Mike Olsen
如果在子类中添加与父类中函数同名的方法,则父类方法的继承将被覆盖(不需要使用任何关键字)
class Person: def __init__(self, fname, lname): self.firstname = fname self.lastname = lname def printname(self): print(self.firstname, self.lastname) class Student(Person): def __init__(self, fname, lname): super().__init__(fname, lname) def printname(self): print(f"Student: {self.firstname} {self.lastname}") x = Student("Mike", "Olsen") x.printname() # Output: Student: Mike Olsen
14. 迭代器,由方法__iter__() 和__next__()组成
简单的迭代使用,当然也可以直接使用for循环进行迭代
mytuple = ("apple", "banana", "cherry") myit = iter(mytuple) print(next(myit)) # Output: apple print(next(myit)) # Output: banana print(next(myit)) # Output: cherry
对类/对象进行迭代
class MyNumbers: def __iter__(self): self.a = 1 return self def __next__(self): x = self.a self.a += 1 return x myclass = MyNumbers() myiter = iter(myclass) print(next(myiter)) # Output: 1 print(next(myiter)) # Output: 2 print(next(myiter)) # Output: 3 print(next(myiter)) # Output: 4 print(next(myiter)) # Output: 5
停止迭代 ,使用StopIteration
class MyNumbers: def __iter__(self): self.a = 1 return self def __next__(self): if self.a <= 20: x = self.a self.a += 1 return x else: raise StopIteration myclass = MyNumbers() myiter = iter(myclass) for x in myiter: print(x)
15. 模块,一组函数的文件叫一个模块,模块文件扩展名 .py , 使用模块和java 一样使用 import 关键字
调用模块的函数使用语法
module_name.function_name。
这里创建了 mymodule.py 的模块

然后创建了test.py 去调用 mymodule.py 模块的函数

也可以重命名模块
import mymodule as mx mx.greeting("Alice")
内置模块,Python 中有多个内置模块
import platform x = platform.system() print(x) # Output: Windows x = dir(platform) #列出属于平台模块的所有已定义名称 print(x)
从模块导入指定的部分内容,使用 from ... import ...
创建mymodule.py 代码
def greeting(name): print("Hello, " + name) person1 = { "name": "John", "age": 36, "country": "Norway" }
创建test.py 进行引用
from mymodule import greeting, person1 greeting("Alice")
16.日期 ,引用内置模块datetime
创建日期
import datetime x = datetime.datetime(2020, 5, 17,23,59,59) print(x) #2020-05-17 23:59:59
读取时间
x = datetime.datetime.now() print(x) # 2025-06-15 14:30:25.123456 print(x.year) # 2025 print(x.strftime("%Y-%m-%d %H:%M:%S")) # 2025-06-15 14:30:25
这里引用了strftime()方法,并采用一个参数 format来指定返回字符串的格式,和c# ToString(format) 很像
17. json 相关操作
解析Json 使用 json.loads()
import json # some JSON: x = '{ "name":"John", "age":30, "city":"New York"}' y = json.loads(x) print(y["age"]) # output: 30
将对象序列化为json使用 json.dumps()
import json x = { "name": "John", "age": 30, "married": True, "divorced": False, "children": ("Ann","Billy"), "pets": None, "cars": [ {"model": "BMW 230", "mpg": 27.5}, {"model": "Ford Edge", "mpg": 24.1} ] } print(json.dumps(x)) # 输出json字符串 print(json.dumps(x,indent=4)) # 格式化输出,首行缩进4个空格 print(json.dumps(x,indent=4, sort_keys=True)) # 格式化输出,首行缩进4个空格,按key排序
18. pip 包管理,也就是c# 的nuget 管理,Python3.4及更高版本自带了pip
安装pip :https://pypi.org/project/pip/
查找各种包地址:https://pypi.org/
常用命令(直接在终端使用命令就行了):
pip --version :查看pip版本
pip install 【包名称】 : 安装【包名称】 ps: pip install camelcase 安装驼峰命名包
pip uninstall 【包名称】 : 删除【包名称】 ps: pip uninstall camelcase 删除驼峰命名包
pip list :列出所有包
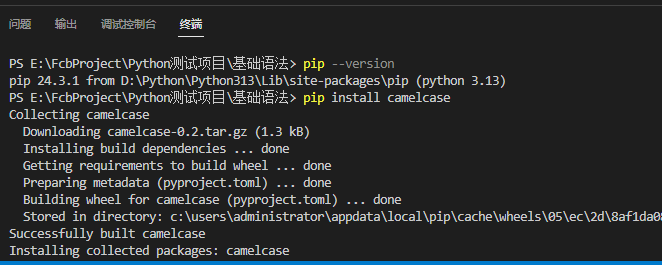
上面安装了 camelcase ,所以这里才能import 引用
import camelcase c = camelcase.CamelCase() txt = "hello world" print(c.hump(txt))
19. try ... except 也就是 try catch
try: print("代码块儿") except: print("执行出错了") else: print("没有错误才会执行我") finally: print("执行结束了")
20. input用户输入 , 也就是c# 的 Console.ReadLine()
username = input("Enter username:") print("Username is: " + username)
文件处理
1. 文件处理 open()
打开文件有四种不同的方法(mode): "r"- 读取 - 默认值。打开文件进行读取,如果文件不存在则出错 "a"- 附加 - 打开文件进行附加,如果文件不存在则创建该文件 "w"- 写入 - 打开文件进行写入,如果文件不存在则创建该文件 "x"- 创建 - 创建指定文件,如果文件存在则返回错误 还可以指定文件是否应以二进制或文本模式处理: "t"- 文本 - 默认值。文本模式 "b"- 二进制 - 二进制模式(例如图像)
2. 读取文件
f = open("C:\\Users\\Administrator\\Desktop\\测试文件.txt", "r",encoding="utf-8") #print(f.read()) # 读取整个文件内容 #print(f.read(2)) # 读取前2个字符 #print(f.readline()) # 运行一次读取一行 #print(f.readline()) # 运行一次读取一行 #print(f.readlines()) # 读取所有行并返回列表 for x in f: print(x) # 循环读取所有行并打印 f.close() # 关闭文件流
3. 写入现有文件
"a"- 附加 - 将附加到文件末尾 "w"- 写入 - 将覆盖任何现有内容"x"- 创建 - 将创建一个文件,如果文件存在则返回错误
f = open("C:\\Users\\Administrator\\Desktop\\测试文件.txt", "a",encoding="utf-8") f.write("\nHello, world!") # 文件末尾追加内容 f.close() # 关闭文件流 f = open("C:\\Users\\Administrator\\Desktop\\测试文件.txt", "w",encoding="utf-8") f.write("\nHello, world!") # 直接覆盖文件内容 f.close() # 关闭文件流
4. 创建文件
f = open("C:\\Users\\Administrator\\Desktop\\测试文件.txt", "a",encoding="utf-8") f.write("\nHello, world!") # 文件末尾追加内容 f.close() # 关闭文件流 f = open("C:\\Users\\Administrator\\Desktop\\测试文件.txt", "w",encoding="utf-8") f.write("\nHello, world!") # 直接覆盖文件内容 f.close() # 关闭文件流 f = open("C:\\Users\\Administrator\\Desktop\\测试文件2.txt", "x",encoding="utf-8") # 创建新文件 f.write("Hello, world11111!") f.close() # 关闭文件流
5. 删除文件
#文件存在就删除 if os.path.exists("C:\\Users\\Administrator\\Desktop\\测试文件.txt"): os.remove("C:\\Users\\Administrator\\Desktop\\测试文件.txt") print("The file has been deleted") else: print("The file does not exist")
Mysql
安装mysql驱动程序
python -m pip install mysql-connector-python
连接mysql
import mysql.connector
mydb = mysql.connector.connect(
host="数据库地址",
user="账号",
password="密码",
database="数据库名称"
) print(mydb)
1. 插入数据
使用execute 执行,并最后要手动 commit() 提交才会成功
import mysql.connector mydb = mysql.connector.connect( host="localhost", user="root", password="hua3182486", database="hello" ) mycursor = mydb.cursor() sql = "insert into hello.userinfo (name, age) values (%s,%s);" val = ("小二", "18") mycursor.execute(sql, val) #插入单行数据 #val = [("小三", "19"), # ("小四", "20")] #mycursor.executemany(sql, val) #插入多行数据 mydb.commit() #提交事务 print("插入最新一行数据的ID:", mycursor.lastrowid)
2. 查询数据使用
fetchone :查询一条数据
fetchall:查询所有数据
import mysql.connector mydb = mysql.connector.connect( host="localhost", user="root", password="hua3182486", database="hello" ) mycursor = mydb.cursor() sql = "select * from hello.userinfo" mycursor.execute(sql) #myresult = mycursor.fetchall() # fetchall() 方法用于获取所有记录 myresult = mycursor.fetchone() # fetchone() 方法用于获取一条记录 print(myresult)
3. 删除
和新增一样,需要手动提交
import mysql.connector mydb = mysql.connector.connect( host="localhost", user="root", password="hua3182486", database="hello" ) mycursor = mydb.cursor() sql = "DELETE FROM hello.userinfo WHERE name = '小二'" mycursor.execute(sql) mydb.commit() print(mycursor.rowcount, "record(s) deleted")
4. 修改
和新增,删除一样
import mysql.connector mydb = mysql.connector.connect( host="localhost", user="root", password="hua3182486", database="hello" ) mycursor = mydb.cursor() sql = "DELETE FROM hello.userinfo WHERE name = '小二'" sql = "UPDATE hello.userinfo SET name = '小二' WHERE name = '小三'" mycursor.execute(sql) mydb.commit() print(mycursor.rowcount, "record(s) affected")
Python 爬虫-BeautifulSoup
爬虫的基本流程通常包括发送 HTTP 请求获取网页内容、解析网页并提取数据,然后存储数据。
一般来说,爬虫的流程可以分为以下几个步骤:
发送 HTTP 请求:爬虫通过 HTTP 请求从目标网站获取 HTML 页面,常用的库包括 requests。 解析 HTML 内容:获取 HTML 页面后,爬虫需要解析内容并提取数据,常用的库有 BeautifulSoup、lxml、Scrapy 等。 提取数据:通过定位 HTML 元素(如标签、属性、类名等)来提取所需的数据。 存储数据:将提取的数据存储到数据库、CSV 文件、JSON 文件等格式中,以便后续使用或分析。
这里主要介绍 BeautifulSoup
注意:BeautifulSoup只能获取初始HTML,无法执行JS,我们F12看到的网页html内容是浏览器执行了JavaScript动态生成的内容
所以BeautifulSoup+requests只能用于简单的需求,如果要获取浏览器渲染后的最终HTML,需要使用能模拟浏览器行为的工具,而不是简单的requests请求,例如后面的Selenium。
安装依赖
pip install beautifulsoup4 pip install lxml # 推荐使用 lxml 作为解析器(速度更快) pip install requests # 使用requests 进行http请求 pip install chardet #使用chardet 进行获取字符编码
基本用法
from bs4 import BeautifulSoup import requests # 使用 requests 获取网页内容 url = 'https://cn.bing.com/' # 抓取bing搜索引擎的网页内容 response = requests.get(url) # 使用 BeautifulSoup 解析网页 soup = BeautifulSoup(response.text, 'lxml') # 使用 lxml 解析器 # 解析网页内容 html.parser 解析器 # soup = BeautifulSoup(response.text, 'html.parser')
抓取网页标题及设置编码格式
from bs4 import BeautifulSoup import requests import chardet # 指定你想要获取标题的网站 url = 'https://cn.bing.com/' # 抓取bing搜索引擎的网页内容 # 发送HTTP请求获取网页内容 response = requests.get(url) # 使用 chardet 自动检测编码 encoding = chardet.detect(response.content)['encoding'] print(encoding) # 中文乱码问题 response.encoding = encoding #response.encoding = 'utf-8' # 如果知道是编码格式,可以手动指定编码方式 # 确保请求成功 if response.status_code == 200: # 使用BeautifulSoup解析网页内容 soup = BeautifulSoup(response.text, 'lxml') #print(soup.prettify()) # 打印网页内容 # 查找<title>标签 title_tag = soup.find('title') # 打印标题文本 if title_tag: print(title_tag.get_text()) else: print("未找到<title>标签") else: print("请求失败,状态码:", response.status_code)
查找标签
BeautifulSoup 提供了多种方法来查找网页中的标签,最常用的包括 find() 和 find_all()。
find() 返回第一个匹配的标签 find_all() 返回所有匹配的标签
from bs4 import BeautifulSoup import requests import chardet # 指定你想要获取标题的网站 url = 'https://www.baidu.com/' # # 发送HTTP请求获取网页内容 response = requests.get(url) # 使用 chardet 自动检测编码 encoding = chardet.detect(response.content)['encoding'] #print(encoding) # 中文乱码问题 response.encoding = encoding #response.encoding = 'utf-8' # 如果知道是编码格式,可以手动指定编码方式 # 确保请求成功 if response.status_code == 200: # 使用BeautifulSoup解析网页内容 soup = BeautifulSoup(response.text, 'lxml') #print(soup.prettify()) # 打印网页内容 # 查找<a>标签 first_link = soup.find('a') print(first_link) print("----------------------------") # 查找<a>标签的href属性 print(first_link.get('href')) print("----------------------------") #查找<a>标签的文本内容 print(first_link.get_text()) print("----------------------------") # 查找所有 <a> 标签 all_links = soup.find_all('a') print(all_links) print("----------------------------") # 获取当前标签的父标签 parent_tag = first_link.parent print(parent_tag.get_text()) print("----------------------------") # 查找所有 class="example-class" 的 <div> 标签 divs_with_class = soup.find_all('div', class_='example-class') print(divs_with_class) print("----------------------------") # 查找具有 id="su" 的 <input> 标签 input_tag = soup.find('input', id='su') print(input_tag.get('value')) print("----------------------------") unique_span_parent = soup.find_all('span', id='s_btn_wr') if unique_span_parent: print(unique_span_parent) else: print("没有找到") else: print("请求失败,状态码:", response.status_code)
修改html内容
from bs4 import BeautifulSoup import requests import chardet # 指定你想要获取标题的网站 url = 'https://www.baidu.com/' # # 发送HTTP请求获取网页内容 response = requests.get(url) # 使用 chardet 自动检测编码 encoding = chardet.detect(response.content)['encoding'] # 中文乱码问题 response.encoding = encoding # 确保请求成功 if response.status_code == 200: # 使用BeautifulSoup解析网页内容 soup = BeautifulSoup(response.text, 'lxml') # 修改第一个 <p> 标签的文本内容 first_paragraph = soup.find('p') first_paragraph.string = 'Updated content' else: print("请求失败,状态码:", response.status_code)
Python 爬虫-Selenium
上面示例中,BeautifulSoup只能获取初始HTML,无法执行JS,我们F12看到的网页html内容是浏览器执行了JavaScript动态生成的内容
所以BeautifulSoup+requests只能用于简单的需求,如果要获取浏览器渲染后的最终HTML,需要使用能模拟浏览器行为的工具,而不是简单的requests请求。
Selenium(浏览器自动化工具)就可以获取到最终浏览器渲染的网页内容,而且还支持多种语音,例如python, c#,java 等等。核心优势,技术局限以及使用的场景如下

主要适合登录类的社交平台数据抓取
准备工作
安装 selenium
pip install selenium # 安装selenium
安装完成后检查selenium 版本
pip show selenium
下载浏览器驱动(Selenium 4.x版本引入了一个新特性 - 它能够自动检测和管理浏览器驱动的下载,所以可以不用在这里手动下载浏览器驱动)
Selenium 需要通过浏览器驱动来控制浏览器。不同的浏览器需要不同的驱动。
这里以谷歌为例,点击下载
基本用法
注意可以手动指定谷歌的驱动路径,如果是4.x 以上版本就可以直接使用 webdriver.Chrome() ,运行时会在当前文件目录同级找对应的谷歌exe驱动文件或者通过path环境变量去找exe驱动文件,如果都找不到,文件运行时会根据浏览器版本自动下载相应的驱动,
会保存到对应的缓存文件夹中,如果不想每次下载,建议将驱动文件放在同级目录中
from selenium import webdriver from selenium.webdriver.chrome.service import Service #手动指定chromedriver路径 #service = Service(r'WebDriver/ChromeDriver/chromedriver.exe') #driver = webdriver.Chrome(service=service) #自动在电脑中path中寻找chromedriver,如果没有找到会在当前目录下寻找, #如果也没有就会自动识别当前电脑chrome版本并下载chromedriver到 C:\Users\Administrator\.cache\selenium\chromedriver\win64\135.0.7049.42 缓存起来 driver = webdriver.Chrome() #打开网页 driver.get('https://www.baidu.com') print(driver.title) #关闭浏览器 driver.quit()
这里运行时会启动浏览器,运行完成后会自动关闭。
注意,driver.get 会在网络不好或者内容较多的情况不会加载完就会执行后面的代码,这里先通过time 进行固定等待进行测试,下面会具体说明各种等待机制
强制停止加载:window.stop();
from selenium import webdriver import time driver = webdriver.Chrome() #打开网页 driver.get('https://www.baidu.com') # 等待页面加载完成 time.sleep(2) # 可以根据需要调整等待时间 # 强制停止页面加载 driver.execute_script("window.stop();") # 获取页面标题 print(driver.title) # 关闭浏览器 driver.quit()
WebDriver 浏览器相关操作
相当于模拟浏览器的一些操作,比如窗口,刷新,后退操作,还可以操作 Cookies、执行 JavaScript 等
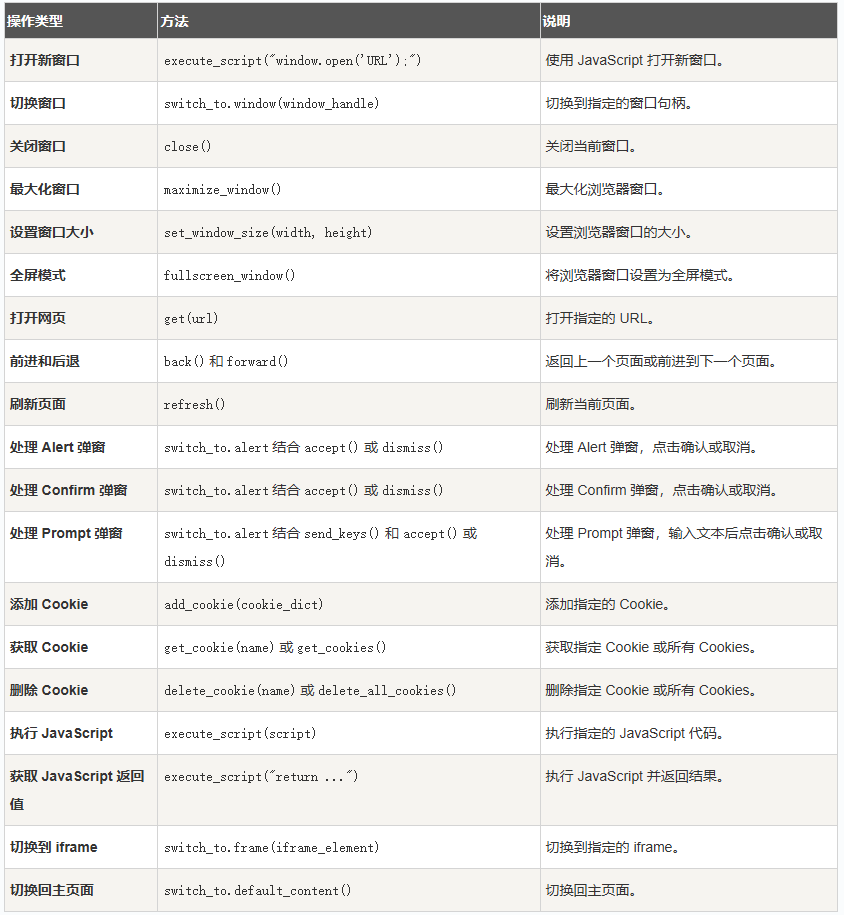
from selenium import webdriver import time driver = webdriver.Chrome() # 打开网页 driver.get('https://www.baidu.com') # 最大化窗口 driver.maximize_window() #driver.minimize_window() # 最小化窗口 #driver.set_window_size(1024, 768) # 设置窗口大小为 1024x768 像素 #driver.fullscreen_window() # 全屏窗口 time.sleep(2) # 等待 2 秒 # 获取页面标题和 URL print("页面标题:", driver.title) print("当前 URL:", driver.current_url) # 导航到另一个页面 driver.get("https://www.jyshare.com") #time.sleep(2) # 等待 2 秒 # 返回上一个页面 driver.back() #time.sleep(2) # 等待 2 秒 # 刷新页面 driver.refresh() # 关闭浏览器 driver.quit()
还可以进行高级用法,比如说操作cookie 和本地存储进行模拟已经登录的场景
from selenium import webdriver import time from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import NoSuchElementException driver = webdriver.Chrome() driver.maximize_window() # 打开网页 driver.get('http://192.168.0.236:9921/#/index') # 添加 Cookie driver.add_cookie({"name": "transcriptiontoken", "value": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIwMDAwMDAwMC0wMDAwLTAwMDAtMDAwMC0wMDAwMDAwMDAwMDAiLCJuYW1lIjoi5oiQ6YO96IGM5Lia5oqA5pyv5a2m5qChIiwiemxneG1jIjoi5oiQ6YO96IGM5Lia5oqA5pyv5a2m5qChIiwiemxneGRtIjoiNTE2ODgiLCJ4eGxiIjoi5Lit6IGMIiwiY29udGFjdHMiOiLotKPku7vkuroiLCJtb2JpbGUiOiIxNTc3NTYwMTE3NyIsImVtYWlsIjoiMTQ1OTAxNzE0MEBxcS5jb20iLCJuYmYiOjE3NDQxMDEwOTQsImV4cCI6MTc0NDE4NzQ5NCwiaXNzIjoiaHR0cDovLzE5Mi4xNjguMC4yMzY6OTkxMCIsImF1ZCI6IkhTQ2xpZW50In0.1yVRQ89aHEOKEdnNyJHJT0HlPMepixHQVayIU7Afn1s"}) driver.add_cookie({"name": "screenResolution", "value": "1920x1080"}) driver.add_cookie({"name": "JSESSIONID.3e2a8efc", "value": "node0a99n9l4joeamx1i5jgirkozf320.node0"}) driver.add_cookie({"name": "expires_in", "value": "NaN"}) driver.add_cookie({"name": "test", "value": "123"}) # 添加 localStorage 数据 driver.execute_script(""" localStorage.setItem('userInfo', '{"c":1744101095866,"e":253402300799000,"v":"{\\\\"accessToken\\\\":\\\\"eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIwMDAwMDAwMC0wMDAwLTAwMDAtMDAwMC0wMDAwMDAwMDAwMDAiLCJuYW1lIjoi5oiQ6YO96IGM5Lia5oqA5pyv5a2m5qChIiwiemxneG1jIjoi5oiQ6YO96IGM5Lia5oqA5pyv5a2m5qChIiwiemxneGRtIjoiNTE2ODgiLCJ4eGxiIjoi5Lit6IGMIiwiY29udGFjdHMiOiLotKPku7vkuroiLCJtb2JpbGUiOiIxNTc3NTYwMTE3NyIsImVtYWlsIjoiMTQ1OTAxNzE0MEBxcS5jb20iLCJuYmYiOjE3NDQxMDEwOTQsImV4cCI6MTc0NDE4NzQ5NCwiaXNzIjoiaHR0cDovLzE5Mi4xNjguMC4yMzY6OTkxMCIsImF1ZCI6IkhTQ2xpZW50In0.1yVRQ89aHEOKEdnNyJHJT0HlPMepixHQVayIU7Afn1s\\\\",\\\\"expires\\\\":\\\\"2025-04-09T16:31:34.0996131+08:00\\\\",\\\\"zlgxdm\\\\":\\\\"51688\\\\",\\\\"zlgxmc\\\\":\\\\"成都职业技术学校\\\\",\\\\"contacts\\\\":\\\\"责任人\\\\",\\\\"mobile\\\\":\\\\"15775601177\\\\",\\\\"email\\\\":\\\\"1459017140@qq.com\\\\",\\\\"xxlb\\\\":\\\\"中职\\\\",\\\\"bz\\\\":null}"}'); localStorage.setItem('isAdmin', '{"c":1744101095866,"e":253402300799000,"v":"\\\\"51688\\\\""}'); localStorage.setItem('isDark', 'false'); localStorage.setItem('key1', 'value1'); // 你可以根据需要添加更多的 localStorage 数据 """) driver.refresh() # 获取所有 Cookies cookies = driver.get_cookies() print(cookies) print('---------------') # 删除 Cookie driver.delete_cookie("test") cookies = driver.get_cookies() print(cookies) # 让脚本等待用户输入,从而保持浏览器打开状态 input("按任意键关闭浏览器...") # 关闭浏览器 driver.quit()
这样可以直接写入cookie ,不需要进行下面的元素操作也可以达到登录的效果,前提是要知道账号密码,可以通过授权接口拿到token 写入cookie中
元素定位
就是精准定位到某个元素(如按钮、输入框、链接等)方便后续进行操作(如点击、输入等),并且要保证定位到的元素唯一性。
这里演示都是使用的 find_element:返回第一个匹配到的元素 。也可以全部改成 find_elements :就是返回所有匹配到的元素返回的是一个数组
from selenium import webdriver import time from selenium.webdriver.common.by import By driver = webdriver.Chrome() # 打开网页 driver.get('https://www.baidu.com') #查找这个元素<input type="submit” id="su" value=”百度一下” class="bg s_btn"> # 通过id定位元素 element = driver.find_element(By.ID, "su") print(element.get_attribute("value")) # 通过class定位元素,只能查找单个类名 element = driver.find_element(By.CLASS_NAME, "s_btn") print(element.get_attribute("value")) # 通过 CSS 选择器定位,支持多个类名 element = driver.find_element(By.CSS_SELECTOR, ".bg.s_btn") # 通过name定位元素 element = driver.find_element(By.NAME, "password") #通过元素的标签名定位 element = driver.find_element(By.TAG_NAME, "input") #通过 XPath 定位(通过 XPath 表达式定位元素。) element = driver.find_element(By.XPATH, "//input[@id='username']") #通过 Link Text 定位(通过链接的文本内容定位(适用于 <a> 标签)) element = driver.find_element(By.LINK_TEXT, "设置") #通过 Partial Link Text 定位(通过链接的部分文本内容定位。) element = driver.find_element(By.PARTIAL_LINK_TEXT, "设置") # 让脚本等待用户输入,从而保持浏览器打开状态 input("按任意键关闭浏览器...") # 关闭浏览器 driver.quit()
注意:
优先使用唯一属性:
-
尽量使用
id、name等唯一属性定位元素。
避免使用动态属性:
-
如果元素的属性是动态生成的(如随机 ID),避免直接使用这些属性定位。
使用相对定位:
-
使用 XPath 或 CSS 选择器结合元素的层级关系定位。
添加等待机制:
-
使用隐式等待或显式等待确保元素加载完成后再进行操作。
动态定位元素
网页中很多元素是动态加载的,正对于这种动态加载的元素我们可以使用等待机制,这里是一个显示等待
from selenium import webdriver import time from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Chrome() # 打开网页 driver.get('https://www.baidu.com') #查找这个元素<input type="submit” id="su" value=”百度一下” class="bg s_btn"> # 如果在指定的 10 秒内找到了 ID 为 "su" 的元素,那么这个元素就会被赋值给变量 element。如果超时没有找到这个元素,Selenium 会抛出一个 TimeoutException 异常 element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "su")) ) # 让脚本等待用户输入,从而保持浏览器打开状态 input("按任意键关闭浏览器...") # 关闭浏览器 driver.quit()
元素操作
定位到元素后,可以对其进行各种操作,例如点击、输入文本、获取属性等
from selenium import webdriver import time from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Chrome() driver.maximize_window() # 打开网页 driver.get('https://www.baidu.com') # 定位输入框并输入搜索关键字 element_ku = driver.find_element(By.ID, "kw") element_ku.send_keys("python") # 定位搜索按钮并点击,点击后应该等待页面加载完成(这里忽略了) element_su = driver.find_element(By.ID, "su") element_su.click() time.sleep(2) #清空搜索框 element_ku.clear() #获取元素属性 attribute_value = element_su.get_attribute("class") print(attribute_value) #获取元素文本 text_content = element_su.text print(text_content) #复选框和单选框操作 # 定位复选框元素 checkbox_element = driver.find_element_by_id("checkbox-id") # 如果复选框未被选中,则点击选中 if not checkbox_element.is_selected(): checkbox_element.click() # 定位单选框元素 radio_button_element = driver.find_element_by_id("radio-button-id") # 如果单选框未被选中,则点击选中 if not radio_button_element.is_selected(): radio_button_element.click() #下拉列表操作 dropdown_element = driver.find_element_by_id("dropdown-id") # 创建Select对象 select = Select(dropdown_element) # 通过可见文本选择选项 select.select_by_visible_text("Option 1") # 通过值选择选项 select.select_by_value("1") # 通过索引选择选项 select.select_by_index(0) # 上传文件操作 通过 <input type="file"> 元素上传文件 file_element = driver.find_element_by_id("file-id") file_element.send_keys("C:\\Users\\Administrator\\Desktop\\test.txt") #鼠标操作ActionChains from selenium.webdriver.common.action_chains import ActionChains action = ActionChains(driver) # 鼠标水平不滚动,向下垂直滚动200px action.scroll_by_amount(0, 200).perform() time.sleep(1) # 鼠标水平不滚动,向上垂直滚动100px action.scroll_by_amount(0, -100).perform() time.sleep(1) # 通过js脚本操作页面 向下滚动页面,水平不滚动,向下垂直滚动200px #driver.execute_script("window.scrollBy(0, 200);") # 通过js脚本操作页面 向下滚动页面,水平滚动100px,向下垂直滚动300px #driver.execute_script("window.scrollBy(100, 300);") # 定位页面底部并滚动到底部 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 鼠标向下移动 action.move_by_offset(0, 100).perform() # 鼠标向上移动 action.move_by_offset(0, -100).perform() # 鼠标左键单击 action.click().perform() # 鼠标左键双击 action.double_click().perform() # 鼠标左键拖动 action.drag_and_drop(element_ku, element_su).perform() # 鼠标右键单击 action.context_click().perform() # 鼠标右键拖动 action.context_click(element_su).perform() # 鼠标中键单击 action.click_and_hold().perform() # 鼠标中键释放 action.release().perform() # 鼠标中键拖动 action.move_to_element(element_su).perform() # 鼠标中键拖动到指定位置 action.move_to_element_with_offset(element_su, 100, 100).perform() # 鼠标悬停 action.move_to_element(element_su).perform() # 键盘操作 Keys from selenium.webdriver.common.keys import Keys # 导入Keys类 element_ku.clear() element_ku.send_keys("c#") # 模拟按下回车键 element_ku.send_keys(Keys.RETURN) # 让脚本等待用户输入,从而保持浏览器打开状态 input("按任意键关闭浏览器...") # 关闭浏览器 driver.quit()
等待机制
在 Selenium 中,等待机制是确保页面元素加载完成后再进行操作的关键。由于网页加载速度受网络、服务器性能等因素影响,直接操作未加载完成的元素会导致脚本失败。Selenium 提供了多种等待机制来解决这一问题。
上面提了显示等待、隐式等待和固定等待,这里具体进行说明各种等待的优缺点
1. 隐式等待
隐式等待是一种全局性的等待机制,它会在查找元素时等待一定的时间。如果在指定的时间内找到了元素,Selenium 会立即继续执行后续操作;如果超时仍未找到元素,则会抛出 NoSuchElementException 异常。
隐式等待通过 implicitly_wait() 方法来设置。这个方法只需要调用一次,之后的所有元素查找操作都会遵循这个等待时间。
优点:
- 简单易用,只需设置一次即可应用于所有元素查找操作。
- 适用于大多数简单的场景。
缺点:
- 全局性等待,可能会导致不必要的等待时间。
- 无法处理某些复杂的等待条件,例如等待元素变为可点击状态。
from selenium import webdriver import time from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Chrome() # 设置隐式等待时间为10秒,10秒内如果页面元素加载完成则立即返回,否则抛出异常 driver.implicitly_wait(5) driver.maximize_window() # 打开网页 driver.get('https://www.baidu.com') # 定位输入框并输入搜索关键字 element_ku = driver.find_element(By.ID, "kw") element_ku.send_keys("python") element_su = driver.find_element(By.ID, "su") element_su.click() # 查找元素并滚动页面 element = driver.find_element(By.ID,"con-ceiling-wrapper") driver.execute_script("window.scrollBy(0, 500);") # 让脚本等待用户输入,从而保持浏览器打开状态 input("按任意键关闭浏览器...") # 关闭浏览器 driver.quit()
2. 显示等待
显式等待是一种更为灵活的等待机制,它允许你为特定的操作设置等待条件。显式等待通常与 WebDriverWait 类和 expected_conditions 模块一起使用。
from selenium import webdriver import time from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import NoSuchElementException driver = webdriver.Chrome() driver.maximize_window() # 打开网页 driver.get('https://www.baidu.com') # 定位输入框并输入搜索关键字 element_ku = driver.find_element(By.ID, "kw") element_ku.send_keys("python") element_su = driver.find_element(By.ID, "su") element_su.click() # 设置显式等待,最多等待 10 秒,直到元素出现 element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "con-ceiling-wrapper")) ) # 设置 Fluent Wait。 #poll_frequency定义了 Selenium 在等待过程中检查一次条件的时间间隔,单位是秒。不设置默认0.5秒 #ignored_exceptions=[NoSuchElementException]: 定义了忽略的异常类型列表。NoSuchElementException 被添加到了这个列表中,这意味着如果在等待过程中 Selenium 捕捉到了 NoSuchElementException 异常,它不会立即中断等待过程,而是会继续等待直到元素出现或达到设定的最大等待时间。这样可以避免因为页面加载速度较慢或者元素还未加载而导致脚本中断 #wait = WebDriverWait(driver, timeout=0.01, poll_frequency=1, ignored_exceptions=[NoSuchElementException]) #element = wait.until(EC.presence_of_element_located((By.ID, "con-ceiling-wrapper"))) driver.execute_script("window.scrollBy(0, 500);") # 让脚本等待用户输入,从而保持浏览器打开状态 input("按任意键关闭浏览器...") # 关闭浏览器 driver.quit()
expected_conditions 模块提供了多种预定义的等待条件,以下是一些常用的条件:
presence_of_element_located:等待元素出现在 DOM 中。visibility_of_element_located:等待元素出现在 DOM 中并且可见。element_to_be_clickable:等待元素可点击。text_to_be_present_in_element:等待元素的文本包含指定的文本。
优点:
- 灵活性高,可以为不同的操作设置不同的等待条件。
- 可以处理复杂的等待场景。
缺点:
- 代码相对复杂,需要更多的代码量。
- 需要为每个操作单独设置等待条件。
3. 固定等待
固定等待是一种最简单的等待机制,它通过 time.sleep() 方法让脚本暂停执行指定的时间。无论页面是否加载完成,脚本都会等待指定的时间后再继续执行。
from selenium import webdriver import time from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Chrome() driver.maximize_window() # 打开网页 driver.get('https://www.baidu.com') # 定位输入框并输入搜索关键字 element_ku = driver.find_element(By.ID, "kw") element_ku.send_keys("python") element_su = driver.find_element(By.ID, "su") element_su.click() # 固定等待 5 秒 time.sleep(5) # 查找元素并滚动页面 element = driver.find_element(By.ID,"con-ceiling-wrapper") driver.execute_script("window.scrollBy(0, 500);") # 让脚本等待用户输入,从而保持浏览器打开状态 input("按任意键关闭浏览器...") # 关闭浏览器 driver.quit()
Selenium测试框架集成
Selenium 可以与多种测试框架集成,例如 unittest 和 pytest,从而实现更结构化的测试代码管理和测试报告生成。
与 unittest 集成
unittest 是 Python 标准库中的一个测试框架,它提供了丰富的断言方法和测试组织方式。我们可以将 Selenium 与 unittest 集成,以编写结构化的测试用例。
import unittest from selenium import webdriver from selenium.webdriver.chrome.service import Service as ChromeService from selenium.webdriver.common.by import By import time class TestGoogleSearch(unittest.TestCase): def setUp(self): # 设置正确的驱动路径 self.driver = webdriver.Chrome() self.driver.get("https://www.baidu.com") def test_search(self): # 定位输入框并输入搜索关键字 element_ku = self.driver.find_element(By.ID, "kw") element_ku.send_keys("Selenium") # 定位搜索按钮并点击,点击后应该等待页面加载完成(这里忽略了) element_su = self.driver.find_element(By.ID, "su") element_su.click() time.sleep(2) #断言页面标题中是否包含"Selenium" self.assertIn("Selenium", self.driver.title) def tearDown(self): self.driver.quit() #如果是主程序运行,则执行测试用例 if __name__ == "__main__": unittest.main()
setUp方法:在每个测试用例执行之前运行,用于初始化测试环境。在这里,我们启动浏览器并打开Google首页。test_search方法:这是一个测试用例,用于测试Google搜索功能。我们找到搜索框,输入"Selenium",然后提交搜索。最后,我们断言页面标题中是否包含"Selenium"。tearDown方法:在每个测试用例执行之后运行,用于清理测试环境。在这里,我们关闭浏览器。
直接在当前页面运行,也可以通过以下命令运行测试:
python -m unittest test_baidu_search.py
与 pytest 集成
pytest 是另一个流行的Python测试框架,它提供了更简洁的语法和更强大的功能。我们可以将Selenium与pytest集成,以编写更灵活的测试用例。
import time import pytest from selenium import webdriver from selenium.webdriver.chrome.service import Service as ChromeService from selenium.webdriver.common.by import By # pytest 中的 fixture 是一种用于设置和清理测试环境的特殊函数。在这个 fixture 中,yield 语句之前的部分用于设置环境(在这个例子中,启动 Chrome 浏览器), #而 yield 语句之后的部分用于清理环境(在这个例子中,关闭浏览器)。 @pytest.fixture def browser(): # 设置环境,启动 Chrome 浏览器 driver = webdriver.Chrome() yield driver # 清理环境,关闭浏览器 driver.quit() #测试用例 def test_baidu_search(browser): browser.get("https://www.baidu.com") # 定位输入框并输入搜索关键字 element_ku = browser.find_element(By.ID, "kw") element_ku.send_keys("Selenium") # 定位搜索按钮并点击,点击后应该等待页面加载完成(这里忽略了) element_su = browser.find_element(By.ID, "su") element_su.click() time.sleep(2) assert "Selenium" in browser.title
browser夹具:这是一个pytest夹具,用于在每个测试用例执行之前启动浏览器,并在测试用例执行之后关闭浏览器。test_baidu_search函数:这是一个测试用例,用于测试Google搜索功能。我们找到搜索框,输入"Selenium",然后提交搜索。最后,我们断言页面标题中是否包含"Selenium"。
Selenium 无头浏览器
无头浏览器模式(Headless Mode)是指在没有图形用户界面(GUI)的情况下运行浏览器,换句话说,浏览器在后台运行,不会弹出可见的窗口。
无头浏览器模式通常用于自动化测试、网页抓取、性能测试等场景,因为它可以节省系统资源,并且在没有显示器的服务器上也能正常运行。
无头浏览器模式优势
- 节省资源:无头模式不需要渲染图形界面,因此可以节省 CPU 和内存资源。
- 提高速度:由于不需要加载和渲染图形界面,无头模式通常比普通模式更快。
- 适合自动化:在自动化测试和网页抓取中,无头模式可以避免干扰,并且可以在没有显示器的服务器上运行。
- 便于调试:在某些情况下,无头模式可以帮助开发者更快地调试和定位问题
无头浏览器模式缺点
- JavaScript执行:某些复杂的JavaScript可能在无头模式下表现不同。
- 调试困难:由于没有用户界面,调试无头模式下的问题可能更加困难。
无头模式只需要设置参数 chrome_options.add_argument("--headless") 就行了,其他参数是优化 ,还可以保存截图和浏览器日志,方便调试
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.options import Options # 设置 Chrome 无头模式 chrome_options = Options() chrome_options.add_argument("--headless") # 启用无头模式 chrome_options.add_argument("--disable-gpu") # 禁用 GPU 加速 chrome_options.add_argument("--window-size=1920,1080") # 设置窗口大小 # 创建 WebDriver 实例 driver = webdriver.Chrome(options=chrome_options) # 设置隐式等待时间为10秒,10秒内如果页面元素加载完成则立即返回,否则抛出异常 driver.implicitly_wait(10) # 打开网页 driver.get('https://www.baidu.com') # 通过id定位元素 element = driver.find_element(By.ID, "su") print(element.get_attribute("value")) # 当前目录下保存当前页面的截图,方便调试查找问题 driver.save_screenshot('screenshot.png') #获取浏览器日志。 logs=driver.get_log('browser') print(logs) # 关闭浏览器 driver.quit()
Selenium 性能优化
1. 减少页面加载时间
禁用图片加载:通过配置浏览器选项禁用图片加载,可以减少页面加载时间。
chrome_options = Options() chrome_options.add_argument("--blink-settings=imagesEnabled=false")
禁用JavaScript:在某些情况下,禁用JavaScript可以加快页面加载速度。
chrome_options = Options() chrome_options.add_argument("--disable-javascript")
2. 并行执行测试
使用 Selenium Grid 或第三方工具(如pytest-xdist)可以并行执行测试,从而减少总执行时间。
# 使用pytest-xdist并行执行测试 pytest -n 4 # 使用4个进程并行执行
3.使用高效的定位策略
选择高效的定位策略可以减少元素查找时间。例如,优先使用 By.ID 或 By.NAME,而不是 By.XPATH。
element = driver.find_element(By.ID, "element-id")
4.减少不必要的等待
避免不必要的等待可以提高脚本的执行效率。确保只在必要时使用等待机制。
# 仅在需要时等待 if not element.is_displayed(): WebDriverWait(driver, 10).until(EC.visibility_of(element))
Python 爬虫-Scrapy
可以查看国内菜鸟教程的Scrapy 入门教程
scrapy是专业级爬虫框架, 是一个用于抓取网站并提取结构化数据的应用程序框架,可用于数据挖掘、信息处理或历史档案等多种有用的应用。Scrapy默认根据URL去重,可通过dont_filter=True关闭。
相对于Selenium 更加适合大规模的数据采集,具体的核心优势,技术局限以及场景如下

更适合静态类不需要用户登录的网站比如很多电商商品抓取
和Selenium 比较
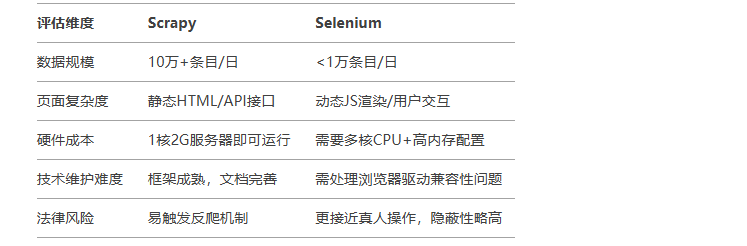
创建项目
scrapy startproject fcbscrapy 创建了一个fcbscrapy 项目
创建命令:
scrapy startproject [项目名称]
创建成功后,会在当前目录自动生成文件

- scrapy.cfg: 项目的配置文件。
- fcbscrapy/: 项目的Python模块,将会从这里引用代码。
- fcbscrapy/items.py: 项目的目标文件。
- fcbscrapy/pipelines.py: 项目的管道文件。
- fcbscrapy/settings.py: 项目的设置文件。
- fcbscrapy/spiders/: 存储爬虫代码目录。
简单示例
创建一个爬虫来抓取外网的一个文章的网站 https://quotes.toscrape.com/page/1/ ,这个网站有下一页的按钮

在fcbscrapy/spiders/下面创建一个爬虫类quotes_spider.py
from pathlib import Path import scrapy class DoubanSpider(scrapy.Spider): name = "quotes" #Spider 的标识,也就是爬虫名称,在项目内必须是唯一的,即不能为不同的 Spider 设置相同的名称 #start_requests 定义爬虫的起始页面,爬虫将从这些页面开始抓取。后续请求将从这些初始请求依次生成 # def start_requests(self): # urls = [ # "https://quotes.toscrape.com/page/1/", # "https://quotes.toscrape.com/page/2/", # ] # for url in urls: # yield scrapy.Request(url=url, callback=self.parse) #简写start_requests,只需要指定url列表即可,scrapy.Request会自动生成callback去回调parse方法 start_urls = [ "https://quotes.toscrape.com/page/1/", "https://quotes.toscrape.com/page/2/", ] #parse 方法是每个爬虫的核心部分,用于处理响应并提取数据。它接收一个 response 对象,表示服务器返回的页面内容。 def parse(self, response): print(f"开始解析页面:{response.url}") page = response.url.split("/")[-2] filename = f"quotes-{page}.html" Path(filename).write_bytes(response.body) self.log(f"Saved file {filename}")
这里涉及到了几个固定函数和属性
name:Spider 的标识,也就是爬虫名称,在项目内必须是唯一的,即不能为不同的 Spider 设置相同的名称 allowed_domains:限制爬虫的访问域名,防止爬虫爬取其他域名的网页。 start_requests(self):定义爬虫的起始页面,爬虫将从这些页面开始抓取。。后续请求将从这些初始请求依次生成 start_urls : 就是上面start_requests函数的简写方式,可以直接指定url列表即可,scrapy.Request会自动生成callback去回调parse方法 parse(self, response): parse 方法是每个爬虫的核心部分,用于处理响应并提取数据。它接收一个 response 对象,表示服务器返回的页面内容
运行爬虫
scrapy crawl quotes
运行命令为
scrapy crawl [爬虫名称]
运行成功后会在根目录新增两个文件 quotes-1.html 和quotes-2.html 里面是存储的两个网页的html
这里运行发生了什么?Scrapy 会调度Spiderscrapy.Request方法返回的对象start_requests。收到每个对象的响应后,它会实例化Response这些对象,并调用与请求关联的回调方法(在本例中为 parse方法),并将响应作为参数传递。
当然也可以用VS Code 直接运行代码方便进行调试
1. 点击左侧边栏的 运行和调试 图标
2. 点击 创建 launch.json 文件,选择 Python 环境
3. 生成的 launch.json 文件中,添加以下配置:
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "调试 Scrapy Spider",
"type": "python",
"request": "launch",
"module": "scrapy",
"console": "integratedTerminal",
"cwd": "${workspaceFolder}/fcbscrapy", // 根据实际路径调整,指向 Scrapy 项目根目录
// 启动命令 模拟scrapy crawl quotes
"args": [
"crawl",
"quotes",
//还可以模拟scrapy crawl quotes -O quotes-humor.json -a tag=humor 后面的参数
//"-O", "quotes-humor.json", // 输出到 JSON 文件
//"-a", "tag=humor" // 传递爬虫参数
//"-s", "LOG_LEVEL=DEBUG"
],
"env": {
"PYTHONPATH": "${workspaceFolder}/fcbscrapy"
}
}
]
}
4. 就可以设置断点进行调试了
浏览器中调试
有时只是想看看某个响应在浏览器中的样子,可以使用该open_in_browser()函数
from scrapy.utils.response import open_in_browser def parse_details(self, response): if "item name" not in response.body: open_in_browser(response)
提取数据
提取数据之前先了解一下选择器和 Scrapy shell
Scrapy shell 是一个交互式 shell,可以在其中快速尝试和调试抓取代码,而无需运行爬虫程序。它旨在用于测试数据提取代码。shell 用于测试 XPath 或 CSS 表达式,并查看它们的工作原理以及它们从您尝试抓取的网页中提取了哪些数据。它允许您在编写爬虫时以交互方式测试表达式,而无需运行爬虫来测试每个更改。
就是当你运行这个命令时,Scrapy 会下载指定的 URL 的内容,并打开一个交互式外壳控制台(通常是 IPython)。在这个控制台中,你可以直接使用 Scrapy 的选择器和提取器来尝试对网页内容进行抓取和解析,而不需要每次都运行整个爬虫。就是用于在控制台进行编写或调试爬虫命令的。
启动shell
scrapy shell <url> # 这里url 就是要抓取的网站url
(注意要在根目录运行)
还支持本地文件,网页的本地副本
scrapy shell file:///absolute/path/to/file.html
scrapy shell ./path/to/file.html
scrapy shell ../other/path/to/file.html
scrapy shell /absolute/path/to/file.html
注意在windows 上url要使用双引号,其他平台使用单引号.
scrapy shell "https://quotes.toscrape.com/page/1/"
运行成功后的界面
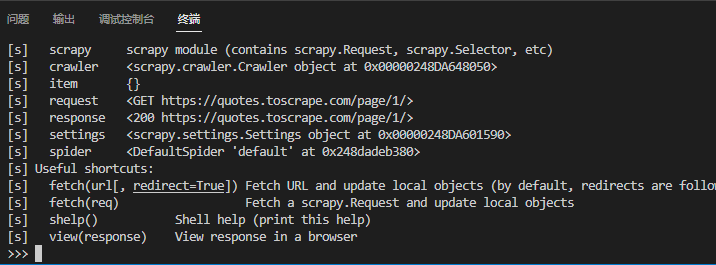
这里提示了能用的属性和方法,每个方法后面都有注释,这里列举几个常用的
crawler- 当前Crawler对象。 spider- 已知可以处理该 URL 的 Spider,或者 Spider如果未找到当前 URL 的 Spider,则为一个对象 request-Request上次获取的页面对象。您可以使用 修改此请求 replace(),或使用快捷方式获取新请求(无需离开 shell)fetch。 response-Response包含最后获取的页面的对象 settings- 当前的Scrapy 设置 view(response) 在浏览器打开连接
和选择器一起展示几个简单的示例
response.css("title") #查找title 标签 # 返回内容(是一个选择器):[<Selector query='descendant-or-self::title' data='<title>Quotes to Scrape</title>'>] response.css("title::text").getall() #标题中提取文档 #返回内容(列表):['Quotes to Scrape'] response.css("title").getall() #查找完整的title 元素 #返回内容(列表): ['<title>Quotes to Scrape</title>'] response.css("title::text").get() #返回第一个结果 # 'Quotes to Scrape' response.css("title::text").re(r"Quotes.*") #通过正则匹配 # ['Quotes to Scrape'] response.xpath("//title") # 结合xpath查找 xml/html 中所有title 标签 [<Selector query='//title' data='<title>Quotes to Scrape</title>'>] response.xpath("//title/text()").get() #查找所有title标签的text 文本并返回第一个结果 # 'Quotes to Scrape'
退出shell 命令
quit()
提取抓取的数据
上面只是在 shell 终端内部进行测试,那么可以把测试的命令放在代码中进行抓取
这里递归轮询爬取前五页数据
from pathlib import Path import scrapy class DoubanSpider(scrapy.Spider): name = "quotes" #Spider 的标识,也就是爬虫名称,在项目内必须是唯一的,即不能为不同的 Spider 设置相同的名称 #简写start_requests,只需要指定url列表即可,scrapy.Request会自动生成callback去回调parse方法 start_urls = [ "https://quotes.toscrape.com/page/1/", ] #parse 方法是每个爬虫的核心部分,用于处理响应并提取数据。它接收一个 response 对象,表示服务器返回的页面内容。 def parse(self, response): #提取页面中div 中class 为quote的数据 for quote in response.css("div.quote"): yield { "text": quote.css("span.text::text").get(), "author": quote.css("small.author::text").get(), "tags": quote.css("div.tags a.tag::text").getall(), } # 递归一直轮询爬取前五页(第五页就触发不了下面的条件了) next_page = response.css("li.next a::attr(href)").get() page=int(response.url.split("/")[-2]) print(f"当前页:{page}") if next_page is not None and page<5: next_page = response.urljoin(next_page) yield scrapy.Request(next_page, callback=self.parse)
注意:这里代码执行流程:
初始请求:爬虫从 start_urls 发起第一个请求,返回的响应(Response)会传递给 parse 方法。
新请求处理时:每个 scrapy.Request 生成的请求会携带 callback=self.parse_link 参数。
-
当 Scrapy 引擎处理这些新请求时,服务器返回的响应会直接传递给 callback 指定的方法,形成新的分支,而不会回到
parse方法(我这里是因为callback指定了parse ,所以还会回到parse )。
这里 scrapy.Request 传递的next_page 为绝对路径,因为 response.urljoin(next_page) 将相对路径转成了绝对路径,那么我们也可以不使用绝对路径,直接用 response.follow
from pathlib import Path import scrapy class DoubanSpider(scrapy.Spider): name = "quotes" #Spider 的标识,也就是爬虫名称,在项目内必须是唯一的,即不能为不同的 Spider 设置相同的名称 #简写start_requests,只需要指定url列表即可,scrapy.Request会自动生成callback去回调parse方法 start_urls = [ "https://quotes.toscrape.com", ] #parse 方法是每个爬虫的核心部分,用于处理响应并提取数据。它接收一个 response 对象,表示服务器返回的页面内容。 def parse(self, response): #提取页面中div 中class 为quote的数据 for quote in response.css("div.quote"): yield { "text": quote.css("span.text::text").get(), "author": quote.css("small.author::text").get(), "tags": quote.css("div.tags a.tag::text").getall(), } # 递归一直轮询爬取前五页(第五页就触发不了下面的条件了) next_page = response.css("li.next a::attr(href)").get() page=int(next_page.split("/")[-2]) print(f"当前页:{page}") if next_page is not None and page<5: yield response.follow(next_page, callback=self.parse) #使用相对路径跳转到下一页
也可以传递整个选择器
for href in response.css("ul.pager a::attr(href)"): yield response.follow(href, callback=self.parse)
针织可以传递多个选择器
yield from response.follow_all(css="ul.pager a", callback=self.parse)
演示抓取每页的作者信息
import scrapy class AuthorSpider(scrapy.Spider): name = "author" start_urls = ["https://quotes.toscrape.com/"] def parse(self, response): author_page_links = response.css(".author + a") yield from response.follow_all(author_page_links, self.parse_author) pagination_links = response.css("li.next a") yield from response.follow_all(pagination_links, self.parse) def parse_author(self, response): def extract_with_css(query): return response.css(query).get(default="").strip() yield { "name": extract_with_css("h3.author-title::text"), "birthdate": extract_with_css(".author-born-date::text"), "bio": extract_with_css(".author-description::text"), }
还可以运行的时候传递参数
scrapy crawl quotes -O quotes-humor.json -a tag=humor
from pathlib import Path import scrapy class DoubanSpider(scrapy.Spider): name = "quotes" #Spider 的标识,也就是爬虫名称,在项目内必须是唯一的,即不能为不同的 Spider 设置相同的名称 def start_requests(self): url = "https://quotes.toscrape.com/" tag = getattr(self, "tag", None) if tag is not None: url = url + "tag/" + tag yield scrapy.Request(url, self.parse) def parse(self, response): for quote in response.css("div.quote"): yield { "text": quote.css("span.text::text").get(), "author": quote.css("small.author::text").get(), } next_page = response.css("li.next a::attr(href)").get() if next_page is not None: yield response.follow(next_page, self.parse)
存储数据
运行scrapy crawl quotes 后可以在控制台打印出来,如果想存储在文件中在运行命令后面添加参数
scrapy crawl quotes -O quotes.json
这里 -O 为每次覆盖原文件 , -o 为每次在文件最后追加,只是json格式追加可能出现问题
日志配置
在settings.py 中进行配置
# 启用日志 LOG_ENABLED = True # 日志文件名 LOG_LEVEL = "ERROR" # 是否将标准输出(如 print)重定向到日志 LOG_STDOUT=False # 日志文件名 LOG_FILE = "fcbscrapy.log" # 日志文件编码 LOG_ENCODING = "utf-8" # 日志格式 LOG_FORMAT = "%(asctime)s [%(name)s] %(levelname)s: %(message)s" # 日志时间格式 LOG_DATEFORMAT = "%Y-%m-%d %H:%M:%S"
使用
from pathlib import Path import scrapy import logging class DoubanSpider(scrapy.Spider): name = "quotes" #Spider 的标识,也就是爬虫名称,在项目内必须是唯一的,即不能为不同的 Spider 设置相同的名称 start_urls = [ "https://quotes.toscrape.com/page/1/", ] #parse 方法是每个爬虫的核心部分,用于处理响应并提取数据。它接收一个 response 对象,表示服务器返回的页面内容。 def parse(self, response): logging.error(f"这是一条错误日志")
效果

管道
Scrapy 的 Item Pipeline(数据管道) 是处理爬虫抓取数据的关键组件,爬虫通过 yield item 将数据传递给 Pipeline后,Pipeline负责对爬虫提取的 Item 进行清洗、验证、存储等操作。通过 Pipeline,可以实现数据处理的模块化和流程化。
Item Pipeline 的核心作用
-
数据清洗
-
去除 HTML 标签、修正格式错误、过滤无效字段(如空值)。
-
-
数据验证
-
检查字段完整性(如必填字段是否存在)、数据类型合法性(如价格是否为数字)。
-
-
数据存储
-
将清洗后的数据持久化到数据库(MySQL、MongoDB)、文件(JSON、CSV)或消息队列。
-
-
去重处理
-
基于唯一标识(如商品 ID)过滤重复数据,避免重复入库。
-
-
第三方集成
-
将数据推送至分析平台(如 Elasticsearch)、云存储(如 AWS S3)或 API 接口。
-
Pipeline 的工作流程
-
Spider 生成 Item
爬虫通过yield item将数据传递给 Pipeline。 -
Pipeline 顺序处理
Item 依次经过所有启用的 Pipeline 组件,每个组件可修改、验证或丢弃 Item。 -
终止条件
若某个 Pipeline 抛出DropItem异常,后续 Pipeline 将不再处理该 Item。 -
最终持久化
最后一个 Pipeline 负责将数据存储到目标位置。
自定义 Pipleline 开发,每个 Pipeline 组件需实现以下方法:
1. 必要方法 process_item
class MyPipeline: def process_item(self, item, spider): # 核心处理逻辑 if not item.get("price"): raise DropItem("Missing price") # 丢弃无效 Item item["price"] = float(item["price"]) # 类型转换 return item # 传递给下一个 Pipeline
2. 可选生命周期方法 open_spider 和 close_spider
def open_spider(self, spider): # 爬虫启动时执行(如连接数据库) self.client = MongoClient() def close_spider(self, spider): # 爬虫关闭时执行(如关闭连接) self.client.close()
配置与启用Pipeline
在 settings.py 中定义 Pipeline 及其优先级(数值越小优先级越高):
ITEM_PIPELINES = { "myproject.pipelines.CleanPipeline": 300, # 先清洗 "myproject.pipelines.DuplicatesPipeline": 400, # 再去重 "myproject.pipelines.MongoDBPipeline": 500, # 最后存储 }
高级用法
1. 动态关闭 Pipeline
根据爬虫名称选择性启用:
class ConditionalPipeline: def process_item(self, item, spider): if spider.name == "special_spider": # 特殊处理逻辑 return item
2. 异步存储优化
使用 Twisted 异步框架提升数据库写入性能:
from twisted.internet import reactor def process_item(self, item, spider): reactor.callInThread(self._save_to_db, item) # 异步执行 return item
3. 错误重试机制
捕获存储异常并重试(如网络波动):
from scrapy.exceptions import NotConfigured def process_item(self, item, spider): try: self.client.insert(item) except ConnectionError: spider.crawler.engine.pause() # 暂停爬虫 time.sleep(60) spider.crawler.engine.unpause() return item # 重新处理
示例实战:
用一个管道将text 前面都加固定字符串“模拟清洗:”,再用另一个管道将text,author和tags 存储到mysql 数据库中,最后并记录日志
1. 在pipelines.py 中加入 两个管道 TextPrefixPipeline 以及 MySQLPipeline
from itemadapter import ItemAdapter import logging import mysql.connector import json class TextPrefixPipeline: """在text字段前添加固定前缀""" def process_item(self, item, spider): # 添加清洗前缀 if 'text' in item: item['text'] = f"模拟清洗:{item['text']}" spider.logger.info(f"已添加前缀的text: {item['text']}") # 记录日志 return item class MySQLPipeline: """将数据存储到MySQL数据库""" def __init__(self, mysql_config): self.mysql_config = mysql_config self.conn = None self.cursor = None # from_crawler 作用是从 Scrapy 的配置(settings.py)中读取 MySQL 相关参数,调用 MySQLPipeline 的构造函数 __init__,传入 mysql_config,构造 mysql_config 字典。 # @classmethod from_crawler 是 Scrapy 框架中用于初始化组件的特殊方法。 # cls:类本身(MySQLPipeline) # crawler:Scrapy 的 Crawler 对象,提供对配置(settings)的访问。 @classmethod def from_crawler(cls, crawler): # 从settings.py读取配置 return cls( mysql_config={ 'host': crawler.settings.get('MYSQL_HOST'), 'port': crawler.settings.get('MYSQL_PORT', 3306), 'user': crawler.settings.get('MYSQL_USER'), 'password': crawler.settings.get('MYSQL_PASSWORD'), 'database': crawler.settings.get('MYSQL_DB'), 'table': crawler.settings.get('MYSQL_TABLE') } ) def open_spider(self, spider): """连接数据库""" try: self.conn = mysql.connector.connect( host=self.mysql_config['host'], port=self.mysql_config['port'], user=self.mysql_config['user'], password=self.mysql_config['password'], database=self.mysql_config['database'] ) self.cursor = self.conn.cursor() # 创建表(如果不存在) #create_table_sql = #CREATE TABLE IF NOT EXISTS {self.mysql_config['table']} ( # id INT AUTO_INCREMENT PRIMARY KEY, # text TEXT NOT NULL, # author VARCHAR(255) NOT NULL, # tags JSON, # created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP #) # self.cursor.execute(create_table_sql) # self.conn.commit() spider.logger.info("成功连接MySQL数据库") except Exception as e: spider.logger.error(f"数据库连接失败: {str(e)}") raise def close_spider(self, spider): """关闭连接""" if self.conn: self.cursor.close() self.conn.close() spider.logger.info("数据库连接已关闭") def process_item(self, item, spider): """插入数据""" try: insert_sql = f""" INSERT INTO {self.mysql_config['table']} (text, author, tags) VALUES (%s, %s, %s) """ self.cursor.execute(insert_sql, ( item.get('text'), item.get('author'), json.dumps(item.get('tags', [])) # 将列表转为JSON字符串 )) self.conn.commit() spider.logger.info(f"成功插入数据: {item['author']}") except Exception as e: spider.logger.error(f"数据插入失败: {str(e)}") self.conn.rollback() return item
2. 在settings.py 中添加配置
# 启用管道 ITEM_PIPELINES = { #"fcbscrapy.pipelines.FcbscrapyPipeline": 300, 'fcbscrapy.pipelines.TextPrefixPipeline': 300, 'fcbscrapy.pipelines.MySQLPipeline': 400, } # MySQL配置 MYSQL_HOST = 'localhost' MYSQL_PORT = 3306 MYSQL_USER = 'root' MYSQL_PASSWORD = 'hua3182486' MYSQL_DB = 'hello' MYSQL_TABLE = 'quotes'
3. 爬虫类(就是之前演示的,没有什么更改,因为只需要添加管道就行了,业务代码不会更改)
from pathlib import Path import scrapy class DoubanSpider(scrapy.Spider): name = "quotes" #Spider 的标识,也就是爬虫名称,在项目内必须是唯一的,即不能为不同的 Spider 设置相同的名称 #简写start_requests,只需要指定url列表即可,scrapy.Request会自动生成callback去回调parse方法 start_urls = [ "https://quotes.toscrape.com", ] #parse 方法是每个爬虫的核心部分,用于处理响应并提取数据。它接收一个 response 对象,表示服务器返回的页面内容。 def parse(self, response): #提取页面中div 中class 为quote的数据 for quote in response.css("div.quote"): yield { "text": quote.css("span.text::text").get(), "author": quote.css("small.author::text").get(), "tags": quote.css("div.tags a.tag::text").getall(), } # 递归一直轮询爬取前五页(第五页就触发不了下面的条件了) next_page = response.css("li.next a::attr(href)").get() page=int(next_page.split("/")[-2]) print(f"当前页:{page}") if next_page is not None and page<5: # 添加页面跟踪日志 self.logger.info(f"正在跟踪下一页:{next_page}") yield response.follow(next_page, callback=self.parse)
4. 运行
文件存储(媒体管道)
Scrapy 的 媒体管道(Media Pipeline) 是专门用于处理非结构化媒体文件(如图片、视频、文档等)的核心组件。它支持高效下载、存储和处理媒体资源,并可与爬虫逻辑无缝集成。
媒体管道的作用
-
自动化下载:根据爬虫提取的媒体 URL,自动下载文件。
-
存储管理:支持本地文件系统、云存储(如 S3、GCS)等多种存储方式。
-
资源处理:对文件进行去重、格式转换、生成缩略图等操作。
-
性能优化:异步并发下载,提升爬取效率。
内置媒体管道类型
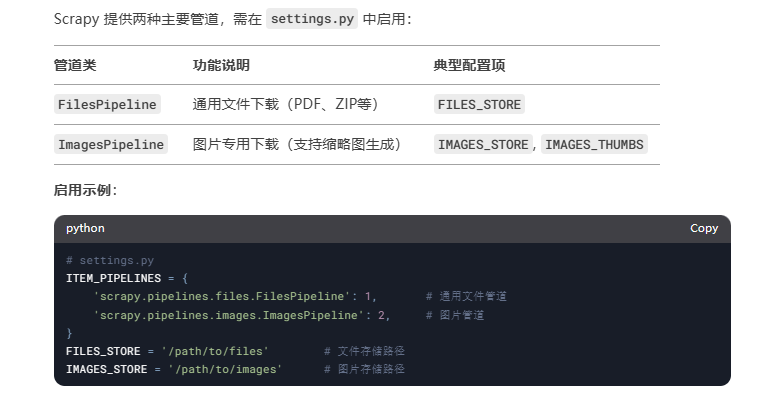
示例
1. 在items.py (类似实体类)里面定义基础结构
import scrapy # 定义爬取的数据结构 class MyItem(scrapy.Item): # 基础字段 title = scrapy.Field() price = scrapy.Field() # 文件下载 file_urls = scrapy.Field() #存储待下载文件的URL列表(必须是列表,即使只有一个URL) files = scrapy.Field() #存储下载完成后的文件信息(如路径、校验码等,由管道自动填充) # 图片下载 image_urls = scrapy.Field() #存储待下载图片的URL列表(必须是列表) images = scrapy.Field() #存储下载完成后的图片信息(如路径、尺寸等,由管道自动填充)
2. 添加爬虫类
import scrapy from fcbscrapy.items import MyItem class BookSpider(scrapy.Spider): name = "book" # custom_settings = { # 'DOWNLOAD_MAXSIZE': 1073741824, # 允许大文件 # 'DEFAULT_REQUEST_HEADERS': { # 'User-Agent': 'Mozilla/5.0', # 'Accept': '*/*', # } # } start_urls = ["https://www.baidu.com/"] def parse(self, response): item = MyItem() # 提取图片(示例链接) #item['image_urls'] = response.css('.image_container img::attr(src)').getall() item['image_urls'] = ["https://xxx.oss-cn-shanghai.aliyuncs.com/2025/4/10/959dc2b7b140457aa9275c0eab4f0b6a.jpg"] # 提取文件(示例链接) item['file_urls'] = [ "https://xxx.oss-cn-shanghai.aliyuncs.com/2025/4/10/%E8%B5%84%E4%BA%A7%E8%B4%9F%E5%80%BA%E8%A1%A8.docx", ] # 提取其他数据 item['title'] = response.css('h3 a::attr(title)').getall() item['price'] = response.css('.price_color::text').getall() yield item
3. 在settings.py里面配置管道启用
# 启用文件和图片管道 ITEM_PIPELINES = { 'scrapy.pipelines.files.FilesPipeline': 1, # 先执行(优先级高) 'scrapy.pipelines.images.ImagesPipeline': 2, # 后执行(优先级低) } # 存储路径配置 FILES_STORE = 'path/files' # 文件存储路径 IMAGES_STORE= 'path/images' # 图片存储路径 # 图片缩略图配置 IMAGES_THUMBS = { 'small': (50, 50), 'big': (270, 270), } # 其他设置... #ROBOTSTXT_OBEY = False 是 Scrapy 的一个爬虫行为控制设置,用于决定是否遵守目标网站的 robots.txt(它是网站根目录下的一个文本文件(如 https://example.com/robots.txt),用于声明哪些页面允许或禁止爬虫抓取。) 协议。 # 如果设置为 True,Scrapy 将遵守 robots.txt 协议,如果设置为 False,Scrapy 则不遵守 robots.txt 协议,强制爬取所有页面(除非网站有其他反爬措施)。 ROBOTSTXT_OBEY = False DOWNLOAD_MAXSIZE = 1073741824 # 1GB(单位:字节) DOWNLOAD_WARNSIZE = 536870912 # 512MB
运行上面代码,只要通过 yield item 传递给 管道就会自动存储

反爬虫设置
很多网站如果使用Scrapy 进行爬取容易触发反爬虫机制,所以这里可以进行一些设置
在爬虫程序设置请求头和用户代理以及cookie信息等等,模拟浏览器访问
def start_requests(self): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'Referer': 'https://movie.douban.com/', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', 'Cookie':'bid=cgUYoAsAgIQ; douban-fav-remind=1; ll="108169"; _vwo_uuid_v2=D555C86708806F0DC65862A6075300BCE|7e5ca7598a68b1b58dcbd92054ef536d; ap_v=0,6.0; __utmc=30149280; dbcl2="249857509:y33ZfjjNIg4"; ck=Umka; __utma=30149280.321278076.1718680473.1744874095.1744875966.5; __utmb=30149280.0.10.1744875966; __utmz=30149280.1744875966.5.3.utmcsr=open.weixin.qq.com|utmccn=(referral)|utmcmd=referral|utmcct=/; push_noty_num=0; push_doumail_num=0; __gads=ID=7b04a8f537a1e1c5:T=1744180813:RT=1744875971:S=ALNI_Mbz-OX9NZ2uiD5hyRuiVV2Lc7XVIQ; __gpi=UID=0000109642667e01:T=1744180813:RT=1744875971:S=ALNI_MYXz5HxGcEqCbzNlC1Q5sjTUhVkLQ; __eoi=ID=a4d3bcbcdd1ddc0a:T=1744180813:RT=1744875971:S=AA-Afja_N2rAJcLp1DIKzoWOZZe6; FCNEC=%5B%5B%22AKsRol-aR9MdhP7QPrQ89UB7k0U1F21YAtKGQ0epVYlWZXPi4uS62yKOTvULvORyEsxeA6_DovZkF5ogvkUOl4yAI2dFCfmWmDjrticY11BRZSPt3M8xirXDEKCbHFfha4ngnRGVl31INNeg2391nPQP5Y0z_flFrw%3D%3D%22%5D%5D; frodotk_db="7d772a4624e0f7d578657ed26ea2e77f"; _ga=GA1.1.102562741.1744876304; _sharedID=17cb078b-ce41-49f2-9926-d45d93ac52d2; _sharedID_cst=2SzgLJUseQ%3D%3D; _ga_P83QWMDYS1=GS1.1.1744876303.1.0.1744876417.0.0.0' } for url in self.start_urls: yield scrapy.Request(url, headers=headers, callback=self.parse)
在settings.py 中设置
# 设置 User-Agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36' # 不遵守 robots.txt 规则 ROBOTSTXT_OBEY = False # 设置下载延迟,避免过快请求 DOWNLOAD_DELAY = 2 RANDOMIZE_DOWNLOAD_DELAY = True # 随机化间隔时间 # 启用自动限速扩展 AUTOTHROTTLE_ENABLED = True AUTOTHROTTLE_START_DELAY = 2 AUTOTHROTTLE_MAX_DELAY = 5
如果还需要加IP代理可以使用IP代理,这样可以动态获取IP进行访问
在middlewares.py 中添加IP代理地址
class ProxyMiddleware: def __init__(self): self.proxies = [ 'http://47.96.252.192:80', # 可以加多个免费或付费代理 ] def process_request(self, request, spider): proxy = random.choice(self.proxies) print(f"当前使用代理: {proxy}") request.meta['proxy'] = proxy
在 setting.py 中 启用管道
#设置代理管道 DOWNLOADER_MIDDLEWARES = { "fcbscrapy.middlewares.ProxyMiddleware": 350, }
打包爬虫类部署到docker
前面测试了这么多,现在部署到docker 上面,来个测试的book 爬虫部署出来
1. 先检查项目是否存在requirements.txt ,就相当于c# 的工程文件,有项目依赖包和对应的版本,没有就创建一个
pip freeze > requirements.txt
2. 创建Dockerfile
# 使用 Alpine 轻量镜像 FROM python:3.11-slim # 设置工作目录 WORKDIR /app # 拷贝代码 COPY . /app # 安装依赖,使用国内镜像 RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --prefer-binary --no-cache-dir -r requirements.txt # 设置默认运行命令(也可以通过 docker run 时指定) CMD ["scrapy", "crawl", "book"]
3. 将整个文件项目文件都拷贝到服务器上面,构建镜像
docker build -t fcbscrapy .
4. 运行容器
这里在运行容器后面可以跟 scrapy crawl book 命令,就可以在运行容器的时候直接启动爬虫(注意:爬虫运行完后会自动停止容器)
docker run -it --name mycrawler fcbscrapy scrapy crawl book
也可以运行容器后,在容器里面执行爬虫
docker run -it --name mycrawler fcbscrapy bash #运行并进入容器 # 在容器中执行爬虫 scrapy crawl book 或者 scrapy crawl book -s LOG_LEVEL=DEBUG # 设置容器日志等级,可以打印出调试信息
如果想设置定时爬取,那么就可以写个脚本文件放在代码中,运行容器后会一直循环请求爬虫
1. 创建轮询的脚本loop.sh
#!/bin/bash # 无限循环,每隔3秒执行一次 Scrapy 爬虫 while true do echo ">>> Running spider..." scrapy crawl book # 执行 Scrapy 爬虫 echo ">>> Sleeping for 3 seconds..." sleep 3 # 等待3秒 done
2. 修改dockerfile 文件
# 使用 Alpine 轻量镜像 FROM python:3.11-slim # 设置工作目录 WORKDIR /app # 复制本地的 scrapy 项目文件到容器内 COPY . /app # 安装所需的依赖 RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --prefer-binary --no-cache-dir -r requirements.txt # 复制 loop.sh 脚本到容器中 COPY loop.sh /app/loop.sh # 给 loop.sh 脚本增加可执行权限 RUN chmod +x /app/loop.sh # 设置容器启动时执行 loop.sh 脚本 CMD ["bash", "loop.sh"]
3. 将整个文件项目文件都拷贝到服务器上面
构建镜像之前,可能由于 loop.sh 内容如果是windows 编辑的,放在linux 上面就可能出现格式问题,需要拷贝上去进行转换
sed -i 's/\r$//' loop.sh
转换后构建镜像
docker build -t fcbscrapy .
4. 运行容器
docker run -it --name mycrawler fcbscrapy
这样就可以3秒钟执行一次了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号