【Agent】MemOS 源码笔记---(1)--基本概念
【Agent】MemOS 源码笔记---(1)--基本概念
0x00 概要
随着大型语言模型(LLMs)的不断演进,其所承担的任务日益复杂,包括多轮对话、规划、决策制定以及个性化代理等。然而,主流 LLM 架构往往在记忆结构化、管理和集成方面存在不足,导致知识更新成本高、行为状态不可持续以及难以积累用户偏好。因此,在此背景下,如何高效管理和利用记忆,成为实现长期智能与适应性能力的关键因素。
MemOS(Memory Operating System)的核心思想是把“记忆”从辅助功能提升为系统级资源:统一格式、统一生命周期、统一调度。它像操作系统管理磁盘一样管理记忆——自动存取、版本控制、冷热分层、并发安全,让大模型应用无需重复编写记忆逻辑,就能持续积累知识、按需调用上下文、并在多轮对话中保持连贯。
MemOS 的内容非常丰富,是个宝库,但是因为内容太多,所以只能找自己最好奇的地方去阅读。而且,因为本系列是使用MemOS的某个版本进行学习,而MemOS 本身在飞速发展,因此本系列的内容可能与最新进展有出入。
本文是基于MemOS的文档内容进行梳理和重整,把散落在多个文档中的内容,按照自己的理解聚合到一个文档中。希望借助本文,读者可以了解到MemOS的意义、设计思路和基本概念。
注:MemOS文档非常出色,本系列会大量直接引用其文档。
0x01 背景
1.1 为什么需要MemOS
大模型原生的记忆存在局限:
-
上下文有限:一次对话的Token窗口再大,也无法承载长期知识。
-
遗忘严重:用户上周说过的偏好,下次对话就消失了。
-
难以管理:随着交互增多,记忆混乱,开发者需要额外逻辑处理。
MemOS的价值在于,它抽象出记忆层,让你只关注业务逻辑:
-
不再手写繁琐的“长文本拼接”或“额外数据库调用”。
-
记忆可以像模块一样复用、扩展,甚至在不同Agent、不同系统之间共享。
-
通过主动调度和多层管理,记忆调用更快、更准,显著降低幻觉。
简单来说:MemOS让AI不再是一次性的对话机器,而是能持续成长的伙伴。
下图右侧是传统记忆系统,左侧是MemOS。
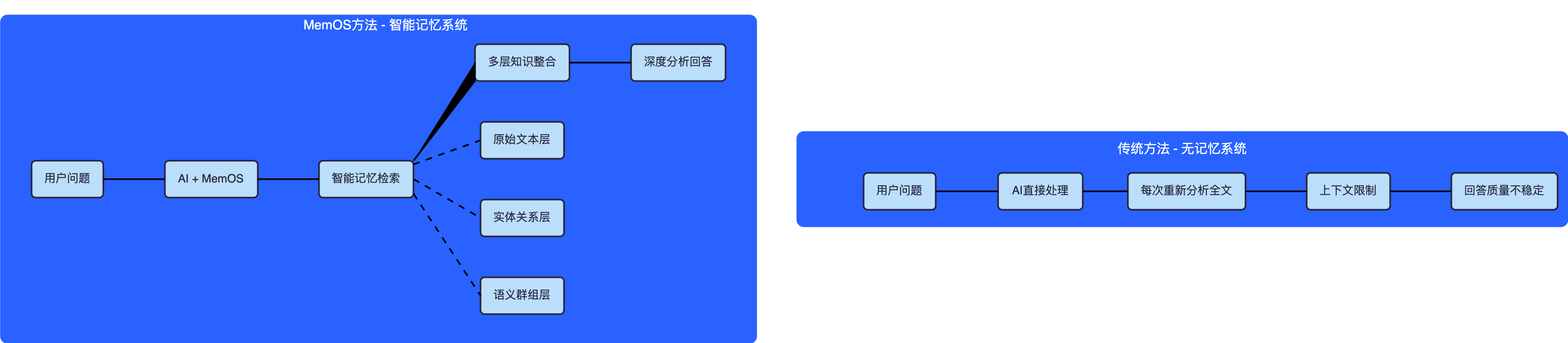
1.2 MemOS 相关信息
论文名称: MemOS: A Memory OS for AI System*
第一作者: MemTensor (Shanghai) Technology Co., Ltd.
论文链接: https://arxiv.org/pdf/2507.03724
GitHub:
1.3 MemOS能做些什么
-
个性化对话:记住用户的姓名、习惯、兴趣、指令偏好,下次自动补充。
-
团队知识库:把碎片对话转化为结构化知识,供多个 Agent 协作使用。
-
任务连续性:跨会话、跨应用保持记忆,让 AI 从容处理长流程任务。
-
多层记忆调度:针对不同需求调用最合适的记忆,提升性能与准确率。
-
开放扩展:支持单独作为 API 使用,也能接入现有的框架(官方使用指导即将上线,着急的老师们也可以先自己动手哦~)
0x02 原理
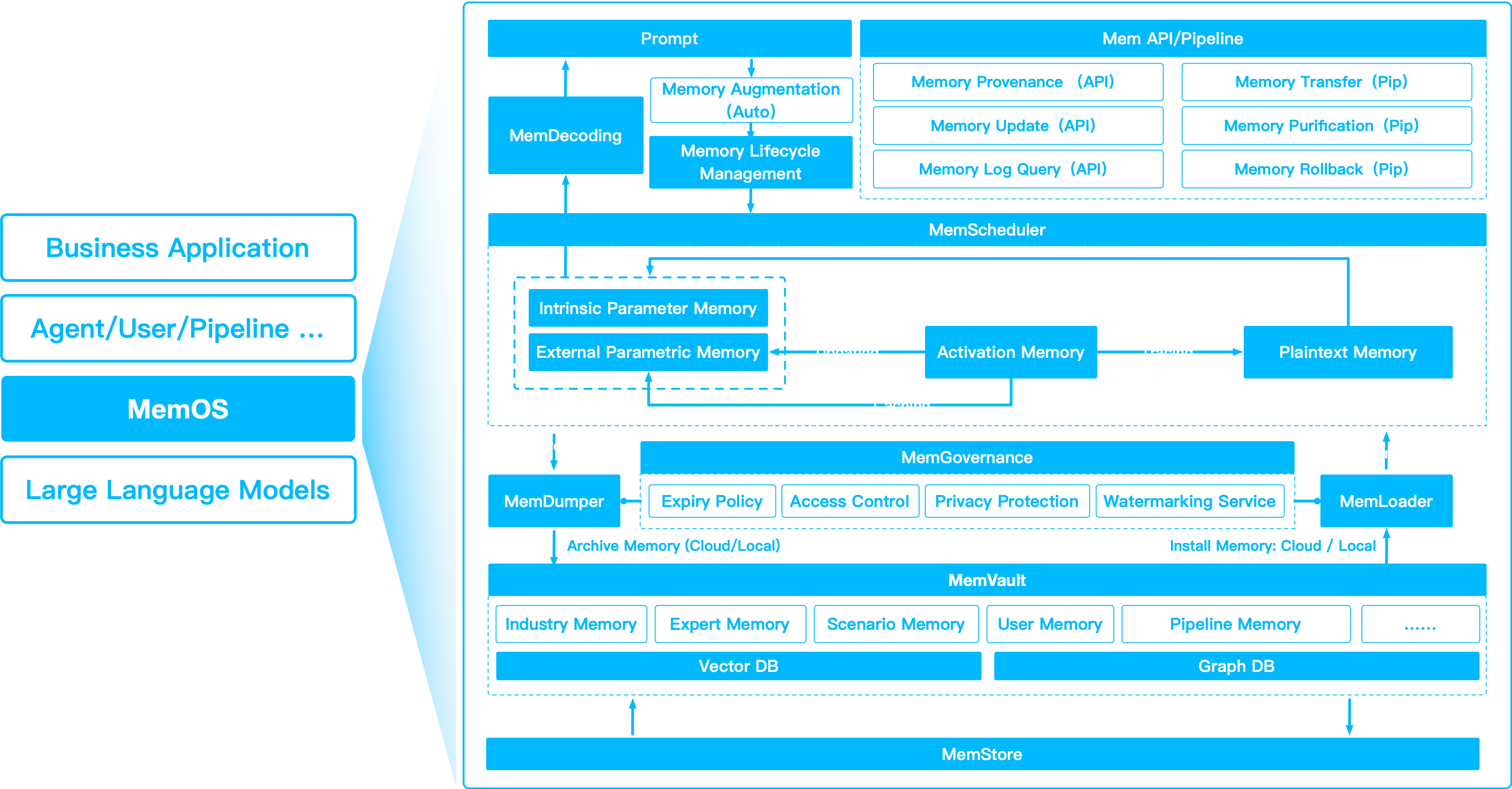
参数化记忆将完成 MemOS 关于统一Memory³架构的设想:
- 参数化记忆: 嵌入知识
- 激活记忆: 短暂的运行状态
- 明文记忆: 结构化的、可追溯的外部记忆
将这三者结合在一起,可以实现适应性强、可进化和可解释的智能系统。
下图就是MemOS的系统架构。
2.1 记忆类型
MemOS 把记忆分为以下三种。
- 结构化记忆(明文记忆):尝试基于图的分层知识 TreeTextMemory,是结构化、层次化和知识图谱。图与向量后端会连接 Neo4j 或 Qdrant 实现生产级向量/图搜索。
- 激活记忆:使用 KVCacheMemory (最近或稳定的上下文)加速多轮对话,高效的运行时状态缓存。
- 参数化记忆:用适配器/LoRA 实现动态技能注入。
2.1.1 GeneralTextMemory
title: "GeneralTextMemory: 通用文本的记忆"。
desc: "GeneralTextMemory 是MemOS中一个灵活的、基于向量的明文记忆模块,用于存储、搜索和管理非结构化知识。它适用于会话代理、个人助理和任何需要语义记忆检索的系统。"
记忆结构
每条记忆都存储为一个 TextualMemoryItem:
memory:主要文本内容(例如,“用户喜欢番茄。”)metadata:额外信息,使记忆可搜索且易于管理——类型、时间、来源、置信度、实体、标签、可见性和更新时间。
这些字段使每条记忆都能被查询、筛选和方便治理。
| 字段 | 类型 | 描述 |
|---|---|---|
id |
str |
UUID (如果省略则自动生成) |
memory |
str |
记忆内容主体 (必填) |
metadata |
TextualMemoryMetadata |
元数据(用于搜索/过滤) |
元数据域 (TextualMemoryMetadata)
| 字段 | 类型 | 描述 |
|---|---|---|
type |
"procedure", "fact", "event", "opinion" |
记忆类型,比如它是事实、事件还是观点 |
memory_time |
str (YYYY-MM-DD),比如"2025-07-02" |
记忆所指的日期/时间 |
source |
"conversation", "retrieved", "web", "file" |
记忆源 |
confidence |
float (0-100) |
确定性/可信度评分(0–100) |
entities |
list[str],比如["tomatoes"] |
主要实体/概念 |
tags |
list[str],比如["food", "preferences"] |
主题标签,即分组用的额外标签 |
visibility |
"private", "public", "session" |
访问范围,即谁可以访问 |
updated_at |
str,比如"2025-07-02T00:00:00Z" |
最近更新时间戳 (ISO 8601) |
所有的值都经过验证,无效的值将引发错误。
2.1.2 TreeTextMemory
TreeTextMemory 支持以结构化方式组织、关联并检索记忆,同时保留丰富的上下文信息与良好的可解释性。即,TreeTextMemory是分层结构的、基于图的、树形明文记忆。当前使用Neo4j作为后端,未来计划支持更多图数据库。
记忆结构
每个节点在TreeTextMemory 是一个 TextualMemoryItem:
id: 唯一记忆ID(如果省略则自动生成)memory: 主要文本metadata: 包括层次结构信息、嵌入、标签、实体、源和状态
元数据字段 (TreeNodeTextualMemoryMetadata)
| 字段 | 类型 | 描述 |
|---|---|---|
memory_type |
"WorkingMemory", "LongTermMemory", "UserMemory" |
生命周期分类 |
status |
"activated", "archived", "deleted" |
节点状态 |
visibility |
"private", "public", "session" |
访问范围 |
sources |
list[str] |
来源列表 (例如: 文件, URLs) |
source |
"conversation", "retrieved", "web", "file" |
原始来源类型 |
confidence |
float (0-100) |
确定性得分 |
entities |
list[str] |
提及的实体或概念 |
tags |
list[str] |
主题标签 |
embedding |
list[float] |
基于向量嵌入的相似性搜索 |
created_at |
str |
创建时间戳(ISO 8601) |
updated_at |
str |
最近更新时间戳(ISO 8601) |
usage |
list[str] |
使用历史 |
background |
str |
附加上下文 |
最佳实践:使用有意义的标签和背景——它们有助于组织你的图进行多跳推理。
特色
TreeTextMemory的特点为:
- 结构层次: 像思维导图一样组织记忆——节点可以有父母、孩子和交叉链接。
- 图风格的链接: 超越纯粹的层次结构-建立多跳推理链。
- 语义搜索+图扩展: 结合向量和图形的优点。
- 可解释性: 追踪记忆是如何连接、合并或随时间演变的.
2.1.3 KVCacheMemory(激活记忆)
KVCacheMemory 是MemOS中用于存储和管理KV cache的专用记忆模块,主要用于加速大语言模型(LLMs)推理并支持有效的上下文复用。它作为激活记忆有助于对于会话式和生成式人工智能系统。
在MemOS中,KV Cache最适合存储语义稳定且经常复用的背景信息,例如:
- 常见问题(FAQs)或特定领域知识
- 先前的对话历史
这些稳定的明文记忆项由MemScheduler模块自动识别和管理。一旦被选中,它们就会被提前转换成KV格式的表示(KVCacheItem)。这个预计算步骤以可复用的格式存储记忆的激活状态(键值对张量),允许它们在推理期间注入到模型的注意力缓存中
一旦进行转换,这些KV记忆就可以跨查询复用,而不需要对原始内容重新编码。这减少了处理和存储大量文本的计算开销,使其成为需要快速响应时间和高吞吐量的应用程序的理想选择。
记忆结构
通过KVCacheMemory实现基于KV的记忆复用,在保持相同输出的同时,大大减少了模型大小和查询类型之间的延迟。通过将可复用记忆从明文提示转移到预先计算的KV Cache,MemOS消除了冗余的上下文编码,并实现了更快的响应时间,特别是在实时的、记忆增强的LLM应用程序中。
每个缓存被存储为一个KVCacheItem:
| 字段 | 类型 | 描述 |
|---|---|---|
kv_cache_id |
str |
缓存中的唯一ID(UUID) |
kv_cache |
DynamicCache |
实际的KV Cache(transformers) |
metadata |
dict |
元数据 (源, 抽取时间等.) |
API总结 (KVCacheMemory)
初始化
KVCacheMemory(config: KVCacheMemoryConfig)
核心方法如下:
| 方法 | 描述 |
|---|---|
extract(text) |
使用LLM从输入文本中提取KV Cache |
add(memories) |
添加一个或多个KVCacheItem到记忆中 |
get(memory_id) |
根据ID获取单个缓存 |
get_by_ids(ids) |
根据IDs获取多个缓存 |
get_all() |
返回所有存储的缓存 |
get_cache(cache_ids) |
从多个IDs合并并返回组合缓存 |
delete(ids) |
通过IDs删除缓存 |
delete_all() |
删除所有缓存 |
dump(dir) |
将所有缓存序列化到目录中的pickle文件 |
load(dir) |
从目录中的pickle文件加载缓存 |
from_textual_memory(mem) |
将TextualMemoryItem 转换为 KVCacheItem |
当调用dump(dir), 系统写到:
<dir>/<config.memory_filename>
该文件包含所有KV Cache的pickle字典,可以使用load(dir)重新加载。
特色
将MemScheduler与KV Cache记忆集成可以实现显著的性能优化,特别是在LLM推理的预填充阶段。
当无KV Cache记忆时
- 每个新查询都被添加到完整的提示模板中,包括背景知识。
- 模型必须在整个序列上重新计算token嵌入和注意力——即使是未更改的记忆。
当有KV Cache记忆时
- 背景知识以键值对张量的形式缓存一次。
- 对于每个查询,只对新用户输入(查询token)进行编码。
- 之前缓存的KV被直接注入到注意力机制中。
KV Cache这种分离减少了预填充阶段的冗余计算,从而导致:
- 跳过背景知识的重复编码
- 更快的查询token和缓存记忆之间的注意力计算
- 降低首次token时间(Time To First Token, TTFT) 生成过程中的延迟
这种优化在以下方面特别有价值:
- 多回合聊天机器人交互
- 检索增强生成或上下文增强生成(RAG, CAG)
- 在固定文档或FAQ风格记忆上操作的助理
2.1.4 参数记忆
参数化记忆(Parametric Memory) 是MemOS内部的核心长期的知识和能力储存。与明文记忆或激活记忆不同,参数记忆,对语言结构、世界知识和一般推理能力的深度表示进行编码,直接嵌入在模型的权重中。
在MemOS架构中,参数记忆不仅仅指静态预训练权重。它还包括模块化权重组件,如LoRA适配器和插件专家模块。这些允许您逐步扩展或专业化您的LLM的能力,而无需重新训练整个模型。
例如,您可以将结构化或稳定的知识提取为参数形式,将其保存为能力块,并在推理过程中动态加载或卸载它。这使得为法律推理、财务分析或特定领域的摘要等任务创建“专家子模型”变得容易——所有这些都由MemOS管理。
设计目标
- 可控制性 — 按需生成、加载、交换或组合参数模块on demand.
- 可塑性 — 与明文和激活记忆一起演化;支持知识的提纯与回滚
- 可追溯性 (开发中) — 参数块的版本控制和管理
当前状态
参数化记忆(Parametric Memory) 目前仍处于设计和原型阶段。用于生成、压缩以及热插拔参数模块的 API 将在未来版本中发布,旨在支持多任务、多角色和多代理架构。
2.1.5 混合模式
何时使用:
- 你希望同时拥有长期可解释记忆与短期快速上下文。
- 理想场景:用于具备计划能力、能记住事实并保持上下文的复杂智能体。
- 展示多记忆调度能力。
工作原理:
- TreeTextMemory 将你的长时记忆存储在图数据库(Neo4j)中。
- KVCacheMemory 将最近或稳定的上下文作为激活缓存保存。
- 二者在一个 MemCube 中协同工作,由你的
MOSPipeline 统一管理。
0x03 MemCube
MemCube是 MemOS 中的核心组织单元,专为封装和管理用户或代理的所有类型记忆而设计。它为加载、保存和操作多个记忆模块提供统一接口,使构建、共享和部署记忆增强应用程序变得容易。
MemCube 是一个容器,捆绑了三种主要类型的记忆:
- 明文记忆 (例如,
GeneralTextMemory、TreeTextMemory): 用于存储和检索非结构化或结构化文本知识。 - 激活记忆 (例如,
KVCacheMemory): 用于存储键值缓存以加速 LLM 推理和上下文重用。 - 参数化记忆 (例如,
LoRAMemory): 用于存储模型适应参数(如 LoRA 权重)。
每种记忆类型都是独立可配置的,可以根据需要进行交换或扩展。
3.1 结构
MemCube 由配置定义(参见 GeneralMemCubeConfig),该配置为每种记忆类型指定后端和配置。典型结构是:
MemCube
├── text_mem: TextualMemory
├── act_mem: ActivationMemory
└── para_mem: ParametricMemory
所有记忆模块都可通过 MemCube 接口访问:
mem_cube.text_memmem_cube.act_memmem_cube.para_mem
基类代码如下:
class BaseMemCube(ABC):
"""Base class for all MemCube implementations."""
@abstractmethod
def __init__(self, config: BaseMemCubeConfig):
"""Initialize the MemCube with the given configuration."""
self.text_mem: BaseTextMemory
self.act_mem: BaseActMemory
self.para_mem: BaseParaMemory
@abstractmethod
def load(self, dir: str) -> None:
"""Load memories from a directory."""
@abstractmethod
def dump(self, dir: str) -> None:
"""Dump memories to a directory."""
3.2 初始化
from memos.mem_cube.general import GeneralMemCube
mem_cube = GeneralMemCube(config)
3.3 核心方法
MemCube 的核心方法如下:
| 方法 | 描述 |
|---|---|
load(dir) |
从目录加载所有记忆 |
dump(dir) |
将所有记忆保存到目录 |
text_mem |
访问明文记忆模块 |
act_mem |
访问激活记忆模块 |
para_mem |
访问参数化记忆模块 |
init_from_dir(dir) |
从目录加载 MemCube |
init_from_remote_repo(repo, base_url) |
从远程仓库加载 |
3.4 GeneralMemCube
GeneralMemCube(通用记忆立方体)是一个记忆管理容器,核心职责是统一管理三种类型的 AI 记忆(文本记忆、激活记忆、参数化记忆),提供 “加载 - 存储 - 实例化” 的全流程能力,适配本地和远程两种数据来源场景。
3.4.1 核心特色
- 多类型记忆统一管理:
- 整合文本记忆(text_mem)、激活记忆(act_mem)、参数化记忆(para_mem)三类记忆,通过统一接口(load/dump)实现批量加载 / 存储,避免分散管理的繁琐。
- 支持按需加载 / 存储:可指定具体记忆类型,无需操作全部记忆,提升效率。
- 灵活的实例化方式:
- 本地初始化:从本地目录加载配置和记忆数据(
init_from_dir),适配离线使用场景。 - 远程初始化:从远程仓库(默认 Hugging Face)下载数据并初始化(
init_from_remote_repo),支持共享和复用公开记忆资源。
- 本地初始化:从本地目录加载配置和记忆数据(
- 配置安全与兼容性:
- 配置校验:加载时校验配置文件的 schema 一致性,避免因配置格式不匹配导致的运行错误。
- 配置合并:支持将默认配置与用户配置合并,兼顾通用设置与个性化需求,提升配置灵活性。
- 类型安全与容错:
- 记忆实例类型校验:通过 setter 方法强制校验记忆实例类型,确保仅支持对应基类的子类实例,避免类型错误。
- 未初始化提示:访问未初始化的记忆时输出警告日志,而非直接抛出异常,提升系统容错性。
- 数据安全保护:
- 存储时校验目标目录是否为空,避免覆盖已有数据,防止误操作导致的数据丢失。
- 存储时自动同步配置文件,确保记忆数据与配置一一对应,便于后续加载和迁移。
3.4.2 流程图
初始化

加载流程

存储流程

3.4.3 代码
GeneralMemCube 的代码如下
class GeneralMemCube(BaseMemCube):
"""记忆立方体(MemCube)是一个用于加载和存储三种类型记忆的容器。
支持的记忆类型:文本记忆(text_mem)、激活记忆(act_mem)、参数化记忆(para_mem)
"""
def __init__(self, config: GeneralMemCubeConfig):
"""使用配置初始化记忆立方体。
参数:
config: 通用记忆立方体配置实例(GeneralMemCubeConfig),包含三种记忆的后端配置等信息
"""
self.config = config # 保存配置实例
time_start = time.time() # 记录文本记忆初始化开始时间
# 初始化文本记忆:若配置中后端不是"未初始化"状态,则通过工厂类创建实例
self._text_mem: BaseTextMemory | None = (
MemoryFactory.from_config(config.text_mem)
if config.text_mem.backend != "uninitialized"
else None
)
# 初始化激活记忆:逻辑同文本记忆
self._act_mem: BaseActMemory | None = (
MemoryFactory.from_config(config.act_mem)
if config.act_mem.backend != "uninitialized"
else None
)
# 初始化参数化记忆:逻辑同文本记忆
self._para_mem: BaseParaMemory | None = (
MemoryFactory.from_config(config.para_mem)
if config.para_mem.backend != "uninitialized"
else None
)
def load(
self, dir: str, memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None
) -> None:
"""从指定目录加载记忆数据。
参数:
dir: 存储记忆文件的目录路径
memory_types: 要加载的记忆类型列表(可选)。若为None,加载所有可用的记忆类型。
可选值:["text_mem", "act_mem", "para_mem"]
"""
# 读取目录中的配置文件schema,用于校验配置一致性
loaded_schema = get_json_file_model_schema(os.path.join(dir, self.config.config_filename))
# 校验加载的配置schema是否与当前实例的配置schema一致,不一致则抛出配置错误
if loaded_schema != self.config.model_schema:
raise ConfigurationError(
f"Configuration schema mismatch. Expected {self.config.model_schema}, "
f"but found {loaded_schema}."
)
# 若未指定记忆类型,默认加载所有三种类型
if memory_types is None:
memory_types = ["text_mem", "act_mem", "para_mem"]
# 加载指定类型的记忆(仅加载已初始化的记忆实例)
if "text_mem" in memory_types and self.text_mem:
self.text_mem.load(dir) # 调用文本记忆的load方法加载数据
if "act_mem" in memory_types and self.act_mem:
self.act_mem.load(dir) # 调用激活记忆的load方法加载数据
if "para_mem" in memory_types and self.para_mem:
self.para_mem.load(dir) # 调用参数化记忆的load方法加载数据
def dump(
self, dir: str, memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None
) -> None:
"""将记忆数据存储到指定目录。
参数:
dir: 保存记忆文件的目标目录路径
memory_types: 要存储的记忆类型列表(可选)。若为None,存储所有可用的记忆类型。
可选值:["text_mem", "act_mem", "para_mem"]
"""
# 校验目标目录是否存在且非空,非空目录则抛出异常(避免覆盖已有数据)
if os.path.exists(dir) and os.listdir(dir):
raise MemCubeError(
f"Directory {dir} is not empty. Please provide an empty directory for dumping."
)
# 始终先存储配置文件(确保配置与记忆数据同步)
self.config.to_json_file(os.path.join(dir, self.config.config_filename))
# 若未指定记忆类型,默认存储所有三种类型
if memory_types is None:
memory_types = ["text_mem", "act_mem", "para_mem"]
# 存储指定类型的记忆(仅存储已初始化的记忆实例)
if "text_mem" in memory_types and self.text_mem:
self.text_mem.dump(dir) # 调用文本记忆的dump方法存储数据
if "act_mem" in memory_types and self.act_mem:
self.act_mem.dump(dir) # 调用激活记忆的dump方法存储数据
if "para_mem" in memory_types and self.para_mem:
self.para_mem.dump(dir) # 调用参数化记忆的dump方法存储数据
@staticmethod
def init_from_dir(
dir: str,
memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None,
default_config: GeneralMemCubeConfig | None = None,
) -> "GeneralMemCube":
"""从本地目录创建并初始化记忆立方体实例。
参数:
dir: 存储记忆文件和配置文件的本地目录路径
memory_types: 要加载的记忆类型列表(可选)。若为None,加载所有可用类型。
default_config: 用于合并的默认配置(可选)。若提供,会合并通用设置,
同时保留用户特定的关键配置字段。
返回:
GeneralMemCube: 已加载指定目录记忆数据的记忆立方体实例
"""
# 构建配置文件路径(默认配置文件名为config.json)
config_path = os.path.join(dir, "config.json")
# 从JSON文件加载配置实例
config = GeneralMemCubeConfig.from_json_file(config_path)
# 若提供了默认配置,将其与加载的配置合并
if default_config is not None:
config = merge_config_with_default(config, default_config)
# 创建记忆立方体实例并加载指定目录的记忆数据
mem_cube = GeneralMemCube(config)
mem_cube.load(dir, memory_types)
return mem_cube
@staticmethod
def init_from_remote_repo(
cube_id: str,
base_url: str = "https://huggingface.co/datasets",
memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None,
default_config: GeneralMemCubeConfig | None = None,
) -> "GeneralMemCube":
"""从远程仓库创建并初始化记忆立方体实例。
参数:
cube_id: 远程仓库名称(即记忆立方体ID)
base_url: 远程仓库的基础URL(默认是Hugging Face数据集仓库)
memory_types: 要加载的记忆类型列表(可选)。若为None,加载所有可用类型。
default_config: 用于合并的默认配置(可选)。
返回:
GeneralMemCube: 已加载远程仓库记忆数据的记忆立方体实例
"""
# 下载远程仓库到本地目录
dir = download_repo(cube_id, base_url)
# 调用本地目录初始化方法,创建并返回记忆立方体实例
return GeneralMemCube.init_from_dir(dir, memory_types, default_config)
@property
def text_mem(self) -> "BaseTextMemory | None":
"""获取文本记忆实例(属性访问器)。"""
if self._text_mem is None:
logger.warning("Textual memory is not initialized. Returning None.")
return self._text_mem
@text_mem.setter
def text_mem(self, value: BaseTextMemory) -> None:
"""设置文本记忆实例(属性修改器)。
参数:
value: 要设置的文本记忆实例,必须是BaseTextMemory的子类实例
"""
if not isinstance(value, BaseTextMemory):
raise TypeError(f"Expected BaseTextMemory, got {type(value).__name__}")
self._text_mem = value
@property
def act_mem(self) -> "BaseActMemory | None":
"""获取激活记忆实例(属性访问器)。"""
if self._act_mem is None:
logger.warning("Activation memory is not initialized. Returning None.")
return self._act_mem
@act_mem.setter
def act_mem(self, value: BaseActMemory) -> None:
"""设置激活记忆实例(属性修改器)。
参数:
value: 要设置的激活记忆实例,必须是BaseActMemory的子类实例
"""
if not isinstance(value, BaseActMemory):
raise TypeError(f"Expected BaseActMemory, got {type(value).__name__}")
self._act_mem = value
@property
def para_mem(self) -> "BaseParaMemory | None":
"""获取参数化记忆实例(属性访问器)。"""
if self._para_mem is None:
logger.warning("Parametric memory is not initialized. Returning None.")
return self._para_mem
@para_mem.setter
def para_mem(self, value: BaseParaMemory) -> None:
"""设置参数化记忆实例(属性修改器)。
参数:
value: 要设置的参数化记忆实例,必须是BaseParaMemory的子类实例
"""
if not isinstance(value, BaseParaMemory):
raise TypeError(f"Expected BaseParaMemory, got {type(value).__name__}")
self._para_mem = value
3.5 实例
官方代码给出了使用实例如下:
🕰️ 创意1:智能世界时间线系统
基于MemOS构建动态的武侠世界时间轴,让AI理解事件的因果关系:
# 示例:智能时间线管理
timeline_memory = {
"1094年": {
"events": ["萧峰身世之谜揭开", "聚贤庄大战"],
"consequences": ["江湖震动", "丐帮分裂"],
"affected_characters": ["萧峰", "阿朱", "段正淳"]
},
"1095年": {
"events": ["雁门关事件真相", "阿朱之死"],
"consequences": ["萧峰心境转变", "宋辽关系紧张"]
}
}
# AI可以回答:如果萧峰没有去雁门关,后续会如何发展?
🧠 创意2:动态Working Memory世界背景
利用MemCube的working memory功能,让世界背景随着剧情发展实时更新:
# 示例:动态世界状态管理
from memos.memories.textual.base import TextualMemoryItem
# 创建世界状态记忆项
world_state_memories = [
TextualMemoryItem(
memory="宋辽政治紧张程度达到0.8级别,边境冲突频发",
metadata={"type": "world_state", "category": "politics"}
),
TextualMemoryItem(
memory="当前江湖流传的绝世武功:九阳神功、易筋经",
metadata={"type": "world_state", "category": "martial_arts"}
),
TextualMemoryItem(
memory="少林与武当保持中立,丐帮内部出现分裂",
metadata={"type": "world_state", "category": "sect_relations"}
)
]
# 使用MemCube的文本记忆管理世界状态
mem_cube.text_mem.replace_working_memory(world_state_memories)
# 当萧峰做出重要决定时,自动更新工作记忆
current_working_memory = mem_cube.text_mem.get_working_memory()
0x04 记忆生产流程
当一条消息进入系统时,它是如何被加工成记忆,并在未来对话中被有效使用的?
MemOS 的记忆机制可以理解为一条完整的「工作流」:
你提交原始消息 → 对记忆进行加工生产 → 调度机制根据任务和上下文安排调用与存储,并可动态调整记忆形态 → 在需要时被召回相关记忆注入为上下文或指令 → 同时由生命周期管理维持演化与更新。
即:记忆生产 → 记忆调度 → 记忆召回与指令补全 → 记忆生命周期管理
比如:构建一个基于《天龙八部》小说的智能记忆分析系统,实现从原始文本到结构化记忆的完整转换流程。数据处理流水线如下:
- 文本预处理 → 章节切分 → 结构化输入
- AI驱动抽取 → 人物建模 → MemCube生成
- 格式转换 → 图结构构建 → MemOS记忆库
0x05 常见问题
Q:MemOS 和普通 RAG 框架有什么区别?
| 对比维度 | RAG | MemOS | MemOS 的优势 |
|---|---|---|---|
| 精准度 | 语料越多,噪声越大 | 通过生产阶段的抽取、图式化/关系建模,再配合调度与生命周期管理,形成结构化组织,记忆条理更清晰 能够基于用户反馈驱动自我进化 |
更准:减少噪声,降低幻觉 |
| 结果组织 | 直接拿原文段落,内容冗余 | 将原始信息加工为记忆,提炼成事实/偏好等单元,内容更短、更纯粹 | 更省:同等信息量下更少 token |
| 搜索范围 | 每次都在全量语料里搜,语料越大越慢 | 记忆动态更新,分层管理,逐层召回 | 更快:避免全局扫描,小范围命中 |
| 理解力 | 不能从用户历史对话中沉淀偏好(无个性化),仅依赖静态知识库的相似度匹配 | 会自动提取记忆做偏好建模,并在召回时转化为可执行的指令,让模型真正理解到位。 | 更懂:回答更贴近真实需求 |
Q:MemOS 可以和已有 RAG 或知识图谱结合吗?
可以结合。
- RAG 专注于 事实检索与知识增强,让模型“知道世界上有什么”;
- MemOS 专注于 状态管理与连续记忆,让模型“知道你是谁、你想要什么”。
两者结合后能形成互补的智能结构:
🧠 RAG 提供外部知识,MemOS 提供内在记忆。
前者让模型更聪明,后者让模型更懂你。
在实践中,MemOS 的记忆单元 可以与 RAG 的向量召回层 直接对接,也能调用外部知识图谱。
区别在于——RAG 管理的是 静态事实,而 MemOS 管理的是 随时间演化的动态记忆。
换句话说:
- RAG 让模型更像百科全书;
- MemOS 让模型更像你长期相处的助手。
当两者融合时,AI 就既能“知道世界”,也能“理解你”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号