[源码分析] Facebook如何训练超大模型 --- (2)
[源码分析] Facebook如何训练超大模型 --- (2)
0x00 摘要
我们在前文介绍过,微软 ZeRO 可以对一个万亿参数模型可以使用 8 路模型并行、64 路管道并行和 8 路数据并行在 4,096 个 NVIDIA A100 GPU 上进行扩展。
而FSDP(Fully Sharded Data Parallel)是Facebook 深度借鉴微软ZeRO之后提出的PyTorch DDP升级版本,可以认为是对标微软 ZeRO,其本质是 parameter sharding。Parameter sharding 就是把模型参数等切分到各个GPU之上。我们会以 Google,微软和 Facebook 的论文,博客以及代码来进行学习分析。
前文我们介绍了 FSDP 如何使用,本文从源码角度来介绍 FSDP 如何实现参数分区。
本系列其他文章如下:
[源码解析] PyTorch 分布式之 ZeroRedundancyOptimizer
[论文翻译] 分布式训练 Parameter sharding 之 ZeRO
[论文翻译] 分布式训练 Parameter Sharding 之 Google Weight Sharding
0x01 回顾
1.1 ZeRO
我们首先回顾一下ZeRO。
深度模型训练之中,显存主要是被Model States 与 Activation 两部分所占用。Model States 包括:
- Optimizer States:优化器在梯度更新时候所用到数据,比如SGD 中的
Momentum。 - Gradient: 反向传播所产生的梯度。
- Model Parameter: 模型参数,即在训练过程中通过数据“学习”到的信息。
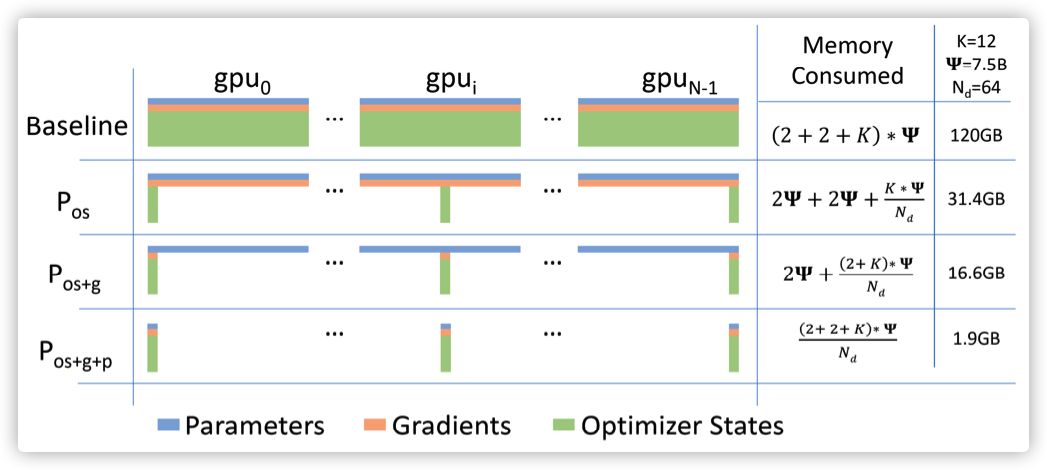
ZeRO 解决的就是Model States占用问题,而ZeRO分为三个级别,如下图所示,分别对应了对于Model States在不同程度上的分割。

1.1.1 ZeRO-1
此级别会切分Optimizer States。
无论在前向传播还是反向传播阶段,优化器都不会起作用,Optimizer States只是在梯度产生之后,在利用梯度做更新时才会与模型参数一起计算,产生新的参数。因此,ZeRO-1对Optimizer States做切分,假设有N个worker,则让每个worker只拥有1/N的Optimizer States,利用这1/N的Optimizer States更新与之对应的1/N参数之后,再把所有参数拼接起来,构成完整的模型(具体是通过broadcast或allgather操作以确保所有rank都收到最新更新的参数值)。
1.1.2 ZeRO-2
ZeRO-2会分割Optimizer States与Gradients。
ZeRO-2 是建立在 ZeRO-1 基础之上,因为ZeRO-1已经把Optimizer States分段储存在了多个worker之中,所以自然而然就只需要得到自己worker的Optimizer States对应的梯度,也就完成了梯度分片。
所有worker的梯度通过AllReduce进行聚合,每个worker只选择自己需要的部分梯度即可,其余梯度可以丢弃。
1.1.3 ZeRO-3
ZeRO-3会分割Optimizer States、Gradients与Parameters。在 ZeRO-1, ZeRO-2基础之上,使得每个worker只保留部分模型分片,所有worker通力合作提供一个完整的Model States,按照具体计算需求进行参数的收集和释放。这里要强调一点,ZeRO-3 做得是的参数收集与释放,就是针对每个参数进行细致处理,我们后续会结合代码进行分析。
1.2 DDP VS FSDP
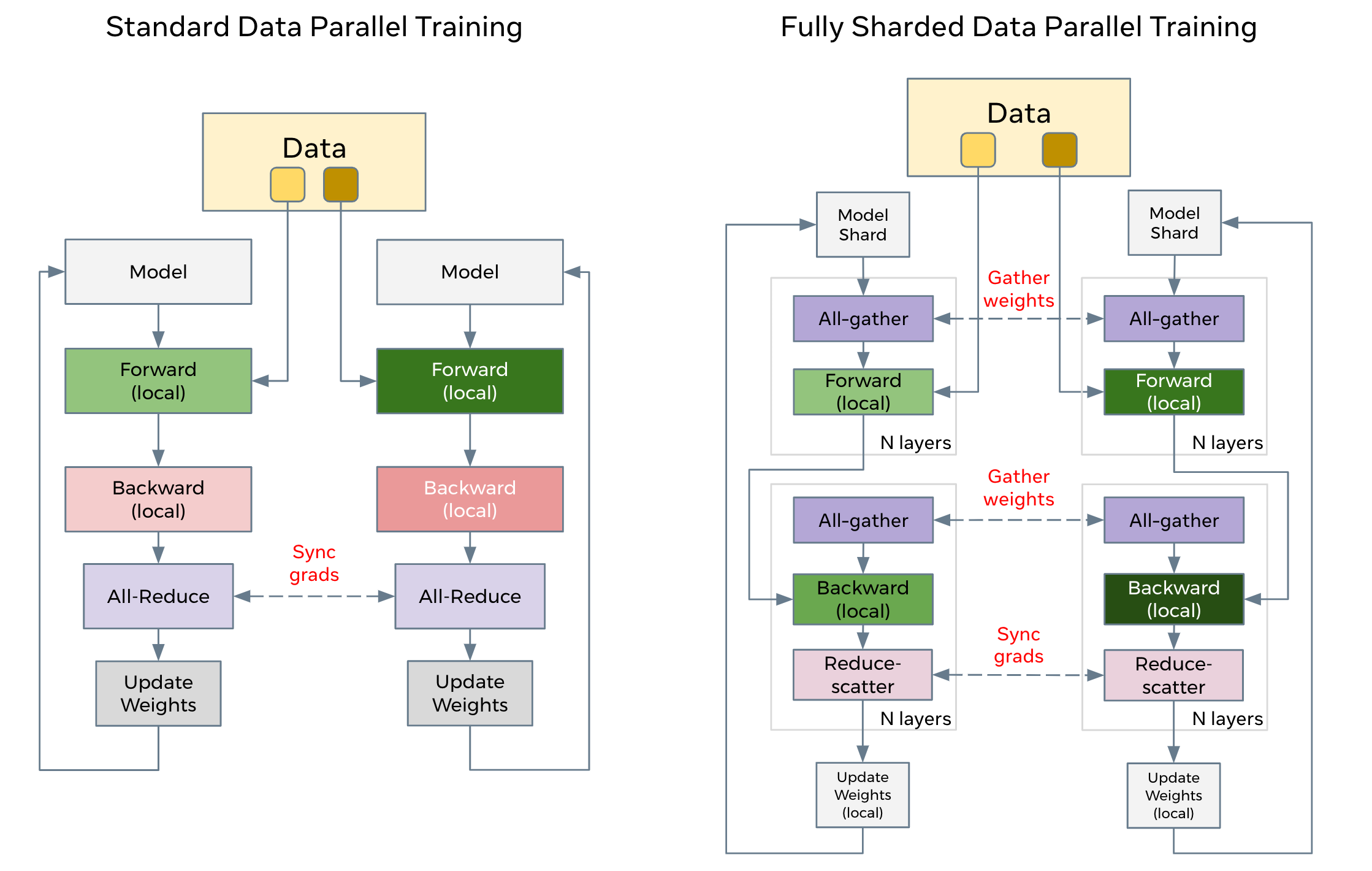
我们先从源码早期版本中找出一个图来看看DDP与FSDP的区别,大家可以回顾一下。
0x02 总体逻辑
2.1 FSDP
我们首先回忆FSDP总体逻辑如下:
- Model shard :每个GPU上仅存在模型的分片。
- All-gather :每个GPU通过all-gather从其他GPU收集所有权重,以在本地计算前向传播。就是论文思路Pp下划线部分。
- Forward(local):在本地进行前向操作。前向计算和后向计算都是利用完整模型。
- All-gather :然后在后向传播之前再次执行此权重收集。就是论文思路Pp之中的下划线部分。
- Backward(local):本地进行后向操作。前向计算和后向计算都是利用完整模型,此时每个GPU上也都是全部梯度。
- Reduce-scatter :在向后传播之后,局部梯度被聚合并且通过 reduce-scatter 在各个GPU上分片,每个分片上的梯度是聚合之后本分区对应的那部分,就是论文思路Pg之中的下划线部分。
- Update Weight(local):每个GPU更新其局部权重分片。
2.2 原始ZeRO
其次,我们看看微软 ZeRO 原始代码是如何处理的,大家可以结合上面FSD思路来对照,在后续FSDP代码分析之中也可以看看两者的具体实现区别。
1.2.1 初始化
ZeRO初始化时候会对参数进行均匀切分给各个进程,它会:
- 把原始参数打平为一维。
- 每个worker依据自己rank来找到在一维参数之中的起始和终止位置,然后拷贝自己对应的数据。
- 为了防止后续填充和分区导致原始数据特性的丢失,会在 _convert_to_deepspeed_param 之中记录原始张量的信息,比如shape, numel等等。
- 会把原始参数释放掉,变成一个标量类型的张量。
因为前向传播/后向传播时候都需要完整参数,所以需要知道如何得到全部参数,ZeRO会在初始化时候就构建控制信息,具体操作是给每个submodule 建立 4个hooks。
_pre_forward_module_hook,在submodule的前向传播开始前收集module parameters。_post_forward_module_hook,在submodule的前向传播结束后释放module parameters。_pre_backward_module_hook,在submodule的反向传播开始前收集module parameters。_post_backward_module_hook,在submodule的反向传播结束后释放module parameters。
具体代码是:
# Pre forward hook
module.register_forward_pre_hook(_pre_forward_module_hook)
# Post forward hook
module.register_forward_hook(_post_forward_module_hook)
# Pre backward hook
module.register_forward_hook(_pre_backward_module_hook)
# post backward hook
module.register_forward_pre_hook(_post_backward_module_hook)
然后会构建两个类:PartitionedParameterCoordinator 和 PrefetchCoordinator,它们负责具体收集和释放,被每个hook调用。
1.2.2 前向传播
前向传播开始之前,_pre_forward_module_hook会收集各个分区上的权重,构建原始参数。这里有一些优秀的技巧。
因为训练是逐层进行,所以ZeRO会进行预取操作,即在收集本层参数时候,也会把下一层参数也收集进来,这样可以节省通信时间。具体是:
- 在做第一个迭代时候,就记录一个模型的完整运行记录,就是每个 nn.module的执行顺序。
- 会依据运行记录来收集本层和下一层的参数,并行依据前面提到的_convert_to_deepspeed_param 之中记录的原始张量信息,重建成原始的大参数。
- 执行本层submodule的forward,记录本次走到哪一步,这样就知道下一次预取哪一个层的参数。
前向传播结束之后,会调用_post_forward_module_hook来释放本层重建的原始的大参数。
这里就是关键了,具体all-gather / release 是逐层操作的,就是每次迭代之中,逐步构建每层的原始大参数 / 释放每层的原始大参数,GPU上始终没有一个完整的所有层的模型,而是陆续拥有每层的原始参数。比如有6层,则达到计算第4层时候,某个GPU上如下,只有第三层是完整的参数,前面三层释放掉了,后面两层还没有收集。
+---------------------------------------------+
| GPU n |
| + gather |
| | forward |
| | release |
| v |
| +---+----+ |
| Layer 0 | | |
| +---+----+ |
| | gather |
| | forward |
| | release |
| v |
| +---+----+ |
| Layer 1 | | |
| +---+----+ |
| | gather |
| | forward |
| | release |
| v |
| +---+----+ |
| Layer 2 | | |
| +---+----+ |
| | |
| | gather |
| | forward |
| v |
| +------------+------------------+ |
| Layer 3 | | |
| +-------------------------------+ |
| |
| +--------+ |
| Layer 4 | | |
| +--------+ |
| |
| +--------+ |
| Layer 5 | | |
| +--------+ |
+---------------------------------------------+
通过这样的方式,每个worker 中 submodule 只需要在前向传播计算前收集/构建参数,计算后释放参数,就可以减少冗余内存空间。如果我们单独拿出一层来看前向传播和后向传播,则其运行机制如下,通过几个 hook 完成了参数分区。
+-------------------------------------------------------------+
| submodule |
| |
| _pre_forward_module_hook() gather & rebuild |
| |
| + |
| | |
| | |
| v |
| |
| forward |
| |
| + |
| | |
| | |
| v |
| |
| _post_forward_module_hook() release |
| |
| + |
| | |
| | |
| v |
| |
| _pre_backward_module_hook() gather & rebuild |
| |
| + |
| | |
| | |
| v |
| |
| backward |
| |
| + |
| | |
| | |
| v |
| |
| _post_backward_module_hook() release |
| |
+-------------------------------------------------------------+
1.2.3 反向传播
_pre_backward_module_hook也是类似前向传播那样收集,预取参数,记录执行步骤。
_post_backward_module_hook也是类似前向传播那样释放计算不再需要的冗余参数。
只是因为 PyTorch 不支持Pre Backward Hook,所以在 register_forward_hook时候配置了一个autograd.Function,其目的是在module 做backward 之前执行自定义的操作,于是all-gather和scatter reduce 操作就挂到每个submodule之上。
2.3 FSDP代码
然后,我们结合代码做一下总述。
2.3.1 初始化
初始化主要作用就是把 Model Parameters 进行切分,每个worker都会分摊部分模型参数。
具体分片操作是通过将每个参数视为一维张量并仅保留一个切片来实现的,其中切片大小由数据并行worker的数量决定。需要注意的是:模型参数必须在加载到GPU之前就进行拆分,然后才能加载到各个worker的GPU之上。
因为后期有填充和分区操作,为了放置原始数据特性丢失,FSDP利用了 PyTorch的 data.size() 方法,把原始数据特性记录在 p._orig_size 之中。
VS ZeRO:此时FSDP没有做hook的控制操作。
2.3.2 前向传播
这一部分的核心是:每个GPU之上进行前向传播,同时为后向传播建立控制关系,这样后向传播知道应该如何收集参数,如何释放参数。具体有如下操作:
- 首先,因为前向传播利用的是完整模型,所以先要使用All-gather来从其他GPU收集所有权重,具体是通过调用 _rebuild_full_params() 完成重建所有模型参数,其会利用p._orig_size存储的原始信息进行重建原始参数。
- 调用_register_post_backward_hooks为后向传播建立 reduce-scatter。
- 进行前向操作。
- 调用 _register_pre_backward_hooks(outputs) 为后向传播注册 all-gather。
具体对应简化代码是:
self._rebuild_full_params() # 做前向操作之前的 all-gather
self._register_post_backward_hooks() # 为后向传播注册 reduce-scatter
outputs = self.module(*args, **kwargs) # 模型前向传播
outputs = self._register_pre_backward_hooks(outputs) # 为后向传播注册 all-gather
VS ZeRO:FSDP在此时hook的控制操作,但是没有利用module的各种hook,而是统一利用张量的 register_hook。
2.3.3 分层优化
大家可能有疑惑,这和ZeRO原始代码不同呀,ZeRO原始代码是每一层都执行收集/丢弃,FSDP这里看起来是对整体模型做了一次forward,没有分层执行。
其实,以上代码只是一个标准实现或者说只把整个系统看作是一层,没有涉及到分层执行收集/丢弃。FSDP已经考虑到了分层的情况,具体如下:
为了最大限度地提高内存效率,我们可以在每层向前传播后丢弃全部权重,为后续层节省内存。这可以通过将FSDP包装应用于网络中的每一层来实现(使用auto_wrap来实现包装每一层,以及设置reshard_after_forward=True)。下面是伪代码示意:
FSDP forward pass:
for layer_i in layers:
all-gather full weights for layer_i # 权重
forward pass for layer_i
discard full weights for layer_i # 权重
FSDP backward pass:
for layer_i in layers:
all-gather full weights for layer_i # 权重
backward pass for layer_i
discard full weights for layer_i # 权重
reduce-scatter gradients for layer_i # 梯度
2.3.4 小结
我们可以看到,如果模型参数被分片,则本地的优化器就会优化这些本地被分到的参数,则优化器状态就自动被分片了,从而梯度也被自动分片了,就是图之中最下面的\(P_{os+g+p}\)。
0x03 初始化
初始化主要作用就是把 Model Parameters进行切分,每个worker都会分摊部分模型参数。假如有3个,则每个worker分担了1/3,于是它们就把不属于自己的另外2/3(因为已经是冗余的了)释放掉。但是3个worker各自模型参数合并起来,恰好又是整个模型参数。
我们首先统览初始化方法全局,大家有一个大致的印象,接下来会仔细逐步分析。
class FullyShardedDataParallel(nn.Module):
def __init__(
self,
module: nn.Module,
process_group: Optional[ProcessGroup] = None,
reshard_after_forward: bool = True,
mixed_precision: bool = False,
fp32_reduce_scatter: bool = False,
flatten_parameters: bool = True,
move_params_to_cpu: bool = False,
compute_dtype: Optional[torch.dtype] = None,
buffer_dtype: Optional[torch.dtype] = None,
move_grads_to_cpu: Optional[bool] = None,
bucket_cap_mb: int = 25,
compute_device: Optional[torch.device] = None,
no_broadcast_optim_state: Optional[bool] = False,
state_dict_device: Optional[torch.device] = None,
clear_autocast_cache: bool = False,
force_input_to_fp32: bool = False,
verbose: bool = False,
cpu_offload: bool = False,
):
init_start = time.time()
super().__init__()
self.process_group = process_group or get_process_group_cached()
self.rank = self.process_group.rank()
self.world_size = self.process_group.size()
self.reshard_after_forward = reshard_after_forward
self.mixed_precision = mixed_precision
self.fp32_reduce_scatter = fp32_reduce_scatter
self.flatten_parameters = flatten_parameters
self.move_params_to_cpu = move_params_to_cpu or cpu_offload
self.compute_dtype = compute_dtype or (torch.float16 if mixed_precision else torch.float32)
self.buffer_dtype = buffer_dtype or self.compute_dtype
self.move_grads_to_cpu = self.move_params_to_cpu if move_grads_to_cpu is None else move_grads_to_cpu
self.bucket_cap_mb = bucket_cap_mb
self.compute_device = compute_device or _get_default_cuda_device(module)
self.uncollected_opt_state: Dict[int, Dict] = {}
self.no_broadcast_optim_state = no_broadcast_optim_state
self.state_dict_device = state_dict_device or self.compute_device
self.clear_autocast_cache = clear_autocast_cache
self.force_input_to_fp32 = force_input_to_fp32
self.verbose = verbose
self.gradient_predivide_factor: float = self._get_gradient_predivide_factor(self.world_size)
self.gradient_postdivide_factor: float = self.world_size / self.gradient_predivide_factor
self.numel_padded_per_param: List[int] = []
self._tstart = time.time()
# skip validation if the process group was created above
if process_group:
validate_process_group(self.compute_device, self.process_group)
# enable pytorch sync_bn just in case model contains sync_bn layers.
enable_pytorch_sync_bn(module)
# 1. 打平参数
# Only handle params which are not already sharded. This enables
# sharding individual layers of a Module, with an outer wrapper to
# shard any leftover parameters.
param_names = []
params = []
# 1.1 遍历模型参数,收集到params之中
for param_name, param in module.named_parameters():
if not hasattr(param, "_is_sharded"):
param_names.append(param_name)
params.append(param)
self._has_params = len(params) > 0
# 1.2 把需要打平的参数收集到 to_be_flatten_params 之中
to_be_flatten_params: List[List[Parameter]] = [[]]
non_flatten_params = params
param_name_groups = [[n] for n in param_names]
if self.flatten_parameters:
to_be_flatten_params = [params]
non_flatten_params = []
param_name_groups = [param_names]
del param_names
# 1.3 使用 FlattenParamsWrapper 来打平参数
self._fsdp_wrapped_module: nn.Module = FlattenParamsWrapper(module, param_list=to_be_flatten_params)
del module # free original module in case it helps garbage collection
# Now, in this FSDP wrapper class, we keep a list of to-be-flatten and not-to-be-flatten
# params for doing sharding, gradient hooks, etc. Note, the ordering of the
# list matters: flatten params are always in the front.
#
# The self._num_flatten_params and self._param_name_groups are computed
# and kept here to support summon_full_params and shard-to-full weight
# consolidation.
# 1.4 把打平的参数和其他参数拼接到 self.params 之中
self.params = cast(List[Parameter], self._fsdp_wrapped_module.flat_params) + non_flatten_params
self._num_flatten_params = len(self._fsdp_wrapped_module.flat_params)
self._param_name_groups = param_name_groups
# 2. 进行参数分区
# Shard module parameters in place
self._shard_parameters_() #
# 3. 惰性初始化
self._reset_lazy_init()
# Flag to indicate if we require gradient reduction in the backward
# pass. This will be False when inside the no_sync context manager.
self._require_backward_grad_sync: bool = True
# Enum to indicate if we're in the forward/backward pass, idle, etc.
self.training_state = TrainingState.IDLE
# Flag to indicate if the full params are gathered.
self.has_full_params: bool = False
# Register hook after state_dict() to remove the "_fsdp_wrapped_module."
# prefix and before load_state_dict() to add it back.
self._register_state_dict_hook(_post_state_dict_hook)
self._register_load_state_dict_pre_hook(_pre_load_state_dict_hook)
# Flag to indicate whether state_dict() should automatically summon the
# full params. This defaults to True, but may be set to False if the
# user explicitly requests the local state dict via local_state_dict().
self._return_full_state_dict = True
init_end = time.time()
# Flag to guard multiple pre-backward hook being executed per iteration.
# This is reset at the end of the backward pass.
self._pre_backward_hook_has_run = False
3.1 处理参数
初始化方法的第一步是处理参数,下面这些具体数字对应代码之中的注释。
- 1.1 会遍历模型参数,收集到params之中。
- 1.2 把需要打平的参数收集到 to_be_flatten_params 之中。
- 1.3 使用 FlattenParamsWrapper 来打平参数。
- 现在,我们得到了一个列表 self.params,其保存用于sharding、gradient hooks等操作的待展平和不展平参数。列表的顺序是:展平参数总是在前面。
- self._num_flatten_params 和 self._param_name_groups 也会被计算出来,以支持summon_full_params and shard-to-full 权重合并。
- 1.4 把打平的参数和其他参数拼接到 self.params 之中。
3.1.2 进行分片
初始化然后会调用 shard_parameters 进行分片。从注释可知,在初始化时会包装一个有完整参数的模块,并将参数原地切分。具体分片操作是通过将每个参数视为一维张量并仅保留一个切片来实现的,其中切片大小由数据并行worker的数量决定。
需要注意的是:模型参数必须在加载到GPU之前就进行拆分,然后才能加载到各个worker的GPU之上。
@torch.no_grad()
def _shard_parameters_(self) -> None:
"""
At initialization we wrap a module with full parameters and shard the
parameters in-place. Sharding is implemented by viewing each parameter
as a 1D Tensor and retaining only a single slice, where the slice size
is determined by the number of data parallel workers.
Wrapping modules with many small parameters (or with a very large data
parallel world size) will result in many small parameter shards and slow
performance. In this case it's better to set *``flatten_parameters``* to
``True``, so that all of the small parameters in the module are combined
into a single contiguous Tensor and sharded once.
After this initial sharding is complete, the user can initialize a
``torch.optim.Optimizer`` in the usual way, i.e.::
The optimizer will see only a single slice of parameters and will thus
allocate less memory for optimizer state, avoiding redundancy across
data parallel workers.
"""
self.numel_padded_per_param = []
for p in self.params: # 遍历模型参数列表
# If world_size is 1, then we all-reduce grads instead of sharding.
p._is_sharded = self.world_size > 1
p._orig_size = p.data.size() # 记录张量原始信息(shape, numel, etc)
if not p._is_sharded:
self.numel_padded_per_param.append(0)
continue
p._is_sharded = True
# Replace p.data with the relevant shard.
orig_data = p.data # 拿到原始数据
p.data, num_padded = self._get_shard(p.data) # 获取这个模型参数的分区
self.numel_padded_per_param.append(num_padded)
free_storage_(orig_data) # 释放冗余数据
_get_shard 就是具体做分区操作,但只是会返回本rank对应的分区。
ZeRO原始代码之中,会对每个模型参数张量套一个_convert_to_deepspeed_param马甲,这样可以把张量原始特性(shape, numel, etc)记录下来,防止后期因为填充和分区导致原始数据特性丢失,FSDP没有采用这个办法,而是记录在 p._orig_size 之中,具体是利用了 PyTorch的 data.size() 方法。
def _get_shard(self, tensor: torch.Tensor) -> Tuple[torch.Tensor, int]:
"""Return the local shard of a full tensor."""
# Shard using torch.chunk to match all-gather/reduce-scatter.
# 把传入的张量打平,按照world size分成一个list
chunks = list(torch.flatten(tensor).chunk(self.world_size))
# 把list之中都初始化
while len(chunks) < self.world_size:
chunks.append(chunks[0].new_empty(0)) # 插入空白张量
# Determine number of padding elements.
# 看看需要pad多少元素
num_to_pad = chunks[0].numel() - chunks[self.rank].numel()
# 获得本rank对应的分区
shard = chunks[self.rank].clone()
if num_to_pad > 0:
shard = F.pad(shard, [0, num_to_pad]) # pad
# 返回
return shard, num_to_pad
3.3 惰性初始化
在 forward 或者其他方法之中,会进行惰性初始化,具体是:
- 调用 _init_param_attributes 来初始化参数,对于需要移动的参数,为后续移动到CPU做准备,放到pin_memory之中。
- 调用 _set_is_root 进行root设置,这里主要是针对进程组做一些设置。
- 调用 _setup_streams 建立CUDA流。为"fp32_to_fp16","all_gather" 和 "post_backward" 分别建立不同的 CUDA 流,建立 ReduceScatterBucketer。
- 调用 _wait_for_previous_optim_step 等待流完成。
def _lazy_init(self) -> None:
"""Initialization steps that should happen lazily, typically right
before the first forward pass.
"""
# Initialize param attributes lazily, in case the param's dtype or
# device changes after __init__.
for p in self.params:
self._init_param_attributes(p) # 1. 初始化参数
# Initialize _is_root and setup streams. These steps would ideally
# happen in __init__, but _is_root can only be determined after the
# entire model hierarchy is setup, thus we run it lazily.
if self._is_root is None:
self._set_is_root()
self._setup_streams()
if self._is_root:
# Buffers stay on GPU, and don't get sharded. Since _cast_buffers
# applies recursively, we only call this from the root instance.
self._cast_buffers()
# Don't free the full params for the outer-most (root) instance,
# since those params will be needed immediately after for the
# backward pass.
self.reshard_after_forward = False
# Due to the use of streams, we need to make sure the previous
# ``optim.step()`` is done before we all-gather parameters.
self._wait_for_previous_optim_step()
3.3.1 初始化参数
此处会设置以下参数,这里就能看出来混合精度的切换:
_fp32_shard:full precision的单个参数分片(通常为fp32,但这取决于用户传入的模型数据类型)。可以在CPU或GPU上进行,具体取决于cpu_offload的值。_fp16_shard:如果mixed_precision为True,这将是fp16中参数的单个shard,用于all-gather。_full_param_padded:在向前和向后传播中用于计算的全部权重(被填充为可被world_size均匀整除)。这将原地调整大小,并仅在需要时具体化(通过all-gather)。
主要逻辑是:为后续移动到CPU做准备,某些参数会放到pin_memory之中,生成一个容纳所有权重的_full_param_padded 。
@torch.no_grad()
def _init_param_attributes(self, p: Parameter) -> None:
"""
We manage several attributes on each Parameter instance. The first two
are set by :func:`_shard_parameters_`:
``_is_sharded``: ``True`` if the Parameter is sharded or ``False``
if the Parameter is intentionally not sharded (in which case we
will all-reduce grads for this param).
``_orig_size``: the size of the original Parameter (before sharding)
The remaining attributes are set here:
``_fp32_shard``: a single shard of the parameters in full precision
(typically FP32, but this is dependent on the dtype of the model
as it's passed in by the user). This can be on CPU or GPU
depending on the value of *``cpu_offload``*.
``_fp16_shard``: if *``mixed_precision``* is ``True``, this will be
a single shard of the parameters in FP16, used for all-gather.
``_full_param_padded``: the full weight (padded to be evenly
divisible by ``world_size``), used for computation in the
forward and backward pass. This will be resized in place and
only materialized (via all-gather) as needed.
"""
if hasattr(p, "_fp32_shard"):
return
# A single shard of the parameters in full precision.
p._fp32_shard = p.data
if self.mixed_precision:
if self.move_params_to_cpu:
# 为后续移动到CPU做准备,放到pin_memory之中
# If we plan to keep the FP32 parameters on CPU, then pinning
# memory allows us to later use non-blocking transfers when moving
# the FP32 param shard to compute_device.
p._fp32_shard = p._fp32_shard.pin_memory()
p.data = p._fp32_shard
# In mixed precision mode, we maintain a reduced precision
# (typically FP16) parameter shard on compute_device for performing
# the computation in the forward/backward pass. We resize the
# storage to size 0 at init (here) and re-materialize (by copying
# from _fp32_shard) as needed.
p._fp16_shard = torch.zeros_like(p._fp32_shard, device=self.compute_device, dtype=self.compute_dtype)
free_storage_(p._fp16_shard)
else:
p._fp16_shard = None # use _fp32_shard
# We also maintain a full-sized parameter of type self.compute_dtype
# (FP16 for mixed_precision or FP32 otherwise). We resize the
# storage to size 0 at init (here) and only materialize as needed. The
# storage may contain padding elements so that it is evenly divisible by
# world_size, although these padding elements will be removed before the
# relevant computation.
if p._is_sharded:
p._full_param_padded = torch.zeros( # _full_param_padded 是所有权重
p.data.numel() * self.world_size, device=self.compute_device, dtype=self.compute_dtype
)
free_storage_(p._full_param_padded)
if self.move_grads_to_cpu:
# 为后续移动到CPU做准备,放到pin_memory之中
# We can optionally move the grad shard to CPU during the backward
# pass. In this case, it's important to pre-allocate the CPU grad
# shard in pinned memory so that we can do a non-blocking transfer.
p._cpu_grad = torch.zeros_like(p.data, device="cpu").pin_memory()
3.3.2 root设置
这里主要是针对进程组做一些设置。
def _set_is_root(self) -> None:
"""If ``True``, implies that no other :class:`FullyShardedDataParallel`
instance wraps this one. Called once by :func:`_lazy_init`.
Also sets self.children_share_process_group = True if all child
instances share the same process group. If some child instances use a
different process group, self.clip_grad_norm_ will raise an error.
"""
if self._is_root is not None:
return
# No FSDP instance wraps this, else _is_root would be set to False.
self._is_root = True
# As the root, we now set all children instances to False and
# give them a closure to try to queue a wait_for_post_backward.
self.children_share_process_group = True
for n, m in self.named_modules():
# `n != ""` excludes self.
if n != "" and isinstance(m, FullyShardedDataParallel):
# We relax the assert for non-root instance, when the nested inialized module is wrapped
# again in FSDP later, for example after training to run inference.
assert m._is_root is None or not m._is_root
if m._is_root is None:
m._is_root = False
if m.process_group != self.process_group:
self.children_share_process_group = False
# if child instance in its own (smaller) world, that was probably an attempt to avoid OOM.
# Therefore gathering this child's optim state will probably cause OOM, so we won't do it.
m.no_broadcast_optim_state = m.no_broadcast_optim_state or (
(m.world_size == 1) and (m.world_size < self.world_size) and (m.process_group != self.process_group)
)
3.3.3 建立CUDA流
为"fp32_to_fp16","all_gather" 和 "post_backward" 分别建立不同的 CUDA 流,建立 ReduceScatterBucketer。
def _setup_streams(self) -> None:
"""Create streams to overlap data transfer and computation."""
if len(self._streams) > 0 or not self._is_root:
return
if torch.cuda.is_available():
# Stream to move main FP32 params (may be on CPU) to FP16 for forward.
self._streams["fp32_to_fp16"] = torch.cuda.Stream()
# Stream for all-gathering parameters.
self._streams["all_gather"] = torch.cuda.Stream()
# Stream for overlapping grad reduction with the backward pass.
self._streams["post_backward"] = torch.cuda.Stream()
# Helper for bucketing reduce-scatter ops. This is also shared with
# children instances to improve bucket utilization.
self._reducer = ReduceScatterBucketer(self.bucket_cap_mb)
# We share streams with all children instances, which allows them to
# overlap transfers across the forward pass without synchronizing with
# the default stream.
for n, m in self.named_modules():
if n != "" and isinstance(m, FullyShardedDataParallel):
m._streams = self._streams
m._reducer = self._reducer
3.3.4 同步
等待流完成操作。
def _wait_for_previous_optim_step(self) -> None:
"""
The outer-most :class:`FullyShardedDataParallel` instance (i.e., the root
instance) needs to synchronize with the default stream to ensure the
previous optimizer step is done.
"""
if not torch.cuda.is_available():
return
if self.mixed_precision:
self._streams["fp32_to_fp16"].wait_stream(torch.cuda.current_stream())
else:
self._streams["all_gather"].wait_stream(torch.cuda.current_stream())
所以,目前状态如下,假设有2个GPU,模型参数被切分到两个GPU之上。假设模型有两个参数,Parameter 0,Parameter 1,每个参数都被切分成两段,分别存在两个GPU之上,其中 Parameter 0 被分成 Parameter 0_0 和 Parameter 0_1,Parameter 1 被分成 Parameter 1_0 和 Parameter 1_1 。
Model Parameter
+----------------------------+
| Parameter 0 |
| |
| Parameter 1 |
| |
+------------+---------------+
|
| split
v
+-----+-----+
| |
| |
GPU 0 v v GPU 1
+------------------------+----+ +--+---------------------------+
| Model Parameter Shard 0 | | Model Parameter Shard 1 |
| +-------------------------+ | | +--------------------------+ |
| | Parameter 0_0 | | | | Parameter 0_1 | |
| | | | | | | |
| | Parameter 1_0 | | | | Parameter 1_1 | |
| | | | | | | |
| +-------------------------+ | | +--------------------------+ |
+-----------------------------+ +------------------------------+
0x04 前向传播
这部分核心是根据参数分片需求做到精确的参数收集/使用/释放。收集就是下面图的All-gather,释放就是Reduce-Scatter。

4.1 forward
依据前文的分析,我们知道前向操作包括两部分:
- All-gather :每个GPU通过all-gather从其他GPU收集所有权重,以在本地计算前向传播。
- Forward(local):在本地进行前向操作。前向计算和后向计算都是利用完整模型。
对应到代码,具体逻辑是:
- 如果使用混合精度,则把输入转换为FP16。
- 如果不使用混合精度,切强制转换FP32,则进行转换 。
- 调用 _rebuild_full_params() 做前向操作之前的 all-gather,这样可以重建所有模型参数。
- 因为参数的收集/释放是发生在前向传播和后向传播之中,所以在前向传播时候就需要为后向传播做好配置。具体就是调用_register_post_backward_hooks为后向传播建立 reduce-scatter。
- 进行前向操作。
- 切换到主FP32参数分片。我们在整个代码中都保持这个不变量,即在每个函数之后,
p.data == p._fp32_shard。因为优化器状态通常在optim.step()中延迟初始化,这还确保在第一次forward之后,优化器状态将使用正确的数据类型和(分片)大小来初始化。 - 调用 _register_pre_backward_hooks(outputs) 为后向传播注册 all-gather。这里是在最终的output张量上注册了hook,所以在反向传播时候,会第一个调用这个hook,就可以顺理成章的做all-gather。因为这个必须在最终output之上注册,所以 _register_pre_backward_hooks 是在前向传播最后部分才调用。
def forward(self, *args: Any, **kwargs: Any) -> torch.Tensor:
self._lazy_init()
# Start of a forward pass.
self.training_state = TrainingState.FORWARD
# 1. 如果使用混合精度,则把输入转换为FP16
# For root and mixed precision, we convert the input to FP16 (no_grad is needed for
# the conversion).
if self._is_root and self.mixed_precision:
args, kwargs = cast_floats_to_right_precision(True, True, *args, **kwargs)
# 2. 如果不使用混合精度,切强制转换FP32,则进行转换
# If enabled, convert the input to FP32 if we are in full precision.
# no_grad is not used because the input might be for a non-root instance,
# which mean autograd needs to go through the conversion.
if self.force_input_to_fp32 and not self.mixed_precision:
args, kwargs = cast_floats_to_right_precision(False, False, *args, **kwargs)
# 3. 调用 _rebuild_full_params() 做前向操作之前的 all-gather
# All-gather full parameters. This will also transfer FP32 parameters to
# ``self.compute_dtype`` (e.g., FP16 if *mixed_precision* is ``True``).
self._rebuild_full_params() # 做前向操作之前的 all-gather
# 4. 调用_register_post_backward_hooks为后向传播建立 Reduce-scatter
# Register backward hooks to reshard params and reduce-scatter grads.
# These need to be re-registered every forward pass.
self._register_post_backward_hooks() # 为后向传播建立 Reduce-scatter
# 5. 进行前向操作
outputs = self.module(*args, **kwargs)
# 6. 丢弃多余模型参数
if self.reshard_after_forward:
self._free_full_params()
if self.mixed_precision:
self._free_fp16_param_shard()
# 7. 切换到主FP32参数分片。我们在整个代码中都保持这个不变量,即在每个函数之后,``p.data == p._fp32_shard``。因为优化器状态通常在``optim.step()``中延迟初始化,这还确保在第一次forward之后,优化器状态将使用正确的数据类型和(分片)大小来初始化,
# Switch to main FP32 param shard. We maintain this invariant throughout
# the code, i.e., ``p.data == p._fp32_shard`` after each function. This
# also ensures that after the first forward, the optimizer state will be
# initialized with the correct dtype and (sharded) size, since optimizer
# state is typically initialized lazily in ``optim.step()``.
self._use_fp32_param_shard()
# 8. 调用 _register_pre_backward_hooks(outputs) 为后向传播注册 all-gather
# Register pre-backward hooks to all-gather the params for the backward
# pass (if output's grad was needed). This won't register anything if
# we are in eval mode.
#
# Some model does forward pass multiple times, we need to register the
# pre-backward hook on every output since the last output's hook has to
# fire first to setup for backward. However, we use ``self._pre_backward_hook_has_run``
# to prevent repeated overhead from multiple hook callbacks.
outputs = self._register_pre_backward_hooks(outputs) # 为后向传播注册 all-gather
# Done with a forward pass.
self.training_state = TrainingState.IDLE
# Only need to clear cache during forward. During backward, the cache is not used.
# TODO (Min): Future PyTorch versions may provide a way to completely disable this
# cache. Update this when that's available.
if self.clear_autocast_cache:
torch.clear_autocast_cache()
return outputs
我们接下来看看每个部分如何实现。
4.1.1 All-gather
self._rebuild_full_params() 会进行前向操作之前的all-gather操作。
# All-gather full parameters. This will also transfer FP32 parameters to
# ``self.compute_dtype`` (e.g., FP16 if *mixed_precision* is ``True``).
self._rebuild_full_params()
4.1.1.1 _rebuild_full_params
这里和OSS一样,都是同步所有的模型参数,具体逻辑是:
-
如果我们已经有完整的参数并且不需要完整的精度,那么就提前退出。
-
设置后续操作使用 all_gather"对应的流。
-
进行精度转换。
-
遍历所有模型参数:
4.1 如果world_size==1,则直接更新,因为只有一个rank。
4.2 把数据从CPU移动到CUDA。
4.3 进行all-gather操作。
4.4 用all-gather结果对本地张量进行更新,其会利用p._orig_size存储的原始信息进行重建。
@torch.no_grad()
def _rebuild_full_params(self, force_full_precision: bool = False) -> Optional[List[Tuple[torch.Tensor, bool]]]:
"""
Gather all shards of params.
Args:
force_full_precision (bool, Optional): by default params will be gathered
in ``compute_dtype`` (e.g., FP16), unless *force_full_precision* is
``True``, in which case they will be gathered in full precision
(e.g., FP32), possibly in fresh storage. The parameter that's being
rebuilt will end up in full precision as well.
Returns:
A list of tuples, where the first element is the full-sized param
and the second element is a bool indicating if it's safe for the
caller to free the full-sized param. This will be ``None`` if
``force_full_precision=False`` and the full params are already gathered.
"""
output_tensors: List[Tuple[torch.Tensor, bool]] = []
def update_p_data(custom_output_tensor: Optional[torch.Tensor] = None) -> None:
"""
Helper function to update p.data pointer.
Args:
custom_output_tensor (torch.Tensor, Optional): if not None, this
tensor contains the data we just gathered.
"""
if custom_output_tensor is not None:
assert p._is_sharded
p.data = custom_output_tensor
output_tensors.append((p.data, True))
elif not p._is_sharded:
if self.mixed_precision and not force_full_precision:
assert p._fp16_shard is not None
p.data = p._fp16_shard
output_tensors.append((p.data, True))
else:
# Here p.data == p._fp32_shard, so it's not safe to free.
output_tensors.append((p.data, False))
else:
p.data = p._full_param_padded
output_tensors.append((p.data, True))
# Trim any padding and reshape to match original size.
p.data = p.data[: p._orig_size.numel()].view(p._orig_size)
# 1. 如果我们已经有完整的参数并且不需要完整的精度,那么就提前退出。
# Early exit if we already have full params and don't need full precision.
if self.has_full_params and not force_full_precision:
for p in self.params:
update_p_data()
return output_tensors
self.has_full_params = True
# 2. 使用 all_gather"对应的流
with torch.cuda.stream(self._streams["all_gather"对应的流]):
# 3. 进行精度转换
if self.mixed_precision and not force_full_precision:
self._cast_fp32_param_shards_to_fp16()
# 4. 遍历所有模型参数
for p in self.params:
if not p._is_sharded: # e.g., when world_size == 1
update_p_data() # 4.1 如果world_size==1,则直接更新,因为只有一个rank
else:
# 4.2 把数据从CPU移动到CUDA
# If self.move_params_to_cpu and force_full_precision, we need to cast
# the FP32 CPU param to CUDA for the all-gather.
p_data = p.data.to(p._full_param_padded.device, non_blocking=True)
p_size = p._full_param_padded.size()
if self.mixed_precision and force_full_precision:
# Allocate fresh tensor in full precision since we are in
# mixed precision and full precision rebuild is asked.
output_tensor = p_data.new_zeros(p_size)
else:
if p._full_param_padded.storage().size() != p_size.numel():
# Allocate based on full size from all shards.
alloc_storage_(p._full_param_padded, size=p_size)
output_tensor = p._full_param_padded
# 4.3 进行all-gather操作
# Fill output_tensor with (p.data for each shard in self.world_size)
if hasattr(dist, "_all_gather_base"):
# New version of PyTorch has all_gather_base, which is faster than chunk and then all_gather.
dist._all_gather_base(output_tensor, p_data, group=self.process_group) # type: ignore
else:
chunks = list(output_tensor.chunk(self.world_size))
dist.all_gather(chunks, p_data, group=self.process_group)
# 4.4 用all-gather结果对本地张量进行更新
# Set p.data = output_tensor (with padding trimmed)
update_p_data(output_tensor)
if self.mixed_precision and not force_full_precision:
self._free_fp16_param_shard([p])
torch.cuda.current_stream().wait_stream(self._streams["all_gather"])
return output_tensors
4.1.1.2 精度操作
_cast_fp32_param_shards_to_fp16 会把 FP32参数分片转换为一个FP16 参数分片。
@torch.no_grad()
def _cast_fp32_param_shards_to_fp16(self, params: Optional[List[Parameter]] = None) -> None:
"""Cast FP32 param shard to FP16 for a list of params."""
if params is None:
params = self.params
with torch.cuda.stream(self._streams["fp32_to_fp16"]):
for p in params:
alloc_storage_(p._fp16_shard, size=p._fp32_shard.size())
p._fp16_shard.copy_(
# If cpu_offload is True, this will be non-blocking because
# _fp32_shard is pinned, otherwise it's a no-op.
p._fp32_shard.to(p._fp16_shard.device, non_blocking=True)
)
p.data = p._fp16_shard
torch.cuda.current_stream().wait_stream(self._streams["fp32_to_fp16"])
4.1.2 丢弃多余参数
这部分包括两种可能,或者丢弃 FP32 参数,比如_free_full_params。
@torch.no_grad()
def _free_full_params(self, params: Optional[List[Parameter]] = None) -> None:
"""Free up storage for full parameters."""
if params is None:
params = self.params
self.has_full_params = False
current_stream = torch.cuda.current_stream()
for p in params:
if not p._is_sharded: # e.g., world_size == 1
if self.mixed_precision:
self._free_fp16_param_shard([p])
continue
# Don't let PyTorch reuse this memory until all work in the current
# stream is complete.
p._full_param_padded.record_stream(current_stream)
# There may be external references to the Tensor Storage that we
# can't modify, such as references that are created by
# ctx.save_for_backward in the forward pass. Thus when we
# unshard parameters, we should reuse the original Tensor
# Storage object and unshard it in-place. For now, just resize
# the Storage to 0 to save memory.
free_storage_(p._full_param_padded)
或者丢弃 FP16 参数。
@torch.no_grad()
def _free_fp16_param_shard(self, params: Optional[List[Parameter]] = None) -> None:
"""Free storage for FP16 shards for a list of params."""
if params is None:
params = self.params
current_stream = torch.cuda.current_stream()
for p in params:
if p._fp16_shard is not None:
# _fp16_shard is allocated in "fp32_to_fp16" stream, so we can't
# free it until the work in the current stream completes.
p._fp16_shard.record_stream(current_stream)
free_storage_(p._fp16_shard)
4.3 配置backward
这部分功能就是为后向传播设置,让其在开始做一个all-gather,结束时候做一个reduce-scatter。这些配置在具体运行逻辑之中就变成了:
- All-gather :然后在后向传播之前再次执行此权重收集。就是论文思路Pp之中的下划线部分。
- Backward(local):本地进行后向操作。前向计算和后向计算都是利用完整模型,此时每个GPU上也都是全部梯度。
- Reduce-scatter :在向后传播之后,局部梯度被聚合并且通过 reduce-scatter 在各个GPU上分片,每个分片上的梯度是聚合之后本分区对应的那部分,就是论文思路Pg之中的下划线部分。
对应前面代码之中就是:
self._register_post_backward_hooks() # 为后向传播注册 reduce-scatter
outputs = self.module(*args, **kwargs) # 模型前向传播
outputs = self._register_pre_backward_hooks(outputs) # 为后向传播注册 all-gather
我们接下来一一分析。
4.3.1 _register_post_backward_hooks
_register_post_backward_hooks 是注册反向传播之后调用的hook,这里的hook 就是重新分区和reduce-scatter操作。我们解读一下其注释:
_register_post_backward_hooks 这在前向传播时被调用。目的是在每个参数的梯度生成函数(下文的
grad_acc)上附加一个钩子方法,以便在该参数的所有梯度计算出来后,调用该钩子。我们的目标是:
- 我们希望这个钩子只触发一次,而且是在该参数的所有梯度被计算之后。
- 如果它启动超过一次,我们最终会错误地将梯度分成多次。(可能导致维度太小)。
- 如果它启动一次但太早或没有启动,我们就不对梯度进行分片。(可能导致维度过大)。
由于多路前向操作,这个函数可以在一次前向传播之中对同一个参数进行多次调用。如果我们多次注册hook,此hook最终会被多次调用。我们可以尝试每次获得一个新的钩子,并删除之前注册的钩子
然而,由于未知的原因,在混合精度模式下,我们在这个函数的不同调用中(在同一个前向传播中)得到两个不同的
grad_acc对象。如果我们保留最后一个,钩子就会过早地启动。在全精度模式下,我们很幸运地得到了相同的grad_acc对象,所以删除和重新注册仍然能确保在所有梯度生成后钩子只启动一次。根据经验,每次前向传播时维持注册的第一个钩子似乎是最有效的。我们也确实需要在后向传播结束时删除钩子。否则,下一个前向传播将不会注册一个新的钩子,而这是新的前向传播所需要的。
除了注释之外,这里还有几个特殊的技巧:
- 为何在 grad_fn.next_functions [0] [0] 之上注册 hook 而非在张量 p 之上直接注册 hook?
这里比较复杂,只能简单说一下,有兴趣的读者可以自己深研究源码。
首先,AccumulateGrad 派生了 TraceableFunction,而 TraceableFunction 派生了 Node。
其次,Node 之中,有两种 hook。
std::vector<std::unique_ptr<FunctionPreHook>> pre_hooks_;
std::vector<std::unique_ptr<FunctionPostHook>> post_hooks_;
如果在张量 p 上运行 register_hook,则注册的是 p.grad_fn 之上的 pre_hooks_,此时还没有进行梯度计算,所以此时得到的梯度只是梯度函数的输入,是一个临时变量,并没有累加到实际的 grad 内存上,所以 tensor 的hook 一般是专门用来观察临时梯度的。
如果在AccumulateGrad 上运行 register_hook,则注册的是 p.grad_fn 之上的 post_hooks_,此时已经完成了梯度计算,此时才能得到梯度,p 和它的 grad 是不会释放的。
grad_fn 的 hook 是没有默认传入参数的,实现 allreduce 一般传入参数 p,p也就是这个 grad_fn 对应的变量,,所以使用 functools.partial 来构建参数。
所以,为了得到正确的梯度,应该使用 post_hook,就是在梯度函数上直接运行 register_hook。
- expand_as 的使用。
这是因为在调用 _register_post_backward_hooks 时候,还没有前向计算,所以此时 p 上的梯度函数 grad_fn 还没有生成。expand_as 的作用就是:可以生成这个梯度函数 grad_fn,而且不会产生实际梯度。
如下代码可以演示的更清楚。
a = torch.tensor(1.0, requires_grad=True)
print(a.grad_fn) # None,此时没有前向计算,所以没有梯度函数
a_temp = a.expand_as(a) # 虽然没有前向计算,但是也可以生成梯度函数,而且不产生实际梯度
print(a_temp.grad_fn) # ExpandBackward
print(a_temp.grad_fn.next_functions[0][0]) # AccumulateGrad
# 输出是:
None
<ExpandBackward object at 0x7fef9794e898>
<AccumulateGrad object at 0x7fef9794e7f0> # 就是在这里注册 hook
注:以上技巧是我从一个朋友 Huper (https://www.zhihu.com/people/huper-52/answers) 那里学习到的。
具体注册 hook 代码如下:
def _register_post_backward_hooks(self) -> None:
"""
Register backward hooks to reshard params and reduce-scatter grads.
This is called during forward pass. The goal is to attach a hook
on each of the parameter's gradient generating function (``grad_acc``
below) so that the hook is called *after* all gradients for that
param are computed.
Goals:
1. We want the hook to fire once and only once *after* all gradients
are accumulated for a param.
2. If it fires more than once, we end up incorrectly shard the grad
multiple times. (could lead to dimension too small)
3. If it fires once but too early or doesn't fire, we leave gradients
unsharded. (could lead to dimension too large)
Due to multiple-pass forward, this function can be called on
the same parameter multiple times in a single forward pass. If we register
the hook multiple time, we end up getting called multiple times. We
could try to get a new hook every time and delete the previous one
registered. However, due to *unknown reason* (I have debugged it for
a long time!), in mixed precision mode, we get two different ``grad_acc``
objects below during different calls of this function (in the same
forward pass). If we keep the last one, the hook end up firing too
early. In full precision mode, we luckily get the *same* ``grad_acc``
object, so deleting and re-registering still ensured the hook fire
once after all gradients are generated.
Empirically, keep the first hook register per forward pass seems to
work the best. We do need to remove the hook at the end of the
backward pass. Otherwise, the next forward pass will not register
a new hook, which is needed for a new forward pass.
"""
if not torch.is_grad_enabled():
return # don't register grad hooks if grad isn't enabled
for p in self.params:
if p.requires_grad:
if hasattr(p, "_shard_bwd_hook"):
continue
# Register a hook on the first call, empirically, autograd
# fires it at the end for this param, which makes sense.
p_tmp = p.expand_as(p) # Get a grad_fn on p_tmp.
assert p_tmp.grad_fn is not None
grad_acc = p_tmp.grad_fn.next_functions[0][0] # Gets its GradAccumulation object.
handle = grad_acc.register_hook(functools.partial(self._post_backward_hook, p))
p._shard_bwd_hook = (grad_acc, handle)
4.3.2 _post_backward_hook
_post_backward_hook 就是hook函数,其会注册 _post_reduction_hook 和 self._reducer.reduce_scatter_async。
在_post_backward_hook的开始,param.grad包含本地批次的全部梯度。reduce-scatter操作将把param.grad 替换为所有GPU的梯度总和的单一分片。这个分片就是当前rank对应的分片,比如:
before reduce_scatter:
param.grad (GPU #0): [1, 2, 3, 4]
param.grad (GPU #1): [5, 6, 7, 8]
after reduce_scatter:
param.grad (GPU #0): [6, 8] # 1+5, 2+6
param.grad (GPU #1): [10, 12] # 3+7, 4+8
本地GPU的optim.step负责更新params的单个分片,也对应于当前GPU的rank。这个对齐方式是由_shard_parameters_创建的,它确保本地优化器只看到相关的参数分片。
以下代码删除了部分检查功能。
@torch.no_grad()
def _post_backward_hook(self, param: Parameter, *unused: Any) -> None:
"""
At the start of :func:`_post_backward_hook`, ``param.grad`` contains the
full gradient for the local batch. The reduce-scatter op will replace
``param.grad`` with a single shard of the summed gradient across all
GPUs. This shard will align with the current GPU rank.
The local GPU's ``optim.step`` is responsible for updating a single
shard of params, also corresponding to the current GPU's rank. This
alignment is created by :func:`_shard_parameters_`, which ensures that
the local optimizer only sees the relevant parameter shard.
"""
# First hook callback will see PRE state. If we have multiple params,
# then subsequent hook callbacks will see POST state. When checkpoint
# fwd counter is used, IDLE is also possible since the pre-backward hook
# is not triggered (see ``auto_wrap_bn`` below, we have to use
# FSDP(checkpoint(conv, FSDP(bn), ...)), with reshard_after_forward=False).
self.training_state = TrainingState.BACKWARD_POST
# If this is a checkpointed module, we check if the following
# counter reaches 0. If not, it is not the final backward call
# for this module yet. Therefore, we early return in that case.
if hasattr(self._fsdp_wrapped_module, "_checkpoint_fwd_counter"):
if self._fsdp_wrapped_module._checkpoint_fwd_counter != 0:
return
if self._require_backward_grad_sync or self.reshard_after_forward:
# Free full params. As a special case, we don't free the full params
# when in a ``no_sync`` context (as inversely indicated by
# ``self._require_backward_grad_sync``), since the params will not
# get updated before the next forward. This saves networking
# bandwidth but uses more GPU memory.
self._free_full_params([param])
if self.mixed_precision:
# This is a no-op if reshard_after_forward is True, since we already
# free the param shard when rebuilding the full params in the
# pre_backward_hook.
self._free_fp16_param_shard([param])
# Switch to FP32 shard after backward.
self._use_fp32_param_shard([param])
# Wait for all work in the current stream to finish, then start the
# reductions in post_backward stream.
self._streams["post_backward"].wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(self._streams["post_backward"]):
orig_grad_data = param.grad.data
if self.mixed_precision and self.fp32_reduce_scatter:
# Cast grad to FP32.
param.grad.data = param.grad.data.to(param.dtype)
if self.gradient_predivide_factor > 1:
# Average grad by world_size for consistency with PyTorch DDP.
param.grad.data.div_(self.gradient_predivide_factor)
# 执行reduce-scatter操作
callback_fn = functools.partial(self._post_reduction_hook, param)
if param._is_sharded:
grad_chunks = chunk_and_pad(param.grad.data, self.world_size)
self._reducer.reduce_scatter_async(grad_chunks, group=self.process_group, callback_fn=callback_fn)
else:
# Currently the only way for _is_sharded to be False is if
# world_size == 1. This could be relaxed in the future, in which
# case grads should be all-reduced here.
callback_fn(param.grad.data)
# After _post_backward_hook returns, orig_grad_data will eventually
# go out of scope, at which point it could otherwise be freed for
# further reuse by the main stream while the div/reduce_scatter/copy
# are underway in the post_backward stream. See:
# github.com/NVIDIA/apex/blob/master/apex/parallel/distributed.py
orig_grad_data.record_stream(self._streams["post_backward"])
4.3.3 Reduce Scatter
ReduceScatterBucketer 用于将小张量上的多个reduce-scatter操作集中到较大的reduce-scatter操作中,以提高通信效率。异步地对张量列表进行Reduce-scatter 可以让较小的reductions可以被集中在一起操作。给定的回调(callback_fn)将在稍后的某个时间被调用,并得到规约的结果。可以调用flush()来强制执行所有排队的操作和回调。请注意,大输入将被立即规约,这个函数也可能刷新相关的桶,以便为input_list腾出空间。
class ReduceScatterBucketer:
"""
Helper for bucketing multiple reduce-scatter operations on small tensors
into larger reduce-scatter ops to improve communication efficiency.
"""
def __init__(self, bucket_cap_mb: int = 25):
self.bucket_cap_mb = bucket_cap_mb
self.buckets: Dict[Tuple[torch.dtype, torch.device, ProcessGroup], Bucket] = {}
@torch.no_grad()
def reduce_scatter_async(
self, input_list: List[Tensor], group: ProcessGroup, callback_fn: Optional[Callable] = None,
) -> None:
"""
Reduce-scatter a list of tensors asynchronously, so smaller reductions
can be bucketed together. The given callback (``callback_fn``) will be
called with the reduced result at some later time. Call ``flush()`` to
force all queued ops and callbacks to be executed.
Note that large inputs will be reduced immediately, and this function
may also flush the relevant bucket to make room for ``input_list``.
Args:
input_list (List[Tensor]): list of tensors to reduce-scatter. List
should contain ``group.size()`` tensors and each tensor should
have identical shape, dtype and device.
group (ProcessGroup): process group for reduction
callback_fn (Callable, Optional): callback function to call after
the reduction executes. Function will be called with a single
argument corresponding to the reduced result.
"""
world_size = group.size()
first_input = input_list[0]
first_input_size = first_input.numel()
bucket_shard_size = self._get_shard_size(first_input.element_size(), world_size)
if first_input_size > bucket_shard_size:
# input is too big to fit in the bucket, reduce-scatter directly
output = torch.zeros_like(input_list[0])
if hasattr(dist, "_reduce_scatter_base"):
input_flattened = torch.cat(input_list)
dist._reduce_scatter_base(output, input_flattened, group=group) # type: ignore
else:
# fallback
dist.reduce_scatter(output, input_list, group=group)
if callback_fn is not None:
callback_fn(output)
return
bucket = self._get_bucket(first_input, group)
if first_input_size > bucket.data.size(1) - bucket.offset:
# not enough space remaining in bucket, flush it now
bucket.flush()
# copy data from input_list into bucket
stacked_input = torch.stack(input_list).view(world_size, first_input_size)
offset = bucket.offset
bucket.data[:, offset : offset + first_input_size].copy_(stacked_input)
bucket.offset += first_input_size
# callback will be given the reduced result
if callback_fn is not None:
result_view = bucket.output_shard[offset : offset + first_input_size].view_as(first_input)
bucket.callbacks.append(functools.partial(callback_fn, result_view))
4.3.4 _register_pre_backward_hooks
这里注册了一个后向传播之前会调用的hook,hook 之中调用了 _rebuild_full_params,其内部会调用 all-gather。因为这个必须在最终output之上注册,所以 _register_pre_backward_hooks 是在前向传播最后部分才调用。
def _register_pre_backward_hooks(self, outputs: Any) -> Any:
"""Register pre-backward hook to run before the wrapped module's
backward. Hooks should be attached to all outputs from the forward.
Returns:
outputs: new outputs with hooks registered if they requires gradient.
"""
if not torch.is_grad_enabled():
return outputs # don't register hooks if grad isn't enabled
if self._is_root:
# This actually means that only root instance has
# _post_backward_callback_queued defined. Accidentally accessing this field
# will assert on all other instances, giving us a nice bug checker.
self._post_backward_callback_queued = False
def _pre_backward_hook(*unused: Any) -> None:
# try to queue final backward callback only once for root, so
# that final backward callback is attached to the outer most
# backward graph task and called after all the backward
# calls are completed.
if self._is_root:
self._queue_wait_for_post_backward()
if self._pre_backward_hook_has_run:
return # only run once (from multiple outputs or multiple forward passes)
self._pre_backward_hook_has_run = True
# Start of a backward pass.
self.training_state = TrainingState.BACKWARD_PRE
# All-gather full parameters.
if self.reshard_after_forward:
self._rebuild_full_params() # 这里调用 all-gather
else:
self._use_full_params()
# Prepare p.grad.
self._prep_grads_for_backward()
def _register_hook(t: torch.Tensor) -> torch.Tensor:
if t.requires_grad:
t.register_hook(_pre_backward_hook)
return t
# Attach hooks to Tensor outputs.
outputs = apply_to_tensors(_register_hook, outputs)
return outputs
运行逻辑大致如下:
+---------------------------------------------+ +--------------------------------------------------+
| forward | | backward |
| | | |
| + | | |
| | all_gather() | | ^ ^ |
| | + | | | | |
| | | | | | | |
| | | | | | | |
| | | + + | | |
| | v register | | |
| | _register_post_backward_hooks() +--------+-----+--> _post_backward_hook() +--> reduce_scatter() | |
| | | | | |
| | + | | ^ | |
| | | | | | | |
| | | | | | | |
| | v | | + | |
| | outputs = self.module(*args, **kwargs) | | compute gradient | |
| | + | | | |
| | | | | ^ | |
| | | | | | | |
| | | + + | | |
| | v register + | |
| | _register_pre_backward_hooks(outputs) +---+-----+--> _pre_backward_hook() +---> all_gather() | |
| v | | + |
| | | |
| Timeline | | Timeline |
| | | |
+---------------------------------------------+ +--------------------------------------------------+
手机如下:

至此,我们介绍了FSDP如何对模型参数分片以减少显存开销,下一篇我们看看Offload如何进一步节约显存。
0xFF 参考
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html
https://developer.nvidia.com/automatic-mixed-precision
http://bindog.github.io/blog/2020/04/12/model-parallel-with-apex/
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号