数据库中的行式存储和列式存储
背景
数据库技术发展迅速,由原来的关系型数据库到越来越丰富的非关系型数据库。如果按照存储形式分类,主要有:行式存储(Row-Based)、列式存储(Column-Based)、键值(key-value)存储、文档(doc)存储、图形(graph)存储、时序数据库等。我们常用的传统关系型数据库(MySQL、Oracle、PostgreSQL 、DB2和 SQL Server)都是采用行式存储,而最新兴起的分布式数据库很多采用列式存储,例如:Druid、Kudu、Clickhouse等。
本文将详细介绍行式存储、列式存储以及业务场景的选型和对比。
第一部分 存储基础
数据库按照存储介质,分为磁盘数据库和内存数据库。对于磁盘数据库,需要依赖于内置硬盘或外置集中式存储设备。首先我们介绍磁盘的存储原理。
1.1 磁盘存储
首先我们先介绍几个概念:
-
磁盘扇区(sector)
磁盘中每个磁道等分为若干弧段,这些弧段即称为扇区。磁盘的读写以扇区为基本单位。可以使用
fdisk -l命令来查看服务器中磁盘扇区的大小,通常是512 bytes=0.5K。为什么是这么大,这是一个行业标准(近期也有4K的扇区磁盘)。扇区是磁盘的最小存储单元。扇区是一个物理层面的概念,操作系统是不直接和扇区交互的,而是和磁盘块交互。
-
磁盘块(IO Block)
操作系统将相邻的扇区组合在一起,形成一个块,对块进行管理,通常称为磁盘块(或磁盘簇)。可以使用
stat /boot参看,一般一个磁盘块由2、4、8、16、64等个扇区组成,这是操作系统中的逻辑概念,所以可以调节。通常一个磁盘块为4096 Bytes=4K,即8个连续扇区。 -
inode操作系统中文件数据存储在磁盘块中,那么还需要有地方存储文件的元数据信息(文件的创建用户、时间信息、权限等),最重要的是文件数据所在的磁盘块地址信息。这就是
inode数据。
文件存储在磁盘中,操作系统有一定规范:
-
每个磁盘块中只能存储一个文件
例如一个文件大小为
5K,操作系统中每个磁盘块大小为4K,那么这个文件实际使用2个磁盘块进行落盘存储。 -
磁盘块是操作系统最小存储单位
例如例子中的
5K文件,存储在两个磁盘块,那么读取这个文件需要进行两次I/O操作。 -
文件的元数据信息
每个文件的数据存储在磁盘块中,
inode进行登记。如果一个磁盘块不够会申请新的磁盘块,均在inode中登记。文件读取时候,顺序读取inode中磁盘块的数据,加载至内存中。
1.2 内存存储
同样对于内存,操作系统同样定义了逻辑读取的基本单位为:页(page)。页的大小为磁盘的$2^n$倍数,可以使用命令getconf PAGE_SIZE参看。通常和磁盘块大小一致为4K。
1.3 数据库中的页
类似磁盘和内存,数据库中同样页(page)的概念,显然这是一个逻辑的概念。数据库中的数据在磁盘上以文件的形式存储,数据库的存储引擎会以固定大小的page为单位组织文件,读写磁盘也以page为单位。不同数据库page大小有差异,比如:SQLite 1KB, Oracle/DB2 4KB, SQL Server 8KB, MySQL 16KB。
第二部分 行列存储原理
磁盘数据库的内部组件组成是复杂的,我们只关注数据文件的存储方式(不同数据库系统会有复杂的处理机制)。
2.1 行式存储
数据按照行数据为基础单元进行组织存储。例如下面的二维表数据:

- 表中每一行数据用
|分割,整体存储在一个磁盘块中(图中每条行记录挤满一个磁盘块); - 表中其他记录连续写入文件分配的磁盘块中;
2.1.1 优势
- 具有随机写入优势,特别是频繁写和更新操作。对于写入的每条记录,只需要内存拼接好整行记录,一次性写入到磁盘块中,单挑记录数量年小于单个磁盘块就只需要1次IO操作。
2.1.2 短板
-
读取冗余。在查询操作中计算机是按照磁盘块为基本单位进行读取,同一个磁盘块中其他记录也需要读取。然后加载至内存,在内存中进行过滤处理。即使查询只涉及少数字段,也需要读取完整的行记录。
行存储数据会引入索引和分库分表技术来避免全量读取。
-
数据压缩。每行数据有不同类型数据,数据压缩率较低。
2.2 列式存储
数据按照列为单元进行集中存储。例如下面的二维表数据:

- 数据列
SSN的数据顺序存储在同一个磁盘块中; - 其他列同样集中顺序存储。顺序写在前列后面或单独一个文件。
2.2.1 优势
- 大量查询操作优势。对于目标查询,列存只需要返回目标列的值。而且列值在磁盘中集中存储,会减少读取磁盘块的频次,较少IO的数量。最后再内存中高效组装各列的值,最终形成查询结果。另外列式记录每一列数据类型同质,容易解析。每列存储是独立的可以并发处理,进一步提升读取效率。
- 数据压缩优势。因为各列独立存储,且数据类型已知,可以针对该列的数据类型、数据量大小等因素动态选择压缩算法,以提高物理存储利用率。如果某一行的某一列没有数据,那在列存储时,就可以不存储该列的值,这将比行式存储更节省空间。整体上减轻IO的频次。
- 映射下推(
Project PushDown)、谓词下推(Predicate PushDown)。可以减少不必要的数据扫描,尤其是表结构比较庞大的时候更加明显,由此也能够带来更好的查询性能
2.2.2 短板
-
写入更新短板。列式存储写入前需要将一条记录拆分成单列,分别追加写入到列所在的磁盘块中,如果列比较多,一条记录就会产生多次磁盘块的IO操作。对于实时的逐条写入性能会比行式弱。
但是对于大量的批写入,列可以在内存中拆分好各分列,然后集中写入,性能和行式数据比不一定差。
第三部分 业务场景适应性分析
对于列存和行存,我们在技术选型的时候应该挑选哪个?技术没有包打一切银弹,只有适应对应场景的技术。通常将数据处理分为三大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)还有混合事务/分析处理(Hybrid transaction/analytical processing)。
3.1 联机事物处理(OLTP)
联机事物处理类型通常表示事务性非常高的系统。一般都是联机在线系统,通常以小的事务和小的查询为主。评估系统性能主要看每秒执行的Transaction以及Execute SQL的数量。单个数据库每秒处理的Transaction往往超过几百个,或者是几千个,查询语句的执行量每秒几千甚至几万个。对于互联网秒杀场景要求会更改。典型的OLTP系统有银行、证券、电子商务系统等互联网在线业务系统等。
业务特点从主要有:
- 数据库视角:
- 每个事务的读、写、更改涉及的数据量非常小。
- 数据库的数据必须是最新的,所以对数据库的可用性要求很高。
- 系统使用用户较大,有海量访问。
- 要求业务处理快速响应,通常一个事务需要在秒级内完成。
- 存储视角:
- 每个I/O非常小,通常为
2KB~8KB。 - 访问硬盘数据的位置非常随机,至少30%的数据是随机写操作。
- REDO日志(重做日志文件)写入非常频繁。
- 每个I/O非常小,通常为
3.2 联机分析处理(OLAP)
联机分析处理 (OLAP) 的概念最早是由关系数据库之父E.F.Codd于1993年提出的。也称为决策支持系统,即数据仓库。该场景下语句的执行量不再是考核标准,通常一条语句的执行延迟非常长,读取的数据也是海量的。性能评估的指标变为查询的吞吐量,如能达到多少MB/s的流量。
业务特点主要有:
- 数据库视角:
- 数据更新操作少(以大批量写入为主)或没有数据更新和修改。
- 数据查询过程复杂。
- 系统用户较少,数据的使用频率逐渐减小,允许延迟。
- 查询结果以统计、聚合计算为主。
- 存储视角:
- 单个I/O数据量大(均为读),通常为MB和GB级别,甚至TB级别。
- 读取操作通常顺序读取。
- 当进行读取操作进行时,写操作的数据存放在临时表空间内。
- 对在线日志写入少。只有在批量加载数据时,写入操作增多。
3.3 混合事务/分析处理(HTAP)
HTAP 就是 OLAP 和OLTP 两种场景的结合。在对新旧数据进行 OLAP 分析的情况下增加事务的处理来对数据进行更新。实际业务场景中,往往是 OLAP、OLTP 是同时存在的(见下图)。对于HTAP系统,一种解决方案分别针对新旧数据构建两套引擎,一套负责 OLTP(热数据),一套负责 OLAP(冷数据),一个查询到达后,需要分别解析成两套查询,在两个查询引擎都得到结果后进行合并,还可能用到两阶段提交等分布式事务。
例如TiDB数据库就是一个典型的HTAP数据库。目前有两种存储节点,分别是 TiKV 和 TiFlash。TiKV 采用了行式存储,更适合 TP(OLTP) 类型的业务;而 TiFlash 采用列式存储,擅长 AP(OLAP) 类型的业务。TiFlash 通过 raft 协议从 TiKV 节点实时同步数据,拥有毫秒级别的延迟,以及非常优秀的数据分析性能。它支持实时同步 TiKV 的数据更新,以及支持在线 DDL。把 TiFlash 作为 Raft Learner 融合进 TiDB 的 raft 体系,将两种节点整合在一个数据库集群中,上层统一通过 TiDB 节点查询,使得 TiDB 成为一款真正的 HTAP 数据库。
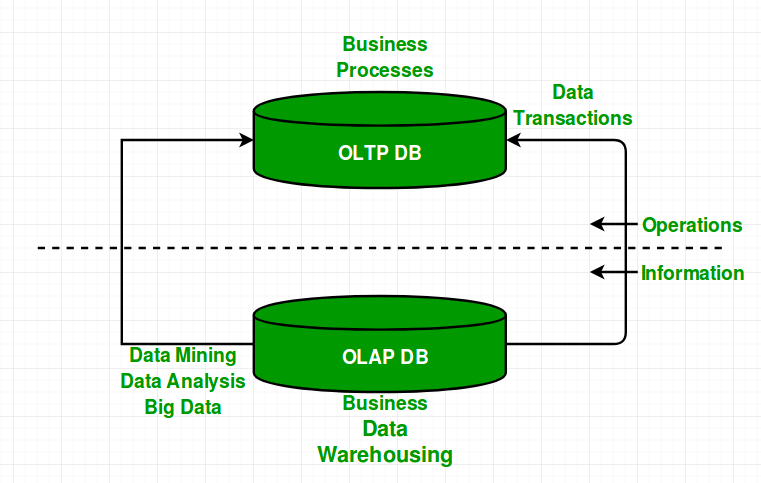
3.4 选型
通过上文的介绍, 联机事物处理(OLTP)、联机分析处理(OLAP)分别适合于行式存储、列式存储数据库。实际选型时,在时间允许的前提下,需要深入了解业务场景的特点,进行场景模拟测试后,根据评测结果最终选择合适的数据库。例如在联机分析处理场景中,如果大量的查询是读取的记录中的大多数或所有字段,主要由单条记录查询和范围扫描组成,则面向行的存储布局的数据库会更适合。
第四部分 总结
在过去几年中,由于对不断增长的数据集和运行复杂分析查询的需求不断增长,产生许多新的面向列的文件格式,如Apache Parquet、Apache ORC、RCFile,以及面向列的存储,如Apache Kudu、ClickHouse,以及许多其他列式数据存储组件。
对于列式存储和行式存储存在的短板,在实际数据系统会有很多巧妙设计去弥补。例如行式存储数据库的索引、分库分表、读写分离等功能加入,大大提升了读写性能。而列式存储在面对数据更新短板,数据库设置缓存池(WAL机制解析),积累一定量更新操作后批量提交执行;对于删除操作,采用先标记后删除方式等设计来提升性能。
随着列式数据库的发展,很多传统的行式数据库也加入了列式存储的支持,形成具有两种存储方式的数据库系统。例如,Oracle在12c版本中推出了in memory组件,使得Oracle数据库具有了双模式数据存放方式。还有新兴数据库TiDB也同时支持行列两种存储模式,从而能够实现对混合类型应用的支持。
总之,技术没有包打一切的银弹,只有适合相应场景的技术,要学会tradeoff。
参考文献及资料
1、TiDB项目地址,链接:https://github.com/pingcap/tidb
2、《数据库系统实现》,[美] 加西亚·莫利纳 等 著,杨冬青 等 译
3、《深入理解计算机系统》,作者: Randal E.Bryant / David O'Hallaron
更多关注公众号:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号