机器学习第一次作业
知识图谱
介绍
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。知识图谱,本质上,是一种揭示实体之间关系的语义网络。知识图谱是由一条条知识组成,每条知识表示为一个SPO三元组(Subject-Predicate-Object)。
通俗的说知识图谱主要目标是用来描述真实世界中存在的各种实体和概念,以及他们之间的强关系,我们用关系去描述两个实体之间的关联,例如姚明和火箭队之间的关系,他们的属性,我们就用“属性--值对“来刻画它的内在特性,比如说我们的人物,他有年龄、身高、体重属性。知识图谱可以通过人为构建与定义,去描述各种概念之间的弱关系,例如:“忘了订单号”和“找回订单号”之间的关系。
知识图谱从语义角度出发,通过描述客观世界中概念、实体及其关系,从而让计算机具备更好地组织、管理和理解互联网上海量信息的能力。更具体的说,在人类与互联网世界交互的过程中,产生了繁杂庞大的信息,这些信息一般被图片声音文字视频这些数据载体保存。我们希望计算机可以分析阅读理解这些数据,精准挖掘找到数据背后隐藏的有价值的知识,在用户需要的时候提供知识服务。
应用
智能搜索
用户的查询输入后,搜索引擎不仅仅去寻找关键词,而是首先进行语义的理解。比如,对查询分词之后,对查询的描述进行归一化,从而能够与知识库进行匹配。查询的返回结果,是搜索引擎在知识库中检索相应的实体之后,给出的完整知识体系。
深度问答
能够以准确简洁的自然语言为用户提供问题的解答。多数问答系统更倾向于将给定的问题分解为多个小的问题,然后逐一去知识库中抽取匹配的答案,并自动检测其在时间与空间上的吻合度等,最后将答案进行合并,以直观的方式展现给用户。eg:苹果智能手机助手Siri
社交网络
Facebook于 2013 年推出了 Graph Search 产品,其核心技术就是通过知识图谱将人、地点、事情等联系在一起,并以直观的方式支持精确的自然语言查询,例如输入查询式:“我朋友喜欢的餐厅”“住在纽约并且喜欢篮球和中国电影的朋友”等,知识图谱会帮助用户在庞大的社交网络中找到与自己最具相关性的人、照片、地点和兴趣等。Graph Search 提供的上述服务贴近个人的生活,满足了用户发现知识以及寻找最具相关性的人的需求。
垂直行业应用
从领域上来说,知识图谱通常分为通用知识图谱和特定领域知识图谱。在金融、医疗、电商等很多垂直领域,知识图谱正在带来更好的领域知识、更低金融风险、更完美的购物体验。更多的,如教育科研行业、图书馆、证券业、生物医疗以及需要进行大数据分析的一些行业。这些行业对整合性和关联性的资源需求迫切,知识图谱可以为其提供更加精确规范的行业数据以及丰富的表达,帮助用户更加便捷地获取行业知识。
关键技术
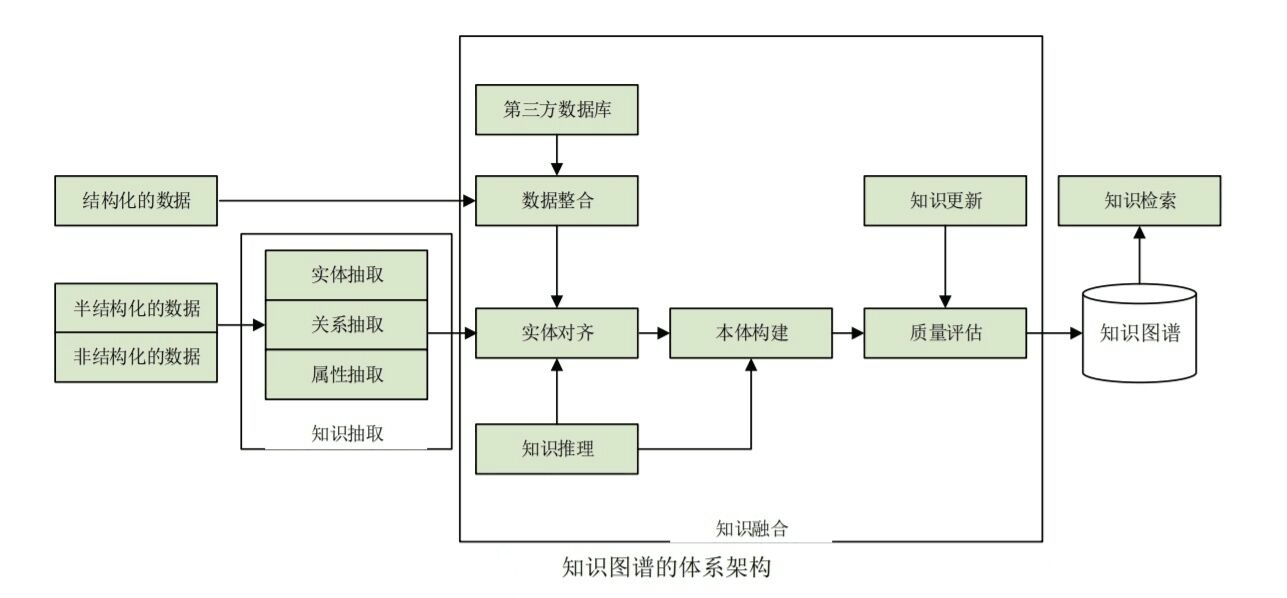
知识抽取
-
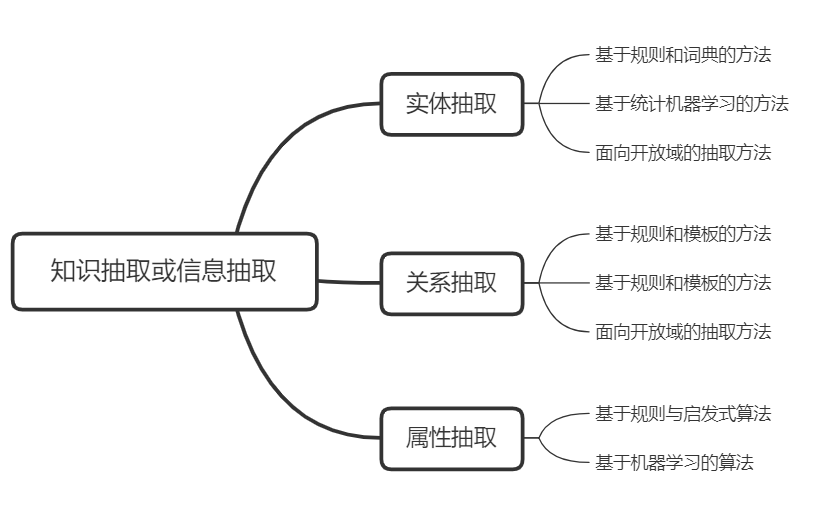
实体抽取
在技术上我们更多称为 NER(named entity recognition,命名实体识别),指的是从原始语料中自动识别出命名实体。由于实体是知识图谱中的最基本元素,其抽取的完整性、准确、召回率等将直接影响到知识库的质量。因此,实体抽取是知识抽取中最为基础与关键的一步;
-
关系抽取
目标是解决实体间语义链接的问题,早期的关系抽取主要是通过人工构造语义规则以及模板的方法识别实体关系。随后,实体间的关系模型逐渐替代了人工预定义的语法与规则。
-
属性抽取
属性抽取主要是针对实体而言的,通过属性可形成对实体的完整勾画。由于实体的属性可以看成是实体与属性值之间的一种名称性关系,因此可以将实体属性的抽取问题转换为关系抽取问题。
知识融合
-
实体连接
实体消岐–专门用于解决同名实体产生歧义问题的技术。实体消岐主要采用聚类的方法,聚类法消歧的关键问题是如何定义实体对象与指称项之间的相似度,常用的方法有:《1》空间向量模型《2》语义模型《3》社会网络模型《4》百科知识模型
实体对齐–主要用于消除异构数据中实体冲突、指向不明等不一致性问题,可以从顶层创建一个大规模的统一知识库,从而帮助机器理解多源异质的数据,形成高质量的知识库。对齐算法可以分为成对实体对齐和集体实体对齐,而集体实体对齐又可以分为局部集体实体对齐和全局集体实体对齐。
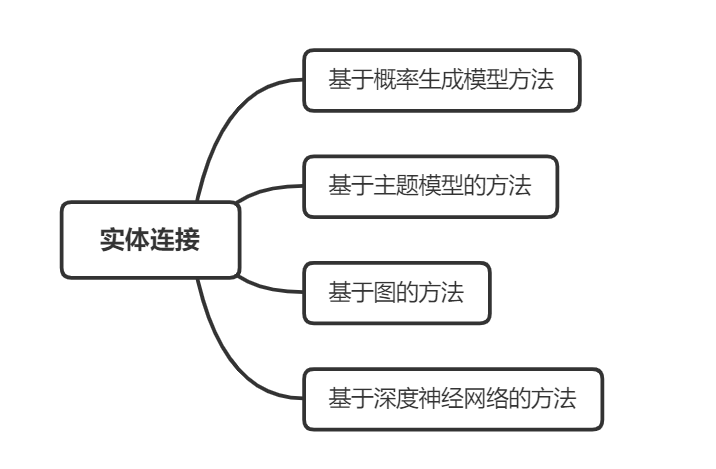
实体连接技术可以从整体层面分类如图:
-
知识合并
合并外部知识库—将外部知识库融合到本地知识库需要处理2个层面的问题。《1》数据层的融合,包括实体的指称、属性、关系以及所属类别等,主要的问题是如何避免实例以及关系的冲突问题,造成不必要的冗余。《2》通过模式层的融合,将新得到的本体融入已有的本体库中。
-
知识加工
知识推理—知识推理是指从知识库中已有的实体关系数据出发,经过计算机推理,建立实体间的新关联,从而拓展和丰富知识网络,知识推理是知识图谱构建的重要手段和关键环节,通过知识推理,能够从现有知识中发现新的知识。
质量评估—对知识库的质量评估任务通常是与实体对齐任务一起进行的,其意义在于,可以对知识的可信度进行量化,保留置信度较高的,舍弃置信度较低的,有效保证知识的质量。

-
知识更新
人类所拥有信息和知识量都是时间的单调递增的函数,因此知识图谱的内容也需要与时俱进,其构建过程是一个不断迭代更新的过程。知识图谱内容的更新有两种方式:数据驱动下的全面更新和增量更新。
-
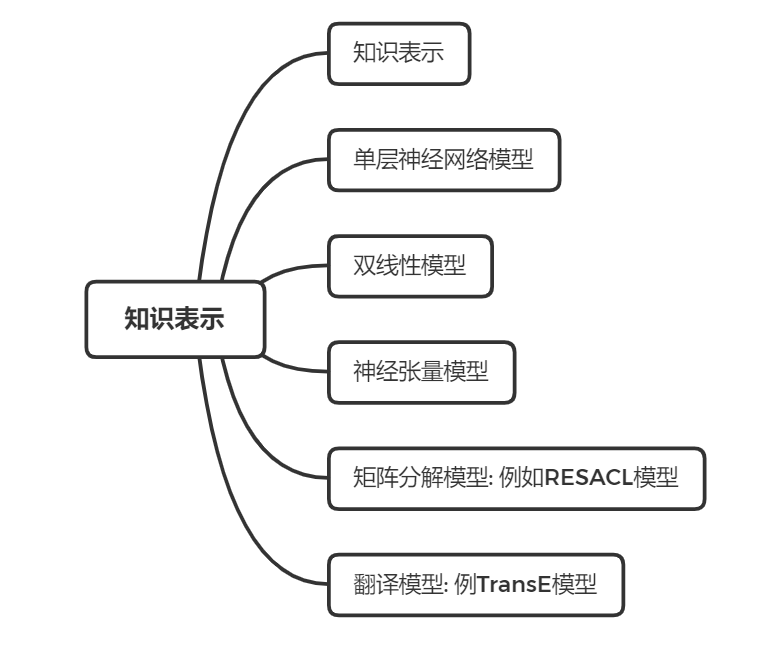
知识表示
虽然三元组的知识表示形式受到了人们的广泛认可,但是其在计算效率、数据稀疏性等方面却面临着诸多问题。近年来,以深度学习为代表的学习技术取得了重要的进展,可以将实体的语义信息表示为稠密低维的实值向量,进而在低维空间中高效计算实体、关系及其之间的复杂语义关联,对知识库的构建、推理、融合以及应用均具有重要的意义。
展望
知识图谱肯定不是人工智能的最终答案,但知识图谱这种综合各项计算机技术的应用方向,一定是人工智能未来的形式之一。在未来的几年时间内,知识图谱毫无疑问将是人工智能的前沿研究问题。知识图谱的重要性不仅在于它是一个全局知识库,更是支撑智能搜索和深度问答等智能应用的基础,而且在于它是一把钥匙,能够打开人类的知识宝库,为许多相关学科领域开启新的发展机会。从这个意义上来看,知识图谱不仅是一项技术,更是一项战略资产。
我国先进和不足(卡脖子技术)
知识抽取
一些传统的知识元素(实体、关系、属性)抽取技术与方法,它们在限定领域、主题的数据集上获得了较好的效果,但由于制约条件较多,算法准确性和召回率低,方法的可扩展能力不够强,未能很好地适应大规模、领域独立、高效的开放式信息抽取要求。
知识表示
目前存在的表示方式仍是基于三元组形式完成的语义映射,在面对复杂的知识类型、多源融合的信息时,其表达能力仍然有限。因此有研究者提出,应针对不同的应用场景设计不同的知识表示方法。
知识加工
知识加工是最具特色的知识图谱技术,同时也是该领域最大的挑战之所在。主要的研究问题包括:本体的自动构建、知识推理技术、知识质量评估手段以及推理技术的应用。目前,本体构建问题的研究焦点是聚类问题,对知识质量评估问题的研究则主要关注建立完善的质量评估技术标准和指标体系。知识推理的方法和应用研究是当前该领域最为困难,同时也是最为吸引人的问题,需要突破现有技术和思维方式的限制,知识推理技术的创新也将对知识图谱的应用产生深远影响
知识更新
在知识更新环节, 增量更新技术是未来的发展方向,然而现有的知识更新技术严重依赖人工干预。可以预见随着知识图谱的不断积累,依靠人工制定更新规则和逐条检视的旧模式将会逐步降低比重,自动化程度将不断提高,如何确保自动化更新的有效性,也是该领域面临的又一重大挑战。
从工业界来说,阿里和美团目前都在大力推进知识图谱+推荐系统的结合,知识图谱在大规模推荐系统中的应用场景非常广阔。从学术界来说,知识图谱+推荐系统其实做的还不多,方法也基本都是统计学习那一套,还是类似于黑盒模型。从推理的角度来做知识图谱+推荐系统,无论是学术上还是实际部署中,都是一个非常有前景的方向。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号