模块与包
模块
定义:一系列功能的集合体。
模块的三种来源:
- 内置模块
- 第三方模块
- 自定义模块
模块的四种格式:
- 使用python编写的.py文件
- 已被编译为共享库或DLL的C或C++扩展
- 把一系列模块组织到一起的文件夹(文件夹下有一个__init__.py的文件,该文件夹称之为包)
- 使用C编写并连接到python解释器的内置模块
为什么要使用模块:
- 使用第三方或内置模块:可以加快开发效率
- 使用自定义的模块:可以减少代码冗余(抽取我们自己程序中要共用的一些功能定义为模块,然后程序的各部分组件都可以去模块中调用共享的功能)
如何使用模块:
大的前提是:要区分开哪个是执行文件,哪个是被导入的模块
例如:文件名是spam.py,模块名就是spam
首次导入模块时:
- 会产生一个模块的名称空间
- 执行模块文件,将执行过程中产生的名字都放到模块的名称空间中
- 在当前执行文件的名称空间中拿到一个模块名,该名字指向模块的名称空间
在之后再次导入模块时,都是直接引用第一次导入的结果,不会重新执行文件
模块之import:
在执行文件中使用模块的语法:模块名.功能名字
例如:从spam模块中导入一个read功能
在执行文件中使用时spam.read就可以
# 可以在一行导入多个模块 import os,sys,.... #(不推荐使用) # 可以为模块起别名(使用import...as...) import spam as sm
import 总结:
- 优点:指名道姓的向某一个名称空间要名字,不会与当前名称空间中的名字冲突
- 缺点:只要使用模块中的名字时都要加前缀,不简洁
模块之from....import....
# 可以在一行导入多个模块 from spam import read1, read2,..... # *代表从被导入模块中拿到所有名字(不推荐使用) from spam import * # 可以为模块起别名(使用from...import...as...) from spam import read as rd
from....import....总结:
- 优点:使用时无需加前缀,更加简洁
- 缺点:容易与当前执行文件中的名字冲突
包
定义:含有__init__.py的文件夹,本质就是一种模块
为什么用包:
包是被用来被导入的,包内的模块(文件)也都是被用来带入使用的
首次导入包:
- 以包下的__init__.py文件为基准产生一个名称空间
- 执行包下的__init__.py文件的代码,将执行过程中产生的名字都存到名称空间中
- 在当前执行文件中拿到一个名字,该名字就是指向__init__.py名称空间的
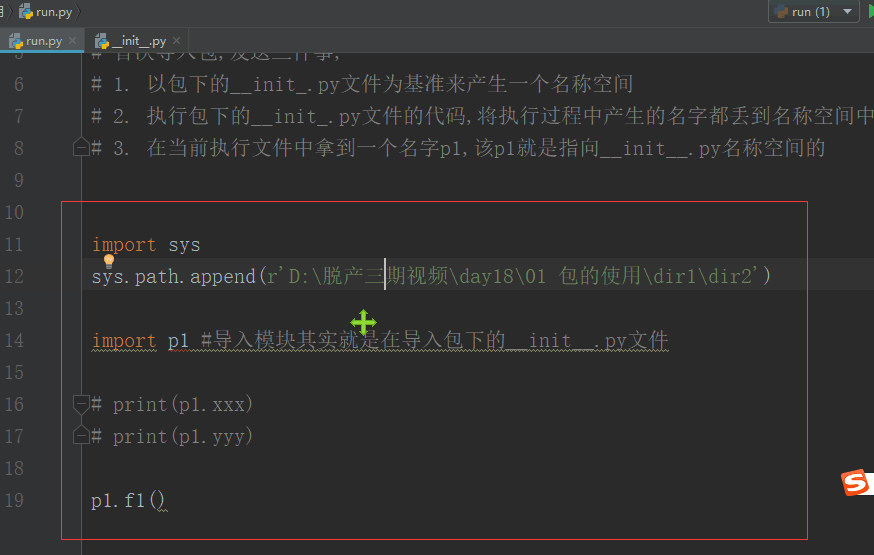
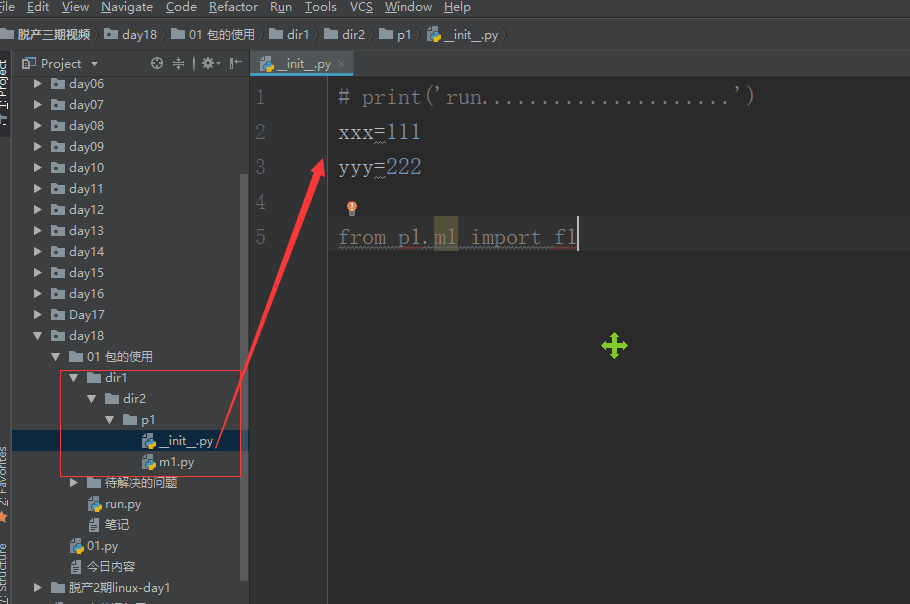
所以,导入包的本质就是在导入包内的__init__.py文件
导入包需要注意的问题:
- 只要再导入语句中带点的,点的左边都必须是一个包
- 导包时用绝对导入,以包的顶级目录为基准
- 包内模块的导入通常用相对导入,用.代表当前的所在文件(非执行文件),..代表上一级
- 相对导入只能在包内部的模块之间相互导入使用(解决修改包的名称的问题),..上一级不能超出顶级包
区分py文件的两种用途
首先,我们编写好的py文件应该有两种用途:
- 文件就是整个程序,可以当做脚本直接被执行
- 文件中存放着一些功能,当做模块被导入使用
为了区分它们,python内置了一个全局变量,__name__
- 当文件被当做脚本执行时:__name__就等于'__main__'
- 当文件被当做模块导入时:__name__就等于 模块名
作用:用来控制.py文件在不同场景中执行不同的逻辑
if __name__ == '__main__':
pass
通俗的理解__name__ == '__main__':假如你叫 小明.py,在朋友(执行文件)眼中,你是小明(__name__ == '小明');在你自己(模块自身)眼中,你是你自己(__name__ == '__main__')。
常用模块
time模块


1 import time 2 3 # 一、三种格式: 4 # 1. 时间戳(获取当前秒数) 5 # 从1970年1月1日(计算机元年)到现在的秒数 6 time.time() 7 8 # 2. 格式化的字符串时间 9 print(time.strftime('%Y-%m-%d %X')) 10 print(time.strftime('%Y-%m-%d %H:%M:%S %p')) # 2018-08-09 19:57:45 PM 11 12 # 3. 时间对象(结构化时间) 13 t = time.localtime() # 当地时间 14 print(t) 15 print(t.tm_min) 16 print(t.tm_mday) 17 18 t1 = time.gmtime() # 世界标准时间 19 20 21 # 二、时间转换 22 # 1. 时间戳 --> 结构化时间 23 print(time.localtime(111111112)) 24 print(time.gmtime(111111112)) 25 26 # 2. 结构化时间 --> 时间戳 27 print(time.mktime(time.localtime())) 28 29 30 # 3. 结构化时间 --> 格式化字符串时间 31 print(time.strftime('%Y',time.localtime())) # 只取出年 2018 32 33 # 4. 格式化字符串时间 --> 结构化时间 34 print(time.strptime('2011-03-07','%Y-%m-%d')) 35 36 37 # 5. 结构化时间 --> %a %b %d %H %M %S %Y 38 print(time.asctime(time.localtime())) # Thu Aug 9 19:57:45 2018 39 40 # 5. 时间戳 --> %a %b %d %H %M %S %Y 41 print(time.ctime(12122121)) # Thu May 21 15:15:21 1970
datetime模块
1 import datetime 2 3 # 获取当前时间 4 print(datetime.datetime.now()) 5 6 # 将时间戳转换成格式化时间 7 print(datetime.datetime.fromtimestamp(1111111)) 8 9 # 获取未来或以前的时间 10 print(datetime.datetime.now()+datetime.timedelta(days=3)) 11 12 # 可以单独指定当前时间的年、月、日。。。 13 tm = datetime.datetime.now() 14 print(tm.replace(year=2020))
random模块
import random # 不用参数 print(random.random()) # 大于0 且 小于1之间的小数 # 取随机整数,包括最小、最大值 print(random.randint(1,4)) # 大于等于1且小于等于4之间的整数 # 顾头不顾尾 print(random.randrange(1,3)) # 大于等于1且小于3之间的整数 # 任选其一 print(random.choice([1,'2',[4,5]])) # 1或者2或者[4,5] # 取任意小数,取不到最大最小 print(random.uniform(1,3)) # 大于1小于3的小数 # 取任意两个元素的组合 print(random.sample([1,'3',[4,5]],2)) # 列表元素任意2个组合 l=[1,5,3,9,-3] random.shuffle(l) # 打乱 l 的顺序,相当于"洗牌" print(l)
os模块
json模块 & pickle模块
序列化:
将内存中的数据结构转换成一种中间格式储存到硬盘或者基于网络传输
反序列化:
硬盘中或者基于网络传来的一种数据格式转换成内存中的数据结构
为什么要有序列化
- 可以保存程序的运行状态
- 数据的跨平台交互
想要在不同的编程语言之间传递对象,就必须把对象序列化为标准的中间格式
1. json: json的格式化: dump(数据类型、文件对象) dumps(数据类型) json的反序列化: load(文件对象) loads(json格式的字符串) 转换格式 内存中的数据--->json格式--->字符串--->存到文件或网络传输 总结: 优点:跨平台性强 缺点:只能支持/对应部分python的部分数据类型 2. pickle: pickle的格式化: dump(数据类型、文件对象) dumps(数据类型) pickle的反序列化: load(文件对象) loads(bytes类型) 转换格式: 内存中的数据--->pickle格式--->bytes--->存到文件或网络传输 总结: 优点:能支持/对应全部的python数据类型 缺点:只能被python识别,不能跨平台
# 序列化
json_str = json.dumps({'name': 'jack', 'age': 22}) # {"name": "jack", "age": 22}
# 反序列化
json.loads(json_str) # {'name': 'jack', 'age': 22}
# 序列化
pickle_str = pickle.dumps({'name': 'jack', 'age': 22}) # b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x04\x00\x00\x00jackq\x02X\x03\x00\x00\x00ageq\x03K\x16u.'
# 反序列化
pickle.loads(pickle_str) # {'name': 'jack', 'age': 22}
logging模块
1 # 日志等级 2 logging.debug() # 10 3 logging.info() # 20 4 logging.warning() # 30 5 logging.error() # 40 6 logging.critical() # 50 7 8 9 # logger对象:负责产生各种级别的日志 10 log = logging.getLogger('name') # name 用来表示日志与什么业务有关 11 log.info() 12 log.error() 13 .... 14 15 # filter对象:过滤日志 16 17 18 # handler对象:控制输出的目标 19 s = logging.FileHandler('文件') 20 s1 = logging.StreamHandler() # 终端 21 22 # formatter对象:日志格式 23 logging.Formatter() 24 25 # 绑定logger与handler 26 log.addHandler(s) 27 log.addHandler(s1) 28 29 # 绑定formatter与handler 30 s.setFormatter(formatter) 31 32 # logger产生日志 33 log.info('aaa')
1 # 定义日志输出格式 2 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ 3 '[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字 4 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' 5 6 id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' 7 8 9 # 如果不存在定义的日志目录就创建一个 10 if not os.path.isdir(BASE_LOG): 11 os.mkdir(BASE_LOG) 12 13 # log文件的全路径 14 logfile_path = os.path.join(BASE_LOG, 'log.log') 15 16 # log配置字典 17 LOGGING_DIC = { 18 'version': 1, 19 'disable_existing_loggers': False, 20 'formatters': { 21 'standard': { 22 'format': standard_format 23 }, 24 'simple': { 25 'format': simple_format 26 }, 27 }, 28 'filters': {}, 29 'handlers': { 30 # 打印到终端的日志 31 'console': { 32 'level': 'DEBUG', 33 'class': 'logging.StreamHandler', # 打印到屏幕 34 'formatter': 'simple' 35 }, 36 # 打印到文件的日志,收集info及以上的日志 37 'default': { 38 'level': 'DEBUG', 39 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 40 'formatter': 'standard', 41 'filename': logfile_path, # 日志文件 42 'maxBytes': 1024 * 1024 * 5, # 日志大小 5M 43 'backupCount': 5, 44 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 45 }, 46 47 }, 48 'loggers': { 49 # logging.getLogger(__name__)拿到的logger配置 50 '': { 51 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 52 'level': 'INFO', 53 'propagate': True, # 向上(更高level的logger)传递 54 }, 55 }, 56 }
hash模块
定义:hash 就是一种算法,接收传入的内容,经过运算得到一串由字母数字组成的hash值
类似于一座工厂,传入原材料,然后产出产品
hash的三大特性:
- 输入的内容一样,得到的hash值也必然一样(不管分开多少次updata)
- 只要使用的hash算法相同,不管输入的内容有多大,得到的hash值的长度固定不变
- 用hash值得到的结果不可能反推出原来的内容
所以:
- 基于1和3可以用来给密码进行加密处理
- 基于1和2可以对文件进行一致性校验
import hashlib # 方法一、 # 1. 造出一个hash工厂 m = hashlib.md5() # 2. 给工厂运送原材料 m.update('hello_baby'.encode('utf-8')) # 必须是bytes类型 m.update('love_you'.encode('utf-8')) # 3. 产出产品 print(m.hexdigest()) # 43a09074cc658f190d053f223dcb4497 # 方法二、 # 1. 造出一个hash工厂 m = hashlib.md5('hello_baby'.encode('utf-8')) # 2. 给工厂运送原材料 m.update('love_you'.encode('utf-8')) # 3. 产出产品 print(m.hexdigest()) # 43a09074cc658f190d053f223dcb4497
# 一、文件校验 m = hashlib.md5() with open('test.txt','rb') as f: for line in f: m.update(line) print(m.hexdigest()) # 二、密码加密 password = input('>>:').strip() m = hashlib.md5() m.update(password.encode('utf-8')) print(m.hexdigest()) # 密码加盐处理思想,可以在用户输入的密码中加入其他的字符,例如: password = input('>>:').strip() m = hashlib.md5() m.update('天王盖地虎'.encode('utf-8')) # 进行加盐处理 m.update(password.encode('utf-8')) print(m.hexdigest())
# hmac 模块,用于强制性的加盐处理
import hmac
m = hmac.new('宝塔镇河妖'.encode('utf-8')) # new(必须要传入位置参数)
m.update('abc154728'.encode('utf-8'))
print(m.hexdigest())
xml模块
序列化与反序列化的一种最早方式,比json复杂
xml的格式,就是通过<>节点来区别数据结构的
如何操作XML(查找方式)
# print(root.iter('y')) #全文搜索,找到所有,是一个迭代器形式
# print(root.find('y')) #在root的子节点找,只找一个,找不到返回None
# print(root.findall('y')) #在root的子节点找,找所有
对于任何标签都有三个属性:标签名、属性、文本
print(root.tag)
print(root.attrib)
print(root.text)
# 遍历整个文档(查)
for x in root.iter('yyy'): # 不写.iter默认就是查找当前节点下的子节点
print(x.tag)
print(x.attrib)
print(x.text)
for item in x:
print(item.tag)
print(item.attrib)
print(item.text)
re模块
正则:
就是用一些特殊的符号组合在一起(正则表达式)来描述字符串(一类事物)的方法\规则。
(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
正则匹配
import re
msg = ('c+c d\nc a3c\ta/c _-*b')
print(re.findall('c', msg)) # 查找全部,不加re符号,就是普通的查找
# \w & \W
print(re.findall('\w', msg)) # 只匹配字母、数字、下划线
print(re.findall('\W', msg)) # 只匹配非字母、数字、下划线
# \s & \S
print(re.findall('\s', msg)) # 匹配任意空白字符,包括换行符(\n)和制表符(\t)
print(re.findall('\S', msg)) # 匹配任意非空白字符
# \d & \D
print(re.findall('\d', msg)) # 匹配任意数字
print(re.findall('\D', msg)) # 匹配任意非数字
# ^ & $
print(re.findall('^c', msg)) # 匹配字符串开头
print(re.findall('b$', msg)) # 匹配字符串末尾
重复匹配
import re
l = ('abc d\nc a3c\ta/c a-c')
# . 匹配任意字符,除了换行符
print(re.findall('.', l))
print(re.findall('a.c', l))
# [] 匹配一个字符,该字符属于中括号内指定的字符
print(re.findall('a[a-z]c', l)) # ['abc']
print(re.findall('a[-]c', l))
# 注意点1:运算符号混用时,减号要进行转义或者放到两端
print(re.findall('a[-+/*]c', l))
# 注意点2:^符号放在[]内代表取反
print(re.findall('a[^a-z]c', l)) # ['a3c', 'a/c', 'a-c']
# * 必须与其他字符连用,代表左侧的字符出现0次或无穷次
print(re.findall('ab*', 'a ab abb abbbb abbbbl albbb a-1234')) # 匹配0个或无数个
print(re.findall('ab{0,}', 'a ab abb abbbb abbbbl albbb a-1234'))
# + 必须与其他字符连用,代表左侧的字符出现1次或无数次
print(re.findall('ab+', 'a ab abb abbbb abbbbbbl albbb a-1234')) # 匹配1个或无数个
print(re.findall('ab{1,}', 'a ab abb abbbb abbbbbbl albbb a-1234'))
# ?必须与其他字符连用,代表左侧的字符出现0次或1次
print(re.findall('ab?', 'a ab abb abbbb abbbbbbl albbb a-1234')) # 匹配0个或1个
print(re.findall('ab{0,1}', 'a ab abb abbbb abbbbbbl albbb a-1234'))
# {n,m} 必须与其他字符连用,最小到最大,可以取代 *、+、?
print(re.findall('ab{1,3}', 'a ab abb abbbb abbbbbbl albbb a-1234')) # ['ab', 'abb', 'abbb', 'abbb']
1 # 非贪婪匹配:(.*?) () 分组,只取()内(组内)的 2 print(re.findall('href="(.*?)"', '<nihaoan><href="http//:www.hao.com"><biaoyi a><href="http//:www.taobao.com">')) 3 # ['http//:www.hao.com', 'http//:www.taobao.com'] 4 5 6 # 贪婪匹配:(.*)任意字符匹配无数次 7 print(re.findall('a.*b', 'a1b222b22222b')) # ['a1b222b22222b'] 8 9 # | 或者的意思,连接左右两个表达式,成功一个就行 10 print(re.findall('a|b', 'assddbqwqhasabba12ba5s')) 11 12 # ?: 可以取消()的分组功能 13 print(re.findall('compan(?:ies|y)', 'Too many companies have gone bankrupt, and the next one is my company')) 14 15 # \ 有转义的作用 16 # re模块的工作过程是先由python解释器识别字符,然后再交给re模块识别 17 print(re.findall(r's\\c', 's\c,s|c,sac,s=c')) # ['s\\c'] 18 print(re.findall('s\\\c', 's\c,s|c,sac,s=c')) # ['s\\c']
常用方法
import re
# re.findall() # 从左往右找到所有,放到列表当中
print(re.findall('abc','SB is abc,abc are niubi')) # ['abc', 'abc']
# re.search() 从左往右只找一个,查看时要加.group(),并且没有加括号分组的作用
print(re.search('ab(c)','SB is abc').group()) # abc
print(re.findall('ab(c)','SB is abc')) # ['c']
# 注意点:查找不存在时返回None,不会报错,但是不能用group查看返回的内容否则报错
# print(re.search('ssss','SB is abc').group()) # AttributeError: 'NoneType' object has no attribute 'group'
# re.match() 只匹配开头的字符,相当于search前加^号,查看时要加.group()
# 查找不存在时返回None,不会报错,但是不能用group查看返回的内容否则报错
print(re.match('abc','abc is SB is abc')) # <_sre.SRE_Match object; span=(0, 3), match='abc'>
print(re.match('abc','SB is abc')) # None
# split 切分,更加灵活,可以用|或者[]连接多个切分符号
ll = re.split(':','abc:18:man') # ['abc', '18', 'man']
print(ll)
l2 = re.split('[: /]','abc:18:man dsb/niu') # ['abc', '18', 'man', 'dsb', 'niu']
print(l2)
l3 = re.split(':| |/','abc:18:man dsb/niu')
print(l3)
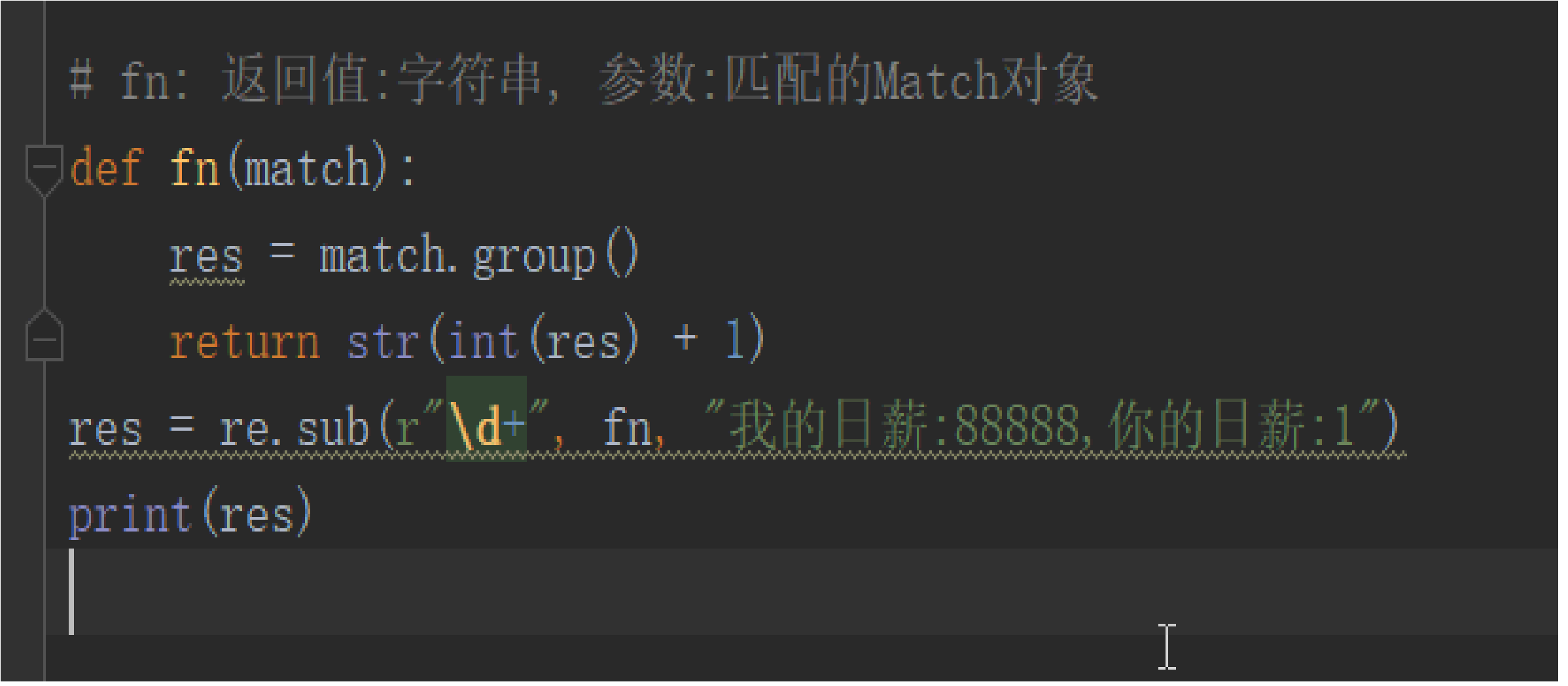
# re.sub 替换
# re.sub('原目标(可以用re表达式)','新目标','被操作的字符串','替换的个数')
print(re.sub('abc','aaa','abc are so good,love abc')) # aaa are so good,love aaa
print(re.sub('abc','aaa','abc are so good,love abc',1)) # aaa are so good,love abc
# re.compile() 将re表达式赋值给一个变量名,可以重复使用
pattern = re.compile('abc')
print(pattern.findall('abc is SB are abc'))
print(pattern.search('abc is SB are abc'))
print(pattern.match('ab is SB are abc'))
subprocess模块
进程:一个正在运行的程序
子进程:在父进程运行的过程中在其内部又开启了一个进程,即子进程。
之前学过的os.system也可以获取当前的进程信息,但是它只能打印到屏幕,而无法进行其他操作,有局限性!
import os
os.system('tasklist')
目前只是简单的了解!!!
import subprocess
# shell 命令解释器
# PIPE 管道,用于进程与进程之间的通信
obj = subprocess.Popen('tasklist',
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
# 正确的命令
stdout_res = obj.stdout.read()
print(stdout_res) # 得到的是bytes类型,用gbk解码
print(stdout_res.decode('gbk'))
# 错误的命令
stderr_res = obj.stderr.read()
print(stderr_res.decode('gbk'))
其他模块
glob模块
本文来自博客园,仅供参考学习,如有不当之处还望不吝赐教,不胜感激!转载请注明原文链接:https://www.cnblogs.com/rong-z/articles/9437317.html
作者:cnblogs用户
 浙公网安备 33010602011771号
浙公网安备 33010602011771号