wordcountExtend第三次作业
---恢复内容开始---
合作者:201631062206,201631062231
代码地址:https://gitee.com/ronanly/wordcountExtend/tree/master
作业地址:https://edu.cnblogs.com/campus/xnsy/2018softwaretest2398/homework/2187
一.代码互审:
俩人因为写的代码语言都不一样,最后都同意用python来写,方便易懂。我负责代码运行部分,另一队友主要负责测试和运行。
在运行过程中发现如下问题:
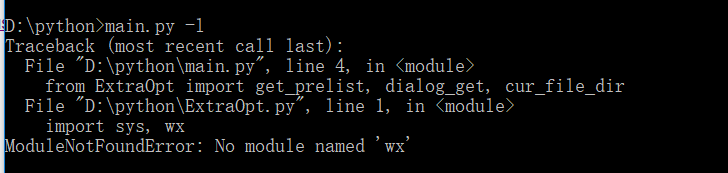
后经修改,发现是写代码途中,大意忘装wxpython这个第三方库了。解决方案如下:
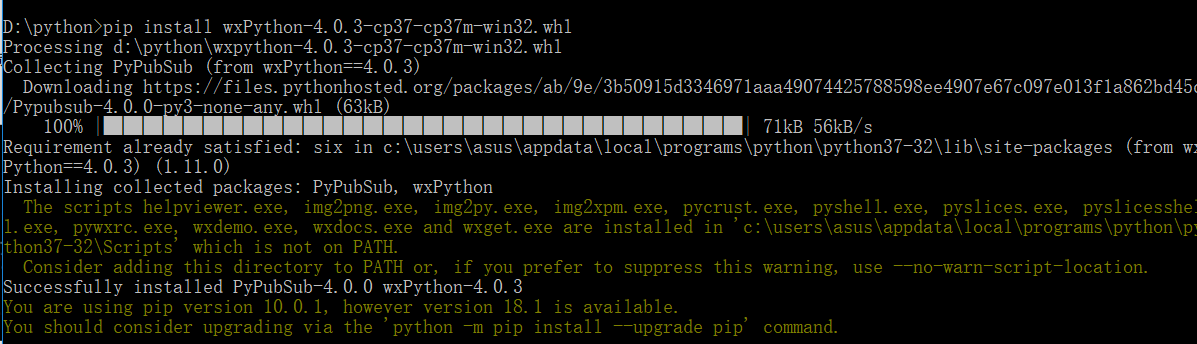

这问题后发现代码中存在非法字符,认真检查后已无碍。

二.实现扩展功能
(1)在实现原来基础功能的代码上增加了扩展功能:
wc.exe -s //递归处理目录下符合条件的文件
wc.exe -a file.c //返回更复杂的数据(代码行 / 空行 / 注释行)
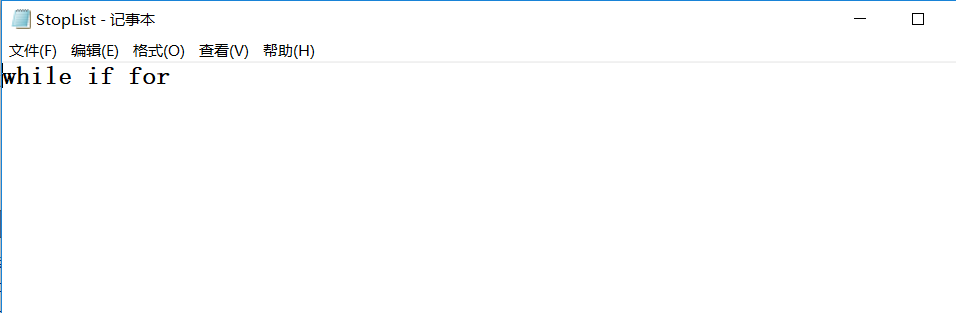
wc.exe -e stopList.txt // 停用词表,统计文件单词总数时,不统计该表中的单词
[file_name]: 文件或目录名,可以处理一般通配符。
(2)代码中分为3个模块:FileInfo.py (基本扩展功能模块), DirInfo.py (创建列表模块) main.py(主函数模块)

(3)扩展功能(代码行,注释行,空行)代码:
1 def line_detail(self): 2 # open the file with the name 'filename' 3 f = open(self.filename, 'r', encoding='utf-8') 4 # get all line string into a list 5 lines = f.readlines() 6 f.close() 7 # distinguish different lines 8 codelines, emptylines, commentlines = [], [], [] 9 for line in lines: 10 tmpline = line.replace(' ', '') 11 tmpline = tmpline.replace('\t', '') 12 tmpline = tmpline.replace('\n', '') 13 if len(tmpline) == 1 or len(tmpline) == 0: 14 emptylines.append(line) 15 elif tmpline.startswith('//'): 16 commentlines.append(line) 17 else: 18 codelines.append(line) 19 return self.fname + ', 代码行/空行/注释行:' + str(len(codelines)) + '/'\ 20 + str(len(emptylines)) + '/' + str(len(commentlines))
(4)递归处理文件代码:
1 # determine the type needed 2 tmplist = desfile.split('.') 3 type = '.' + tmplist[-1] 4 # get the required list 5 localinfo = directory.build_infolist(type) 6 # build up the information list from the file list 7 def build_infolist(type=''): 8 filenames = build_filelist(type) 9 dirnames = build_dirlist() 10 # get information by creating a FileInfo object 11 infos = [] 12 for fname in filenames: 13 info = FileInfo(path, fname) 14 infos.append(info) 15 # deal with the inner directory 16 for dirname in dirnames: 17 new_path = join(path, dirname) 18 newdir = DirInfo(new_path) 19 new_infos = newdir.build_infolist(type) 20 infos = infos + new_infos 21 return infos
(4)主函数模块:


1 import sys 2 from FileInfo import FileInfo 3 from DirInfo import DirInfo 4 from ExtraOpt import get_prelist, dialog_get, cur_file_dir 5 6 # get all valid arguments 7 args = sys.argv[1:] 8 9 # create a dictionary to contain all operations 10 fnames, indexs = [], [-1] 11 relation = {} 12 for arg in args: 13 if arg[0] != '-': 14 fnames.append(arg) 15 16 # determine the position of each file 17 for fname in fnames: 18 indexs.append(args.index(fname)) 19 relation[fname] = [] 20 21 # link the operations to the files 22 for i in range(0, len(indexs) - 1): 23 for j in range(indexs[i] + 1, indexs[i + 1]): 24 relation[fnames[i]].append(args[j]) 25 26 # determine the operations on one file 27 outputfile, desfile, prelistfile = "", "", "" 28 for fname in fnames: 29 if '-o' in relation[fname]: 30 outputfile = fname 31 elif '-e' in relation[fname]: 32 prelistfile = fname 33 else: 34 desfile = fname 35 36 # use dialog to open file 37 if args == ['-x']: 38 path, fname = dialog_get() 39 onefile = FileInfo(path, fname) 40 print(onefile.char_num()) 41 print(onefile.line_num()) 42 print(onefile.word_num([])) 43 # dealing with the directory 44 elif desfile != '' and '-s' in relation[desfile]: 45 directory = DirInfo(cur_file_dir()) 46 # determine the type needed 47 tmplist = desfile.split('.') 48 type = '.' + tmplist[-1] 49 # get the required list 50 localinfo = directory.build_infolist(type) 51 for info in localinfo: 52 str = "" 53 if '-c' in relation[desfile]: 54 print(info.char_num()) 55 str += info.char_num() + '\n' 56 if '-w' in relation[desfile]: 57 if prelistfile != "": 58 # get the preserved word list 59 prelist = get_prelist(prelistfile) 60 print(info.word_num(prelist)) 61 str += info.word_num(prelist) + '\n' 62 else: 63 print(info.word_num([])) 64 str += info.word_num([]) + '\n' 65 if '-l' in relation[desfile]: 66 print(info.line_num()) 67 str += info.line_num() + '\n' 68 if '-a' in relation[desfile]: 69 print(info.line_detail()) 70 str += info.line_detail() + '\n' 71 if outputfile != "": 72 info.write_file(outputfile, str) 73 # deal with the single file 74 else: 75 thisfile = FileInfo(cur_file_dir(), desfile) 76 thisstr = "" 77 if '-c' in relation[desfile]: 78 print(thisfile.char_num()) 79 thisstr += thisfile.char_num() + '\n' 80 if '-w' in relation[desfile]: 81 if prelistfile != "": 82 # get the preserved word list 83 prelist = get_prelist(prelistfile) 84 print(thisfile.word_num(prelist)) 85 thisstr += thisfile.word_num(prelist) + '\n' 86 else: 87 print(thisfile.word_num([])) 88 thisstr += thisfile.word_num([]) + '\n' 89 if '-l' in relation[desfile]: 90 print(thisfile.line_num()) 91 thisstr += thisfile.line_num() + '\n' 92 if '-a' in relation[desfile]: 93 print(thisfile.line_detail()) 94 thisstr += thisfile.line_detail() + '\n' 95 96 if outputfile != "": 97 thisfile.write_file(outputfile, thisstr) 98 99
三.静态代码检查
1.在这用的静态代码工具是:pyflakes
安装后(pip install pyflakes)对代码进行测试如下:

经对代码仔细检查后,发现是变量thisstr写错
其他错误:

多次修改后检查三个模块:

静态代码检查正确。
四.单元测试
测试文件:test1.c

(1)开始测试:
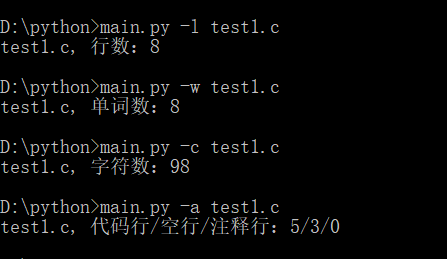
(2)写入文件:
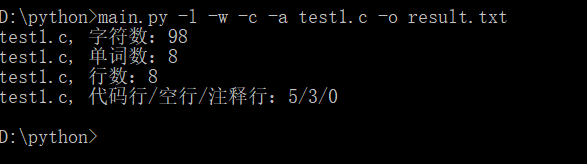
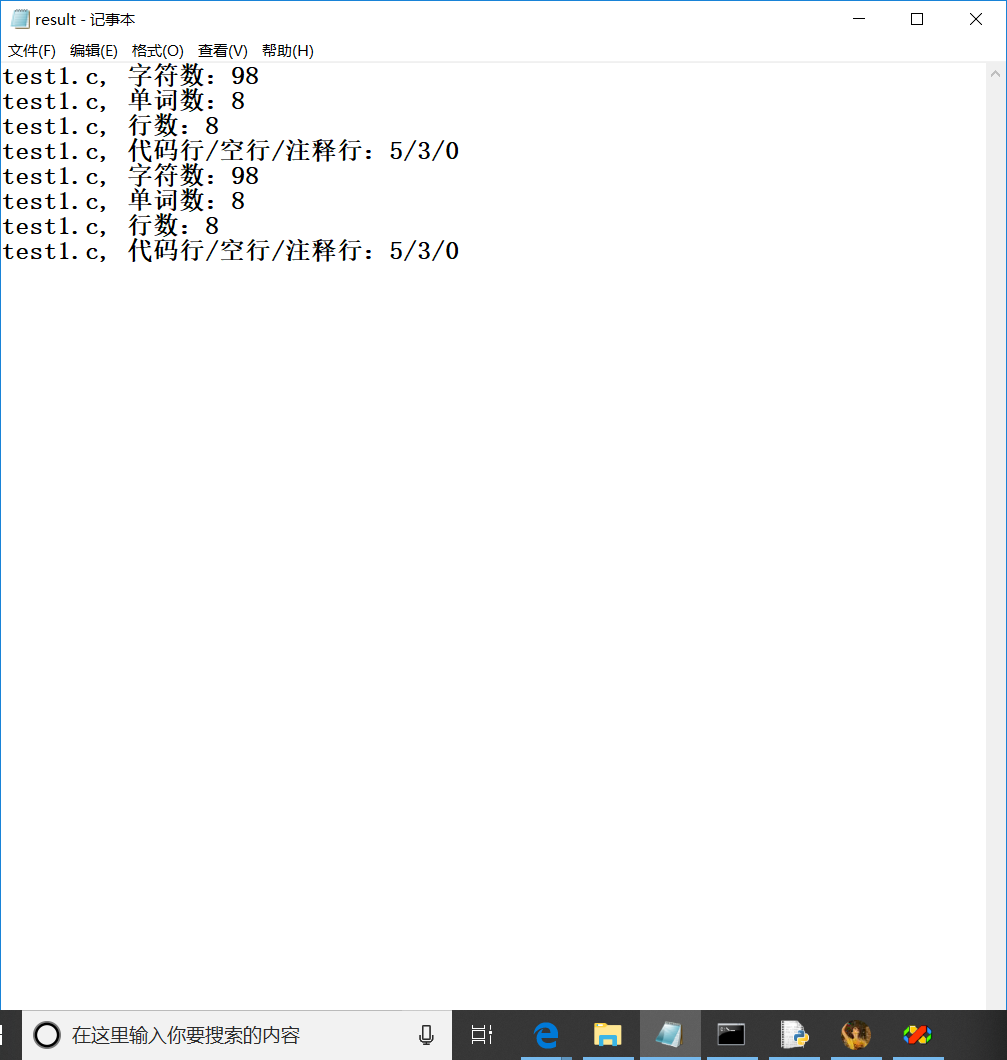
(3)停用词表,统计文件单词总数时,不统计该表中的单词:

五.性能测试和优化
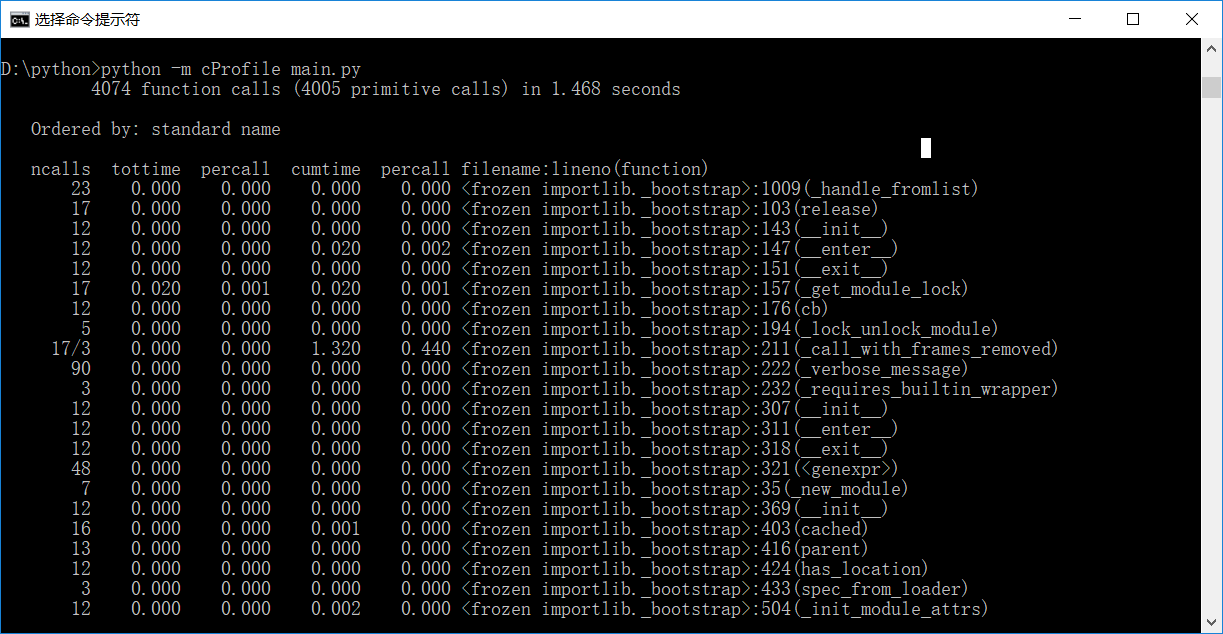
性能优化工具:cProfile
cProfile:基于lsprof的用C语言实现的扩展应用,运行开销比较合理,适合分析运行时间较长的程序,推荐使用这个模块;
使用cProfile分析的结果可以输出到指定的文件中,但是文件内容是以二进制的方式保存的,用文本编辑器打开时乱码。所以,Python提供了一个pstats模块,用来分析cProfile输出的文件内容。
如下图所示:
六.参考文献
python.py文件打包为exe文件:https://www.jb51.net/article/140067.htm
python性能优化cProfile:https://blog.csdn.net/asukasmallriver/article/details/74356771
python静态代码测试:https://blog.csdn.net/fan_hai_ping/article/details/41733817
七.总结
结对编程过程中,两人对问题看待会更透彻,全面。但同时也会有很多分歧,需要彼此理论磨合。在此过程中,出现了很多我们双方都难以解决的小问题,不知道该如何解决,但将问题摆出来,说出自己的观念,往往小问题就会引刃而解。我写的代码部分在测试过程中被队友检查出很多小问题,如果自己测试的话可能会忽视,然后小问题变成大问题。对方的测试和观点使得我们俩的这此项目更加完善优化,这是必不可少的。
---恢复内容结束---

 浙公网安备 33010602011771号
浙公网安备 33010602011771号