



SQL简单总结
SQL简单总结
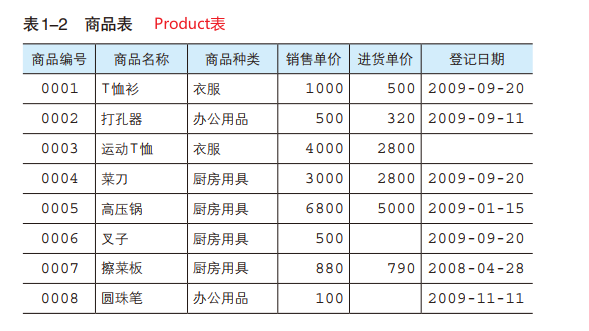
NOTE:本文所用的都以postgreSQL为例,对标准SQL语句进行简单的总结,语法等细节详细参考《SQL基础教程》,下称《教程》。下面的代码例子都基于下表:
1. 数据库
1.1 分类
-
层次数据库
-
关系数据库(最常用)
-
面向对象数据库
-
xml数据库
-
键值存储数据库
1.2 结构
![]()
2. 什么是SQL
SQL是为了操作数据库而开发的语言。
国际标准化组织(ISO)为 SQL 制定了相应的标准,以此为基准的SQL 称为标准 SQL 。大多数SQL语法都类似,但是不同的数据库的SQL语法还是不一样的。
3. 表的创建、删除、更新
目前在关系型数据库中,用来管理数据的二维表称之为表(table)。表存储在数据库中,一个数据库中可以有多个表。
-
创建
数据库的创建:
语法:
CREATE DATABASE <数据库名称>;表的创建:
语法:
CREATE TABLE <表名> ( <列名1> <数据类型> <该列所需约束>, <列名2> <数据类型> <该列所需约束>, <列名3> <数据类型> <该列所需约束>, <列名4> <数据类型> <该列所需约束>, . . . <该表的约束1>, <该表的约束2>,……); eg. 创建一个名为Product的表,存储商品ID、商品名、类型、销售价格、购买价格等列。并且,所有列必须指定数据类型。
CREATE TABLE Product (product_id CHAR(4) NOT NULL, product_name VARCHAR(100) NOT NULL, product_type VARCHAR(32) NOT NULL, sale_price INTEGER , purchase_price INTEGER , regist_date DATE , PRIMARY KEY (product_id)); -- 主键约束其中:数据类型有:
- 数字型
- INTEGER。只能存储整数,不能存储小数。
- 字符型
- CHAR(10)。定长字符串,长度为10,不足的用空格补齐。
- VARCHAR(10)。变长字符串,最大长度为10,不足的时候不用空格补齐。
- 日期型
- DATE。存储日期的类型。
约束条件指的是对存入数据的限制。如:NOT NULL,指的就是必须存入数据,不能为NULL。
- 数字型
-
删除
-
DROP
语法:
DROP TABLE <表名>;。需要注意的是删除的表是不能恢复的。 -
DELETE
DELETE FROM <表名>;。执行完后效果是清空表中的数据行,但表还是存在的。DELETE FROM <表名> WHERE <条件>;。指定条件的删除其中的行。
-
-
更新
-
表定义更新:
ALTER TABLE <表名> ADD COLUMN <列的定义>;。eg.
ALTER TABLE Product ADD COLUMN product_name_pinyin VARCHAR(100); --添加列
ALTER TABLE Product DROP COLUMN product_name_pinyin; --删除列- 向表中插入数据 插入一行:`INSERT INTO ProductIns (product_id, product_name, product_type, sale_price, purchase_price, regist_date) VALUES ('0005', '高压锅','厨房用具', 6800, 5000, '2009-01-15'); ` 省略列清单的单行插入: ````sql -- DML :插入数据 BEGIN TRANSACTION; INSERT INTO Product VALUES ('0001', 'T恤衫', '衣服',1000, 500, '2009-09-20'); INSERT INTO Product VALUES ('0002', '打孔器', '办公用品',500, 320, '2009-09-11'); INSERT INTO Product VALUES ('0003', '运动T恤', '衣服',4000, 2800, NULL); INSERT INTO Product VALUES ('0004', '菜刀', '厨房用具',3000, 2800, '2009-09-20'); INSERT INTO Product VALUES ('0005', '高压锅', '厨房用具',6800, 5000, '2009-01-15'); INSERT INTO Product VALUES ('0006', '叉子', '厨房用具',500, NULL, '2009-09-20'); INSERT INTO Product VALUES ('0007', '擦菜板', '厨房用具',880, 790, '2008-04-28'); INSERT INTO Product VALUES ('0008', '圆珠笔', '办公用品',100, NULL,'2009-11-11'); COMMIT;插入多行:
INSERT INTO ProductIns VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11'), ('0003', '运动T恤', '衣服', 4000, 2800, NULL), ('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');-
表复制
-- 将商品表中的数据复制到商品复制表中 INSERT INTO ProductCopy (product_id, product_name, product_type, sale_price, purchase_price, regist_date) SELECT product_id, product_name, product_type, sale_price, purchase_price, regist_date FROM Product; -
UPDATE
更新所有的列:
--更新所有的列为'2009-10-10' UPDATE Product SET regist_date = '2009-10-10';当然也可以通过WHERE来指定需要更新的行。
多行更新:
-- 使用逗号对列进行分隔排列 UPDATE Product SET sale_price = sale_price * 10, purchase_price = purchase_price / 2 WHERE product_type = '厨房用具'; -- 将列用()括起来的清单形式 UPDATE Product SET (sale_price, purchase_price) = (sale_price * 10, purchase_price / 2) WHERE product_type = '厨房用具';
-
-
事务:事务就是需要在同一个处理单元中执行的一系列更新处理(INSERT/DELETE/UPDATE)的集合
语法:
事务开始语句; DML语句①; DML语句②; DML语句③; ... 事务结束语句( COMMIT或者ROLLBACK) ;eg.
BEGIN TRANSACTION; -- 将运动T恤的销售单价降低1000日元 UPDATE Product SET sale_price = sale_price - 1000 WHERE product_name = '运动T恤'; -- 将T恤衫的销售单价上浮1000日元 UPDATE Product SET sale_price = sale_price + 1000 WHERE product_name = 'T恤衫'; COMMIT;在事务最后,
COMMIT代表提交事务,一旦提交,无法恢复到事务开始前的状态。ROLLBACK代表取消事务,一旦回滚,数据库会恢复到事务开始前的状态。事务的ACID特性:
- 原子性(Atomicity):所包含的更新处理要么全部执行,要么完全不执行 。
- 一致性(Consistency):事务中包含的处理要满足数据库提前设置的约束 。如NOT NULL约束,如果更新操作违反约束,则该事务会ROLLBACK。
- 隔离性(Isolation):指的是保证不同事务之间互不干扰的特性
- 持久性(Durability):指的是在事务(不论是提交还是回滚)结束后, DBMS 能够保证该时间点的数据状态会被保存的特性。
4. 查询
4.1 一般查询
-
SELECT
语法:
SELECT <列名>,……FROM <表名>;。eg.SELECT product_id, product_name, purchase_price FROM Product;SELECT * FROM Product;表示选取所有的列。SELECT product_id as id FROM Product;,AS可以为列起别名。 -
DISTINCT
效果:删除重复的行,达到去重效果。
语法:
SELECT DISTINCT product_type FROM Product; -
WHERE(筛选行)
效果:通过制定WHERE后面的条件,来筛选出想要的数据行。
语法:
SELECT <列名>, ……FROM <表名> WHERE <条件表达式>;。eg.
SELECT product_name, product_type FROM Product WHERE product_type = '衣服'; -
GROUP BY
效果:把表分成几组,然后再进行汇总处理
语法:
SELECT <列名1>, <列名2>, <列名3>, …… FROM <表名> GROUP BY <列名1>, <列名2>, <列名3>, ……;eg.
SELECT product_type, COUNT(*) FROM Product GROUP BY product_type; -
HAVING(筛选组)
效果:通过制定HAVING后面的条件,来筛选出想要的组。
-
ORDER BY
效果:对结果进行排序
语法:
SELECT <列名1>, <列名2>, <列名3>, …… FROM <表名> ORDER BY <排序基准列1>, <排序基准列2>, ……eg.
SELECT product_id, product_name, sale_price, purchase_price FROM Product ORDER BY sale_price;ORDER BY后面可以跟多个列。如col1, col2...,优先按col1排列,如果存在col1相同的情况下,再按col2排列。ORDER BY默认为升序排列
ASC,如果要降序,则需在列的后面添加DESC。eg.ORDER BY col1 desc;在ORDER BY子句中可以使用SELECT子句中定义的别名。
4.2 子查询
子查询通俗的将就是查询语句的嵌套。也可以理解为是一次性的视图。eg.
SELECT product_type, cnt_product
FROM ( SELECT product_type, COUNT(*) AS cnt_product
FROM Product
GROUP BY product_type ) AS ProductSum;
其中括号里的查询就是子查询。执行顺序:先执行子查询,然后在子查询的基础上做查询。
标量子查询:必须而且只能返回 1 行 1列的结果 。
--WHERE字句中不能使用聚合函数,这时可以用标量子查询完成这一效果
SELECT product_id, product_name, sale_price
FROM Product
WHERE sale_price > (SELECT AVG(sale_price)
FROM Product);
关联子查询:
--选取Product中每种类型的商品中销售单价大于该类商品平均售价的商品
SELECT product_type, product_name, sale_price
FROM Product AS P1
WHERE sale_price > (SELECT AVG(sale_price)
FROM Product AS P2
WHERE P1.product_type = P2.product_type --关联
GROUP BY product_type);
5. 视图VIEW
在SQL中,表是存储在硬盘上的,我们通过SELECT语句查询所需的数据。但是使用视图时,不会将数据保存到任何地方。实际上,视图保存的是SELECT语句。当我们从视图中读取数据时,视图内部其实在执行SELECT语句。所以使用视图有2大有点:①节省存储空间;②自动更新(表中数据更新,视图结果也自动更新)
创建视图:
CREATE VIEW 视图名称(<视图列名1>, <视图列名2>, ……)
AS
<SELECT语句>
eg.
CREATE VIEW ProductSum (product_type, cnt_product)
AS
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type;
使用视图来查询:
-- 确认创建好的视图
SELECT product_type, cnt_product
FROM ProductSumJim;
我们可以再视图的基础上再创建视图,即多重视图。但应避免这种情况,因为多重视图会降低SQL性能。
删除视图:DROP VIEW ProductSum;
6. 运算符
-
算术运算符:
+、-、*、/。注意:所有包含 NULL 的计算,结果肯定是 NULL。 -
比较运算符:
=、<>、>、>=、<、<=。注意:不能对NULL使用比较运算符 。 -
逻辑运算符:
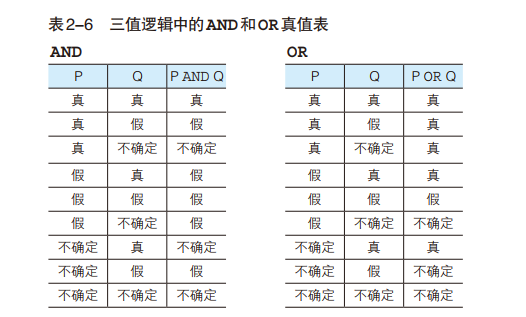
NOT、AND、OR。注意:AND运算符的优先级高于OR运算符。想要优先执行OR运算符时可以使用括号。但是当运算符涉及到NULL时,情况就不太一样了,如下图:
![]()
7. 函数
-
聚合函数(聚合函数会将NULL排除在外。但COUNT(*)例外,并不会排除NULL。)
-
COUNT:计算表中的记录数(行数)
eg.
SELECT COUNT(*) FROM Product;注意:COUNT(*)会得到包含NULL的数据 行数,而COUNT(<列名>)会得到NULL之外的数据行数。
-
SUM:计算表中数值列中数据的合计值
-
AVG:计算表中数值列中数据的平均值
-
MAX:求出表中任意列中数据的最大值
-
MIN:求出表中任意列中数据的最小值
-
-
算术函数
- 算数运算符:
+、-、*、/。注意:所有包含 NULL 的计算,结果肯定是 NULL。 ABS(数值):绝对值。MOD(被除数,除数):求余。ROUND(对象数值,保留小数的位数):四舍五入。
- 算数运算符:
-
字符串函数
字符串1||字符串2:拼接。eg.'code' || 'mao' = 'codemao'LENGTH(字符串):求字符串长度。LOWER(字符串) /UPPER(字符串):大小写转换。REPLACE(对象字符串,替换前的字符串,替换后的字符串):字符串替换。eg.REPLACE('Abc', 'bc', 'BC') = 'ABC'SUBSTRING(对象字符串 FROM 截取的起始位置 FOR 截取的字符数):子串截取。注意:这里字符串索引从1开始。
-
日期函数:
CURRENT_DATE:返回当前日期。如2009-12-13 。CURRENT_TIME:返回当前时间。如17:26:50.995+09 。CURRENT_TIMESTAMP:返回当前日期和时间。EXTRACT(日期元素 FROM 日期):截取出日期数据中的一部分,例如“年“,“月”,或者“小时”“秒”等 ,其返回值是数值类型,不是日期类型。
-
转换函数
-
CAST(转换前的值 AS 想要转换的数据类型):相当于C语言中的强制类型转换。 -
COALESCE(数据1,数据2,数据3……):该函数会返回可变参数 A 中左侧开始第 1个不是 NULL 的值。参数个数是可变的,因此可以根据需要无限增加。--通过这个函数,可以实现将NULL转换为其他值 SELECT COALESCE(NULL, 1) AS col_1, COALESCE(NULL, 'test', NULL) AS col_2 FROM TABLE;
-
-
谓词
谓词可以理解为是一种返回真值的函数。
-
LIKE:字符串的部分一致查询。
'abc' LIKE 'ab%' 返回 真。 其中 % 代表0个字符及以上的任意字符串 'abdd' LIKE 'ab__' 返回 真。 其中 _ 代表任意一个字符串 -
BETWEEN:范围查询
150 BETWEEN 100 AND 1000返回真。 -
IS NULL、IS NOT NULL:判断是否为空。不能用
=判断。 -
IN、NOT IN:相当于
OR的简便用法。SELECT product_name, purchase_price FROM Product WHERE purchase_price IN (320, 500, 5000); -
EXISTS:有点难理解,可理解为存在与否。eg.
--列出Product中存在于名为‘000C’的商店中的商品 SELECT product_name, sale_price FROM Product AS P WHERE EXISTS (SELECT * FROM ShopProduct AS SP WHERE SP.shop_id = '000C' AND SP.product_id = P.product_id);
-
-
CASE(SQL中的条件分支)
-
搜索CASE表达式
SELECT product_name, CASE WHEN product_type = '衣服' THEN 'A : ' || product_type WHEN product_type = '办公用品' THEN 'B : ' || product_type WHEN product_type = '厨房用具' THEN 'C : ' || product_type ELSE NULL END AS abc_product_type --END不可省略 FROM Product; -
行列转换
-- 对按照商品种类计算出的销售单价合计值进行行列转换 SELECT SUM(CASE WHEN product_type = '衣服' THEN sale_price ELSE 0 END) AS sum_price_clothes, SUM(CASE WHEN product_type = '厨房用具' THEN sale_price ELSE 0 END) AS sum_price_kitchen, SUM(CASE WHEN product_type = '办公用品' THEN sale_price ELSE 0 END) AS sum_price_office FROM Product;
-
-
窗口函数(OLAP函数)
窗口函数兼具分组和排序两种功能。
在使用范围上:原则上窗口函数只能在SELECT子句中使用
语法:
<窗口函数> OVER ([PARTITION BY <列清单>] ORDER BY <排序用列清单>)RANK():计算排序时,如果存在相同位次的记录,则会跳过之后的位次。eg. 有3条记录并列第一时:1,1,1,4······。eg.
-- 结果根据product_type分组,每组内部按照sale_price排序,ranking列显示排名顺序 SELECT product_name, product_type, sale_price, RANK () OVER (PARTITION BY product_type ORDER BY sale_price) AS ranking FROM Product;其中,PARTITION BY(可以省略,不分组)能够设定排序的对象范围, ORDER BY 能够指定按照哪一列、何种顺序进行排序。
DENSE_RANK():同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。 eg. 有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位……
ROW_NUMBER():赋予唯一的连续位次。eg. 有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位……
SELECT product_name, product_type, sale_price, RANK () OVER (ORDER BY sale_price) AS ranking, DENSE_RANK () OVER (ORDER BY sale_price) AS dense_ranking, ROW_NUMBER () OVER (ORDER BY sale_price) AS row_num FROM Product;另外,所有的聚合函数都能作为窗口函数使用,只是语法不一样。如:
SELECT product_id, product_name, sale_price, SUM (sale_price) OVER (ORDER BY product_id) AS current_sum FROM Product; 效果: product_id | product_name | sale_price | current_sum ---------- +----------- +------------+------------ 0001 | T恤衫 | 1000 | 1000 ←1000 0002 | 打孔器 | 500 | 1500 ←1000+500 0003 | 运动T恤 | 4000 | 5500 ←1000+500+4000 0004 | 菜刀 | 3000 | 8500 ←1000+500+4000+3000 0005 | 高压锅 | 6800 | 15300 0006 | 叉子 | 500 | 15800 0007 | 擦菜板 | 880 | 16680 0008 | 圆珠笔 | 100 | 16780计算移动平均:
SELECT product_id, product_name, sale_price, AVG (sale_price) OVER (ORDER BY product_id ROWS 2 PRECEDING) AS moving_avg FROM Product;其中:
ROWS 2 PRECEDING指的是统计当前行及前2行的数据;同理还有ROWS 2 FOLLOWING统计当前行及后2行数据;ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING统计当前行、前一行和后一行的数据。 -
GROUPING运算符
只使用GROUP BY子句和聚合函数是无法同时得出小计和合计的,这时GROUPING运算符上场了。
-
ROLLUP
-- 结果会有每组销售价格小计和所有销售价格的总计 SELECT product_type, SUM(sale_price) AS sum_price FROM Product GROUP BY ROLLUP(product_type);相当于做了下面2个操作:
① GROUP BY ():会得到全部数据的合计行的记录。称为超级分组记录(super group row)。
② GROUP BY (product_type)
-
GROUPING
这部分比较难理解,详见《教程》。
-
8. 集合运算
8.1 表加减
表加减仅仅是对表中数据行的操作。
-
UNION(并集)
表的加法。但是不包括2张表中的重复行。
--Product表 + Product2表 SELECT product_id, product_name FROM Product UNION SELECT product_id, product_name FROM Product2;注意:
- 作为运算对象的记录的列数必须相同
- 作为运算对象的记录中列的类型必须一致
- 可以使用任何SELECT语句,但ORDER BY子句只能在最后使用一次
ALL选项:
SELECT product_id, product_name FROM Product UNION ALL -- 包含重复行,就是2张表简单的相加 SELECT product_id, product_name FROM Product2; -
INTERSECT(交集)
选取2张表中的公共部分。
-
EXCEPT(差集)
-- Product中去除Product2中的行 SELECT product_id, product_name FROM Product EXCEPT SELECT product_id, product_name FROM Product2 ORDER BY product_id;注意,差集的2张表被减数和减数位置不一样,结果亦不同。
8.2 联结
联结是将其他表中的列添加过来,进行“添加列”的集合运算 。
-
INNER JOIN
内联结:以2张表同时存在的列(称之为公共列)为桥梁,将只存在于一张表中的列汇集到结果里。但是只会汇集公共列里2张表同时存在的值的行。
--选出同时存在于SP和P中的product_id数据行 SELECT SP.shop_id, SP.shop_name, SP.product_id, P.product_name, P.sale_price FROM ShopProduct AS SP INNER JOIN Product AS P ON SP.product_id = P.product_id; -
OUTER JOIN
外联结:和内联结类似,也是扩大列,但与内联结不同的是,它会汇集其中一张表中所有公共列的行。用关键字RIGHT和LEFT来指定哪个表是主表(使用 LEFT 时 FROM 子句中写在左侧的表是主表,使用 RIGHT时右侧的表是主表),最终结果会包含主表里所有的数据。
--在内联结的基础上,加上只存在于P中的product_id的行。 SELECT SP.shop_id, SP.shop_name, SP.product_id, P.product_name, P.sale_price FROM ShopProduct AS SP RIGHT OUTER JOIN Product AS P ON SP.product_id = P.product_id; -
CROSS JOIN(笛卡尔积)
交叉联结。在实际应用中很少使用,但是是所有联结的基础。
--SP有13行,P有8行。则结果有13×8行 SELECT SP.shop_id, SP.shop_name, SP.product_id, P.product_name FROM ShopProduct AS SP CROSS JOIN Product AS P;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号