
【视频笔记】Elastic Search是什么?Lucene是什么?架构是怎么样的?
什么是Elastic Search?是一个开源的搜索引擎
从倒排索引聊起。
回到文章开头的例子,依次遍历文本,匹配是否含有“xiaobai”,很低效。

高效一点的方法,对文本进行切分

句子切分为几部分,这个操作叫做分词。

分词后,每一部分叫做一个词项,term。记录词项和文本id的关系,

上面文本就变成

当要搜索“xiaobai”的时候,只需要匹配对应的词项,就可以得到它所在的文档id

上面这种挨个遍历词项的方式,时间复杂度是O(N)。将词项按字典序从小到大排序,按照二分查找的方法,时间复杂度为O(lgN)

左侧排好序的team叫team dictionary,右侧序号列表叫做Posting list,他们共同构成了一个用于搜索的数据结构,就是倒排索引inverted index

term dictionary数据量很大,放内存里不现实,因此需要放在磁盘中,但查询磁盘是一个较慢的过程。优化手段,term index

词项和词项之间有些前缀是一致的,把前缀提取出来,构建出一个精简的目录树

目录树的节点中存放这些词项在磁盘中的偏移量。目录树的结构体积小,适合放在内存中,它就是所谓的term index,可以用它来加速搜索。

当我们搜索某个词项的时候,只需要搜索term index,就能快速获得词项在term dictionary的大概位置,跳到term dictionary,通过少量的检索定位到词项内容

Stored fields是什么
通过倒排索引查到的是文档id,还需要通过这个文档id,找到文档内容本身,才能返回给用户

因此,还需要有个地方存放完整的文档内容,他就是stored Fields,他是个行式存储结构

Doc Values是什么
有了id,我们就能从stored fields中取出文档内容

但用户经常需要根据某个字段,排序文档,比如按时间排序或商品价格排序,但这些字段散落在文档里。
也就是说,我们需要先获取stored fields里的文档,再提取出内部字段,进行排序。
更高效的办法,用空间换时间的方法,将散落在各个文档的某个字段,集中存放,当我们想对某个字段排序的时候,将这些集中存放的字段一次性读取出来,就能进行针对性的排序,这个列式存储结构就是所谓的Doc Values (用于排序和聚合)

segment是什么
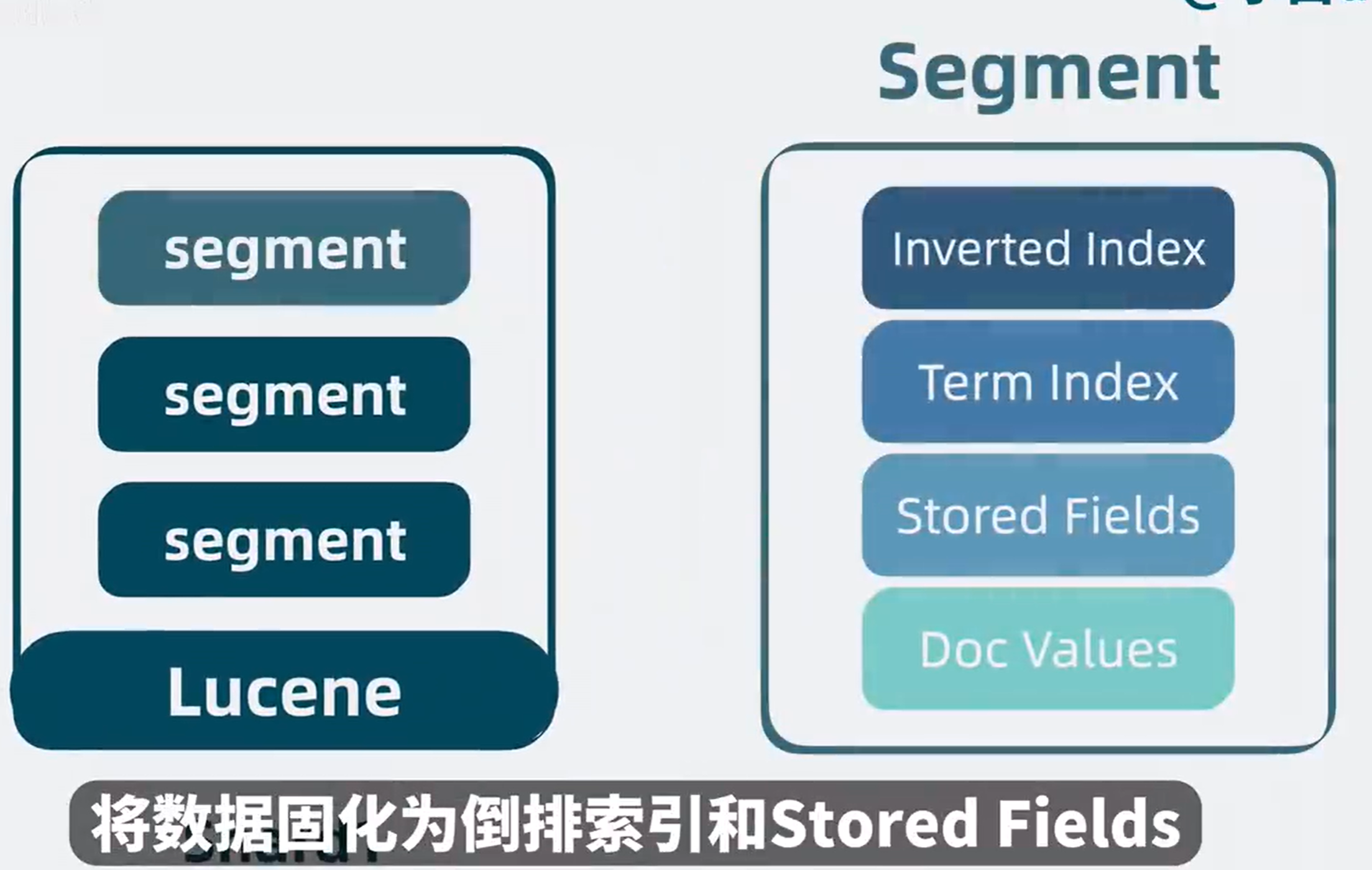
上面四种结构,Inverted index,Term Index,Sorted Fields,Doc Values,这些结构共同组成了一个复合文件,也就是所谓的segment,它是一个具备完整搜索功能的最小单元。

Lucene是什么
如果新增文档(document)还是塞入原有的segment,那就需要更新其内部的多个数据结构,性能肯定会受到影响。

怎么办?segment一旦生成,就不能被修改。如果还有新的文档(document)要写入,那就生成新的segment。
这样,老的segment只负责读,写则生成新的segment(同时保证了读和写的性能)。

但同时存在多个segment,那怎么知道要搜索的数据,在哪个segment里呢?(解决:并发同时读多个segment就好了)随着数据量变大,segment文件越来越多,文件句柄被耗尽,是指日可待啊(解决:不定期合并多个小segment成一个大segment, 也就是段合并segment merging), 这样文件数量就可控了。

多个segment就构成了单机文本检索库
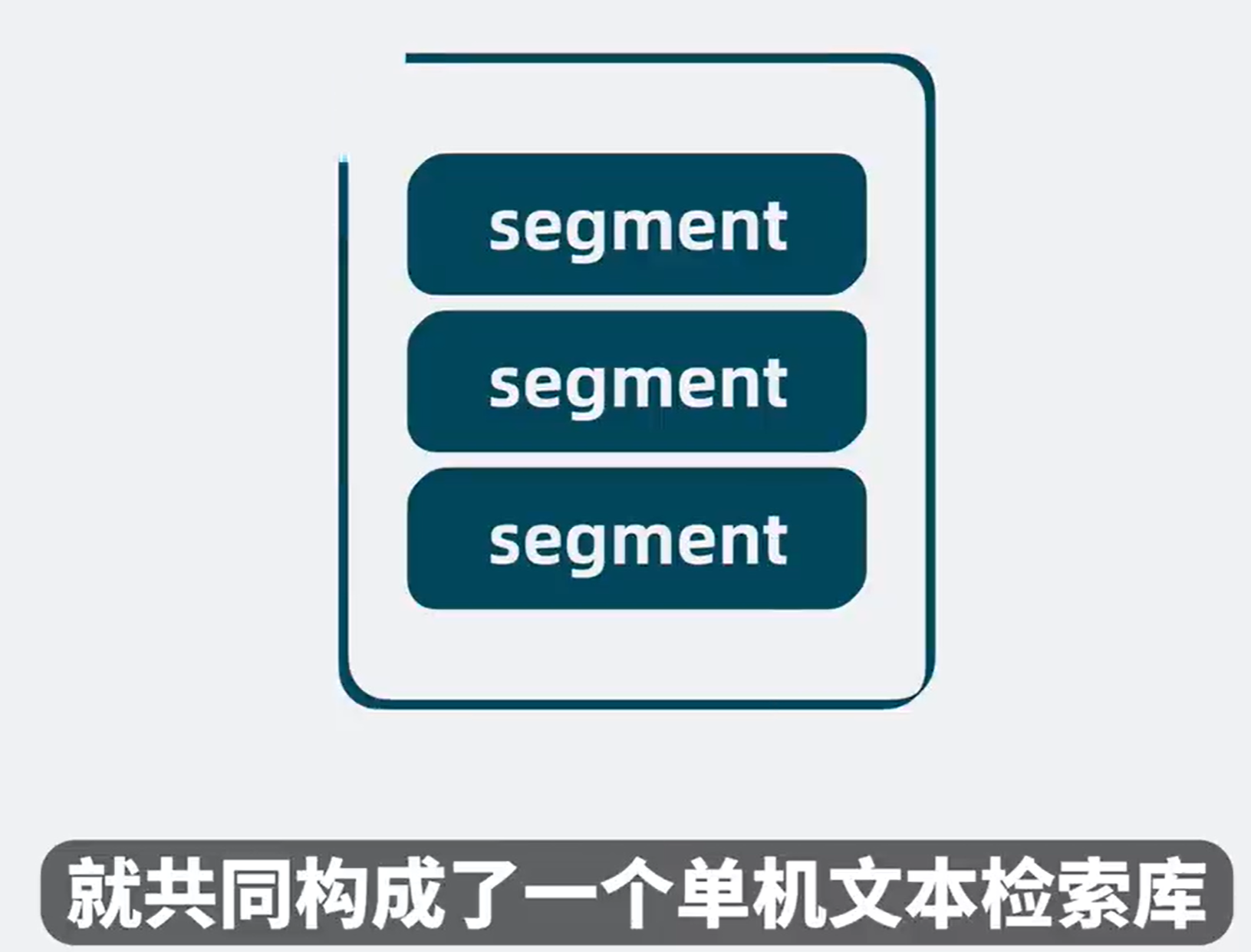
它就是开源搜索库 lucene
多个调用方同时调用同一个lucene,必然导致争抢资源,抢不到资源的一方就得等待。

对写入lucene的数据进行分类,必然体育新闻和八卦新闻算两类,每一类是一个Index name

然后根据index name新增lucene的数量,将不同类数据写入到不同的lucene中

读取数据时,根据需要搜索不同的index name,这就大大降低了单个lucene的压力。
但单个index name里数据依然可能过多,于是可以将单个index name的同类数据,拆分成好几份,每份是一个shard分片

每个shard分片,本质上就是一个独立的lucene库,这样我们就可以将读写操作,分摊到多个分片中去,大大降低了争抢,提升了系统性能。

高扩展性
随着分片变多,如果分片都在同一个机器上的话,就会导致cpu和内存过高,影响整体系统性能,于是可以申请更多的机器,将分片分散部署在多台机器上,这每一台机器就是一个Node,我们可以通过增加Node,缓解机器cpu过高带来的性能问题

高可用
如果一个node挂了,那node里的所有分片,都无法对外提供服务了,为了保证服务的高可用,我们可以给分片多加几个副本。
将分片分为primary shard和replica shard

副本分片既可以提供读操作,还可以在主分片挂了的时候,选举为主分片,让系统保持正常运行,保证了系统的高可用。
Node角色分化
node共有“集群管理”、“存储数据”、“处理请求”几种功能,复制node时,如果每个node都承担这三种功能,复制后都承担这些功能没有必要,所以划分一下角色。
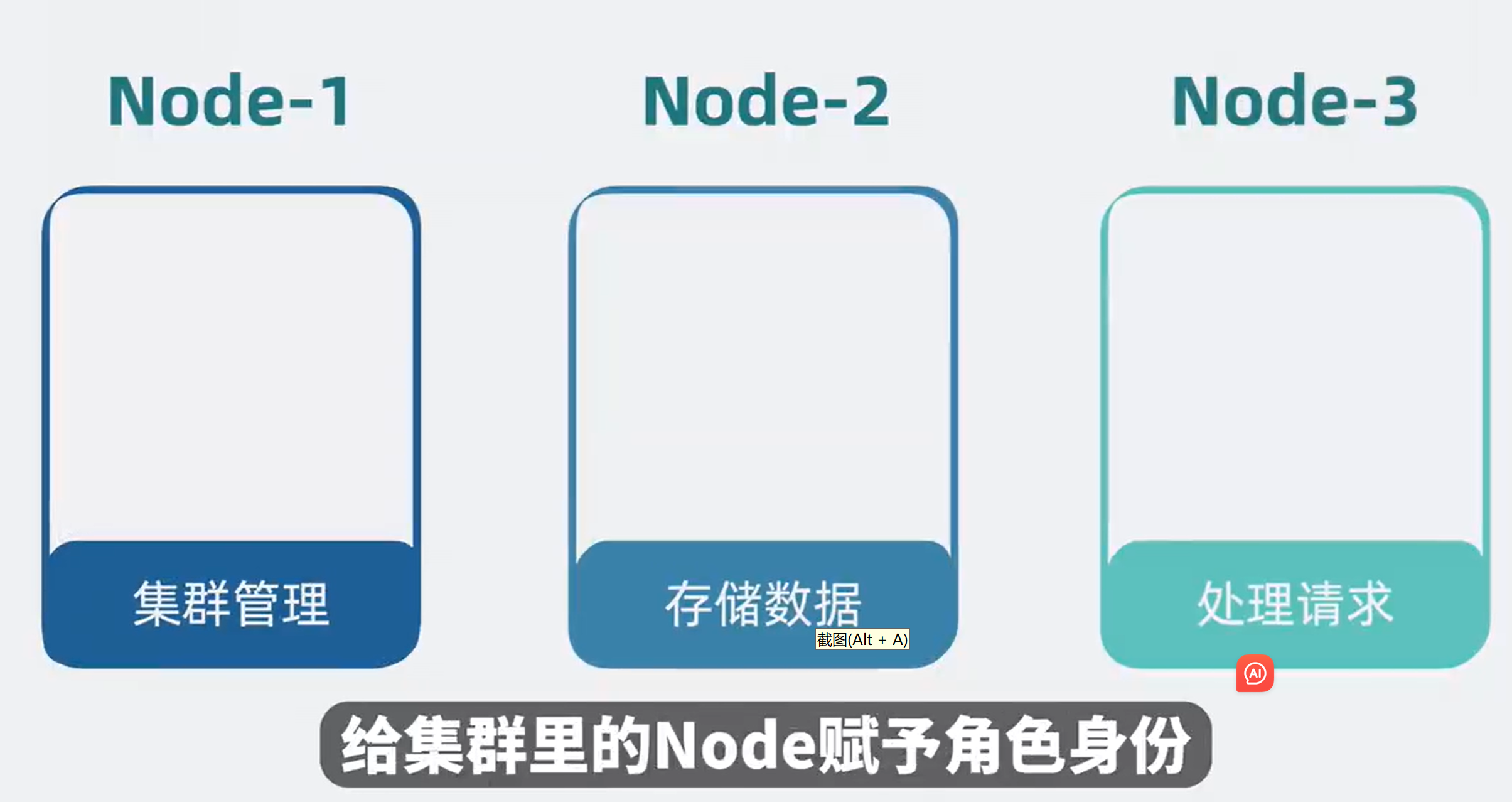
不同的角色负责不同的功能,比如负责管理集群的叫主节点Master Node,数据存储数据的叫Data Node,负责客户端请求的叫协调节点Coordinate Node
一个集群小的时候,一个Node可以充当多个角色,随着集群规模逐渐变大可以一个Node一个角色。
去中心化
上面提到了主节点,那就意味着还有一个选主的过程。但现在每个Node都是独立的,需要有个机制协调Node间的数据。
比如kafka有个注册中心zookeeper。但如果不想引入中心节点,还有其他更轻量的方案吗?有,去中心化。
在每个Node节点,引入魔改过的Raft模块,在节点间互相同步数据,让所有的Node看到的集群数据状态都是一致的。

这样集群内的Node就能参与选主过程,还能了解到集群内某个Node是不是挂了。
到这里,当初那个lucene就成了一个高性能、高扩展、高可用,支持持久化的分布式搜索引擎。

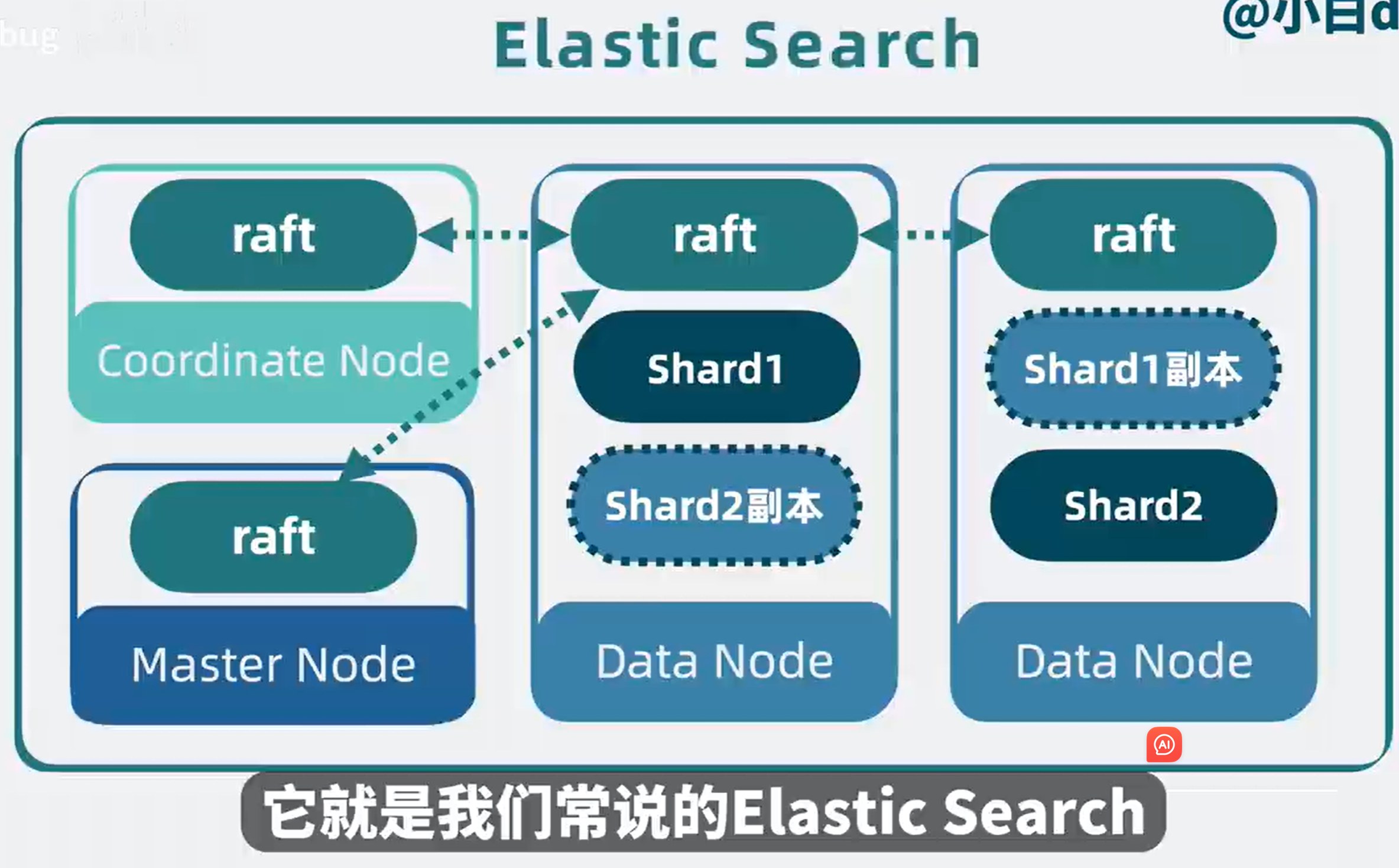
它对外提供http的接口。
例子1,客户端http请求,会先发到协调节点(Coordinate Node),协调节点通过hash路由,判断数据应该写入到那个数据节点(Data Node)里的那个分片(Shard),找到主分片并写入,分片底层是lucene,所以最终是将数据写入到lucene库里的segment内,将数据固话为倒排索引和Stored Fields以及Doc Values等多种结构。
主分片写入成功后,会将数据同步给副本分片

副本分片写入完成后,主分片会响应协调节点一个ack,意思是写入完成。最后协调节点响应客户端应用写入完成。
ES的搜索流程
分为两个阶段,分别是查询阶段query phase和获取阶段fetch phase。
查询阶段,当客户端应用发起搜索请求,请求先发到集群内的协调节点(Coordinate Node),协调节点根据index name的信息,可以了解到index name被分为了几个分片,以及这些分片分散在哪个数据节点上,将请求转发到这些数据节点的分片上面,搜索请求到达分片后,分片底层的lucene库会并发搜索多个segment,利用每个segment内部的倒排索引,获取到对应文档的id,并结合Doc Values获得排序信息,分片将结果聚合返回给协调节点

协调节点(Coordinate Node)对多个分片(shard)中拿到的数据进行排序聚合, 舍弃大部分不需要的数据

获取阶段
协调节点再次拿着文档ID,请求数据节点里的分片,分片底层的lucene库,会从segment内的sorted fields读出完整文档内容

并返回给协调节点,协调节点最终将数据结果返回给客户端

完成整个搜索过程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号