
【视频笔记】耗时三个月,终于找到了JVM停顿十几秒的原因,实习生:运气真好
凌晨系统挂了几分钟,幸好是凌晨零点,要是在大促就完了。促销活动经常在零点呀!!!!
排查监控与日志,但没找到任何有用的线索。
看起来进程重启了,凌晨流量没啥波动呀,也没有oom killer的日志,进程线程丢失了。
要不写个脚本监测cpu、堆内存使用率,当占用高时,自动jstack、jmap保存现场信息
监控脚本有问题,在没有问题的时间点,执行了jmap,导致jvm长时间卡顿,k8s探活失败,杀掉了我们的进程
发现一个新线索,gc日志中显示jvm有十几秒STW

是gc时间太长了吗?不是的,在这条日志上面,并没有这样的gc日志。
奇怪,除了gc日志,还有其他的东西导致jvm暂停吗?
网上查,JVM中除了GC,还有很多操作也需要jvm暂停

比如我们获取线程栈的jstack,还有撤销偏向锁等等vm操作。
那怎么知道是哪个vm操作导致的呢?
这需要开启safepoint日志了。
开启safepoint日志:
java ... -XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1
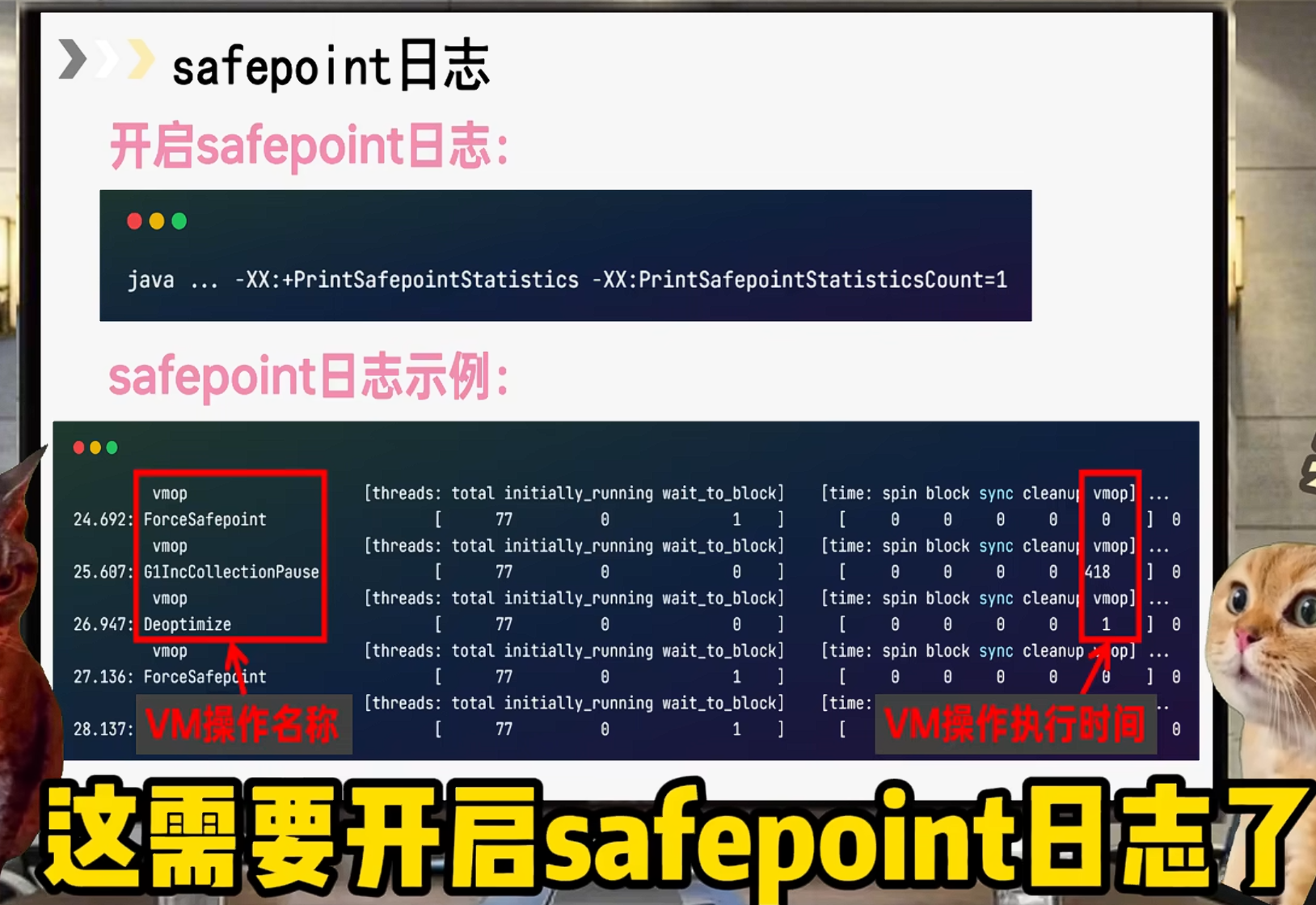
safepoint是jvm实现所有线程暂停的机制,所有线程进入safepoint后,就可以执行vm操作了
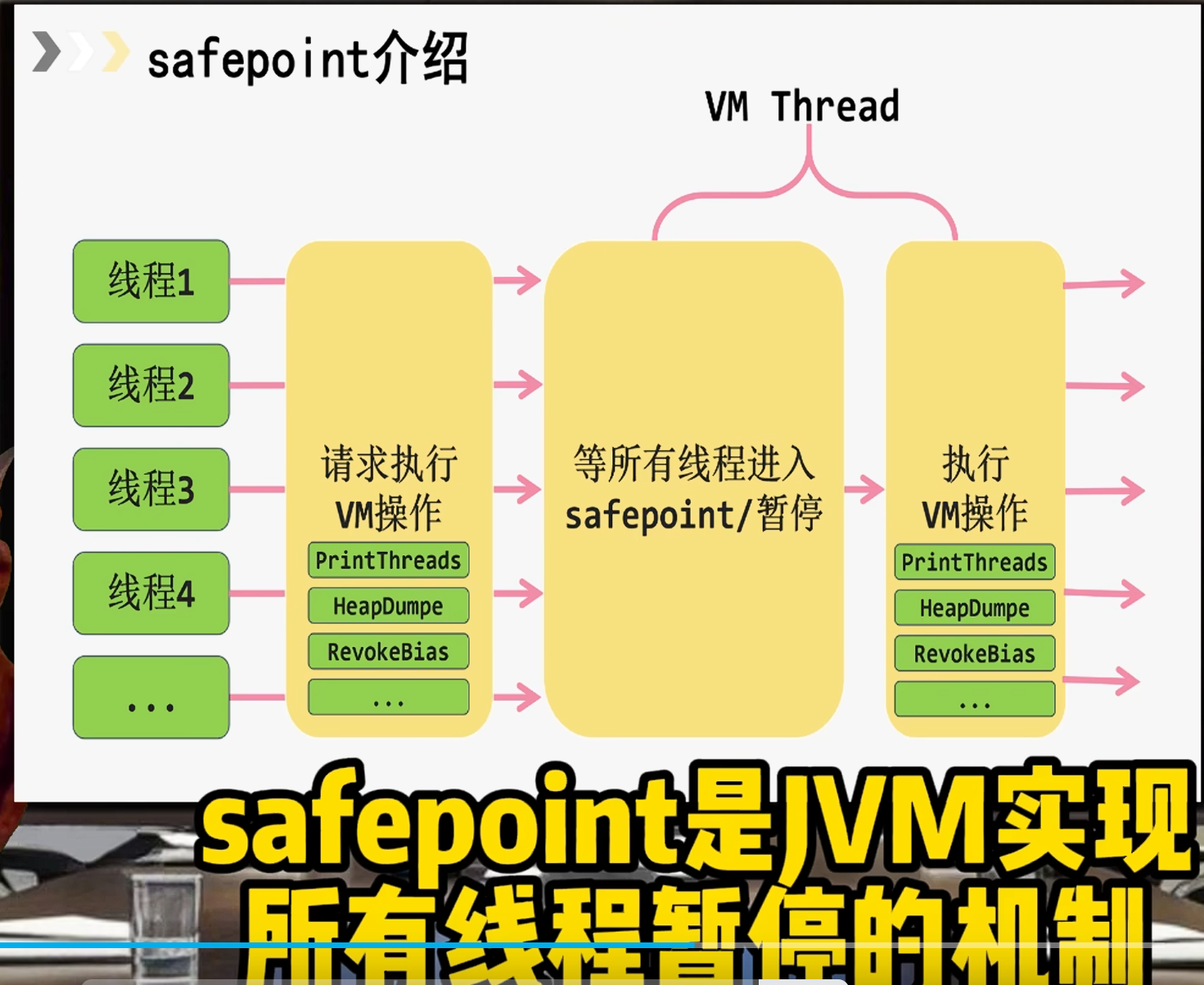
服务又挂了,看下safepoint日志,看有个vm操作执行了16s,触发的vm操作叫HeapWalkOperation
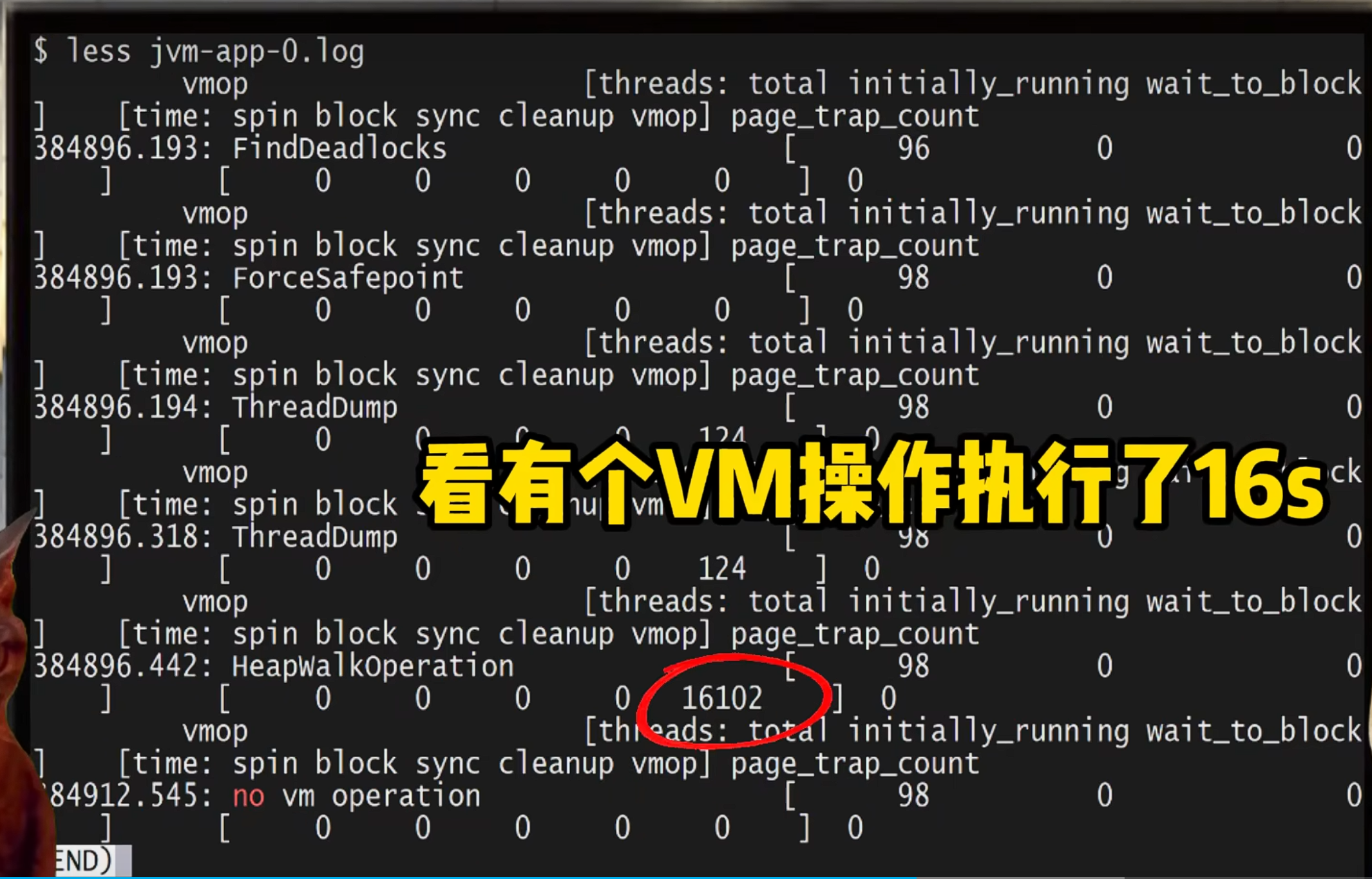
听起来像是在遍历java堆,哪里代码触发的呢?
网上没有人分享过这个!
问题卡了很久,直到第N次问题复现。
没有线索,MD,暴力搜索一下
grep -rni heap
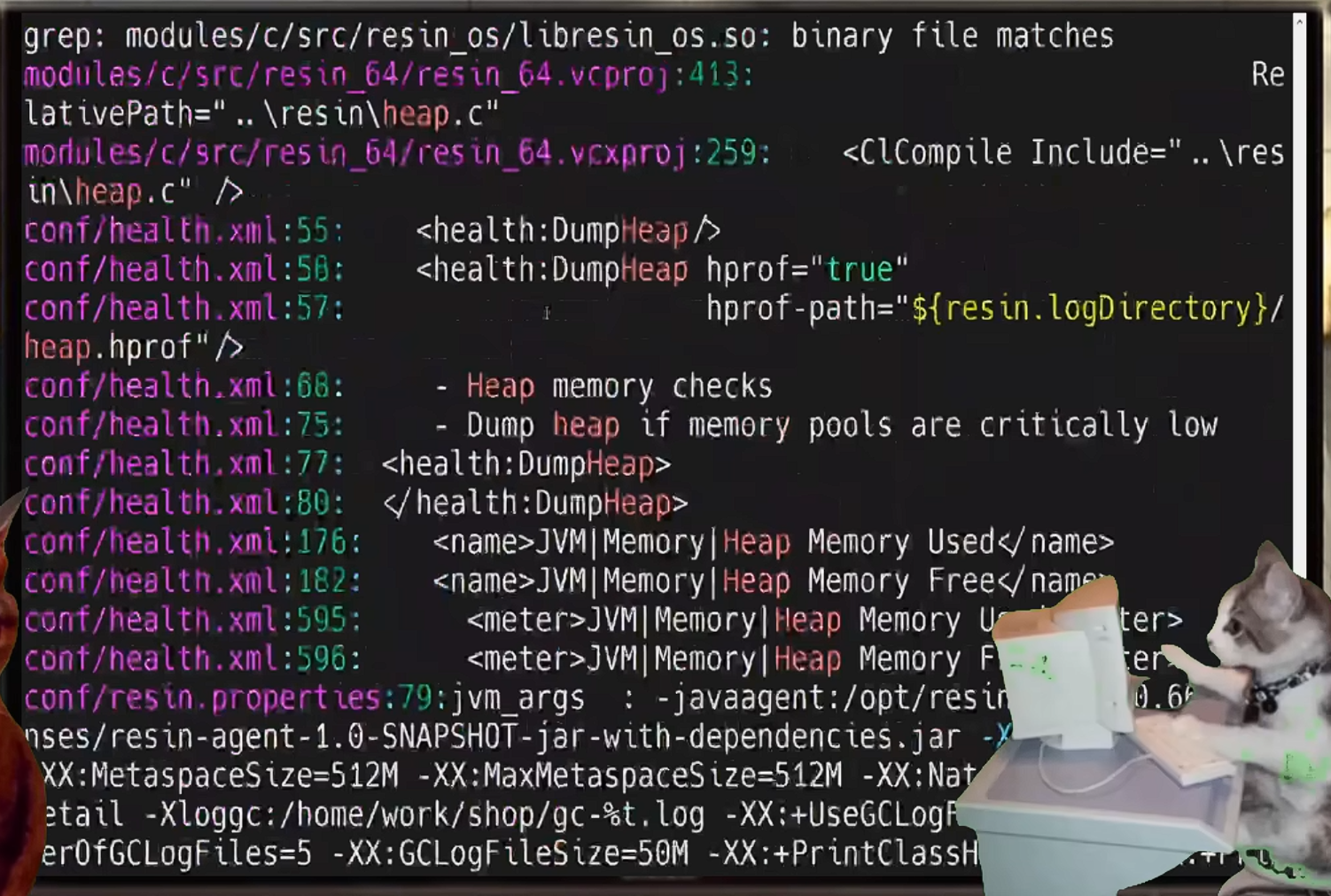
在resin web服务器中,搜到了DumpHeap关键字,好像resin有一些堆遍历相关的健康检查机制。
那关一下这个配置
简单总结 

 浙公网安备 33010602011771号
浙公网安备 33010602011771号