
【视频笔记】为什么不推荐使用数据库自增主键?也不推荐使用UUID作主键,用雪花算法会有什么问题?
为什么不推荐数据库自增主键?
使用数据库自增主键,在分库分表情况下会有问题
横向分表,id可能重复
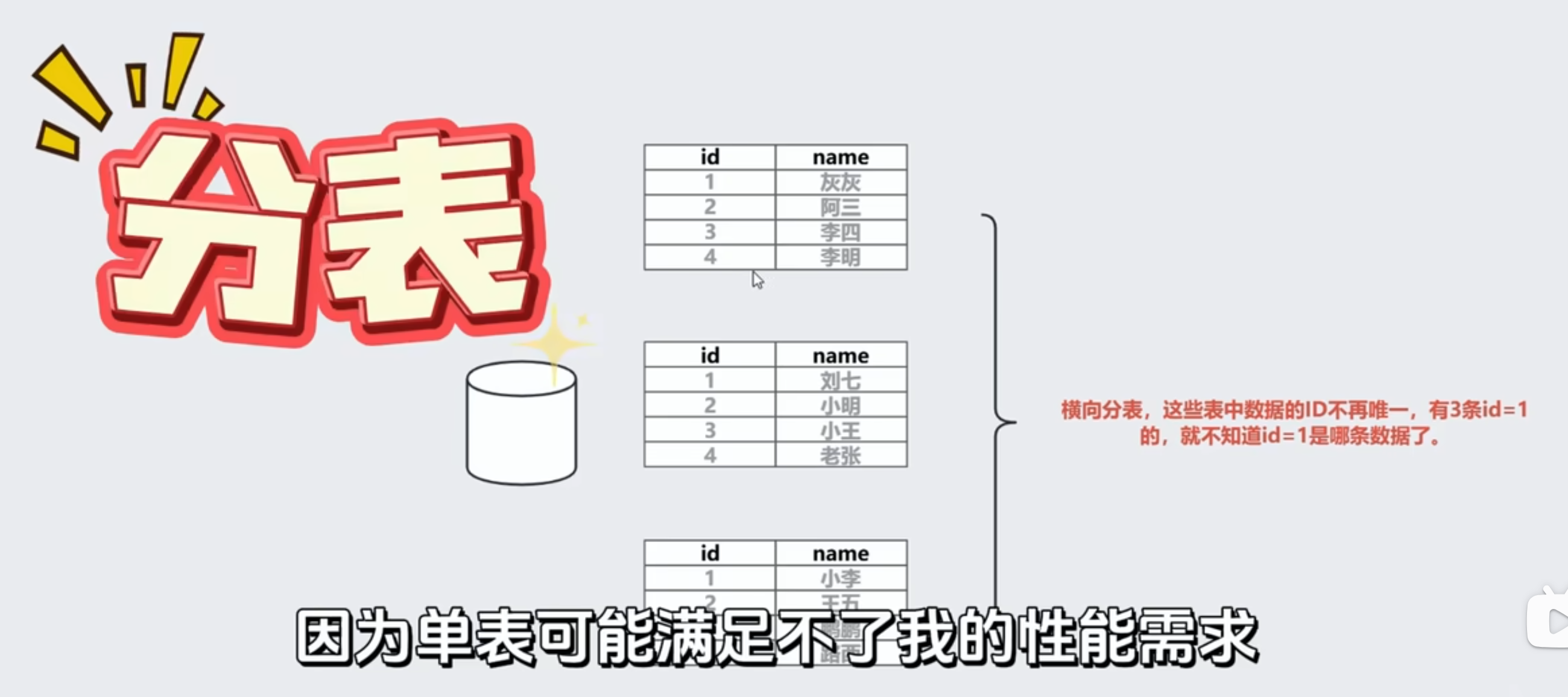
用步长差开的话,当前表和库可以,但是扩容会有问题或者数据迁移时有问题
分布式id,UUID 雪花算法
UUID(不建议):Innodb引擎索引结果时b+树,有个概念就是索引即数据
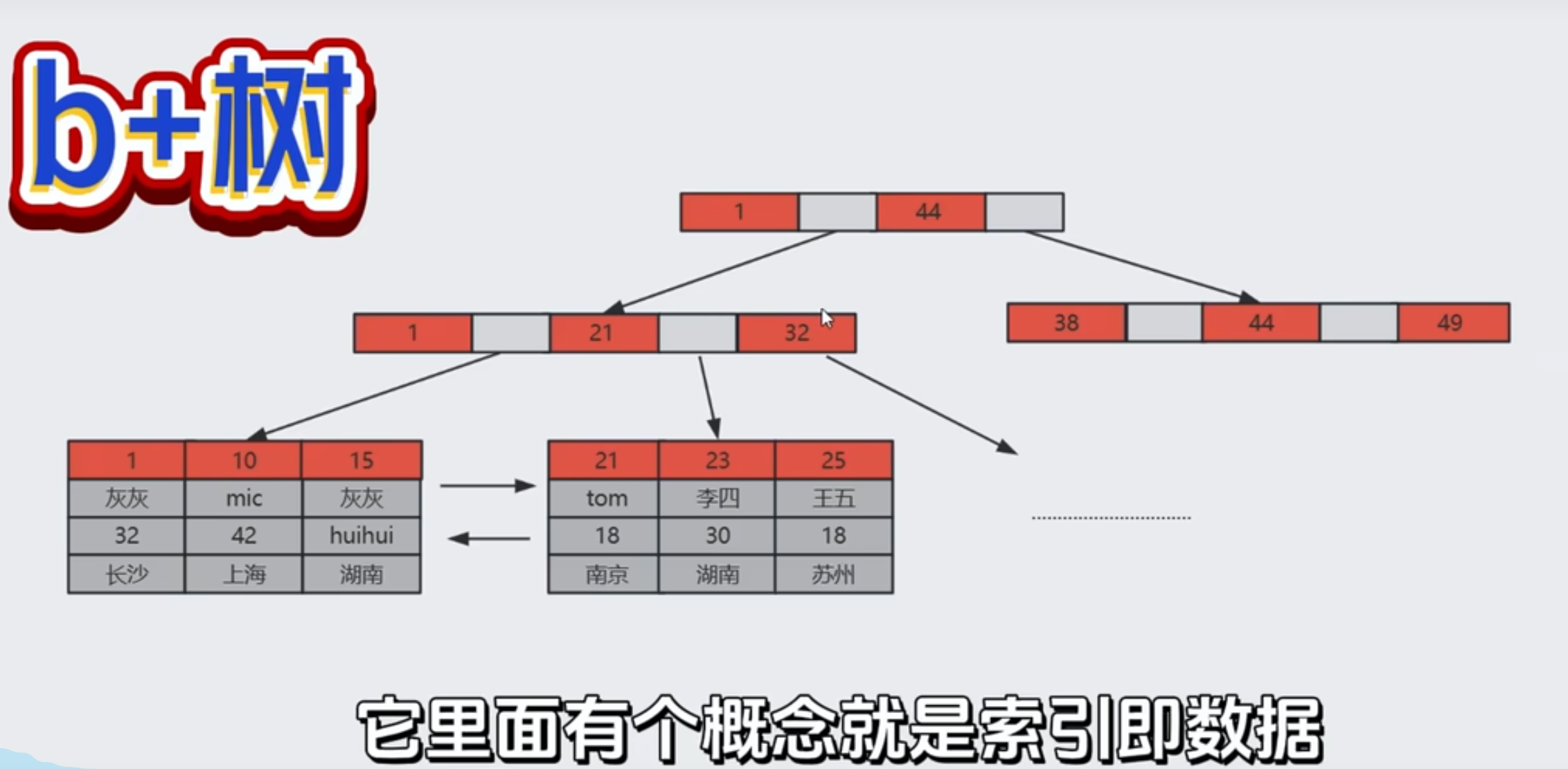
主键索引的叶子节点会去保存完整的行数据

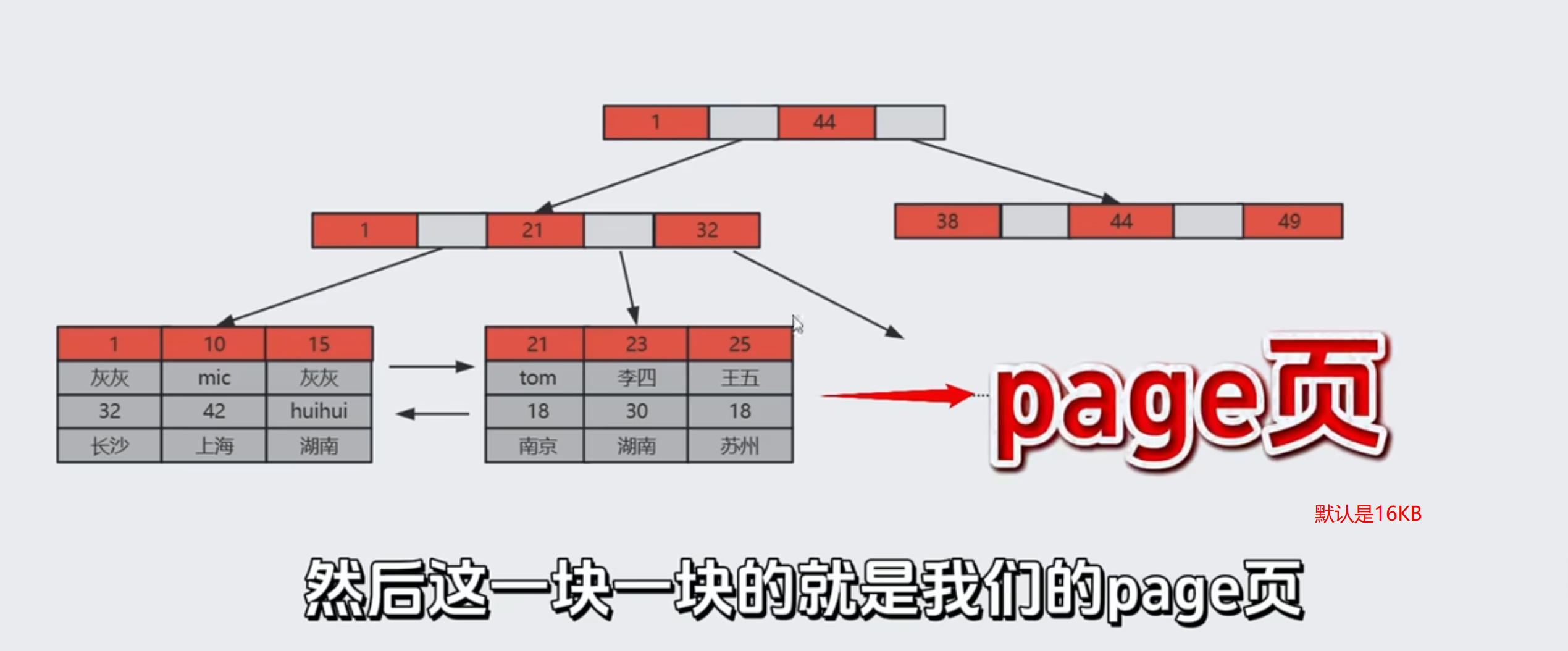
一块一块的事page页,默认是16KB
uuid做主键影响性能
1、影响查询性能
page页是内存跟磁盘交互的最小单位
主键索引树里面,这个主键是每一个节点每一行数据都需要去保存的,
uuid比较长,代表它占用的空间比较大(那同样的数据量需要更多的page页,那么索引树的高度也就越高,遍历的次数就越多,代表需要跟磁盘进行更多的IO,所以会影响我们的查询性能)
2、影响操作性能
uuid是无序的,非趋势递增。
而主键索引树是需要排好序的,所以每次添加数据的时候,需要对数据的内容进行重排序,这个也叫树的分裂与合并,严重影响了我们操作数据的性能
所以需要避免非趋势递增的一些主键id,设计时设计为趋势递增的
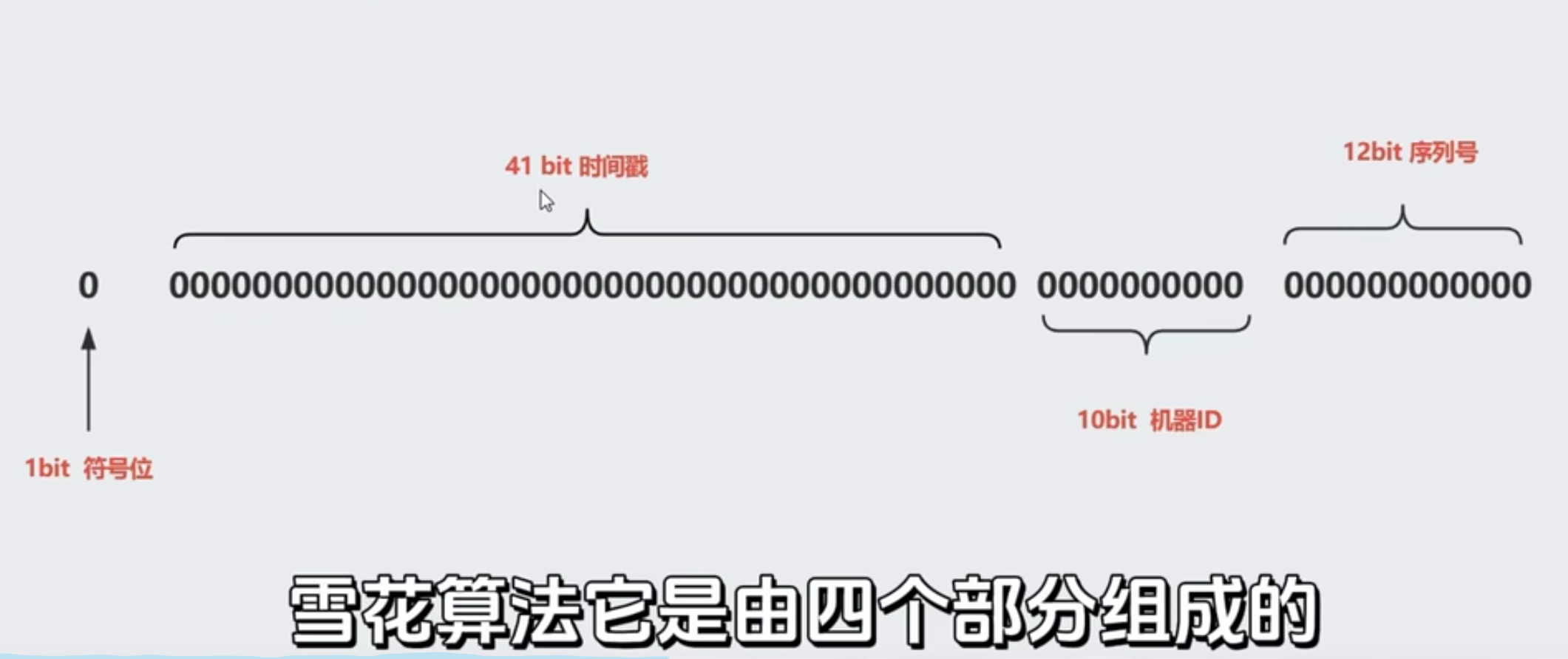
雪花算法由四部分组成,64位的二进制,然后转化成我们需要的10进制ID
有3个问题:
1、时间回拨的问题
依赖于机器时间(可能不准,甚至手动改系统时间等)。
解决方案:a.直接抛出异常(发现时间戳小于之前生成ID的时间戳时)b.等待时间恢复,并设置最大的等待时间(超过直接报错)c.采用备用的方式去生成(如随机)
2、机器ID的管理问题
借用一些框架,如服务注册组件(拿服务ID),可以拿到注册中心的实例ID。像美团的leaf它就是基于雪花算法做这样一些改进
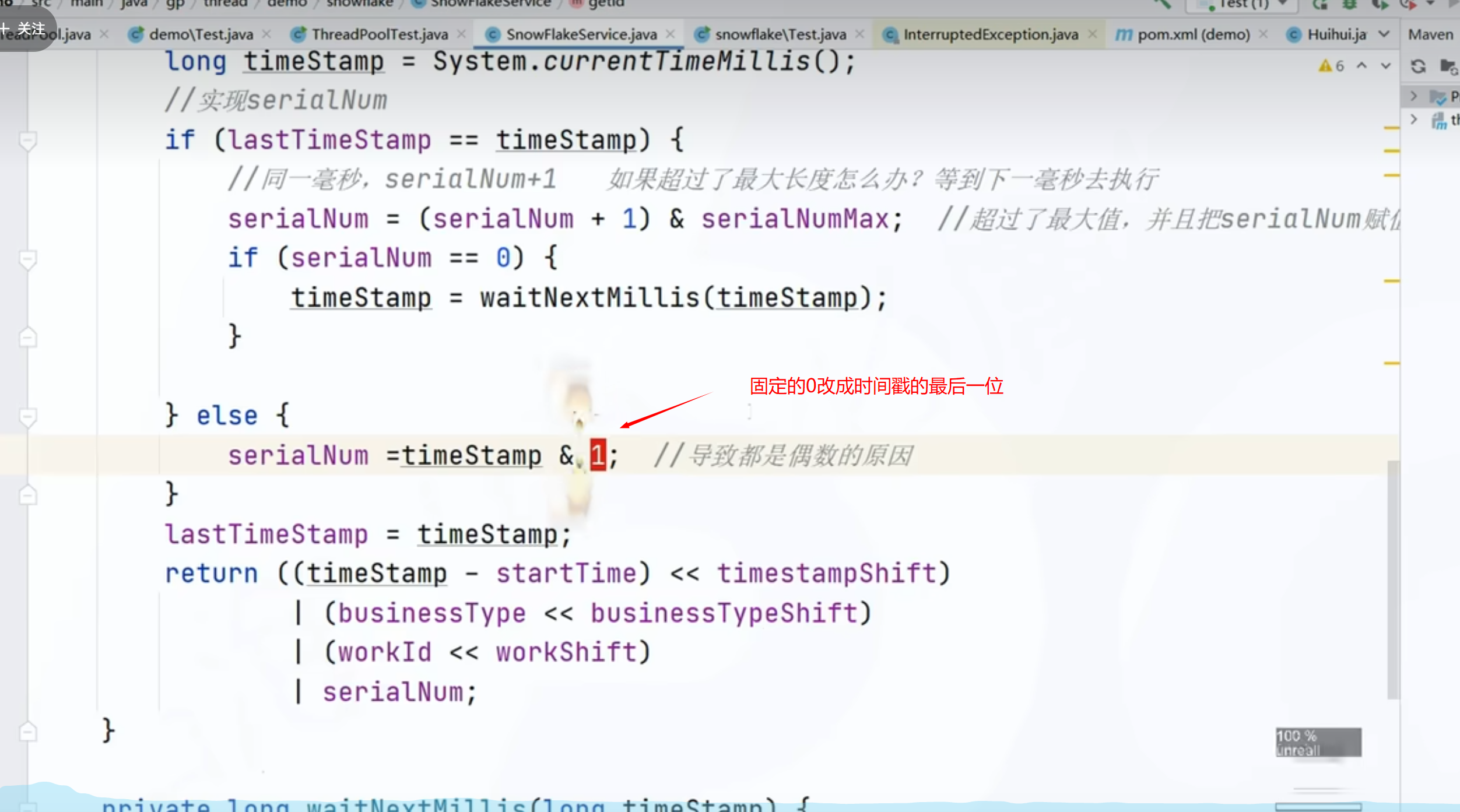
3、序列号一直是0的问题
同一时间同一机器,在并发生成的时候它才会去递增。在取模,基于ID取模分库分表的场景,可能会导致数据的偏移
因为0结尾,数据取模以后它一定会在偶数表里面,这个时候很多表可能是没有数据的
定义不同的位代表的含义,再通过位移的方式得到64bit位的二进制,然后转化为10进制

固定的0改成时间戳的最后一位
参考:【Java面试大厂真题】为什么不推荐使用数据库自增主键?也不推荐使用UUID作主键,用雪花算法会有什么问题?_哔哩哔哩_bilibili

 浙公网安备 33010602011771号
浙公网安备 33010602011771号