
【线上问题笔记】线上频繁full gc排查
频繁full gc可能原因
引起线上服务频繁full gc原因很复杂,大致有以下常见原因;
- System.gc() 引起的频繁 Full GC;这种原因导致的full gc,可以添加 -XX:+DisableExplicitGC,屏蔽 System.gc() 动作;
- 老年代没有连续可用的内存空间,触发full gc;这里我们需要分情况讨论了,一种情况是生成了大对象,而大对象直接进入老年代,空间不足就会触发full gc;另一种情况是程序生成了大量的对象,而这些对象的引用一直保持,minor gc未能成功回收它们,这些对象跃升到老年代,导致老年代内存空间不足,触发了full gc;
- 元空间不足引起的full gc;这种情况一般是设置了元空间内存大小的阈值导致的,调大{{-XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m}}阈值大小即可解决问题。
dump文件导出并下载到本地
- 首先需要导出线上服务dump文件,将文件复制到宿主机,这个流程因为研发无法操作线上容器,可以找运维代为操作;
- 第二步需要下载dump文件至本地;
- 在宿主机dump文件所在路径下执行以下命令,开启{{http server}};根据宿主机上安装的python版本不同,使用不同的启动命令;
- * #python2 的用法
* python -m SimpleHTTPServer
* #python3 的用法
* python3 -m http.server
- 本地使用{{wget}}或者{{curl}}下载dump文件;
- wget http://{宿主机ip}:8000/20210128.hprof
使用mat分析dump文件
- dump文件过大,mat打不开怎么办?
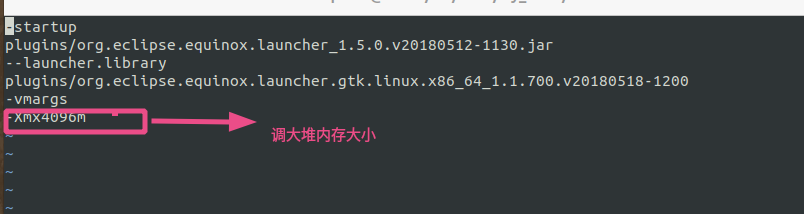
- 线上dump文件一般都有5,6G的大小,mat分析工具很有可能打不开,因为内存不足导致软件崩溃,这种情况我们得手动修改配置文件{{MemoryAnalyzer.ini}}增加软件的堆内存大小;
- 如何定位问题代码呢?
- 就拿企业管理后台的一次生产问题举例;
- 问题起因是这样的,钉钉预警群里不断发出后台服务full gc的报警,于是我们迅速找到运维同学帮忙导出dump文件分析定位问题(这里的报警避免我们自己使用{{jstat -gcutil}}等命令手动定位是不是full gc导致的服务不可用),具体定位过程如下:
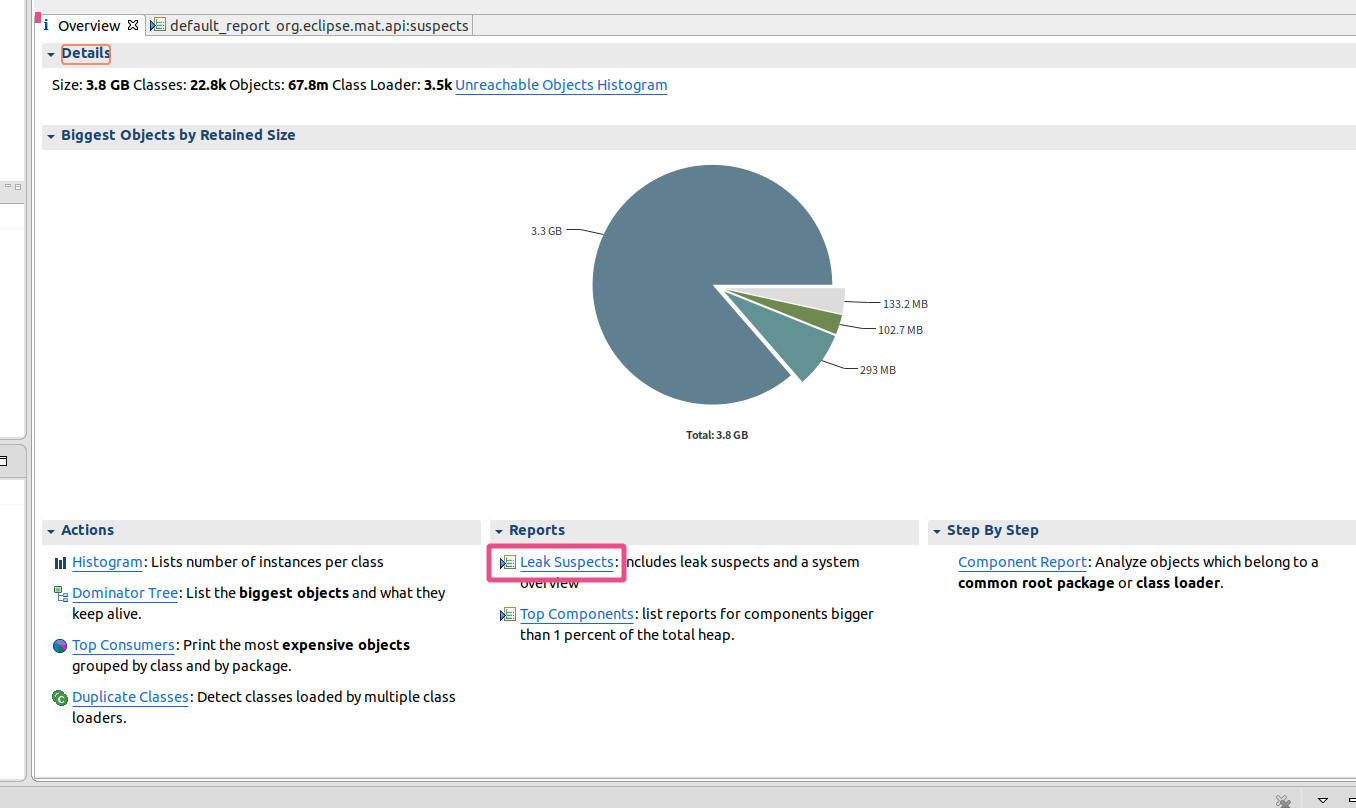
- mat这个工具很强大,帮我们分析到了leak的可疑点;打开文件找到{{leak suspects}}
- 进去之后可以找到对应的可以点{{detail}};
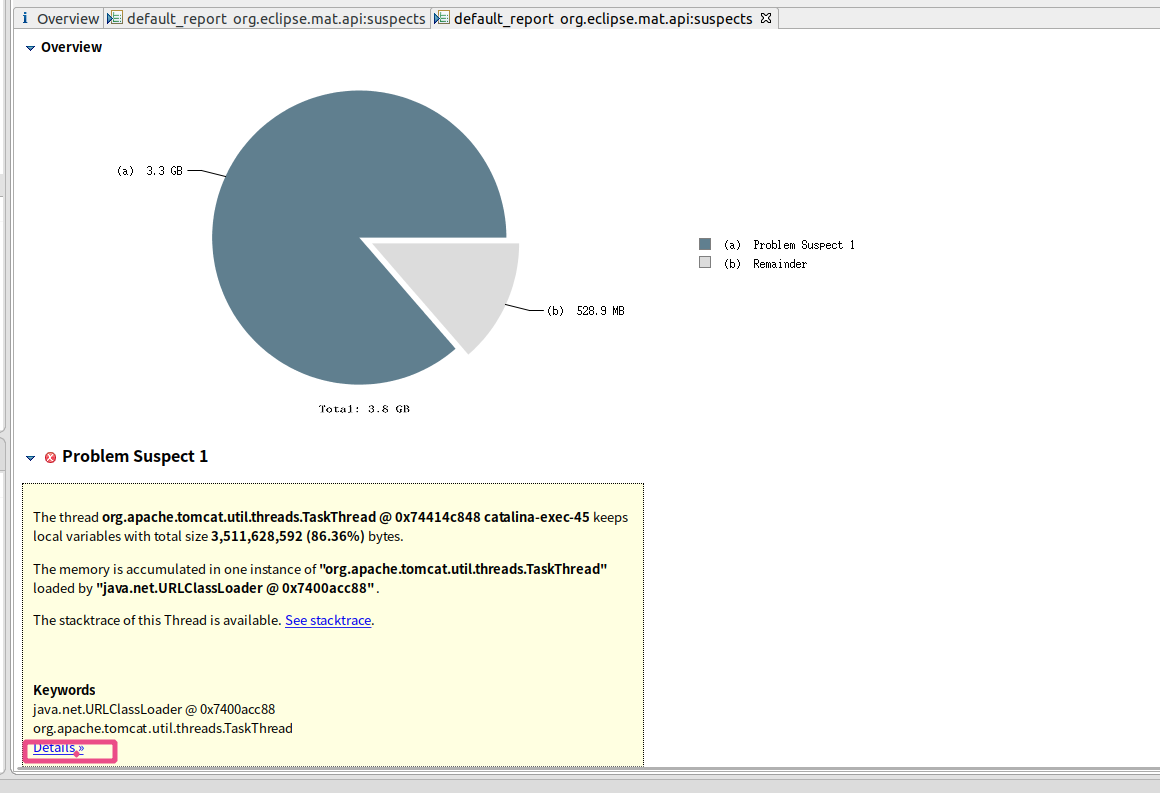
在详情中可以定位到具体问题代码;
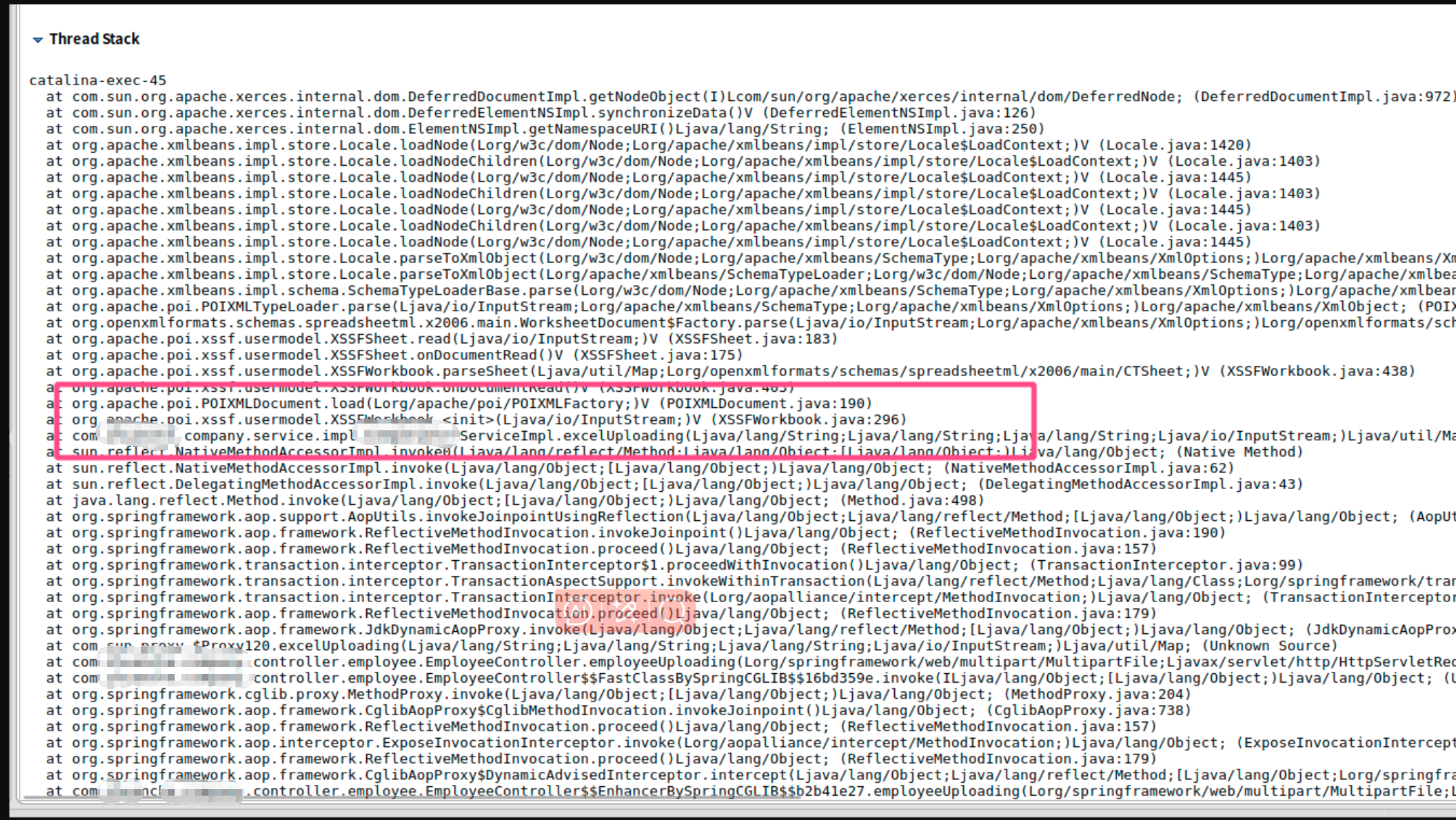
线程栈信息表明是poi这个插件在读取文件时发生了内存泄漏,随后定位到问题代码,这是一段上传excel批量添加员工的操作,检查对应的excel发现只是单sheet150行记录,理论上pom在解析文件时不会发生内存泄漏,就在百思不得其解之时,偶然发现文件大小高达15M,显然不是150行记录的量,原来是文件的锅,excel中存在大量空白行,致使文件过大,最终导致poi在解析大文件时内存泄漏,需要频繁的full gc。
- 解决方案
- 第一时间找运维临时调整堆内存大小;重启服务实例,依次上线;同时修改问题代码,限制上传文件大小;根据实际情况找合适时机上线,修复问题。
扩展阅读:
dump文件导出可以一般可以使用如下命令:
# 进入容器内找到服务进程,执行如下命令
jmap -dump:format=b,file=/my.dump pid
我们还可以通过添加jvm参数方式自动导出dump文件;
-XX:+HeapDumpOnOutOfMemoryError 设置当首次遭遇内存溢出时导出此时堆中相关信息
-XX:+HeapDumpBeforeFullGC 表示在Full GC前进行dump
-XX:+HeapDumpAfterFullGC 表示在Full GC后进行dump
-XX:HeapDumpPath=/tmp/heapdump.hprof 指定导出堆信息时的路径或文件名

 浙公网安备 33010602011771号
浙公网安备 33010602011771号