大疆嵌入式笔试
2024年大疆嵌入式秋招笔试B卷
1.应用程序可直接进行系统调用,也可以使用库函数,有的库函数涉及系统调用,有的不涉及。这对不对?
对的。应用程序可以直接进行系统调用,也可以通过库函数来执行任务。这里有几点需要注意:
系统调用:应用程序通过系统调用可以直接与操作系统内核进行交互,执行诸如文件操作、内存管理等低级功能。
库函数:许多库函数是为了简化系统调用的使用而设计的。这些库函数通常在更高级的抽象层上进行调用,比如标准库中的输入输出函数,它们可能会在内部使用系统调用。
有的库函数不涉及系统调用:一些库函数完全是在用户空间中执行,并不需要与操作系统交互,例如一些数学计算或字符串处理函数。
因此,应用程序可以选择直接使用系统调用或通过库函数来间接使用系统调用,具体选择取决于需求和设计目标。
2.使用编程语言可将系统调用封装成库函数,应隐藏系统调用的细节,使上层进行系统调用更加方便,这对不对?
对的。将系统调用封装成库函数的做法有以下几个优点:
简化接口:库函数提供了更简单、友好的接口,允许开发者更方便地进行系统调用,而无需处理底层的细节。
抽象化:封装可以隐藏系统调用的复杂性,开发者无需了解具体的实现细节,从而提高了开发效率。
错误处理:库函数可以统一处理错误,使上层调用者不必关注各种可能的错误情况,提高了代码的健壮性。
跨平台性:通过封装,可以实现跨平台的支持,使得同一套代码能够在不同的操作系统上运行而无需修改。
便于维护:如果需要更改底层实现,只需更新库函数,而不必改动使用它的多个上层应用程序。
因此,将系统调用封装成库函数是一种良好的编程实践。
3.系统调用和库函数都不依赖平台有操作性的保证接口调用的一致性
系统调用和库函数确实在一定程度上能够提供接口调用的一致性,但它们的依赖性和保证方式不同。
系统调用:
系统调用通常在操作系统层面实现。
不同的操作系统可能有不同的系统调用接口,这可能导致跨平台时不一致。
尽管操作系统会努力提供兼容性,但新的版本或不同派系的系统在系统调用方面可能会有差异。
库函数:
库函数往往在用户空间中实现,并依赖于特定的语言或框架。
通过标准库(如 C 的标准库、Python 的标准库等),库函数提供了一致的接口,使得开发者可以在不同平台上调用相同的函数。
标准库通常会处理底层的操作系统差异,从而提供统一的体验。
综上所述,库函数在提供平台无关的接口一致性方面通常更加有效,而系统调用则依赖于操作系统的兼容性。使用库函数可以更好地确保跨平台开发的一致性和可移植性。
4.假设ab是一个类,则执行ab x;语句时将自动调用该类的什么构造函数?
在执行 ab x; 语句时,将自动调用类 ab 的 默认构造函数。这是因为在没有提供构造函数参数的情况下,编译器会寻找一个无参数的构造函数来初始化对象 x。
如果类 ab 没有定义任何构造函数,编译器会自动生成一个默认构造函数。如果定义了其他构造函数但没有定义默认构造函数,且类需要提供一个无参数的方式来构造对象,则会导致编译错误。
5.计算机只能直接执行机器语言程序。
对的,计算机只能直接执行机器语言程序。机器语言是计算机能够理解和执行的最低级语言,由二进制代码组成,指令直接对应于计算机硬件的操作。其他类型的编程语言(如高级语言)需要通过编译器或解释器转换成机器语言,才能被计算机执行。
这样做的原因是:
直接控制硬件:机器语言可以直接对计算机的硬件进行控制,实现具体操作。
性能高效:机器语言指令可以被直接执行,避免了转换过程,提升了运行效率。
硬件依赖性:不同计算机架构的机器语言格式可能不同,这使得编写在某个体系结构上的机器语言程序不能在其他体系结构上直接执行。
因此,高级语言程序通常需要先被转换为机器语言才能执行。
6.冯诺依曼计算机"存储程序"工作原理的基本思想是什么?
冯诺依曼计算机的“存储程序”工作原理的基本思想可以概括为以下几点:
统一存储:程序和数据都存储在计算机的内存中,使用相同的存储机制。这意味着计算机可以处理指令和数据的一致性,增加了灵活性。
可修改性:程序可以动态修改,这意味着计算机可以根据需要读取、写入和执行存储在内存中的程序。这使得程序的自我修改成为可能。
顺序执行:计算机根据存储在内存中的机器指令的地址顺序逐条执行这些指令,依据指令流控制程序的执行过程。这种顺序性使得程序可以被顺序、跳转和循环控制。
控制单元:计算机的控制单元从内存中读取指令,解析后发出控制信号,指挥算术逻辑单元(ALU)、存储器等组件执行操作。
地址指令:指令中包含操作码(操作类型)和地址部分(操作的数据存储地址),使得指令能够明确指向内存中的特定数据。
这种“存储程序”的设计理念极大地提高了计算机的灵活性和功能性,形成了现代计算机的基础架构。
7.下列哪个不是Linux内核里面任务调度切换的时间点?A,中断函数处理完毕返回到用户台,b,系统调用处理完毕,从内核态返回到用户态。内核主动调用schedule()函数,try_to _wake_up函数唤醒任务。
在Linux内核中,任务调度切换的时间点包括:
A,中断函数处理完毕返回到用户态。
B,系统调用处理完毕,从内核态返回到用户态。
内核主动调用 schedule() 函数,这是进行任务调度的主要方式。
而 try_to_wake_up 函数 主要用于唤醒等待的任务,但它并不会直接导致任务切换,因此也不是调度切换的时间点。
因此,try_to_wake_up 函数唤醒任务 不是任务调度切换的时间点。
8.Linux系统中哪些函数调用时系统不会马上分配物理内存?
当然可以!以下是更详细的说明关于 Linux 系统中不会立即分配物理内存的函数和它们的工作原理:
1. malloc()
功能:在用户空间中分配内存。
内存分配:malloc() 在调用时仅分配虚拟内存。实际的物理内存将仅在访问分配内存时(例如写入数据)才会被请求。
2. mmap()
功能:将文件或设备映射到进程的虚拟地址空间,允许内存映射I/O。
内存分配:mmap() 可能创建一个内存映射区域,但不分配物理内存。实际物理页面在读取或写入映射区域时被分配。
3. vmalloc()
功能:在内核中分配虚拟内存,允许不连续的物理内存分配。
内存分配:vmalloc() 会为请求的虚拟地址空间分配,但背后的物理内存可能只在访问时才被分配。
4. kmap()
功能:在内核中将物理页映射到虚拟地址空间,用于按需访问物理内存。
内存分配:在调用时并不直接分配物理内存,只有在实际访问这些页时,物理内存才会被激活。
5. get_free_page()
功能:分配一个物理页面。
内存分配:虽然此函数分配物理页面,但操作系统的内存管理可能会延迟一些页面的分配直到真正需要使用它们。
6. 延迟分配的好处
性能优化:延迟分配可以减少不必要的物理内存分配,特别是在实际使用内存之前,避免了内存的浪费。
内存回收:通过推迟实际分配,操作系统可以更有效地管理内存,回收未使用或不再需要的内存。
这些机制使得 Linux 系统在内存管理上更加高效和灵活,能够适应不同的应用需求和运行环境。
9.USB3.0接口的引脚配置是什么?
USB 3.0 接口的引脚配置如下:
USB 3.0 Type-A 接口引脚配置:
引脚 1: VBUS(电源,+5V)
引脚 2: D-(数据线,负极)
引脚 3: D+(数据线,正极)
引脚 4: GND(接地)
引脚 5: SSRX-(SuperSpeed 接收,负极)
引脚 6: SSRX+(SuperSpeed 接收,正极)
引脚 7: GND_DRAIN(接地排水)
引脚 8: SSTX-(SuperSpeed 发送,负极)
引脚 9: SSTX+(SuperSpeed 发送,正极)
USB 3.0 Type-B 接口引脚配置:
引脚 1: VBUS(电源,+5V)
引脚 2: D-(数据线,负极)
引脚 3: D+(数据线,正极)
引脚 4: GND(接地)
引脚 5: SSRX-(SuperSpeed 接收,负极)
引脚 6: SSRX+(SuperSpeed 接收,正极)
引脚 7: GND_DRAIN(接地排水)
引脚 8: SSTX-(SuperSpeed 发送,负极)
引脚 9: SSTX+(SuperSpeed 发送,正极)
总结
USB 3.0 在原有的 USB 2.0 基础上增加了 SuperSpeed 数据线,支持更高的数据传输速率,达到了 5 Gbps。这个引脚配置使得 USB 3.0 向后兼容 USB 2.0,可以在相同的连接器上使用。
10.在Linux系统中,关于pagecache的工作机制和行为是什么?
在Linux系统中,pagecache 是内核用来缓存文件系统数据的一种机制,它显著提高了文件操作的性能。以下是其工作机制和行为的主要方面:
工作机制
缓存机制:
当应用程序访问文件时,内核会将该文件的数据载入到内存中,以减少后续访问的延迟。
文件数据通过页(通常为4KB或更大)进行管理,这些页被称为页缓存(pagecache)。
读取操作:
当应用程序请求文件数据时,内核首先检查 pagecache 是否已经缓存了所需的数据页。如果存在,直接从内存返回,避免磁盘I/O。
如果数据不在缓存中,内核会从磁盘读取数据,并将其存储在 pagecache 中,以备后续使用。
写入操作:
对文件的写操作首先会更新 pagecache 中的数据页,而不是立即写入磁盘。
定期或在特定条件下,内核会将缓存中的脏页(已修改但未写入磁盘的页)刷新到磁盘。这一过程称为好写(flush)或写回(write-back)。
行为特点
延迟写入:
通过将写操作推迟到适当的时候,可以减少对磁盘的频繁访问,提高整体性能。这种策略称为写回策略。
空间管理:
pagecache 占用的内存是动态分配的,内核会根据系统的可用内存情况来管理。如果系统内存紧张,内核会释放不再使用的缓存页,以腾出空间给其他进程。
共享性:
pagecache 允许多个进程共享同一文件的数据。当多个进程同时读取相同的文件时,只有当数据在缓存中时,才会被有效利用。
IO调度:
Linux内核利用独特的I/O调度算法(如CFQ、Deadline等)来优化对磁盘的请求,确保优先处理高优先级的I/O。
文件系统交互:
pagecache 与文件系统层紧密集成,任意文件操作(如读取、写入、删除等)都会被影响并能利用缓存的优势。
总结
pagecache 机制是Linux十分重要的性能优化手段,通过有效利用内存资源,降低了对磁盘的访问频率,提高了文件操作的速度。理解并合理配置 pagecache 可以大幅提升系统的整体性能和响应能力。
11.rtos stack中调用嵌套函数会增加栈的使用。
是的,在实时操作系统(RTOS)中,调用嵌套函数确实会增加栈的使用。以下是具体原因:
1. 栈的基本概念
栈 是用来存储函数调用的返回地址、局部变量和参数的内存区域。每次函数调用时,都会在栈上分配一定的空间。
2. 嵌套调用的影响
当一个函数调用另一个函数时,栈中会为每个函数的局部变量和返回地址分配额外的空间。
如果存在多个嵌套函数调用,栈的深度会随着每次调用而增加,从而消耗更多的栈空间。
3. 对系统的影响
栈溢出:如果嵌套调用层级过深、或每个函数使用的栈空间过大,可能会导致栈溢出,尤其是在资源受限的嵌入式系统中。
性能问题:过多的栈使用可能导致上下文切换变慢,因为需要更多的时间来保存和恢复堆栈状态。
4. 优化策略
栈大小配置:在RTOS中,根据任务的需求合理配置栈大小。
避免深度嵌套:尽量减少函数的嵌套深度,或者使用非递归的算法。
使用静态内存:在合适的情况下,使用静态或全局变量来替代局部变量,减少栈的使用。
总之,管理好栈的使用对于实时操作系统的稳定性和性能非常重要。
12.rtos stack的元素是按照后进先出的顺序进行操作。
是的,在实时操作系统(RTOS)中,栈(stack)的操作遵循后进先出(LIFO,Last In First Out)的原则。这意味着:
栈的操作特性
后进先出:
最后被压入栈中的元素会最先被弹出。这种特性使得栈非常适合用于函数调用管理。
函数调用:
每次函数调用时,函数的返回地址、局部变量和参数等都会被压入栈中。
当函数执行完毕,返回到调用它的函数时,这些数据会被从栈中弹出。
数据存取:
栈顶的元素代表当前活动的函数或任务,进一步的操作总是对栈顶的元素进行。
优势和应用
简化管理:后进先出机制使得函数调用和返回过程简单高效,减少了对复杂数据结构的需求。
上下文切换:在RTOS中,任务切换时,当前任务的栈状态会被保存,并在恢复中再次使用。
总结
后进先出的栈操作模式是RTOS运行的基础部分,确保了函数调用和任务管理的高效性。
13.在arm架构中,关于LR寄存器的描述是什么?
在ARM架构中,LR(Link Register)寄存器的主要作用是存储函数调用的返回地址。以下是LR寄存器的一些关键点:
1. 函数调用
当一个函数被调用时,程序计数器(PC)将指向调用后的位置,LR寄存器会保存这个地址,以便在函数执行完毕后能够正确返回到调用点。
2. 返回指令
在ARM架构中,通常使用 BX LR 或者 MOV PC, LR 指令来返回到调用函数之前的地址。
3. 嵌套调用
在嵌套函数调用中,每次调用新的函数,LR寄存器的值都会被更新。为了正确返回到每个函数的调用点,通常需要将LR的值保存到栈中。
4. 异常处理
在异常或中断发生时,LR寄存器可能记录异常返回地址,以便在处理完异常后返回到正确的执行点。
5. 移动和特定用途
在ARM的某些模式下,例如ARM和Thumb模式,LR寄存器的存储和使用可能有所不同。Thumb状态下,LR的高位会被设置为1,表示返回到Thumb状态。
总结
LR寄存器是ARM架构中重要的寄存器,用于管理函数调用和返回地址,它在程序控制流和异常处理方面发挥着关键作用。
14.假如你设计一个c++类,并将其析构函数标记为delete,下列哪种设计意图是合理的?a,你希望内的对象可以在站上创建并自动销毁。但不希望在堆上分配,b你希望类的对象只能在堆上分配,并且由外部代码控制其生命周期。c,你希望类的对象可以被复制和移动。
在C++中,如果将类的析构函数标记为 delete,意味着该类的对象不能被销毁。这种设计意图通常合理的选项是:
合理的设计意图
a,你希望类的对象可以在栈上创建并自动销毁,但不希望在堆上分配。
解释
选项 a:这种情况下,使用 delete 标记析构函数可以防止在堆上分配对象,这在某些情况下是合适的。例如,如果你希望类的实例只有栈上的生命周期,可以通过这种机制来阻止用户在堆上使用 new 关键字。
选项 b:如果你希望对象只能在堆上分配并控制其生命周期,析构函数通常应该是公有的而不是 delete。
选项 c:如果你希望对象可以被复制和移动,构造函数和析构函数都不能被标记为 delete,因为这会阻止对象的正常管理。
因此,选项 a 是合理的设计意图。
15.在GDB调试中,用于查看变量的值的命令是哪个
在GDB调试中,用于查看变量值的命令是 print 或 p。
16.最能确保提高页面缓存访问储存的命中率的改进途径是什么?
提高页面缓存访问存储的命中率,可以通过以下途径来实现,特别是结合LRU(最近最少使用)策略和页面数的管理:
1. 实施LRU替换策略
LRU(最近最少使用):该策略优先保留最近使用的页面,因而可以显著提高页面的命中率。LRU 会根据页面访问的时间轨迹来决定哪些页面应当被替换,这样频繁访问的页面不会被移除。
2. 优化页面数
合理配置页面大小和数量:页面大小的选择直接影响到系统的页面数。较小的页面可能会导致内存碎片增加,但可以提高空间局部性。适当调整页面大小,以便尽可能提高命中率。
增加页面缓存的总数:如果可能的话,增加页面缓存的数量,可以提高缓存的容量,进而提高命中率。
3. 监测和分析访问模式
分析访问模式:根据应用程序的访问行为,调整LRU策略的实现,确保频繁访问的页面始终保持在缓存中。
4. 预读取策略
实施预读取:借助预测算法,提前加载可能会被访问的页面,减少页面缺失。
5. 减少页面换入换出
减少频繁的页面置换:尽量避免频繁的页面换入换出,确保缓存中保持有效页面,尤其是在访问模式较稳定的情况下。
通过结合有效的LRU策略和优化页面数管理,可以大幅提高页面缓存的命中率,提升系统的整体性能
17.Linux内核调度策略有哪些?
Linux内核调度策略主要包括以下几种:
1. 完全公平调度器 (CFS)
CFS 是 Linux 2.6.23 引入的默认调度器。它基于时间片和红黑树算法,旨在使所有进程公平地使用 CPU 资源。
2. 实时调度策略
SCHED_FIFO:一种实时优先级调度策略,为高优先级进程提供尽可能快速的响应,不会被其他进程抢占。
SCHED_RR:与 SCHED_FIFO 类似,但在相同优先级的进程之间轮流调度,采用时间片方式。
3. 脑死亡调度 (SCHED_DEADLINE)
用于支持基于时间的实时任务调度,允许用户为任务定义最迟完成时间和执行周期。
4. 时间共享调度
针对交互式和非实时进程的调度,确保良好的响应速度。
5. CFS的调度类
Linux内核支持多种调度类,除了上述调度策略外,内核允许开发者实现自定义调度类以满足特定需求。
6. 其他调度策略
SCHED_BATCH:用于长时间运行的批处理任务,优先级较低,适合对响应时间要求不高的任务。
SCHED_IDLE:最低优先级,适用于空闲时运行的任务,减少对其他任务的影响。
7. 能源感知调度
在移动和嵌入式设备中,调度策略可能会考虑节能,调整任务运行以延长电池续航。
总结
Linux内核提供多种调度策略,以支持不同类型的应用和任务,确保系统的响应性和资源的有效利用。
18.R数据通道频率是时钟通道频率的几倍?
在USB(通用串行总线)协议中,R数据通道频率通常是时钟通道频率的两倍。这一点在USB 2.0和更高版本的规范中都有体现。
解释
时钟通道:用于同步数据传输,提供必要的时钟信号。
R数据通道:用于实际的数据传输,频率为时钟信号的两倍,这样可以在多个时钟周期内传输更多数据。
这种设计使得数据传输更加高效,支持更高的数据带宽。
19.UART可以实现全双工通讯,常用波特率为9600到115200。
是的,UART(通用异步收发传输器)可以实现全双工通讯。这意味着它可以同时进行发送和接收数据。常用的波特率范围确实从 9600 bps 到 115200 bps,这使得UART在许多应用中得到了广泛的使用。
关键点
全双工通讯:UART通过独立的发送和接收线(TX和RX)实现全双工,允许同时发送和接收数据。
波特率:波特率是数据传输速率,常用值包括:
9600 bps:常用于基本串行通信。
115200 bps:适用于对速度要求较高的应用,如数据采集或高速设备。
应用场景
嵌入式系统:常用于微控制器之间的通信。
串行设备:连接传感器、模块或电脑等设备。
UART的全双工特性和灵活的波特率设置,使其在串行通信中非常实用。
20.RS485总线使用差分信号进行传输。
是的,RS-485总线使用差分信号进行数据传输。这种传输方式具有以下优点:
关键特性
差分信号传输:
RS-485通过两条信号线(A和B)发送相反的电压信号。这种差分传输可以有效抵抗电磁干扰(EMI),提高信号的抗干扰能力。
长距离传输:
RS-485支持较长的传输距离,通常可达到1200米(约4000英尺),适合于工业环境中的远距离通信。
多点通讯:
支持多个设备(通常达到32个)在同一总线上进行通信,非常适合应用于网络系统。
更高的传输速率:
传输速率可以达到10 Mbps,适合高数据速率的需求。
应用场景
工业自动化:常用于控制系统和传感器网络。
建筑自动化:如楼宇监控和管理系统。
数据采集:适合需要远程监测和数据收集的应用。
总之,RS-485的差分信号特性使其在多个应用中具有显著优势,尤其是在噪声较多和传输距离较远的环境中。
21.I2C是一种半双工异步通讯总线。
是的,I2C(Inter-Integrated Circuit)是一种半双工异步通信总线。
关键特性
半双工通讯:
I2C通过同一条数据线(SDA)进行数据的发送和接收,但不能同时进行。数据的传输是双向的,但在任意时刻只能有一个方向的数据流。
同步传输:
I2C使用时钟线(SCL)进行同步,确保主从设备之间的数据传输的时序一致。
多主多从:
I2C支持多主机和多从机的架构,一个总线上可以连接多个设备,主机可以控制从机进行数据传输。
地址寻址:
每个从机有唯一的7位或10位地址,主机通过地址选择要通信的从机。
应用场景
传感器接口:广泛用于连接各种传感器和微控制器。
嵌入式系统:在各类嵌入式设备中进行短距离通信。
低速设备:适合用于需要较低速度通信的应用,通常不超过400 kbps(标准模式),有些情况下可以达到3.4 Mbps(高速模式)。
总之,I2C是一个灵活且广泛应用的通信协议,尤其适用于多个设备之间的低速数据交换。
22. 802.11b是蓝牙技术吗?
802.11b 不是蓝牙技术。它属于无线局域网(WLAN)标准,主要用于Wi-Fi网络。以下是两者的主要区别:
802.11b
类别:无线局域网标准(Wi-Fi)。
频段:工作在2.4 GHz频段。
传输速率:最高可达11 Mbps。
用途:主要用于构建无线局域网,提供数据通信。
蓝牙
类别:短距离无线通信技术。
频段:也工作在2.4 GHz频段,但与Wi-Fi及其他设备共享。
传输速率:通常在1 Mbps到3 Mbps之间(取决于版本)。
用途:用于短距离设备之间的无线连接,如耳机、键盘、手机等。
虽然两者都在2.4 GHz频段操作,但它们的应用、传输速率和通信范围是不同的。
23.虚拟内存为进程提供了一致的地址空间,从而简化了内存管理,对吗?
是的,虚拟内存为进程提供了一致的地址空间,这确实简化了内存管理。以下是相关的几个要点:
虚拟内存的优势
统一地址空间:
每个进程都有其独立的虚拟地址空间,使得它们之间的地址不会冲突。每个进程视图中的内存地址都是从0开始的。
内存隔离:
虚拟内存提供了进程之间的隔离,提高了系统的安全性和稳定性。如果一个进程崩溃,不会影响其他进程的内存。
简化管理:
进程不需要关心物理内存的组织和管理。操作系统负责将虚拟地址映射到物理内存,简化了编程模型。
高效利用内存:
虚拟内存允许系统以更加灵活的方式使用物理内存,通过页面替换算法,确保活跃的页面保留在内存中,不常用的页面可以被换出以释放内存。
需求分页:
系统可以按需加载页到内存中,优化内存使用,避免一次性加载所有进程需要的内存。
综上所述,虚拟内存确实提高了内存管理的效率与简洁性。
24.操作系统通过将一个虚拟内存区域与磁盘上的对象关联起来,以初始化该虚拟内存区域的过程称为内存分配。对吗?
不完全正确。操作系统通过将一个虚拟内存区域与磁盘上的对象关联起来的过程更准确地称为内存映射(memory mapping),而不是简单的内存分配。
主要概念
内存映射:
此过程涉及将磁盘文件或对象的内容映射到虚拟内存空间,使得程序能够直接访问这些数据。
内存分配:
内存分配是指操作系统为进程分配内存的过程,这包括分配虚拟内存区域,但不特指与磁盘对象的关联。
结论
因此,虽然将虚拟内存区域与磁盘对象的关联涉及初始化虚拟内存,但这一过程更具体地称为内存映射,而内存分配是一个更广泛的过程
25.MMU用来将虚拟地址转换为物理地址。
是的,MMU(内存管理单元)用于将虚拟地址转换为物理地址。以下是一些关键点:
MMU的功能
虚拟地址到物理地址的映射:
MMU负责将进程生成的虚拟地址转换为对应的物理地址,使得程序可以使用更大的虚拟地址空间,而不必直接管理物理内存。
页表:
MMU使用页表来存储虚拟地址和物理地址之间的映射关系。页表记录了每个虚拟页面对应的物理页面。
地址转换:
当CPU发出一个虚拟地址时,MMU查找页表以获取相应的物理地址,并进行转换,允许访问真正的物理内存。
支持内存保护和隔离:
MMU确保不同进程之间的内存是隔离的,提高系统的安全性和稳定性。
总结
因此,MMU是关键的硬件组件,用于实现虚拟内存机制,并有效管理内存地址的转换。
26.当处理器访问的虚拟内存也不在物理内存中会触发缺页异常,对吗?
是的,当处理器访问的虚拟内存不在物理内存中时,会触发缺页异常(page fault)。
关键点
缺页异常:
当进程试图访问一个未映射到物理内存的虚拟地址时,MMU会产生缺页异常,通知操作系统。
处理过程:
操作系统会捕获这个异常,检查虚拟地址是否有效,并决定如何处理。如果该页面在磁盘上(例如,交换区或文件存储),操作系统会将其加载到物理内存中。
页面调度:
操作系统可能需要选择一个已在物理内存中的页面进行换出,以便腾出空间来加载请求的页面,这通常涉及页面置换算法(如LRU、FIFO等)。
恢复执行:
一旦页面被加载到物理内存中,处理器会重新尝试访问该虚拟地址,进程能够继续执行。
总结
因此,缺页异常是虚拟内存管理的关键机制,能够有效支持内存的动态管理和保护。
27.volatile可以修饰一个指针吗? volatile修饰的变量可以保证多线程下的原子访问,对吗?volatile可以跟const一起使用吗?
1. volatile可以修饰一个指针吗?
是的,volatile可以修饰指针。具体来说,可以这样使用:
volatile int* ptr;
这表示指针 ptr 所指向的整型值是 volatile 的,意味着这个值可能会在程序的其他地方被改变(例如,通过硬件或其他线程),编译器不会进行优化。
2. volatile修饰的变量可以保证多线程下的原子访问吗?
不完全正确。volatile 仅表示变量的值可能被异步修改,防止编译器对该变量进行优化。然而,它并不能保证原子性。要实现多线程的原子访问,需要使用其他机制,如互斥锁(mutex)或原子操作。
3. volatile可以跟const一起使用吗?
是的,volatile可以与const一起使用,形成一个只读的volatile变量。例如:
const volatile int value;
这表示 value 是一个 volatile 变量,且只能被读取,不能被修改,但其值可能会被外部因素(如硬件或其他线程)改变。
总结
volatile可以修饰指针。
volatile不保证原子性。
volatile可以与const一起使用。
28.不同优先级线程竞争同一把锁可能会导致优先级反转。
是的,不同优先级的线程竞争同一把锁可能会导致优先级反转问题。
关键点
优先级反转:
当一个高优先级线程需要被一个低优先级线程持有的锁时,低优先级线程会阻塞。此时,如果有一个中等优先级的线程运行,它可能会使得低优先级线程无法运行,从而导致高优先级线程被长期阻塞。
示例:
假设有三个线程:A(高优先级)、B(中等优先级)、C(低优先级)。线程 C 持有一把锁,线程 A 试图获取这把锁,但由于 C 正在执行,A 被阻塞。如果此时线程 B 被调度并执行,那么 C 将无法执行,从而导致 A 无法继续运行。
解决方案:
优先级继承:低优先级线程在持有锁时提升它的优先级至高优先级线程的优先级,直到释放锁。
优先级天花板:为共享资源设定一个固定的高优先级,以防止低优先级线程阻塞高优先级线程。
总结
优先级反转是多线程编程中的一个重要问题,了解并采取适当措施来解决它是确保系统性能的关键。
29.在Linux系统中,两个处于ready态的线程,高优先级的线程一定会先于低优先级的线程运行。
在Linux系统中,两个处于ready态的线程,高优先级线程并不一定会立即先于低优先级线程运行。这是由于以下几个原因:
关键因素
调度策略:
Linux使用多种调度策略,例如CFS(完全公平调度器)和实时调度策略(如 SCHED_FIFO 和 SCHED_RR)。在实时策略下,高优先级线程会优先执行,但在CFS策略下,调度并不是简单的优先级排序。
时间片和计划:
即使高优先级线程处于ready状态,如果低优先级线程正在执行且其时间片尚未耗尽,它也可能继续运行。调度器会考虑线程的时间片和其他因素。
内核负载和调度延迟:
在系统负载较高或发生上下文切换时,调度可能会受到影响,因此高优先级线程可能会延迟执行。
总结
虽然高优先级线程在ready状态下有更高的执行优先权,但在实际运行时,由于调度策略和系统状态的影响,它不一定总是优先运行。
30.在ARM CPU中,在同一线程中,CPU会按照c语言代码顺序执行。
在ARM CPU中,虽然C语言代码通常按照书写的顺序执行,但实际上,CPU的执行过程可能受到多种因素的影响,导致并不总是严格按照代码顺序执行。这些因素包括:
关键因素
编译器优化:
编译器可能会进行优化,如重新排序代码,以提高性能。有时这会导致指令的执行顺序与源代码不完全一致。
流水线架构:
ARM CPU通常采用流水线架构,多个指令可以在不同阶段同时处理,可能会造成指令的实际执行顺序与代码顺序不同。
内存访问:
在多核或多线程环境中,内存访问的延迟或冲突也可能影响指令的执行顺序。
中断和异常:
如果发生中断或异常,当前线程的执行可能被暂停并转而执行中断处理程序,这也会影响程序的控制流。
总结
尽管在同一线程中C语言代码通常会按照顺序执行,但由于许多因素的影响,实际的执行结果可能并不总是严格按代码顺序。因此,特别是涉及多线程或并发编程时,需要注意这些潜在的顺序问题。
31.MMU负责地址虚实转换,同一物理地址在不同进程上的虚拟地址可能不一样。
是的,MMU(内存管理单元)负责将虚拟地址转换为物理地址,并且同一物理地址在不同进程中的虚拟地址确实可能不一样。
关键点
虚拟地址与物理地址:
每个进程都有独立的虚拟地址空间,MMU通过页表将虚拟地址映射到物理地址。
地址空间隔离:
不同进程的虚拟地址空间是独立的,意味着进程A中的虚拟地址0x1000可能对应于物理地址0xABCDEF,而进程B中的虚拟地址0x1000可以映射到不同的物理地址,这样可以避免地址冲突。
内存保护:
这种地址映射机制不仅提供了灵活的内存管理,也增强了进程之间的隔离和保护。
总结
因此,MMU使得同一物理地址可以在不同进程中通过不同的虚拟地址进行访问,确保了内存的有效管理与安全性。
32.DMA搬运内存过程中不会占用CPU,所以可以使用DMA优化CPU loading。
是的,DMA(直接内存访问)在数据搬运过程中不会占用CPU,从而可以有效地优化CPU的负载。
关键点
DMA的工作原理:
DMA控制器可以直接在内存和外设之间传输数据,而无需CPU的干预。这样,CPU可以继续执行其他任务,提高整体系统的效率。
CPU负载优化:
通过使用DMA,CPU可以在数据传输过程中处理其他计算或操作,减少拥塞和提高资源的使用率。
降低延迟:
DMA可以减少数据传输的延迟,特别是在需要大量数据移动的场景中(如音视频流、网卡数据包等),这对实时系统尤为重要。
中断处理:
一旦DMA传输完成,DMA控制器会生成中断通知CPU,这样可以在完成传输后再进行后续处理。
总结
综上所述,使用DMA可以显著减轻CPU的负载,使其更加高效地执行其他任务,从而提高整个系统的性能。
33.将整型变量赋值给另一个整型变量是原子操作,可由一条汇编指令完成。
是的,将整型变量赋值给另一个整型变量通常是一个原子操作,并且可以由一条汇编指令完成。这种操作在大多数现代处理器体系结构中,例如x86或ARM,都是原子性的,意味着它不会被中断或打断。
关键点
原子性:
原子操作是不会被其他线程或处理器中断的操作。对于整型赋值,由于它只涉及单一的数据移动,通常在硬件层面上保证了原子性。
汇编指令:
赋值操作通常可以通过简单的汇编指令(如 MOV 指令)实现。这样可以确保在执行赋值时,操作是不可分割的。
多线程环境:
在多线程编程中,使用原子操作可以避免竞态条件。如果只涉及基本类型(如整型),赋值通常是安全的,不需要额外的锁机制。
注意事项
尽管赋值本身是原子操作,但对整型变量的其他操作(如增加、减少)可能不是原子性的,尤其是在多处理器系统中。在这些情况下,需要使用锁或原子操作库提供的函数来确保整体的原子性。
总结
因此,将整型变量赋值给另一个整型变量通常是一个原子操作,并可以通过一条汇编指令完成。
34.一个多核CPU的不同核心可以同时运行不同的操作系统。
是的,一个多核CPU的不同核心可以同时运行不同的操作系统。这种架构通常被称为异构多核系统或多虚拟化环境。
关键点
核心独立性:
在多核CPU中,每个核心可以独立地执行任务,包括不同的操作系统。如果硬件设计支持,这允许某些核心运行Linux,而其他核心可能运行Windows或其他操作系统。
虚拟化技术:
通过虚拟化技术(如KVM、VMware等),可以在同一物理CPU上创建多个虚拟机,每个虚拟机可以运行不同的操作系统。这些虚拟机可以分配到不同的CPU核心上。
应用场景:
这种能力适用于服务器环境、实验室研究以及某些复杂的嵌入式系统,可以实现CPU资源的灵活利用和多样化用途。
硬件支持:
需要注意,具体的支持能力取决于硬件架构和CPU设计,不是所有的多核处理器都支持这样的特性。
总结
因此,多核CPU的不同核心确实可以同时运行不同的操作系统,这为系统设计和资源管理提供了更大的灵活性
35.SPI同步通信,I2C是异步通信。SPI涉及地址分配 I2C用于连接大量的设备,对吗?
SPI(串行外设接口)
同步通信:
SPI是一种同步通信协议,采用时钟信号来协调数据传输。
地址分配:
SPI通常不需要地址分配。每个外设通常通过片选信号(CS)进行选择,允许在同一总线上连接多个设备。
优势:
SPI提供高速数据传输,适合需要快速通信的应用。
I2C(互连集成电路)
异步通信:
I2C是一种同步通信协议,也采用时钟信号来协调数据传输,因此它不是异步协议。
地址分配:
I2C支持地址分配,每个设备都有唯一的地址,便于在同一总线上连接多个设备。
用于连接多个设备:
I2C特别适合连接大量设备,最多可以连接127个设备。
总结
SPI是同步通信协议,使用片选信号控制设备,不进行地址分配。
I2C是同步通信协议,支持地址分配,适合连接多个设备。
36.TCP的拥塞控制通过调整发射窗口来控制发射速率。第二,用手控制是为了避免网络拥塞,防止传输性能下降。第三,TCP的拥塞控制可以仅依赖于接收方的反馈。第四,用设窗口的大小是动态调整的。第五,用色控制的唯一目的是限制接收方的数据处理速度。
TCP拥塞控制
通过调整窗口控制发射速率:
正确。TCP的拥塞控制确实通过调整拥塞窗口(cwnd)来控制发送速率,从而避免网络拥塞。
避免网络拥塞:
正确。TCP拥塞控制的主要目标是避免网络拥塞,防止数据传输性能下降。
接收方的反馈:
不完全正确。TCP的拥塞控制不仅依赖于接收方的反馈,还依赖于网络的反馈信息(如数据包丢失情况)。接收方的窗口大小主要用于流量控制,而非拥塞控制。
窗口大小动态调整:
正确。拥塞窗口的大小是动态调整的,TCP会根据网络状况(如延迟、丢包)来调整窗口大小。
限制接收方的数据处理速度:
不完全正确。TCP的流量控制(通过接收方的窗口大小)主要目的是避免接收方处理不及,而拥塞控制则是根据网络的实际情况调整发送速率,是两个不同的功能。
总结
TCP拥塞控制通过调整窗口大小来控制发送速率,以避免网络拥塞。
它并不仅仅依赖接收方的反馈,而是同时考虑网络状态。
流量控制和拥塞控制是TCP中的两个不同机制。
37. Gcc -S可以将c代码编译成汇编代码。
是的,gcc -S 命令可以将C代码编译成汇编代码。具体来说,这个命令的作用是将源代码中的C语言编译成对应的汇编语言文件,而不会生成目标文件或可执行文件。
gcc -S source_file.c
输出文件:
执行完该命令后,会生成一个 .s 后缀的汇编语言文件,文件名通常与源文件相同。例如,source_file.c 会生成 source_file.s。
用途:
该命令对于学习和分析生成的汇编代码很有用,特别是在进行性能优化或理解编译过程时。
总结
因此,gcc -S 确实可以将C代码编译成汇编代码,用于进一步的分析或处理
38. If #defined symbol可用来判断symbol是否被定义。
是的,#defined 符号在C和C++中用于判断某个宏是否已被定义。这种用法通常与条件编译指令一起使用。
#ifdef SYMBOL
// 如果 SYMBOL 被定义,执行这段代码
#endif
#define MY_MACRO
#ifdef MY_MACRO
// 这个块会被编译
printf("MY_MACRO is defined.\n");
#else
// 这个块不会被编译
printf("MY_MACRO is not defined.\n");
#endif
39.Include <filename.h>会直接到库函数所在的目录去查找头文件。
是的,#include <filename.h> 语句用于引用标准库或外部库的头文件,其查找机制如下:
查找过程
尖括号语法:
使用尖括号(< >)时,编译器会在系统的标准库路径中查找指定的头文件。通常这些路径包括编译器安装时的标准目录。
查找顺序:
首先,编译器会查找预定义的标准目录,例如 /usr/include 或其他编译器特定的目录。
如果在这些目录中未找到该文件,则会产生编译错误。
与双引号的区别
使用双引号(#include "filename.h")时,编译器会首先在当前源文件所在目录查找头文件,如果找不到,才会去标准目录查找。
总结
因此,#include <filename.h> 确实会直接到库函数所在的标准目录查找头文件,而不在源文件目录中查找。
40.Typedef有类型检查吗?
typedef 本身并不提供类型检查,它只是一种为已有类型创建别名的机制。在编译器的视角下,typedef 后的别名与原始类型是完全相同的。
关键点
类型别名:
使用 typedef 创建的别名只是在代码中为某个类型提供了一个新的名字,不会影响类型系统。
没有额外的类型检查:
编译器在处理 typedef 时不会进行额外的类型检查,任何与原类型相同的操作都适用。
实用性:
尽管没有类型检查,typedef 可以提高代码的可读性和可维护性,尤其是对于复杂类型(如结构体、指针等)。
typedef unsigned long ulong;
ulong a = 5; // 这实际上是 unsigned long a = 5;
在这种情况下,ulong 与 unsigned long 是等价的,编译器不会针对 ulong 进行额外的类型检查。
总结
因此,typedef 不提供类型检查,其主要功能是创建类型的别名。
41.在Linux内核驱动开发中,哪些函数不能在中断上下文中调用?wait_event(),spinlock(),mutex_lock()函数呢?
在Linux内核驱动开发中,还有许多其他函数和操作不适合在中断上下文中调用。以下是一些常见的例子:
不能在中断上下文中调用的函数
睡眠操作:
wait_event_interruptible() 或 wait_event():这些函数导致进程进入睡眠状态。
msleep() 和类似的函数:导致调用线程睡眠,无法在中断上下文中使用。
大多数 I/O 操作:
如 copy_from_user() 和 copy_to_user():这些函数中涉及进程上下文的操作。
动态内存分配:
kmalloc():虽然可以在某些中断上下文中使用,但应尽量避免,因为它可能导致休眠。
信号发送:
kill_fasync() 等会导致进程调度的函数。
调度函数:
schedule(), schedule_timeout() 等,这些会将执行权转给其他任务。
其他注意事项
打印函数:
printk() 是可以在中断上下文中调用,但输出会被限制,且可能影响性能。
复杂操作:
避免调用复杂的函数链,因为它们可能依赖于可能会导致睡眠的其他函数。
总结
在设计中断处理程序时,应该仅限于简单且快速的操作,避免睡眠和复杂的内存操作。确保使用合适的同步机制,如自旋锁等,来避免在中断上下文中引入阻塞。这样可以保证系统的稳定性和性能。
在Linux内核驱动开发中,有些函数和操作不适合在中断上下文中调用。以下是对于你提到的函数的分析:
1. wait_event()
不能在中断上下文中调用:这个函数会导致进程睡眠,而在中断上下文中,不能进行睡眠操作。中断上下文非常短暂,不允许进行阻塞。
2. spin_lock()
可以在中断上下文中调用:spin_lock() 可以在中断上下文中使用,它是自旋锁,适合在这种上下文中,因为它不会导致进程睡眠。但需要注意,使用自旋锁时要小心死锁和性能问题。
3. mutex_lock()
不能在中断上下文中调用:mutex_lock() 是一个可能导致进程睡眠的操作,因此无法在中断上下文中使用。使用互斥锁时要确保在进程上下文中。
总结
wait_event() 和 mutex_lock() 不能在中断上下文中调用。
spin_lock() 可以在中断上下文中使用,但需谨慎对待。
42.用户进程通常情况只能访问用户空间的虚拟地址,不能访问内核空间虚拟地址。Cortex m3体系结构中,系统复位后所有代码都是由用户在psp。Git commit命令用于将暂存区的内容添加到本地仓库中。自选锁在等待获取锁的过程中会让出CPU资源。MMU可以支持虚拟内存的概念,允许虚拟内存的大小超过实际的RAM容量。
1. 用户进程访问内核空间
正确:用户进程通常只能访问用户空间的虚拟地址,无法直接访问内核空间的虚拟地址。这种保护机制通过硬件和操作系统共同实现,以防止用户进程干扰和破坏内核的操作。
2. Cortex-M3体系结构
部分正确:在Cortex-M3体系结构中,系统复位后所有代码确实从用户模式(PSP,Process Stack Pointer)开始执行。然而,Cortex-M3不具有高级的虚拟内存管理(MMU),而是使用简单的内存保护机制,所有代码最初都在用户模式下执行。
3. Git commit命令
正确:git commit 命令用于将暂存区(staging area)中的更改提交到本地仓库中。它会创建一个新的提交,记录当前项目的状态。
4. 自选锁
不完全正确:自选锁(例如自旋锁)在等待获取锁的过程中不会让出CPU资源。自旋锁会持续忙等待,直到它被获取。相比之下,互斥锁(mutex)在等待时可能会让出CPU控制权,允许其他线程运行。
5. MMU与虚拟内存
正确:内存管理单元(MMU)确实支持虚拟内存的概念,允许程序使用的虚拟内存空间超出物理RAM容量。通过页面置换等技术,系统能有效管理内存
43.汇编语言程序不一定包括.data和.bss段,但必须包括.text段。
汇编语言程序的段
.text段:
必须包括**.text段**,因为这是存放程序代码的地方。执行代码必须在这个段中定义。
.data段:
可选的**.data段**用于存放已初始化的全局和静态变量。虽然常用,但并不是所有汇编程序都需要包含它。
.bss段:
可选的**.bss段**用于存放未初始化的全局和静态变量。类似于.data段,并不是每个程序都必须使用这个段。
总结
因此,汇编语言程序必须包含**.text段**,而**.data和.bss**段是可选的。这种结构允许开发者根据具体需求灵活地组织代码与数据。
44.在c++中,操作符new的功能和calloc函数的功能完全一样。
在C++中,new 操作符和 C 语言中的 calloc 函数的功能并不完全相同。以下是它们之间的主要区别:
1. 基本功能
new:
分配内存并调用构造函数。如果分配失败,会抛出 std::bad_alloc 异常(可以使用 new(nothrow) 来返回 nullptr)。
calloc:
分配一块内存并初始化为零。如果分配失败,返回 NULL。
2. 内存初始化
new:
仅在分配基础类型时不初始化。例如,new int 不会初始化,但 new int() 会初始化为零。
calloc:
默认将分配的内存初始化为零。
3. 使用方式
new:
用于对象和基本数据类型。语法示例:
int* p = new int; // 不初始化
int* q = new int(); // 初始化为零
MyClass* obj = new MyClass(); // 调用构造函数
calloc:
主要用于 C 语言中进行低级内存管理。语法示例:
int* arr = (int*)calloc(10, sizeof(int)); // 初始化为零
4. 释放内存
new:
应用 delete 来释放内存,并调用析构函数:
delete p;
delete[] arr; // 对于数组
calloc:
应用 free 来释放内存:
free(arr);
总结
虽然 new 和 calloc 都用于动态内存分配,但它们有不同的功能、初始化行为和释放方式,因此不能说它们的功能完全一样。
45.在Linux内核中为一个数据结构分配空间调用kmalloc函数。
是的,在Linux内核中,为数据结构分配空间通常会使用 kmalloc 函数。这是一个用于动态分配内存的内核函数。
使用 kmalloc 的主要特点
分配内存:
kmalloc 用于在内核空间中分配指定大小的内存块。函数原型如下
void *kmalloc(size_t size, gfp_t flags);
参数:
size: 要分配的字节数。
flags: 分配的标志,控制内存分配的行为,例如可以使用 GFP_KERNEL(在进程上下文中允许睡眠)或 GFP_ATOMIC(在中断上下文中不允许睡眠)。
返回值:
返回指向分配内存的指针。如果分配失败,返回 NULL。
内存释放:
使用 kfree 函数释放分配的内存:
kfree(ptr);
示例代码
#include <linux/slab.h>
struct my_struct {
int data;
// 其他成员
};
void my_function(void) {
struct my_struct *obj;
// 分配内存
obj = kmalloc(sizeof(struct my_struct), GFP_KERNEL);
if (!obj) {
// 处理分配失败
}
// 使用 obj...
// 释放内存
kfree(obj);
}
总结
在Linux内核开发中,kmalloc 是用于动态分配内存的标准方法,适用于内核中的数据结构管理。
46.SPI无起始位和停止位数据可以持续传输,不会中断。
是的,SPI(串行外设接口)是一种全双工通信协议,具有以下特点:
SPI 特点
无起始位和停止位:
SPI 数据传输不使用起始位和停止位。数据流是连续的,发送和接收可以在同一时刻进行。
持续传输:
一旦建立起通信,数据可以持续传输,直到满足特定条件(如发送特定字节或手动结束传输)。
全双工通信:
SPI 支持全双工传输,因此数据可以同时从主设备和从设备传输,增加了传输效率。
时钟信号:
SPI 使用时钟信号来同步数据的发送和接收,通常由主设备提供。
应用场景
这种持续、无起始位和停止位的传输方式使得 SPI 特别适合高速度和实时数据传输应用,如传感器数据读取和显示控制等。
总结
因此,您的描述是正确的,SPI 支持连续的数据传输而不会中断,提供了一种高效的通信方式。
47.在Linux系统中对IO端口的访问和IO空间的访问方式是一样的。
在Linux系统中,对I/O端口的访问和I/O空间的访问是有区别的。
I/O端口访问
I/O端口(Port I/O):
使用特定指令(如 inb、outb)直接访问I/O设备的端口。
这种方式一般是在 x86 架构上使用,通过特定的CPU指令进行数据传输。
通常在驱动程序中使用 #include <linux/io.h>。
I/O内存映射访问
内存映射I/O(Memory Mapped I/O):
将I/O设备的寄存器映射到内存地址空间,从而使用普通的内存访问指令(如 read 和 write)进行访问。
使用 ioremap() 函数将设备寄存器映射到内核虚拟地址范围。
访问方式类似于访问内存,能够利用缓存和更灵活的寻址。
总结
尽管在功能上都能访问I/O设备,但访问方式和实现机制截然不同。I/O端口使用特定指令,而I/O内存映射则利用内存访问指令。根据硬件架构和设备驱动的设计,驱动开发者会选择适合的方式进行I/O访问。
48.leetcode23合并k个升序链表
#include <stdio.h>
#include <stdlib.h>
struct ListNode {
int val;
struct ListNode *next;
};
// 最小堆节点结构
struct MinHeapNode {
struct ListNode *node;
};
// 最小堆结构
struct MinHeap {
struct MinHeapNode *array;
int size;
};
// 创建一个新的链表节点
struct ListNode* createNode(int val) {
struct ListNode *newNode = (struct ListNode*)malloc(sizeof(struct ListNode));
newNode->val = val;
newNode->next = NULL;
return newNode;
}
// 创建最小堆
struct MinHeap* createMinHeap(int capacity) {
struct MinHeap *minHeap = (struct MinHeap*)malloc(sizeof(struct MinHeap));
minHeap->array = (struct MinHeapNode*)malloc(capacity * sizeof(struct MinHeapNode));
minHeap->size = 0;
return minHeap;
}
// 交换两个最小堆节点
void swap(struct MinHeapNode *a, struct MinHeapNode *b) {
struct MinHeapNode temp = *a;
*a = *b;
*b = temp;
}
// 维护最小堆性质
void minHeapify(struct MinHeap *minHeap, int idx) {
int smallest = idx;
int left = 2 * idx + 1;
int right = 2 * idx + 2;
if (left < minHeap->size && minHeap->array[left].node->val < minHeap->array[smallest].node->val)
smallest = left;
if (right < minHeap->size && minHeap->array[right].node->val < minHeap->array[smallest].node->val)
smallest = right;
if (smallest != idx) {
swap(&minHeap->array[smallest], &minHeap->array[idx]);
minHeapify(minHeap, smallest);
}
}
// 插入节点到最小堆
void insertMinHeap(struct MinHeap *minHeap, struct ListNode *node) {
minHeap->size++;
int i = minHeap->size - 1;
minHeap->array[i].node = node;
while (i && minHeap->array[i].node->val < minHeap->array[(i - 1) / 2].node->val) {
swap(&minHeap->array[i], &minHeap->array[(i - 1) / 2]);
i = (i - 1) / 2;
}
}
// 移除最小堆的最小节点
struct ListNode* removeMin(struct MinHeap *minHeap) {
if (minHeap->size == 0)
return NULL;
struct ListNode *root = minHeap->array[0].node;
minHeap->array[0] = minHeap->array[minHeap->size - 1];
minHeap->size--;
minHeapify(minHeap, 0);
return root;
}
// 合并 K 个升序链表
struct ListNode* mergeKLists(struct ListNode **lists, int listsSize) {
struct MinHeap *minHeap = createMinHeap(listsSize);
// 将每个链表的头节点加入最小堆
for (int i = 0; i < listsSize; i++) {
if (lists[i]) {
insertMinHeap(minHeap, lists[i]);
}
}
struct ListNode dummy;
struct ListNode *tail = &dummy;
dummy.next = NULL;
// 合并链表
while (minHeap->size > 0) {
struct ListNode *minNode = removeMin(minHeap);
tail->next = minNode;
tail = tail->next;
if (minNode->next) {
insertMinHeap(minHeap, minNode->next);
}
}
free(minHeap->array);
free(minHeap);
return dummy.next; // 返回合并后的链表头
}
// 示例代码用法
void printList(struct ListNode *head) {
while (head) {
printf("%d -> ", head->val);
head = head->next;
}
printf("NULL\n");
}
int main() {
// 示例链表
struct ListNode *l1 = createNode(1);
l1->next = createNode(4);
l1->next->next = createNode(5);
struct ListNode *l2 = createNode(1);
l2->next = createNode(3);
l2->next->next = createNode(4);
struct ListNode *l3 = createNode(2);
l3->next = createNode(6);
struct ListNode *lists[] = {l1, l2, l3};
struct ListNode *mergedList = mergeKLists(lists, 3);
printList(mergedList);
return 0;
}
2020年大疆秋招嵌入式笔试题A卷(部分)
一、单选题
1、3个进程,需要的资源数依次为4,5,6,为了防止死锁,所需的最少资源数为(B)
A、12 B、13 C、14 D、15
解析:最差情况各进程占用3,4,5,再有一个资源时候,其中一个进程完成释放资源,所以3+4+5+1=13
2、Thumb指令集支持16位、32位。
3、类似宏定义计算问题(64位系统,char **a[5][6],sizeof(a))
define PRODUCT (x) (x*x)
int main()
{
int a,b=3;
a=PRODUCT(b+2);
}
解答
b+2b+2=3+23+2=11
参见博客:https://blog.csdn.net/qingzhuyuxian/article/details/81459346
4、嵌入式系统的特点:
专用型
隐蔽型
资源受限
高可靠性
软件固化
实时性
5、mov寻址方式
6、MMU的特点
大疆笔试题目解析
大疆公司每年秋招是分批考试,考试时间自选,分为AB卷,本文分享是B卷。
选考时间:2020.08.16,19:00-20:30(A卷为2020.08.10)
题型:单选(2' * 10)、多选(3' * 5)、填空(4' * 4)、简答(6' * 3)、编程( * 2 = 31')
B卷主要考察C语言,还考察一些Liunx和ARM知识点
一、单选
1、
const char 和 const char 定义变量的区别
2、关于cache错误的是?
3、sizeof 结构体(含位域的)
unit16_t
unit32_t
unit8_t
4、FIQ中断向量入口地址?(考察ARM知识点)
回答:FIQ的中断向量地址在0x0000001C,而IRQ的在0x00000018。
5、R15除了本身的功能还可以作为程序计数器?
回答:寄存器R13在ARM指令中常用作堆栈指针SP,寄存器R14称为子程序链接寄存器LR(Link Register),寄存器R15用作程序计数器(PC)。
ARM微处理器共有37个32位寄存器,其中31个为通用寄存器,6个位状态寄存器。通用寄存器R0~R14、程序计数器PC(即R15)是需要熟悉其功能的。
6、如何判断机器大小端?

联合体方法判断方法:利用union结构体的从低地址开始存,且同一时间内只有一个成员占有内存的特性。大端储存符合阅读习惯。联合体占用内存是最大的那个,和结构体不一样。
a和c公用同一片内存区域,所以更改c,必然会影响a的数据
include<stdio.h>
int main(){
union w
{
int a;
char b;
}c;
c.a = 1;
if(c.b == 1)
printf("小端存储\n");
else
printf("大端存储\n");
return 0;
}
指针方法
通过将int强制类型转换成char单字节,p指向a的起始字节(低字节)
include <stdio.h>
int main ()
{
int a = 1;
char *p = (char )&a;
if(p == 1)
{
printf("小端存储\n");
}
else
{
printf("大端存储\n");
}
return 0;
}
二、多选
1、哪些类型可以自加:i++
2、全双工总线类型有哪几个?
3、线程间同步方式?
进程间通讯:
(1)有名管道/无名管道(2)信号(3)共享内存(4)消息队列(5)信号量(6)socket
线程通讯:
(1)信号量(2)读写锁(3)条件变量(4)互斥锁(5)自旋锁
三、填空
1、填一种编译优化选项:-o
2、在有数据cache情况下,DMA数据链路为:外设-DMA-DDR-cache-CPU,CPU需要对cache做什么操作,才可以得到数据?
3、面向对象编程三大特点?
回答:封装、继承和多态
四、简答
1、SPI四种模式,简述其中一种模式,画出时序图?
回答:请参考CSDN博客。
2、判断大小端的三种方式?
3、为什么TCP是稳定传输?
回答:可以从TCP和UDP的区别出发去回答。
五、编程
1、求最大的和:
取两个不重复的字串,求他们的最大的和
输入
10
1 -1 2 2 3 -3 4 -4 5 -5
取 2、2、3、-3、4、5,最大输出13
输入
5
-5 9 -5 11 20
取9、11、20,加起来40
输入
10
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1
答案是-2
2、停车,求收费最多(数据太多,可能有误,自己可以想思路)
用户编号 1 2 3 4
开始时间 1 2 3 7
结束时间 4 4 12 9
同一时间只能服务一个用户
1<=t<6 10元一小时
6<=t<10 5元一小时
10<=t 2元一小时
嵌入式基本知识
1、简述处理器中断处理的过程(中断向量、中断保护现场、中断嵌套、中断返回等)。(总分10分)
解答:将中断处理过程之前,首先先看一下什么是中断:
所谓中断,就是指CPU在正常执行程序的时候,由于内部/外部事件的触发、或由程序预先设定,而引起CPU暂时中止当前正在执行的程序,保存被执行程序相关信息到栈中,转而去执行为内部/外部事件、或由程序预先设定的事件的中断服务子程序,待执行完中断服务子程序后,CPU再获取被保存在栈中被中断的程序的信息,继续执行被中断的程序,这一过程叫做中断。
了解了中断的定义,再来看一下中断的几个概念:
中断向量:中断服务程序的入口地址;
中断向量表:把系统中所有的中断类型码及其对应的中断向量按一定的规律存放在一个区域内,这个存储区域就叫做中断向量表;
中断源:软中断/内中断、外中断/硬件中断、异常等。
处理器在中断处理的过程中,一般分为以下几个步骤:
请求中断→中断响应→保护现场→中断服务→恢复现场→中断返回。
详细地讲解:
请求中断:当某一中断源需要CPU为其进行中断服务时,就输出中断请求信号,使中断控制系统的中断请求触发器置位,向CPU请求中断。系统要求中断请求信号一直保持到CPU对其进行中断响应为止;
中断响应:CPU对系统内部中断源提出的中断请求必须响应,而且自动取得中断服务子程序的入口地址,执行中断服务子程序。对于外部中断,CPU在执行当前指令的最后一个时钟周期去查询INTR引脚,若查询到中断请求信号有效,同时在系统开中断(即IF=1)的情况下,CPU向发出中断请求的外设回送一个低电平有效的中断应答信号,作为对中断请求INTR的应答,系统自动进入中断响应周期;
保护现场:主程序和中断服务子程序都要使用CPU内部寄存器等资源,为使中断处理程序不破坏主程序中寄存器的内容,应先将断点处各寄存器的内容(主要是当前IP(将要执行的下一条地址)和CS值(代码段地址))压入堆栈保护起来,再进入的中断处理。现场保护是由用户使用PUSH指令来实现的;
中断服务:中断服务是执行中断的主体部分,不同的中断请求,有各自不同的中断服务内容,需要根据中断源所要完成的功能,事先编写相应的中断服务子程序存入内存,等待中断请求响应后调用执行;
恢复现场:当中断处理完毕后,用户通过POP指令将保存在堆栈中的各个寄存器的内容弹出,即恢复主程序断点处寄存器的原值。
中断返回:在中断服务子程序的最后要安排一条中断返回指令IRET(interrupt return),执行该指令,系统自动将堆栈内保存的 IP(将要执行的下一条地址)和CS值(代码段地址)弹出,从而恢复主程序断点处的地址值,同时还自动恢复标志寄存器FR或EFR的内容,使CPU转到被中断的程序中继续执行。
而中断嵌套是指中断系统正在执行一个中断服务时,有另一个优先级更高的中断提出中断请求,这时会暂时终止当前正在执行的级别较低的中断源的服务程序,去处理级别更高的中断源,待处理完毕,再返回到被中断了的中断服务程序继续执行,这个过程就是中断嵌套。
最后,补充几个知识点:
CS:IP两个寄存器:指示了 CPU 当前将要读取的指令的地址,其中CS为代码段寄存器,而IP为指令指针寄存器 。可以简单地认为,CS段地址,IP是偏移地址。
RET:也可以叫做近返回,即段内返回。处理器从堆栈中弹出IP或者EIP,然后根据当前的CS:IP跳转到新的执行地址。如果之前压栈的还有其余的参数,则这些参数也会被弹出;
RETF:也叫远返回,从一个段返回到另一个段。先弹出堆栈中的IP/EIP,然后弹出CS,有之前压栈的参数也会弹出。(近跳转与远跳转的区别就在于CS是否压栈);
IRET:用于从中断返回,会弹出IP/EIP,然后CS,以及一些标志。然后从CS:IP执行。
参考文章:牛客网试题。
2、简述处理器在读内存的过程中,CPU核、cache、MMU如何协同工作?画出CPU核、cache、MMU、内存之间的关系示意图加以说明(可以以你熟悉的处理器为例)。(总分10分)
解答:现代操作系统普遍采用虚拟内存管理(Virtual Memory Management) 机制,这需要MMU( Memory Management Unit,内存管理单元) 的支持。有些嵌入式处理器没有MMU,则不能运行依赖于虚拟内存管理的操作系统。
也就是说:操作系统可以分成两类,用MMU的、不用MMU的。用MMU的是:Windows、MacOS、Linux、Android;不用MMU的是:FreeRTOS、VxWorks、UCOS……与此相对应的:CPU也可以分成两类,带MMU的、不带MMU的。带MMU的是:Cortex-A系列、ARM9、ARM11系列;不带MMU的是:Cortex-M系列……(STM32是M系列,没有MMU,不能运行Linux,只能运行一些UCOS、FreeRTOS等等)。
首先我来说一下MMU的作用,MMU就是负责虚拟地址(virtual address)转化成物理地址(physical address)。
下面我来说一下ARM CPU上的地址转换过程涉及三个概念:虚拟地址(VA)(CPU内核对外发出VA),变换后的虚拟地址(MVA)(VA被转换为MVA供cache和MMU使用,在此将MVA转换为PA),物理地址(PA)(最后使用PA读写实际设备)。
CPU看到的用到的只是VA,CPU不管VA最终是怎样到PA的;
而cache、MMU也是看不到VA的,它们使用的是MVA(VA到MVA的转换是由硬件自动完成的);
实际设备看不到VA、MVA,读写设备使用的是PA物理地址。
CPU通过地址来访问内存中的单元,如果CPU没有MMU,或者有MMU但没有启动,那么CPU内核在取指令或者访问内存时发出的地址(此时必须是物理地址,假如是虚拟地址,那么当前的动作无效)将直接传到CPU芯片的外部地址引脚上,直接被内存芯片(物理内存)接收,这时候的地址就是物理地址;
如果CPU启用了MMU(一般是在bootloader中的eboot阶段的进入main()函数的时候启用),CPU内核发出的地址将被MMU截获,这时候从CPU到MMU的地址称为虚拟地址,而MMU将这个VA翻译成为PA发到CPU芯片的外部地址引脚上,也就是将VA映射到PA中。
MMU将VA映射到PA是以页(page)为单位的,对于32位的CPU,通常一页为4k,物理内存中的一个物理页面称页为一个页框(page frame)。虚拟地址空间划分成称为页(page)的单位,而相应的物理地址空间也被进行划分,单位是页框(frame)。页和页框的大小必须相同。

CPU访问内存时的硬件操作顺序,各步骤在图中有对应的标号:
CPU内核(图1中的ARM)发出VA请求读数据,TLB(translation lookaside buffer)接收到该地址,那为什么是TLB先接收到该地址呢?因为TLB是MMU中的一块高速缓存(也是一种cache,是CPU内核和物理内存之间的cache),它缓存最近查找过的VA对应的页表项,如果TLB里缓存了当前VA的页表项就不必做translation table walk了,否则就去物理内存中读出页表项保存在TLB中,TLB缓存可以减少访问物理内存的次数;
页表项中不仅保存着物理页面的基地址,还保存着权限和是否允许cache的标志。MMU首先检查权限位,如果没有访问权限,就引发一个异常给CPU内核。然后检查是否允许cache,如果允许cache就启动cache和CPU内核互操作;
如果不允许cache,那直接发出PA从物理内存中读取数据到CPU内核;
如果允许cache,则以VA为索引到cache中查找是否缓存了要读取的数据,如果cache中已经缓存了该数据(称为cache hit)则直接返回给CPU内核,如果cache中没有缓存该数据(称为cache miss),则发出PA从物理内存中读取数据并缓存到cache中,同时返回给CPU内核。但是cache并不是只去CPU内核所需要的数据,而是把相邻的数据都取上来缓存,这称为一个cache line。ARM920T的cache line是32个字节,例如CPU内核要读取地址0x300001340x3000137的4个字节数据,cache会把地址0x300001200x3000137(对齐到32字节地址边界)的32字节都取上来缓存。
关于translation table walk的具体步骤,可以参考文章:MMU和cache详解(TLB机制)、硬件篇之MMU。
基本通信知识
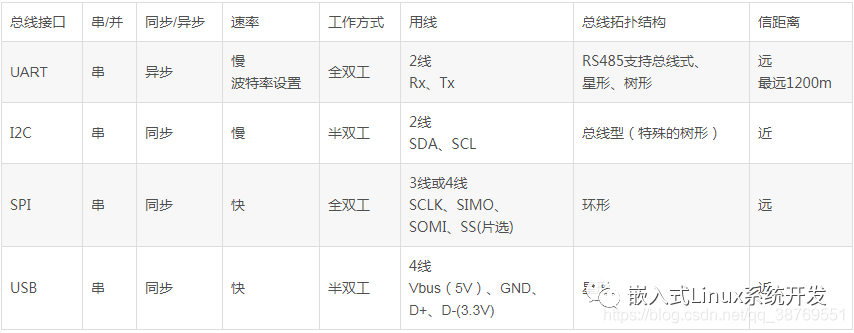
1、请说明总线接口USRT、I2C、USB的异同点(串/并、速度、全/半双工、总线拓扑等)。(总分5分)
解答:UART、I2C、SPI、USB的异同点:
UART:通用异步串行口,速率不快,可全双工,结构上一般由波特率产生器、UART发送器、UART接收器组成,硬件上两线,一收一发;
I2C:双向、两线、串行、多主控接口标准。速率不快,半双工,同步接口,具有总线仲裁机制,非常适合器件间近距离经常性数据通信,可实现设备组网;
SPI:高速同步串行口,高速,可全双工,收发独立,同步接口,可实现多个SPI设备互联,硬件3~4线;
USB 通用串行总线,高速,半双工,由主机、hub、设备组成。设备可以与下级hub相连构成星型结构。

2、列举你所知道的linux内核态和用户态之间的通信方式并给出你认为效率最高的方式,说明理由。(总分5分)
解答:首先对内核态和用户态的概念有所了解:
内核态(Kernel Mode):在内核态,代码拥有完全的,不受任何限制的访问底层硬件的能力。可以执行任意的CPU指令,访问任意的内存地址。内核态通常情况下,都是为那些最底层的,由操作系统提供的,可信可靠的代码来运行的。内核态的代码崩溃将是灾难性的,它会影响到整个系统。
用户态(User Mode):在用户态,代码不具备直接访问硬件或者访问内存的能力,而必须借助操作系统提供的可靠的,底层的APIs来访问硬件或者内存。由于这种隔离带来的保护作用,用户态的代码崩溃(Crash),系统是可以恢复的。我们大多数的代码都是运行在用户态的。
Linux下内核空间与用户空间进行通信的方式主要有syscall(system call)、procfs和netlink等。
syscall:一般情况下,用户进程是不能访问内核的。它既不能访问内核所在的内存空间,也不能调用内核中的函数。Linux内核中设置了一组用于实现各种系统功能的子程序,用户可以通过调用他们访问linux内核的数据和函数,这些系统调用接口(SCI)称为系统调用;
procfs:是一种特殊的伪文件系统 ,是Linux内核信息的抽象文件接口,大量内核中的信息以及可调参数都被作为常规文件映射到一个目录树中,这样我们就可以简单直接的通过echo或cat这样的文件操作命令对系统信息进行查取。
在这几个通信方式中,选择netlink,原因如下:
全双工:procfs是基于文件系统,用于内核向用户发送消息;syscall是用户访问内核。它们都是单工通信方式。netlink是一种特殊的通信方式,用于在内核空间和用户空间传递消息,是一种双工通信方式。使用地址协议簇AF_NETLINK,使用头文件include/linux/netlink.h;
易于添加:为新特性添加system call、或者procfs是一件复杂的工作,它们会污染kernel(内核),破坏系统的稳定性,这是非常危险的。Netlink的添加,对内核的影响仅在于向netlink.h中添加一个固定的协议类型,然后内核模块和应用层的通信使用一套标准的API。
这里再多介绍一个,用户态和内核态的转换方式:
系统调用:这是用户进程主动要求切换到内核态的一种方式,用户进程通过系统调用申请操作系统提供的服务程序完成工作。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的ine 80h中断;
异常:当CPU在执行运行在用户态的程序时,发现了某些事件不可知的异常,这是会触发由当前运行进程切换到处理此异常的内核相关程序中,也就到了内核态,比如缺页异常;
外围设备的中断:当外围设备完成用户请求的操作之后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条将要执行的指令转而去执行中断信号的处理程序,如果先执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了有用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
从出发方式看,可以在认为存在前述3种不同的类型,但是从最终实际完成由用户态到内核态的切换操作上来说,涉及的关键步骤是完全一样的,没有任何区别,都相当于执行了一个中断响应的过程,因为系统调用实际上最终是中断机制实现的,而异常和中断处理机制基本上是一样的,用户态切换到内核态的步骤主要包括:
从当前进程的描述符中提取其内核栈的ss0及esp0信息;
使用ss0和esp0指向的内核栈将当前进程的cs,eip,eflags,ss,esp信息保存起来,这个过程也完成了由用户栈找到内核栈的切换过程,同时保存了被暂停执行的程序的下一条指令;
将先前由中断向量检索得到的中断处理程序的cs,eip信息装入相应的寄存器,开始执行中断处理程序,这时就转到了内核态的程序执行了。
系统设计
有一个使用UART进行通信的子系统X,其中UART0进行数据包接收和回复,UART1进行数据包转发。子系统X的通信模块职责是从UART0接收数据包,如果为本地数据包(receiver 为子系统X),则解析数据包中的命令码(2字节)和数据域(0~128字节),根据命令码调用内部的处理程序,并将处理结果通过UART0回复给发送端,如果非本地数据包,则通过UART1转发。如果由你来设计子系统X的通信模块:
1)请设计通信数据包格式,并说明各字段的定义;(总分5分)
2)在一个实时操作系统中,你会如何部署模块中的任务和缓存数据,画出任务间的数据流视图加以说明;(总分5分)
3)你会如何设置任务的优先级,说说优缺点;(总分5分)
4)如果将命令码对应的处理优先级分为高、低两个等级,你又会如何设计;(总分5分)
解答:1)采用帧头+检验位+数据+帧尾的形式,并且数据由数据头、数据内容和数据尾确定。
比如:TB/校验位OR/命令码/ORME/数据域/ME/TE。
其中:“TB/”为帧头,校验位用于判断是否为本地数据包,“OR/”和“/OR”之间的为命令码,“ME/”和“/ME”之间的为数据域,“/TE”为帧尾。
2014大疆嵌入式笔试题试题
编程基础
1、有如下CAT_s结构体定义,回答:
1)在一台64位的机器上,使用32位编译,Garfield变量占用多少内存空间?64位编译又是如何?(总分5分)
2)使用32位编译情况下,给出一种判断所使用机器大小端的方法。(总分5分)
struct CAT_s
{
int ld;
char Color;
unsigned short Age;
char Name;
void(Jump)(void);
}Garfield;
2、描述下面XXX这个宏的作用。(总分10分)
define offsetof(TYPE,MEMBER) ((size_t)&((TYPE*)0)->MEMBER)
define XXX(ptr,type,member)({\
const typeof(((type)0)->member) __mptr=(ptr);
(type)((char)__mptr – offsetof(type,member));})
3、简述C函数:
1)参数如何传递(__cdecl调用方式);
2)返回值如何传递;
3)调用后如何返回到调用前的下一条指令执行。(总分10分)
4、在一个多任务嵌入式系统中,有一个CPU可直接寻址的32位寄存器REGn,地址为0x1F000010,编写一个安全的函数,将寄存器REGn的指定位反转(要求保持其他bit的值不变)。(总分10分)
5、有10000个正整数,每个数的取值范围均在1到1000之间,编程找出从小到大排在第3400(从0开始算起)的那个数,将此数的值返回,要求不使用排序实现。(总分10分)
嵌入式基本知识
1、简述处理器中断处理的过程(中断向量、中断保护现场、中断嵌套、中断返回等)。(总分10分)
2、简述处理器在读内存的过程中,CPU核、cache、MMU如何协同工作?画出CPU核、cache、MMU、内存之间的关系示意图加以说明(可以以你熟悉的处理器为例)。(总分10分)
基本通信知识
1、请说明总线接口USRT、I2C、USB的异同点(串/并、速度、全/半双工、总线拓扑等)。(总分5分)
2、列举你所知道的linux内核态和用户态之间的通信方式并给出你认为效率最高的方式,说明理由。(总分5分)
系统设计
有一个使用UART进行通信的子系统X,其中UART0进行数据包接收和回复,UART1进行数据包转发。子系统X的通信模块职责是从UART0接收数据包,如果为本地数据包(receiver 为子系统X),则解析数据包中的命令码(2字节)和数据域(0~128字节),根据命令码调用内部的处理程序,并将处理结果通过UART0回复给发送端,如果非本地数据包,则通过UART1转发。如果由你来设计子系统X的通信模块:
1)请设计通信数据包格式,并说明各字段的定义;(总分5分)
2)在一个实时操作系统中,你会如何部署模块中的任务和缓存数据,画出任务间的数据流视图加以说明;(总分5分)
3)你会如何设置任务的优先级,说说优缺点;(总分5分)
4)如果将命令码对应的处理优先级分为高、低两个等级,你又会如何设计;(总分5分)
试题解答
编程基础
1、有如下CAT_s结构体定义,回答:
1)在一台64位的机器上,使用32位编译,Garfield变量占用多少内存空间?64位编译又是如何?(总分5分)
2)使用32位编译情况下,给出一种判断所使用机器大小端的方法。(总分5分)
struct CAT_s
{
int ld;
char Color;
unsigned short Age;
char Name;
void(Jump)(void);
}Garfield;
解答:1)这是一条很经典的判断结构体大小的题目,经典到只要面试C语言或者C++的工作,无论是嵌入式还是互联网公司,绝大多数情况下都会问到的一种题型。
这题主要考的就是:内存对齐。
对于大多数的程序员来说,内存对齐基本上是透明的,这是编译器该干的活,编译器为程序中的每个数据单元安排在合适的位置上,从而导致了相同的变量,不同声明顺序的结构体大小的不同。
那么编译器为什么要进行内存对齐呢?主要是为了性能和平台移植等因素,编译器对数据结构进行了内存对齐。
为了分析造成这种现象的原因,我们不得不提及内存对齐的3大规则:
对于结构体的各个成员,第一个成员的偏移量是0,排列在后面的成员其当前偏移量必须是当前成员类型的整数倍;
结构体内所有数据成员各自内存对齐后,结构体本身还要进行一次内存对齐,保证整个结构体占用内存大小是结构体内最大数据成员的最小整数倍;
如程序中有#pragma pack(n)预编译指令,则所有成员对齐以n字节为准(即偏移量是n的整数倍),不再考虑当前类型以及最大结构体内类型。
按照上面的3大规则直接来进行分析:
使用32位编译,int占4, char 占1, unsigned short int占2,char占4,函数指针占4个,由于是32位编译是4字节对齐,所以该结构体占16个字节。(说明:按几字节对齐,是根据结构体的最长类型决定的,这里是int是最长的字节,所以按4字节对齐);
使用64位编译 ,int占4, char 占1, unsigned short int占2,char占8,函数指针占8个,由于是64位编译是8字节对齐,(说明:按几字节对齐,是根据结构体的最长类型决定的,这里是函数指针是最长的字节,所以按8字节对齐)所以该结构体占24个字节。
2)大端小端问题:
所谓的大端模式(BE big-endian),是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中(低对高,高对高);
所谓的小端模式(LE little-endian),是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中(低对低,高对高)。
为什么要有大小端区分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
首先给出一个方法(Linux操作系统的源码中的判断):
static union {
char c[4];
unsigned long mylong;
} endian_test = {{ 'l', '?', '?', 'b' } };
define ENDIANNESS ((char)endian_test.mylong)
这是利用:联合体union的存放顺序是所有成员都从低地址开始存放的特性。由于联合体的各个成员共用内存,并应该同时只能有一个成员得到这块内存的使用权(即对内存的读写)。如果是“l”(小端)、“b”(大端)。
除了这种方法之外,也可以利用数据类型转换的截断特性:
void Judge_duan()
{
int a = 1; //定义为1是为了方便 如果你喜欢你可以随意,
//只要你能搞清楚 例如:0x11223344;
char *p = (char )&a;//在这里将整形a的地址转化为char;
//方便后面取一个字节内容
if(*p == 1)//在这里解引用了p的一个字节的内容与1进行比较;
printf("小端\n");
else
printf("大端\n");
}
顺便提一下,大小端之间的转化,以小端转化为大端为例:
int endian_convert(int t)
{
int result=0;
int i;
for (i = 0; i < sizeof(t); i++) {
result <<= 8;
result |= (t & 0xFF);
t >>= 8;
}
return result;
}
2、描述下面XXX这个宏的作用。(总分10分)
define offsetof(TYPE,MEMBER)((size_t)&((TYPE*)0)->MEMBER)
define XXX(ptr,type,member)({\
const typeof(((type)0)->member)__mptr=(ptr);
(type)((char)__mptr – offsetof(type,member));})
解答:其实这个宏定义是Linux内核结构体container_of的宏定义,几乎没修改过(该宏定义在kernel.h中)。当然,我们先认为这是一个陌生的宏定义来进行分析它的作用。
首先你得能看出来这是两个宏定义……,第二个宏定义是换行的宏定义方式,以“\”结尾。
先来看第一个宏定义:
define offsetof(TYPE,MEMBER) ((size_t)&((TYPE*)0)->MEMBER)
(TYPE)0:将0强转为TYPE类型的指针,且指向了0地址空间;
(TYPE)0->MEMEBER:指向结构体中的成员;
&((TYPE*)0->MEMBER):获取成员在结构体的位置,因为起始为0,所以获取的地址即为实际的偏移地址。
分析:(TYPE *)0,将 0 强制转换为 TYPE 型指针,记 p = (TYPE *)0,p是指向TYPE的指针,它的值是0。那么 p->MEMBER 就是 MEMBER 这个元素了,而&(p->MEMBER)就是MENBER的地址,而基地址为0,这样就巧妙的转化为了TYPE中的偏移量。再把结果强制转换为size_t型的就OK了,size_t其实也就是unsigned int。
再来看需要我们描述功能的宏定义XXX:
define XXX(ptr,type,member)({\
const typeof(((type)0)->member) __mptr=(ptr);
(type)((char)__mptr – offsetof(type,member));})
typeof构造的主要应用是用在宏定义中。可以使用typeof关键字来引用宏参数的类型。也就是说,typeof(((type*)0)->member)是引用与type结构体的member成员的数据类型;
获得了数据类型之后,定义一个与type结构体的member成员相同的类型的指针变量__mptr,且将ptr值赋给它;
用宏offsetof(type,member),获取member成员在type结构中的偏移量;
最后将__mptr值减去这个偏移量,就得到这个结构变量的地址了(亦指针)。
XXX宏的实现思路:计算type结构体成员member在结构体中的偏移量,然后ptr的地址减去这个偏移量,就得出type结构变量的首地址。
具体的功能就是:ptr是指向正被使用的某类型变量指针;type是包含ptr指向的变量类型的结构类型;member是type结构体中的成员,类型与ptr指向的变量类型一样。功能是计算返回包含ptr指向的变量所在的type类型结构变量的指针。
参考文章:老生常谈的Linux内核中常用的两个宏定义。
3、简述C函数:
1)参数如何传递(__cdecl调用方式);
2)返回值如何传递;
3)调用后如何返回到调用前的下一条指令执行。(总分10分)
解答:1)参数如何传递 (__cdecl调用方式) :
__cdecl是C Declaration的缩写(declaration,声明),是C语言中函数调用约定中的一种(默认)。
什么是函数调用约定?
当一个函数被调用时,函数的参数会被传递给被调用的函数,同时函数的返回值会被返回给调用函数。函数的调用约定就是用来描述参数(返回值)是怎么传递并且由谁来平衡堆栈的。也就是说:函数调用约定不仅决定了发生函数调用时函数参数的入栈顺序,还决定了是由调用者函数还是被调用函数负责清除栈中的参数,还原堆栈。
常见的函数调用约定有:__stdcall,__cdecl(默认),__fastcall,__thiscall,__pascal等等。
它们按参数的传递顺序对这些约定可划分为:
从右到左依次入栈:__stdcall,__cdecl,__thiscall;
从左到右依次入栈:__pascal,__fastcall。
下面比较一下最为常见的两种:
__cdecl:是C Declaration的缩写(declaration,声明),表示C语言默认的函数调用方法:所有参数从右到左依次入栈,由调用者负责把参数压入栈,最后也是由调用者负责清除栈的内容 ;
__stdcall:是StandardCall的缩写,是C++的标准调用方式:所有参数从右到左依次入栈,由调用者负责把参数压入栈,最后由被调用者负责清除栈的内容。
另外,还要注意的是,如printf此类支持可变参数的函数,由于不知道调用者会传递多少个参数,也不知道会压多少个参数入栈,因此函数本身内部不可能清理堆栈,只能由调用者清理了。
也就是说:支持可变参数的函数调用约定:__cdecl,带有可变参数的函数必须是cdecl调用约定,由函数的调用者来清除栈,参数入栈的顺序是从右到左。由于每次函数调用都要由编译器产生清除(还原)堆栈的代码,所以使用__cdecl方式编译的程序比使用__stdcall方式编译的程序要大很多。
2)C语言返回值如何传递:
一般情况下,函数返回值是通过eax进行传递的,但是eax只能存储4个字节的信息,对于那些返回值大于4个字节的函数,返回值是如何传递的呢?
假设返回值大小为M字节:
M <= 4字节,将返回值存储在eax返回;
4 < M <=8,把eax,edx联合起来。其中,edx存储高位,eax存储低位;
M > 8,如何传递呢?用一下代码测试:
typedef struct big_thing
{
char buf[128];
}big_thing;
big_thing return_test()
{
big_thing b;
b.buf[] = 0;
return b;
}
int main()
{
big_thing n = return_test();
}
首先main函数在栈额外开辟了一片空间,并将这块空间的一部分作为传递返回值的临时对象,这里称为temp;
将temp对象的地址作为隐藏参数传递个return_test函数;
return_test 函数将数据拷贝给temp对象,并将temp对象的地址用eax传出;
return_test返回以后,mian函数将eax指向的temp对象的内容拷贝给n。
也就是说,如果返回值的类型的尺寸太大,c语言在函数的返回时会使用一个临时的栈上内存作为中转,结果返回值对象会被拷贝两次。整个过程使用的是指向返回值的指针来进行拷贝的,而指针本身是通过eax返回的。因而不到万不得已,不要轻易返回大尺寸对象。
那么上面的eax、edx是什么呢?
eax是"累加器"(accumulator), 它是很多加法乘法指令的缺省寄存器;
ebx 是"基地址"(base)寄存器, 在内存寻址时存放基地址;
ecx是计数器(counter), 是重复(REP)前缀指令和LOOP指令的内定计数器;
edx则总是被用来放整数除法产生的余数。
函数返回值为什么一般放在寄存器中?
这主要是为了支持中断;如果放在堆栈中有可能因为中断而被覆盖。
参考文章: C函数参数传递与返回值传递。
3)C语言调用后如何返回到调用前的下一条指令执行:
这就涉及到函数的堆栈帧这个概念。
栈在程序运行中具有举足轻重的地位。最重要的,栈保存了一个函数调用所需要的维护信息,被称为堆栈帧(Stack Frame),一个函数(被调函数)的堆栈帧一般包括下面几个方面的内容:
函数的参数;函数的局部变量;寄存器的值(用以恢复寄存器);函数的返回地址以及用于结构化异常处理的数据(当函数中有try…catch语句时才有)等等。
由于在函数的堆栈帧中存放了函数的返回地址,即调用方调用此函数的下一条指令的地址。故而,在函数调用后,由函数调用方执行,直接返回调用前的下一条指令。
参考文章:浅谈C/C++堆栈指引——C/C++堆栈很强大(绝美)。
4、在一个多任务嵌入式系统中,有一个CPU可直接寻址的32位寄存器REGn,地址为0x1F000010,编写一个安全的函数,将寄存器REGn的指定位反转(要求保持其他bit的值不变)。(总分10分)
解答:指定为反转用异或,多任务嵌入式系统保证安全性!
void bit_reverse(uint32_t nbit)
{
*((volatile unsigned int *)0x1F000010) ^= (0x01 << nbit);
}
对于位运算的一些小总结:特定位清零用&;特定位置1用|;所有位取反用~;特定位取反用^。
参考文章:2.2.位与位或位异或在操作寄存器时的特殊作用。
5、有10000个正整数,每个数的取值范围均在1到1000之间,编程找出从小到大排在第3400(从0开始算起)的那个数,将此数的值返回,要求不使用排序实现。(总分10分)
解答:10000个正整数找出从小到大的第3400个(从0开始算起),第一个想到的就是排序(冒泡排序、插入排序、选择排序……),或者使用桶排序。但这些显然都不满足这个题目的要求。
关键的点是:正整数,每个数的取值均在1-1000之间,这是本题一个特殊性。
本题思路:维护一个数组count[1000],分别存储1-1000每个数字的出现次数。
include
using namespace std;
define TOTAL 10000
define RANGE 1000
define REQUIRED 3400
int main()
{
int number[TOTAL] = { 0 };
int count[RANGE] = { 0 };
int i, sum = 0;
for (i = 0; i < 10000; i++) {
number[i] = (rand() % 1000) + 1; /产生10000个1-1000之间的随机数/
}
for (i = 0; i < 10000; i++) {
count[number[i] - 1]++; /计算10000个整数出现次数/
}
for (i = 0; i < 1000; i++) {
sum += count[i];
if (sum >= REQUIRED + 1) {
cout << i + 1 << endl;
break;
}
}
return 0;
}
2020大疆校招嵌入式B卷编程题
题考的比较基础,同时也很注重细节,最坑的是不能用本地编译器编译测试,在线的也不能,只能手写
1、写宏定义
(1)x对a向下取整数倍的宏定义ALIGN_DOWN(x, a) 例子(65,3)->63
(2)x对a向上取整数倍的宏定义ALIGN_UP(x, a) 例子(65,3)->66
其实这个就是个取余的问题,向下就是减掉余数,向上加上a-余数,注意宏定义细节,括号都加上加好,防止出现输入64+1或者其他的情况,造成计算错误
define ALIGN_DOWN(x, a) ((x) - (x) % (a))
define ALIGN_UP(x, a) ((x) + a - (x) % (a))
(3)x对a向下取整数倍的宏定义ALIGN_2N_DOWN(x, a) ,a是2的n次幂例子(65,4)->64
(4)x对a向上取整数倍的宏定义ALIGN_2N_UP(x, a) 例子,a是2的n次幂例子(65,4)->68
注意要用2的n次幂这个特性进行加速
笔者做的时候知道这个是利用位运算,然而在笔试时紧张第二个写错了,现在想想真的二啊我。。。。
首先2的n次幂有个特性,减一之后低于n的位全部变为1,举例4d,0100b,减一变为0011,取反1100,利用这个特性便可以做出第三四来(好气啊,笔试紧张,向上的我写错了!!!)
define ALIGN_2N_DOWN(x, a) ((x)&~(a - 1))
define ALIGN_2N_UP(x, a) ((x + a - 1)&~(a - 1))
其实最后一个向上2n次幂向上取整是在linux内核中定义的,哎多看源码,多积累把~~~
linux原始定义如下,和我们写的一样,注意(),我上面没有写。
define ALIGN(x,a) (((x)+(a)-1)&~(a-1))
2、第二考察特别细节,
硬件数据寄存器地址0x8000_0000
状态寄存器0x8000_0004
状态寄存器31位为1时数据有效读出来,并清除,有效返0,无效返回负数
注意volatile、const、assert、等等吧
具体见下面代码,笔试时重定位写错了,哎,注意细节!!!!

【机试题】2019.8.6大疆嵌入式笔试题B卷笔试题目总结
关键字volatile
表示一个变量也许会被后台程序改变,关键字 volatile 是与 const 绝对对立的。它指示一个变量也许会被某种方式修改,这种方式按照正常程序流程分析是无法预知的(例如,一个变量也许会被一个中断服务程序所修改)。这个关键字使用下列语法定义:volatile data-definition。
变量如果加了 volatile 修饰,则会从内存重新装载内容,而不是直接从寄存器拷贝内容。 volatile 的作用是作为指令关键字,确保本条指令不会因编译器的优化而省略,且要求每次直接读值。
volatile应用比较多的场合,在中断服务程序和cpu相关寄存器的定义。
//示例一
include <stdio.h>
int main (void)
{
int i = 10;
int a = i; //优化
int b = i;
printf ("i = %d\n", b);
return 0;
}
//示例二
include <stdio.h>
int main (void)
{
volatile int i = 10;
int a = i; //未优化
int b = i;
printf ("i = %d\n", b);
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
使用 volatile 的代码编译未优化。volatile 指出 i 是随时可能发生变化的,每次使用它的时候必须从 i的地址中读取,因而编译器生成的汇编代码会重新从i的地址读取数据放在 b 中。而优化做法是,由于编译器发现两次从 i读数据的代码之间的代码没有对 i 进行过操作,它会自动把上次读的数据放在 b 中。而不是重新从 i 里面读。这样以来,如果 i是一个寄存器变量或者表示一个端口数据就容易出错,所以说 volatile 可以保证对特殊地址的稳定访问。
volatile 使用:1.并行设备的硬件寄存器(如:状态寄存器);2.一个中断服务子程序中会访问到的非自动变量(Non-automatic variables);3.多线程应用中被几个任务共享的变量。
关键字volatile参考链接
关键字volatile参考链接
关键字 inline
大多数的机器上,调用函数都要做很多工作:调用前要先保存寄存器,并在返回时恢复,复制实参,程序还必须转向一个新位置执行C++中支持内联函数,其目的是为了提高函数的执行效率,用关键字 inline 放在函数定义(注意是定义而非声明,下文继续讲到)的前面即可将函数指定为内联函数,内联函数通常就是将它在程序中的每个调用点上“内联地”展开。
关键字 inline参考链接
关键字 inline参考链接
C语言编译过程中,volatile关键字和extern关键字分别在哪个阶段起作用
volatile应该是在编译阶段,extern在链接阶段。
volatile关键字的作用是防止变量被编译器优化,而优化是处于编译阶段,所以volatile关键字是在编译阶段起作用。
请你说一下源码到可执行文件的过程
对于C++源文件,从文本到可执行文件一般需要四个过程:
预处理阶段:对源代码文件中文件包含关系(头文件)、预编译语句(宏定义)进行分析和替换,生成预编译文件。
编译阶段:将经过预处理后的预编译文件转换成特定汇编代码,生成汇编文件
汇编阶段:将编译阶段生成的汇编文件转化成机器码,生成可重定位目标文件
链接阶段:将多个目标文件及所需要的库连接成最终的可执行目标文件

1)预编译
主要处理源代码文件中的以“#”开头的预编译指令。处理规则见下
1、删除所有的#define,展开所有的宏定义。
2、处理所有的条件预编译指令,如“#if”、“#endif”、“#ifdef”、“#elif”和“#else”。
3、处理“#include”预编译指令,将文件内容替换到它的位置,这个过程是递归进行的,文件中包含其他文件。
4、删除所有的注释,“//”和“/**/”。
5、保留所有的#pragma 编译器指令,编译器需要用到他们,如:#pragma once 是为了防止有文件被重复引用。
6、添加行号和文件标识,便于编译时编译器产生调试用的行号信息,和编译时产生编译错误或警告是能够显示行号。
2)编译
把预编译之后生成的xxx.i或xxx.ii文件,进行一系列词法分析、语法分析、语义分析及优化后,生成相应的汇编代码文件。
1、词法分析:利用类似于“有限状态机”的算法,将源代码程序输入到扫描机中,将其中的字符序列分割成一系列的记号。
2、语法分析:语法分析器对由扫描器产生的记号,进行语法分析,产生语法树。由语法分析器输出的语法树是一种以表达式为节点的树。
3、语义分析:语法分析器只是完成了对表达式语法层面的分析,语义分析器则对表达式是否有意义进行判断,其分析的语义是静态语义——在编译期能分期的语义,相对应的动态语义是在运行期才能确定的语义。
4、优化:源代码级别的一个优化过程。
5、目标代码生成:由代码生成器将中间代码转换成目标机器代码,生成一系列的代码序列——汇编语言表示。
6、目标代码优化:目标代码优化器对上述的目标机器代码进行优化:寻找合适的寻址方式、使用位移来替代乘法运算、删除多余的指令等。
3)汇编
将汇编代码转变成机器可以执行的指令(机器码文件)。 汇编器的汇编过程相对于编译器来说更简单,没有复杂的语法,也没有语义,更不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译过来,汇编过程有汇编器as完成。经汇编之后,产生目标文件(与可执行文件格式几乎一样)xxx.o(Windows下)、xxx.obj(Linux下)。
4)链接
将不同的源文件产生的目标文件进行链接,从而形成一个可以执行的程序。链接分为静态链接和动态链接:
1、静态链接:
函数和数据被编译进一个二进制文件。在使用静态库的情况下,在编译链接可执行文件时,链接器从库中复制这些函数和数据并把它们和应用程序的其它模块组合起来创建最终的可执行文件。
空间浪费:因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个目标文件都有依赖,会出现同一个目标文件都在内存存在多个副本;
更新困难:每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。
运行速度快:但是静态链接的优点就是,在可执行程序中已经具备了所有执行程序所需要的任何东西,在执行的时候运行速度快。
2、动态链接:
动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。
共享库:就是即使需要每个程序都依赖同一个库,但是该库不会像静态链接那样在内存中存在多分,副本,而是这多个程序在执行时共享同一份副本;
更新方便:更新时只需要替换原来的目标文件,而无需将所有的程序再重新链接一遍。当程序下一次运行时,新版本的目标文件会被自动加载到内存并且链接起来,程序就完成了升级的目标。
性能损耗:因为把链接推迟到了程序运行时,所以每次执行程序都需要进行链接,所以性能会有一定损失。
sizeof
1.如果是数组
include<stdio.h>
int main()
{
int a[5]={1,2,3,4,5};
printf(“sizeof数组名=%d\n”,sizeof(a));
printf(“sizeof 数组名=%d\n”,sizeof(a));
}
运行结果
sizeof数组名=20
sizeof 数组名=4
2.如果是指针,sizeof只会检测到是指针的类型,指针都是占用4个字节的空间(32位机)。
char p = “sadasdasd”;
sizeof( p):4
sizeof(p):1//指向一个char类型的
sizeof(数组名)与sizeof(数组名)参考链接
sizeof(指针)与sizeof(*指针)参考链接
结构体struct内存对齐的3大规则:
1.对于结构体的各个成员,第一个成员的偏移量是0,排列在后面的成员其当前偏移量必须是当前成员类型的整数倍;
2.结构体内所有数据成员各自内存对齐后,结构体本身还要进行一次内存对齐,保证整个结构体占用内存大小是结构体内最大数据成员的最小整数倍;
3.如程序中有#pragma pack(n)预编译指令,则所有成员对齐以n字节为准(即偏移量是n的整数倍),不再考虑当前类型以及最大结构体内类型。
pragma pack(1)
struct fun{
int i;
double d;
char c;
};
sizeof(fun) = 13
struct CAT_s
{
int ld;
char Color;
unsigned short Age;
char Name;
void(Jump)(void);
}Garfield;
按照上面的3大规则直接来进行分析:
1.使用32位编译,int占4, char 占1, unsigned short 占2,char* 占4,函数指针占4个,由于是32位编译是4字节对齐,所以该结构体占16个字节。(说明:按几字节对齐,是根据结构体的最长类型决定的,这里是int是最长的字节,所以按4字节对齐);
2.使用64位编译 ,int占4, char 占1, unsigned short 占2,char* 占8,函数指针占8个,由于是64位编译是8字节对齐,(说明:按几字节对齐,是根据结构体的最长类型决定的,这里是函数指针是最长的字节,所以按8字节对齐)所以该结构体占24个字节。
//64位
struct C
{
double t; //8 1111 1111
char b; //1 1
int a; //4 0001111
short c; //2 11000000
};
sizeof(C) = 24; //注意:1 4 2 不能拼在一起
联合体union内存对齐的2大规则:
1.找到占用字节最多的成员;
2.union的字节数必须是占用字节最多的成员的字节的倍数,而且需要能够容纳其他的成员.
//x64
typedef union {
long i;
int k[5];
char c;
}D
要计算union的大小,首先要找到占用字节最多的成员,本例中是long,占用8个字节,int k[5]中都是int类型,仍然是占用4个字节的,然后union的字节数必须是占用字节最多的成员的字节的倍数,而且需要能够容纳其他的成员,为了要容纳k(20个字节),就必须要保证是8的倍数的同时还要大于20个字节,所以是24个字节。
内存对齐作用:
1.平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2.性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
结构体占用内存
在32位系统中有如下定义,则sizeof(data_t)的值是()
A.15 B.19 C.11 D.8
typedef struct_data{
char m:3;
char n:5;
short s;
union{
int a;
char b;
};
int h;
}attribute((packed)) data_t;
片上系统中,常用来在片内做数据传输的总线是
A. UART B .I2C C.AXI D SPI
AXI总线参考链接
ARM指令和Thumb指令
ARM指令和Thumb指令参考链接
请简述linux或RTOS中,栈空间最大使用率和栈溢出检测方法。
方法一:在任务切换时检测任务指针是否过界了,如果过界了,在任务切换的时候会触发栈溢出的钩子函数。
方法二:任务创建的时候将任务栈所有的数据初始化为0xa5,任务切换时进行任务栈检测的时候会检测末尾的16个字节是否都是0xa5,通过这种方式来检测任务栈是否溢出了。
抢占式内核中,任务调度实际有哪些
Linux内核
抢占式内核参考链接
一个程序中含有以下代码块,请说明其中各个变量的生命周期,作用域和存储位置(提示:存储位置可以选泽 ‘text’ ‘data’ ‘bss’ ‘heap’ ‘stack’)
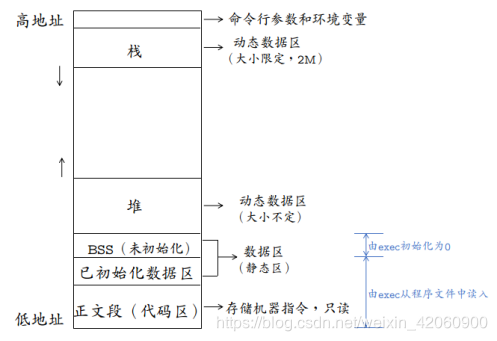
一个程序本质上都是由BSS段、data段、text段(代码区)三个组成的。可以看到一个可执行程序在存储(没有调入内存)时分为代码段、数据区和未初始化数据区三部分。
BSS段(未初始化数据区):通常用来存放程序中未初始化的全局变量和静态变量的一块内存区域。BSS段属于静态分配,程序结束后静态变量资源由系统自动释放。
数据段:数据段也属于静态内存分配。该区包含了在程序中明确被初始化的全局变量、已经初始化的静态变量(包括全局静态变量和局部静态变量)和常量数据(如字符串常量)。
代码段:存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域属于只读。在代码段中,也有可能包含一些只读的常数变量
text段和data段在编译时已经分配了空间,而BSS段并不占用可执行文件的大小,它是由链接器来获取内存的。
bss段(未进行初始化的数据)的内容并不存放在磁盘上的程序文件中。其原因是内核在程序开始运行前将它们设置为0。需要存放在程序文件中的只有正文段和初始化数据段。
data段(已经初始化的数据)则为数据分配空间,数据保存到目标文件中。
数据段包含经过初始化的全局变量以及它们的值。BSS段的大小从可执行文件中得到,然后链接器得到这个大小的内存块,紧跟在数据段的后面。当这个内存进入程序的地址空间后全部清零。包含数据段和BSS段的整个区段此时通常称为数据区。
可执行程序在运行时又多出两个区域:栈区和堆区。
栈区:由编译器自动释放,存放函数的参数值、局部变量等。每当一个函数被调用时,该函数的返回类型和一些调用的信息被存放到栈中。然后这个被调用的函数再为他的自动变量和临时变量在栈上分配空间。每调用一个函数一个新的栈就会被使用。栈区是从高地址位向低地址位增长的,是一块连续的内存区域,最大容量是由系统预先定义好的,申请的栈空间超过这个界限时会提示溢出,用户能从栈中获取的空间较小。
堆区:用于动态分配内存,位于BSS和栈中间的地址区域。由程序员申请分配和释放。堆是从低地址位向高地址位增长,采用链式存储结构。频繁的malloc/free造成内存空间的不连续,产生碎片。当申请堆空间时库函数是按照一定的算法搜索可用的足够大的空间。因此堆的效率比栈要低的多。

int a0=1;
static int a1;
const static a2=0;
extern int a3;
void fun(void)
{
int a4;
volatile int a5;
return;
}
a0 :全局初始化变量;生命周期为整个程序运行期间;作用域为所有文件;存储位置为data段。
a1 :全局静态未初始化变量;生命周期为整个程序运行期间;作用域为当前文件;储存位置为BSS段。
a2 :全局静态变量
a3 :全局初始化变量;其他同a0。
a4 :局部变量;生命周期为fun函数运行期间;作用域为fun函数内部;储存位置为栈。
a5 :局部易变变量;生命周期为
内存管理参考链接
变量的类型、作用域、存储空间、生命周期参考链接
static extern 局部变量 全局变量 生命周期 作用域
变量类型参考链接
请用c语言直接编写以下四个宏
1、ALGN_DOWN(x,a)将数值x按照a的整数倍向下取整,例如ALGN_DOWN(65,3)—>63
2、ALGN_UP(x,a) 将数值x按照a的整数倍向上取整,例如ALGN_UP(65,3)—>66
3、ALGN_2N_DOWN(x,a) 将数值x按照a的整数倍向下取整,a是2的n次幂,例如ALGN_2N_DOWN(65,4)—>64.
4、ALGN_2N__UP(x,a) 将数值x按照a的整数倍向上取整,a是2的n次幂,例如ALGN_2N_UP(65,4)—>68.
备注:数值位unsigned int;对2的n次幂的情况只要利用这个特性用更高效的方法实现。
问题3.4执行运算符右移操作,右移就是原数除2
C语言编程
已知某外设有两个32—bit的寄存器
数据寄存器,内存映射地址为0x80000000
状态寄存器,内存映射地址0x80000004
状态寄存器的bit31为A功能的标志位
请补充完成以下结构体描述两个寄存器,
Typedef struct{
………
}A_regs_t;
请用c语言实现如下函数;
/*
*read A data if A status is 1,and then clear the A status bit.
*@param[in] a_regs;pointer to registers of A function
*@param[out] result;data read from register
@retval 0:successs;<0:error code
*/
Int32_t_get_A_result(A_regs_t a_regs,uint32 _tresult);
并写出调用这个函数的代码。
谈一谈大疆的嵌入式笔试题
这次总的来说笔试题并不难,可能头一次参加正规的笔试,稍微有点紧张导致很多简单的题漏掉了一些转换,比如bit和Byte等等。
题型:
一、选择 10道 2*10
以Linux和C为主,还有操作系统,内存带宽等等,题目不是很难,但是一定一定要沉下心来做,争取做一个对一个。
二 多选 3道 4*3
涉及类型跟选择差不多。
三 填空 忘了,3道应该 4*3
循环,内存填充,进程通信方式
四 简答 3道 6*3
1.实时操作系统优缺点。
2.给个程序问里面的四个函数分别调用了多少次,
- mmap比fread读的快的原因。
五 编程 2道 31
两道考的全是链表,这里要多说几句,之前有的人考的是环形队列和有序数组的组合,相对而言,这次的B卷题目有点难,考链表,加上紧张,可能有的指针的指针的指针就给搞迷糊了,编程就在文本编辑框里写,说是能用本地IDE,但是系统还是会记录你跳出的次数,这是我们也是很纠结,干脆直接纯手撕代码了,程序八九不离十跑不起来肯定。
删除双向链表倒数第N个节点后的所有节点。
反转链表。
通过这次笔试,最重要的还是历练一下笔试的心态问题,再就是知识点涉及范围很广,重在平时的积累。
【机试题】2019大疆嵌入式笔试题A卷(附超详细解答)
填空选择题
1、ARM指令和Thumb指令。(选择题)
解答:在ARM的体系结构中,可以工作在三种不同的状态,一是ARM状态,二是Thumb状态及Thumb-2状态,三是调试状态。而ARM状态和Thumb状态可以直接通过某些指令直接切换,都是在运行程序,只不过指令长度不一样而已。
ARM状态:arm处理器工作于32位指令的状态,所有指令均为32位;
Thumb状态:arm执行16位指令的状态,即16位状态;
thumb-2状态:这个状态是ARM7版本的ARM处理器所具有的新的状态,新的thumb-2内核技术兼有16位及32位指令,实现了更高的性能,更有效的功耗及更少地占用内存。总的来说,感觉这个状态除了兼有arm和thumb的优点外,还在这两种状态上有所提升,优化;
调试状态:处理器停机时进入调试状态。
也就是说:ARM状态,此时处理器执行32位的字对齐的ARM指令;Thumb状态,此时处理器执行16位的,半字对齐的THUMB指令。
ARM状态和Thumb状态切换程序:
从ARM到Thumb: LDR R0,=lable+1 BX R0(状态将寄存器的最低位设置为1,BX指令、R0指令将进入thumb状态);
从ARM到Thumb: LDR R0,=lable BX R0(寄存器最低位设置为0,BX指令、R0指令将进入arm状态)。
当处理器进行异常处理时,则从异常向量地址开始执行,将自动进入ARM状态。
关于这个知识点还有几个注意点:
ARM处理器复位后开始执行代码时总是只处于ARM状态;
Cortex-M3只有Thumb-2状态和调试状态;
由于Thumb-2具有16位/32位指令功能,因此有了thumb-2就无需Thumb了。
另外,具有Thumb-2技术的ARM处理器也无需再ARM状态和Thumb-2状态间进行切换了,因为thumb-2具有32位指令功能。
2、哪种总线方式是全双工类型、哪种总线方式传输的距离最短?(选择题)
解答:几种总线接口的通信方式的总结如下图所示:
3、TCP与UDP的区别。(选择题)
解答:TCP和UDP的区别总结如下图所示:

4、Linux的用户态与内核态的转换方法。(选择题)
解答:Linux下内核空间与用户空间进行通信的方式主要有syscall(system call)、procfs、ioctl和netlink等。
syscall:一般情况下,用户进程是不能访问内核的。它既不能访问内核所在的内存空间,也不能调用内核中的函数。Linux内核中设置了一组用于实现各种系统功能的子程序,用户可以通过调用他们访问linux内核的数据和函数,这些系统调用接口(SCI)称为系统调用;
procfs:是一种特殊的伪文件系统 ,是Linux内核信息的抽象文件接口,大量内核中的信息以及可调参数都被作为常规文件映射到一个目录树中,这样我们就可以简单直接的通过echo或cat这样的文件操作命令对系统信息进行查取;
netlink:用户态应用使用标准的 socket API 就可以使用 netlink 提供的强大功能;
ioctl:函数是文件结构中的一个属性分量,就是说如果你的驱动程序提供了对ioctl的支持,用户就可以在用户程序中使用ioctl函数控制设备的I/O通道。
5、linux目录结构,选项是/usr、/tmp、/etc目录的作用。(选择题)
解答:linux目录图:
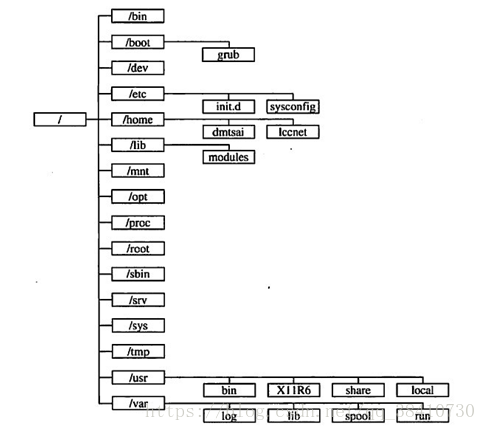
/usr:不是user的缩写,其实usr是Unix Software Resource的缩写, 也就是Unix操作系统软件资源所放置的目录,而不是用户的数据啦。这点要注意。 FHS建议所有软件开发者,应该将他们的数据合理的分别放置到这个目录下的次目录,而不要自行建立该软件自己独立的目录;
/tmp:这是让一般使用者或者是正在执行的程序暂时放置档案的地方。这个目录是任何人都能够存取的,所以你需要定期的清理一下。当然,重要资料不可放置在此目录啊。 因为FHS甚至建议在开机时,应该要将/tmp下的资料都删除;
/etc:系统主要的设定档几乎都放置在这个目录内,例如人员的帐号密码档、各种服务的启始档等等。 一般来说,这个目录下的各档案属性是可以让一般使用者查阅的,但是只有root有权力修改。 FHS建议不要放置可执行档(binary)在这个目录中。 比较重要的档案有:/etc/inittab, /etc/init.d/, /etc/modprobe.conf, /etc/X11/, /etc/fstab, /etc/sysconfig/等等。
6、下面这段程序的运行结果?(选择题)
int main(){
const int x=5;
const int *ptr;
ptr=&x;
*ptr=10;
printf("%d\n",x);
return 0;
}
解答:编译出错。
这道题主要是讲解const与指针的问题:
const int a;
int const a;
const int a;
int * const a;
const int * const a;
int const * const a;
前两个的作用是一样,a是一个常整型数;
第三个意味着a是一个指向常整型数的指针(也就是,整型数是不可修改的,但指针可以);
第四个意思a是一个指向整型 数的常指针(也就是说,指针指向的整型数是可以修改的,但指针是不可修改的);
最后两个意味着a是一个指向常整型数的常指针(也就是说,指针指向的整型数 是不可修改的,同时指针也是不可修改的)。
也就是说:本题x是一个常量,不能改变;ptr是一个指向常整型数的指针。而当ptr=10;的时候,直接违反了这一点。同时要记得一点,const是通过编译器在编译的时候执行检查来确保实现的。
7、在32位系统中,有如下结构体,那么sizeof(fun)的数值是()
pragma pack(1)
struct fun{
int i;
double d;
char c;
};
解答:13。
可能是一般的内存对齐做习惯了,如果本题采用内存对齐的话,结果就是24(int 4 double char 7)。但是#pragma pack(1)让编译器将结构体数据强制按1来对齐。
每个特定平台上的编译器都有自己的默认“对齐系数”(32位机一般为4,64位机一般为8)。我们可以通过预编译命令#pragma pack(k),k=1,2,4,8,16来改变这个系数,其中k就是需要指定的“对齐系数”。
只需牢记:
第一个数据成员放在offset为0的地方,对齐按照对齐系数和自身占用字节数中,二者比较小的那个进行对齐;
在数据成员完成各自对齐以后,struct或者union本身也要进行对齐,对齐将按照对齐系数和struct或者union中最大数据成员长度中比较小的那个进行;
参考文章:#pragma pack()的解读。
8、Linux中的文件/目录权限设置命令是什么?(选择题)
解答:chmod

10、C语言的各种变量的存取区域,给你一段小程序,让你分析各个变量的存储区域(填空题)
解答:具体的题目内容忘了,但是大体上给出各个变量可能的存储区域:
堆:堆允许程序在运行时动态地申请某个大小的内存。一般由程序员分配释放;
栈:由编译器自动分配释放,存放函数的参数值,局部变量等值;
静态存储区:一定会存在且不会消失,这样的数据包括常量、常变量(const 变量)、静态变量、全局变量等;
常量存储区:常量占用内存,只读状态,决不可修改,常量字符串就是放在这里的。
11、下面这段程序的运行结果?(填空题)
int main() {
int a[10] = { 0,1,2,3,4,5,6,7,8,9 };
memcpy(a + 3, a, 5);
for (int i = 0; i<10; i++){
printf("%d ", a[i]);
}
return 0;
}
解答:0 1 2 0 1 5 6 7 8 9
首先看一下内存复制函数memcpy()函数的定义:
void * memcpy ( void * destination, const void * source, size_t num );
将source指向的地址处的 num 个字节 拷贝到 destination 指向的地址处。注意,是字节。
因为memcpy的最后一个参数是需要拷贝的字节的数目!一个int类型占据4个字节!这样的话,本题5字节,实际上只能移动2个数字(往大的去)。如果要想达到将a地址开始的5个元素拷贝到a+3地址处,需要这么写:
memcpy(a + 3, a, 5*sizeof(int));
参考文章:memcpy使用时需要注意的地方。
12、C语言编译过程中,volatile关键字和extern关键字分别在哪个阶段起作用?(填空题)
解答:volatile应该是在编译阶段,extern在链接阶段。
volatile关键字的作用是防止变量被编译器优化,而优化是处于编译阶段,所以volatile关键字是在编译阶段起作用。
参考文章:C语言文件的编译与执行的四个阶段并分别描述和volatile为什么要修饰中断里的变量。
13、linux系统打开设备文件,进程可能处于三种基本状态,如果多次打开设备文件,驱动程序应该实现什么?(填空题)
不太清楚……
简答题
1、简述实时操作系统和非实时操作系统特点和区别。
解答:实时操作系统是保证在一定时间限制内完成特定功能的操作系统。实时操作系统有硬实时和软实时之分,硬实时要求在规定的时间内必须完成操作,这是在操作系统设计时保证的;软实时则只要按照任务的优先级,尽可能快地完成操作即可。
实时性最主要的含义是:任务的最迟完成时间是可确认预知的。

2、简述static关键字对于工程模块化的作用。
解答:在C语言中,static有下3个作用:
函数体内的static变量的作用范围为该函数体,不同于auto变量,该变量的内存只被分配一次,以为其值在下次调用时仍维持上次的值(该变量存放在静态变量区);
在模块内static全局变量可以被模块内所有函数访问,但不能被模块外其他函数访问。(注意,只有在定义了变量后才能使用。如果变量定义在使用之后,要用extern 声明。所以,一般全部变量都会在文件的最开始处定义。);
在模块内的static函数只可被这一模块内的其他函数调用,这个函数的使用范围被限制在声明它的模块内。
在嵌入式系统中,要时刻懂得移植的重要性,程序可能是很多程序员共同协作同时完成,在定义变量及函数的过程,可能会重名,这给系统的集成带来麻烦,因此保证不冲突的办法是显示的表示此变量或者函数是本地的,static即可。在Linux的模块编程中,这一条很明显,所有的函数和全局变量都要用static关键字声明,将其作用域限制在本模块内部,与其他模块共享的函数或者变量要EXPORT到内核中。
3、无锁可以提高整个程序的性能,但是CPU需要对此提供支持,请以x86/ARM为例简述。
解答:无锁编程具体使用和考虑到的技术方法包括:原子操作(atomic operations), 内存栅栏(memory barriers), 内存顺序冲突(memory order), 指令序列一致性(sequential consistency)和顺ABA现象等等。
在这其中最基础最重要的是操作的原子性或说原子操作。原子操作可以理解为在执行完毕之前不会被任何其它任务或事件中断的一系列操作。原子操作是非阻塞编程最核心基本的部分,没有原子操作的话,操作会因为中断异常等各种原因引起数据状态的不一致从而影响到程序的正确。
对于原子操作的实现机制,在硬件层面上CPU处理器会默认保证基本的内存操作的原子性,CPU保证从系统内存当中读取或者写入一个字节的行为肯定是原子的,当一个处理器读取一个字节时,其他CPU处理器不能访问这个字节的内存地址。但是对于复杂的内存操作CPU处理器不能自动保证其原子性,比如跨总线宽度或者跨多个缓存行(Cache Line),跨页表的访问等。这个时候就需要用到CPU指令集中设计的原子操作指令,现在大部分CPU指令集都会支持一系列的原子操作。
而在无锁编程中经常用到的原子操作是Read-Modify-Write (RMW)这种类型的,这其中最常用的原子操作又是 COMPARE AND SWAP(CAS),几乎所有的CPU指令集都支持CAS的原子操作,比如X86平台下中的是 CMPXCHG(Compare Are Exchange)。
继续说一下CAS,CAS操作行为是比较某个内存地址处的内容是否和期望值一致,如果一致则将该地址处的数值替换为一个新值。CAS操作具体的实现原理主要是两种方式:总线锁定和缓存锁定。所谓总线锁定,就是CPU执行某条指令的时候先锁住数据总线的, 使用同一条数据总线的CPU就无法访问内存了,在指令执行完成后再释放锁住的数据总线。锁住数据总线的方式系统开销很大,限制了访问内存的效率,所以又有了基于CPU缓存一致性来保持操作原子性作的方法作为补充,简单来说就是用CPU的缓存一致性的机制来防止内存区域的数据被两个以上的处理器修改。
最后这里随便说一下CAS操作的ABA的问题,所谓的ABA的问题简要的说就是,线程a先读取了要对比的值v后,被线程b抢占了,线程b对v进行了修改后又改会v原来的值,线程1继续运行执行CAS操作的时候,无法判断出v的值被改过又改回来。
解决ABA的问题的一种方法是,一次用CAS检查双倍长度的值,前半部是指针,后半部分是一个计数器;或者对CAS的数值加上版本号。
参考文章:无锁编程技术及实现。
编程题
1、已知循环缓冲区是一个可以无限循环读写的缓冲区,当缓冲区满了还继续写的话就会覆盖我们还没读取到的数据。下面定义了一个循环缓冲区并初始化,请编写它的Write函数:
typedef struct RingBuf {
char *Buf;
unsigned int Size;
unsigned int RdId;
unsigned int WrId;
}RingBuf;
void Init(RingBuf *ringBuf, char *buf, unsigned int size) {
memset(ringBuf, 0, sizeof(RingBuf));
ringBuf->Buf = buf;
ringBuf->Size = size;
ringBuf->RdId = 0;
ringBuf->WrId = 0;
}
解答:实际上我觉得提供的初始化代码部分,对WrId的初始化有点问题,Write()函数的完整代码如下:
typedef struct RingBuf {
char *Buf;
unsigned int Size;
unsigned int RdId;
unsigned int WrId;
}RingBuf;
void Init(RingBuf *ringBuf, char *buf, unsigned int size) {
memset(ringBuf, 0, sizeof(RingBuf));
ringBuf->Buf = buf;
ringBuf->Size = size;
ringBuf->RdId = 0;
ringBuf->WrId = strlen(buf);
}
void Write(RingBuf *ringBuf, char *buf, unsigned int len) {
unsigned int pos = ringBuf->WrId;
while (pos + len > ringBuf->Size) {
memcpy(ringBuf->Buf + pos, buf, ringBuf->Size - pos);
buf += ringBuf->Size - pos;
len -= ringBuf->Size - pos;
pos = 0;
}
memcpy(ringBuf->Buf + pos, buf, len);
ringBuf->WrId = pos + len;
}
void Print(RingBuf *ringBuf) {
for (int i = 0; i < ringBuf->Size; i++) {
cout << ringBuf->Buf[i];
}
cout << endl;
}
int main()
{
RingBuf *rb = (RingBuf *)malloc(sizeof(RingBuf));
char init_str[] = "ABC";
int size = 6;
Init(rb, init_str, size);
char p[] = "1234567";
Write(rb, p, 7);
Print(rb);
return 0;
}
2、已知两个已经按从小到大排列的数组,将它们中的所有数字组合成一个新的数组,要求新数组也是按照从小到大的顺序。请按照上述描述完成函数:
int merge(int *array1, int len1, int *array2, int len2, int *array3);
解答:这道题本质上就是一道合并排序,网上一大堆的程序案例,就不多介绍了。下面这段程序是我自己写的,并不是从网上贴的,如果有一些BUG,还请指出。
int merge(int *array1, int len1, int *array2, int len2, int array3) {
int retn = len1 + len2;
if ((array1 < *array2 || len2 == 0) && len1 > 0) {
*array3 = array1;
merge(++array1, --len1, array2, len2, ++array3);
}
if ((array1 >= *array2 || len1 == 0) && len2 > 0) {
*array3 = *array2;
merge(array1, len1, ++array2, --len2, ++array3);
}
return retn;
【机试题】2019.8.4大疆嵌入式笔试题A卷
1、求a的值
经过表达式a = 5 ? 0 : 1的运算,变量a的最终值是 0
1
boolean虚拟机取值时候是掩码去掉前七位之后取末尾判断,0是false,1是true,而5对应的是00001001,所以这块表示的是1,也就是true,所以对应的是三目运算里面的结果是 0。
2、数组int a[3][4]中的a[2][1]用其他形式表示:
((a+2)+1)
1
*(a[2] + 1)
1
int *p = &a[0][0] ;//p[9], 表示 a[2][1];
1
3、在soc中常常用做对外设寄存器配置总线的是:i2c,spi
4、哈佛结构和冯诺依曼结构的区别:
要理解哈弗结构和冯诺依曼结构的区别,首先要知道我们在编写程序的时候其实可以对程序的代码划分为两个部分,一部分是程序编写完成后就不再需要对其进行修改了的(也就是逻辑代码部分)另一部分就是在程序编写完毕后其内容会随着程序的运行而不断变化的部分(也就是定义变量)。而哈佛结构和冯诺依曼结构就是对于这个两部分代码的存储方式的区别。
哈佛结构(Harvard architecture)是一种将程序指令储存和数据储存分开的存储器结构。
中央处理器首先到程序指令储存器中读取程序指令内容,解码后得到数据地址,再到相应的数据储存器中读取数据,并进行下一步的操作(通常是执行)。程序指令储存和数据储存分开,数据和指令的储存可以同时进行,可以使指令和数据有不同的数据宽度。
哈佛结构的微处理器通常具有较高的执行效率。其程序指令和数据指令分开组织和储存的,执行时可以预先读取下一条指令。
大多数ARM、DSP是哈佛结构。

冯.诺伊曼结构(von Neumann architecture)是一种将程序指令存储器和数据存储器合并在一起的存储器结构。
大多数CPU和GPU是冯诺依曼结构的。

冯诺依曼结构则是将逻辑代码段和变量统一都存储在内存当中,他们之间一般是按照代码的执行顺序依次存储。这样就会导致一个问题,如果当程序出现BUG的时候,由于程序没有对逻辑代码段的读写限定,因此,他将拥有和普通变量一样的读写操作权限。于是就会很容易的死机,一旦他的逻辑执行出现一点该变就会出现非常严重的错误。但是,冯诺依曼结构的好处是可以充分利用有限的内存空间,并且会使CPU对程序的执行十分的方便,不用来回跑。
5、联合体和结构体
结构体(struct)各成员各自拥有自己的内存,各自使用互不干涉,同时存在的,遵循内存对齐原则。一个struct变量的总长度等于所有成员的长度之和。
而联合体(union)各成员共用一块内存空间,并且同时只有一个成员可以得到这块内存的使用权(对该内存的读写),各变量共用一个内存首地址。因而,联合体比结构体更节约内存。一个union变量的总长度至少能容纳最大的成员变量,而且要满足是所有成员变量类型大小的整数倍。
include<stdio.h>
//结构体
struct u //u表示结构体类型名
{
char a; //a表示结构体成员名
int b;
short c;
}U1;
//U1表示结构体变量名
//访问该结构体内部成员时可以采用U1.a=1;其中"点"表示结构体成员运算符
//联合体
union u1 //u1表示联合体类型名
{
char a; //a表示联合体成员名
int b;
short c;
}U2;
//U2表示联合体变量名
//访问该联合体内部成员时可以采用U2.a=1;其中"点"表示联合体成员运算符
//主函数
int main(){
printf("%d\n",sizeof(U1));
printf("%d\n",sizeof(U2));
return 0;
}
/程序运行结果是:
12
4/
填空题4道
1、大小端问题
A=0x12345678存入地址1000H~10003H中,
小端模式:1000H=78 1001H=56 1002H=34 1003H=12
大端模式:1000H=12 1001H=34 1002H=56 1003H=78
2、宏定义计算问题
define PRODUCT (x) (x*x)
int main()
{
int a,b=3;
a=PRODUCT(b+2);
}
1
2
3
4
5
6
7
求a值:
b+2b+2=3+23+2=11
1
3、有符号和无符号混合三目运算问题
void foo(void)
{
unsigned int a = 6;
int b = -20;
int c;
(a+b > 6) ? (c=1) : (c=0);
}
1
2
3
4
5
6
7
这个问题测试C语言中的整数自动转换原则,这无符号整型问题的答案是c=1。原因是当表达式中存在有符号类型和无符号类型时所有的操作数都自动转换为无符号类型。因此-20变成了一个非常大的正整数,所以该表达式计算出的结果c=1。
简答题3道
1、简述任务/线程之间的同步方式
互斥锁:锁机制是同一时刻只允许一个线程执行一个关键部分的代码。
条件变量:条件变量是利用线程间共享全局变量进行同步的一种机制。条件变量上的基本操作有:触发条件(当条件变为 true 时),等待条件,挂起线程直到其他线程触发条件。
信号量:为控制一个具有有限数量用户资源而设计。
事 件:用来通知线程有一些事件已发生,从而启动后继任务的开始。
Linux中四种进程或线程同步互斥控制方法
2、简述可执行程序的内存布局


3、设计机制保证锁可以按照先到先得的方式被任务获取,并且占用内存空间最小(题目没有说全,记不清,考察操作系统和队列的应用)
编程题2道
1、比较输入字符串s1和s2前n个字符,忽略大小写,如果字符串s1和s2相同则返回0,不同则返回第一个不同字符的差值。
tolower是一种函数,功能是把字母字符转换成小写,非字母字符不做出处理。
include <stdio.h>
include <string.h>
include <ctype.h>
int strcmpx(const char s1, const char s2, unsigned int n)
{
int c1, c2;
do {
c1 = tolower(s1++);
c2 = tolower(s2++);
} while((--n > 0) && c1 == c2 && c1 != 0);
return c1 - c2;
}
int main(void)
{
int n = 4;
char str3[] = "ABCf";
char str4[] = "abcd";
printf("strcmpx(str3, str4, n) = %d", strcmpx(str3, str4, n));
return 0;
}
2、N X N数组,输出行中最小,列中最大的数的位置,比如:
1 2 3
4 5 6
7 8 9
输出:row=2,col=0
分析:
在矩阵中,一个数在所在行中是最大值,在所在列中是最小值,则被称为鞍点。
鞍点C++实现
//C语言输出矩阵马鞍点
include<stdio.h>
void Input_Matrix(int m,int n,int a[100][100]) //输入矩阵元素
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
scanf("%d", &a[i][j]);
}
}
}
void Output_Matrix(int m, int n, int a[100][100]) //输出矩阵元素
{
for (int i = 0; i < m; i++)
{
for (int j = 0; j < n; j++)
{
printf("%-5d", a[i][j]);
}
printf("\n");
}
}
void Matrix_Mn(int m, int n, int a[100][100]) //输出矩阵马鞍点
{
int flag = 0;
int min, max, k, l;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
min = a[i][j];
for (k = 0; k < m; k++)
{
if (min < a[i][k])
break;
}
if (k == m)
{
max = a[i][j];
for (l = 0; l < n; l++)
{
if (max > a[l][j])
break;
}
if (l == n)
{
printf("%-5d%-5d\n", i, j);
printf("矩阵元素为:a[%d][%d]=%d\n",i,j, a[i][j]);
flag = 1;
}
}
}
}
if (flag == 0)
{
printf("该矩阵没有马鞍点!\n");
}
}
int main(void)
{
int m, n;
int a[100][100];
for (;😉
{
printf("请输入矩阵的行数和列数:\n");
scanf("%d %d", &n, &m);
printf("请输入矩阵中的元素:\n");
Input_Matrix(m, n, a);
printf("矩阵输出为:\n");
Output_Matrix(m, n, a);
printf("马鞍点输出(该点所在的行数和列数):\n");
Matrix_Mn(m, n, a);
}
return 0;
}
题目要求是一个数在所在行中是最小值,在所在列中是最大值,不确定还能不能称为鞍点,但是算法思路相似的。
思路:
先找第i行上最小的元素t,以及所在列minj
判断t是否为第minj列的最大值,如果不是则在minj列中继续寻找最大值并输出,如果是则输出
include <stdio.h>
define N 3
int a[N][N]={1,2,3,4,5,6,7,8,9};
int main()
{
int i,j,t,minj;
for(i=0;i<N;i++)
{
t=a[i][0];
minj=0;
for(j=1;j<N;j++)//行上最小
{
if(a[i][j]<t)
{
t=a[i][j];
minj=j;//找到了行上最小的数所在的列
}
}
int k;
for(k=0;k<N;k++)
if(a[k][minj]>t)//判断是否列上最大
break;
if(k<N) continue;//接着查找下一行
printf("所求点是:a[%d][%d]:%d\n",i,minj,t);
}
return 0;
}
相关基础知识:
break:
(1).结束当前整个循环,执行当前循环下边的语句。忽略循环体中任何其它语句和循环条件测试。
(2).只能跳出一层循环,如果你的循环是嵌套循环,那么你需要按照你嵌套的层次,逐步使用break来跳出。
continue:
(1).终止本次循环的执行,即跳过当前这次循环中continue语句后尚未执行的语句,接着进行下一次循环条件的判断。
(2).结束当前循环,进行下一次的循环判断。
(3).终止当前的循环过程,但他并不跳出循环,而是继续往下判断循环条件执行语句.他只能结束循环中的一次过程,但不能终止循环继续进行。
2020届校招大疆嵌入式部分笔试题
在32位系统中有如下定义,则sizeof(data_t)的值是()
typedef struct data{
char m:3;
char n:5;
short s;
union{
int a;
char b;
};
int h;
}attribute((packed)) data_t;
sizeof(data_t) = 11;
attribute((packed))的作用就是告诉编译器取消结构在编译过程中的优化对齐,按照实际占用字节数对齐,union联合体里面的变量是共享一个地址空间的,以及结构体的位段操作知识点。
参考博客:
attribute((packed))详解
结构体、位段与联合体
程序按64位编译,运行下列程序代码,打印输出结果是多少
define CALC(x,y) (x*y)
int main(void) {
int i=3;
int calc;
char **a[5][6];
calc = CALC(i++, sizeof(a)+5);
printf("i=%d, calc=%d\n", i, calc);
return 0;
}
输出结果为:i=4, calc=725
注意在宏定义中带参数时括号的用法,在本题中#define CALC(x, y) (xy)的结果是725,但是如果这样写:#define CALC(x,y) (x)(y) 的结果就是735
一般32位机器就是564 = 120,64位则是568=240 ,char *a是字符型指针,char **a是指针的指针,在64位和32位中指针的大小是不一样的
参考博客:
带参数的宏定义
Linux系统中内核线程和普通线程的区别
普通线程和内核线程
内核线程和用户线程
大疆嵌入式笔试总结
单选,多选和填空
(1)缓存和寄存器哪个比较快
CPU <— > 寄存器<— > 缓存<— >内存
(2)波特率是以什么为单位,比特率又是以为什么为单位
1波特即指每秒传输1个码元符号(通过不同的调制方式,可以在一个码元符号上负载多个bit位信息),1比特每秒是指每秒传输1比特(bit)。
用实际使用中,最常用的串口通讯协议举例,注意前置条件为:1 个起始位,8 个数据位,0 个校验位,1 个停止位,也就是我们常说的:8,N,1;8 个数据位,一个停止位,无校验位。
这个条件分析一下就是,如果我要传输一个字节(8 位)的数据,则我应该在总线上产生 10 个电平变换,也就是串行总线上,需要 10 位,才能发送 1 个字节数据。
1 秒可以发送 9600 位,那么用 9600/10 ,就是1秒可以发送 960 个字节数据,则每发送一个字节需要的时间就是:1/960 ~= 0.00104166…s ~= 1.0416667 ms。
此时就可以得出一个结论,在 9600 波特率下,大概 1ms 发送 1 个字节的数据。
(3)对ARM处理器异常的理解
外部中断,内部异常,系统调用都属于
(4)Cotex_M基础知识的掌握
(5)LDR R0,=0x12345678是直接将值赋给R0吗
就是把0x12345678这个地址中的值存放到r0中。
(6)IO密集型类知识
(7)支持优先级继承调度器会动态改变任务优先级?
(8)git命令相关知识
(9)哪些不是实时操作系统
需要注意的是带有RT的基本上都是实时性操作系统
WIN,Linux都是分时操作系统
(10)ARM_V8支持64位?
大致来说,ARMv8架构跟AMD和Intel的做法一样,采取64位兼容32位的方式。应用程序可以以32位模式执行,也可以以64位模式执行。
(11)NEON,PMIPB等操作
(12)SPI有几种工作模式
SPI总线有四种工作方式(SP0, SP1, SP2, SP3),其中使用的最为广泛的是SPI0和SPI3方式。
(13)栈空间大小会不会影响编译出来的bin固件大小
这个。。暂时还没听说过
(14)00编译优化是不是默认不优化
(15)inline内联基础知识及其作用
在 c/c++ 中,为了解决一些频繁调用的小函数大量消耗栈空间(栈内存)的问题,特别的引入了 inline 修饰符,表示为内联函数。栈空间就是指放置程序的局部数据(也就是函数内数据)的内存空间。
(16)给图片大小和码率还是啥,求带宽多少Gbps
(17)VTOR作用,普通中断是不是只把R0-R3数据压栈,PRIMASK作用
VTOR中断向量表偏移寄存器
cortex-M3 中断调用过程
入栈
中断发生后,中断服务函数运行前,会先把xPSR, PC, LR, R12以及R3‐R0总共8个寄存器由硬件自动压入适当的堆栈中(中断前使用的MSP就压入MSP,中断前使用的是PSP就压入PSP
(18)内联函数的作用
避免函数调用的开销
(19)ARM Cotex -M 都是哈佛体系?-A冯诺依曼体系?
有一些ARM(Cortex-M系列)是哈佛结构,而另一些ARM(Cortex-A)是冯诺依曼结构(或者更准确说是混合结构)。
(20)I2S总线相关知识
I2S特点
①支持全双工和半双工通信。(单工数据传输只支持数据在一个方向上传输;半双工数据传输允许数据在两个方向上传输,但是在某一时刻,只允许数据在一个方向上传输,它实际上是一种切换方向的单工通信;全双工数据通信允许数据同时在两个方向上传输,因此,全双工通信是两个单工通信方式的结合,它要求发送设备和接收设备都有独立的接收和发送能力。
②支持主/从模式。(主模式:就是主CPU作为主机,向从机(挂载器件)发送接收数据。从模式:就是主CPU作为从机,接收和发送主机(挂载器件)数据。而主从机的分别其实是一个触发的作用,主机主动触发,从机只能被动响应触发。)
I2S总线拥有三条数据信号线:
1、SCK: (continuous serial clock) 串行时钟
对应数字音频的每一位数据,SCK都有1个脉冲。SCK的频率=2×采样频率×采样位数。
2、WS: (word select) 字段(声道)选择
用于切换左右声道的数据。WS的频率=采样频率。
命令选择线表明了正在被传输的声道。
WS为“1”表示正在传输的是左声道的数据。
WS为“0”表示正在传输的是右声道的数据。
WS可以在串行时钟的上升沿或者下降沿发生改变,并且WS信号不需要一定是对称的。在从属装置端,WS在时钟信号的上升沿发生改变。WS总是在最高位传输前的一个时钟周期发生改变,这样可以使从属装置得到与被传输的串行数据同步的时间,并且使接收端存储当前的命令以及为下次的命令清除空间。
3、SD: (serial data) 串行数据
用二进制补码表示的音频数据。 I2S格式的信号无论有多少位有效数据,数据的最高位总是被最先传输(在WS变化(也就是一帧开始)后的第2个SCK脉冲处),因此最高位拥有固定的位置,而最低位的位置则是依赖于数据的有效位数。也就使得接收端与发送端的有效位数可以不同。如果接收端能处理的有效位数少于发送端,可以放弃数据帧中多余的低位数据;如果接收端能处理的有效位数多于发送端,可以自行补足剩余的位(常补足为零)。这种同步机制使得数字音频设备的互连更加方便,而且不会造成数据错位。为了保证数字音频信号的正确传输,发送端和接收端应该采用相同的数据格式和长度。当然,对I2S格式来说数据长度可以不同。
(21)I2C主机发送__作为初始信号
起始信号:SCL为高电平期间,SDA线由高电平向低电平的变化
问答:
(1)栈空间大小多大,往一个数组写4K btye数据栈会不会溢出?如果会还有哪些情况会溢
出?如果不会溢出会发生什么问题?
自行测试linux的栈的默认空间在7~8Mbyte之间接近8M,通过ulimit -s可以知道理论值是8M
但是栈的空间是不固定的,我们可以用ulimit -s 10240 更改其栈空间,单位KByte
当然不同系统的默认栈值可能不一样,比如win系统的栈不到1M
对于堆内存来说,可以申请的内存非常大,几乎可以申请超万个G我也不知道为什么。
当一个进程退出后,不管是正常退出或者是异常退出,操作系统都会释放这个进程的资源。包括这个进程分配的内存。
(2)写一个宏定义,给一个结构体成员地址,返回结构体的首地址
编程题:
(1)给一个正整数n,求从1-n这些数字总共出现’1’的次数
(2)求圆周率的N位精度,这个N可能非常非常大

 浙公网安备 33010602011771号
浙公网安备 33010602011771号