
NLP-特征选择
文本分类之特征选择
1 研究背景
对于高纬度的分类问题,我们在分类之前一般会进行特征降维,特征降维的技术一般会有特征提取和特征选择。而对于文本分类问题,我们一般使用特征选择方法。
- 特征提取:PCA、线性判别分析
- 特征选择:文档频数、信息增益、期望交叉熵、互信息、文本证据权、卡方等
特征选择的目的一般是:
- 避免过拟合,提高分类准确度
-
通过降维,大大节省计算时间和空间
特征选择基本思想:
1)构造一个评价函数
2)对特征空间的每个特征进行评分
3)对所有的特征按照其评估分的大小进行排序
4)从中选取一定数目的分值最高的特征项
2 常用特征选择方法
|
c |
~c |
|
|
t |
A |
B |
|
~t |
C |
D |
2.1文档频率(Document Frequency,DF)
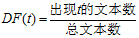
优点:实现简单,计算量小。
缺点:基于低频词不含分类信息或者只包含极少量分类信息,没有考虑类别信息,但实际并非如此。
2.2 互信息(Mutual Information, MI)
来自Claude Edwood Shannon的信息论,计算一个消息中两个信号之间的相互依赖程度。在文本分类中是计算特征词条与文本类的相互关联程度。
特征t在类别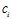 中MI公式:
中MI公式:
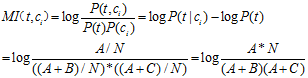
特征项t在整个样本中的互信息值:
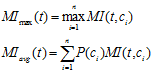
缺点:
对低频词十分敏感。若B为0时,无论A为多少算出来MI都一样,而且都很大。
2.3信息增益(Information Gain, IG)
来源于信息熵,公式:
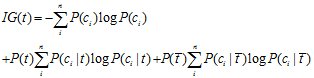
优点:信息增益考虑了特征未发生的情况,特征不出现的情况可能对文档类别具有贡献
缺点:对只出现在一类的低频词有一定程度的倚重,但这类低频词未必具有很好的分类信息。
2.4卡方检验(chi-square)
源于统计学的卡方分布(chi-square),从(类,词项)相关表出发,考虑每一个类和每一个词项的相关情况,度量两者(特征和类别)独立性的缺乏程度,卡方越大,独立性越小,相关性越大。
特征t在类别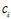 中的CHI公式:
中的CHI公式:
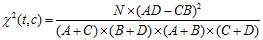
特征项t在整个样本中的卡方值:
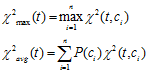
缺点:和IG一样,对低频词有一定程度的倚重。
3实验效果
任务:二元文本分类
数据集:
|
训练集 |
测试集 |
|
|
BCII |
5494篇文档(3536个正例,1959个负例) |
677篇文档(338个负例,339个负例) |
|
BCIII |
2280篇文档(1140个正例,1140个负例) |
6000篇文档(910个正例,5090个负例) |
实验方法:
-
文本预处理
-
特征选择:一元词特征
-
构建文本模型:BoW(布尔权值)
-
机器学习分类算法:SVM
-
评价指标:正类的F值
实验结果:
BCII结果
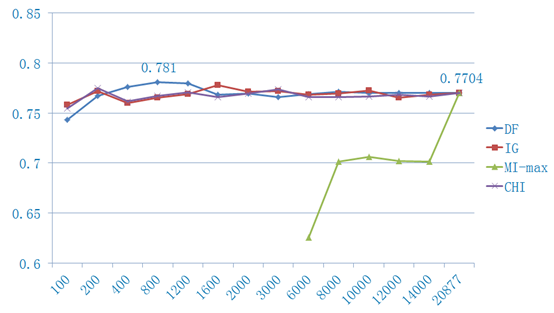
BCIII结果
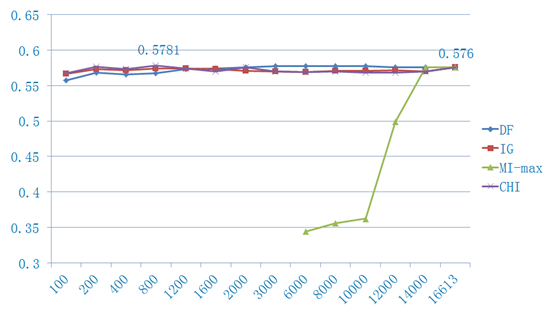 4 总结
4 总结
|
DF |
IG |
CHI |
MI |
|
|
倚重低频词 |
N |
Y |
Y |
Y |
|
考虑类别信息 |
N |
Y |
Y |
Y |
|
考虑特征不出现的情况 |
N |
Y |
Y |
N |
经验:
1)MI对于低频词过于敏感,对于特征出现频率差异较大的数据集,MI效果十分不理想。
2)DF的效果并没有想象中的差(除去停用词),和IG、CHI差不多,不过要是降到很低维的时候,一般还是IG和CHI的效果比较好。
3)若是数据集低频词数量比较多,DF效果甚至好于IG和CHI。
4)当数据集是均匀分布时,CHI的效果要略优于IG,而当数据集类别分布极为不均时,IG的效果要优于CHI。
5)不同的分类算法、评价指标等得到的效果可能会有所不同。
我们最好是根据自己的数据集分布,想达到的目的(降维?精确度?),来选择合适的特征选择方法。
参考文献:
[1] Y.Yang, J.Pedersen. A comparative study on feature selection in text categorization. 1997
[2] G. Foreman. An Extensive Empirical Study of Feature Selection Metrics for Text Classification. 2003
[3] 代六玲,黄河燕等. 中文文本分类中特征抽取方法的比较研究. 2004

 浙公网安备 33010602011771号
浙公网安备 33010602011771号