人工智能结课作业-遗传算法/粒子群寻优/蚁群算法解决TSP问题
代码已经发布到了github:https://github.com/roadwide/AI-Homework
如果帮到你了,希望给个star鼓励一下
1 遗传算法
1.1算法介绍
遗传算法是模仿自然界生物进化机制发展起来的随机全局搜索和优化方法,它借鉴了达尔文的进化论和孟德尔的遗传学说。其本质是一种高效、并行、全局搜索的方法,它能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应的控制搜索过程以求得最优解。遗传算法操作使用适者生存的原则,在潜在的解决方案种群中逐次产生一个近似最优解的方案,在遗传算法的每一代中,根据个体在问题域中的适应度值和从自然遗传学中借鉴来的再造方法进行个体选择,产生一个新的近似解。这个过程导致种群中个体的进化,得到的新个体比原来个体更能适应环境,就像自然界中的改造一样。
遗传算法具体步骤:
(1)初始化:设置进化代数计数器t=0、设置最大进化代数T、交叉概率、变异概率、随机生成M个个体作为初始种群P
(2)个体评价:计算种群P中各个个体的适应度
(3)选择运算:将选择算子作用于群体。以个体适应度为基础,选择最优个体直接遗传到下一代或通过配对交叉产生新的个体再遗传到下一代
(4)交叉运算:在交叉概率的控制下,对群体中的个体两两进行交叉
(5)变异运算:在变异概率的控制下,对群体中的个体进行变异,即对某一个体的基因进行随机调整
(6)经过选择、交叉、变异运算之后得到下一代群体P1。
重复以上(1)-(6),直到遗传代数为 T,以进化过程中所得到的具有最优适应度个体作为最优解输出,终止计算。
旅行推销员问题(Travelling Salesman Problem, TSP):有n个城市,一个推销员要从其中某一个城市出发,唯一走遍所有的城市,再回到他出发的城市,求最短的路线。
应用遗传算法求解TSP问题时需要进行一些约定,基因是一组城市序列,适应度是按照这个基因的城市顺序的距离和分之一。
1.2实验代码
import random import math import matplotlib.pyplot as plt #读取数据 f=open("test.txt") data=f.readlines() #将cities初始化为字典,防止下面被当成列表 cities={} for line in data: #原始数据以\n换行,将其替换掉 line=line.replace("\n","") #最后一行以EOF为标志,如果读到就证明读完了,退出循环 if(line=="EOF"): break #空格分割城市编号和城市的坐标 city=line.split(" ") map(int,city) #将城市数据添加到cities中 cities[eval(city[0])]=[eval(city[1]),eval(city[2])] #计算适应度,也就是距离分之一,这里用伪欧氏距离 def calcfit(gene): sum=0 #最后要回到初始城市所以从-1,也就是最后一个城市绕一圈到最后一个城市 for i in range(-1,len(gene)-1): nowcity=gene[i] nextcity=gene[i+1] nowloc=cities[nowcity] nextloc=cities[nextcity] sum+=math.sqrt(((nowloc[0]-nextloc[0])**2+(nowloc[1]-nextloc[1])**2)/10) return 1/sum #每个个体的类,方便根据基因计算适应度 class Person: def __init__(self,gene): self.gene=gene self.fit=calcfit(gene) class Group: def __init__(self): self.GroupSize=100 #种群规模 self.GeneSize=48 #基因数量,也就是城市数量 self.initGroup() self.upDate() #初始化种群,随机生成若干个体 def initGroup(self): self.group=[] i=0 while(i<self.GroupSize): i+=1 #gene如果在for以外生成只会shuffle一次 gene=[i+1 for i in range(self.GeneSize)] random.shuffle(gene) tmpPerson=Person(gene) self.group.append(tmpPerson) #获取种群中适应度最高的个体 def getBest(self): bestFit=self.group[0].fit best=self.group[0] for person in self.group: if(person.fit>bestFit): bestFit=person.fit best=person return best #计算种群中所有个体的平均距离 def getAvg(self): sum=0 for p in self.group: sum+=1/p.fit return sum/len(self.group) #根据适应度,使用轮盘赌返回一个个体,用于遗传交叉 def getOne(self): #section的简称,区间 sec=[0] sumsec=0 for person in self.group: sumsec+=person.fit sec.append(sumsec) p=random.random()*sumsec for i in range(len(sec)): if(p>sec[i] and p<sec[i+1]): #这里注意区间是比个体多一个0的 return self.group[i] #更新种群相关信息 def upDate(self): self.best=self.getBest() #遗传算法的类,定义了遗传、交叉、变异等操作 class GA: def __init__(self): self.group=Group() self.pCross=0.35 #交叉率 self.pChange=0.1 #变异率 self.Gen=1 #代数 #变异操作 def change(self,gene): #把列表随机的一段取出然后再随机插入某个位置 #length是取出基因的长度,postake是取出的位置,posins是插入的位置 geneLenght=len(gene) index1 = random.randint(0, geneLenght - 1) index2 = random.randint(0, geneLenght - 1) newGene = gene[:] # 产生一个新的基因序列,以免变异的时候影响父种群 newGene[index1], newGene[index2] = newGene[index2], newGene[index1] return newGene #交叉操作 def cross(self,p1,p2): geneLenght=len(p1.gene) index1 = random.randint(0, geneLenght - 1) index2 = random.randint(index1, geneLenght - 1) tempGene = p2.gene[index1:index2] # 交叉的基因片段 newGene = [] p1len = 0 for g in p1.gene: if p1len == index1: newGene.extend(tempGene) # 插入基因片段 p1len += 1 if g not in tempGene: newGene.append(g) p1len += 1 return newGene #获取下一代 def nextGen(self): self.Gen+=1 #nextGen代表下一代的所有基因 nextGen=[] #将最优秀的基因直接传递给下一代 nextGen.append(self.group.getBest().gene[:]) while(len(nextGen)<self.group.GroupSize): pChange=random.random() pCross=random.random() p1=self.group.getOne() if(pCross<self.pCross): p2=self.group.getOne() newGene=self.cross(p1,p2) else: newGene=p1.gene[:] if(pChange<self.pChange): newGene=self.change(newGene) nextGen.append(newGene) self.group.group=[] for gene in nextGen: self.group.group.append(Person(gene)) self.group.upDate() #打印当前种群的最优个体信息 def showBest(self): print("第{}代\t当前最优{}\t当前平均{}\t".format(self.Gen,1/self.group.getBest().fit,self.group.getAvg())) #n代表代数,遗传算法的入口 def run(self,n): Gen=[] #代数 dist=[] #每一代的最优距离 avgDist=[] #每一代的平均距离 #上面三个列表是为了画图 i=1 while(i<n): self.nextGen() self.showBest() i+=1 Gen.append(i) dist.append(1/self.group.getBest().fit) avgDist.append(self.group.getAvg()) #绘制进化曲线 plt.plot(Gen,dist,'-r') plt.plot(Gen,avgDist,'-b') plt.show() ga=GA() ga.run(3000) print("进行3000代后最优解:",1/ga.group.getBest().fit)
1.3实验结果
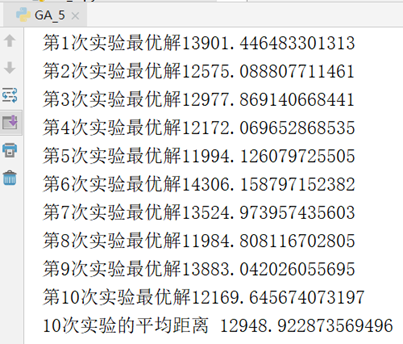
下图是进行一次实验的结果截图,求出的最优解是11271

为避免实验的偶然性,进行10次重复实验,并求平均值,结果如下。
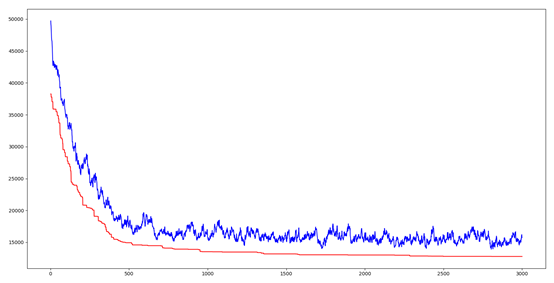
上图横坐标是代数,纵坐标是距离,红色曲线是每一代的最优个体的距离,蓝色曲线是每一代的平均距离。可以看出两条线都呈下降趋势,也就是说都在进化。平均距离下降说明由于优良基因的出现(也就是某一段城市序列),使得这种优良的性状很快传播到整个群体。就像自然界中的优胜劣汰一样,具有适应环境的基因才能生存下来,相应的,生存下来的都是具有优良基因的。算法中引入交叉率和变异率的意义就在于既要保证当前优良基因,又要试图产生更优良的基因。如果所有个体都交叉,那么有些优良的基因片段可能会丢失;如果都不交叉,那么两个优秀的基因片段无法组合为更优秀的基因;如果没有变异,那就无法产生更适应环境的个体。不得不感叹自然的智慧是如此强大。
上面说到的基因片段就是TSP中的一小段城市序列,当某一段序列的距离和相对较小时,就说明这段序列是这几个城市的相对较好的遍历顺序。遗传算法通过将这些优秀的片段组合起来实现了TSP解的不断优化。而组合的方法正是借鉴自然的智慧,遗传、变异、适者生存。
1.4实验总结
1、如何在算法中实现"优胜劣汰"?
所谓优胜劣汰也就是优良的基因保留,不适应环境的基因淘汰。在上述GA算法中,我使用的是轮盘赌,也就是在遗传的步骤中(无论是否交叉),根据每个个体的适应度来挑选。这样就能达到适应度高得个体有更多的后代,也就达到了优胜劣汰的目的。
在具体的实现过程中,我犯了个错误,起初在遗传步骤筛选个体时,我每选出一个个体就将这个个体从群体中删除。现在想想,这种做法十分愚蠢,尽管当时我已经实现了轮盘赌,但如果选出个体就删除,那么就会导致每个个体都会平等地生育后代,所谓的轮盘赌也不过是能让适应度高的先进行遗传。这种做法完全背离了"优胜劣汰"的初衷。正确的做法是选完个体进行遗传后再重新放回群体,这样才能保证适应度高的个体会进行多次遗传,产生更多后代,将优良的基因更广泛的播撒,同时不适应的个体会产生少量后代或者直接被淘汰。
2 、如何保证进化一直是在正向进行?
所谓正向进行也就是下一代的最优个体一定比上一代更适应或者同等适应环境。我采用的方法是最优个体直接进入下一代,不参与交叉变异等操作。这样能够防止因这些操作而"污染"了当前最优秀的基因而导致反向进化的出现。
我在实现过程中还出现了另一点问题,是传引用还是传值所导致的。对个体的基因进行交叉和变异时用的是一个列表,Python中传列表时传的实际上是一个引用,这样就导致个体进行交叉和变异后会改变个体本身的基因。导致的结果就是进化非常缓慢,并且伴随反向进化。
3、交叉如何实现?
选定一个个体的片段放入另一个体,并将不重复的基因的依次放入其他位置。
在实现这一步时,因为学生物时对真实染色体行为的固有认识,"同源染色体交叉互换同源区段",导致我错误实现该功能。我只将两个个体的相同位置的片段互换来完成交叉,显然这样的做法是错误的,这会导致城市的重复出现。
4、在刚开始写这个算法时,我是半OOP,半面向过程地写。后续测试过程中发现要改参数,更新个体信息时很麻烦,于是全部改为OOP,然后方便多了。对于这种模拟真实世界的问题,OOP有很大的灵活性和简便性。
5、如何防止出现局部最优解?
在测试过程中发现偶尔会出现局部最优解,在很长时间内不会继续进化,而此时的解又离最优解较远。哪怕是后续调整后,尽管离最优解近了,但依然是"局部最优",因为还没有达到最优。
算法在起初会收敛得很快,而越往后就会越来越慢,甚至根本不动。因为到后期,所有个体都有着相对来说差不多的优秀基因,这时的交叉对于进化的作用就很弱了,进化的主要动力就成了变异,而变异就是一种暴力算法了。运气好的话能很快变异出更好的个体,运气不好就得一直等。
防止局部最优解的解决方法是增大种群规模,这样就会有更多的个体变异,就会有更大可能性产生进化的个体。而增大种群规模的弊端是每一代的计算时间会变长,也就是说这两者是相互抑制的。巨大的种群规模虽然最终能避免局部最优解,但是每一代的时间很长,需要很长时间才能求出最优解;而较小的种群规模虽然每一代计算时间快,但在若干代后就会陷入局部最优。
猜想一种可能的优化方法,在进化初期用较小的种群规模,以此来加快进化速度,当适应度达到某一阈值后,增加种群规模和变异率来避免局部最优解的出现。用这种动态调整的方法来权衡每一代计算效率和整体计算效率之间的平衡。
2 粒子群寻优
2.1算法介绍
粒子群算法(particle swarm optimization,PSO)的思想源于对鸟/鱼群捕食行为的研究,模拟鸟集群飞行觅食的行为,鸟之间通过集体的协作使群体达到最优目的。
粒子群寻优算法作以下假设:
每个寻优的问题解都被想像成一只鸟,称为"粒子"。所有粒子都在一个D维空间进行搜索。
所有的粒子都由一个fitness function 确定适应值以判断目前的位置好坏。
每一个粒子必须赋予记忆功能,能记住所搜寻到的最佳位置。
每一个粒子还有一个速度以决定飞行的距离和方向。这个速度根据它本身的飞行经验以及同伴的飞行经验进行动态调整。
传统的粒子群寻优算法的位置更新公式如下
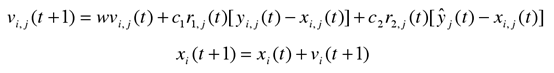
每一只鸟会根据自身速度惯性、自身最佳位置和群体最佳位置来决定下一时刻的速度(包括大小和方向),并根据速度来更新位置。
当应用PSO来解决TSP问题时需要进行一些改进,将多维的城市列表信息转换为一种坐标信息,并在此基础上定义相应的速度、加速度等。这些研究在卞锋的《粒子群优化算法在TSP中的研究及应用》和《求解TSP的改进QPSO算法》两篇文章中有详细介绍。其中最重要的一个概念是交换序,相当于传统PSO中的速度。在进行了这些改进之后就可以将PSO算法应用于TSP问题中了。
2.2实验代码
import random import math import matplotlib.pyplot as plt #读取数据 f=open("test.txt") data=f.readlines() #将cities初始化为字典,防止下面被当成列表 cities={} for line in data: #原始数据以\n换行,将其替换掉 line=line.replace("\n","") #最后一行以EOF为标志,如果读到就证明读完了,退出循环 if(line=="EOF"): break #空格分割城市编号和城市的坐标 city=line.split(" ") map(int,city) #将城市数据添加到cities中 cities[eval(city[0])]=[eval(city[1]),eval(city[2])] #计算适应度,也就是距离分之一,这里用伪欧氏距离 def calcfit(addr): sum=0 for i in range(-1,len(addr)-1): nowcity=addr[i] nextcity=addr[i+1] nowloc=cities[nowcity] nextloc=cities[nextcity] sum+=math.sqrt(((nowloc[0]-nextloc[0])**2+(nowloc[1]-nextloc[1])**2)/10) #最后要回到初始城市 return 1/sum #生成交换序的函数,交换后数组b变为a,也就是a-b的结果 def switchB2A(a,b): #防止传进来的b被更改 tmpb=b[:] q=[] for i in range(len(a)): if(a[i]!=tmpb[i]): j=b.index(a[i]) q.append([i,j]) #刚学的简洁的交换list的方法 tmpb[j],tmpb[i]=tmpb[i],tmpb[j] return q #w*v,w是一个数,v是一个数组。w乘v的数组长度,然后对结果取整,取数组的前这么多个元素 def multiply(w,v): l=int(w*len(v)) res=v[0:l] return res #鸟个体的类,实现鸟位置的移动 class Bird: def __init__(self,addr): self.addr=addr self.v=0 #初始化时自己曾遇到得最优位置就是初始化的位置 self.bestAddr=addr #初始状态没有速度 self.v=[] self.fit=calcfit(self.addr) self.bestFit=self.fit #根据交换序移动位置 def switch(self,switchq): for pair in switchq: i,j=pair[0],pair[1] self.addr[i],self.addr[j]=self.addr[j],self.addr[i] #交换后自动更行自己的成员变量 self.upDate() #更新鸟自身相关信息 def upDate(self): newfit=calcfit(self.addr) self.fit=newfit if(newfit>self.bestFit): self.bestFit=newfit self.bestAddr=self.addr #变异操作 #设置变异后避免了所有鸟都聚集到一个离食物近,但又不是最近的地方,并且就停在那里不动了 def change(self): i,j=random.randrange(0,48),random.randrange(0,48) self.addr[i],self.addr[j]=self.addr[j],self.addr[i] self.upDate() #贪婪倒立变异 def reverse(self): #随机选择一个城市 cityx=random.randrange(1,49) noxcity=self.addr[:] noxcity.remove(cityx) maxFit=0 nearCity=noxcity[0] for c in noxcity: fit=calcfit([c,cityx]) if(fit>maxFit): maxFit=fit nearCity=c index1=self.addr.index(cityx) index2=self.addr.index(nearCity) tmp=self.addr[index1+1:index2+1] tmp.reverse() self.addr[index1+1:index2+1]=tmp self.upDate() #种群的类,里面有很多鸟 class Group: def __init__(self): self.groupSize=500 #鸟的个数、粒子个数 self.addrSize=48 #位置的维度,也就是TSP城市数量 self.w=0.25 #w为惯性系数,也就是保留上次速度的程度 self.pChange=0.1 #变异系数pChange self.pReverse=0.1 #贪婪倒立变异概率 self.initBirds() self.best=self.getBest() self.Gen=0 #初始化鸟群 def initBirds(self): self.group=[] for i in range(self.groupSize): addr=[i+1 for i in range(self.addrSize)] random.shuffle(addr) bird=Bird(addr) self.group.append(bird) #获取当前离食物最近的鸟 def getBest(self): bestFit=0 bestBird=None #遍历群体里的所有鸟,找到路径最短的 for bird in self.group: nowfit=calcfit(bird.addr) if(nowfit>bestFit): bestFit=nowfit bestBird=bird return bestBird #返回所有鸟的距离平均值 def getAvg(self): sum=0 for p in self.group: sum+=1/p.fit return sum/len(self.group) #打印最优位置的鸟的相关信息 def showBest(self): print(self.Gen,":",1/self.best.fit) #更新每一只鸟的速度和位置 def upDateBird(self): self.Gen+=1 for bird in self.group: #g代表group,m代表me,分别代表自己和群组最优、自己最优的差 deltag=switchB2A(self.best.addr,bird.addr) deltam=switchB2A(bird.bestAddr,bird.addr) newv=multiply(self.w,bird.v)[:]+multiply(random.random(),deltag)[:]+multiply(random.random(),deltam) bird.switch(newv) bird.v=newv if(random.random()<self.pChange): bird.change() if(random.random()<self.pReverse): bird.reverse() #顺便在循环里把最优的鸟更新了,防止二次遍历 if(bird.fit>self.best.fit): self.best=bird Gen=[] #代数 dist=[] #距离 avgDist=[] #平均距离 #上面三个列表是为了画图 group=Group() i=0 #进行若干次迭代 while(i<500): i+=1 group.upDateBird() group.showBest() Gen.append(i) dist.append(1/group.getBest().fit) avgDist.append(group.getAvg()) #将过程可视化 plt.plot(Gen,dist,'-r') plt.plot(Gen,avgDist,'-b') plt.show()
2.3实验结果
下面是进行500次迭代后的结果,求出的最优解是11198
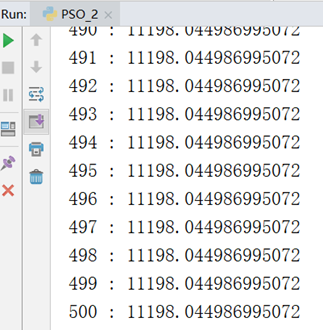
为避免计算过程的偶然性,下面进行10次重复实验并求平均值。
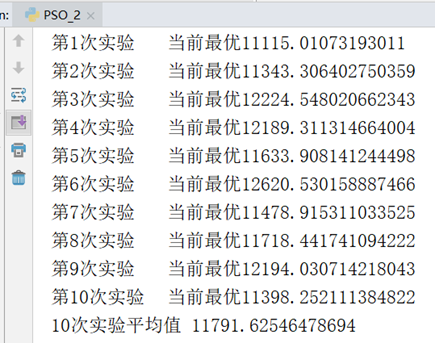

上图横坐标是迭代次数,纵坐标是距离,红色曲线是每次迭代最接近食物的鸟(也就是本次迭代的最优解,食物的位置也就是最优解城市序列所构成的坐标),蓝色曲线是每次迭代所有鸟的平均距离。可以看出不同于遗传算法,最初的最优解具有波动性,并不是一直下降的(遗传算法之所以一直下降是因为每次都保留的最优个体直接传到下一代)出现这种情况的原因是,最开始阶段所有鸟都是随机分散的,大家离食物的距离都差不多,就算是距离食物最近的鸟其能提供的信息的参考价值也不大。所以在开始的一段时间内最优位置的鸟在波动,而到后期,当食物位置更加确定之后,其波动性就消失了。
从趋势来看,无论是每次迭代的最优距离还是大家的平均距离,整体都是呈现下降趋势的,也就是说整个群体都是在朝着食物的位置移动。
2.4实验总结
1、在阅读完卞锋的两篇文章,并用他的方法将PSO应用于解决TSP问题后,让我认识到原来一种算法并不是拘泥于解决特定的一类问题,将算法与实际情况相结合,然后进行抽象和类比就能应用于新的问题的解决。这种抽象和类比的思维非常让我惊讶,我要好好学习。
2、引入遗传算法的变异操作
起初完成PSO时,测试发现很容易陷入离最优解较远的局部最优。在参考卞锋的《求解TSP的改进QPSO算法》后引入相关变异操作,从而解决了这个问题。
他提出的贪婪倒立变异很有意思。贪婪倒立变异是指找到一个城市,再找到离他最近的城市,然后将城市序列中两个城市之间的序列进行倒序排列。这样能够在实现优化了所选两个城市的距离的同时,保证其他城市顺序尽量不变化。
不知道作者是怎么想到这种变异方法的。我在看完文章后首先想到的是染色体变异中的倒位,也就是染色体中的一段旋转180度放回原来位置。染色体的倒位变异和作者提到的贪婪倒立变异非常相似。可能作者也是借鉴自然界的染色体变异吧,再次感叹自然界的智慧无穷。
传统的PSO没有变异操作,这种引入变异的操作是借鉴遗传算法的。可见吸收借鉴其他算法的精华,能够提升自身算法的效率。
3 蚁群算法
3.1算法介绍
蚁群算法(Ant Colony Optimization, ACO),是一种用来在图中寻找优化路径的机率型算法,对蚂蚁行为进行模仿抽象。在求解旅行推销员问题时,蚂蚁随机从某一城市出发,根据城市间距离与残留信息素浓度按概率选择下一城市,蚂蚁走完所有的城市后,在走过的路径上留下信息素,蚂蚁走的总路程越少,留下的信息素就越多。多次循环后,最好的路径就有可能被筛选出。
其核心原理在于单位时间内通过短距离的路径的次数要多,也就会留下更浓信息素,而蚂蚁会选择信息素浓的路径,这样根据信息素的浓度就能找到最短路径,非常适合解决TSP问题。
3.2实验代码
import math import random import matplotlib.pyplot as plt #读取数据 f=open("test.txt") data=f.readlines() #将cities初始化为字典,防止下面被当成列表 cities={} for line in data: #原始数据以\n换行,将其替换掉 line=line.replace("\n","") #最后一行以EOF为标志,如果读到就证明读完了,退出循环 if(line=="EOF"): break #空格分割城市编号和城市的坐标 city=line.split(" ") map(int,city) #将城市数据添加到cities中 cities[eval(city[0])]=[eval(city[1]),eval(city[2])] #计算适应度,也就是距离分之一,这里用伪欧氏距离 #用于决定释放多少信息素 def calcfit(addr): sum=0 for i in range(-1,len(addr)-1): nowcity=addr[i] nextcity=addr[i+1] nowloc=cities[nowcity] nextloc=cities[nextcity] sum+=math.sqrt(((nowloc[0]-nextloc[0])**2+(nowloc[1]-nextloc[1])**2)/10) #最后要回到初始城市 return 1/sum #计算两个城市的距离,用于启发信息计算 def calc2c(c1,c2): #cities是一个字典,key是城市编号,value是一个两个元素的list,分别是x y的坐标 return math.sqrt((cities[c1][0]-cities[c2][0])**2+(cities[c1][1]-cities[c2][1])**2) #方便从1开始,所以0-48共49个数字 #全部初始化为1,否则后面的概率可能因为乘以0而全为0 #信息素浓度表 matrix=[[1 for i in range(49)] for i in range(49)] #蚂蚁的类,实现了根据信息素和启发信息完成一次遍历 class Ant: def __init__(self): #tabu是已经走过的城市 #规定从第一个城市开始走 self.tabu=[1] self.allowed=[i for i in range(2,49)] self.nowCity=1 #a,b分别表示信息素和期望启发因子的相对重要程度 self.a=2 self.b=7 #rho表示路径上信息素的挥发系数,1-rho表示信息素的持久性系数。 self.rho=0.1 #本条路线的适应度,距离分之一 self.fit=0 #计算下一个城市去哪 def next(self): sum=0 #用一个数组储存下一个城市的概率 p=[0 for i in range(49)] #计算分母和分子 for c in self.allowed: tmp=math.pow(matrix[self.nowCity][c],self.a)*math.pow(1/calc2c(self.nowCity,c),self.b) sum+=tmp #此处p是分子 p[c]=tmp #更新p为概率 for c in self.allowed: p[c]=p[c]/sum #更新p为区间 for i in range(1,49): p[i]+=p[i-1] r=random.random() for i in range(48): if(r<p[i+1] and r>p[i]): #i+1即为下一个要去的城市 self.tabu.append(i+1) self.allowed.remove(i+1) self.nowCity=i+1 return #将所有城市遍历 def tour(self): while(self.allowed): self.next() self.fit=calcfit(self.tabu) #更新信息素矩阵 def updateMatrix(self): #line储存本次经历过的城市 line=[] for i in range(47): #因为矩阵是对阵的,2-1和1-2应该有相同的值,所以两个方向都要加 line.append([self.tabu[i],self.tabu[i+1]]) line.append([self.tabu[i+1],self.tabu[i]]) for i in range(1,49): for j in range(1,49): if([i,j] in line): matrix[i][j]=(1-self.rho)*matrix[i][j]+self.fit else: matrix[i][j]=(1-self.rho)*matrix[i][j] #一只蚂蚁复用,每次恢复初始状态 def clear(self): self.tabu=[1] self.allowed=[i for i in range(2,49)] self.nowCity=1 self.fit=0 #蚁群算法的类,实现了算法运行过程 class ACO: def __init__(self): #初始先随机N只蚂蚁 self.initN=200 self.bestTour=[i for i in range(1,49)] self.bestFit=calcfit(self.bestTour) self.initAnt() def initAnt(self): i=0 tmpAnt=Ant() print(self.initN,"只先锋蚂蚁正在探路") while(i<self.initN): i+=1 tmpTour=[i for i in range(1,49)] random.shuffle(tmpTour) tmpAnt.tabu=tmpTour tmpAnt.allowed=[] tmpAnt.updateMatrix() tmpFit=calcfit(tmpAnt.tabu) if(tmpFit>self.bestFit): self.bestFit=tmpFit self.bestTour=tmpAnt.tabu tmpAnt.clear() #n为蚂蚁数量 def startAnt(self,n): i=0 ant=Ant() Gen=[] #迭代次数 dist=[] #距离,这两个列表是为了画图 while(i<n): i+=1 ant.tour() if(ant.fit>self.bestFit): self.bestFit=ant.fit self.bestTour=ant.tabu print(i,":",1/self.bestFit) ant.clear() Gen.append(i) dist.append(1/self.bestFit) #绘制求解过程曲线 plt.plot(Gen,dist,'-r') plt.show() #达到阈值后更改策略,对信息素的倾向更大 # if(1/self.bestFit<36000): # # ant.a=5 # ant.b=2 # break # while(i<n): # i+=1 # ant.tour() # if(ant.fit>self.bestFit): # self.bestFit=ant.fit # self.bestTour=ant.tabu # print(i,":",1/self.bestFit) # ant.clear() a=ACO() a.startAnt(1000)
3.3实验结果
下面是放置1000只蚂蚁的结果,计算出最优解是10967.
为防止实验的偶然性,下面进行10次重复实验并求平均值

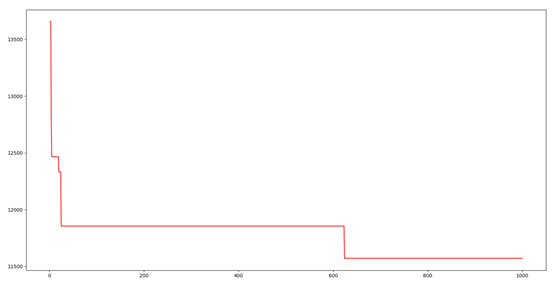
上图横坐标是放出的蚂蚁数,纵坐标是信息素浓度最大的路径的距离。可以看出其收敛得非常快。
3.4实验总结
1、群算法的不难看出其非常适合求解最短距离问题,因此在三个算法中,ACO无论是算法的稳定性,还是最优解的距离长度都是最好的。不仅如此,它的运行速度也是另外两者无法匹敌的。还有,GA和PSO都要维持一个群体,而ACO只需要一只蚂蚁就能完成任务,占用内存更小。可见,ACO在算法的时间复杂度,空间复杂度,解的质量等各个方面都完胜另外两个算法。
2、初始状态时每条路的信息素浓度相等,所以蚂蚁的选择会有随机性。随机的选择也需要在每个路口进行判断,而这种判断是无意义,因为并不能选出信息素浓度高的。所以,我在初始时将若干只蚂蚁指定随机的几条路,这样能防止无意义的判断,并在算法正式开始时各条路上已经存在具有指示性的信息素。
3、蚂蚁选择路线并不是只依靠信息素,还有一个启发信息。启发信息也就是距离下一个城市的距离,蚂蚁会趋向于选择更近的城市。

我在进行信息素和期望启发因子的重要程度参数调优时发现期望启发因子的重要程度会影响解的收敛速度。当启发信息的权重越大,收敛得就会越快,而当启发信息权重很小时,就会收敛得很慢。通过观察公式,不难发现,启发信息权重越大,算法就越趋向于贪婪算法,也就是说一部分城市序列得最优解可以用贪婪算法求。这可以给遗传算法和粒子群寻优的初始群体的确定一定的启发。也就是说贪婪算法求出的位置比随机分布更接近解,从而节省从随机位置到趋近解这一过程所消耗的时间。
同时,对于蚁群算法的优化,我提出一种猜想。初始阶段较大的启发信息权重有助于解的快速收敛,而到后面时则会影响找到最优解。所以可以在初始阶段设置较大的启发信息权重,让解快速收敛,到了后面再降低其权重,让算法变为以信息素为主要导向的,以此来加快逼近最优解的速度。也就是说在两个阶段动态调整信息素和期望启发因子的重要程度。
4、一只蚂蚁是如何实现众多蚂蚁的行为的?
真实世界的蚂蚁是在同一时间有蚁群蚂蚁经过几条路线,因为单位时间内通过的蚂蚁数量不同,而造成每条路的信息素浓度不同。而在算法实现时并没有模拟很多蚂蚁。
算法所模拟的是一只蚂蚁,在走完全程时,对其经过的所有城市之间施加相同的信息素值,这个值是该次行程的距离分之一。每次进行的只是一只蚂蚁。
仔细想想我们就会发现其实两者所达到的效果是一样的。尽管一个是同时有很多蚂蚁在行走,另一个是同一时间只有一只蚂蚁在行走。但是他们施加信息素的方式也不同,一个是经过蚂蚁的多少决定,另一个是该条路的距离决定。这两方面的不同所导致的结果是一样的,并且模拟一只蚂蚁更加简便,容易实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号