
Sharding-JDBC 读写分离和绑定表的使用
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
读写分离的数据节点中的数据内容是一致的,而水平分片的每个数据节点的数据内容却并不相同。将水平分片和读写分离联合使用,能够更加有效的提升系统的性能。
Sharding-JDBC读写分离则是根据SQL语义的分析,将读操作和写操作分别路由至主库与从库。它提供透明化读写分离,让使用方尽量像使用一个数据库一样使用主从数据库集群。Sharding-JDBC不提供主从数据库的数据同步功能,需要采用其他机制支持(如果使用MySQL,可以用MySQL本身提供的主从同步机制)。
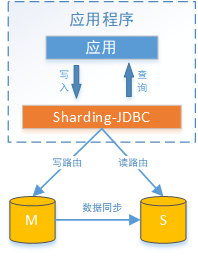
实现sharding-jdbc读写分离:
修改分片规则:
# sharding-jdbc分片规则配置 # 数据源,新增s0,s0对应的是从库 spring.shardingsphere.datasource.names = m0,m1,m2,s0 # s0数据源 spring.shardingsphere.datasource.s0.type = com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.s0.driver-class-name = com.mysql.jdbc.Driver spring.shardingsphere.datasource.s0.url = jdbc:mysql://localhost:3307/user_db?useUnicode=true spring.shardingsphere.datasource.s0.username = root spring.shardingsphere.datasource.s0.password = root
...... # 主库从库逻辑数据源定义 ds0为user_db spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name = m0 spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names = s0 # 从库有多个用逗号分隔 s0,s1,s2 #spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names = s0,s1,s2 ...... # t_user分表策略,固定分配至m0的t_user真实表 #spring.shardingsphere.sharding.tables.t_user.actual-data-nodes = m0.t_user # t_user分表策略,固定分配至ds0的t_user真实表 spring.shardingsphere.sharding.tables.t_user.actual-data-nodes = ds0.t_user
如果在水平分库基础上再进行读写分离,配置水平分库策略需要注意:
# sharding-jdbc分片规则配置 # 数据源 spring.shardingsphere.datasource.names = m0,m00,m1,m2,s0,s00
# m0数据源 spring.shardingsphere.datasource.m0.type = com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.m0.driver-class-name = com.mysql.jdbc.Driver spring.shardingsphere.datasource.m0.url = jdbc:mysql://localhost:3306/user_db_1?useUnicode=true spring.shardingsphere.datasource.m0.username = root spring.shardingsphere.datasource.m0.password = root
# s0数据源 spring.shardingsphere.datasource.s0.type = com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.s0.driver-class-name = com.mysql.jdbc.Driver spring.shardingsphere.datasource.s0.url = jdbc:mysql://localhost:3307/user_db_1?useUnicode=true spring.shardingsphere.datasource.s0.username = root spring.shardingsphere.datasource.s0.password = root
# m00数据源 spring.shardingsphere.datasource.m00.type = com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.m00.driver-class-name = com.mysql.jdbc.Driver spring.shardingsphere.datasource.m00.url = jdbc:mysql://localhost:3306/user_db_2?useUnicode=true spring.shardingsphere.datasource.m00.username = root spring.shardingsphere.datasource.m00.password = root
# s00数据源 spring.shardingsphere.datasource.s00.type = com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.s00.driver-class-name = com.mysql.jdbc.Driver spring.shardingsphere.datasource.s00.url = jdbc:mysql://localhost:3307/user_db_2?useUnicode=true spring.shardingsphere.datasource.s00.username = root spring.shardingsphere.datasource.s00.password = root ...... # 主库从库逻辑数据源定义 ds0为user_db_1 spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name = m0 spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names = s0
# ds1为user_db_2
spring.shardingsphere.sharding.master-slave-rules.ds1.master-data-source-name = m00 spring.shardingsphere.sharding.master-slave-rules.ds1.slave-data-source-names = s00 ...... # 分库策略 spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column = user_id spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression = ds$->{user_id % 2 + 1}
......
# 指定user_db表的主键生成策略
spring.shardingsphere.sharding.tables.user_db.key-generator.column = user_id
spring.shardingsphere.sharding.tables.user_db.key-generator.type = SNOWFLAKE
....... # 分表策略
spring.shardingsphere.sharding.tables.user_db.actual-data-nodes = ds$->{1..2}.user_db_$->{1..2}
spring.shardingsphere.sharding.tables.user_db.table-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.user_db.table-strategy.inline.algorithm-expression = t_order_$->{user_db % 2 + 1}
绑定表:
指分片规则一致的主表和子表。例如: t_order 表和 t_order_item 表,均按照 order_id 分片,绑定表之间的分区键完全相同,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10,11);
在不配置绑定表关系时,假设分片键 order_id 将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in(10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in(10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in(10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in(10, 11);
在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in(10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in(10, 11);
配置方式:
# 设置绑定表
spring.shardingsphere.sharding.binding-tables[0] = t_order,t_order_item

 浙公网安备 33010602011771号
浙公网安备 33010602011771号