HTTP的发展历史
在 1968 年6月3日,罗伯茨向泰勒描述了建立阿帕网的计划,18 天后,也就是 6 月 21 日,泰勒批准了这个计划,14 个月后阿帕网建立。
在 1973 年 ARPA 网扩展成互联网,第一批接入的有英国和挪威计算机,逐渐地成为网络连接的骨干。
1974 年 ARPA 的罗伯特·卡恩和斯坦福的文顿·瑟夫提出TCP/IP 协议。
1986 年,美国国家科学基金会(National Science Foundation,NSF)建立了大学之间互联的骨干网络 NSFNET ,这是互联网历史上重要的一步,NSF网成为新的骨干,1990 年 ARPA网退役。
万维网(World Wide Web)
-
URI,统一资源标识符,作为互联网上的唯一标识。
-
HTML,超文本标记语言,描述超文本。
-
HTTP ,超文本传输协议,传输超文本。
HTTP各大版本的演进
HTTP/0.9
在 1990 年 ,蒂姆·伯纳斯-李创建了运行万维网所需的所有工具,其中包括HTTP。那时候是互联网初期,计算机的处理能力包括网速等等都很弱,所以 HTTP 也逃脱不了那个时代的约束,因此设计的非常简单,而且也是纯文本格式。
因此只有 “GET”,也不需要啥请求头,并且拿完了就结束了,因此请求响应之后连接就断了。这时候的 HTTP 还没有版本号的,之所以称之为 HTTP / 0.9 是后人加上去了,为了区别之后的版本。

HTTP/1.0
随着图像和音频的发展,1995年Apache诞生(HTTP 服务器),浏览器也在不断的进步予以支持,这也促进了 HTTP 协议的修改。为了添加各种特性来满足用户的需求, 于 1996 年正式发布。
增加了以下几点:
-
增加了 HEAD、POST 等新方法。
-
增加了响应状态码。
-
引入了头部,即请求头和响应头。
-
在请求中加入了 HTTP 版本号。
-
引入了 Content-Type ,使得传输的数据不再限于文本。
HTTP/1.1
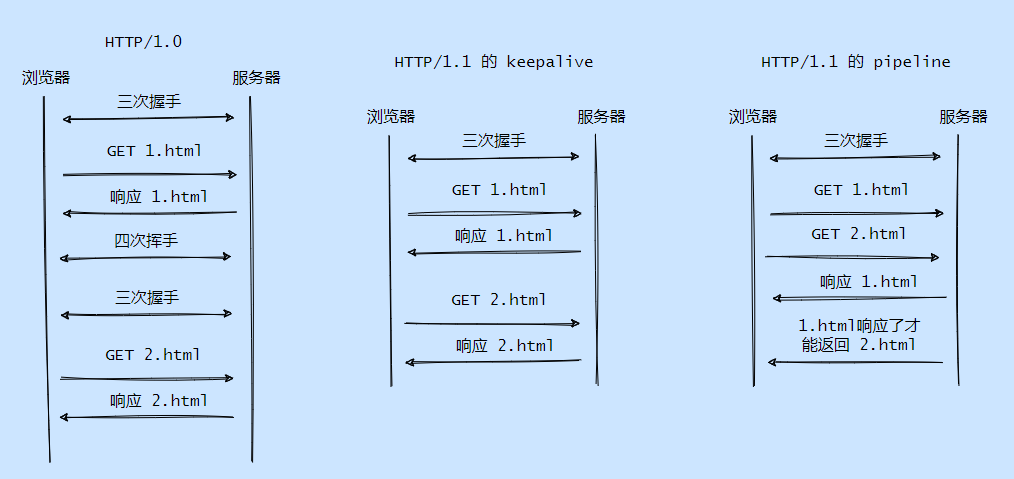
从 1995 年至 1999 年间的第一次浏览器大战,极大的推动了 Web 的发展。主要是因为 HTTP/1.0 很大的性能问题,就是每请求一个资源都得新建一个 TCP 连接,而且只能串行请求。
增加了以下几点:
-
新增持久连接keep-alive,目的是复用TCP连接;
-
支持 pipeline,无需等待前面的请求响应,即可发送第二次请求。
-
允许响应数据分块(chunked),即响应的时候不标明Content-Length,客户端就无法断开连接,直到收到服务端的 EOF ,利于传输大文件。
-
新增缓存的控制和管理。
-
加入了 Host 头,用在你一台机子部署了多个主机,然后多个域名解析又是同一个 IP,此时加入了 Host 头就可以判断你到底是要访问哪个主机。
HTTP/1.1存在的问题
-
头阻塞:HTTP/1.1中只有收到当前请求响应后才能重用当前tcp连接发送下一次请求。虽然HTTP/1.1提出了pipeline,旨在缓解这个问题。但是一方面pipeline在复杂的网络环境下很难实现和普及,其次就算都用上了pipeline,pipeline也只是使得可以在本次响应完成之前可以发送下次请求,但响应依然要严格按照顺序返回,也就是如果前一个响应被阻塞,后边的响应将不会到来,头阻塞问题还是没有完全解决。目前客户端(比如浏览器)一般会同时打开多个tcp连接来绕开头阻塞的问题,chrome默认会打开6个tcp链接,并发请求各种类型数据。但是这就带来了一个矛盾,tcp链接越多,肯定对资源的浪费是越大的,链接越少,头阻塞的问题就会越突出。
-
重复的未压缩头数据的传输:自HTTP/1.1之后,HTTP请求中通常带有大量ASCII编码的头部,这些头部通常大部分不会变化,需要每次请求都携带(尤其像是User Agent、Cookie这些值比较长的头部字段),会给本来就拥挤的网络带来很大的压力。
除此之外还有一些问题,比如TCP 的慢启动,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度,而大量http的业务请求其实本身都只是短链接的,所以导致tcp的流量控制算法没有很好的应用。为此,HTTP/2的出现就很有必要了。
HTTP/2.0
随着 HTTP/1.1 的发布,互联网也开始了爆发式的增长,这种增长暴露出 HTTP 的不足,主要还是性能问题,而 HTTP/1.1 无动于衷。互联网标准化组织以 Google 推出的SPDY 协议为基础开始制定新版本的 HTTP 协议,最终在 2015 年发布了 HTTP/2。
增加了以下几点:
-
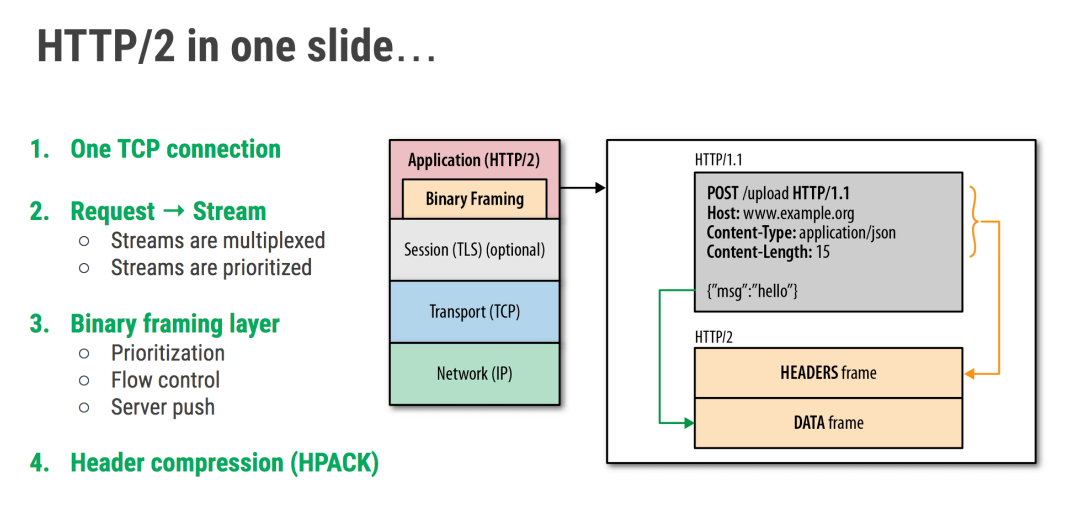
是二进制协议,不再是纯文本。(解析数据开销更小,减少了网络延迟,提升了整体的吞吐量)
-
支持一个 TCP 连接发起多请求,即支持多路复用,移除了 pipeline。(HTTP/1.1 pipeline 还是有阻塞的情况,需要等前面的一个响应返回了后面的才能返回。)
-
利用 HPACK 压缩头部(减少数据传输量。)
-
允许服务端主动推送数据。(其实就是减少了请求的次数)
HTTP/2 引入了一个新的二进制分帧层,该层无法与之前的 HTTP/1.x 服务器和客户端兼容,HTTP/2的新特性都是建立在这个二进制分帧层基础之上的。
HTTP/3.0
这次的痛点来自于 HTTP 依赖的是可靠的、有序的,具有失败重传和按序机制的传输协议 TCP。
依赖TCP存在的问题:
-
HTTP/2 是所有流共享一个 TCP 连接,所以会有 TCP 层面的队头阻塞,当发生重传时会影响多个请求响应;
-
TCP 是基于四元组(源IP,源端口,目标IP,目标端口)来确定连接的,而在移动网络的情况下 IP 地址会频繁的换,这会导致反复的建连;
-
TCP 与 TLS 的叠加握手,增加了延时
因此 Google 把 TCP 可靠、有序、丢包重传和拥塞控制功能提到应用层来实现,就研究出了基于 UDP 的 QUIC 协议。在 2018 年,互联网标准化组织 IETF 提议将 HTTP over QUIC 更名为 HTTP/3 并获得批准。
增加了以下几点:
-
基于UDP,并把 TCP 可靠、有序、丢包重传和拥塞控制功能提到应用层来实现;
-
引入了个叫 Connection ID 来标识一个链接,所以切换网络之后可以复用这个连接,达到 0 RTT 就能开始传输。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号