

结对编程作业
我的github项目地址 博客链接
队友的github项目地址 博客链接
具体分工情况表格
| 任务 | 我 | 队友 |
|---|---|---|
| 原型设计 | √ | |
| 算法 | √ | |
| 界面 | √ | |
| 接口 | √ |
原型设计
设计说明
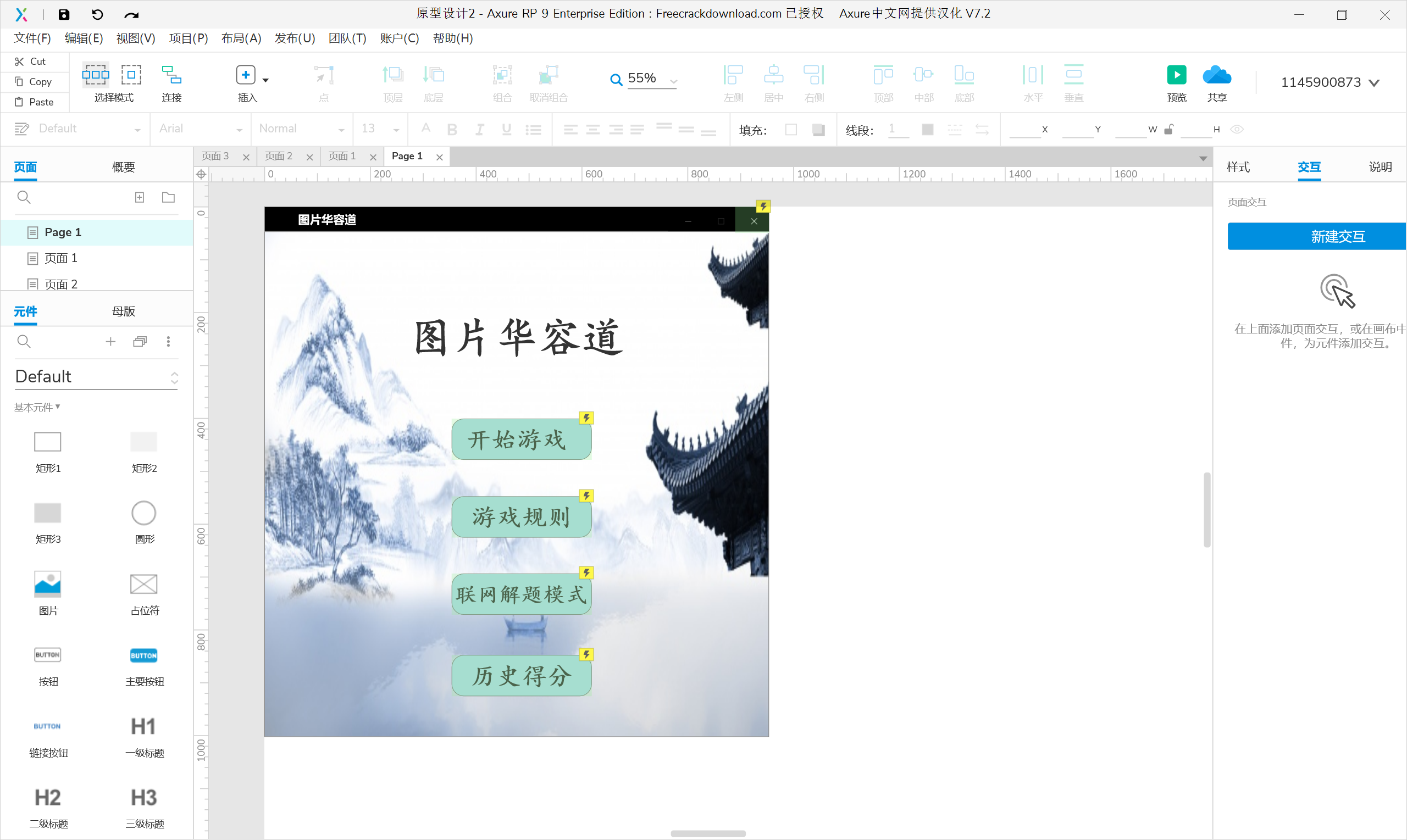
- 这次的结对编程作业界面的设计主要参考传统游戏界面的设计,程序由几个不同的界面组成,在主界面中有几个按钮用于页面的跳转,如下图所示:


- 说明:我们选用带有水墨风的背景作为我们游戏的背景,主要是因为图片华容道的题目带点中国古风的韵味。然后在中上方显示游戏的名字——“图片华容道”。接着自上而下是几个大小相同但是点击后会跳转到不同界面的按钮,分别是“开始游戏”、“游戏规则”、“联网解题模式”、“历史得分”。

- 说明:这个是点击第一个按钮或第三个按钮后进入的游戏界面,我们把不同游戏模式设置为同一个界面,这是因为两种不同游戏只是获取图片的方式不同,第一种是用本地图片进行解题,第二种联网模式是通过接口获取题目。我们这样设计的目的是我们想给用户专注的解题界面,带给用户沉浸式的体验,所以我们把一整个窗口都用于拼图,同时在标题栏给出最简明扼要的操作方法,这样用户仅仅通过键盘就可以对游戏进行操作,具有非常好的操作体验。

- 说明:这是进入游戏规则的界面,在左上角给出返回主界面的按钮,同时在界面中间给出我们设计游戏的不同模式的游戏规则。

- 说明:这是进入历史得分后的界面,与游戏规则的界面类似,左上角给出返回主界面的按钮,同时在界面中间给出按步数从小到大排序的步数。
开发工具
- 此次原型设计我们所用的工具是Axure RP9
结对过程
- 由于我们是一个班的关系还不错,平时经常交流讨论学习问题,我们都认可对方的实力,算是比较有默契的朋友吧,所以一开始我就邀请他一起组队,他二话不说就同意了。铁哥们!
- “非摆拍”图片(两个人在讨论的时候怎么拍图片嘛,要拍的时候只能摆个pos咯)

困难及其解决办法
- 困难描述
1.实话说在此次结对编程之前我根本就不知道还有原型设计这个东西,所以我根本不知道怎么做,无从下手。
2.不会使用Axure Rp9 工具。
- 解决尝试
一开始不知道原型设计的概念,后来通过百度,B站等途径了解了原型设计是产品经理的一门必修课,然后在B站两小时速成Axure Rp的使用,就可以做一个简单的还算可以的原型。学习链接,需要自取
- 是否解决
是
- 有何收获
1.了解了原型设计的重要性,扩展了知识面。
2.学会了宝藏软件Axure Rp的使用,可以独立做一些简单的、工程量小的原型设计。附:可以下载中文汉化包,方便快速入门。
3.打算在接下来的团队编程中也进行原型设计,辅助软件的开发。
AI与原型设计实现
1.代码实现思路
网络接口的使用
- 请求接口
import base64
import json
import requests
def gethtml(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3941.4 Safari/537.36'
}
r=requests.get(url,headers = headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
if __name__ == "__main__":
url = "http://47.102.118.1:8089/api/problem?stuid=031802433"
# 每次请求的结果都不一样,动态变化
text = json.loads(gethtml(url))
img_base64 = text["img"]
step = text["step"]
swap = text["swap"]
uuid = text["uuid"]
img = base64.b64decode(img_base64)
- 提交接口
import json
import requests
def getAnswer(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3941.4 Safari/537.36',
'Content-Type': 'application/json'
}
r=requests.post(url,headers = headers,data = data_json)
return r.text
if __name__ == "__main__":
url = " http://47.102.118.1:8089/api/answer"
data = {
"uuid":"20c8d3e27d6e4d638a1fed4218737e41",#本道题目标识
"answer":{
"operations": "wsaaadasdadadaws",
"swap": [1,2]
}
}
data_json = json.dumps(data)#转为json提交
ret = getAnswer(url)
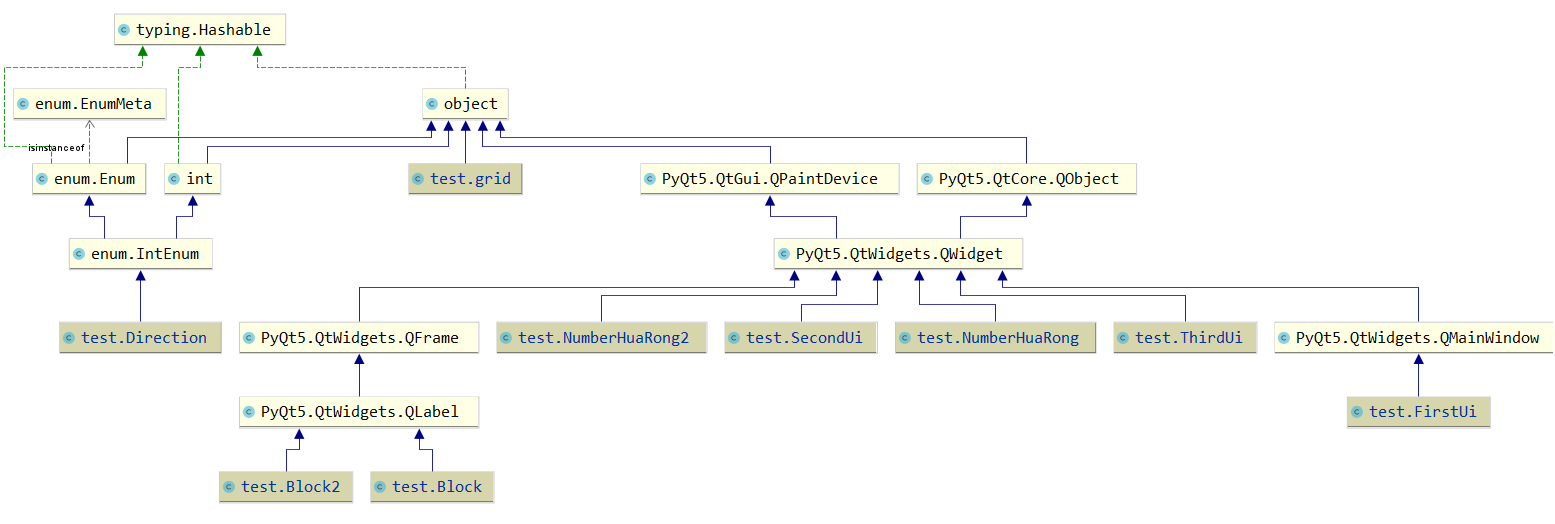
代码组织与内部实现设计(类图)
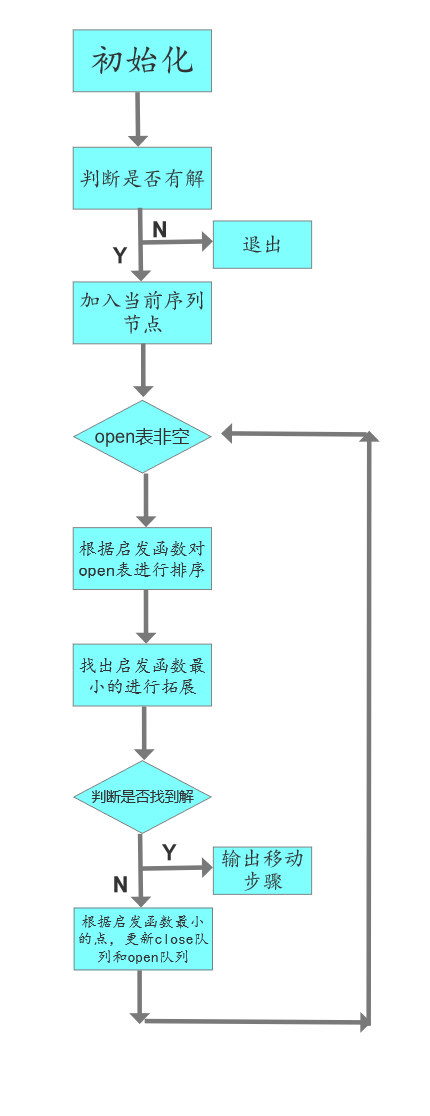
说明算法的关键与关键实现部分流程图
算法的关键有两个
- 一个是Astar算法
Astar算法是一种求解最短路径最有效的直接搜索方法,也是许多其他问题的常用启发式算法。它的启发函数为f(n)=g(n)+h(n),其中,f(n) 是从初始状态经由状态n到目标状态的代价估计,g(n) 是在状态空间中从初始状态到状态n的实际代价,h(n) 是从状态n到目标状态的最佳路径的估计代价。h(n)是启发函数中很重要的一项,它是对当前状态到目标状态的最小代价h(n)的一种估计,且需要满足h(n)<=h(n)也就是说h(n)是h*(n)的下界,这一要求保证了Astar算法能够找到最优解。这一点很容易想清楚,因为满足了这一条件后,启发函数的值总是小于等于最优解的代价值,也就是说寻找过程是在朝着一个可能是最优解的方向或者是比最优解更小的方向移动,如果启发函数值恰好等于实际最优解代价值,那么搜索算法在一直尝试逼近最优解的过程中会找到最优解;如果启发函数值比最优解的代价要低,虽然无法达到,但是因为方向一致,会在搜索过程中发现最优解。
h函数设计的好坏决定了Astar算法的效率。h值越大,算法运行越快。但是在设计评估函数时,需要注意一个很重要的性质:评估函数的值一定要小于等于实际当前状态到目标状态的代价。否则虽然程序运行速度加快,但是可能在搜索过程中漏掉了最优解。相对的,只要评估函数的值小于等于实际当前状态到目标状态的代价,就一定能找到最优解。所以,在这个问题中我们可以将评估函数设定为1-8八数字当前位置到目标位置的曼哈顿距离之和。
Astar算法与BFS算法的不同之处在于每次会根据启发函数的值来进行排序,每次先出队的是启发函数值最小的状态。
Astar算法可以被认为是Dijkstra算法的扩展。Dijkstra算法在搜索最短距离时是已知了各个节点之间的距离,而对于Astar而言,这个已知的距离被启发函数值替换。 - 对应流程图如下
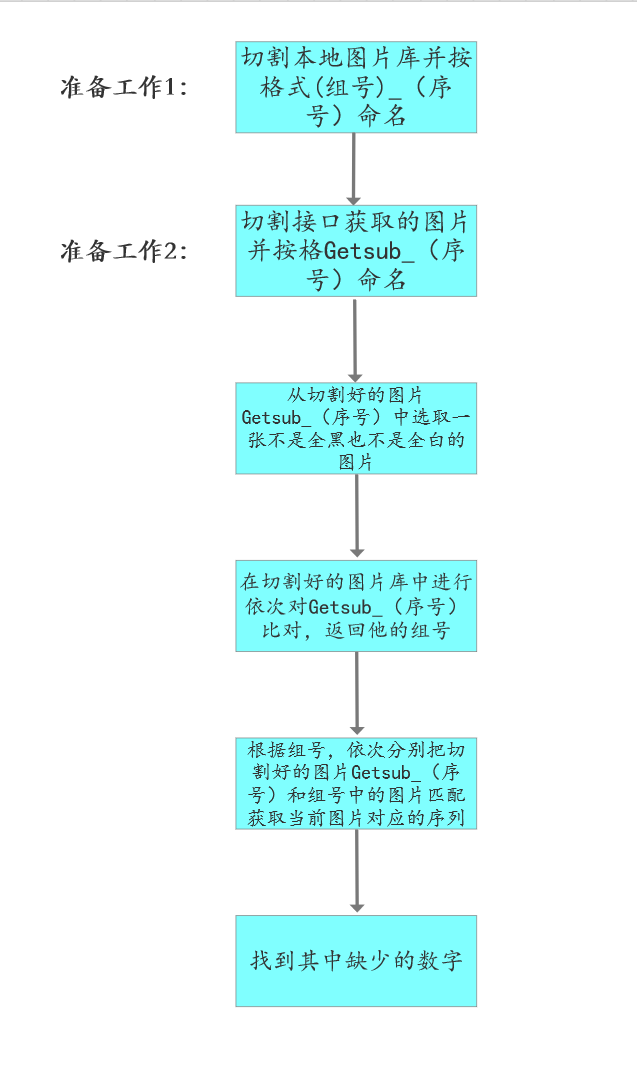
- 另一个是根据接口获取的图片确定对应的数字队列
贴出你认为重要的/有价值的代码片段,并解释
- 在我看来大部分的代码都是有价值的,毕竟都是自己智慧的结晶,这里挑三个我负责的部分且花了比较多时间思考的代码片段
- (1)交换函数
def change(self, x):
global myswap
row1 = int((x[0] - 1) / 3)
col1 = (x[0] - 1) % 3
row2 = int((x[1] - 1) / 3)
col2 = (x[1] - 1) % 3
print('第{0}步 强制交换{1}:'.format(step, swap))
# print('强制交换前', self.blocks)
self.blocks[row1][col1], self.blocks[row2][col2] = self.blocks[row2][col2], self.blocks[row1][col1]
# print('强制交换后', self.blocks)
if judge(self.blocks, self.goal):
return
else:
mini = 10
flag1 = 0
flag2 = 0
for i in range(9):
for j in range(i, 9):
list1 = copy.deepcopy(self.blocks)
row1 = int(i / 3)
col1 = i % 3
row2 = int(j / 3)
col2 = j % 3
list1[row1][col1], list1[row2][col2] = list1[row2][col2], list1[row1][col1]
if judge(list1, self.goal):
thiscost = getcost(list1)
if mini > thiscost:
mini = thiscost
flag1 = i
flag2 = j
row1 = int(flag1 / 3)
col1 = flag1 % 3
row2 = int(flag2 / 3)
col2 = flag2 % 3
# print('用户交换前', self.blocks)
self.blocks[row1][col1], self.blocks[row2][col2] = self.blocks[row2][col2], self.blocks[row1][col1]
print('无解,进行用户交换{0}:'.format([flag1 + 1, flag2 + 1]))
# print('用户交换后', self.blocks)
myswap = [flag1 + 1, flag2 + 1]
return
- 解释:其实这次的华容道是经典的八数码问题,我们在人工智能课上已经了解到利用Astar算法可以轻易的求解问题,网络上利用Astar算法进行解题的代码很多并且质量很高,本人在自己实现Astar后发现解题速度特别慢,在权衡利弊后还是借鉴了互联网上优化过后的Astar算法,当然对这部分的代码已经理解透彻。所以Astar算法看似是这次作业的核心,其实不是。我认为这次作业的关键在与step步后进行交换,这是网上搜索不到的算法,非常考验我们算法设计能力。我交换算法的过程是这样的,首先先进行强制交换,如果有解则返回,如果交换完还是没有解,那么就进入算法的关键部分——用户交换。在此之前先介绍一个getcost()函数,这是我自己编写的获取代价的函数,这里的代价指的是当前序列数字中不在目的位置的个数。我用的方法是穷举法,把所有可能的交换都试过去,选出其中代价最小,且交换完有解的交换,这个交换就是我们需要的用户交换
- (2)确定图片序列函数和识别字母
def compare_images(path_one, path_two):
image_one = Image.open(path_one)
image_two = Image.open(path_two)
try:
diff = ImageChops.difference(image_one, image_two)
if diff.getbbox() is None:
return True
else:
return False
except ValueError as e:
return "{0}\n{1}".format(e, "图片大小和box对应的宽度不一致!")
def getzu(path11):
path = 'D://0作业/软工实践/hrd/确定序列/'
for i in range(36):
path2 = path + str(i) + '_'
for j in range(1, 10):
path22 = path2 + str(j) + '.jpg'
if compare_images(path11, path22):
return i
def getxulie(zuhao):
listnow = []
for i in range(1, 10):
path11 = 'D://0作业/软工实践/hrd/图片华容道1.0/' + "Getsub" + str(i) + ".jpg"
if compare_images(path11, 'white.jpg'):
listnow.append(0)
else:
for j in range(1, 10):
path22 = 'D://0作业/软工实践/hrd/确定序列/' + str(zuhao) + '_' + str(j) + ".jpg"
if compare_images(path11, path22):
listnow.append(j)
disnumber = 0
listnowsum = 0
for i in listnow:
listnowsum += int(i)
disnumber = 45 - listnowsum
listnow2 = [[], [], []]
listnow2[0] = listnow[0:3]
listnow2[1] = listnow[3:6]
listnow2[2] = listnow[6:9]
return listnow2, disnumber
def getlist():
path1 = ''
zimu = 'aabbcddefghhjkmmnooppqqrstuuvwxxyyzz'
for i in range(1, 10):
filename = 'D://0作业/软工实践/hrd/图片华容道1.0/' + "Getsub" + str(i) + ".jpg"
if not compare_images(filename, 'white.jpg'):
if not compare_images(filename, 'black.jpg'):
path1 = filename
break
zuhao = getzu(path1)
alist, disnumber = getxulie(zuhao)
print("该图是第{0}张图片".format(zuhao))
print("对应字母为:", zimu[zuhao])
print("题目序列是")
print(alist[0])
print(alist[1])
print(alist[2])
return zuhao, alist, disnumber
-
解释:具体的流程图已经在上个部分算法核心中给出,这里补充介绍getlist()中的从组号获取他对应字母的一个打表算法,在获取完图片对应的组号后,我们先根据图片库建立一个字符串zimu,该字符串中存放着对应组号的字母,所以在获取zuhao后我们就可以通过zimu[zuhao]来获取图片对应的字母
-
(3)解题函数solve()
def solve(self):
self.goal = []
for row in range(3):
self.goal.append([])
for column in range(3):
temp = self.numbers[row * 3 + column]
self.goal[row].append(temp)
global target
target = self.goal.copy()
stat = self.mylist
global operations
if not judge(stat, target):
print('一开始无解,随机移动到step步再进行解题')
anscopy = ""
for i in range(step):
if self.zero_row == 0:
anscopy += 's'
self.move(Direction.UP)
else:
anscopy += 'w'
self.move(Direction.DOWN)
self.change(swap)
stat = self.mylist
Astar(stat)
anscopy = anscopy + ans
operations = anscopy
else:
Astar(stat)
if len(ans) <= step:
operations = ans
else:
anscopy = ans[0:step]
for i in range(step):
mm = ans[i]
if mm == 'w':
self.move(Direction.DOWN)
elif mm == 's':
self.move(Direction.UP)
elif mm == 'a':
self.move(Direction.RIGHT)
elif mm == 'd':
self.move(Direction.LEFT)
self.change(swap)
stat = self.mylist
Astar(stat)
anscopy = anscopy + ans
operations = anscopy
print('uuid=', uuid)
print('operations=', operations)
print('myswap=', myswap)
requestion.submit(uuid, operations, myswap)
- 解释:solve()函数的主要流程是这样的,分为两种大情况,一开始有解和一开始无解,
- 如果一开始无解的话,先随机移动到强制交换的步数,然后再利用change()函数调换当前序列,使之一定有解,然后调用Astar算法解题即可,这种方法有一定的欠缺,因为在强制交换步数之前的步数由于是随机交换,所以基本上是浪费了,但是有的时候以不变应万变还有奇效,希望接下来能想出更好的算法利用强制交换前的步数。
- 如果一开始有解,那么直接调用Astar算法进行解题,然后取前step个交换操作,然后进行强制交换,我们的change函数会自动判断交换完是否有解,如果无解则会找到最优的用户交换,然后再次根据当前的序列调用Astar算法进行解题即可。
性能分析与改进
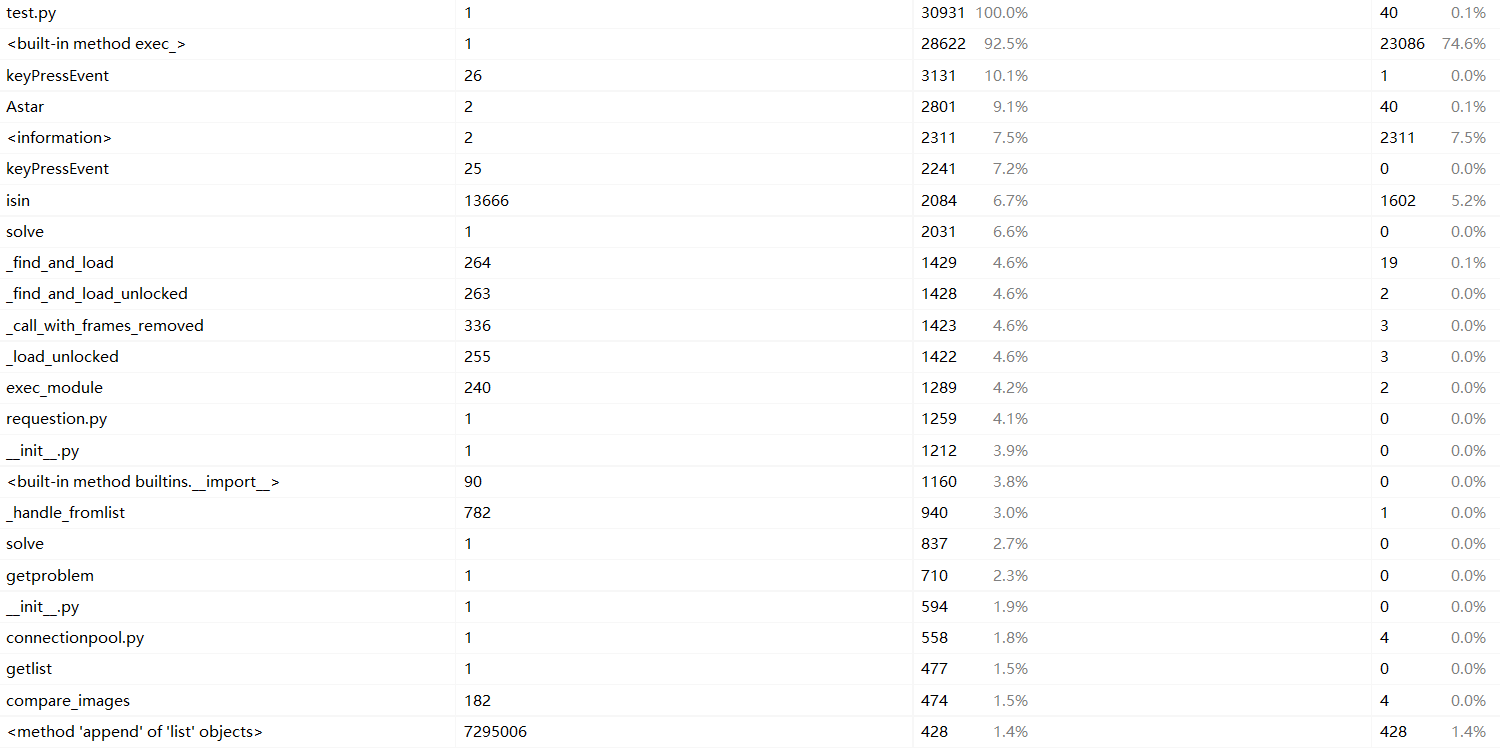
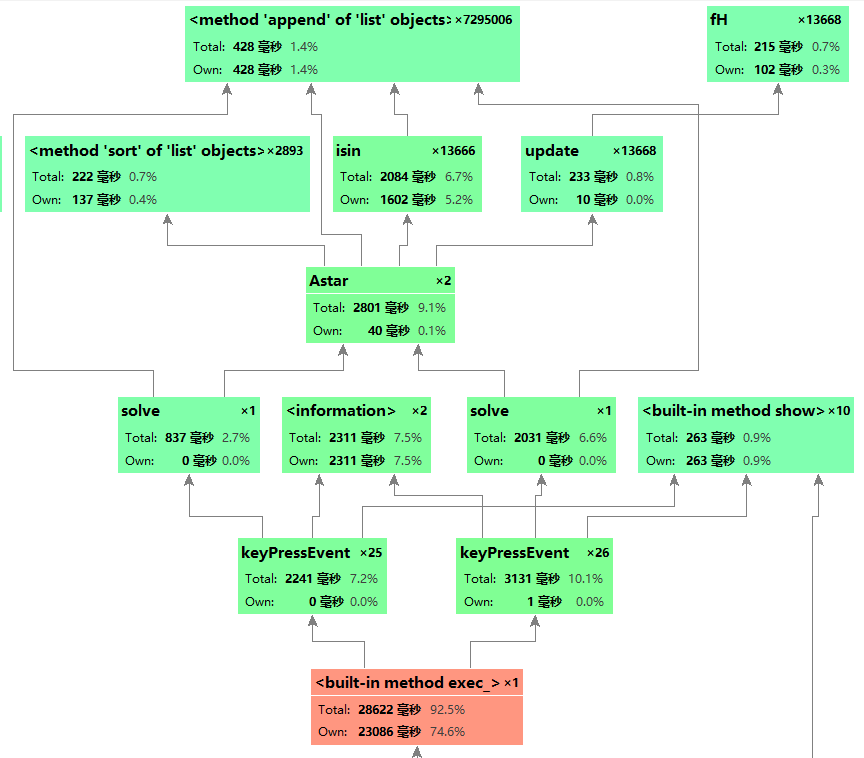
从图可以看出本程序的时间消耗最大是pyqt5内置方法,键盘等待时间,AStart算法,pyqt5内置方法无法优化,键盘等待时间受人为因素影响不确定,所以唯一可以优化的就是AStart算法。
- 描述你改进的思路
通过优化AStart算法来提高程序的性能。
在AStart算法中,其中有一步计算了逆序数的个数。
def N(nums):
count = 0
for i in range(len(nums)):
if nums[i] != 0:
for j in range(i):
if nums[j] > nums[i]:
count += 1
return count
这里的时间复杂度是O(n^2)
我们可以通过利用归并排序的思想来进行优化,优化后的时间复杂度为O(nlogn),算法代码如下:
def merge_count(A,B):
lenA,lenB=len(A),len(B)
i,j,rC=0,0,0
C=[]
while(i<lenA and j<lenB):
if A[i]>B[j]:
C.append(B[j])
j+=1
rC+=lenA-i
else:
C.append(A[i])
i+=1
if i<lenA:
C=C+A[i:]
if j<lenB:
C=C+B[j:]
return (rC,C)
def sort_count(L):
if len(L)==1:
return (0,L)
else:
(rA,A)=sort_count(L[0:len(L)//2])
(rB,B)=sort_count(L[len(L)//2:])
(rC,C)=merge_count(A,B)
return (rA+rB+rC,C)
展示性能分析图和程序中消耗最大的函数
-
性能分析图

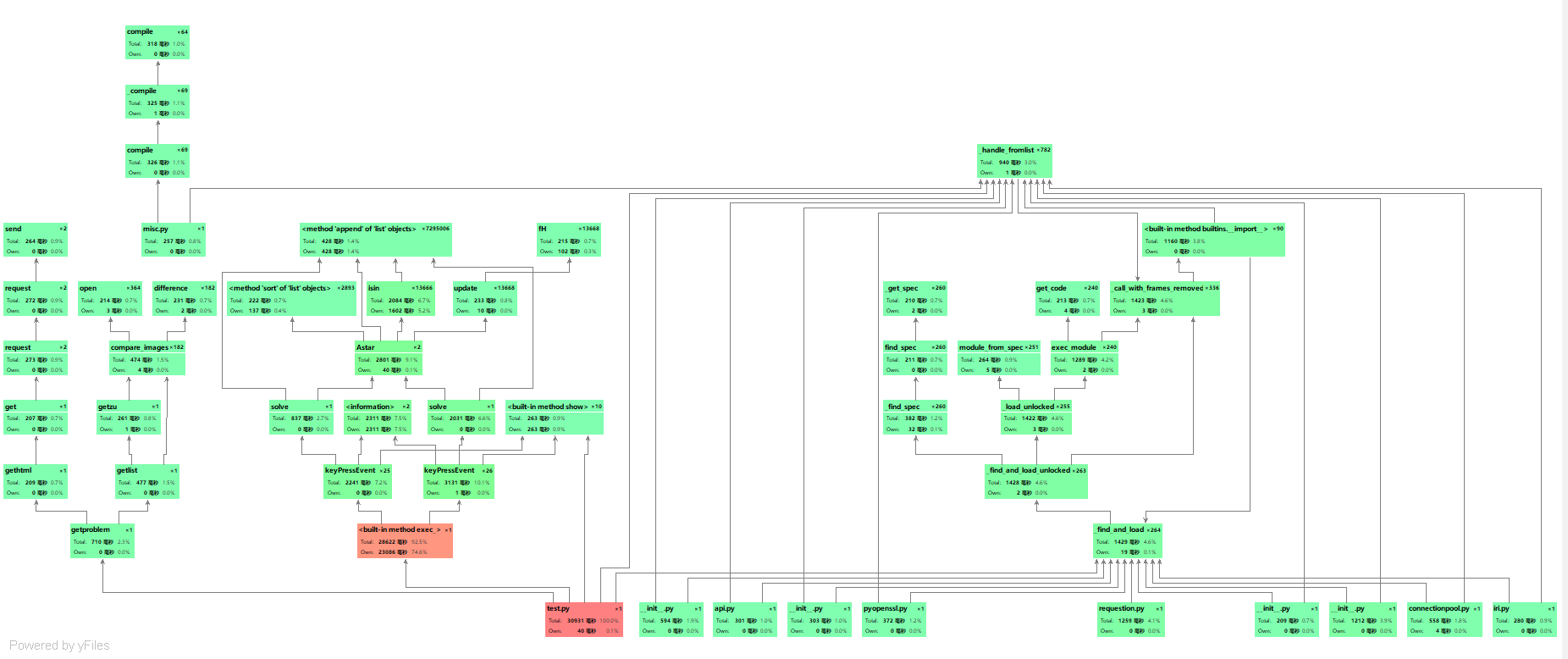
程序中消耗最大的函数:pyqt5内置方法(大约占了程序的74.6%)
-
展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路
单元测试采用AI大比拼的接口,通过返回的"success"值与True比较,如果相同则说明本题求解成功,通过单元测试,反之则未通过。具体实现代码如下:
#coding:utf-8
import unittest
from AI大比拼 import *
class MyTestCase(unittest.TestCase):
def test1(self):
uuid = "7aa3a255-a8a9-4314-91d8-57772d068087"
global answer
answer = False
step, swap, uuid, zuhao, listproblem, dis = jiekou.challenge(uuid)
set(step, swap, uuid, zuhao, listproblem, dis)
NumberHuaRong()
jiekou.submit(uuid, operations, myswap)
self.assertEqual(answer, True)
def test2(self):
uuid = "ec0dd026-3a78-4b18-971f-2b651aaa7b5f"
global answer
answer = False
step, swap, uuid, zuhao, listproblem, dis = jiekou.challenge(uuid)
set(step, swap, uuid, zuhao, listproblem, dis)
NumberHuaRong()
jiekou.submit(uuid, operations, myswap)
self.assertEqual(answer, True)
def test3(self):
uuid = "cac66a4d-956b-4abe-9baf-f45087a4290a"
global answer
answer = False
step, swap, uuid, zuhao, listproblem, dis = jiekou.challenge(uuid)
set(step, swap, uuid, zuhao, listproblem, dis)
NumberHuaRong()
jiekou.submit(uuid, operations, myswap)
self.assertEqual(answer, True)
if __name__ == '__main__':
unittest.main()
2.贴出Github的代码签入记录,合理记录commit信息。
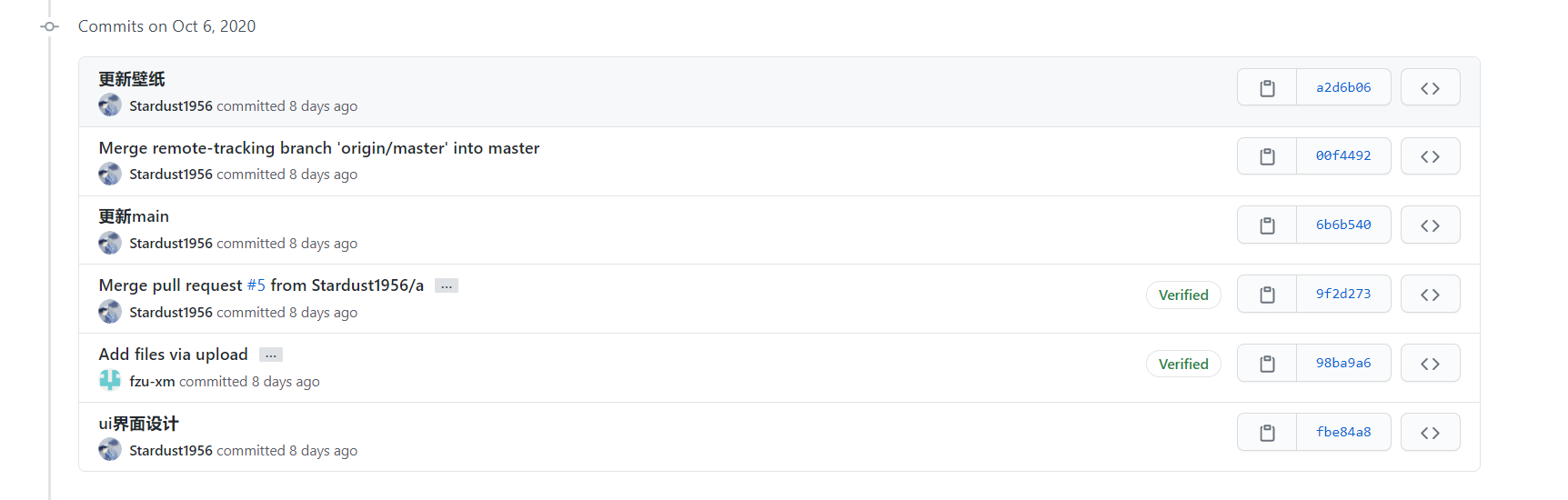

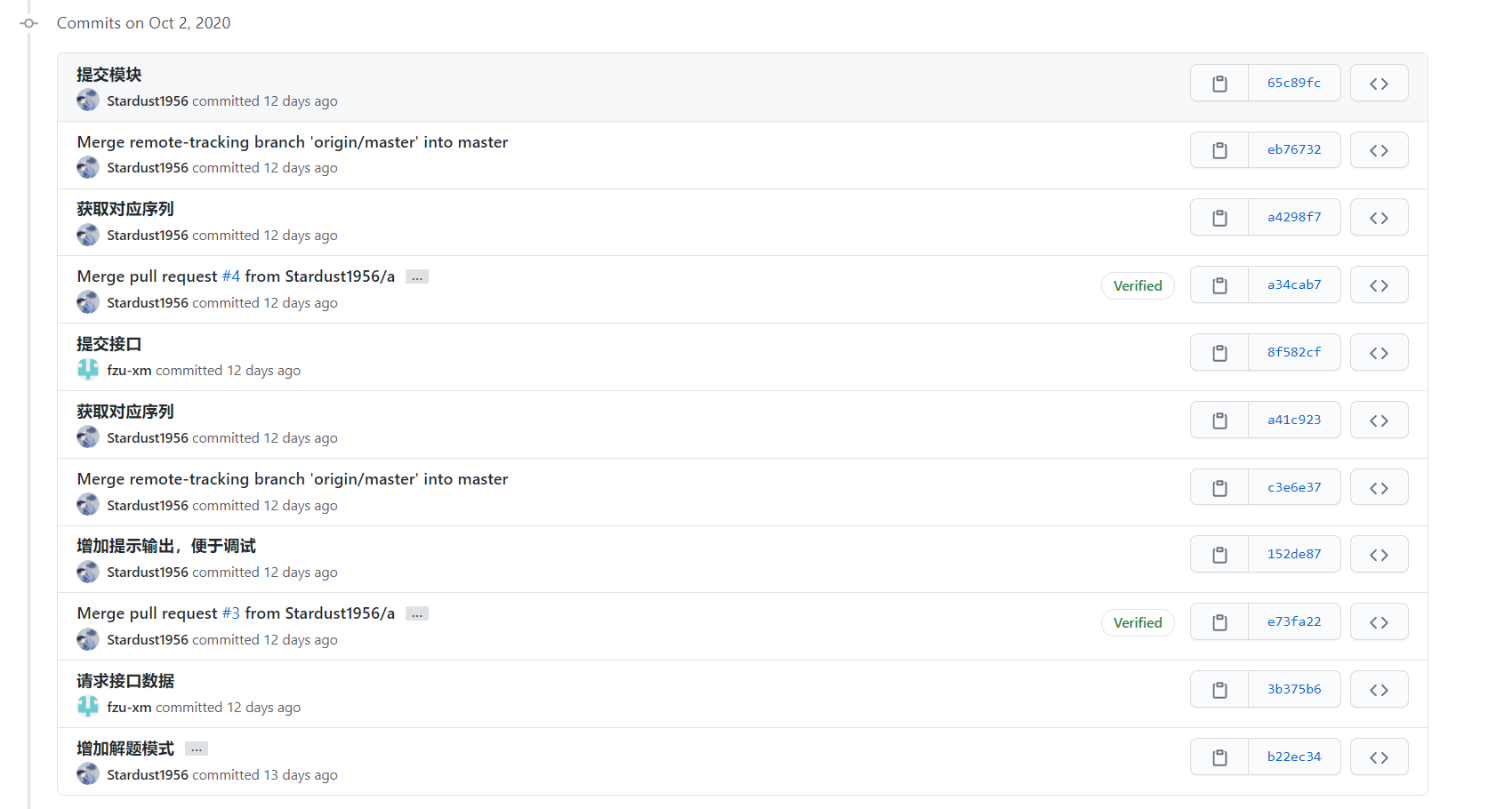
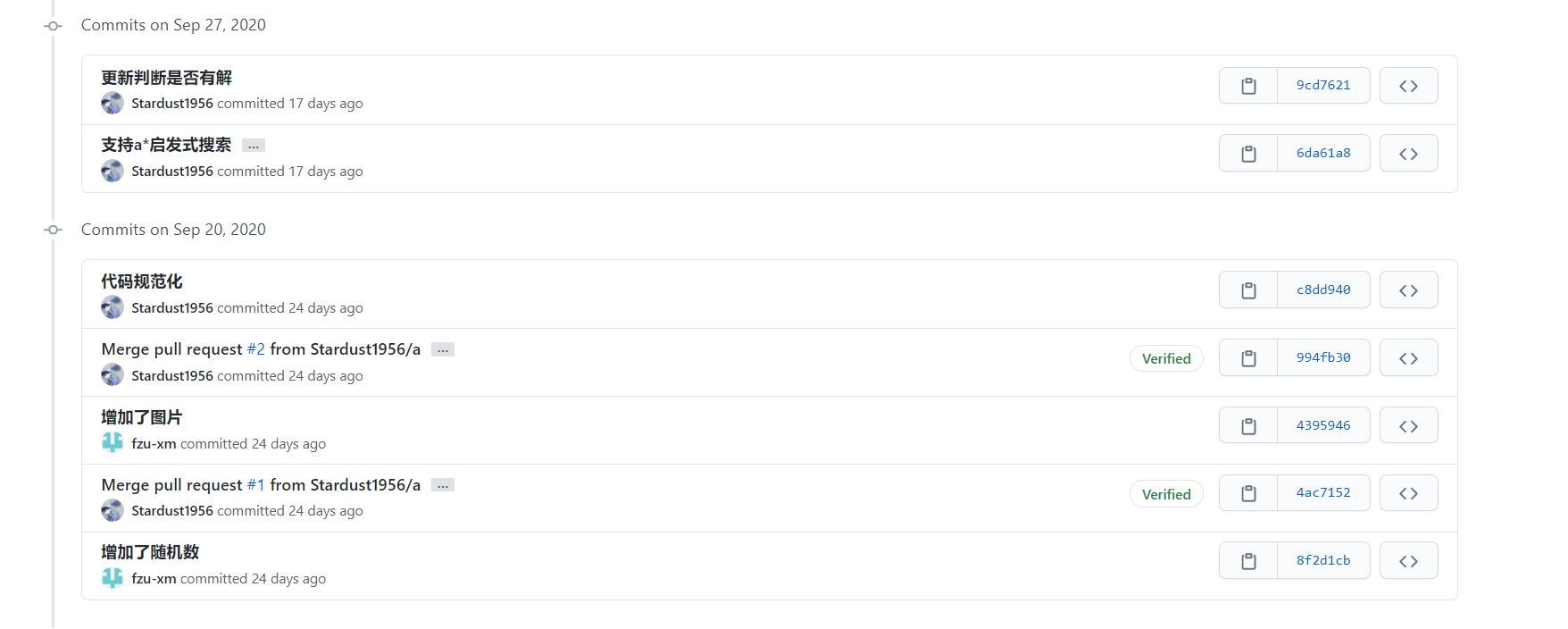

3.遇到的代码模块异常或结对困难及解决方法。
- 问题描述
在编写UI界面的过程中,华容道的界面和主界面无法进行切换,开始是想通过一个按钮来实现界面的切换,但是添加了按钮后整个游戏的九宫格布局就被毁了,而且还有可能闪退.
- 解决尝试
队友灵机一动,想出了通过键盘的按钮来触发界面的切换,既不会破坏布局,也可以实现切换功能,而且效果还更好。问题完美解决~~~nice
- 是否解决
是
- 有何收获
通过这次华容道的学习,学习到了非常多的知识。比如pyqt5的以及qtDesigner的使用,在这之前,我只会用tkinter进行一些简单的GUI界面编程,这次通过pyqt5的学习,可以用之开发一些较为复杂的界面,qt不愧是GUI编程的神器。还有接口的使用,学习了使用Python提交url请求。
4.评价你的队友。(2分)
- 值得学习的地方
我的队友还是非常可靠的,交给他的任务总是能够很有效率并且很有质量的完成。他写的代码的可读性很好,是值得我学习的方面,具有通俗易懂的注释,所以我总是能够很快的和我的代码部分进行整合。总的来说就是非常有效率!非常可靠!(偷偷看了下队友对我的评价他写的过于夸张了,我们两个实力差不多,如果他没生病住院,可能我们的核心算法会更完美)
- 需要改进的地方
在实力这方面已经很强了,但是身体素质不行,所以请你按时吃饭!好好爱惜自己的身体,不要再为了学习废寝忘食了,身体养好才有精力学习!
5.提供此次结对作业的PSP和学习进度条(每周追加)
- 学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 第一周 | 300 | 300 | 10 | 10 | 学会设计原型和Axure的使用,初步了解qt |
| 第二周 | 500 | 800 | 12 | 22 | 增强了代码能力 |
| 第三周 | 300 | 1100 | 5 | 27 | 学习了Astar算法 |
| 第四周 | 300 | 1400 | 5 | 32 | 学习了接口的编写和调用,调试代码能力进一步增强 |
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
70 |
70 |
|
· Estimate |
· 估计这个任务需要多少时间 |
70 |
70 |
|
Development |
开发 |
1030 |
1750 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
300 |
870 |
|
· Design Spec |
· 生成设计文档 |
200 |
210 |
|
· Design Review |
· 设计复审 |
50 |
40 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 |
30 |
|
· Design |
· 具体设计 |
30 |
30 |
|
· Coding |
· 具体编码 |
300 |
430 |
|
· Code Review |
· 代码复审 |
30 |
20 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
100 |
120 |
|
Reporting |
报告 |
400 |
440 |
|
· Test Repor |
· 测试报告 |
300 |
320 |
|
· Size Measurement |
· 计算工作量 |
50 |
50 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
50 |
70 |
|
|
· 合计 |
1500 |
2260 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号