
第一次个人编程作业
Github链接
点击左上角跳转
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planin | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 30 | |
| Development | 开发 | ||
| Analysis | 需求分析(包括学习新技术) | 180 | |
| Design Spec | 生成设计文档 | ||
| Design Review | 设计复审 | 60 | |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 60 | |
| Design | 具体设计 | 60 | |
| Coding | 具体编码 | 60 | |
| Code Review | 代码复审 | 60 | |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | |
| Reporting | 报告 | ||
| Test Repot | 测试报告 | 60 | |
| Size Measurement | 计算工作量 | 10 | |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | |
| 合计 | 820 |
计算模块接口的设计与实现过程
流程图
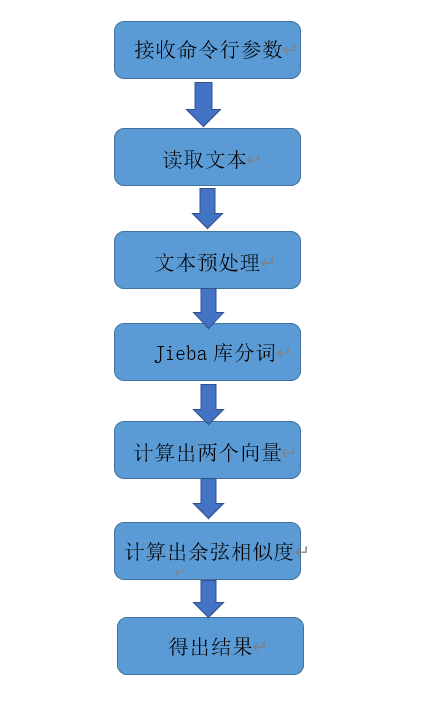
解题思路
刚刚看到这个题目的时候是比较茫然的,迅速在脑子过了一遍题目,没有一点点头绪,于是我想起了武林绝学《面向百度编程》,得益于强大的搜索能力,我很快就找到了许多解决的方法。要知道方法多也很头疼,在测试复现了几种不同的算法后,最后选择了运行效率比较高的余弦相似度计算文本相似度的方法。
初看,奇怪了,余弦定理不是数学上的知识吗?怎么会和文本相似度有关呢。仔细阅读别人的博客后,才发现了其中的奥妙。
举个简单的例子:
- 句子A:我喜欢上软工实践,也喜欢做作业。
- 句子B:我喜欢上软工实践,不喜欢做作业。
如何计算相似度? - 第一步预处理去标点
- 句子A:我喜欢上软工实践也喜欢做作业
- 句子B:我喜欢上软工实践不喜欢做作业 - 第二步分词
- 句子A:我/喜欢/上/软工实践/也/喜欢/做/作业
- 句子B:我/喜欢/上/软工实践/不/喜欢/做/作业 - 第三步合并所有词
我,喜欢,上,软工实践,也,不,做,作业 - 第四步计算词频
- 句子A:我:1,喜欢:2,上:1,软工实践:1,也:1,不:0,做:1,作业:1
- 句子B:我:1,喜欢:2,上:1,软工实践:1,也:0,不:1,做:1,作业:1 - 第五步写出词频向量
-句子A:[1,2,1,1,1,0,1,1]
-句子0:[1,2,1,1,0,1,1,1]
然后就可以利用两个向量带入余弦公式计算余弦相似度
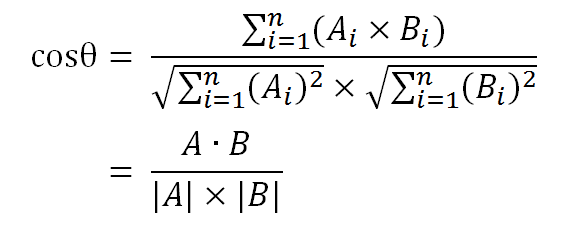
这两句话算出来相似度为90%
相似度越接近1说明两个句子相似度越高
总结如下 - 1.利用TF-IDF算法,找出两篇文章的关键词
- 2.每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
- 3.生成两篇文章各自的词频向量;
- 4.计算两个向量的余弦相似度,值越大就表示越相似。
代码组织
由上面的解题思路可以看出,我的代码模块分为
- 文本预处理
- 分词调用python中的jieba库
- 计算向量
- 计算余弦相似度
其中计算向量和余弦相似度归为Similarty类
文本预处理和写结果以及一些其他的细节放在主函数中实现
计算机模块接口部分的性能改进
一张复杂的由pycharm执行单元测试时自动生成的图
Profile的statistics
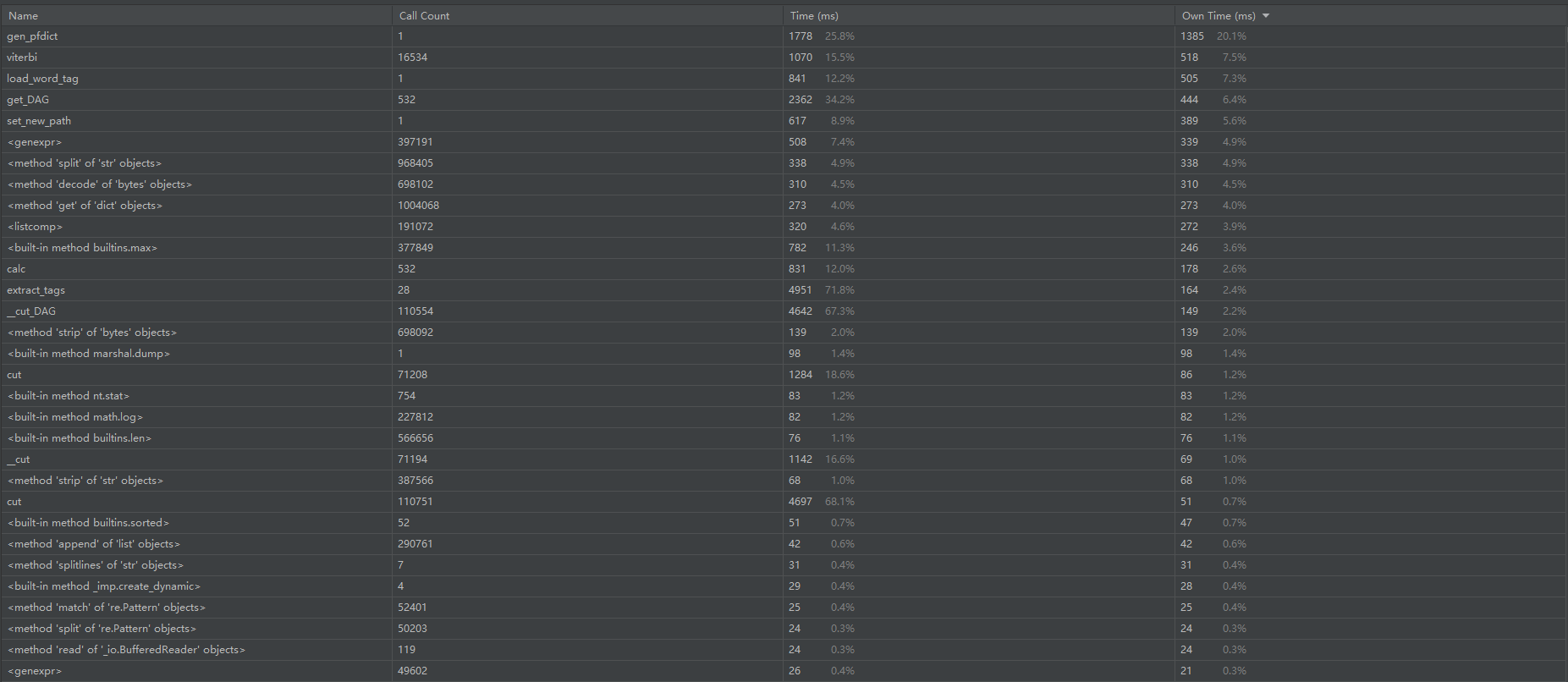
其中计算的模块消耗最大
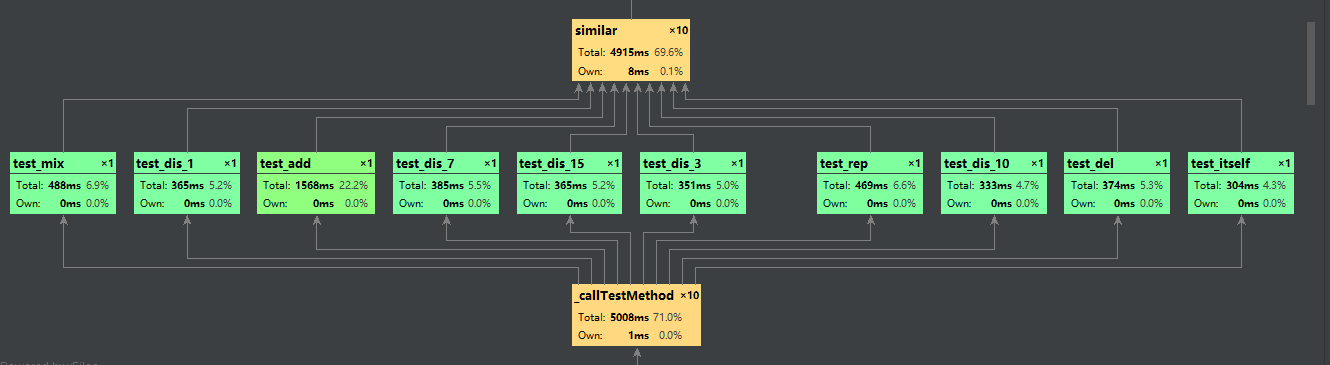
说下我计算模块的改进方法,一开始我用的方法是,把文本一中的每一句话都和文本二中的每一句比较取最大值,然后求和除以总句子数。得到的结果非常的不错,奈何耗时太大有22秒多(如图),肯定不能符合题目的要求。于是我不得不牺牲精确度来换取效率。

后来,我以一整篇文本为整体进行匹配,只取和文本长度相匹配的关键词数,时间大大加快,但是精确度也却下降了不少,结果如图

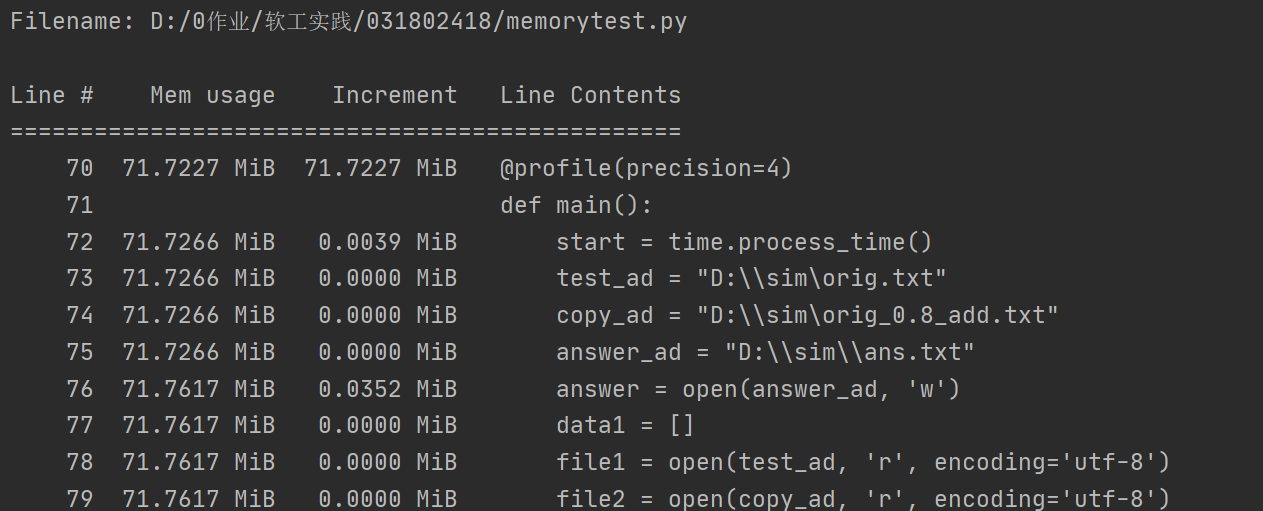
内存测试,符合要求
计算模块部分单元测试展示
先上代码
import unittest
from main import Similarity
import time
import re
def yuchuli(position1, position2):
test_ad = position1
copy_ad = position2
data1 = []
# 以utf-8格式,打开要测试的文件并按行读取拼接到data2列表中
file1 = open(test_ad, 'r', encoding='utf-8')
file2 = open(copy_ad, 'r', encoding='utf-8')
for line in file1:
line = line.strip()
if line != '\n':
if line != '':
data1.append(line)
# 以utf-8格式,打开要测试的文件并按行读取拼接到data2列表中
data2 = []
for line in file2:
line = line.strip()
if line != '\n':
if line != '':
data2.append(line)
# 连接每个行使其成为一个完整的文本存入字符串中
test1 = ''.join(data1)
test2 = ''.join(data2)
# 去符号
# punc用来记录去符号的标志字符串
punc = '~`!#$%^&*()_+-=|\';":/.,?><~·!@#¥%……&*()——+-=“”:’;、。,?》《{}'
test1 = re.sub(r'[%s]+' % punc, '', test1)
test2 = re.sub(r'[%s]+' % punc, '', test2)
file1.close()
file2.close()
return test1, test2
class Testformain(unittest.TestCase):
def test_itself(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\orig.txt", "D:\\sim\orig.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Test1")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_add(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\orig.txt", "D:\\sim\orig_0.8_add.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Test2")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_del(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\orig.txt", "D:\\sim\orig_0.8_del.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Test3")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_dis_1(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\orig.txt", "D:\\sim\orig_0.8_dis_1.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Test4")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_dis_3(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\orig.txt", "D:\\sim\orig_0.8_dis_3.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Test5")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_dis_7(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\orig.txt", "D:\\sim\orig_0.8_dis_7.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Test6")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_dis_10(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\orig.txt", "D:\\sim\orig_0.8_dis_10.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Test7")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_dis_15(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\orig.txt", "D:\\sim\orig_0.8_dis_15.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Test8")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_mix(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\orig.txt", "D:\\sim\orig_0.8_mix.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Test9")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_rep(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\orig.txt", "D:\\sim\orig_0.8_rep.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Test10")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_my1(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\mytest1.txt", "D:\\sim\mytest1_1.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Myest_1")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_my2(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\mytest2.txt", "D:\\sim\mytest2_2.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Myest_2")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_my3(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\mytest3.txt", "D:\\sim\mytest3_3.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Myest_3")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
def test_my4(self):
start = time.process_time()
t1, t2 = yuchuli("D:\\sim\mytest4.txt", "D:\\sim\mytest4_4.txt")
s = Similarity(t1, t2, int(len(t1)))
print("Myest_4")
print(s.similar())
end = time.process_time()
print('Running time: %s Seconds' % (end - start))
print()
if __name__ == '__main__':
unittest.main()
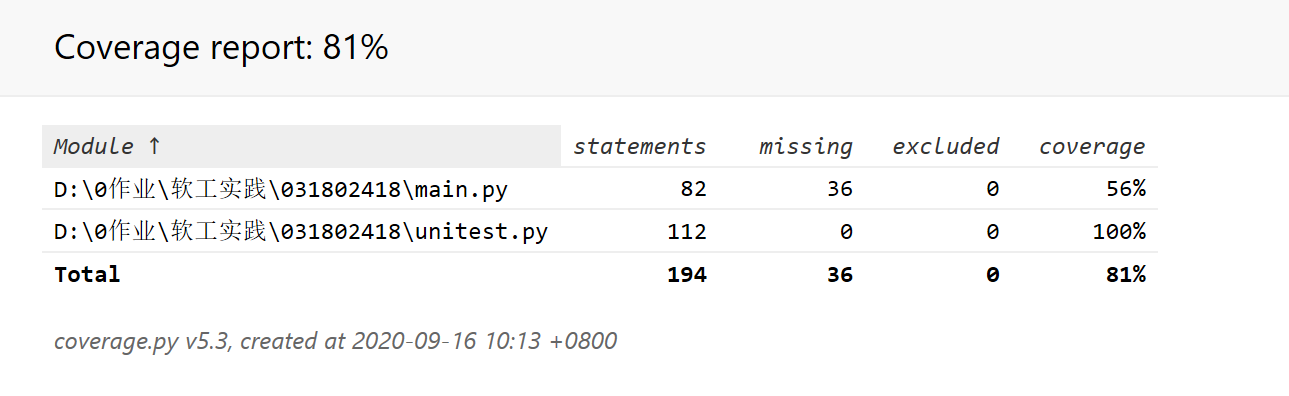
测试函数通过python自带的unitest进行单元测试,由于原来的程序需要命令行参数才能运行,所以在单元测试中重新写了数据预处理的部分yuchuli(),然后对每一个文本进行测试,并输出时间。由于重新写了预处理所以单元测试覆盖率不是100%很正常下面是截图
计算模块部分异常处理说明
出现空文档匹配
这种情况会让函数中的除数为0,因此增加了try异常处理
对应单元测试2样例很简单,一个为空文档,一个随便打点字
不支持英文符号的相似度匹配
这种情况,调用jieba不能正常的进行分词,道行不够,时间来不及,日后有机会再完善这个功能。目前的处理方法是当作空文档
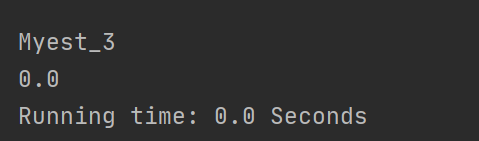
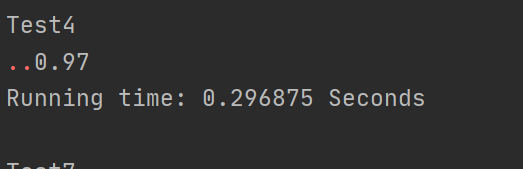
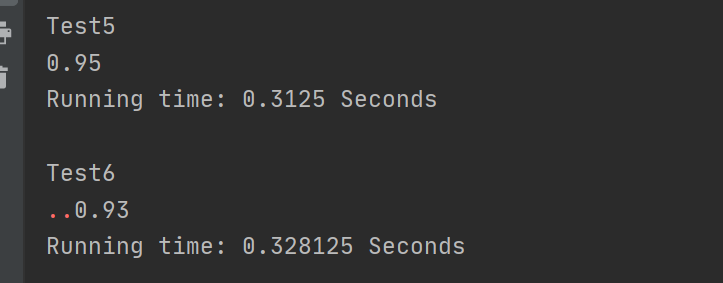
对于乱序文本相似度整体偏高,这个是余弦相似度的算法劣势,要想解决必须改变计算算法,原因是这样的,余弦相似度通过计算词频来构造向量,然而乱序文本只是顺序打乱,文本中的词语大都还在,所以计算出来的向量差距不会太大。自己测试了几个样例,想了许多方法都没有解决这个问题。或许,要另辟蹊径换个相似度的计算算法。测试结果如下
完成后的PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planin | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | ||
| Analysis | 需求分析(包括学习新技术) | 180 | 240 |
| Design Spec | 生成设计文档 | ||
| Design Review | 设计复审 | 60 | 120 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 60 | 120 |
| Design | 具体设计 | 60 | 120 |
| Coding | 具体编码 | 60 | 240 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 240 |
| Reporting | 报告 | ||
| Test Repot | 测试报告 | 60 | 10 |
| Size Measurement | 计算工作量 | 10 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 820 | 1270 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号