


evaluating indicator for nlp
准确率,精确率与召回率
定义符号:
- 真正例(True Positive, TP):被模型预测为正的正样本;
- 假正例(False Positive, FP):被模型预测为正的负样本;
- 假负例(False Negative, FN):被模型预测为负的正样本;
- 真负例(True Negative, TN):被模型预测为负的负样本;
准确率公式:
| $ Accuracy = \frac{TP+TN}{TP+TN+FP+FN} $ |
准确率公式大致表现为正确值除以总值,缺点在于在样本正反例子分布不均匀时表现不佳。
精确率公式:
| $ Precision = \frac{TP}{TP+FP} $ |
精确率公式大致表现与预测为某一类型的准确率,大多数用于二分类
召回率公式:
$ Recall = \frac{TP}{TP+FN} $
召回率表现于实际某一类型的准确率,大多数用在二分类
两者权衡:
在不同的应用场景下,我们的关注点不同,例如,在预测股票的时候,我们更关心精准率,即我们预测升的那些股票里,真的升了有多少,因为那些我们预测升的股票都是我们投钱的。而在预测病患的场景下,我们更关注召回率,即真的患病的那些人里我们预测错了情况应该越少越好。
精确率和召回率是一对此消彼长的度量。例如在推荐系统中,我们想让推送的内容尽可能用户全都感兴趣,那只能推送我们把握高的内容,这样就漏掉了一些用户感兴趣的内容,召回率就低了;如果想让用户感兴趣的内容都被推送,那只有将所有内容都推送上,宁可错杀一千,不可放过一个,这样准确率就很低了。
在实际工程中,我们往往需要结合两个指标的结果,去寻找一个平衡点,使综合性能最大化。
引用
总体而言:精确率主要关心预测值的表现,召回率主要关心真实值的情况。
变异的评价指标
- P-R曲线:对精确率与召回率的曲线表达,更好的平衡二者。

- F1:对精确率与召回率的加权平均,二者同时兼顾。
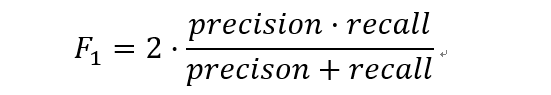
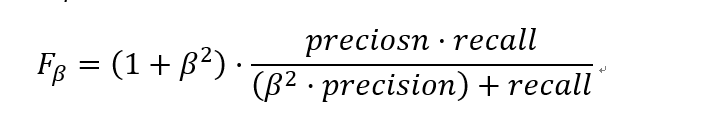
nlp中的评价指标
BLEU(Bilingual Evaluation Understudy))
一种针对与机器翻译提出的评价指标(论文地址)
在机器翻译中对翻译出来的句子有很多考虑因素:
- 翻译的是否完全
- 翻译的是否通顺
- 翻译的信息是否准确
| $ p_{n}=\frac{\sum_{c_{\in candidates}}\sum_{n-gram_{\in c}}Count_{clip}(n-gram)}{\sum_{c^{'}_{\in candidates}}\sum_{n-gram^{'}_{\in c^{'}}}Count(n-gram^{'})} $ |
通过引入n-gram(一个包含n个单词的片段),主要计算翻译后的句子与原句子的n-gram值,原始的计算方式是匹配Candidate 和Reference的n-gram片段,但是问题是匹配时发现Reference会被重复利用,所以论文改进了n-gram的方式,将匹配后的Reference的n-gram裁剪。然后把一段话或者所有翻译句子的结果综合得到评价指标。
而在翻译时,若出现译文很短的句子时往往会有较高的BLEU值,因此引入对句子长度的乘法因子,其表达式如下:
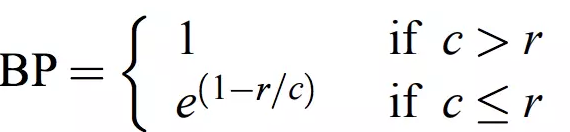
在这里cc表示cadinate的长度,rr表示reference的长度。
将上面的整合在一起,得到最终的表达式:
$ BLEU = BP exp(\sum_{n=1}^N w_n \log p_n) $
其中 $ exp(\sum_{n=1}^N w_n \log p_n) $ 表示不同的n−gramn−gram的精度的对数的加权和。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号