


Celery学习笔记
转载请注明出处:点我
我的第一篇博客!嘿嘿!
在公司实习,接触到的第一个项目就用到了Celery,之前是完全没有接触过Celery这玩意,然后花了点时间仔细的研究了下怎么用。在学习过程中也遇到了些问题,所以把自己的学习过程记录下来,供他人参考下。
先说一下我的实验环境:两台ubuntu的机子,一台win7的机子,都安装好了必须的软件。用户名为atsgxxx的机子跑的是ubuntu的系统,Redis就运行在这个上面,另外一台ubuntu的机子的用户名是sclu084。
Celery
那么什么是Celery呢?
Celery是一个用Python开发的异步的分布式任务调度模块。
Celery本身不包含消息服务,使用第三方消息服务,也就是Broker,来传递任务,目前支持的有Rebbimq,Redis,数据库以及其他的一些比如Amazon SQS,Monogdb和IronMQ 。
因为项目里面用的是Redis,所以这里以Redis作为Broker。
安装Celery
sudo apt-get install celery
使用Redis作为Broker的话,可以两者一块安装
sudo pip install -U celery[redis]
当然如果正式生产环境中,有可能redis服务器和Celery在不同的机器上面的话,就要两者单独安装
sudo apt-get install redis-server 这个命令可以安装redis,包括了redi-cli工具
第一个简单的例子
这个例子来自于Celery的官方文档。先看代码:
1 from celery import Celery 2 app = Celery('tasks',broker="redis://127.0.0.1:6379/0") 3 4 @app.task 5 def add(x,y): 6 return x + y
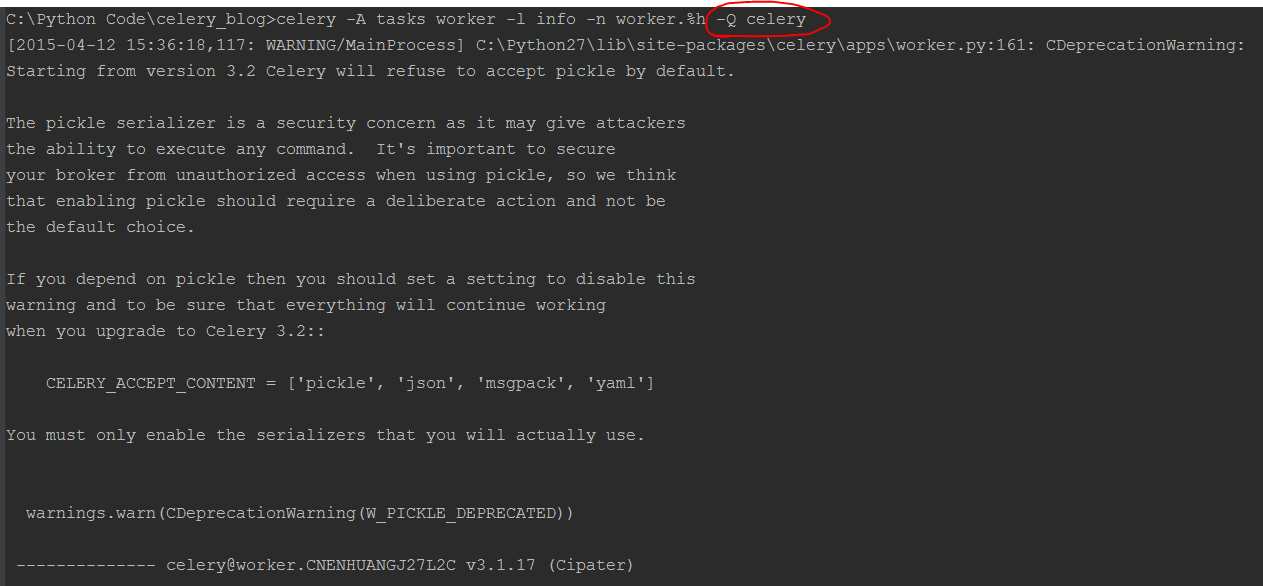
把代码保存为tasks.py文件(这个例子运行在atsgxxx这台机器上,上面运行了Redis,所以broker是127.0.0.1)。然后再terminal下启动worker。
celery -A tasks worker -l info
这个命令会启动一个worker来执行task。执行完这条命令后,不出意外的出现下面这个界面的话表示worker已经启动成功,正在等待执行任务。
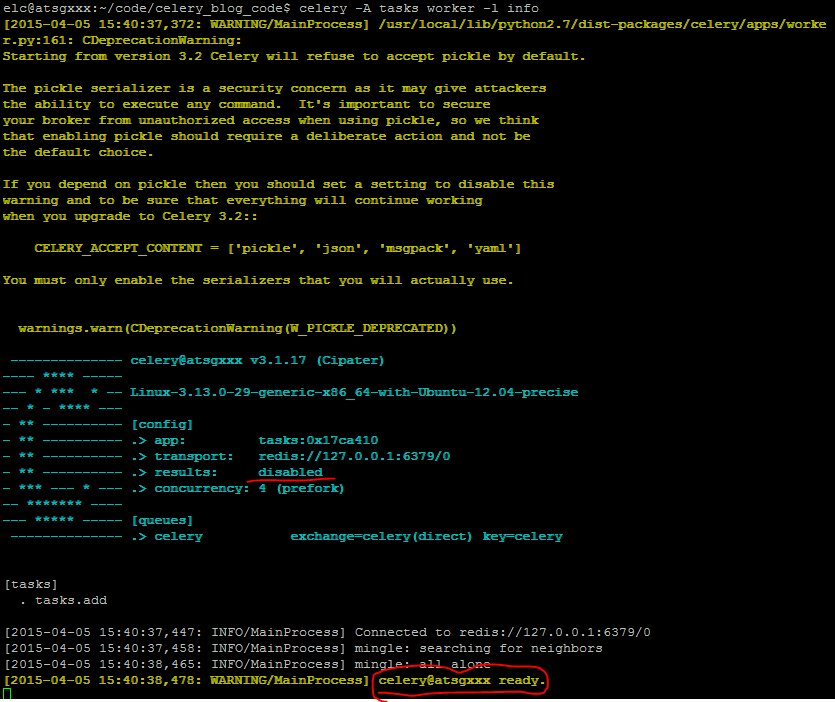
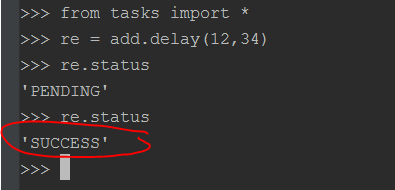
然后启动另外一个终端,进入python工作环境,执行任务,如下图所示:
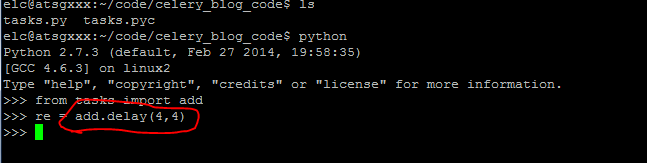
调用delay函数即可启动add这个任务,add函数的参数为4,4,这个函数的效果是发送一条消息到broker中去,这个消息包括要执行的函数已经执行函数的参数,还有一些其他信息,具体的可以看Celery的文档。
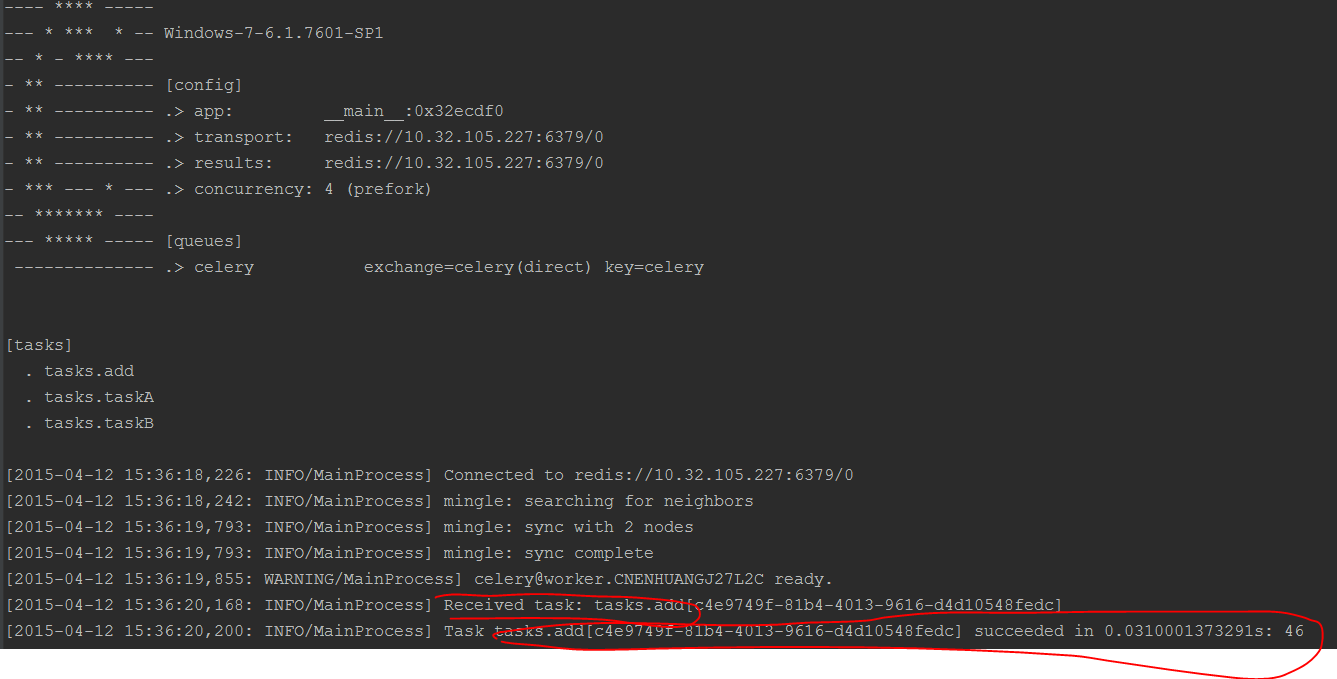
因为之前已经启动了一个worker,这个worker会等待broker中的消息,一旦收到消息就会立刻执行消息
启动了一个任务之后,可以看到之前启动的worker已经开始执行任务了。效果如下图所示:

从上图中可以看到,任务已经被执行成功。
Celery与分布式
既然Celery是一个分布式的任务调度模块,那么Celery是如何跟分布式挂上钩的呢?首先得明白什么是分布式。我的理解是所谓的分布式就是由多台分布在不同地方的计算机通过网络共同完成任务。在Celery里面,就可以是多台不同的计算机执行不同的任务或者是相同的任务。
如果要说Celery的分布式应用的话,我觉得就要提到Celery的消息路由机制,就要提一下AMQP协议。具体的可以查看AMQP的文档。简单地说就是可以有多个消息队列(Message Queue),不同的消息可以指定发送给不同的Message Queue,而这是通过Exchange来实现的。发送消息到Message Queue中时,可以指定routiing_key,Exchange通过routing_key来把消息路由(routes)到不同的Message Queue中去。具体的可以参考下这个网页,上面讲的很详细的了。
现在来看下代码:(代码实现的功能是在两台ubuntu上面启动worker,每个worker执行指定的Queue中的Task,然后在win7上面执行消息。同时演示了默认消息队列的使用。)
1 from celery import Celery 2 3 app = Celery() 4 app.config_from_object("celeryconfig") 5 6 @app.task 7 def taskA(x,y): 8 return x + y 9 10 @app.task 11 def taskB(x,y,z): 12 return x + y + z 13 14 @app.task 15 def add(x,y): 16 return x + y
上面的tasks.py中,首先定义了一个Celery对象,然后用celeryconfig.py对celery对象进行设置,之后再分别定义了三个task,分别是taskA,taskB和add。接下来看一下celeryconfig.py文件
1 from kombu import Exchange,Queue 2 3 BROKER_URL = "redis://10.32.105.227:6379/0" CELERY_RESULT_BACKEND = "redis://10.32.105.227:6379/0" 4 5 CELERY_QUEUES = (
Queue("default",Exchange("default"),routing_key="default"),
Queue("for_task_A",Exchange("for_task_A"),routing_key="task_a"),
Queue("for_task_B",Exchange("for_task_B"),routing_key="task_a")
) 6 7 CELERY_ROUTES = { 8 'tasks.taskA':{"queue":"for_task_A","routing_key":"task_a"}, 9 'tasks.taskB":{"queue":"for_task_B","routing_key:"task_b"} 10 }
在celeryconfig.py文件中,首先设置了brokel以及result_backend,接下来定义了三个Message Queue,并且指明了Queue对应的Exchange(当使用Redis作为broker时,Exchange的名字必须和Queue的名字一样)以及routing_key的值。
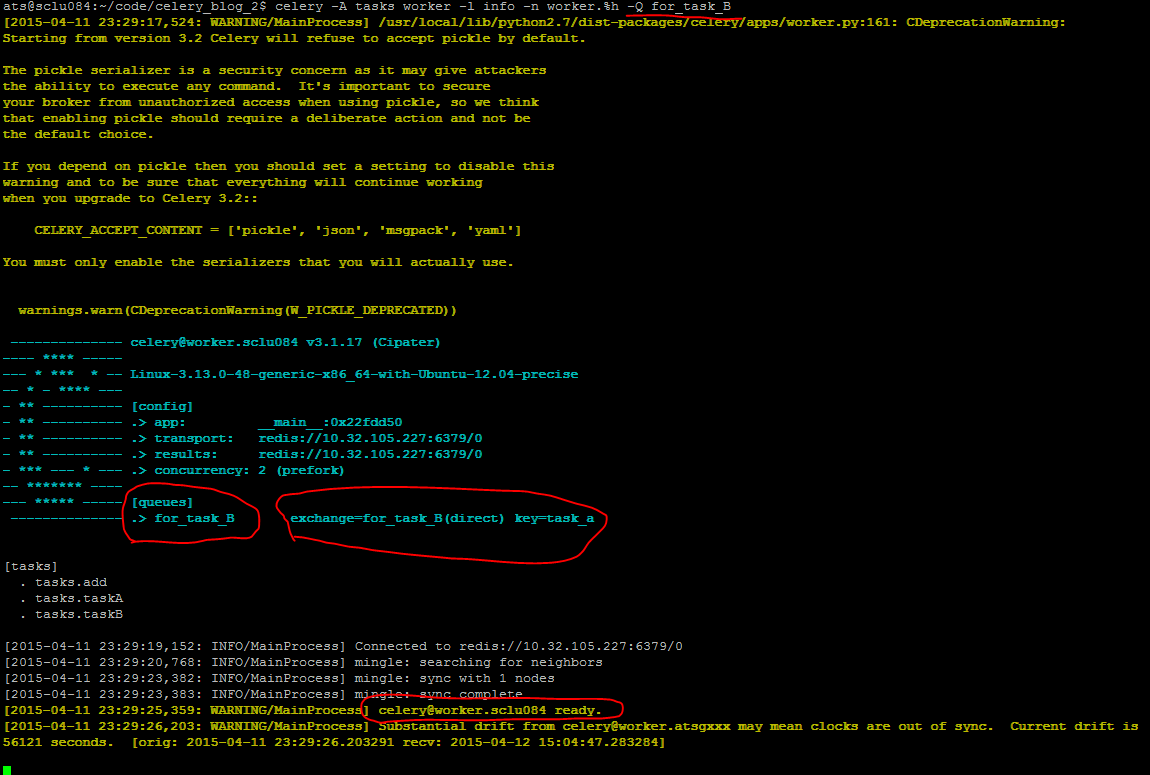
现在现在其中一台ubuntu上面启动一个worker,这个worker只执行for_task_A队列中的消息,这是通过在启动worker是使用-Q Queue_Name参数指定的。
celery -A tasks worker -l info -n worker.%h -Q for_task_A
其中-n参数表示这个worker的name,-Q参数指定了这个worker执行for_task_A队列中的消息。执行结果如下图所示:
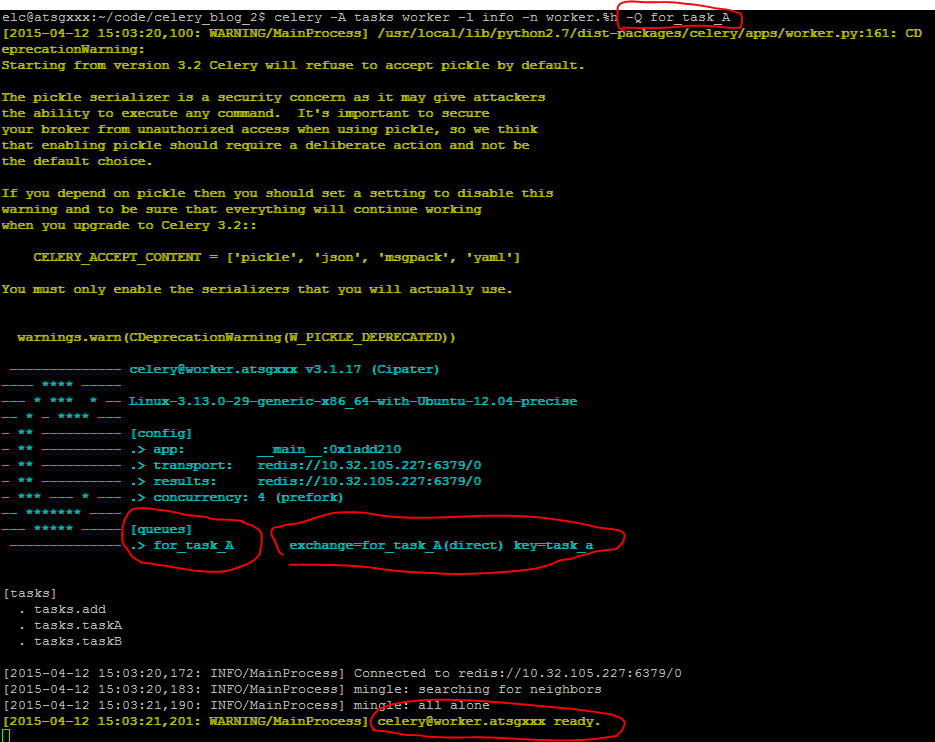
上面的执行结果表明名字为worker.atsgxxx的任务已经启动,等待执行for_task_A中的任务。
然后再win7上面执行taskA任务。在win7上,进入CMD,切换当前目录到代码坐在的工程下,启动python,执行下面代码启动taskA:
from tasks import * task_A_re = taskA.delay(100,200)
执行完上面的代码之后,task_A消息会被立即发送到for_task_A队列中去。此时已经启动的worker.atsgxxx 会立即执行taskA任务。效果如下图所示:
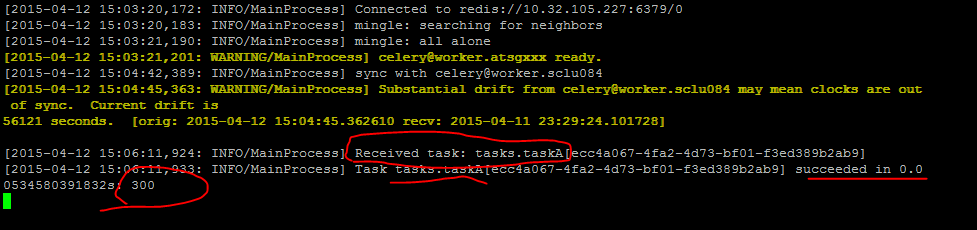
可以看到taskA已经被worker.atsgxxx执行成功.
然后再win7上面查看taskA的执行状态:
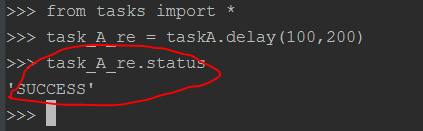
也显示taskA已经成功被执行了。
重复上面的过程,在另外一台机器上启动一个worker专门执行for_task_B中的任务,在win7上执行taskB任务。整个过程及结果如下面的图所示:

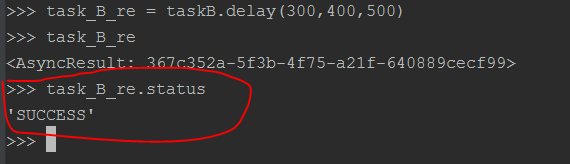
在上面的tasks.py文件中还定义了add任务,但是在celeryconfig.py文件中没有指定这个任务route到那个Queue中去执行,此时执行add任务的时候,add会route到Celery默认的名字叫做celery的队列中去。
下面现在wind7上面执行add任务,然后再另外一个终端上面启动一个worker执行名字为celery的队列中的消息(这个名字叫做celery的Queue不是我们定义的,是Celery默认的)。结果如下图所示:
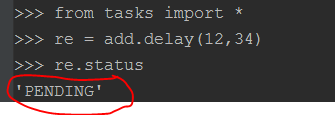
此时可以看到add任务的状态是PENDING,表示还没有被执行,因为这个消息没有在celeryconfig.py文件中指定应该route到哪一个Queue中,所以会被发送到默认的名字为celery的Queue中,但是我们还没有启动worker执行celery中的任务。接下来我们在启动一个worker执行celery队列中的任务。
1 celery -A tasks worker -l info -n worker.%h -Q celery
然后再查看add的状态,会发现状态由PENDING变成了SUCCESS。效果如下图所示:
Celery与定时任务
在celery中执行定时任务非常简单,只需要设置celery对象的CELERYBEAT_SCHEDULE属性即可。
下面我们接着上面的代码,在celeryconfig.py中添加CELERYBEAT_SCHEDULE变量:
1 CELERY_TIMEZONE = 'UTC' 2 CELERYBEAT_SCHEDULE = { 3 'taskA_schedule' : { 4 'task':'tasks.taskA', 5 'schedule':20, 6 'args':(5,6) 7 }, 8 'taskB_scheduler' : { 9 'task':"tasks.taskB", 10 "schedule":200, 11 "args":(10,20,30) 12 }, 13 'add_schedule': { 14 "task":"tasks.add", 15 "schedule":10, 16 "args":(1,2) 17 } 18 }
其中定义了3个定时任务,即每隔20s执行taskA任务,参数为(5,6),每隔200s执行taskB任务,参数为(10,20,30),每隔10s执行add任务,参数为(1,2).通过下列命令启动一个定时任务:
1 celery -A tasks beat
使用beat参数即可启动定时任务。
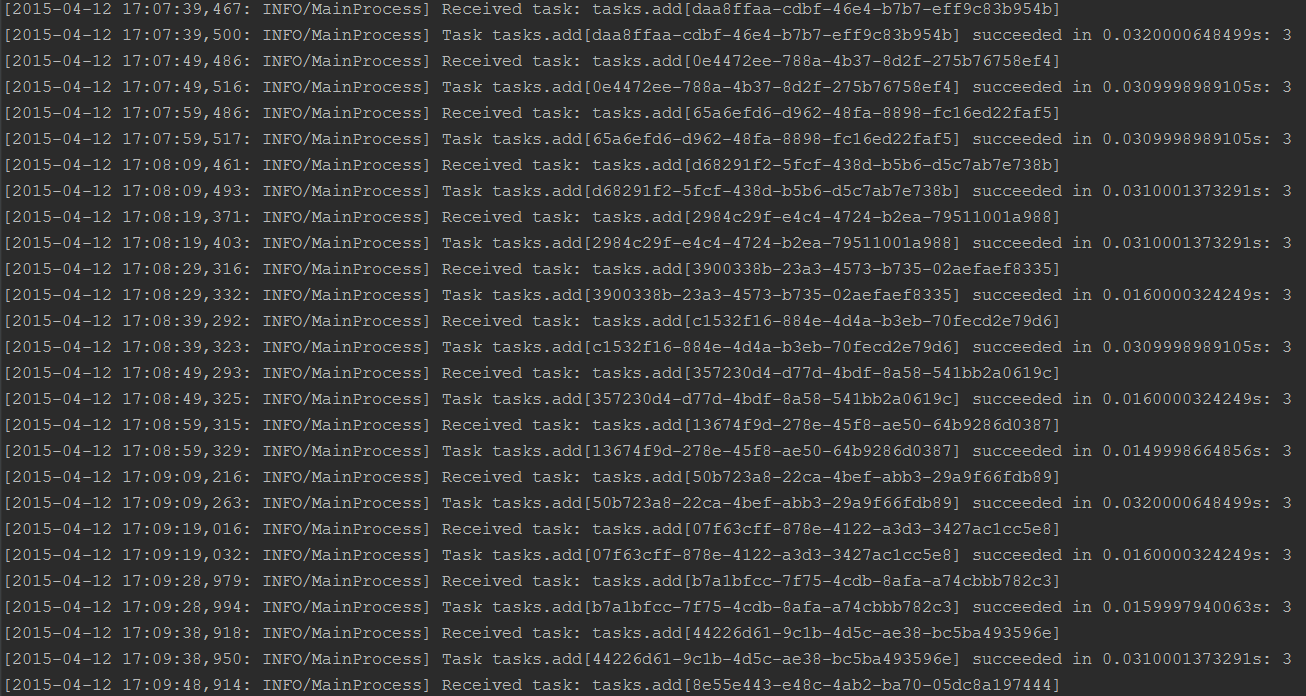
下面分别在三台机器上面启动三个worker分别执行for_task_A,for_task_B和celery这三个Queue中的任务。启动之后,再在其中一台机器上面启动定时任务。结果如下图所示(第一张为启动定时任务一段时间后的截图):
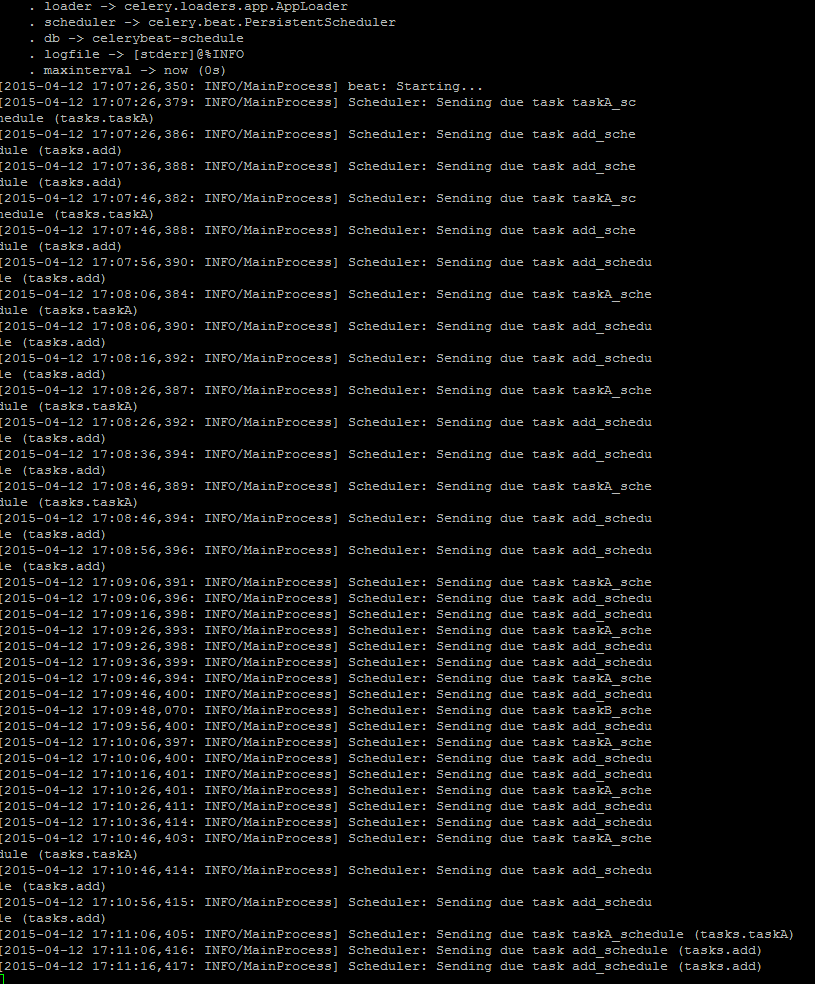
可以看到一旦scheduler启动起来,就会按照CELERYBEAT_SCHEDULE指定的时间执行指定的任务。然后已经启动的worker已接受到一消息就会执行任务,如下图所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号