

遗留系统现代化主要模式
代码现代化的主要模式
1. 先对代码做可测试化重构,并添加测试
2. 在测试的保护下,安全地重构
3. 在测试的保护下,将代码分层
一个软件的自动化测试,可以从内部表达这个软件的质量,我们通常管它叫做内建质量(Build Quality In)。
例1
public class EmployeeService { public EmployeeDto getEmployeeDto(long employeeId) { EmployeeDao employeeDao = new EmployeeDao(); // 访问数据库获取一个Employee Employee employee = employeeDao.getEmployeeById(employeeId); // 其他代码 } }
这段代码之所以不可测,是因为在方法内部直接初始化了一个可以访问数据库的 Dao 类,要想测试这个方法,就必须访问数据库了。倒不是说所有测试都不能连接数据库,但大多数直连数据库的测试跑起来都太慢了,而且数据的准备也会相当麻烦。
这属于不可测代码的第一种类型:在方法中构造了不可测的对象。
例2
public class EmployeeService { public EmployeeDto getEmployeeDto(long employeeId) { // 访问数据库获取一个Employee Employee employee = EmploeeDBHelper.getEmployeeById(employeeId); // 其他代码 } }
这段代码同样是不可测的,它在方法中调用了不可测的静态方法,因为这个静态方法跟前面的实例方法一样,也访问了数据库。
除了不能在测试中访问真实数据库以外,也不要在测试中访问其他需要部署的中间件、服务等,它们也会给测试带来极大的不便。
在测试中,我们通常把被测的元素(可能是组件、类、方法等)叫做 SUT(System Under Test),把 SUT 所依赖的组件叫做 DOC(Depended-on Component)。导致 SUT 无法测试的原因,通常都是 DOC 在当前的测试上下文中不可用。
DOC 不可用的原因通常有三种:
1. 不能访问。比如 DOC 访问了数据库或其他需要部署的中间件、服务等,而本地环境没有这些组件,也很难部署这些组件。
2. 不是当前测试期望的返回值。即使本地能够访问这些组件,但它们却无法返回我们想要的值。比如我们想要获取 ID 为 1 的员工信息,但数据库中却并没有这条数据。
3. 执行这些 DOC 的方法会引发不想要的副作用。比如更新数据库,会破坏已有数据,影响其他测试。另外连接数据库,还会导致测试执行时间变长,这也是一种副作用。
如何才能让 DOC 的行为可变呢?如果 DOC 是静态的或是在 SUT 内构造的,那自然不可改变。所以,我们要让 DOC 的构造和 SUT 本身分离,SUT 只需使用外部构造好的 DOC 的实例,而不用关心它的构造。这种可以让 DOC 的行为发生改变的位置,叫做接缝(seam),这是 Michael Feathers 在《修改代码的艺术》这本书里提出来的。
如何让代码变得可测?
a.接缝的位置
如例1,可以把EmployeeDao提取成EmployeeService的字段,并通过EmployeeService的构造函数注入进来。
public class EmployeeService { private EmployeeDao employeeDao; public EmployeeService(EmployeeDao employeeDao) { this.employeeDao = employeeDao; } public EmployeeDto getEmployeeDto(long employeeId) { Employee employee = employeeDao.getEmployeeById(employeeId); // 其他代码 } }
除了构造函数,接缝也可以位于方法参数中,如:
public class EmployeeService { public EmployeeDto getEmployeeDto(long employeeId, EmployeeDao employeeDao) { Employee employee = employeeDao.getEmployeeById(employeeId); // 其他代码 } }
b.接缝的类型
接缝的类型是指,通过什么样的方式来改变 DOC 的行为。
提取完接缝后,创建一个 EmployeeDao 的子类,这个子类重写了 getEmployeeById 的默认行为,从而让这个 DOC 返回了我们“期望的值”。
public class InMemoryEmployeeDao extends EmployeeDao { @Override public Employee getEmployeeById(long employeeId) { return null; } }
这种通过继承 DOC 来改变默认行为的接缝类型叫做对象接缝。
除此之外,还可以将原来的 EmployeeDao 类重命名为 DatabaseEmployeeDao,并提取出一个 EmployeeDao 接口。然后再让 InMemoryEmployeeDao 类实现 EmployeeDao 接口。
public interface EmployeeDao { Employee getEmployeeById(long employeeId); }
在 EmployeeService 中,我们仍然通过构造函数来提供这个接缝,代码基本上可以保持不变。这样,我们和对象接缝一样,只需要在构造 EmployeeService 的时候传入 InMemoryEmployeeDao 就可以改变默认的行为,之后的测试也更方便。
这种通过将 DOC 提取为接口,并用其他实现类来改变默认行为的接缝类型,就叫做接口接缝。
c.新生和外覆
假设我们有这样一段代码,根据传入的开始和结束时间,计算这段时间内所有员工的工作时间:
public class EmployeeService { public Map<Long, Integer> getWorkTime(LocalDate startDate, LocalDate endDate) { EmployeeDao employeeDao = new EmployeeDao(); List<Employee> employees = employeeDao.getAllEmployees(); Map<Long, Integer> workTimes = new HashMap<>(); for(Employee employee : employees) { WorkTimeDao workTimeDao = new WorkTimeDao(); int workTime = workTimeDao.getWorkTimeByEmployeeId(employee.getEmployeeId(), startDate, endDate); workTimes.put(employee.getEmployeeId(), workTime); } return workTimes; } }
需求是这样的,业务人员拿到工时的报表后发现,有很多员工的工时都是 0,原来他们早就离职了。现在要求你修改一下代码,过滤掉那些离职的员工。
如果不需要写测试,这样的需求对你来说就是小事一桩,你一定轻车熟路。你可以在 EmployeeDao 中添加一个新的查询数据库的方法 getAllActiveEmployees,只返回在职的 Employee。也可以仍然使用 getAllEmployees,并在内存中进行过滤。
public class EmployeeService { public Map<Long, Integer> getWorkTime(LocalDate startDate, LocalDate endDate) { EmployeeDao employeeDao = new EmployeeDao(); List<Employee> employees = employeeDao.getAllEmployees() .stream() .filter(e -> e.isActive()) .collect(toList()); // 其他代码 } }
这样的修改不仅在遗留系统中,即使在所谓的新系统中,也是十分常见的。需求要求加一个过滤条件,那我就加一个过滤条件就好了。然而,这样的代码仍然是不可测的,你加了几行代码,但你加的代码也是不可测的,系统没有因你的代码而变得更好,反而更糟了。更好的做法是添加一个新生方法,去执行过滤操作,而不是在原来的方法内去过滤。
public class EmployeeService { public Map<Long, Integer> getWorkTime(LocalDate startDate, LocalDate endDate) { EmployeeDao employeeDao = new EmployeeDao(); List<Employee> employees = filterInactiveEmployees(employeeDao.getAllEmployees()); // 其他代码 } public List<Employee> filterInactiveEmployees(List<Employee> employees) { return employees.stream().filter(e -> e.isActive()).collect(toList()); } }
这样一来,新生方法是可测的,你可以对它添加测试,以验证过滤逻辑的正确性。原来的方法虽然仍然不可测,但我们也没有让它变得更糟。
除了新生,你还可以使用外覆的方式来让新增加的功能可测。比如下面这段计算员工薪水的代码。
public class EmployeeService { public BigDecimal calculateSalary(long employeeId) { EmployeeDao employeeDao = new EmployeeDao(); Employee employee = employeeDao.getEmployeeById(); return SalaryEngine.calculateSalaryForEmployee(employee); } }
如果我们现在要添加一个新的功能,有些调用端在计算完薪水后,需要立即给员工发短信提醒,而且其他调用端则保持不变。你脑子里可能有无数种实现方式,但最简单的还是直接在这段代码里添加一个新生方法,用来通知员工。
public class EmployeeService { public BigDecimal calculateSalary(long employeeId, bool needToNotify) { EmployeeDao employeeDao = new EmployeeDao(); Employee employee = employeeDao.getEmployeeById(); BigDecimal salary = SalaryEngine.calculateSalaryForEmployee(employee); notifyEmployee(employee, salary, needToNotify); return salary; } }
这的确非常方便,但将 needToNotify 这种标志位一层层地传递下去,是典型的代码坏味道FlagArgument。你也可以在调用端根据情况去通知员工,但那样对调用端的修改又太多太重,是典型的霰弹式修改。最好的方式是在原有方法的基础上外覆一个新的方法 calculateSalaryAndNotify,它会先调用原有方法,然后再调用通知方法。
public BigDecimal calculateSalary(long employeeId) { // ... } public BigDecimal calculateSalaryAndNotify(long employeeId) { BigDecimal salary = calculateSalary(employeeId); notifyEmployee(employeeId, salary); return salary; } public void notifyEmployee(long employeeId, BigDecimal salary) { // 通知员工 }
添加测试的方法
决策表模式
以著名的镶金玫瑰重构道场的代码为例
public void updateQuality() { for (int i = 0; i < items.length; i++) { if (!items[i].name.equals("Aged Brie") && !items[i].name.equals("Backstage passes to a TAFKAL80ETC concert")) { if (items[i].quality > 0) { if (!items[i].name.equals("Sulfuras, Hand of Ragnaros")) { items[i].quality = items[i].quality - 1; } } } else { if (items[i].quality < 50) { items[i].quality = items[i].quality + 1; if (items[i].name.equals("Backstage passes to a TAFKAL80ETC concert")) { if (items[i].sellIn < 11) { if (items[i].quality < 50) { items[i].quality = items[i].quality + 1; } } if (items[i].sellIn < 6) { if (items[i].quality < 50) { items[i].quality = items[i].quality + 1; } } } } } if (!items[i].name.equals("Sulfuras, Hand of Ragnaros")) { items[i].sellIn = items[i].sellIn - 1; } if (items[i].sellIn < 0) { if (!items[i].name.equals("Aged Brie")) { if (!items[i].name.equals("Backstage passes to a TAFKAL80ETC concert")) { if (items[i].quality > 0) { if (!items[i].name.equals("Sulfuras, Hand of Ragnaros")) { items[i].quality = items[i].quality - 1; } } } else { items[i].quality = items[i].quality - items[i].quality; } } else { if (items[i].quality < 50) { items[i].quality = items[i].quality + 1; } } } } }
这是非常典型的遗留代码,if/else 满天飞,可谓眼花缭乱;而且分支的规则不统一,有的按名字去判断,有的按数量去判断。
对于这种分支条件较多的代码,我们可以梳理需求文档(如果有的话)和代码,找出所有的路径,根据每个路径下各个字段的数据和最终的值,制定一张决策表,如下图所示。
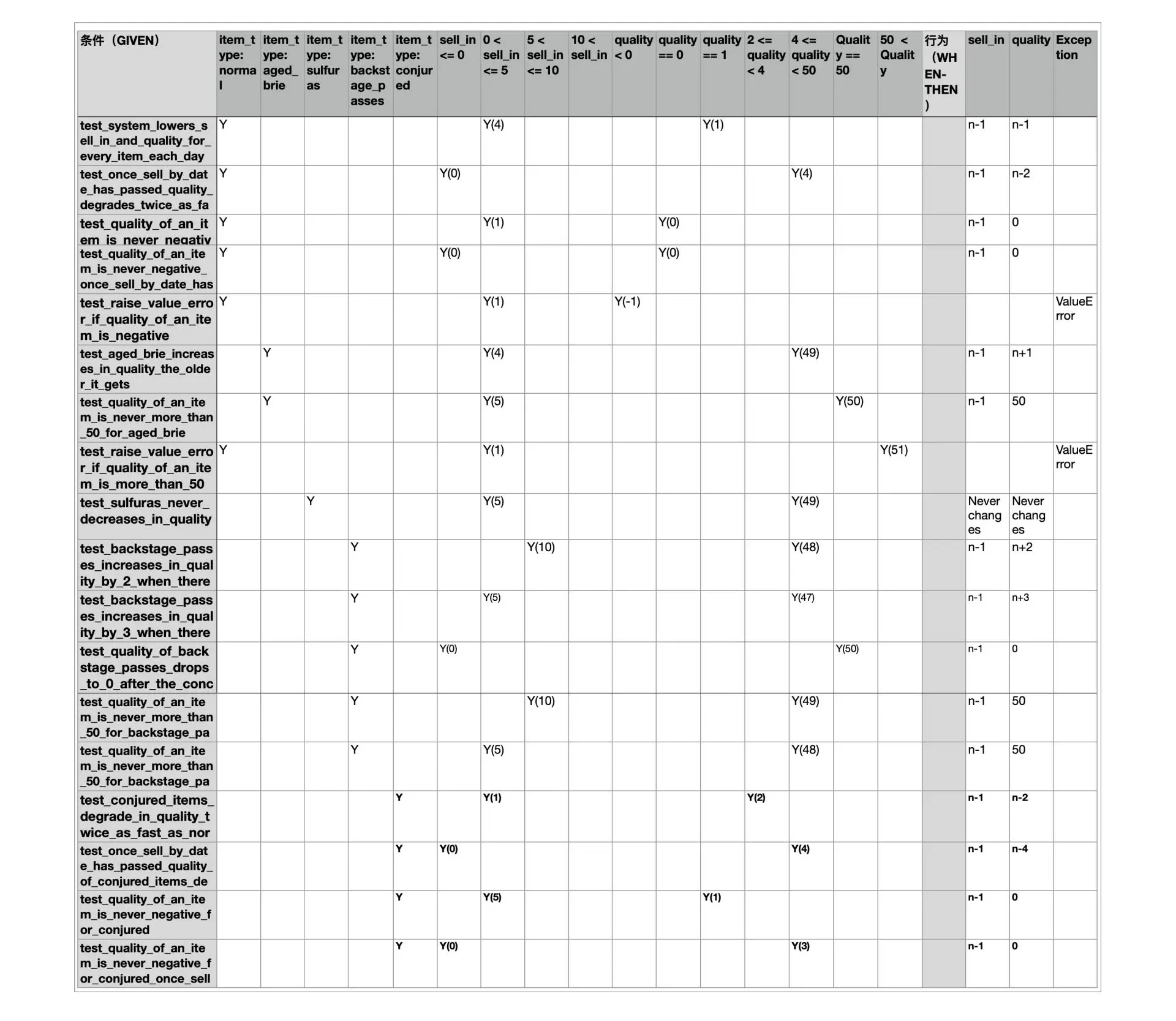
遗留系统中的测试策略
测试的命名:用“实例化需求”的方式,从业务角度来命名测试,使得测试可以和代码一起演进,成为活文档。
测试的组织:当测试变多时,如果不好好对测试进行分组,很快就会变得杂乱无章。这样的测试即使是活文档,也会增加认知负载。+
最好的方法是,将单个类的测试都放在同一个包中,将不同方法的测试放在单独的测试类里。而对于同一个方法,要先写它 Happy path 的测试,再写 Sad path。记住一个口诀:先简单,再复杂;先正常,再异常。也就是测试的场景要先从简单的开始,逐步递进到复杂的情况;而测试的用例要先写正常的 Case,再逐步递进到异常的 Case。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号