python之路[12] - 数据库和sqlalchemy ORM -- 迁
数据库操作
Mysql 模块的安装
 View Code
View Code
Python MySQL API
安装
redhat/centos yum install mysql-devel* python-devel debian apt-get install mysql-client mysql-server libmysqld-dev python-dev 不装会提示mysql_config找不到
windows
安装 MySQL-python-1.2.3.win-amd64-py2.7.exe
pip install MySQL-python # 注意 django 1.6 -- libmysqlclient.so.18
返回字典结构
import MySQLdb
import MySQLdb.cursors
db = MySQLdb.connect(host='localhost', user='root',
passwd='123456', db='test',
cursorclass=MySQLdb.cursors.DictCursor)
cur = db.cursor()
cur.execute('select * from user')
rs = cur.fetchall()
print rs
# 返回类似如下
# ({'age': 0L, 'num': 1000L}, {'age': 0L, 'num': 2000L}, {'age': 0L, 'num': 3000L})
# 如果不使用cursorclass,返回格式: ((1000L, 0L), (2000L, 0L), (3000L, 0L))
对返回的数据进行二次处理(比如decode)
db = MySQLdb.connect(host = ′localhost′, user = ′root′, passwd = ′123456′, db = ′test′)
cursor = conn.cursor(cursorclass = MySQLdb.cursors.DictCursor)
# 处理函数
def rows_to_dict_list(cursor):
columns = [i[0] for i in cursor.description]
#对字段进行处理
return [dict(zip(columns,[row[0],row[1],row[2],base64.b64decode(row[3]).replace('\r\n',' ').decode('utf-8'),row[4]])) for row in cursor ]
y=c.execute(sql)
rows=rows_to_dict_list(y)
return rows
使用tuple的格式传输到values里面
cursor.execute('''insert into nc_result (ip,port,result,check_time,LocName)values('%s','%s','%s','%s','%s');''' % (result))
数据库插入中文问题
check the manual that corresponds to your MySQL server version for the right syntax to use near 'set LocName='\xe6\xb5\xa6\xe5\x8f\x91\xe9\x93 首先先去mysql UI 上执行一下,不要一直在脚本中试,如果不行就修改表的属性: ALTER TABLE nc_result MODIFY LocName CHAR(20) CHARACTER SET gbk; 将字段修改为gbk编码的格式
批量执行,比自己写循环快很200倍!
View Code
关于lastrowid和insert_id() )的结果一般情况下是一样的,最后一条记录肯定就是刚刚插入的记录。但如果是并发插入就不一样了,多线程的时候
print "ID of last record is ", int(cursor.lastrowid) #最后插入行的主键ID print "ID of inserted record is ", int(conn.insert_id()) #最新插入行的主键ID,conn.insert_id()一定要在conn.commit()之前,否则会返回0
使用tuple的格式传输到values里面,快速拼接sql
self.cursor.execute('''insert into nc_result (ip,port,result,check_time,LocName)values('%s','%s','%s','%s','%s');''' % (result))
python Oracle API
windows安装
windows 下安装cx_Oracle http://www.cnblogs.com/pcode/archive/2013/04/01/2992695.html cx_Oracle-5.2-11g.win-amd64-py2.7.exe
linux安装
yum install gcc libffi-devel python-devel openssl-devel
安装oracle 客户端(直接复制安装版本)
处理 libclntsh.so.10.1
输入:locate libclntsh.so.10.1
编辑/etc/ld.so.conf 加入环境变量:/home/ecp/oracle/ORACLE/lib/libclntsh.so.10.1
执行
ldconfig
再调用就好了
如果一直报:No module named cx_Oracle
那就用 source code 直接装,装时候先设置oracle库的环境变量
关于连接方式:
Create and return a session pool object. This allows for very fast connections to the database and is of primary use in a server where the same connection is being made multiple times in rapid succession (a web server, for example).
普通版
cx_Oracle.Connection(user=None, password=None, dsn=None, mode=None, handle=None, pool=None, threaded=False, events=False, cclass=None, purity=None, newpassword=None, encoding=None, nencoding=None, edition=None, appcontext=[], tag=None, matchanytag=False, shardingkey=[], supershardingkey
=[])
cx_Oracle.Connect(user=None, password=None, dsn=None, mode=None, handle=None, pool=None, threaded=False, events=False, cclass=None, purity=None, newpassword=None, encoding=None, nencoding=None, edition=None, appcontext=[], tag=None, matchanytag=None, shardingkey=[], supershardingkey=[])
conn = cx.Connect('bm','bm','10.0.0.44:1521/orcl')
cursor = conn.cursor()
c = cursor.execute(checksql(sqlmap.sql_text))
使用SessionPool可以减少连接重复
cx_Oracle.SessionPool(user, password, dsn, min, max, increment, connectiontype=cx_Oracle.Connection, threaded=False, getmode=cx_Oracle.SPOOL_ATTRVAL_NOWAIT, events=False, homogeneous=True, externalauth=False, encoding=None, nencoding=None, edition=None)
def db_connect(self):
dsn = cx_Oracle.makedsn(self.args.address, self.args.port,
self.args.database)
self.pool = cx_Oracle.SessionPool(
user=self.args.username,
password=self.args.password,
dsn=dsn,
min=1,
max=3,
increment=1)
self.db = self.pool.acquire()
self.cur = self.db.cursor()
def db_close(self):
self.cur.close()
self.pool.release(self.db)
注意1:execute执行sql不能带;,用checksql过滤下
def checksql(sqlstate):
newsqlstate = sqlstate.rstrip(';')
return newsqlstate
注意2,默认返回:
fetchall : ((0.966507403377643,),) fetchone : (0.966507403377643,)
要求返回为json类型,即k-v返回
def rows_to_dict_list(cursor):
columns = [i[0] for i in cursor.description]
dict_with_columns = [dict(zip(columns, row)) for row in cursor]
return dict_with_columns
完整代码+executemany+sql字典
import cx_Oracle
def rows_to_dict_list(cursor):
columns = [i[0] for i in cursor.description]
dict_with_columns = [dict(zip(columns, row)) for row in cursor]
return dict_with_columns
def checksql(sqlstate):
newsqlstate = sqlstate.rstrip(';')
return newsqlstate
def db_handle(arg):
if isinstance(arg,(list,tuple)):
try:
dsn = cx.makedsn(ip, port, db)
conn = cx.connect(username, pwd, dsn)
cursor = conn.cursor()
SQL = "insert into log_detail values(:type, :gmt_create, :line_count, :gmt_log_date, :gmt_log_hour);"
logging.debug("create_db_sql: [%s]" % SQL)
cursor.executemany(checksql(SQL), arg)
conn.commit()
except Exception as e:
logging.error(str(e))
finally:
cursor.close()
conn.close()
def main():
insert_data_list = []
for prod_env in PRODS:
getHitsByProd = do_search(prod_env)
insert_data_dict = {
'type':prod_env,
'gmt_create':datetime.datetime.now(), #oracle field: timestamp
'line_count':getHitsByProd,
'gmt_log_date':before_dt.strftime('%Y%m%d'),
'gmt_log_hour':before_dt.strftime('%H')
}
insert_data_list.append(insert_data_dict)
logging.debug(insert_data_list)
db_handle(insert_data_list)
ORM
ORM介绍
orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。
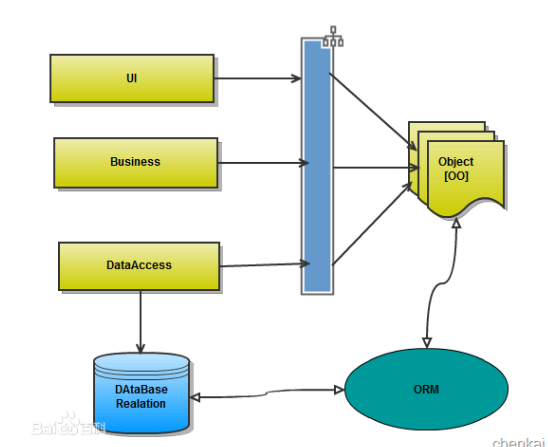
orm的优点:
- 隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。
- ORM使我们构造固化数据结构变得简单易行。
缺点:
- 无可避免的,自动化意味着映射和关联管理,代价是牺牲性能(早期,这是所有不喜欢ORM人的共同点)。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的。
sqlalchemy安装
在Python中,最有名的ORM框架是SQLAlchemy。用户包括openstack\Dropbox等知名公司或应用
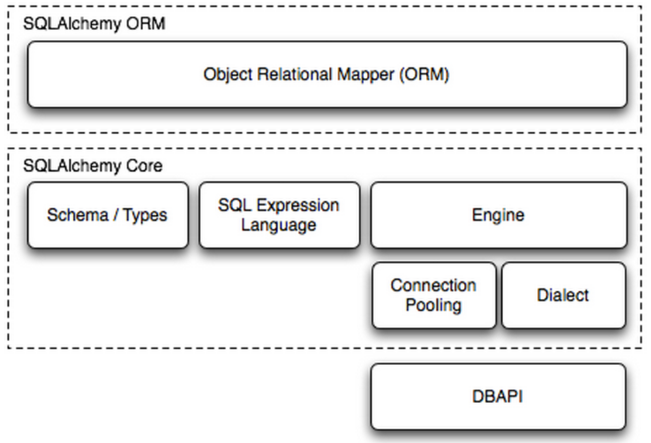
Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html
安装sqlalchemy
pip install SQLAlchemy pip install pymysql #由于mysqldb依然不支持py3,所以这里我们用pymysql与sqlalchemy交互
sqlalchemy基本使用
一般表的创建
CREATE TABLE user (
id INTEGER NOT NULL AUTO_INCREMENT,
name VARCHAR(32),
password VARCHAR(64),
PRIMARY KEY (id)
)
这只是最简单的sql表,如果再加上外键关联什么的,一般程序员的脑容量是记不住那些sql语句的,于是有了orm,实现上面同样的功能,代码如下
import sqlalchemy
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, Table, Column, Integer,DateTime ,Boolean,String, MetaData, ForeignKey, UniqueConstraint
engine = create_engine("mysql+pymysql://root:mysql@localhost/testdb",
encoding='utf-8', echo=True)
Base = declarative_base() #生成orm基类
class User(Base):
__tablename__ = 'user' #表名
id = Column(Integer, primary_key=True)
name = Column(String(32))
password = Column(String(64))
Base.metadata.create_all(engine) #创建表结构
除上面的创建之外,还有一种创建表的方式,虽不常用,但还是看看吧
from sqlalchemy import Table, MetaData, Column, Integer, String, ForeignKey
from sqlalchemy.orm import mapper
metadata = MetaData()
user = Table('user', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(50)),
Column('fullname', String(50)),
Column('password', String(12))
)
class User(object):
def __init__(self, name, fullname, password):
self.name = name
self.fullname = fullname
self.password = password
mapper(User, user) #the table metadata is created separately with the Table construct, then associated with the User class via the mapper() function
事实上,我们用第一种方式创建的表就是基于第2种方式的再封装。
最基本的表我们创建好了,那我们开始用orm创建一条数据试试
from sqlalchemy.orm import relationship,sessionma Session_class = sessionmaker(bind=engine) #创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例 Session = Session_class() #生成session实例 user_obj = User(name="alex",password="alex3714") #生成你要创建的数据对象 print(user_obj.name,user_obj.id) #此时还没创建对象呢,不信你打印一下id发现还是None Session.add(user_obj) #把要创建的数据对象添加到这个session里, 一会统一创建 print(user_obj.name,user_obj.id) #此时也依然还没创建 Session.commit() #现此才统一提交,创建数据
查询
my_user = Session.query(User).filter_by(name="alex").first() all_user = Session.query(User).all() print(my_user,all_user)
此时你看到的输出是这样的应该, 只不过sqlalchemy帮你把返回的数据映射成一个对象啦
<__main__.User object at 0x105b4ba90> <__main__.User object at 0x15g2e4bdd90>
调用方式:
print(my_user.id,my_user.name,my_user.password) 输出 1 user1 123
不过刚才上面的显示的内存对象对址你是没办法分清返回的是什么数据的,除非打印具体字段看一下,如果想让它变的可读,只需在定义表的类下面加上这样的代码
def __repr__(self):
return "<User(name='%s', password='%s')>" % (
self.name, self.password)
插入
sqlmap_add = SqlMap(auth_id=1,name="test1",sql_text="select count(*) from sqlmap",created_by='gt',status=1,interval=argv.get('interval') or 5)
Session.add(sqlmap_add)
修改
my_user = Session.query(User).filter_by(name="alex").first() my_user.name = "Alex Li" Session.commit()
删除
>>> from sqlalchemy import delete >>> Session.delete(users).where(users.c.username == 'u1') >>> Session.commit()
回滚
my_user = Session.query(User).filter_by(id=1).first() my_user.name = "Jack" fake_user = User(name='Rain', password='12345') Session.add(fake_user) print(Session.query(User).filter(User.name.in_(['Jack','rain'])).all() ) #这时看session里有你刚添加和修改的数据 Session.rollback() #此时你rollback一下 print(Session.query(User).filter(User.name.in_(['Jack','rain'])).all() ) #再查就发现刚才添加的数据没有了。 # Session # Session.commit()
获取所有数据
print(Session.query(User.name,User.id).all() )
多条件查询
objs = Session.query(User).filter(User.id>0).filter(User.id<7).all()
上面2个filter的关系相当于 user.id >1 AND user.id <7 的效果
统计和分组
Session.query(User).filter(User.name.like("Ra%")).count()
from sqlalchemy import func
print(Session.query(func.count(User.name),User.name).group_by(User.name).all()
相当于原生sql为
SELECT count(user.name) AS count_1, user.name AS user_name
FROM user GROUP BY user.name
输出为
[(1, 'Jack'), (2, 'Rain')]
Choicetype
pip install sqlalchemy_utils
from sqlalchemy_utils.types.choice import ChoiceType
class Auth(Base):
__tablename__ = 'auth' #表名
TYPE_CHOICE = (
('mysql','Mysql'),
('ora', 'Oracle')
)
id = Column(Integer, primary_key=True)
db_url = Column(String(64))
username = Column(String(32))
password = Column(String(32))
db_type = Column(ChoiceType(TYPE_CHOICE, impl=String(32)), default='ora')
# 插入数据 auth_add = Auth(db_url="10.0.0.1/dev",username="config",password="123",db_type='ora') Session.add(auth_add) Session.commit() ## 注意db_type 写入值不在choicetype里面,也能提交成功,但是查下会报错的! print auth.db_type.value >>> Oracle
外键关联
class Auth(Base):
__tablename__ = 'auth' #表名
id = Column(Integer, primary_key=True)
db_url = Column(String(64))
username = Column(String(32))
password = Column(String(32))
class SqlMap(Base):
__tablename__ = 'sqlmap'
id = Column(Integer, primary_key=True)
auth_id = Column(Integer, ForeignKey('auth.id')) # auth_id 是auth的外键
name = Column(String(32),unique=True)
sql_text = Column(String(500))
items = Column(String(64))
created_at = Column(DateTime(),default=datetime.now)
updated_at = Column(DateTime(),default=datetime.now, onupdate=datetime.now)
created_by = Column(String(64))
interval = Column(Integer)
status = Column(Boolean())
auth = relationship("Auth", backref="sqlmap") # 允许你在Auth表内通过backref字段反向查出所有它在SqlMap表里的关联项
def __repr__(self):
return self.name
表创建好后,我们可以这样反查试试
sqlmap = Session.query(SqlMap).first()
# 外键查询
print sqlmap.auth.db_url
auth = Session.query(Auth).first()
# 根据auth反向查关联sqlmap的记录
for i in auth.sqlmap:
print i
创建关联对象
sqlmap_obj = Session.query(SqlMap).filter(name='test').all()[0] sqlmap_obj.auth_id = [Auth(id=1)] #添加关联对象 Session.commit()
常用查询语法

Common Filter Operators Here’s a rundown of some of the most common operators used in filter(): equals: query.filter(User.name == 'ed') not equals: query.filter(User.name != 'ed') LIKE: query.filter(User.name.like('%ed%')) IN: NOT IN: query.filter(~User.name.in_(['ed', 'wendy', 'jack'])) IS NULL: IS NOT NULL: AND: 2.1. ObjectRelationalTutorial 17 query.filter(User.name.in_(['ed', 'wendy', 'jack'])) # works with query objects too: query.filter(User.name.in_( session.query(User.name).filter(User.name.like('%ed%')) )) query.filter(User.name == None) # alternatively, if pep8/linters are a concern query.filter(User.name.is_(None)) query.filter(User.name != None) # alternatively, if pep8/linters are a concern query.filter(User.name.isnot(None)) SQLAlchemy Documentation, Release 1.1.0b1 # use and_() from sqlalchemy import and_ query.filter(and_(User.name == 'ed', User.fullname == 'Ed Jones')) # or send multiple expressions to .filter() query.filter(User.name == 'ed', User.fullname == 'Ed Jones') # or chain multiple filter()/filter_by() calls query.filter(User.name == 'ed').filter(User.fullname == 'Ed Jones') Note: Makesureyouuseand_()andnotthePythonandoperator! • OR: Note: Makesureyouuseor_()andnotthePythonoroperator! • MATCH: query.filter(User.name.match('wendy')) Note: match() uses a database-specific MATCH or CONTAINS f
插入
auth = Session.query(Auth).filter_by(id=1).first() sqlmap_add = SqlMap(auth_id=auth.id,name="test2",structure='colum',sql_text="select 1 as t1 from dual",created_by='gt',status=1,interval=5)
多外键关联
下表中,Customer表有2个字段都关联了Address表
from sqlalchemy import Integer, ForeignKey, String, Column
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
Base = declarative_base()
class Customer(Base):
__tablename__ = 'customer'
id = Column(Integer, primary_key=True)
name = Column(String)
billing_address_id = Column(Integer, ForeignKey("address.id"))
shipping_address_id = Column(Integer, ForeignKey("address.id"))
billing_address = relationship("Address")
shipping_address = relationship("Address")
class Address(Base):
__tablename__ = 'address'
id = Column(Integer, primary_key=True)
street = Column(String)
city = Column(String)
state = Column(String)
创建表结构是没有问题的,但你Address表中插入数据时会报下面的错
sqlalchemy.exc.AmbiguousForeignKeysError: Could not determine join condition between parent/child tables on relationship Customer.billing_address - there are multiple foreign key paths linking the tables. Specify the 'foreign_keys' argument, providing a list of those columns which should be counted as containing a foreign key reference to the parent table.
解决办法如下
class Customer(Base):
__tablename__ = 'customer'
id = Column(Integer, primary_key=True)
name = Column(String)
billing_address_id = Column(Integer, ForeignKey("address.id"))
shipping_address_id = Column(Integer, ForeignKey("address.id"))
billing_address = relationship("Address", foreign_keys=[billing_address_id])
shipping_address = relationship("Address", foreign_keys=[shipping_address_id])
这样sqlachemy就能分清哪个外键是对应哪个字段了
多对多关系
现在来设计一个能描述“图书”与“作者”的关系的表结构,需求是
- 一本书可以有好几个作者一起出版
- 一个作者可以写好几本书
#一本书可以有多个作者,一个作者又可以出版多本书
from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
book_m2m_author = Table('book_m2m_author', Base.metadata,
Column('book_id',Integer,ForeignKey('books.id')),
Column('author_id',Integer,ForeignKey('authors.id')),
)
class Book(Base):
__tablename__ = 'books'
id = Column(Integer,primary_key=True)
name = Column(String(64))
pub_date = Column(DATE)
authors = relationship('Author',secondary=book_m2m_author,backref='books')
def __repr__(self):
return self.name
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
name = Column(String(32))
def __repr__(self):
return self.name
接下来创建几本书和作者
Session_class = sessionmaker(bind=engine) #创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例 s = Session_class() #生成session实例 b1 = Book(name="跟Alex学Python") b2 = Book(name="跟Alex学把妹") b3 = Book(name="跟Alex学装逼") b4 = Book(name="跟Alex学开车") a1 = Author(name="Alex") a2 = Author(name="Jack") a3 = Author(name="Rain") b1.authors = [a1,a2] b2.authors = [a1,a2,a3] s.add_all([b1,b2,b3,b4,a1,a2,a3]) s.commit()
此时,手动连上mysql,分别查看这3张表,你会发现,book_m2m_author中自动创建了多条纪录用来连接book和author表
mysql> select * from books; +----+------------------+----------+ | id | name | pub_date | +----+------------------+----------+ | 1 | 跟Alex学Python | NULL | | 2 | 跟Alex学把妹 | NULL | | 3 | 跟Alex学装逼 | NULL | | 4 | 跟Alex学开车 | NULL | +----+------------------+----------+ 4 rows in set (0.00 sec) mysql> select * from authors; +----+------+ | id | name | +----+------+ | 10 | Alex | | 11 | Jack | | 12 | Rain | +----+------+ 3 rows in set (0.00 sec) mysql> select * from book_m2m_author; +---------+-----------+ | book_id | author_id | +---------+-----------+ | 2 | 10 | | 2 | 11 | | 2 | 12 | | 1 | 10 | | 1 | 11 | +---------+-----------+ 5 rows in set (0.00 sec)
此时,我们去用orm查一下数据
print('--------通过书表查关联的作者---------')
book_obj = s.query(Book).filter_by(name="跟Alex学Python").first()
print(book_obj.name, book_obj.authors)
print('--------通过作者表查关联的书---------')
author_obj =s.query(Author).filter_by(name="Alex").first()
print(author_obj.name , author_obj.books)
s.commit()
输出如下
--------通过书表查关联的作者--------- 跟Alex学Python [Alex, Jack] --------通过作者表查关联的书--------- Alex [跟Alex学把妹, 跟Alex学Python]
多对多删除
删除数据时不用管book_m2m_authors , sqlalchemy会自动帮你把对应的数据删除
通过书删除作者
author_obj =s.query(Author).filter_by(name="Jack").first() book_obj = s.query(Book).filter_by(name="跟Alex学把妹").first() book_obj.authors.remove(author_obj) #从一本书里删除一个作者
直接删除作者
删除作者时,会把这个作者跟所有书的关联关系数据也自动删除
author_obj =s.query(Author).filter_by(name="Alex").first() # print(author_obj.name , author_obj.books) s.delete(author_obj) s.commit()
处理中文
sqlalchemy设置编码字符集一定要在数据库访问的URL上增加charset=utf8,否则数据库的连接就不是utf8的编码格式
eng = create_engine('mysql://root:root@localhost:3306/test2?charset=utf8',echo=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号