[zabbix]自定义监控和api进阶 - 迁
API部分
自定义监控项目
zabbix自动发现

可以在模板也可以在主机添加自动发现规则,这个自动发现和主机的自动发现不是一样的!
采用客户端方式

创建一个bmt.discovery的键值,加在客户端UserParameter自定义监控项中执行脚本
UserParameter=bmt.discovery,source /etc/profile && python /usr/local/zabbix-agent/shell/business_monitor.py
#!/usr/bin/env python
# set coding: utf-8
# :output:
# {
# "data":[
# {
# "{#SQL_NAME_COL}":"TEST1_T1",
# },
# {
# "{#SQL_NAME_COL}":"TEST1_T2",
# },
# {
# "{#SQL_NAME_COL}":"TEST2_T1"
# }
# ]
# }
# TempFile:
#SQL_NAME_COL VALUE
# TEST1_T1 1
# TEST1_T2 0
# TEST2_T1 10
__author__ = "richardzgt"
import cx_Oracle as cx
import ConfigParser
import os,sys
import re
import datetime,time
import logging
import logging.handlers
import multiprocessing
import json
"""logging info"""
LOG_FILE = '/tmp/bm.log'
logger = logging.getLogger('bm') # 获取名为Ldap的logger
logger.setLevel(logging.INFO)
handler = logging.handlers.RotatingFileHandler(LOG_FILE, maxBytes = 1024*1024) # 实例化handler
formatter = logging.Formatter('%(asctime)s- %(levelname)s - %(message)s') # 实例化formatter
handler.setFormatter(formatter) # 为handler添加formatter
logger.addHandler(handler)
""" :parameter """
# 建立数据库连接
ip = ''
port = 1521
db = ''
username = ''
pwd = ''
runtime = 1
tempfile = "/tmp/tmp.zabbix.bm"
class datetimeToJson(json.JSONEncoder):
"""docstring for datatimeToJson"""
def default(self, obj):
if isinstance(obj, (datetime.datetime,)):
return obj.isoformat()
else:
return super().default(obj)
def intToString(vdata):
if isinstance(vdata,(int,float)):
return str(vdata)
return vdata
def checksql(sqlstate):
newsqlstate = sqlstate.rstrip(';')
return newsqlstate
def do_db_query(item,q):
# output: {'DATA': {'COL1': 345}, {'COL1': 52}, 'SQL_NAME': 'test'}
conn = cx.connect(item['USERNAME'],
item['PASSWORD'],
item['DB_URL'],
)
cursor = conn.cursor()
try:
c = cursor.execute(checksql(item['SQL_TEXT']))
rows = rows_to_dict_list(c)
except Exception,e:
rows = [{'error':0}]
logger.warning( "[%s]%s" % (item['SQL_NAME'],str(e)))
SQL_NAME = item['NAME'] if item['NAME'] else item['ID']
sql_name_data = {"DATA":rows[0],"SQL_NAME":SQL_NAME}
q.put(sql_name_data)
def rows_to_dict_list(cursor):
columns = [i[0] for i in cursor.description]
dict_with_columns = [dict(zip(columns, row)) for row in cursor]
return dict_with_columns
def get_bm_config():
sql = 'select * from bm_config where status=1;'
dsn = cx.makedsn(ip, port, db)
conn = cx.connect(username, pwd, dsn)
cursor = conn.cursor()
c = cursor.execute(checksql(sql))
rows = rows_to_dict_list(c)
return rows
def updateTempFile(for_data):
# param: [('test_COL2', '66'), ('test_COL1', 345), ('test2_K1', 3742)]
_list = []
with open(tempfile,'w') as fobj:
_list = [" ".join(i) for i in for_data ]
content = "\n".join(_list)
fobj.write(content+"\n")
fobj.close()
def strft_json(for_data):
# param: [{'DATA': {'COL2': '66', 'COL1': 345}, 'SQL_NAME': 'test'}, {'DATA': {'K1': 3742}, 'SQL_NAME': 'test2'}]
# output :
#格式化成适合zabbix lld的json数据
format_data = []
file_data = []
for one_result in for_data:
for k in one_result['DATA']:
SQL_NAME_COL = "%s_%s" % (one_result['SQL_NAME'],k)
file_data += [(SQL_NAME_COL,intToString(one_result['DATA'][k]))]
format_data += [{'{#SQL_NAME_COL}':SQL_NAME_COL}]
updateTempFile(file_data)
return json.dumps({'data':format_data},sort_keys=True,indent=4,separators=(',',':'))
def main():
logger.info("buisness check starting")
db_query_result = []
bm_items = get_bm_config()
p = multiprocessing.Pool(50)
q = multiprocessing.Queue()
for bm_item in bm_items:
mp = multiprocessing.Process(target=do_db_query,args=(bm_item,q))
mp.start()
time.sleep(0.5)
if mp.is_alive():
# 等待查询时间
time.sleep(runtime)
if mp.is_alive():
mp.terminate()
logger.error("%s: sql[%s],runtime[%s] exceed!" % (bm_item['NAME'],bm_item['SQL_TEXT'],runtime))
return ""
else:
logger.warning("run_sql name: <"+bm_item['NAME']+"> is ok,but test query db is too slow!") ##alarm
db_query_result.append(q.get())
# print q.get()
print strft_json(db_query_result)
if __name__ == '__main__':
main()
这个脚本的作用是提取数据库sql并在目标数据库执行,将执行结果打到/tmp/tmp.zabbix.bm。
格式如下:
SQL_NAME_COL VALUE xxx_xxxx_message_RECVS 0
将key是唯一性的,由sql_name+column拼接成的为了查询出来的键值不重复
然后再通过监控项原型根据key提取此文件value值,而监控项原型的意义就在于利用自动发现的key去查询value,所以必须在原型项中定义后续的查询条件
{#SQL_NAME_COL}是根据bm.discovery上传的json中的key定义的
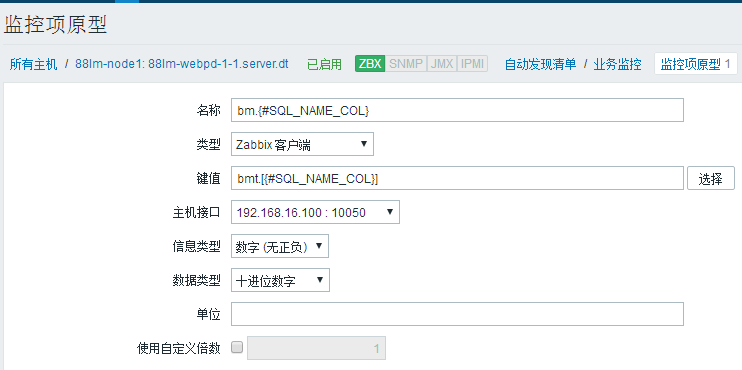
在客户端userParameter配置bmt原型项:
UserParameter=bmt.[*],python /usr/local/zabbix-agent/shell/bm_get_values.py $1
注意 commandType[MEMORY_STATUS, heap.max] zabbix参数用默认,分割
$1 ==> MEMORY_STATUS
$2 ==> heap.max

采用采集器方式

后面应用监控可以通过监控原型扩展预设值来判断业务历史预测值和实际值的偏差
使用采集器可以减轻proxy压力
# 上传监控值
def metric_sender(hostname,itemKeysList):
# args[0]
# 组装成zbx的 item
# sys.exit()
try:
for item in itemKeysList:
packet = [ ZabbixMetric(hostname, "commandType[%s]" % item.keys()[0],item.values()[0]) ]
result = ZabbixSender(zabbix_server=ZABBIX_ENDPOINT,zabbix_port=10051).send(packet)
if result.failed:
logger.error(u"主机上传[%s]上传监控值失败,上传数据[%s],结果[%s]" % (hostname, packet, result))
except IndexError as e:
logger.error(u"IndexError %s [%s]" % e)
except Exception as e:
logger.error(u"%s [%s]" % (hostname,e))
else:
logger.info(u"主机[%s]上传采集值成功" % hostname)
自定义触发器
创建触发器, 告警时会将$1替换成告警阈值

3分钟平均
{test-cif.base-98-13:commandType[MEMORY_STATUS,Usage/Max].avg(3m)}>50
Problem: 最近5分钟剩余磁盘空间小于10GB。(异常)
Recovery: 最近10分钟磁盘空间大于40GB。(恢复)
简单说便是一旦剩余空间小于10G就触发异常,然后接下来剩余空间必须大于40G才能解除这个异常(注意这个表达式,不是>40G哦),就算你剩余空间达到了39G(不在报警条件里)那也是没用的.
TRIGGER.VALUE的意义就在于连接前后的触发器,之后的业务告警也可以尝试用这个方法,可以大大减少告警反复
({TRIGGER.VALUE}=0&{server:vfs.fs.size[/,free].max(5m)}<10G) |
({TRIGGER.VALUE}=1&{server:vfs.fs.size[/,free].min(10m)}<40G)
6次不等于0 的事件,出现4次以上就告警
{88lm-webpd-1-1.server.dt:xmty_balance_acctrans_account.count(#6,0,"ne")}>4
6分钟内,如果最后一次出现strlen >4 那么就成立
{88lm-webpd-1-1.server.dt:bmt.[xmty_message_greater_1k_ACTIVEMQ_MSGS].strlen(,6m)}>4
3个周期内匹配不到N,就报警
{88lm-webpd-1-1.server.dt:bmt.[xmty_message_greater_1k_ACTIVEMQ_MSGS].str(N,#3)}=0
count计数部分
参数:秒或#num 支持类型:float,int,str,text,log 作用:返回指定时间间隔内数值的统计, 举例: count(600)最近10分钟得到值的个数 count(600,12)最近10分钟得到值的个数等于12 count(600,12,"gt")最近10分钟得到值大于12的个数 count(#10,12,"gt")最近10个值中,值大于12的个数 count(600,12,"gt",86400)24小时之前的10分钟内值大于12的个数 count(600,,,86400)24小时之前的10分钟数据值的个数 第一个参数:指定时间段 第二个参数:样本数据 第三个参数:操作参数 第四个参数:漂移参数
支持比较符操作
eq: 相等 ne: 不相等 gt: 大于 ge: 大于等于 lt: 小于 le: 小于等于 like: 内容匹配
日常使用
上行流量最近两次都大于50M告警
{zabbix:net.if.out[em1].count(#2,50M,"gt")}=2
最近30分钟zabbix这个主机超过5次不可到达。
{zabbix:icmpping.count(30m,0)}>5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号