[Linux性能优化]一:CPU - 迁
套路篇
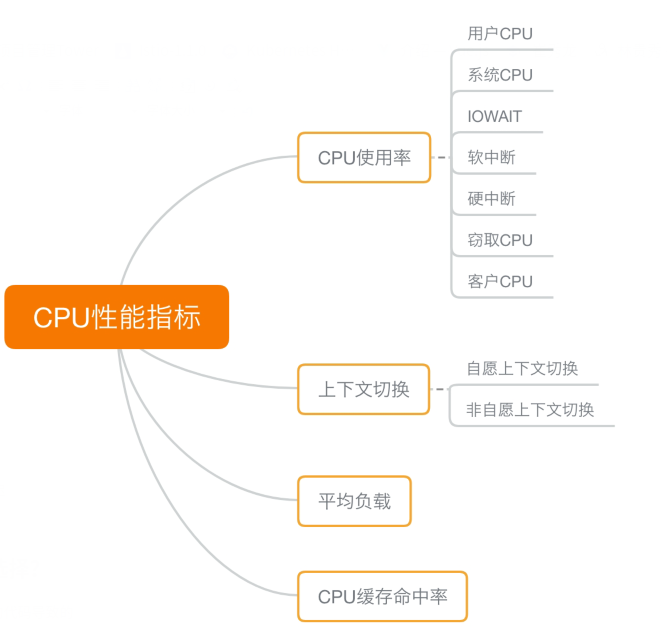
1 CPU性能指标
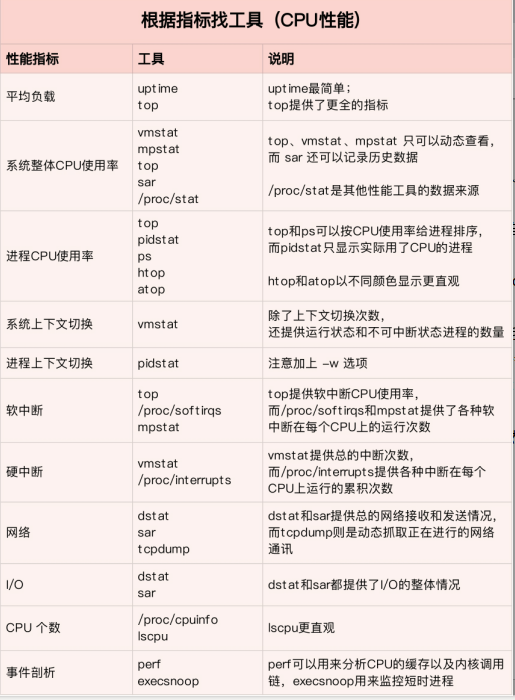
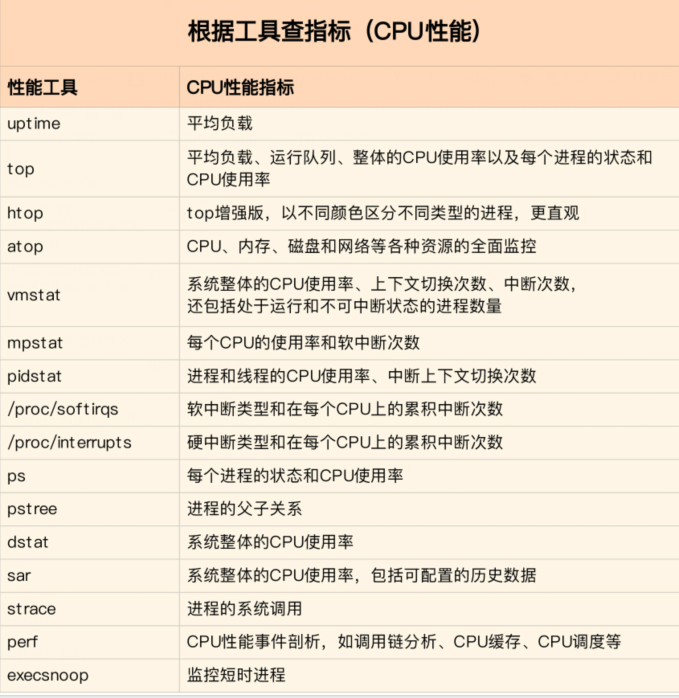
2 性能工具
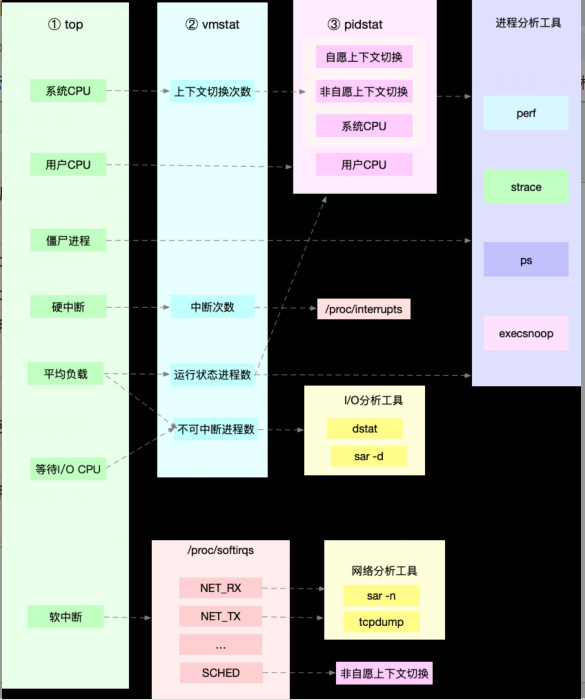
首先,平均负载的案例。我们先用 uptime, 查看了系统的平均负载;而在平均负载升高后,又用 mpstat 和 pidstat ,分别观察了每个 CPU 和每个进程 CPU 的使用情况,进而找出了导致平均负载升高的进程,也就是我们的压测工具 stress。
第二个,上下文切换的案例。我们先用 vmstat ,查看了系统的上下文切换次数和中断次数;然后通过 pidstat ,观察了进程的自愿上下文切换和非自愿上下文切换情况;最后通过 pidstat ,观察了线程的上下文切换情况,找出了上下文切换次数增多的根源,也就是我们的基准测试工具 sysbench。
第三个,进程 CPU 使用率升高的案例。我们先用 top ,查看了系统和进程的 CPU 使用情况,发现 CPU 使用率升高的进程是 php-fpm;再用 perf top ,观察 php-fpm 的调用链,最终找出 CPU 升高的根源,也就是库函数 sqrt() 。
第四个,系统的 CPU 使用率升高的案例。我们先用 top 观察到了系统 CPU 升高,但通过 top 和 pidstat ,却找不出高 CPU 使用率的进程。于是,我们重新审视 top 的输出,又从 CPU 使用率不高但处于 Running 状态的进程入手,找出了可疑之处,最终通过 perf record 和 perf report ,发现原来是短时进程在捣鬼。另外,对于短时进程,我还介绍了一个专门的工具 execsnoop,它可以实时监控进程调用的外部命令。
第五个,不可中断进程和僵尸进程的案例。我们先用 top 观察到了 iowait 升高的问题,并发现了大量的不可中断进程和僵尸进程;接着我们用 dstat 发现是这是由磁盘读导致的,于是又通过 pidstat 找出了相关的进程。但我们用 strace 查看进程系统调用却失败了,最终还是用 perf 分析进程调用链,才发现根源在于磁盘直接 I/O 。
最后一个,软中断的案例。我们通过 top 观察到,系统的软中断 CPU 使用率升高;接着查看 /proc/softirqs, 找到了几种变化速率较快的软中断;然后通过 sar 命令,发现是网络小包的问题,最后再用 tcpdump ,找出网络帧的类型和来源,确定是一个 SYN FLOOD 攻击导致的。
利用top、vmstat和pidstat三个工具,快速定位性能问题:
3 有多个性能问题同时存在,要怎么选择?
广泛使用“二八原则”,就是说80%的问题都是20%的代码导致的
4 有多种优化方法时,要如何选择
- CPU性能优化
- 性能指标: CPU使用率,用户CPU使用率,系统CPU使用率,等待I/O的CPU使用率,软中断和硬中断的CPU使用率
- 平均负载(Load Average) 1 5 15分钟的平均负载,理想情况平均负载等于逻辑CPU个数
- 进程上下文切换 无法获取资源而导致的自愿上下文切换; 被系统强制调用导致的非自愿上下文切换
- CPU缓存的命中率
- 应用程序优化
- 编译器优化
- 算法优化
- 异步处理
- 多线程代替多线程
- 善用缓存
- 系统优化
- CPU绑定
- CPU独占
- 优先级调整
- 为进程设置资源限制
- NUMA优化
- 中断负载均衡
- 千万避免过早优化
- 过早优化是万恶之源
|
1 确定性能的量化指标 2 测试优化前的性能指标 3 测试优化后的性能指标 |
像是 Java 这种通过 JVM 来运行的应用程序,运行堆...
极客时间版权所有: https://time.geekbang.org/column/article/73738

 浙公网安备 33010602011771号
浙公网安备 33010602011771号