自然语言处理 - 如何通俗地理解TFIDF?
本博客属个人学习笔记,如有疏漏,欢迎在评论留言指出~转载请注明。

在自然语言处理中,TFIDF常常被人提及。很多材料都提及TFIDF中的“普遍重要性”,但很少有材料去简单解释其中的原理。TFIDF其实分为两个部分:TF与IDF。
(1)词频 TF
TF即Term Frequency,中文也叫词频。这个相对容易理解。
假设这里给出的文档$d_1$是:
“我有一只超级超级可爱的猫”
那么分词后我们很可能会得到:
['我','有','一只','超级','超级','可爱','的','猫']
我们分别给这些词标上序号与出现次数:
| 词语 | 序号 | 出现次数 |
| 我 | $w_1$ | 1 |
| 有 | $w_2$ | 1 |
| 一只 | $w_3$ | 1 |
| 超级 | $w_4$ | 2 |
| 可爱 | $w_5$ | 1 |
| 的 | $w_6$ | 1 |
| 猫 | $w_7$ | 1 |
不难发现,这个文档中有一共8个词语。
对于'我'(即$w_1$)这个词来说,它在这个文档$d_1$中的词频TF为:$$tf(w_1,d_1) = \frac{1}{8}$$
而对于'超级'(即$w_4$)这个词来说,它在这个文档$d_1$中的词频TF则为:$$tf(w_4,d_1) = \frac{2}{8} = \frac{1}{4}$$
而对于'猫'(即$w_7$)这个词来说,它在这个文档$d_1$中的词频TF则为:$$tf(w_7,d_1) = \frac{1}{8} $$
小结:词频TF的计算公式为$$tf(词语w_i,文档d_j)=tf(w_i, d_j) = \frac{文档d_j中词语w_i出现的次数}{文档d_j中的词语总数}$$
(2) 逆向文档频率 IDF
IDF即Inver Document Frequency,中文也叫逆向文档频率。先不着急理解它的作用~我们先来看看它是怎么算出来的。
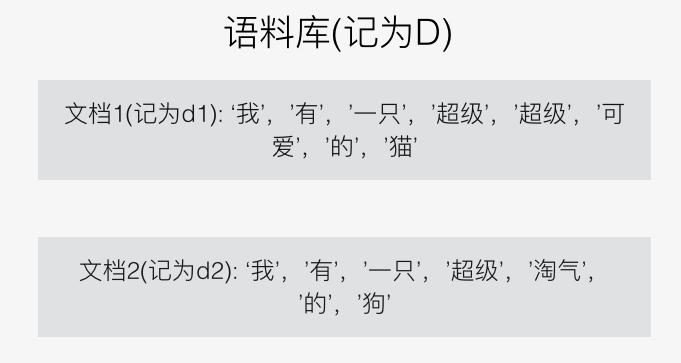
假设我们的语料库(这里我们称它为D)中有两个文档——
文档1:“我有一只超级超级可爱的猫”
文档2:“我有一只超级淘气的狗”
如果我们忘记自己在做自然语言处理,改成用人脑思考这两句话的差别,我们会发现真正有区别的无非是“可爱的猫”和“淘气的狗”。
而“我”,“有”,“一只”,“超级”并没有提供什么关键信息,因此它们并不太重要。“猫”、“狗”、“淘气”、“可爱”才是提供关键信息的词语。
而IDF正是在为我们处理这个问题——
对于“我”这个词而言,它分别在文档1和文档2里各出现了一次——这说明虽然“我”是一个在语料库中非常常见的词,但是它并不对区别语义起到很大的作用,因此它的重要性可能并不是特别高。
对应的,“我”这个词的idf是:$$idf(“我”,语料库D) = log \frac{语料库D中的文档总数}{包含“我”的文档个数} = log \frac{2}{2} = log(1) = 0$$
而对于“猫”这个词而言,它只在文档1中出现过一次。 这说明,它可能对区分文档语义有着重要的作用,因此它的重要性比较大。
对应的,“猫”这个词的idf是:$$idf(“猫”,语料库D) = log\frac{语料库D中的文档总数}{语料库中包含“猫”的文档个数} = log\frac{2}{1} = log(2) $$
注意到,$$log(2) > 0$$可见IDF实际上是为我们筛选了对语义起到重要作用的词语。
小结:逆向文档频率的计算公式为$$idf(词语w,语料库D) = idf(w,D) = \frac{语料库D中的文档总数}{语料库D中包含该词语w的文档个数}$$
(3)TF-IDF
定义:对于语料库D中,文档d包含的一个词w,有TF-IDF为$$tfidf(词语w,文档d,语料库D) = tfidf(w,d,D) = tf(w,d) \dot idf(w,D)$$.
比如说在刚才的例子中,对于不是很重要的“我”:$$tfidf(“我”, d1, D) = tf(“我”,d_1 \dot idf(“我”,D) = \frac{1}{8} \dot 0 = 0$$
而对于比较重要的“猫”:$$tfidf(“猫”, d1, D) = tf(“猫”,d_1 \dot idf(“猫”,D) = \frac{1}{8} \dot log(2) = \frac{log(2)}{8}$$
注意到$\frac{log(2)}{8} > 0$.
假设我把第一个文档$d_1$改为只有“猫”一个词,那么毋庸置疑,对文档$d_1$来说最重要的就是“猫”了。在这个情况下,猫的词频就是1了——乘数的其中一个会变大。
$$tfidf(“猫”, d1, D) = tf(“猫”,d_1 \dot idf(“猫”,D) = 1 \dot log(2) = log(2)$$
注意到$log(2) > \frac{log(2)}{8}$.
这就是为什么,TFIDF可以过滤掉过于常见的词语,以此保证所提取出的词语具有“普遍重要性”。
参考资料:
https://en.wikipedia.org/wiki/Tf%E2%80%93idf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号