
Java中的集合
Java中的集合
- 集合分为:List,Set,Map三种,其中List与Set是继承自Collection,而Map不是。

一、List与Set的区别:
List中的元素有存放顺序,并且可以存放重复元素,检索效率高,插入删除效率低;
Set没有存放顺序,而且不可以存放重复元素,后来的元素会把前面重复的元素替换掉,检索效率低,插入删除效率高。(Set存储位置是由它的HashCode码决定的,所以它存储的对象必须有equals()方法,而且Set遍历只能用迭代,因为它没有下标。)(参考1)
二、ArrayList与LinkList的区别:
ArrayList基层是以数组实现的,可以存储任何类型的数据,但数据容量有限制,超出限制时会扩增50%容量,把原来的数组复制到另一个内存空间更大的数组中,查找元素效率高。ArrayList是一个简单的数据结构,因超出容量会自动扩容,可认为它是常说的动态数组。
LinkedList以双向链表实现,链表无容量限制,但双向链表本身使用了更多空间,每插入一个元素都要构造一个额外的Node对象,也需要额外的链表指针操作。允许元素为null,线程不安全。(参考2)
ArrayList和LinkedList都实现了List接口,LinkedList还额外实现了Deque接口。
综合比较结论:(参考3)
LinkList在增、删数据效率方面要优于ArrayList,而ArrayList在改和查方面效率要远超LinkList。
ArrayList查询直接根据下标查询,而LinkedList需要遍历才能查到元素。增加时直接增加放在队尾,指定位置增加时,数组的元素会往后移动,而链表则需要进行先遍历到指定的位置。
但是,虽然综合比较之下LinkedList的优势要比ArrayList要好,但是在java中,我们用的比较多的确实ArrayList,因为我们的业务通常是对数据的改和查用的比较多。线程是非安全的。
综合比较结论:(参考3)
LinkList在增、删数据效率方面要优于ArrayList,而ArrayList在改和查方面效率要远超LinkList。
ArrayList查询直接根据下标查询,而LinkList需要遍历才能查到元素。增加时直接增加放在队尾,指定位置增加时,数组的元素会往后移动,而链表则需要进行先遍历到指定的位置。
但是,虽然综合比较之下LinkList的优势要比ArrayList要好,但是在java中,我们用的比较多的确实ArrayList,因为我们的业务通常是对数据的改和查用的比较多。线程是非安全的。
三、Map之间的区别
HashMap
数组
数组存储区间连续,占用内存比较严重,空间复杂度很大。但数组的二分查找时间复杂度小,为O(1);
数组的特点是:寻址容易,插入和删除困难;
链表
链表存储区间离散,占用内存比较宽松,空间复杂度很小,但时间复杂度很大,达O(N)。
链表的特点是:寻址困难,插入和删除容易。
HashMap
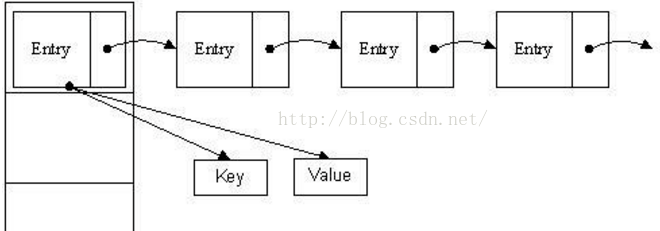
(1.7 数组+链表;1.8 数组+链表+红黑树)是用得最多的一种键值对存储的集合, 用一个数组来存储元素,但是这个数组存储的不是基本数据类型。HashMap实现巧妙的地方就在这里,数组存储的元素是一个Entry类,这个类有三个数据域,key、value(键值对),next(指向下一个Entry) 。
特点:HashMap允许空键值,并且它是非线程安全的,所以插入、删除和定位元素会比较快。
说一下HashMap的put方法
大体流程:
-
根据key通过哈希算法拿到一个HashCode结合与操作,与数组的长度-1进行运算,得到一个数组下标
-
如果得到的数组下标位置元素为空,则将key和value封装成Entry对象(1.7为Entry对象,1.8为Node对象)并放入该位置。
-
如果下标元素不为空,需要分情况讨论
a. 1.7 首先需要判断需不需要扩容,需要的话先扩容,如果不需要扩容则将Key和Value封装成Entry对象,采用头插法插入当前位置链表中。
b. 1.8 需要先判断是红黑树Node还是链表Node
- 如果是红黑树则需要将Key和Value封装成红黑树节点添加到红黑树中,在添加的过程中会判断是否包含节点,如果包含则更新
- 如果是链表则先将Key和Value封装成Node节点,采用尾插法进行插入,如果插入的过程中包含此节点则更新,如果没有则插入到最后。插入完之后如果节点个数大于等于8则转为红黑树存储。
- 插入完成之后则判断是否需要扩容,需要扩容则扩容,不需要则结束PUT方法。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true); //将Key进行hash
}
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) //得到的hashcode与数组长度-1进行与运算 得到一个数组下标
tab[i] = newNode(hash, key, value, null); //元素为空则放入
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Hashcode有什么作用
HashMap 的添加、获取时需要通过 key 的 hashCode() 进行 hash(),然后计算下标 ( n-1 & hash),从而获得要找的同的位置。当发生冲突(碰撞)时,利用 key.equals() 方法去链表或树中去查找对应的节点。
Hash
Hash是散列的意思,就是把任意长度的输入,通过散列算法变换成固定长度的输出,该输出就是散列值。关于散列值,有以下几个关键结论:
- 如果散列表中存在和散列原始输入K相等的记录,那么K必定在f(K)的存储位置上
- 不同关键字经过散列算法变换后可能得到同一个散列地址,这种现象称为碰撞
- 如果两个Hash值不同(前提是同一Hash算法),那么这两个Hash值对应的原始输入必定不同
HashCode
- HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的
- 如果两个对象equals相等,那么这两个对象的HashCode一定也相同
- 如果对象的equals方法被重写,那么对象的HashCode方法也尽量重写
- 如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置
总结
-
hashCode() 在散列表中才有用,在其它情况下没用
-
哈希值冲突了场景,hashCode相等,但equals不等
-
hashcode:计算键的hashcode作为存储键信息的数组下标用于查找键对象的存储位置
-
equals:HashMap使用equals()判断当前的键是否与表中存在的键相同。
-
如果两对象equals()是true,那么它们的hashCode()值一定相等,
-
如果两对象的hashCode()值相等,它们的equals不一定相等(hash冲突啦)
-
TreeMap
是基于红黑树实现的,适用于按自然顺序火兹定于顺序遍历key。
HashTable
是基于HashCode实现的(数组+链表),但它是线程安全的,无论key还是value都不能为null,所以会比HashMap效率低,而且不允许null值。
ConcurrentHashMap
(分段数组+链表),线程安全。
四、Set中最常用的集合:HashSet
HashSet是使用Hash表实现的,集合里面的元素是无序得,可以有null值,但是不能有重复元素。(参考1)
特点:因为相同的元素具有相同的hashCode,所以不能有重复元素
五、线程安全与不安全的集合
线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据。List接口下面有两个实现,一个是ArrayList,另外一个是vector。 从源码的角度来看,因为Vector的方法前加了synchronized 关键字,也就是同步的意思,sun公司希望Vector是线程安全的,而希望arraylist是高效的,缺点就是另外的优点。
ArrayList为什么线程不安全
一个 ArrayList ,在添加一个元素的时候,它可能会有两步来完成: 在 Items[Size] 的位置存放此元素; 增大 Size 的值。
在单线程运行的情况下,如果 Size = 0,添加一个元素后,此元素在位置 0,而且 Size=1;
而如果是在多线程情况下,比如有两个线程,线程 A 先将元素存放在位置 0。但是此时 CPU 调度线程A暂停,线程 B 得到运行的机会。线程B也向此 ArrayList 添加元素,因为此时 Size 仍然等于 0 (注意哦,我们假设的是添加一个元素是要两个步骤哦,而线程A仅仅完成了步骤1),所以线程B也将元素存放在位置0。然后线程A和线程B都继续运行,都增加 Size 的值。 那好,现在我们来看看 ArrayList 的情况,元素实际上只有一个,存放在位置 0,而 Size 却等于 2。这就是“线程不安全”了。
线程安全的工作原理
jvm中有一个main memory对象,每一个线程也有自己的working memory,一个线程对于一个变量variable进行操作的时候, 都需要在自己的working memory里创建一个copy,操作完之后再写入main memory。 当多个线程操作同一个变量variable,就可能出现不可预知的结果。
而用synchronized的关键是建立一个监控monitor,这个monitor可以是要修改的变量,也可以是其他自己认为合适的对象(方法),然后通过给这个monitor加锁来实现线程安全,每个线程在获得这个锁之后,要执行完加载load到working memory 到 use && 指派assign 到 存储store 再到 main memory的过程。才会释放它得到的锁。这样就实现了所谓的线程安全。
安全与不安全的类
Java中提供了很多的集合类,比如ArrayList、LinkedList、HashMap...等,集合类内部采用了诸多的方式进行存储这些数据,目的是能够让增删改查某些操作更快一些,不同的存储方式被称作数据结构。因为这些不同的存储方式,导致了增删改查效率的不同。
数据结构:容器存储数据,管理数据的一种方式,数据结构常用的包括数组、链表、哈希表、树。
- ArrayList主要是用数组来存储元素,LinkedList主要是用链表来存储元素,HashMap的底层实现主要是借助数组+链表+红黑树来实现。
- Vector、HashTable、Properties等集合类效率比较低但都是线程安全的。包java.util.concurrent下包含了大量线程安全的集合类,效率上有较大提升。
- CopyOnWriteArrayList 线程安全,适用于读转写操作,每次操作时会复制一个新的List,在新的List上进行写操作,操作完成之后,再将原来的List指向新的List。线程安全地遍历,因为如果另外一个线程在遍历的时候修改List的话,实际上会拷贝出一个新的List上修改,而不影响当前正在被遍历的List。
- ConcurrentLinkedQueue 线程安全,是一个基于链接节点的、无界的、线程安全的队列。此队列按照 FIFO(先进先出)原则对元素进行排序,队列的头部 是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。新的元素插入到队列的尾部,队列检索操作从队列头部获得元素。当许多线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择,此队列不允许 null 元素。
- ConcurrentHashMap 线程安全 分段数组+链表,采用了分段锁的设计, 将一个HashMap分成N段,使用key的hashCode来确定分配到那个字段,只有在同一分段内才存在竞态关系,每个分段相当于一个HashTable,执行效率相当于提升了N倍。
- ArrayList、LinkedList、HashSet、TreeSet、HashMap、TreeMap等都是线程不安全的。(线程不安全是指:当多个线程访问同一个集合或Map时,如果有超过一个线程修改了ArrayList集合,则程序必须手动保证该集合的同步性。)
六、集合的遍历
-
for循环遍历,基于计数器
遍历者自己在集合外部维护一个计数器,然后依次读取每一个位置的元素,当读取到最后一个元素后,停止。主要就是需要按元素的位置来读取元素。
因为是基于元素的位置,按位置读取。所以我们可以知道,对于顺序存储,因为读取特定位置元素的平均时间复杂度是O(1),所以遍历整个集合的平均时间复杂度为O(n)。而对于链式存储,因为读取特定位置元素的平均时间复杂度是O(n),所以遍历整个集合的平均时间复杂度为O(n2)(n的平方)。
for (int i = 0; i < list.size(); i++) { list.get(i); } -
迭代器遍历
Iterator本来是OO的一个设计模式,主要目的就是屏蔽不同数据集合的特点,统一遍历集合的接口。Java作为一个OO语言,自然也在Collections中支持了Iterator模式。
那么对于RandomAccess类型的集合来讲,没有太多意义,反而由于一些额外的操做,还会增长额外的运行时间。可是对于Sequential Access的集合来讲,就有很重大的意义了,由于Iterator内部维护了当前遍历的位置,因此每次遍历,读取下一个位置并不须要从集合的第一个元素开始查找,只要把指针向后移一位就好了,这样一来,遍历整个集合的时间复杂度就下降为O(n);
Iterator iterator = list.iterator(); while (iterator.hasNext()) { iterator.next(); } -
foreach循环遍历
屏蔽了显式声明的Iterator和计数器。分析Java字节码可知,foreach内部实现原理,也是经过Iterator实现的,只不过这个Iterator是Java编译器帮咱们生成的,因此咱们不须要再手动去编写。可是由于每次都要作类型转换检查,因此花费的时间比Iterator略长。时间复杂度和Iterator同样。
优点:代码简洁,不易出错。
缺点:只能做简单的遍历,不能在遍历过程中操作(删除、替换)数据集合。
for (ElementType element : list) { } -
遍历map (也可以使用迭代)
Map<Integer, Integer> map = new HashMap<Integer, Integer>(); //遍历map中的键 for (Integer key : map.keySet()) { System.out.println("Key = " + key); } //遍历map中的值 for (Integer value : map.values()) { System.out.println("Value = " + value); }
七、针对ArrayList的操作
- List 包含的方法
-
add(Object element): 向列表的尾部添加指定的元素。
-
size(): 返回列表中的元素个数。
-
get(int index): 返回列表中指定位置的元素,index从0开始。
-
add(int index, Object element): 在列表的指定位置插入指定元素。
-
set(int i, Object element): 将索引i位置元素替换为元素element并返回被替换的元素。
-
clear(): 从列表中移除所有元素。
-
isEmpty():判断列表是否包含元素,不包含元素则返回 true,否则返回false。
-
contains(Object o): 如果列表包含指定的元素,则返回 true。
-
remove(int index): 移除列表中指定位置的元素,并返回被删元素。
-
remove(Object o): 移除集合中第一次出现的指定元素,移除成功返回true,否则返回false。
-
iterator(): 返回按适当顺序在列表的元素上进行迭代的迭代器。
-
排序
Collections.sort(list); //针对一个ArrayList内部的数据排序 如果想自定义排序方式则需要有类来实现Comparator接口并重写compare方法 调用sort方法时将ArrayList对象与实现Commparator接口的类的对象作为参数 -- 调用 Collections.sort(list, new SortByAge()); -- 实现接口 class SortByAge implements Comparator { public int compare(Object o1, Object o2) { Student s1 = (Student) o1; Student s2 = (Student) o2; return s1.getAge().compareTo(s2.getAge()); } } 注:compareTo方法比较字符串,但是也可以比较数字(数字为String类型) 原理:先比较字符串长度,再逐一转成char类型去比较字符串里的每一个字符。 -
遍历
-- for循环的遍历方式 for (int i = 0; i < lists.size(); i++) { System.out.print(lists.get(i)); } -- foreach的遍历方式 for (Integer list : lists) { System.out.print(list); } -- Iterator的遍历方式 for (Iterator list = lists.iterator(); list.hasNext();) { System.out.print(list.next()); } -
删除
lists.remove(6); //指定删除 List 删除元素的逻辑是将目标元素之后的元素往前移一个索引位置, 最后一个元素置为 null,同时 size - 1。 遍历删除时,操作不当会导致异常, 原因:ArrayList 中两个 remove() 方法都对 modCount 进行了自增, 那么我们在用迭代器迭代的时候,若是删除末尾 的元素, 则会造成 modCount 和 expectedModCount 的不一致导致异常抛出。 Iterator 迭代遍历删除是最安全的方法。(参考4) -- 示例: public static void remove(List list, String target){ Iterator iter = list.iterator(); while (iter.hasNext()) { String item = iter.next(); if (item.equals(target)) { iter.remove(); } } System.out.println(list); } -
去重(参考6)
-
利用HashSet(不保证元素顺序一致)
-
利用LinkedHashSet (去重后顺序一致),继承的父类HashSet
参考资料
- Java中的几种集合的区别及适用场景
- Java集合之ArrayList与LinkList
- Java中ArrayList与LinkList比较
- ArrayList中元素的删除操作
- ArrayList常用方法总结
- ArrayList去重
- 讲讲HashCode的作用
- HashMap原理详解
- JAVA中常用的高级集合类总结(包含Concurrent包下的并发集合类)
- Java线程(十四):Concurrent包中强大的并发集合类
- 线程安全,为什么说ArrayList,LinkedList是线程不安全的,以及CopyOnWriteArrayList和vector为什么安全
- 常用集合类简介及线程安全和非线程安全的集合对象
- Java遍历集合的几种方法分析(实现原理、算法性能、适用场合)
- Map集合的五种遍历方式及Treemap方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号