前端进化史
来源https://www.cnblogs.com/brancepeng/p/5383254.html
https://blog.csdn.net/z591102/article/details/106162047/
前端进化史
突然好奇前端的历史由来。记录下来。
这是一个众所周知的故事。说来好笑:如今奠定前端基石的javascript这门语言刚开始被开发出来时仅仅是为了处理以前有服务器端语言负责的一些输入验证操作。次年,Netscape公司就发布了浏览器端语言javascript,并且向ecma国际提交了将该javascript作为工业化标准的申请,逐渐的便有了ECMAScript这个标准。ECMA-262的第三版在1999年12月发布。在2009年1月,旨在为javascript离开浏览器端开发而建立的一套共同的标准库而成立的项目CommonJs产生,而且目前是作为最好的后端编程语言之一。
前端开发技术,从狭义看就是围绕HTML,css,javascript的这样一套体系的开发技术。它的运行宿主是浏览器。从前端技术的发展来看:大致分为以下几个阶段:
一.刀耕火种
最早的了web界面主要是用来浏览的,主要以html为主,最多加点javascript脚本填写表单并且提交。这个时候的css也用的比较少。
几个例子:
<html> <head> <title>测试二</title> </head> <body> <input id="firstNameInput" type="text" /> <input id="lastNameInput" type="text" /> <input type="button" onclick="greet()" /> <script language="JavaScript"> function greet() { var firstName = document.getElementById("firstNameInput").value; var lastName = document.getElementById("lastNameInput").value; alert("Hello, " + firstName + "." + lastName); } </script> </body> </html>
但是由于静态页面不能实现保存数据等功能,出现了很多服务端技术,早起的有CGI,ASP,JSP,PHP等等。有了这类技术,在HTML中就可以使用表单的post功能提交数据了,比如:
<form method="post" action="username.asp"> <p>First Name: <input type="text" name="firstName" /></p> <p>Last Name: <input type="text" name="lastName" /></p> <input type="submit" value="Submit" /> </form>
在这个阶段,由于客户端和服务端的职责未作明确的划分,比如生成一个字符串,可以由前端的JavaScript做,也可以由服务端语言做,所以通常在一个界面里,会有两种语言混杂在一起,用<%和%>标记的部分会在服务端执行,输出结果,甚至经常有把数据库连接的代码跟页面代码混杂在一起的情况,给维护带来较大的不便。
<html> <body> <p>Hello world!</p> <p> <% response.write("Hello world from server!") %> </p> </body> </html>
组件化的萌芽:
这个时代,也逐渐出现了组件化的萌芽。比较常见的有服务端的组件化,比如把某一类服务端功能单独做成片段,然后其他需要的地方来include进来,典型的有:ASP里面数据库连接的地方,把数据源连接的部分写成conn.asp,然后其他每个需要操作数据库的asp文件包含它。
上面所说的是在服务端做的,浏览器端通常有针对JavaScript的,把某一类的Javascript代码写到单独的js文件中,界面根据需要,引用不同的js文件。针对界面的组件方式,通常利用frameset和iframe这两个标签。某一大块有独立功能的界面写到一个html文件,然后在主界面里面把它当作一个frame来载入,一般的B/S系统集成菜单的方式都是这样的。
此外,还出现了一些基于特定浏览器的客户端组件技术,比如IE浏览器的HTC(HTML Component)。这种技术最初是为了对已有的常用元素附加行为的,后来有些场合也用它来实现控件。微软ASP.net的一些版本里,使用这种技术提供了树形列表,日历,选项卡等功能。HTC的优点是允许用户自行扩展HTML标签,可以在自己的命名空间里定义元素,然后,使用HTML,JavaScript和CSS来实现它的布局、行为和观感。这种技术因为是微软的私有技术,所以逐渐变得不那么流行。
Firefox浏览器里面推出过一种叫XUL的技术,也没有流行起来。
二.铁器时代
这个时代典型特征就是Ajax的出现。
1.Ajax
AJAX其实是一系列已有技术的组合,早在这个名词出现之前,这些技术的使用就已经比较广泛了,Gmail因为恰当地应用了这些技术,获得了很好的用户体验。
由于Ajax的出现,规模更大,效果更好的Web程序逐渐出现,在这些程序中,JavaScript代码的数量迅速增加。出于代码组织的需要,“JavaScript框架”这个概念逐步形成,当时的主流是prototype和mootools,这两者各有千秋,提供了各自方式的面向对象组织思路。
2.javascript基础库
Prototype框架主要是为JavaScript代码提供了一种组织方式,对一些原生的JavaScript类型提供了一些扩展,比如数组、字符串,又额外提供了一些实用的数据结构,如:枚举,Hash等,除此之外,还对dom操作,事件,表单和Ajax做了一些封装。
Mootools框架的思路跟Prototype很接近,它对JavaScript类型扩展的方式别具一格,所以在这类框架中,经常被称作“最优雅的”对象扩展体系。
从这两个框架的所提供的功能来看,它们的定位是核心库,在使用的时候一般需要配合一些外围的库来完成。
jQuery与这两者有所不同,它着眼于简化DOM相关的代码。 例如:
$("*") //选取所有元素
$("#lastname") //选取id为lastname的元素
$(".intro") //选取所有class="intro"的元素
$("p") //选取所有<p>元素
$(".intro.demo") //选取所有 class="intro"且class="demo"的元素
- DOM的选择
jQuery提供了一系列选择器用于选取界面元素,在其他一些框架中也有类似功能,但是一般没有它的简洁、强大。
链式表达式:
在jQuery中,可以使用链式表达式来连续操作dom,比如下面这个例子:如果不使用链式表达式,可能我们需要这么写:
var neat = $("p.neat"); neat.addClass("ohmy"); neat.show("slow"); //有了链式表达式,就可以这样一行代码完成; $("p.neat").addClass("ohmy").show("slow");
除此之外,jQuery还提供了一些动画方面的特效代码,也有大量的外围库,比如jQuery UI这样的控件库,jQuery mobile这样的移动开发库等等。
3.模块代码加载方式:
以上这些框架提供了代码的组织能力,但是未能提供代码的动态加载能力。动态加载JavaScript为什么重要呢?因为随着Ajax的普及,jQuery等辅助库的出现,Web上可以做很复杂的功能,因此,单页面应用程序(SPA,Single Page Application)也逐渐多了起来。单个的界面想要做很多功能,需要写的代码是会比较多的,但是,并非所有的功能都需要在界面加载的时候就全部引入,如果能够在需要的时候才加载那些代码,就把加载的压力分担了,在这个背景下,出现了一些用于动态加载JavaScript的框架,也出现了一些定义这类可被动态加载代码的规范。
在这些框架里,知名度比较高的是RequireJS,它遵循一种称为AMD(Asynchronous Module Definition)的规范。
比如下面这段,定义了一个动态的匿名模块,它依赖math模块:
define(["math"], function(math) { return { addTen : function(x) { return math.add(x, 10); } }; }); //假设上面的代码存放于adder.js中,当需要使用这个模块的时候,通过如下代码来引入adder: <script src="require.js"></script> <script> require(["adder"], function(adder) { //使用这个adder }); </script>
三.工业革命
这个时期,随着Web端功能的日益复杂,人们开始考虑这样一些问题:
1.如何更好的模块化开发;
2.业务数据如何组织;
3.界面和业务数据之间通过何种方式进行交互。
在这种背景下,出现了一些前端MVC、MVP、MVVM框架,我们把这些框架统称为MV*框架。这些框架的出现,都是为了解决上面这些问题,具体的实现思路各有不同,主流的有Backbone,AngularJS,Ember,Spine等等,下篇主要选用Backbone和AngularJS来讲述一些相关场景。
目前来说,引入前端框架已经是大势所趋了,很多时候后端的一些数据处理都转移给了前端去完成,特别是在REST模式下。
什么是前端框架?引入前端框架的契机是什么?
当前端从web page变成web app,就需要前端框架了,web page 以表现为主,web app以应用为主。现在我们在 web 上,已经不仅仅是去看了,我们更多的时候是去用。
前端框架的使用,让不断刷新从服务器获得静态页面的流程 变成了纯粹的客户端对服务端的请求数据-组织数据-显示数据的流程 。
1.数据模型
在这一块,我想插入一些面向对象的思想。
什么是面向对象?
面向对象编程:简称就是OOP(Object Oriented Programming)。它把对象当做程序的基本单元,一个对象包括数据和操作数据的函数。
面向过程的程序设计把计算机程序视为一系列的命令集合,即一组函数的顺序执行。为了简化程序设计,面向过程把函数继续切分为子函数,即把大块函数通过切割成小块函数来降低系统的复杂度。
而面向对象的程序设计把计算机程序视为一组对象的集合,而每个对象都可以接收其他对象发过来的消息,并处理这些消息,计算机程序的执行就是一系列消息在各个对象之间传递。(总的宗旨就是:你办事我放心!)这也是一个很好的鉴别一个面向对象的设计是否正确的方法。一个好的面向对象设计,会让你让他办事的时候,你不得不放心(也就是说,你不放心也没用,反正你什么都不知道)。
面向对象的设计思想是从自然界中来的,因为在自然界中,类(Class)和实例(Instance)的概念是很自然的。Class是一种抽象概念,比如我们定义的Class——Student,是指学生这个概念,而实例(Instance)则是一个个具体的Student,比如,Bart Simpson和Lisa Simpson是两个具体的Student:
所以,面向对象的设计思想是抽象出Class,根据Class创建Instance。
面向对象的抽象程度又比函数要高,因为一个Class既包含数据,又包含操作数据的方法。
这里产生一个问题:如何理解js中的数据模型?(...后面会介绍)
在这些框架里,定义数据模型的方式与以往有些差异,主要在于数据的get和set更加有意义了,比如说,可以把某个实体的get和set绑定到RESTful的服务上,这样,对某个实体的读写可以更新到数据库中。另外一个特点是,它们一般都提供一个事件,用于监控数据的变化,这个机制使得数据绑定成为可能。
在一些框架中,数据模型需要在原生的JavaScript类型上做一层封装,比如Backbone的方式是这样:
//下面是backboneJs的定义数据模型的方式; var Todo = Backbone.Model.extend({ // Default attributes for the todo item. defaults : function() { return { title : "empty todo...", order : Todos.nextOrder(), done : false }; }, // Ensure that each todo created has `title`. initialize : function() { if (!this.get("title")) { this.set({ "title" : this.defaults().title }); } }, // Toggle the 'done' state of this todo item. toggle : function() { this.save({ done : !this.get("done") }); } });
上述例子中,defaults方法用于提供模型的默认值,initialize方法用于做一些初始化工作,这两个都是约定的方法,toggle是自定义的,用于保存todo的选中状态。
数据模型也可以包含一些方法,比如自身的校验,或者跟后端的通讯、数据的存取等等,在上面例子中,也有体现一些。
2.控制器
控制器是模型和视图之间的纽带。控制器从视图获得事件和输入,对它们进行处理(很可能包含模型),并相应地更新视图。当页面加载时,控制器会给视图添加事件监听,比如监听表单提交或按钮点击。然后,当用户和应用产生交互时,控制器中的事件触发器就开始工作了。很典型的,在controller中定义表单的提交事件或者点击事件。
下面用Jquery实现一个例子:
var Controller = {}; // 使用匿名函数来封装一个作用域 (Controller.users = function($){ var nameClick = function(){ /* ... */ }; // 在页面加载时绑定事件监听 $(function(){ $("#view .name").click(nameClick); }); })(jQuery); 上面的代码创建了user控制器,这个控制器是放在controller变量下的命名空间。然后用匿名函数封装了作用域,防止对全局作用域污染。
当页面加载时,程序给视图元素绑定了点击事件的监听。
3.视图
双向绑定
- 改变模型可以随时反映到界面上
- 在界面上做的操作(输入,选择等等)可以实时反映到模型里。
而且,这种绑定都会自动忽略其中可能因为空数据而引起的异常情况。
4.模板
模板是这个时期一种很典型的解决方案。来个场景:在一个界面上重复展示类似的DOM片段,例如微博,
iv class="post" ng-repeat="post in feeds">
<div class="author">
<a ng-href="/user.html?user={{post.creatorName}}">@{{post.creatorName}}</a>
</div>
<div>{{post.content}}</div>
<div>
发布日期:{{post.postedTime | date:'medium'}}
</div>
</div>
5.路由
通常路由是定义在后端的,但是在这类MV*框架 的帮助下,路由可以由前端来解析执行。
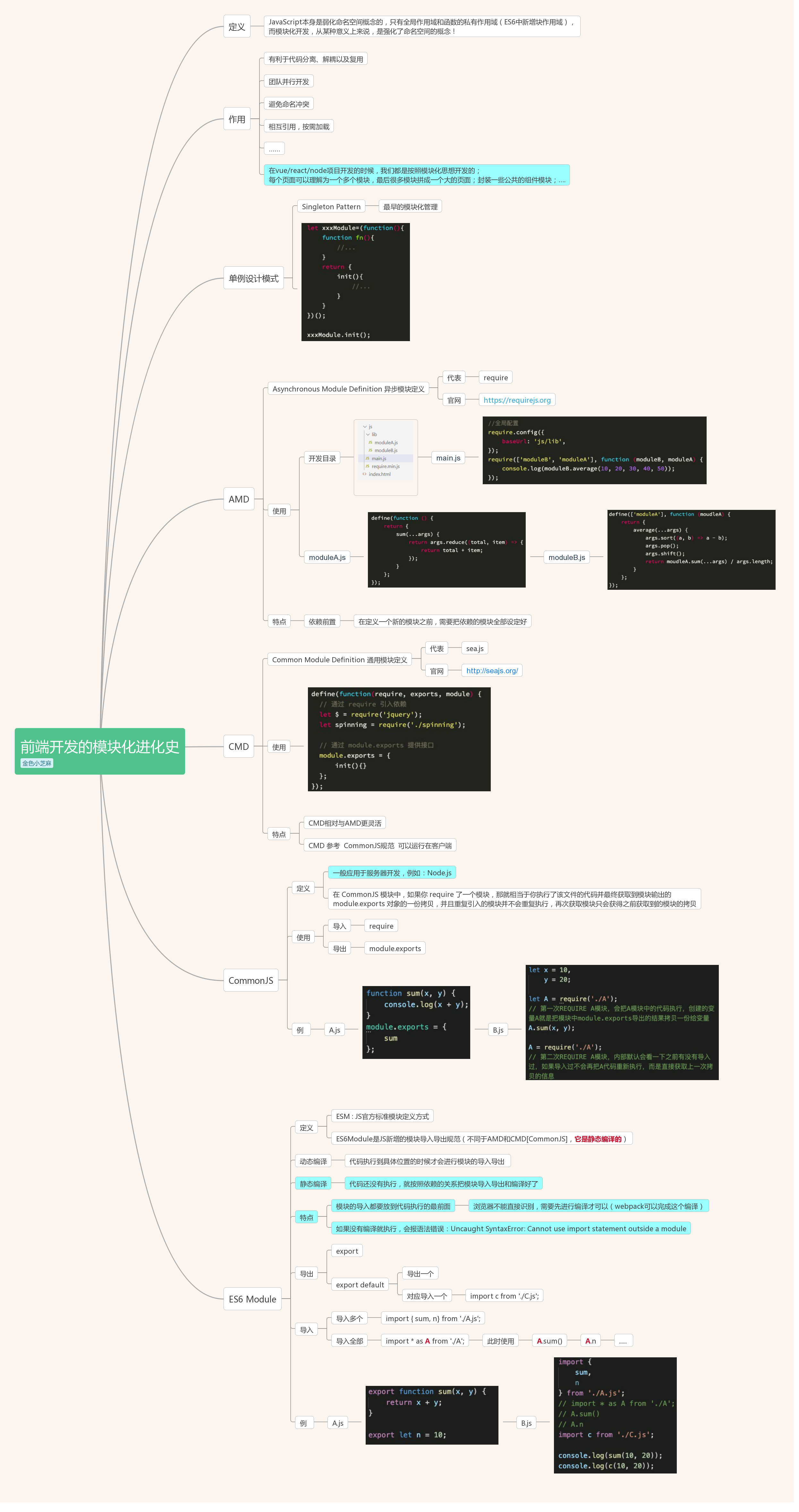
模块化演进过程
模块化的几个代表阶段
1. 文件划分方式
最早我们会基于文件划分的方式实现模块化,也就是 Web 最原始的模块系统。具体做法是将每个功能及其相关状态数据各自单独放到不同的 JS 文件中,约定每个文件是一个独立的模块。使用某个模块将这个模块引入到页面中,一个 script 标签对应一个模块,然后直接调用模块中的成员(变量 / 函数)。
// module-a.js function foo () { console.log('moduleA#foo') } // module-b.js var data = 'something' //结合 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> </head> <body> <script src="module-a.js"></script> <script src="module-b.js"></script> <script> // 直接使用全局成员 foo() // 可能存在命名冲突 console.log(data) data = 'other' // 数据可能会被修改 </script> </body> </html>
缺点:
模块直接在全局工作,大量模块成员污染全局作用域;
没有私有空间,所有模块内的成员都可以在模块外部被访问或者修改;
一旦模块增多,容易产生命名冲突;
无法管理模块与模块之间的依赖关系;
在维护的过程中也很难分辨每个成员所属的模块。
总之,这种原始“模块化”的实现方式完全依靠约定实现,一旦项目规模变大,这种约定就会暴露出种种问题,非常不可靠,所以我们需要尽可能解决这个过程中暴露出来的问题。
2. 命名空间方式
后来,我们约定每个模块只暴露一个全局对象,所有模块成员都挂载到这个全局对象中,通过将每个模块“包裹”为一个全局对象的形式实现,这种方式就好像是为模块内的成员添加了“命名空间”,所以我们又称之为命名空间方式。
// module-a.js window.moduleA = { method1: function () { console.log('moduleA#method1') } } // module-b.js window.moduleB = { data: 'something' method1: function () { console.log('moduleB#method1') } }
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> </head> <body> <script src="module-a.js"></script> <script src="module-b.js"></script> <script> moduleA.method1() moduleB.method1() // 模块成员依然可以被修改 moduleA.data = 'foo' </script> </body> </html>
这种命名空间的方式只是解决了命名冲突的问题,但是其它问题依旧存在。
3. IIFE
使用立即执行函数表达式(IIFE,Immediately-Invoked Function Expression)为模块提供私有空间。具体做法是将每个模块成员都放在一个立即执行函数所形成的私有作用域中,对于需要暴露给外部的成员,通过挂到全局对象上的方式实现。
// module-a.js (function () { var name = 'module-a' function method1 () { console.log(name + '#method1') } window.moduleA = { method1: method1 } })()
// module-b.js (function () { var name = 'module-b' function method1 () { console.log(name + '#method1') } window.moduleB = { method1: method1 } })()
这种方式带来了私有成员的概念,私有成员只能在模块成员内通过闭包的形式访问,这就解决了前面所提到的全局作用域污染和命名冲突的问题。
4.IIFE 依赖参数
在 IIFE 的基础之上,我们还可以利用 IIFE 参数作为依赖声明使用,这使得每一个模块之间的依赖关系变得更加明显。
// module-a.js ;(function ($) { // 通过参数明显表明这个模块的依赖 var name = 'module-a' function method1 () { console.log(name + '#method1') $('body').animate({ margin: '200px' }) } window.moduleA = { method1: method1 } })(jQuery)
模块化规范
以上解决了模块代码的组织问题,但模块加载的问题却被忽略了。
我们都是通过 script 标签的方式直接在页面中引入的这些模块,这意味着模块的加载并不受代码的控制,时间久了维护起来会十分麻烦。
模块化规范的出现
提到模块化规范,可能会想到 CommonJS 规范(它是 Node.js 中所遵循的模块规范)。该规范约定以同步的方式加载模块,一个文件就是一个模块,每个模块都有单独的作用域,通过 module.exports 导出成员,再通过 require 函数载入模块。
因为 Node.js 执行机制是在启动时加载模块,执行过程中只是使用模块,所以这种方式不会有问题。如果要在浏览器端使用同步的加载模式,就会引起大量的同步模式请求,导致应用运行效率低下。
所以在早期制定前端模块化标准时,并没有直接选择 CommonJS 规范,而是专门为浏览器端重新设计了一个规范,叫做 AMD ( Asynchronous Module Definition) 规范,即异步模块定义规范。(同期还推出了一个非常出名的库,叫做 Require.js,它除了实现了 AMD 模块化规范,本身也是一个非常强大的模块加载器)
在 AMD 规范中约定每个模块通过 define() 函数
定义,这个函数默认可以接收两个参数,第一个参数是一个数组,用于声明此模块的依赖项;第二个参数是一个函数,参数与前面的依赖项一一对应,每一项分别对应依赖项模块的导出成员,这个函数的作用就是为当前模块提供一个私有空间。如果在当前模块中需要向外部导出成员,可以通过 return 的方式实现。
模块化的标准规范
随着技术的发展,JavaScript 的标准逐渐走向完善,可以说,如今的前端模块化已经发展得非常成熟了,而且对前端模块化规范的最佳实践方式也基本实现了统一。
在 Node.js 环境中,我们遵循 CommonJS 规范来组织模块。
在浏览器环境中,我们遵循 ES Modules 规范。
因为 CommonJS 属于内置模块系统,所以在 Node.js 环境中使用时不存在环境支持问题,只需要直接遵循标准使用 require 和 module 即可。(在最新的 Node.js 提案中表示,Node 环境也会逐渐趋向于 ES Modules 规范)
但是对于 ES Modules 规范来说,情况会相对复杂一些。我们知道 ES Modules 是 ECMAScript 2015(ES6)中才定义的模块系统,也就是说它是近几年才制定的标准,所以肯定会存在环境兼容的问题。在这个标准刚推出的时候,几乎所有主流的浏览器都不支持。但是随着 Webpack 等一系列打包工具的流行,这一规范才开始逐渐被普及。
思维导图
个人

 浙公网安备 33010602011771号
浙公网安备 33010602011771号