

机器学习7逻辑回归实践
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
(1)增加样本量(通用)
(2)数据正则化
(3)通过特征选择,剔除一些不重要的特征,从而降低模型复杂度。
(4)如果还过拟合,那就看看是否使用了过度复杂的特征构造工程
(5)检查业务逻辑,判断特征有效性,是否在用结果预测结果等。
(6)逻辑回归特有的防止过拟合方法:进行离散化处理,所有特征都离散化。
2.用logiftic回归来进行实践操作,数据不限。
from sklearn import datasets from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report #载入鸢尾花数据集 data = datasets.load_iris() x = data['data'] y = data['target']
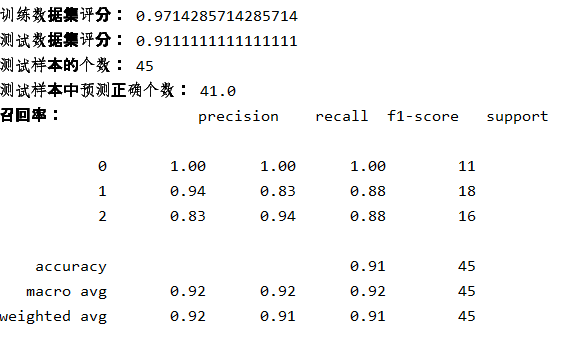
#划分训练集 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3) LR_model = LogisticRegression() # 构建逻辑回归模型 LR_model.fit(x_train, y_train) # 训练模型 pre = LR_model.predict(x_test) # 预测模型 print('训练数据集评分:', LR_model.score(x_train, y_train)) print('测试数据集评分:', LR_model.score(x_test, y_test)) print('测试样本的个数:',x_test.shape[0]) print('测试样本中预测正确个数:',x_test.shape[0]*LR_model.score(x_test,y_test)) print("召回率:", classification_report(y_test, pre))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号