elasticsearch ES使用文档
1. 先说需求
有一批医疗数据,需要搭建搜索引擎数据库,按照之前的管理,我优先选择了python的whoosh,毕竟对自己熟悉的东西会最先使用
同时,对ES不是特别了解,用whoosh搭建了数据库
问题:
由于数据有几个G,数据量巨大,导致whoosh在用的时候,内存溢出,MemoryError。故此,我决定改用ES
2. ES使用文档
参考: es文档 搭建 https://blog.csdn.net/zhezhebie/article/details/105482149 https://www.jianshu.com/p/da3c3612686a 下载 https://elasticsearch.cn/download/ 使用 https://blog.csdn.net/diyiday/article/details/82153780 配置文件 https://www.cnblogs.com/hanyouchun/p/5163183.html 文件位置: /etc/elasticsearch/elasticsearch.yml 创建索引有问题: 400, 'mapper_parsing_exception', 'Root mapping definition has unsupported parameters: 解决方案: https://blog.csdn.net/h_sn9999/article/details/102767040 统计总数据量 https://blog.csdn.net/whq12789/article/details/101062968
下载ES,这里我选择了最新版的
本地的下载速度比服务器下载的还快,需要等很久,我等了1h
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.0-x86_64.rpm
搭建rmp,我选择直接在服务器直接搭建
rpm -Uvh /路径/es_64位.rpm
systemctl enable elasticsearch 开机自启动
systemctl start elasticsearch 启动
systemctl status elasticsearch 启动
查看日志
/var/log/elas.../elas....log 日志文件
修改配置文件
ES拒绝你连接, 怎么办,修改配置文件
ES默认端口
9300端口: ES节点之间通讯使用
9200端口: ES节点 和 外部 通讯使用
9300是TCP协议端口号,ES集群之间通讯端口号
9200端口号,暴露ES RESTful接口端口号
修改配置文件
node.name: node-1 cluster.initial_master_nodes: ["node-1"] path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 http.port: 5000 discovery.seed_hosts: ["127.0.0.1"]
陈总的配置文件
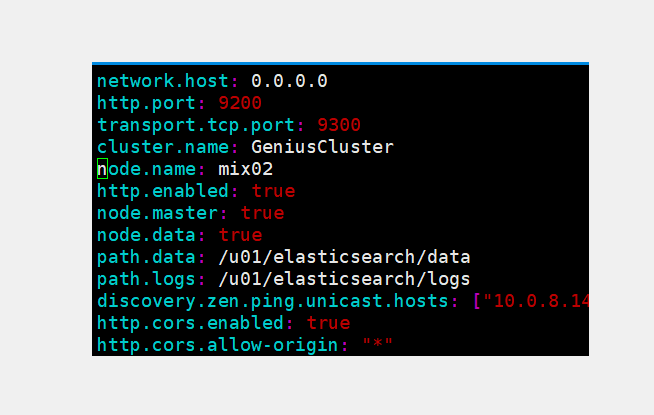
修改ES host主机报错
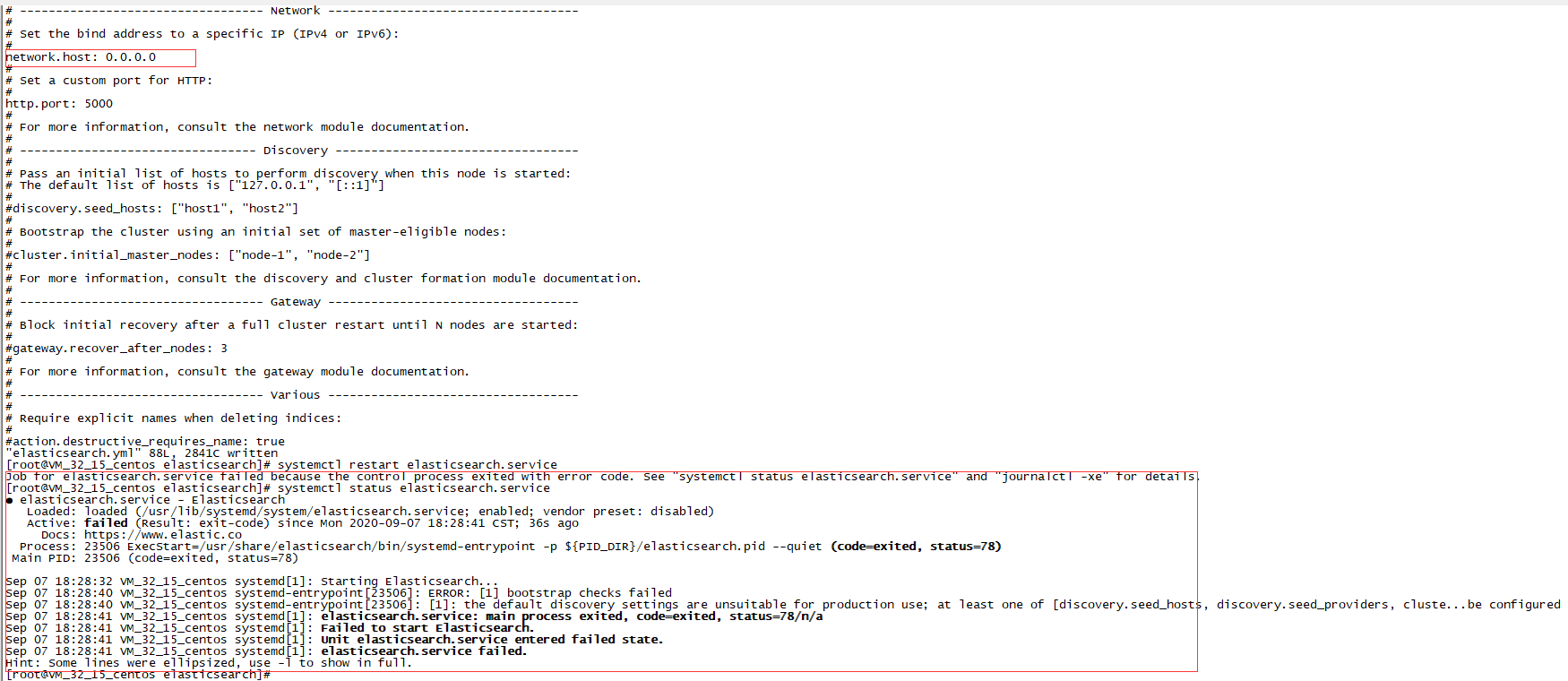
看日志

at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
按照上面配置文件修改就可以解决
使用ES
#!/usr/bin/env python # -*- coding:utf-8 -*- from elasticsearch import Elasticsearch es = Elasticsearch(["ip:5000"]) # journal-ref, report-no # journal_ref, report_no # columnName = ['id', 'submitter', 'authors', 'title', 'comments', 'journal_ref', 'doi', 'report_no', 'categories', # 'license', 'abstract', 'versions', 'update_date', 'authors_parsed'] mappings = { 'mappings': { 'type_doc_test': { 'properties': { 'id': { 'type': 'text', }, 'submitter': { 'type': 'text', }, 'authors': { 'type': 'text', }, 'title': { 'type': 'text', }, 'comments': { 'type': 'text', }, 'journal_ref': { 'type': 'text', }, 'doi': { 'type': 'text', }, 'report_no': { 'type': 'text', }, 'categories': { 'type': 'text', }, 'license': { 'type': 'text', }, 'abstract': { 'type': 'text', }, 'versions': { 'type': 'text', }, 'update_date': { 'type': 'text', }, 'authors_parsed': { 'type': 'text', } } } } } mappings_1 = { # 这个是7版本的方法,上面那个是6版本的方法 'mappings': { 'properties': { 'id': { 'type': 'text', }, 'submitter': { 'type': 'text', }, 'authors': { 'type': 'text', }, 'title': { 'type': 'text', }, 'comments': { 'type': 'text', }, 'journal_ref': { 'type': 'text', }, 'doi': { 'type': 'text', }, 'report_no': { 'type': 'text', }, 'categories': { 'type': 'text', }, 'license': { 'type': 'text', }, 'abstract': { 'type': 'text', }, 'versions': { 'type': 'text', }, 'update_date': { 'type': 'text', }, 'authors_parsed': { 'type': 'text', } } } } res = es.indices.create(index="index_test", body=mappings_1)
具体可以参考链接:
Root mapping definition has unsupported parameters: [product : {properties={title={type=text}}}
https://blog.csdn.net/h_sn9999/article/details/102767040
写入数据
#!/usr/bin/env python # -*- coding:utf-8 -*- # 写入索引数据 from decimal import Decimal import pymysql, json from elasticsearch import Elasticsearch def insert_es_data(): es = Elasticsearch(["ip:5000"]) file_path = r"D:\files\612177_1419905_compressed_arxiv-metadata-oai-snapshot-2020-08-14/" file_name = r"arxiv-metadata-oai-snapshot-2020-08-14.json" file_path_name = file_path + file_name with open(file_path_name, "r", encoding='UTF-8') as f: for action in f.readlines(): action = json.loads(action) action["journal_ref"] = action["journal-ref"] del action["journal-ref"] action["report_no"] = action["report-no"] del action["report-no"] for key in action: val_ = action[key] if not val_: val_ = "" elif isinstance(val_, (Decimal,)): val_ = str(val_) else: val_ = pymysql.escape_string(json.dumps(val_)) action[key] = val_ es.index(index="index_test", body=action)
删除数据
from elasticsearch import Elasticsearch es = Elasticsearch(["ip:5000"]) res = es.delete(index="index_test", id ="oClia3QBQ2tDmCR81pYz") print(res)
查询数据
from elasticsearch import Elasticsearch es = Elasticsearch(["ip:5000"]) doc = { "query": { "match": { "comments": "published" } } } import time a = time.time() res = es.search(index="index_test", body=doc) print(res) print(time.time() - a)
查询总数据count
#!/usr/bin/env python # -*- coding:utf-8 -*- from elasticsearch import Elasticsearch es = Elasticsearch(["ip:5000"]) import time a = time.time() res = es.count(index="index_test") print(res) print(time.time() - a)
作者:沐禹辰
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号