Mysql 系列 | 基础架构
其实用 Mysql 已经好多年了,也能写一些复杂 SQL。但对原理一窍不通。最近项目中的 Aurora 总是出现 CPU 爆满的情况,有一些慢 SQL,想来顺便深入了解一下 SQL 执行的内部原理,大概能更好更彻底地解决问题。看了丁奇的《Mysql 实战45讲》收获颇丰,在这里按照自己的思路做一些整理,其一是起到加深理解的作用,其二方便以后查阅,进而查漏补缺。
了解 Mysql 的基础架构
Mysql 基本架构示意图
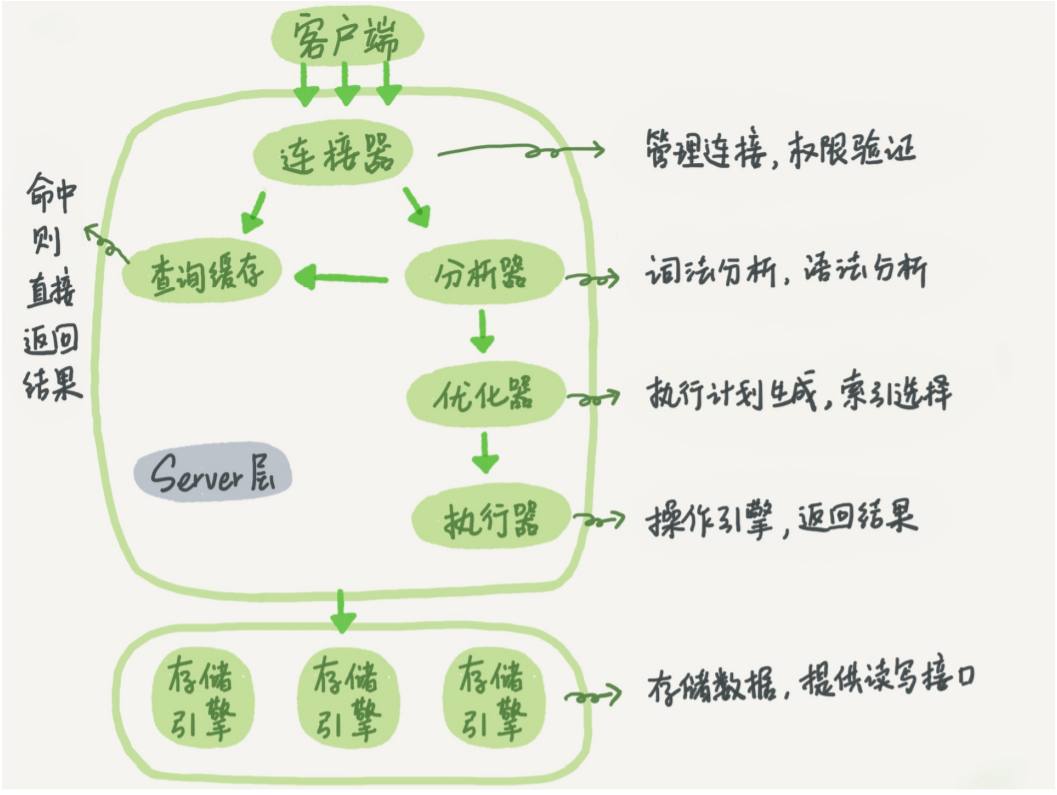
(丁奇原图)
大体分为 Server 层和存储引擎层。
-
Server 层,包括连接器、查询存储、分析器、优化器、执行器等,涵盖大多核心服务功能。以及所有内置函数,如日期、时间、数字、加密函数等。存储引擎、触发器、视图等跨存储引擎的功能,都在 Server 层实现。
-
存储引擎层,负责数据存储、提取。最常用的是 InnoDB,它从MySQL 5.5.5版本开始成为了默认存储引擎。之前版本默认是 MyISAM。
连接器
连接器负责跟客户端建立连接、获取权限、维持和管理连接。
用客户端工具 mysql 连接数据库服务层。
mysql -h127.0.0.1 -p3306 -uroot -p
mysql: [Warning] Using a password on the command line interface can be insecure.
Enter password: **********
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 92
Server version: 8.0.27 MySQL Community Server - GPL
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
-
用户名密码通过验证后,会去权限表中查到当前用户拥有的权限。
-
一个连接成功建立后,所有的操作都基于上面查到的权限,不会中途改变。如果在连接过程中更改了用户权限,则在下一次建立连接时生效。
-
连接成功后,如果没有后续操作,则该连接处于空闲状态,Command 显示为 Sleep。
mysql> show processlist;
+----+-----------------+-----------------+------+---------+--------+------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------------+------+---------+--------+------------------------+------------------+
| 92 | root | localhost:60117 | NULL | Sleep | 27 | | NULL |
| 93 | root | localhost:61070 | NULL | Query | 0 | init | show processlist |
+----+-----------------+-----------------+------+---------+--------+------------------------+------------------+
2 rows in set (0.00 sec)
- 连接如果空闲太长时间就会自动断开,默认为 8 小时(28800s)。
mysql> show variables like "wait_timeout";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wait_timeout | 28800 |
+---------------+-------+
1 row in set, 1 warning (0.01 sec)
-
长连接是指,客户端持续有请求,则一直使用同一个连接。建立连接的过程比较复杂,建议尽量使用长连接。
-
长连接中,Mysql 执行时的临时内存管理在连接资源中,在断开连接时才释放。长时间积累占用较大内存就会被系统强行杀掉(Mysql 异常重启)。
查询缓存
-
缓存是 Key-Value 的形式,Key 是 SQL 语句,Value 是结果集。
-
MySQL 拿到一个请求后,先去缓存中看看之前是否执行过同样的命令。如果有则直接返回对应的结果。如果没有则继续后面的执行操作,执行后,存入查询缓存。
-
对于更新频繁的表,查询缓存失效非常频繁。只要表中有改修,和改修表相关缓存就会全部清空。
-
查询缓存模块在 8.0 后直接删掉了。
-
8.0 前的版本,可以设置是否使用缓存。
- ON 使用
- NO 不使用
- DEMAND 需要时使用
mysql> show variables like "query_cache_type";
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| query_cache_type | ON |
+------------------+-------+
1 row in set (0.00 sec)
- 当设置为 DEMAND 时,默认不使用,可以在要用到的 SQL 语句中显式设定。
select SQL_CACHE * from T where ID=1;
分析器
-
知道接收到的请求要干什么。
-
词法分析,分析 SQL 语句字符串中,字符分别代表什么意思。
-
语法分析,根据规则分析判断是否符合 Mysql 语法,不符合则提示语法错误。
优化器
-
决定要怎么执行命令,选择系统认为的最优解决方案。
-
有多个索引时,选择其中的一个;多表连接时,选择先差哪个后查哪个等等。
执行器
-
首先判断是否有权限,没有则返回权限错误。
-
根据表的引擎定义,调用对应的引擎接口。
-
比如一条简单的查询 SQL,
mysql> select * from T where ID=1;执行过程如下:(下面过程描述不是很准确,简单理解即可)-
调用 InnoDB 引擎接口取得第一条数据,判断 ID 是否为 1,如果是则存在结果集中。
-
调用接口取下一条数据,判断 ID,直到取到表中的最后一条数据。
-
执行器将上面取到满足条件的数据组成结果集,返回给客户端。
-
总算开了头,后面再一边学习一边总结。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号