CTRE-01-基本原理
Compile Time Regular EXpression(CTRE)是一个在编译期生成正则表达式(Regex)匹配器的C++库。因为是在编译期对表达式进行构建,这比很多运行期构建的regex库要高效很多,而且代码——包括生成的汇编——也更简洁易读,效果像这样:
bool matched = ctre::match<"[0-9]*">(str);
当然class模版参数(Non Type Template Parameter)是C++20的特性,C++17不能这样用,而应该传入一个static对象的引用给模版。
经过一番搜索,我发现网上关于CTRE的学习资料几乎等于没有,甚至关于模版编程也只有大神们偶尔贴几段代码,一点解释都没有。这里我尝试重新造一遍此轮子,希望能帮到也想学习Metaprogramming的你。
在模版编程前,我们先了解一下Regex的原理。
正则表达式(Regex)
Regex的语法其实非常简单,Regex可以是
- 空集,即什么都没有
- 空字符串\(\epsilon\),这与空集不同,\(\epsilon\)表示不匹配任何字符
- 一个字符,如a
- 两个Regex的连接(Concatenation),我们用一个点表示:A·B
- 两个Regex的Alternation(不知道怎么翻译了),我们用竖线表示:A|B
- 一个Regex的重复,我们用星号(Kleene star)表示:A*
注意我们使用的Regex中,a?是(\(\epsilon\)|a)的“缩写”,a+是(a·a*)的“缩写”。我们一般还省略Concat的点号。
这个语法足以构建我们一般使用的基本的Regex,当然高级特性如capture group不包含在这语法里。
LL(1) parser
要构建Regex,首先要用parser将输入的字符串转换成AST形式。由于 我还没学编译原理,只知道LL(1) Regex语法属于LL(1)语法,所以我们选择简单的LL(1) parser即可。
LL(1) parser只需要一个parse table,而parse table由\(Firsts\)和\(Follows\)得到,可以看这里的解释。其中用到的语法表达形式叫Context Free Grammar (CFG),可以看这里的解释。
有个稍微不好理解的地方是:如果\(T'\rightarrow FT\),且\(T\)是Non-terminal,那么\(Follows(F)=Firsts(T)\)。如果\(Firsts(T)\)含有\(\epsilon\)(空字符),则\(Follows(F)\)就包含\(Follows(T)\)中所有terminal。这是因为\(\epsilon\)表示\(T\)可以转换为空字符,如果\(T\)是空的,那么跟在\(T\)后的terminal就相当于跟在\(F\)后。
有了parse table后,就可以根据它进行stack的push和pop操作了。
有限状态机
Regex的匹配一般是通过有限状态机(Finite Automata, FA)进行的。
FA由4元组描述:(有限个状态,状态转移条件,一个起始状态,一或多个终止状态)。
FA从一个初始状态开始,然后根据状态转移条件转移到下一状态,直到到达终止状态,可以看这个解释。对Regex来说,到达输入末端时,FA处于终止状态就代表匹配成功。
[0-9]+生成的FA,双圈的圆表示终止状态:
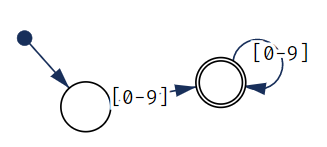
实际生成FA时是不断地进行小FA的连接,连接的方法其实不太简单,写到这部分再说。
还有一个问题是,FA可能存在同时可以进行几个状态转移的情况,这样的FA称为Non-determinestic FA(NFA),匹配NFA需要同时考虑多个状态转移进行搜索,导致效率低。于是就出现如何将NFA转换为状态转移路径可以唯一确定的Determinestic FA(DFA)的问题,这个问题也不简单,以后再说。
总结
总结一下我们需要实现些什么,首先计算都是编译期进行的,所以所有数据结构都要支持constexpr。
- 模版参数Regex是一个字符串,这个字符串在编译期即确定,所以我们需要大小固定的字符串对象:
class FixedString - 一个通过重载规则描述的parse table:
struct ParseTable - LL(1) parser需要的编译期栈:
class Stack - 一个能够表示AST的表达式模版(expression template)
- 有限状态机本身:
class FiniteAutomata - 有限状态机的运行期匹配机制
- 有限状态机需要的集合容器,同样在编译期即确定:
class FixedSet - 状态转移的表示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号