buuctf rip 详细wp
 关于buu刚开始的入门pwn题rip
关于buu刚开始的入门pwn题rip
buu上rip这道题作为pwn里面最简单的栈题,意外的发现网上很多wp因为远程环境的更新,需要维持堆栈平衡,所以原先老旧的wp在本地可以打通,但在远程却打不通,甚至很多人的blog就拿着原本可以打通的wp贴上去,自己都没有实操一遍,我相信很多人都和我一样因为这些wp对初期学习造成了不小的困扰,特别是初期自己底层知识什么都不懂的时候,看到一些甚至是在胡乱解释的wp,就不知道该如何进行后续的学习了,所以今天我通过近两天的摸索,写一篇尽量正确的wp,因为我自己水平有限,一些细节的地方可能会有错误,但大的思路一定是对的,希望能给大家提供帮助,其中用到了别人ppt里现成的图,本人仅用作学习交流,侵删。
ps:因为这里是作为本人的学习笔记,所以前面会有大量的关于栈如何工作的基础内容,不想看的可以直接跳过去看最后的wp
1.Stack(栈)的工作原理
1.1C语言内存分布
首先我们来看当一个c语言函数在执行的时候,操作系统是如何调度内存将数据存放并且完成相关函数操作的
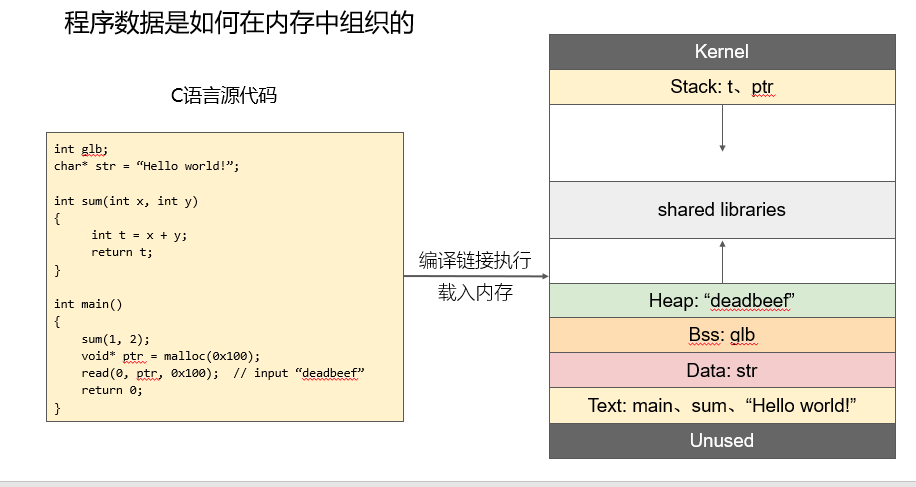
在右边的图中,我们可以大致的了解,一个c程序被编译成可执行文件执行时,他在内存中的存储情况如该图所示,这是一个内存空间,地址由底部逐渐升高,其中,最上层的kernel是操作系统的核心源码,他是操作系统完成各项功能的关键,这一部分我们暂时不做深入的研究,在早期的学习中,我们关注的是Stack(栈),Heap(堆),BSS(静态内存分配)。
其中Stack(栈)用于静态分配中的存放局部变量,如局部变量t和ptr都被储存在了栈中,而BSS存储全局变量,Heap则负责存储动态分配的内存空间,如c语言中的malloc/free分配内存时,就会分配到Heap区域。
而Heap与Stack中间的内存空间,则是共享的一片内存空间,Heap从低地址向高地址分配空间,Stack从高地址向低地址分配空间,从而完整高效的使用了这一片内存空间。
1.2栈中的内存分布与工作原理
好了,现在我们已经大致了解了c语言的内存分布,其中heap和Bss尤其是heap会在后面更深入的学习中使用,我也会在后续的wp中更新相关知识,今天这道题只需要用的栈的相关知识,现在我们来看,当函数调用时,栈的内存空间是如何分布的。
栈这个数据结构相信大家早就学过,首先我们需要了解一下栈中常用的3个寄存器,64位cpu对应rsp,rbp,rip三个寄存器。而32位cpu则对应esp,ebp,eip三个寄存器。然后我们了解一下栈帧的概念,一个栈帧就是保存一个函数的状态,简单来说就是一个函数所需要的栈空间,rsp/esp永远指向栈帧的栈顶,rbp/ebp则永远指向栈帧的栈底,rip/eip指向当前栈栈帧执行的命令。如图中文字所,栈从高地址向低地址开辟内存空间,所以低地址的是栈顶,而栈底的第一个栈帧在这里存放着我们的主函数的父函数,所以main函数并不是最栈顶的函数,main上面还会在编译过程中有一些库函数,但是他们并不会产生栈帧,因为栈先进后出的特性,所以当在main函数中需要调用其他函数时,就开辟一个新的函数栈帧,并存储上一个栈的栈底,当调用结束时,将现在的栈帧弹出,恢复到原来的main函数继续执行完main函数,比如,当上面的代码main函数调用到sum函数时,便会开辟一个新的栈帧,而sum函数所需要的参数,会被逆向存储在父函数(在这里也就是main函数)的栈帧中
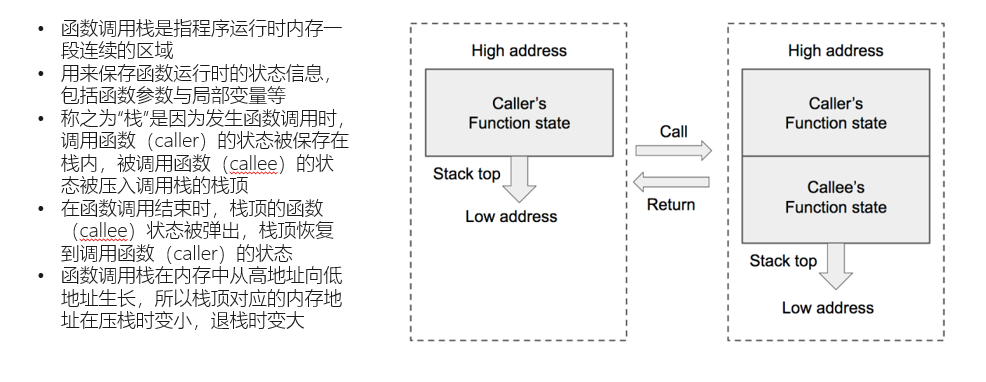
下面,我们来看每个栈帧的具体结构
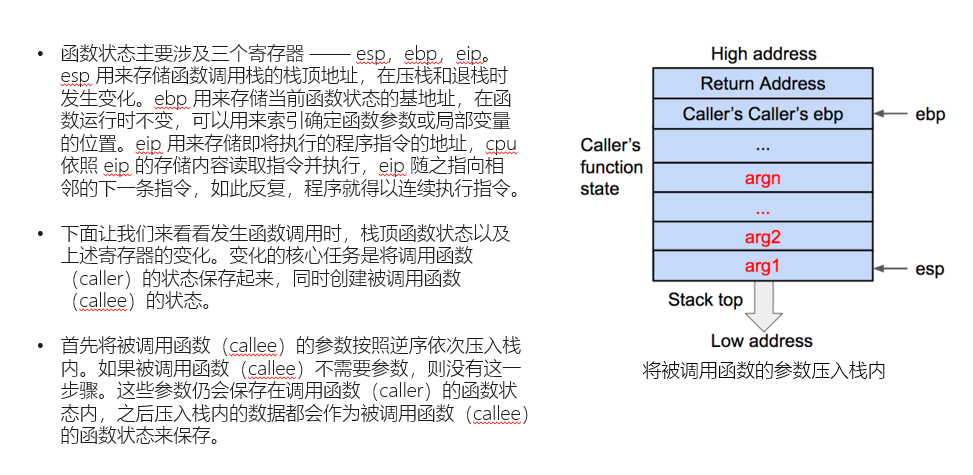


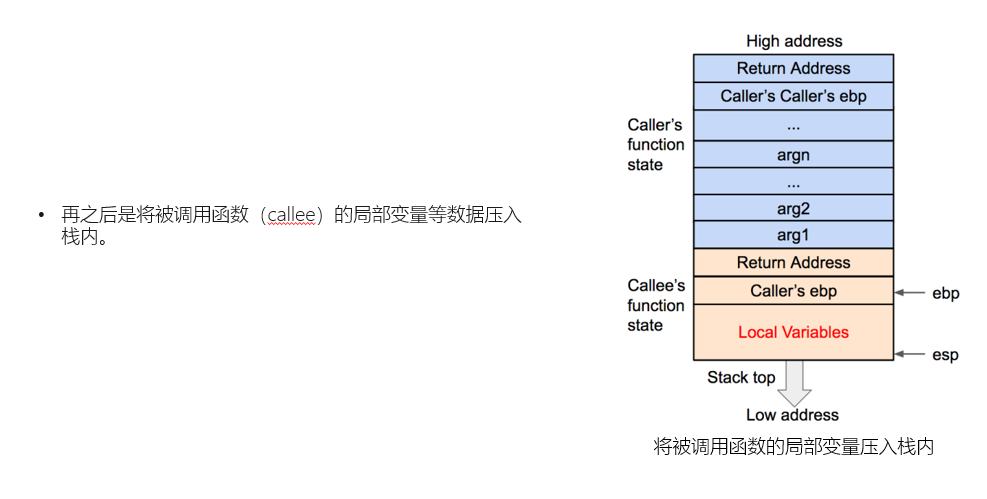
上面的几张图,就是创建新栈帧的过程,当然,图中所演示的是在32位cpu中的情况,也是就是寄存器与存储字长有着细微的变化,但是差别并不是很大,并且,图中的对于寄存器的各种操作都是在汇编代码中具体实现的,这里我们并不赘述太多,相信大家都对简单的汇编或多或少有些了解,图中我们可以看到两个相邻的栈帧,子函数(callee's function state)栈帧的Return Address紧挨着父函数(caller's...state),而我们需要注意的是,Return Address是什么呢?在第二张图中,很明确的告诉我们,在调用子函数时,我们将汇编中父函数的下一个汇编指令的地址,放入Return Address,这样我们在子函数完成时,便可以将Return Address中的值弹入rip/eip中,这样程序便会从上次调用的地方继续完成父函数,而这一点,也就是我们实行栈溢出的关键,我们不妨想一想,如果我们能够通过某种方式,操控Return Address的返回地址,那么是不是意味着,我们可以任意操控远程的机器指向任何指令,也就是说我们只要可以篡改Return Address指向一个危险函数的地址,理论上,我们就可以通过危险函数干任何我们想干的事情。那么我们再来看看当子函数调用结束后,是如何删除子函数的栈帧返回父函数的。
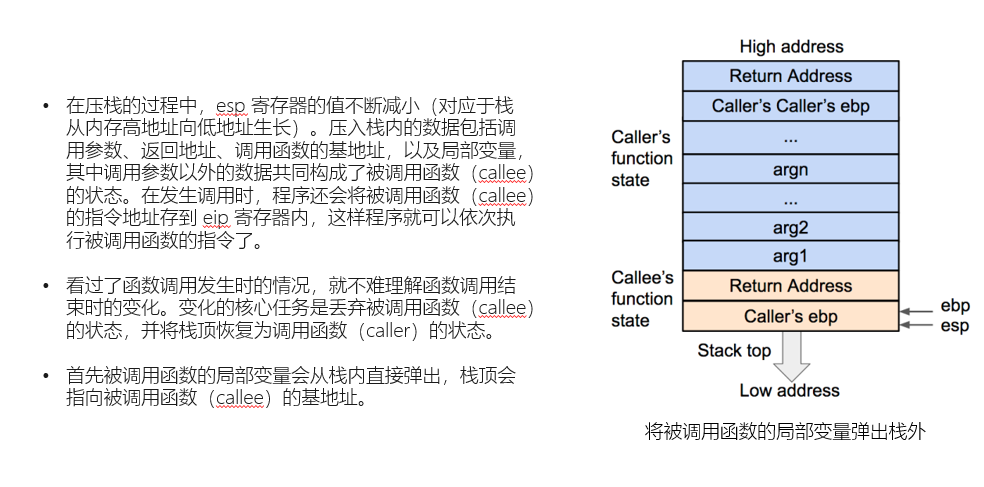
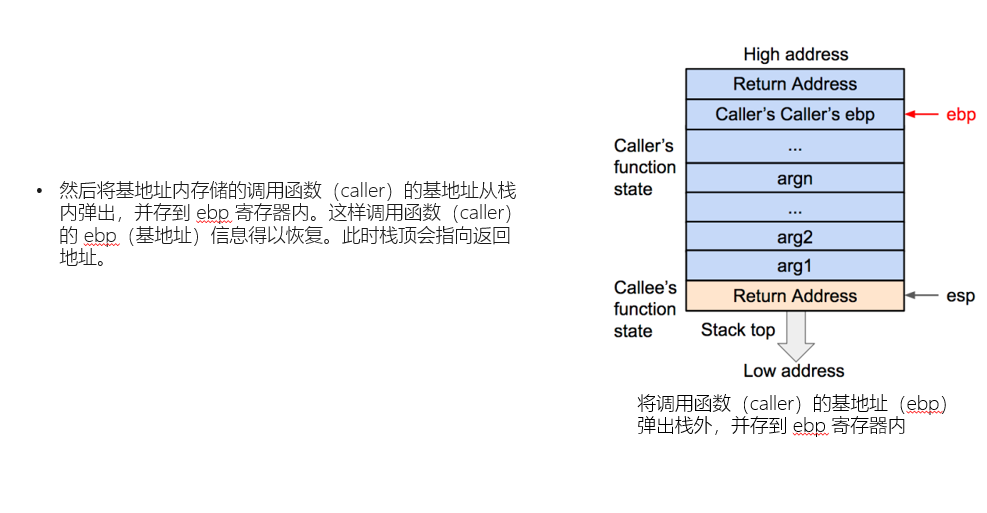
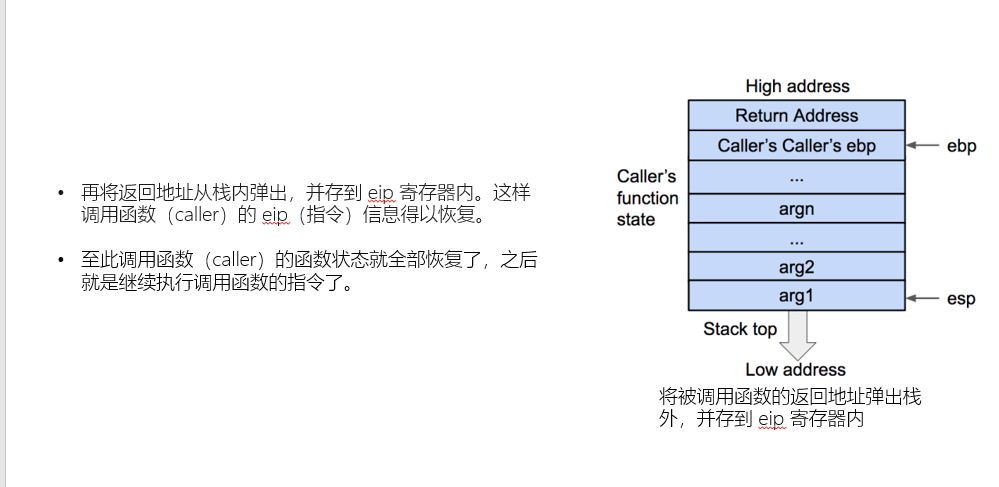
这里具体需要ppt中的汇编代码辅助理解,但是汇编代码的流程图实在太多,改天有空我会发上去,大概就是esp先等于ebp,然后再pop ebp 将esp指向的地址的值赋给ebp,也就是此时的父函数的一个栈帧的栈底,于是ebp就回到了父函数的栈底,而因为pop以后esp自动加一指向Return Address(因为栈是从高地址指向低地址,所以是加一),然后再执行return指令,简单的讲就是pop eip,将esp指向的值弹入到eip中,前面我们说过Return Address里存放的是当前栈帧函数的父函数调用当前函数时下一个指令的地址,而eip又是当前要执行的指令地址的寄存器,于是这样就会回到父函数继续执行父函数的下一个指令。而此时pop以后esp再次加一,所以就回到了父函数栈帧的栈顶,ebp也在上一次pop ebp时就回到了父函数的栈底,而这样一个过程可以理论上被无数次执行,所以用栈来实现函数调用及其的方便。
2.buuctf rip wp
2.1栈溢出的原理
那么上面我们学习了栈的基础知识,我们便以buu上的这一道rip来看一下最简单的栈溢出。
如果你认真的看了上面的栈的工作流程,那么你就会发现,实际上在一个函数调用完以后,就要删除此时的栈帧并将Return Address的值返回rip/eip,Return Address的值也就是上面说的,父函数调用此函数(也就是他的子函数)时的下一个地址,通俗一点解释就是从父函数跳转到子函数时,父函数会从某个call指令断开,跳转到子函数,Return Address就是把他从断开的地方接上,也就是断开指令下一个指令的地址,而rip/eip将执行这一指令,并继续完成父函数,那么我们只要设法将Return Address的值改变到一个危险函数的地址,我们就可以通过这个危险函数获得系统的控制权。
那么我们怎么样才可以改变Return Address的地址呢?以这道rip为例,下载rip给我们的elf文件,将其拖入ida pro,按f5将其反编译成c语言伪代码
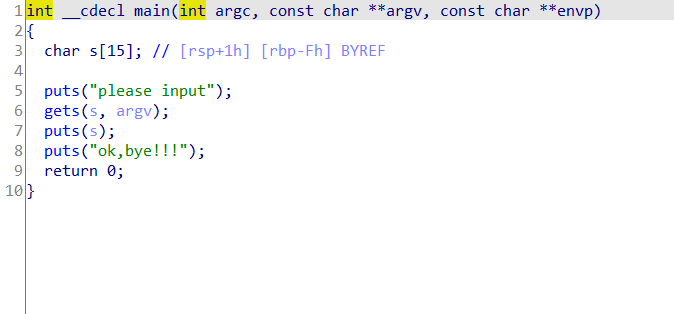
我们可以看到,主要有一个main函数,还有一个fun函数

这个elf可执行文件,补充一下,elf是linux下的可执行文件,相当于windows中的exe文件,他的反编译文件是由一个main函数和一个fun函数组成的,当我们用虚拟机在unbantu中正常执行他时,他只会执行main函数,因为fun函数并没有被调用,而fun函数也就是我们上面说的危险函数,system是c语言下的一个可以执行shell命令的函数,目前你可以简单理解为,执行了这个危险函数,我们就拿到了远端服务器的shell,也就是相当于在windows下以管理员身份开启cmd,那么我们就可以通过一系列后续指令控制远端服务器,但在ctf中,我们只需要拿到shell以后获得flag就算成功。
那么,回过头来,我们再来看这个main函数,我们刚刚说过,函数的局部变量会存放在他的栈中,那么在main函数中,他char了一个s,也就是在main函数的栈帧中,划分了一个15字节的存储空间,我们在unbantu中file一下这个文件:
我们可以发现,这是一个64位的elf文件,也就是说,每个存储单元是8个字节(如果不知道的去学学计组),简单的讲就是一个字节是8位,因为他是64位,所以一个存储单元就是8个字节,同理32位就是4个字节。(注意,这里我出了个小失误,我们应该先file这个文件,看看他是64位还是32位,再选择将其拖入64位的ida还是32位的ida)
然后我们可以先通过checksec查看保护机制(不知道没关系,以后才会用到),因为这题是任何保护都没有打开的,所以我们可以实现最简单的栈溢出
接回上面的话题,我们开辟了一个15个字节的存储空间,那么在栈帧中系统就会给我们分配一个15个字节的存储空间,那么我们再注意一下我们是如何写入这15个字节的数据的,没错,我们使用的是gets函数,相信大家在c语言中都学习过这个函数,我们在c语言的学习中知道,这个函数时可以无限制输入数据的,但当时,我们并没有意识到gets函数时危险的,现在,我们通过前面栈的工作原理的学习,我们发现,我们明明只分配了15个字节的内存空间,但是我们可以输入无数个字节,那么这会导致什么问题呢?请大家自己回过头再去看一看前面栈的结构图!
此时,我们的s就在Local Variables,把他想象成一个水桶,我们如果可以一直往里面不停的倒水,那么这个水桶的水满了,是不是就可以溢出到另一个水桶Caller's ebp里?再继续倒水,那是不是就溢出到了Return Address里,那么原本不属于Return Address的水由于其他水桶的溢出而进入了Return Address,也就是改变了Return Address的值。这个时候,我们前面所说的,通过改变Return Address的值来完成对危险函数的调用,是不是就可以实现了?
那么,最后的问题就是,我们该怎么确定溢出多少水呢?这个也是很简单的问题,Local Variables也就是char s[]划定了15个字节的内存空间,那么我们需要知道这个内存空间在栈中的位置,就可以知道需要多少个字节才能到达
我们打开ida pro ,作为最简单的栈题,我们在ida pro中的main函数在创建空间s时已经清晰的告诉了我们距离rbp的距离是Fh,这是16进制也就是15个字节,当然,这只是理想的情况,在复杂一些的情况中,开辟的内存地址显然不会像这题一样紧挨着上一个rbp,甚至有时出题人会故意在ida的静态调试中告诉你错误的地址,这个时候你需要用pwndbg进行动态调试,这题通过动态调试也可以发现,二者的地址是一样的。所以我们首先需要输入15个字节到达rbp的位置。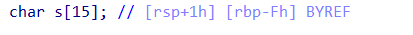
然后Caller's ebp中存储的是上一个函数的ebp的值,当然,我们这个图的例子是32位的系统,而我们是64位的系统,所以ebp应该是rbp才对,是8个字节,那么我们还需要8个自己的数据把Caller's rbp的数据填满(当然在本题中应该是rbp,因为是64位的系统),这样我们就填满了前两个水桶,你可以理解为水即将溢出进入Return Address了,所以接下来我们输入的值,将溢出进入Return Address,也就是说,这时我们还需要输入危险函数,也就是fun函数的地址,查看一下ida pro发现fun函数的地址是0x401186,于是只需要再输入0x401186这一地址值,该地址就被我们送到了Return Address,当这个函数调用结束后就会被送到rip,执行fun函数,从而控制shell。
2.2exp
from pwn import *
p = remote("node4.buuoj.cn",27296)
payload=b'A'15+b'B'8+p64(0x401186+1)
p.sendline(payload)
p.interactive()
作为最简单的pwn题,当然是最简单的exp,只要知道原理几行代码就可以搞定,我们发送了15个A用来填充s,再发送8个字节用来填充b,将地址打包位p64位的数据一起发送,就可以完成栈溢出,至于最后为什么要+1,我们可以发现,不加一我们在本地可以打通,但是却打不通远程,这也是我开头说的,和以前payload不一样的地方,原理我们是没有错的,这里+1是为了堆栈平衡,详细可以看大佬的博客http://blog.eonew.cn/archives/958
因为现在已经是凌晨三点,再加上我对这里还有点模糊,也就不废话了,总之我们学的知识是没有错的,这里需要堆栈平衡应该也是远程buu的服务器更新以后linux环境发生了变化,加了新的要求,而不是因为其他原因,改成15个字节直接发送地址不加一也可以完成交互,但是并不是因为不需要覆盖rbp,而是满足堆栈平衡的一种另外一种方式,后续如果学明白了会更新。
总结
虽然是最简单的pwn题,exp只有短短几行代码,但是想要完全掌握背后的知识,却不是那么简单,哪怕是已经学了两天,今天在复盘栈的工作原理的时候,发现自己也会很多不熟练的地方,所以只有将基础打牢,能在脑海中自动演示栈的工作原理,才能完成后续更加复杂的学习,这也是二进制安全难入门的地方之一,在此与各位师傅共勉。
这里面用的图,全都是某个安全团队大师傅讲pwn入门公开课用的图,因为一些问题不太方便公开,如果有人需要完整ppt的话,如果有疑问或者想要ppt再或者想要一起学习的师傅可以中私信联系我。
其实大家看完这题以后一定和我刚学完一样会有一个异或,那就是实际情况中,怎么可能会有人傻到将程序设置一个后门函数呢?实际情况中确实是不会有人这么傻的,因此这只是一个最简单的栈溢出题,意在让你了解栈工作的基本原理,属于level 0,在后续更深入的学习中,我们会遇到更符合实际情况的题目,也会见招拆招,构造出更复杂的payload。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号