
[总结] 网络概念性问题(TCP/UDP, HTTP, 长连接/短连接) TOMCAT处理请求/参数配置
Posted on 2019-05-08 18:20 redcoatjk 阅读(2812) 评论(0) 收藏 举报1 首先认识网络模型
1.1 网络模型
OSI七层网络模型 | TCP/IP四层概念模型 | 对应网络协议 |
应用层(Application) | 应用层 | HTTP、TFTP, FTP, NFS, WAIS、SMTP |
表示层(Presentation) | Telnet, Rlogin, SNMP, Gopher | |
会话层(Session) | SMTP, DNS | |
传输层(Transport) | 传输层 | TCP, UDP |
网络层(Network) | 网络层 | IP, ICMP, ARP, RARP, AKP, UUCP |
数据链路层(Data Link) | 数据链路层 | FDDI, Ethernet, Arpanet, PDN, SLIP, PPP |
物理层(Physical) | IEEE 802.1A, IEEE 802.2到IEEE 802.11 |
- 物理层 (对应网卡,网线,集线器,中继器,调制解调器)
- 数据链路层 (对应网桥,交换机)
- 网络层 (对应路由器)
- 传输层(OSI下3层的主要任务是数据通信,上3层的任务是数据处理。而传输层(Transport Layer)是OSI模型的第4层。因此该层是通信子网和资源子网的接口和桥梁,起到承上启下的作用.传输层的作用是向高层屏蔽下层数据通信的细节,即向用户透明地传送报文。)
- 会车层 略..
- 表示层 略..
- 应用层(是计算机用户,以及各种应用程序和网络之间的接口,其功能是直接向用户提供服务,完成用户希望在网络上完成的各种工作。它在其他6层工作的基础上)
1.2 其他概念
1.2.1 TCP/IP
1.2.2 tcp/udp
| TCP | UDP | |
| 是否连接 | 面向连接 | 面向非连接 |
| 传输可靠性 | 可靠 | 不可靠 |
| 应用场合 | 传输大量的数据,对可靠性要求较高的场合 | 传送少量数据、对可靠性要求不高的场景 |
| 速度 | 慢 | 快 |
1.2.3 HTTP
全称是Hypertext Transfer Protocol,即超文本传输协议。从名字上可以看出该协议用于规定客户端与服务端之间的传输规则,所传输的内容不局限于文本(HTML 文件, 图片文件, 查询结果等)。
- HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
- HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
1.2.4 Socket
通过Socket,我们才能使用TCP/IP协议。tcp、udp,简单的说(虽然不准确)是两个最基本的协议,
Socket的大致位置如下: 为了便于编程而设想出来的API/编程模型
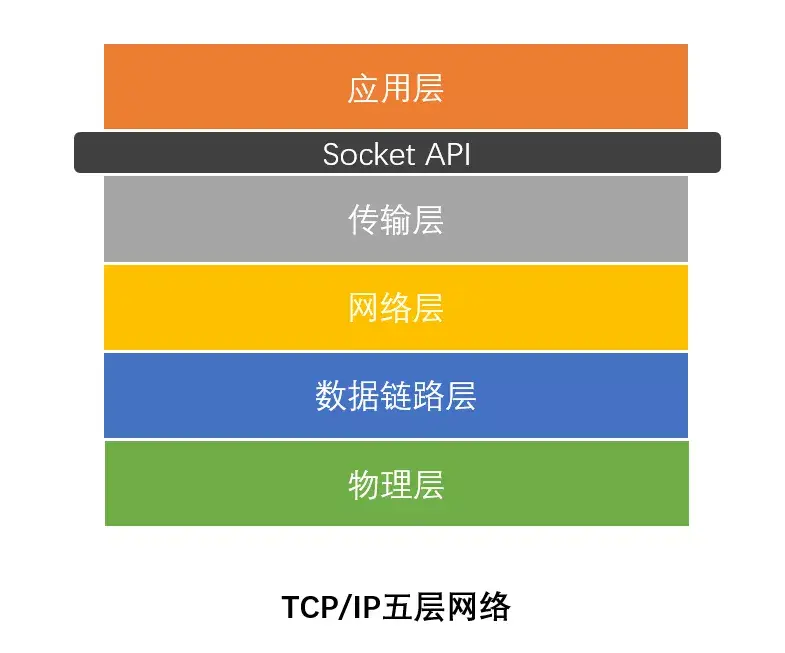
2 网络请求过程
3.1 HTTP, 长连接,短连接
HTTP是应用层协议.定义的是传输数据的内容的规范。
全称是Hypertext Transfer Protocol,即超文本传输协议。从名字上可以看出该协议用于规定客户端与服务端之间的传输规则,所传输的内容不局限于文本(HTML 文件, 图片文件, 查询结果等)。
HTTP对应在传输层使用的还是TCP协议进行通信.HTTP是应用层协议.定义的是传输数据的内容的规范。全称是Hypertext Transfer Protocol,即超文本传输协议。从名字上可以看出该协议用于规定客户端与服务端之间的传输规则,所传输的内容不局限于文本(HTML 文件, 图片文件, 查询结果等)。HTTP对应在传输层使用的还是TCP协议进行通信.- HTTP基于请求响应模型。
- HTTP是无连接的
- HTTP协议是无状态的协议
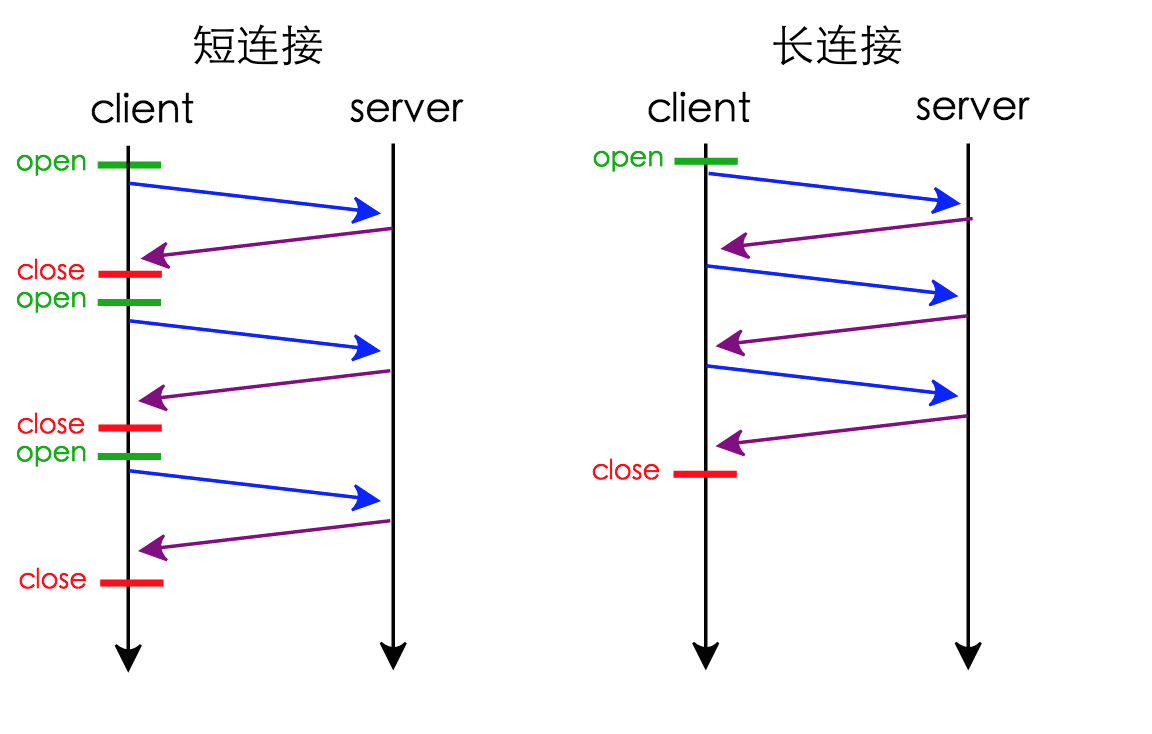
从图中可以看到:
在串行连接中,每次交互都要打开关闭连接
在持久连接中,第一次交互会打开连接,交互结束后连接并不关闭,下次交互就省去了建立连接的过程。
3.2 HTTP的版本
- 不支持持久连接。一旦服务器对客户端发出响应就立即断开TCP连接 (即每次http请求都是短连接,每次请求需要先创建tcp连接(三次握手)后才能发送http请求,得到响应后通过四次握手关闭tcp连接)
- 无请求头跟响应头
- 客户端的前后请求是同步的。下一个请求必须等上一个请求从服务端拿到响应后才能发出,有点类似多线程的同步机制。
- 与1.1之前的版本相比,做了以下性能上的提升
- 增加请求头跟响应头
- 支持持久连接。客户端通过请求头中指定Connection为keep-alive告知服务端不要在完成响应后立即释放连接。HTTP是基于TCP的,在HTTP 1.1中一次TCP连接可以处理多次HTTP请求
- 客户端不同请求之间是异步的。下一个请求不必等到上一个请求回来后再发出,而可以连续发出请求,有点类似多线程的异步处理。
3.3 长连接/短连接
3.3.1 概念
3.3.2 HTTP/1.0+的Keep-Alive
Connection: Keep-AliveConnection: Keep-AliveConnection: Keep-AliveConnection: Keep-Alive3.3.3 HTTP/1.1的持久连接
4 Socket编程
Socket socket=new Socket("127.0.0.1",4700);
//向本机的4700端口发出客户请求
BufferedReader sin=new BufferedReader(new InputStreamReader(System.in));
//由系统标准输入设备构造BufferedReader对象
PrintWriter os=new PrintWriter(socket.getOutputStream());
//由Socket对象得到输出流,并构造PrintWriter对象
BufferedReader is=new BufferedReader(new InputStreamReader(socket.getInputStream()));
//由Socket对象得到输入流,并构造相应的BufferedReader对象
String readline;
readline=sin.readLine(); //从系统标准输入读入一字符串
while(!readline.equals("bye")){
//若从标准输入读入的字符串为 "bye"则停止循环
os.println(readline);
//将从系统标准输入读入的字符串输出到Server
os.flush();
//刷新输出流,使Server马上收到该字符串
System.out.println("Client:"+readline);
//在系统标准输出上打印读入的字符串
System.out.println("Server:"+is.readLine());
//从Server读入一字符串,并打印到标准输出上
readline=sin.readLine(); //从系统标准输入读入一字符串
} //继续循环
os.close(); //关闭Socket输出流
is.close(); //关闭Socket输入流
socket.close(); //关闭Socket
}catch(Exception e) {
System.out.println("Error"+e); //出错,则打印出错信息
}
Socket socket=new Socket("127.0.0.1",4700); //向本机的4700端口发出客户请求 BufferedReader sin=new BufferedReader(new InputStreamReader(System.in)); //由系统标准输入设备构造BufferedReader对象 PrintWriter os=new PrintWriter(socket.getOutputStream()); //由Socket对象得到输出流,并构造PrintWriter对象 BufferedReader is=new BufferedReader(new InputStreamReader(socket.getInputStream())); //由Socket对象得到输入流,并构造相应的BufferedReader对象 String readline; readline=sin.readLine(); //从系统标准输入读入一字符串 while(!readline.equals("bye")){ //若从标准输入读入的字符串为 "bye"则停止循环 os.println(readline); //将从系统标准输入读入的字符串输出到Server os.flush(); //刷新输出流,使Server马上收到该字符串 System.out.println("Client:"+readline); //在系统标准输出上打印读入的字符串 System.out.println("Server:"+is.readLine()); //从Server读入一字符串,并打印到标准输出上 readline=sin.readLine(); //从系统标准输入读入一字符串 } //继续循环 os.close(); //关闭Socket输出流 is.close(); //关闭Socket输入流 socket.close(); //关闭Socket }catch(Exception e) { System.out.println("Error"+e); //出错,则打印出错信息 } try{
ServerSocket server=null;
try{
server=new ServerSocket(4700);
//创建一个ServerSocket在端口4700监听客户请求
}catch(Exception e) {
System.out.println("can not listen to:"+e);
//出错,打印出错信息
}
Socket socket=null;
try{
socket=server.accept();
//使用accept()阻塞等待客户请求,有客户
//请求到来则产生一个Socket对象,并继续执行
}catch(Exception e) {
System.out.println("Error."+e);
//出错,打印出错信息
}
String line;
BufferedReader is=new BufferedReader(new InputStreamReader(socket.getInputStream()));
//由Socket对象得到输入流,并构造相应的BufferedReader对象
PrintWriter os=newPrintWriter(socket.getOutputStream());
//由Socket对象得到输出流,并构造PrintWriter对象
BufferedReader sin=new BufferedReader(new InputStreamReader(System.in));
//由系统标准输入设备构造BufferedReader对象
System.out.println("Client:"+is.readLine());
//在标准输出上打印从客户端读入的字符串
line=sin.readLine();
//从标准输入读入一字符串
while(!line.equals("bye")){
//如果该字符串为 "bye",则停止循环
os.println(line);
//向客户端输出该字符串
os.flush();
//刷新输出流,使Client马上收到该字符串
System.out.println("Server:"+line);
//在系统标准输出上打印读入的字符串
System.out.println("Client:"+is.readLine());
//从Client读入一字符串,并打印到标准输出上
line=sin.readLine();
//从系统标准输入读入一字符串
} //继续循环
os.close(); //关闭Socket输出流
is.close(); //关闭Socket输入流
socket.close(); //关闭Socket
server.close(); //关闭ServerSocket
}catch(Exception e){
System.out.println("Error:"+e);
//出错,打印出错信息
}
} try{ ServerSocket server=null; try{ server=new ServerSocket(4700); //创建一个ServerSocket在端口4700监听客户请求 }catch(Exception e) { System.out.println("can not listen to:"+e); //出错,打印出错信息 } Socket socket=null; try{ socket=server.accept(); //使用accept()阻塞等待客户请求,有客户 //请求到来则产生一个Socket对象,并继续执行 }catch(Exception e) { System.out.println("Error."+e); //出错,打印出错信息 } String line; BufferedReader is=new BufferedReader(new InputStreamReader(socket.getInputStream())); //由Socket对象得到输入流,并构造相应的BufferedReader对象 PrintWriter os=newPrintWriter(socket.getOutputStream()); //由Socket对象得到输出流,并构造PrintWriter对象 BufferedReader sin=new BufferedReader(new InputStreamReader(System.in)); //由系统标准输入设备构造BufferedReader对象 System.out.println("Client:"+is.readLine()); //在标准输出上打印从客户端读入的字符串 line=sin.readLine(); //从标准输入读入一字符串 while(!line.equals("bye")){ //如果该字符串为 "bye",则停止循环 os.println(line); //向客户端输出该字符串 os.flush(); //刷新输出流,使Client马上收到该字符串 System.out.println("Server:"+line); //在系统标准输出上打印读入的字符串 System.out.println("Client:"+is.readLine()); //从Client读入一字符串,并打印到标准输出上 line=sin.readLine(); //从系统标准输入读入一字符串 } //继续循环 os.close(); //关闭Socket输出流 is.close(); //关闭Socket输入流 socket.close(); //关闭Socket server.close(); //关闭ServerSocket }catch(Exception e){ System.out.println("Error:"+e); //出错,打印出错信息 } }5 HTTP编程和连接池
5.1 HttpComponents
5.2 HTTP连接池
- 当有连接第一次使用的时候建立连接
- 结束时对应连接不关闭,归还到池中
- 下次同个目的的连接可从池中获取一个可用连接
- 定期清理过期连接
5.2.1 使用连接池的好处
5.2.2 简单连接管理器
BasicHttpClientConnectionManager是个简单的连接管理器,它一次只能管理一个连接。尽管这个类是线程安全的,它在同一时间也只能被一个线程使用。BasicHttpClientConnectionManager会尽量重用旧的连接来发送后续的请求,并且使用相同的路由。如果后续请求的路由和旧连接中的路由不匹配,BasicHttpClientConnectionManager就会关闭当前连接,使用请求中的路由重新建立连接。如果当前的连接正在被占用,会抛出java.lang.IllegalStateException异常。5.2.3 连接池管理器
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
// 将最大连接数增加到200
cm.setMaxTotal(200);
// 将每个路由基础的连接增加到20
cm.setDefaultMaxPerRoute(20);
//将目标主机的最大连接数增加到50
HttpHost localhost = new HttpHost("www.yeetrack.com", 80);
cm.setMaxPerRoute(new HttpRoute(localhost), 50);
CloseableHttpClient httpClient = HttpClients.custom()
.setConnectionManager(cm)
.build();
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager(); // 将最大连接数增加到200 cm.setMaxTotal(200); // 将每个路由基础的连接增加到20 cm.setDefaultMaxPerRoute(20); //将目标主机的最大连接数增加到50 HttpHost localhost = new HttpHost("www.yeetrack.com", 80); cm.setMaxPerRoute(new HttpRoute(localhost), 50); CloseableHttpClient httpClient = HttpClients.custom() .setConnectionManager(cm) .build();5.2.4 关闭连接管理器
CloseableHttpClient httpClient = <...>
httpClient.close(); CloseableHttpClient httpClient = <...> httpClient.close();5.2.5 连接回收策略
经典阻塞I/O模型的一个主要缺点就是只有当组侧I/O时,socket才能对I/O事件做出反应。当连接被管理器收回后,这个连接仍然存活,但是却无法监控socket的状态,也无法对I/O事件做出反馈。如果连接被服务器端关闭了,客户端监测不到连接的状态变化(也就无法根据连接状态的变化,关闭本地的socket)。
HttpClient为了缓解这一问题造成的影响,会在使用某个连接前,监测这个连接是否已经过时,如果服务器端关闭了连接,那么连接就会失效。这种过时检查并不是100%有效,并且会给每个请求增加10到30毫秒额外开销。唯一一个可行的,且does not involve a one thread per socket model for idle connections的解决办法,是建立一个监控线程,来专门回收由于长时间不活动而被判定为失效的连接。这个监控线程可以周期性的调用ClientConnectionManager类的closeExpiredConnections()方法来关闭过期的连接,回收连接池中被关闭的连接。它也可以选择性的调用ClientConnectionManager类的closeIdleConnections()方法来关闭一段时间内不活动的连接。
5.2.6 连接存活策略
6 Tomcat 处理请求过程
6.1 Tomcat的相关配置
6.1.1 配置文件server.xml
6.1.2 认识Connector
6.1.3 BIO/NIO有何不同
在NIO实现的Connector中,处理请求的主要实体是NIoEndpoint对象。NIoEndpoint中除了包含Acceptor和Worker外,还使用了Poller,处理流程如下图所示(图片来源:http://gearever.iteye.com/blog/1844203)。
图6-2
Acceptor接收socket后,不是直接使用Worker中的线程处理请求,而是先将请求发送给了Poller,而Poller是实现NIO的关键。Acceptor向Poller发送请求通过队列实现,使用了典型的生产者-消费者模式。在Poller中,维护了一个Selector对象;当Poller从队列中取出socket后,注册到该Selector中;然后通过遍历Selector,找出其中可读的socket,并使用Worker中的线程处理相应请求。与BIO类似,Worker也可以被自定义的线程池代替。
通过上述过程可以看出,在NIoEndpoint处理请求的过程中,无论是Acceptor接收socket,还是线程处理请求,使用的仍然是阻塞方式;但在“读取socket并交给Worker中的线程”的这个过程中,使用非阻塞的NIO实现,这是NIO模式与BIO模式的最主要区别(其他区别对性能影响较小,暂时略去不提)。而这个区别,在并发量较大的情形下可以带来Tomcat效率的显著提升:
目前大多数HTTP请求使用的是长连接(HTTP/1.1默认keep-alive为true),而长连接意味着,一个TCP的socket在当前请求结束后,如果没有新的请求到来,socket不会立马释放,而是等timeout后再释放。如果使用BIO,“读取socket并交给Worker中的线程”这个过程是阻塞的,也就意味着在socket等待下一个请求或等待释放的过程中,处理这个socket的工作线程会一直被占用,无法释放;因此Tomcat可以同时处理的socket数目不能超过最大线程数,性能受到了极大限制。而使用NIO,“读取socket并交给Worker中的线程”这个过程是非阻塞的,当socket在等待下一个请求或等待释放时,并不会占用工作线程,因此Tomcat可以同时处理的socket数目远大于最大线程数,并发性能大大提高。
6.1.4 参数说明
个人理解, 可能有误.
如图6-1所示, Tomcat在accept队列中接收连接,
backlog)- acceptCount(最大排队数)
- maxConnections(最大连接数)
- maxThreads(处理线程的最大数量)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号