逻辑回归
前言
逻辑回归与线性回归都是回归,使用什么回归函数,是通过数据来决定的。
而逻辑回归的数据的特点就是“x自变量向量组对应的y值只有1和0两个值”。
所以我们自然希望能找到一种方程,将x代入,得出来的值只有1或0两种。
根据经验可知sigmoid函数很符合我们的需求,sigmoid函数随着自变量的不断改变,其值域也在[0,1]上改变。
现在我们要做的就是“找到x和sigmoid函数自变量的一种关系”,即:x如何变化后,通过这种“关系”,可以将x变化后的结果映射到sigmoid函数的自变量上,然后得到具体的因变量y值。而这个关系就是某个函数,可以是线性的也可是非线性的。
这段话挺抽象的。。。再具体说下:
sigmoid函数函数有自变量和因变量。
我们希望找到我们样本值x和sigmoid函数因变量之间的关系。
但我们不能直接把x代到sigmoid函数的自变量中,因为sigmoid函数的自变量并不一定符合我们的样本参数,我们需要“定制化的sigmoid函数”(这段话也挺抽象的。。下面会给解释)
所以我们需要一个“函数关系”,把x代入函数关系,然后再代入sigmoid函数。
即:sigmoid函数为:ϕ(z),其中z(x)又是个关于x的函数(一般定义为线性函数)
逻辑回归也是属于回归方程,同线性回归一样,我们一样要“根据所给的样本参数求出代价函数”。
(大致回顾一下之前的代价函数例子)
我们有一大堆已经分好类的样本参数(这是大前提)
我们现在要做的就是根据这一大堆的“已经知道结果”的样本参数,来找到一个回归方程,(重点)“使得这些样本参数代入此回归方程的结果与我们已知的正确结果相同”(如,假设这些样本参数都是平面上的点,那么这些点的x和y坐标我们都是知道的了。代入x进回归方程后都能得到结果,其结果要和我们已知的y保持一致性)。
这个时候我们要做的其实就是选择“合适的回归方程”作为模型。在将我们知道的样本数据带进去,把这个回归方程“定制”成符合我们问题的方程。
最后的这个定制化的模型算法就是我们“学习后的成果”。
一般这种问题都会有两部分参数:一部分是已知的样本参数,通过这部分参数我们能训练出模型。
另一部分是“不知道结果”的参数,我们可以通过模型来“预测”出这些参数的结果。
结论
1、其实这个“把已知的样本参数代入我们选择的模型中,然后将模型定制化”的过程就是一个“学习过程”,而且我们很容易看出,我们的样本参数越多,最后训练出来的模型也越准确。
2、一个模型只能适用于某一种类型的数据或问题。适用于什么场景与我们的样本参数有很大关系,因为模型是我们用同一问题场景的样本参数训练出来的,他以后能接收的参数自然也是该场景下的参数。
3、目前分类问题都是这么个流程
步骤可化简为:
有已知结果的样本参数。
选择一个合适的算法模型(此处的选择更多的是根据业务场景凭借经验和知识选择出来的,这也是最考验人的地方)。
将我们拥有的“已知结果的样本参数”代入我们选择的模型中(其中还会涉及代价函数的问题),将模型“训练”成更符合我们问题的模型(如此处的规划模型,实际上每种规划模型的区别只在常量向量θ上,而代入不同样本参数,最终我们能得到的常量向量θ都不一样,而有明确的常量向量θ的模型就是我们需要的“定制模型”)
最后,我们就能用这个训练后的模型“预测”以后参数的结果。
逻辑回归的代价函数
回到逻辑回归问题上
之前的推理中我们说了,
我们需要根据我们的样本参数,把sigmoid函数训练成我们需要的定制化模型。
怎么个训练法?用我们之前讲代价函数的时候的通俗语言说就是:
把我们样本参数中的x的值代入sigmoid函数得到的结果,“与我们已知的x的真正结果做差异比较”,我们希望这个结果差异很小。
而将x代入sigmoid函数求结果唯一的问题是我们不知道sigmoid函数中的常量向量组θ应该定义多少。
所以现在我们的问题就变成了“求解未知量θ”的问题了。
θ变成了自变量,而为了求出θ而产生的方程就是我们此时需要的代价方程。
接下来就推导一下这个逻辑回归的代价方程:
假设,根据数据我们选择线性模型作为函数模型。
所以设函数模型为:Z = θTX + b (θT是θ响向量的转置,X是自变量x的向量集)
每次将Z值代入sigmoid函数,然后计算出该自变量x对应的因变量z值属于“1分类”还是“0分类”。
所以我们的sigmoid函数ϕ(z)如下:
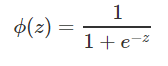
首先我们先尝试套用线性回归中的代价函数,即使用误差平方和公式来当代价函数。得到代价函数方程J(θ)为:
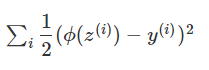
此代价函数的图像是一个“非凸函数”,里面有很多局部的最小值,
所以虽然该代价方程“可以找到θ值”,但很不好找。
我们换一个角度来创建该代价函数。
ϕ(z)的值在也可以看成是“知道某个x后,z属于1分类的概率”,我们将“z属于某个分类”这个事件设为y,y的样本点为0和1,“1样本点”代表z属于1分类事件,“0样本点”代表z属于0分类事件。(也可以设别的数为,但设0,1一个是符合事件描述,再者方便后续方程的建立,如果设别的值后续的代价函数方程虽然也能建立,但不如设0,1简单)
所以P(y=1|x) = ϕ(z) ,P(y=0|x) = 1 - ϕ(z)
可以将两个方程合并成一般式,概率P(y|x)为:
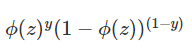
(根据之前的设,其中y=1或0)
这就是我们逻辑回归的代价函数。
注意:这个代价函数中的z是个线性方程(也可以是非线性方程),其中包含了我们需要求出的常量向量集θ
与之前通过平方差公式通过距离差的方式推导的代价函数不同,
我们这次选择通过“概率”的方式,来使我们的方程“尽可能的能精准分类”。
我们上面已经把P(y|x)公式推导出来了,P(y|x)的含义是:x为某值的前提下,“其属于y分类的概率”。
用于逻辑回归模型的数据其X自变量对应的y值只有两种情况,即:y=1或0(属于1分类或0分类)。
我们现在手里已经有很多样本点了,如(x1,1)、(x2,0)、(x3,1)、(x4,1)·······
假设我们 代价函数是个非常完美的函数,以样本点(x1,1)为例,在我们已经知道了该样本点的正确分类为1的情况下,把x1代入我们的代价函数,其计算出的概率P(1 | x1)应该是100%
但肯定没有那么神的函数,所以我们要做的就是“代入我们已知的样本点(x,y)后,通过选择合适的θ向量集,让函数的P(y|x)的结果更接近100%”
然后就是一些计算上的处理了:
首先我们的样本值很多,假设所有样本之间相互独立,那么该样本集的生概率就是各样本点概率相乘。
所以我们把个样本点代入代价函数后,相乘并对整个表达式取对数(方便计算),得到最终的关于θ的代价函数J(θ):

(其中的h(x)就是sigmoid函数)
推导此处,就能很明确的发现,现在问题已经变成了知道函数中的x和y,求:函数取最大值时θ的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号