
第八章 Planning and Learning with Tabular Methods 读书笔记
在这一章中我们从一种统一的视角结合了强化学习中有模型的方法和无模型的方法。基于模型的方法的主要部分是规划,无模型的方法主要依赖学习。这两类方法有共同的基础体现在值函数。
- 都依靠值函数的计算
- 再者这些方法都是基于未来状态然后靠反向传播来更新当前值函数。
8.1 模型和规划
agent可以根据环境的模型来预计某一动作的反应。有些模型是随机性的,这种情况下每一种反馈都有它发生的概率。
- 分布模型有所有可能性的概率分布
- 采样模型是一种根据分布概率采样的一种可能选择。分布模型更精确,但是实际上采样模型比分布模型更容易得到。模型可以用来模拟环境或者产生模拟经验。
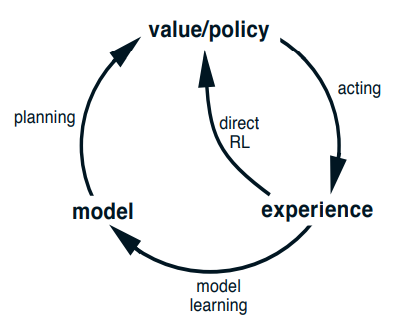
规划在这指的是模型是输入,输出一个模型或者改进一个模型。如下图所示。

规划 共有的结构

通过这个角度我们强调了规划方法和学习方法的关系。它们都是通过反向传播操作来更新值函数。区别是规划方法使用模拟的经验,学习方法用到了实际的经验
这个共有的结构意味着许多思想和算法可以在规划方法和学习方法中相互转换。下图展示了基于一步Q-learning的规划方法的简单的例子。称为random sample One step tabular Q-learning。

除了规划方法和学习方法的统一视角,在这一章的另一个主题是微小步进。小的步进使得规划方法可以在小的损失下被打断,以便于高效的在规划方法中结合学习和行动。
8.2 Dyna:结合规划,行动和学习
思想
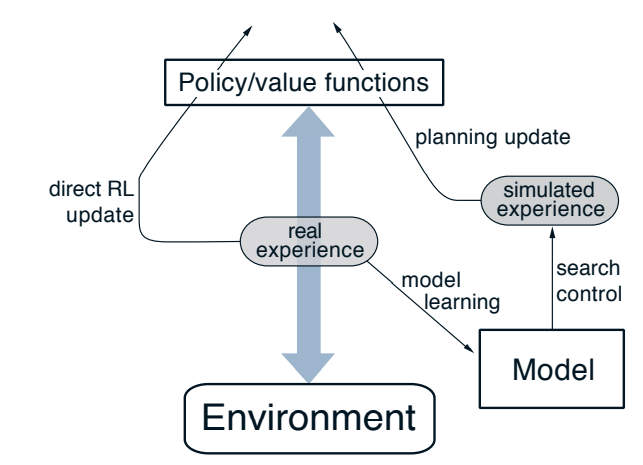
伪代码

8.3 当模型是错误的
如上图中可以看出,在环境发生变化是,Dyna-Q+能找到更好的策略,而Dyna-Q没有找到更好的策略,尽管action的选择使用e-greedy方法。
Dyna-Q+算法是Dyna-Q的改进版,它是简单的启发式搜索的一种应用。在Dyna-Q+智能体记录着每个状态-动作对发生后的时间,时间越长说明对它的估计不正确的可能性就越大。为了鼓励访问它们,所以当在模拟经验中选中她们时额外的奖励被加在他们身上,奖励被设置为r+k√t(r是本来的回报t是访问过后的时间)。
8.4 有优先目标的扫描
But a uniform selection is usually not the best; planning can be much more ecient if simulated transitions and updates are focused on particular state–action pairs

8.5 期望更新VS采样更新
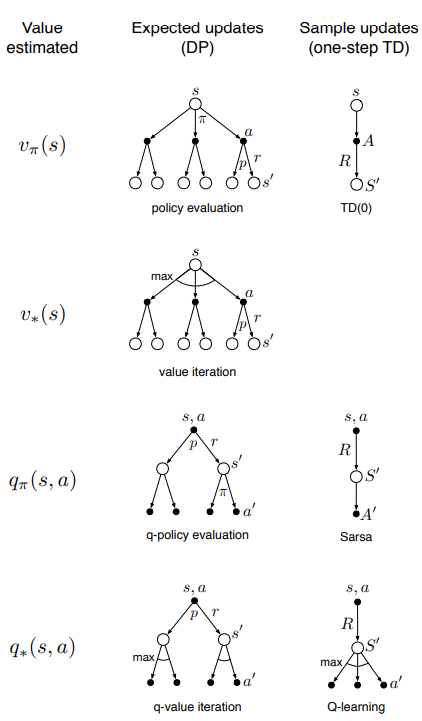
8.6 轨迹采样
8.7 实时动态规划
8.8 在决策时的规划
8.9 启发式搜索
8.10 rollout算法
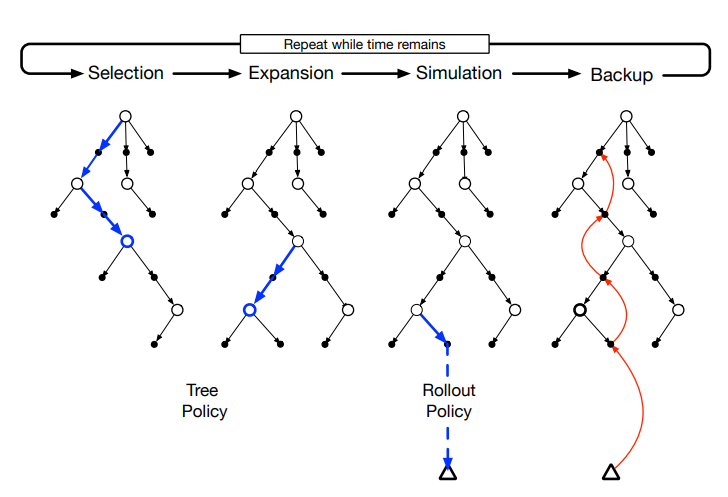
8.11 蒙特卡洛树搜索
总结起来有四个步骤,如下图
- 选择。从根节点开始,遍历状态行为值来选择最大的叶子节点。
- 扩张。通过已选叶节点的一个孩子结点并给他们添加未探索过的叶子节点来拓展树。
- 模拟。从选择的结点或者新加的结点开始,用rollout算法来模拟完整的情节,首先选择在树里的状态。
- 反馈更新。用模拟的反馈奖赏来反向传播并更新在搜索树之内的状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号